【Redis缓存数据库】Redis的引入及NIO的原理
一.为什么会有数据库
?1.1 数据的存储形式
? ? ? ? 在计算机中,数据一般是存储在磁盘之中(传统的机械硬盘),而磁盘存储数据会有两个操作步骤(寻址及带宽)直接会影响到计算机读取数据的速度,一般情况下,磁盘寻址的时间在ms级别,磁盘带宽一般是达到G/M级别。而磁盘读取数据的时候,针对应用程序,操作系统一般会以4K的数据块形式去读取
?1.2 数据库技术的引入?
? ? ? ? 假设现在有一堆数据存储在磁盘中,并且以连续扇区(一般情况下是512Byte)的方式存储,而计算机一般针对数据的操作,是要先将数据读取到内存(内存寻址速度一般在ns级别,带宽级别远超过磁盘带宽)之中,如果数据量达到GB级别,这个时候影响数据操作的瓶劲就在于磁盘IO,因此,为了解决该问题,便引入了数据库技术,方便其对数据进行管理和内存读取数据。
?1.3?数据库技术的原理
? ? ? ? 为了解决以上的问题,就需要设计一种数据结构,使得操作系统在内存中管理这些数据十分高效,根据数据结构中B+树的概念(该部分会在另外一个地方讲解为什么要使用B+树)就可以知道通过B+树的数据结构形式可以使得查询数据的时间复杂度大大降低,数据库的整体架构如下:
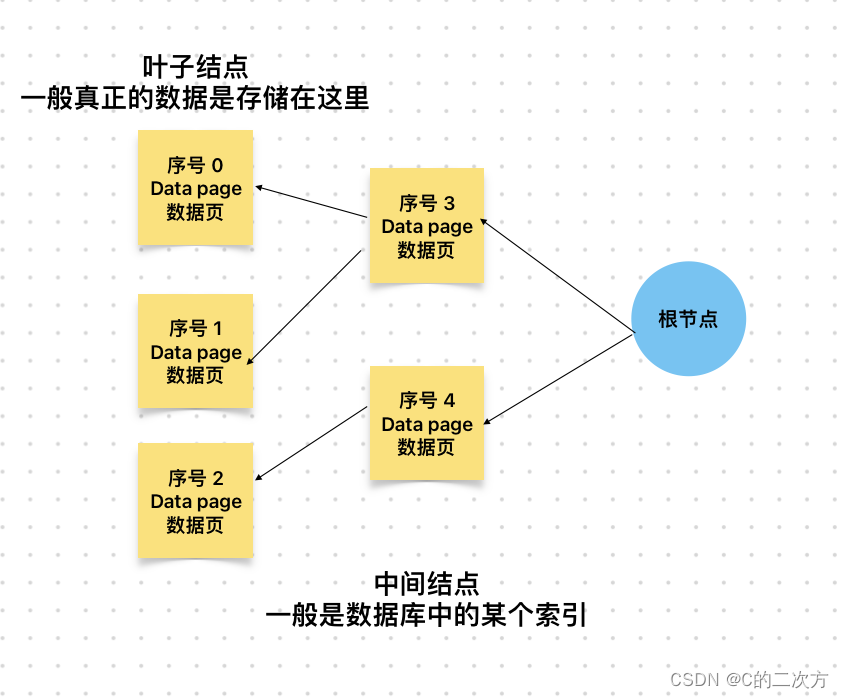 ???????
???????
? ? ? ? 在关系型数据库中,我们需要通过scheme来定义数据表,其实就是定义了多少数据页来存储对应的数据,而且数据库一般是采用行级存储的
二.缓存机制的引入
1.1 传统数据库存在的问题
? ? ? ?假设使用数据库管理数据,就会存在一个问题,如果数据量很大,那么数据库表结构就会变得很大,这个时候在有索引的情况下,会带来性能上的下降(增删改性能会下降,因为这个时候会改变整体的B+树中叶子结点及中结点,系统需要重新维护这些结点,但查询操作就会受到磁盘带宽的影响),在当前访问量如此巨大的互联网系统中,使用传统的数据库对其进行管理,已经非常不符合当前实际情况。
1.2 缓存机制
? ? ? 正如上面所说,内存在寻址和带宽方面是明显优于磁盘的,因此,如果使用内存存储数据,就会满足数据量很大情况下,系统性能的要求,当如果将全部数据都使用内存型的数据库,就会带来成本过高的情况,例如采用 SAP的HANA的解决方案,成本会非常高,因此,这里采用了一种折中方案,就是将部分数据存储到内存之中,这样在成本和性能上都可以满足实际情况。
三.Redis的诞生
1.1 传统的memcached技术存在的问题
? ? ?基于以上的缓存机制,已经有了memcached的技术存在,但大部分互联网公司并没有采用该方案,以下面的例子来展开讲讲,memcached存在的问题,假设现在有多个客户端client访问服务器,中间有一个memcached作为缓存,如下图所示:
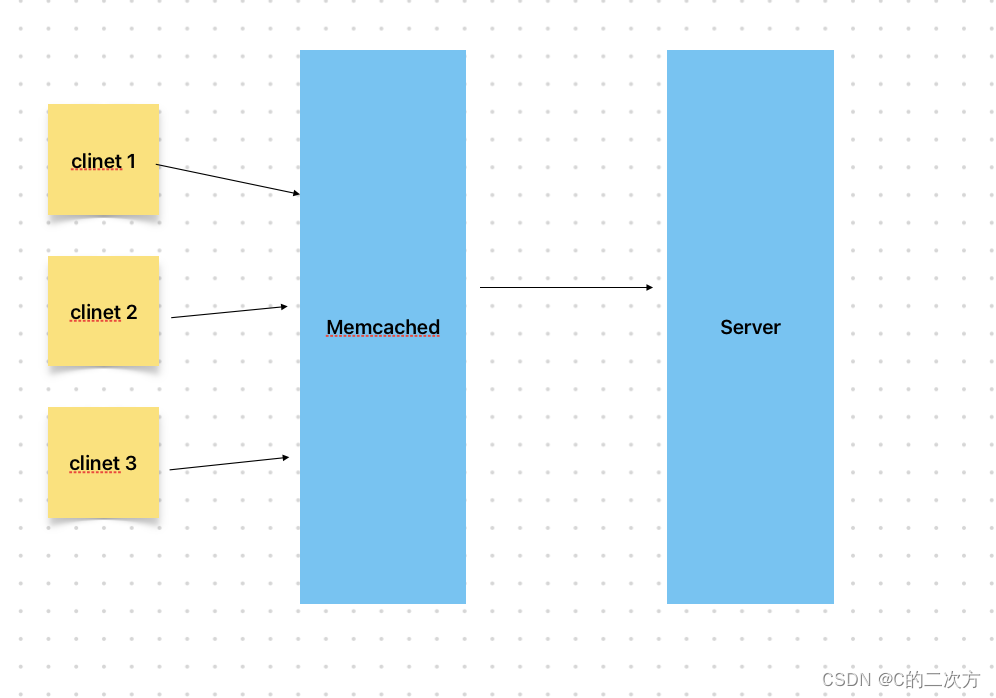
? ? ? ? 某个客户端查询数据,memcached会进行处理,这个时候会将整个数据返回回来,一般是json形式返回,这个时候,数据量会很大,而且客户端要做对应的操作,性能也会受到影响。
1.2 Redis技术引入
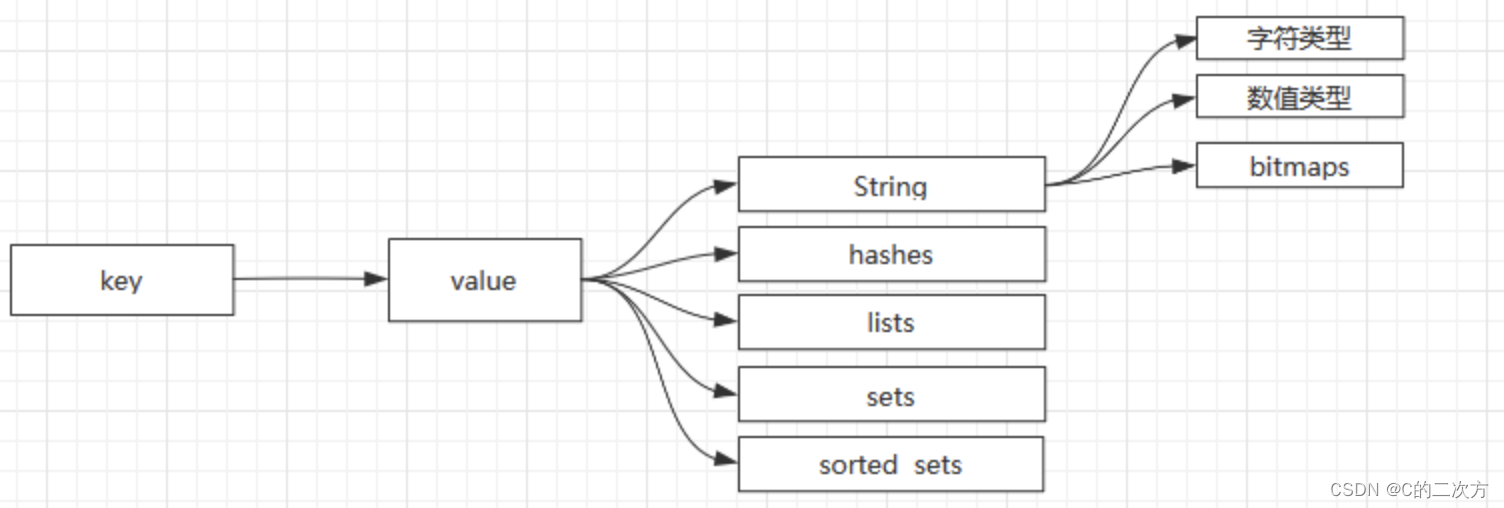
? ? ? ?这个时候,需要让缓存数据库能够进行对应的操作,减少网络IO的负担,因此便有了Redis技术,Redis提供许多种数据类型,它可以针对对应的数据进行进一步的处理。Redis支持的数据类型如下图所示:
? ? ? ?
? ? ?这个时候,实际上就是将计算向数据移动。
?redis官网介绍:
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。
.
它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。
Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)
? ? ? 具体和memcached的对比可以看下图:
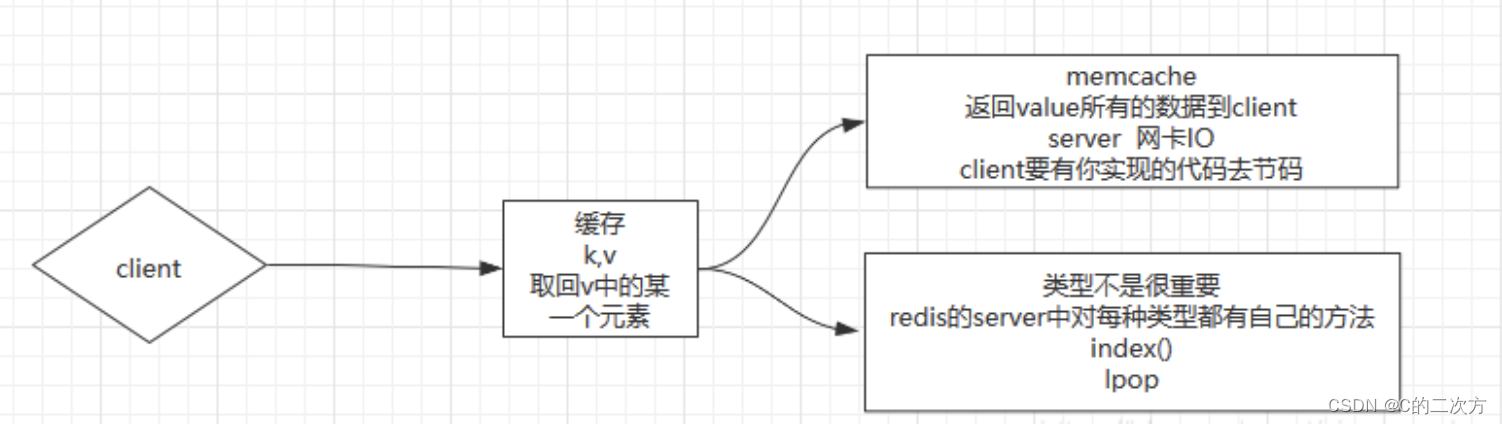
? ? ? 总结:
?? ? ? ??Memcached:多个Client进行访问的时候,网卡IO就会成为最大的瓶颈,并且在Client端要需要编写代码去针对数据做对应的操作。
? ? ? ? Redis:因为有类型,但是类型有不是太重要的,重要的是Redis服务器对每种类型都有自己的方法index(),lpop(),Client端的代码也会比较轻盈。不需要将全部的数据返回。
四.NIO的原理(epoll函数实现)
1.BIO
? ?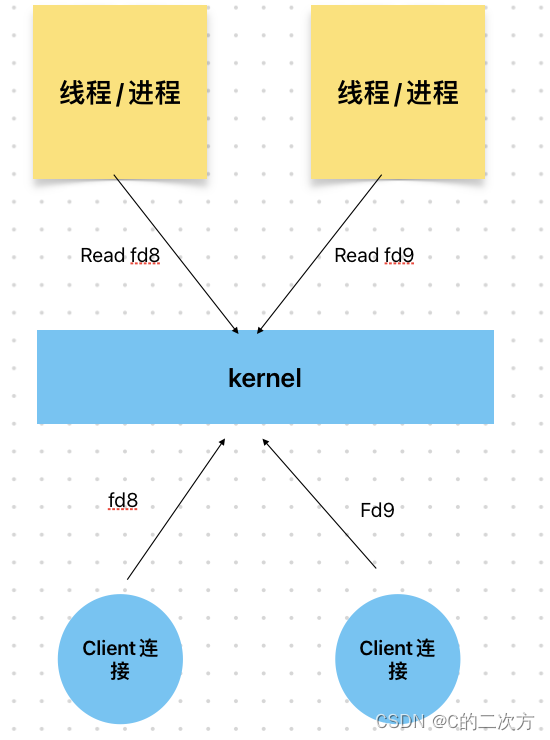
? ? ? ?Linux有kernel内核,很多的Client连接都会由kernel内核处理,而在Linux中所有的操作是基于文件的,这些连接就是文件描述符(fd8,fd9),进程(Windows中)/线程(Linux中)可以从kernel中read这些描述符获得数据。在BIO时期,当Client1想要发送数据给Server,首先要先把数据通过fd8发送给kernel,再由Server进程1 read(fd8)得到数据进行计算处理,处理的时候进程1不能做别的事情,是一个阻塞的状态,这个时候如果Client2也来数据了,Server需要再开启一个进程2才能处理Client2发送过来的数据。
弊端:
?1.在JVM中,一个线程所占据的内存空间为1M,BIO会随着Clinet访问变多,会不断开辟空间,导致内存消耗过大。
?2.线程多了CUP调度会出现问题。
? ? 如果在只有一个CPU的情况下,CPU在调度进程1的时间片里,数据没到,进程1会block。这个时候如果进程2的数据包到了,但是CPU的时间片在处理进程1,还没有轮到进程2,所以进程2需要等待进程1CPU时间片结束后才能得到处理
? ? ? 通过以上的描述,可以得知,在BIO模式下,无法适应在网络访问次数较高的情况。因为内存有限,BIO需要不断创建线程空间,而且线程切换需要成本。
2.同步非阻塞NIO
? ? ??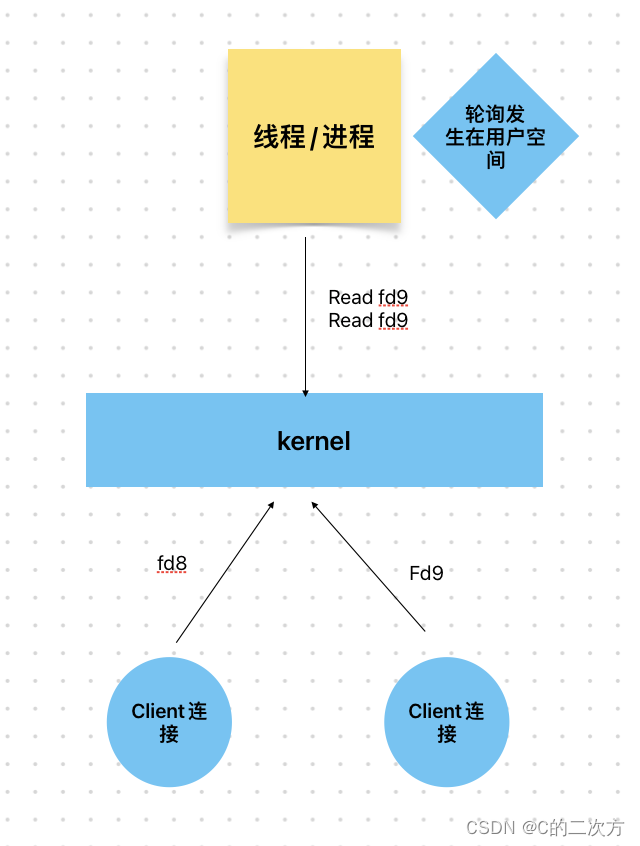
? ? ? ?而在后期发展的历程中,kernel内核发展出了非阻塞的socket,这个时候BIO中阻塞问题得到解决,建立连接后socket对应的fd不是nonBlock(非阻塞,无需等待其中一个fd被read完数据之后,才能处理其他fd),这个时候,只要在JVM中创建一个线程,不断轮询遍历read这些文件操作符fd,进行对应的处理。
注意事项:
? ? 同步:遍历和处理数据都是一个线程来完成的。
? ? 非阻塞:指的是socket I/O非阻塞,不阻塞线程而导致后面的代码无法执行同步非阻塞NIO的分析:
优势:通过修改内核fd非阻塞的方式,可以使用一个线程完成对数据的读取,减少了线程的创建和CUP切换线程所带来的的成本。
缺点:用户空间需要不断轮询操作符fd,当有10000个client的时候,会有10000个fd出现,用户空间轮询一次要进行10000次内核的调用,这样带来的成本很大(从用户态切换到内核太所需要的成本较大,切换次数频繁)。
3.多路复用NIO
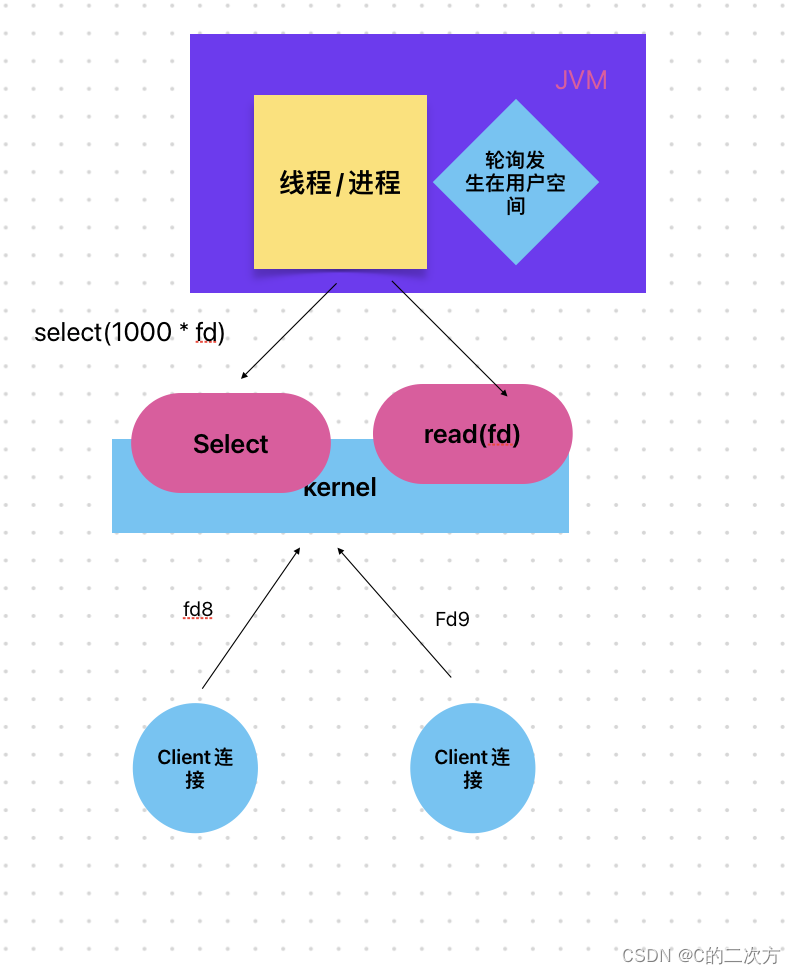
? ? ??
? ? ? 基于同步非阻塞NIO的情况,它的性能瓶颈在于需要在用户空间不断轮询,频繁进行用户态和内核态之间的切换,因此,解决思路就是减少该部分的切换,将轮询工作交给内核进行处理。于是,在Linux的内核中,便诞生了select的系统调用。
-
? ? ?Select的工作原理
? ? ?Client发送数据给Server的进程会建立fd(文件描述符),用户空间的线程收到多少描述符都会传递给内核的select函数,由select监控这些fd是否有数据包到达。
? ? ? select监控到有fd并且把这些fd发送给Server进程,Server进程遍历这些fd查看哪些标记为有数据到达,根据这些有数据到达的fd调用read(fd)读取数据。
总结:
?优点:与同步非阻塞NIO对比,将轮询的工作交给Kernel,减少了kernel调用的次数。
?缺点:fd相关数据在用户态和内核态之间传递其实是一个copy的过程,需要创建对应的内存空间,还是会造成资源的损耗。
4.epoll的出现
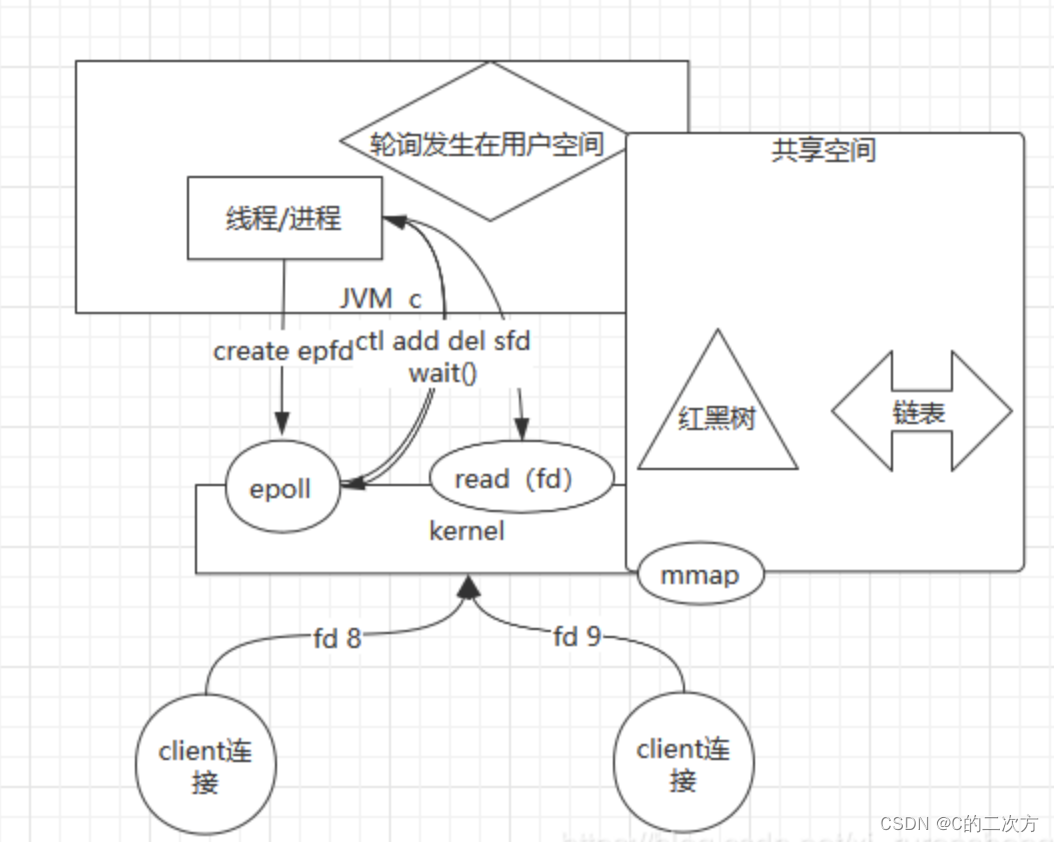
? ? ? ?基于多路复用NIO的问题,主要的解决思路就是建立一个共享空间,减少fd之间的拷贝。这个时候便有了epoll函数。
-
epoll函数的工作原理
? ? ? 在epoll的模型中,用户空间进程会先创建epoll的fd,只要外界有连接到进程,进程就会把和外界连接的fd写给epoll的fd,然后内核的epoll会准备一个mmap的映射,就是用户态和内核态的fd对应数据位置做了一个映射,mmap的本质是给用户态和内核态建立一个共享空间,这个共享空间里有一个红黑树的数据结构和一个链表的数据结构,epoll再把收到的fd存到这个共享空间的红黑树,内核检测红黑树中的fd哪个有数据了,就把这个fd放到链表中。用户空间进程调用wait()等待,只要Client那边有数据了,wait就可以返回变成不阻塞从链表中取出fd,然后用户空间的进程可以直接调用read(fd)读取数据就可以了。
-
?Redis为什么这么快
? ? Redis是单线程的,单线程可以实现串行,串行的结果就是在高并发的时候数据并不需要加锁,减少冲突,而且Redis调用来epoll,具体优势如上所述。
? ?官方给出的数据是Redis每秒能处理15W的请求(单机),也就是说再每秒15W请求一下的并发,Redis处理请求的速度是大于IO的。(Redis是基于内存的,寻址是纳秒,而socket对应的是网卡,寻址是毫秒,纳秒和毫秒差了10W倍。)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 深入了解鸿鹄电子招投标系统:Java版企业电子招标采购系统的核心功能
- 【算法】【动规】环绕字符串中唯一的子字符串
- python爬虫案例分享
- @NotBlank、@Length、@Range详细讲解
- ASCII码常用
- QT界面表格加入勾选框和表格更改颜色显示NG和OK
- Synchronized、ReentrantLock、ReadWriteLock 介绍
- Vue学习笔记8--插槽<slot></slot>
- 第四周:机器学习知识点回顾
- 磁盘坏道修复工具-是一款非常方便实用的磁盘坏道修复软件-供大家学习研究参考