yolov7简化网络yaml配置文件
发布时间:2023年12月18日
本篇介绍如何简化yolov7的网络配置文件
先上一张简化后的网络结构图:
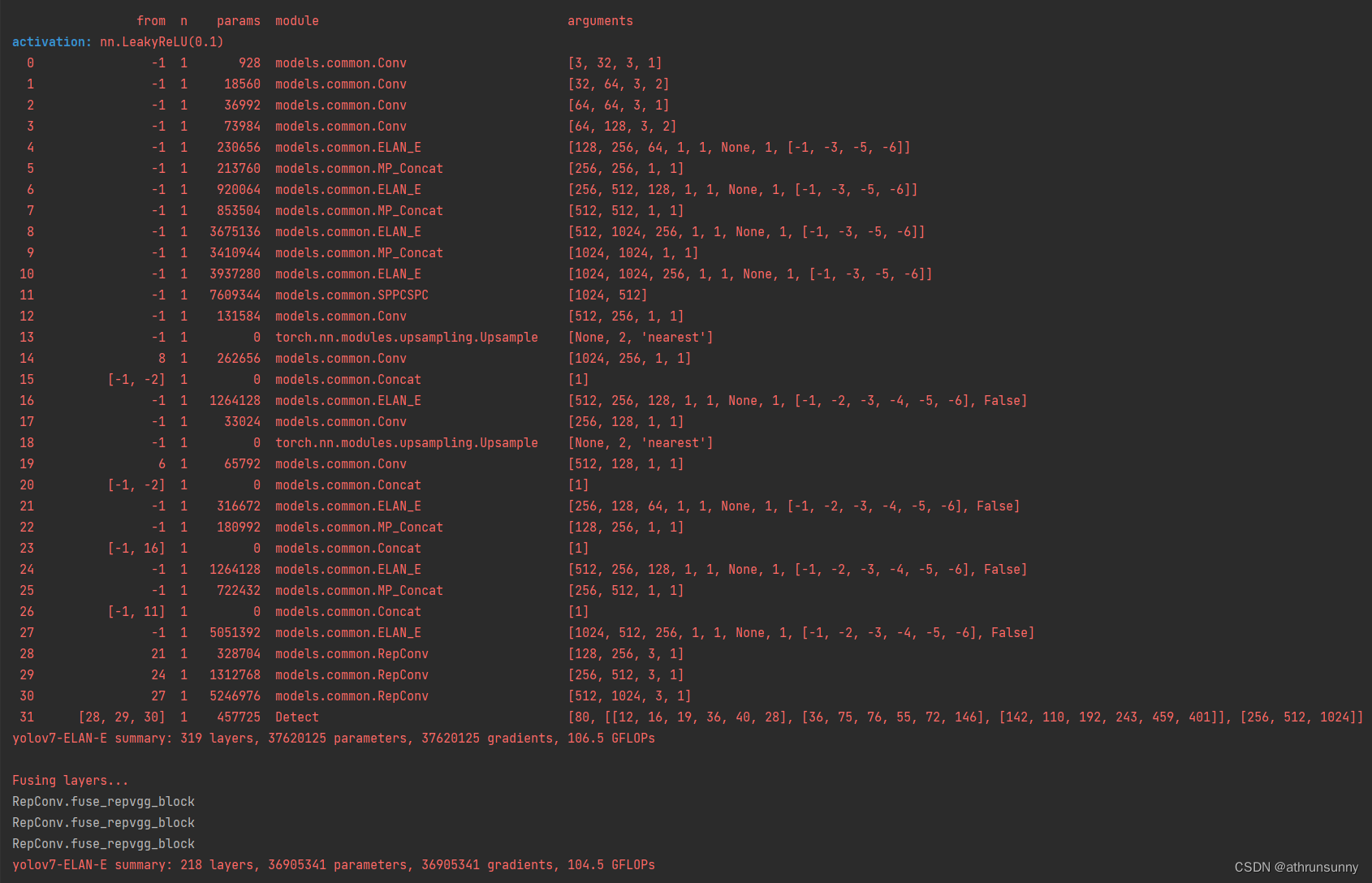
了解v7的都知道,配置文件中网络层数多达100多层,不过并不复杂,相似的模块比较多,可以看到简化后配置文件的层数也就31层。
简化前的配置文件:
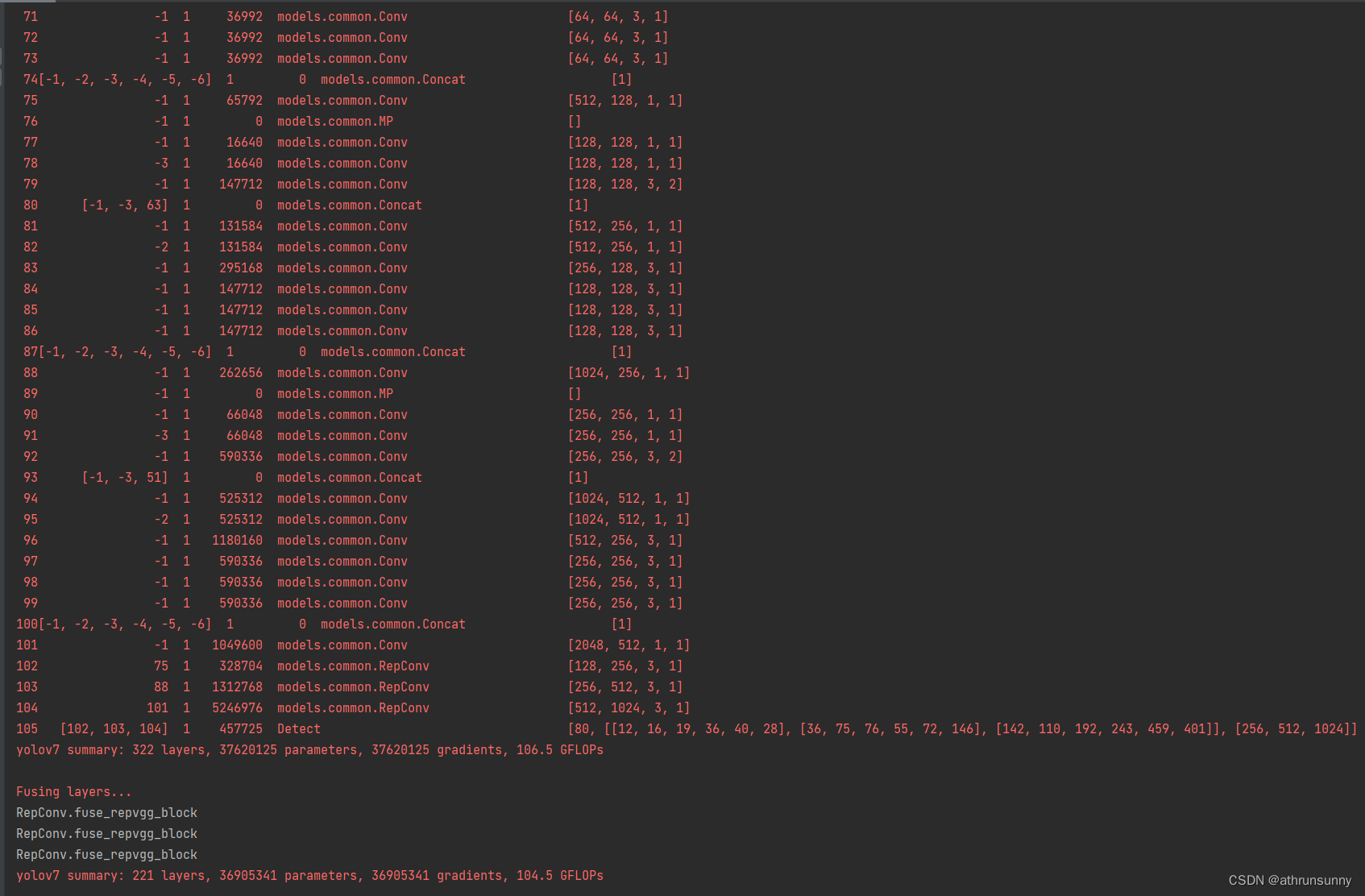
首先创建?yolov7-ELAN-E.yaml
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
activation: nn.LeakyReLU(0.1)
# anchors
anchors:
- [12,16, 19,36, 40,28] # P3/8
- [36,75, 76,55, 72,146] # P4/16
- [142,110, 192,243, 459,401] # P5/32
# yolov7 backbone
backbone:
# [from, number, module, args] c2, k=1, s=1, p=None, g=1, act=True
[[-1, 1, Conv, [32, 3, 1]], # 0
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [128, 3, 2]], # 3-P2/4
# c2, in_c, k=1, s=1, p=None, g=1, layer=[], backbone=True, act=True
[-1, 1, ELAN_E, [256, 64,1, 1, None, 1, [-1, -3, -5, -6]]], # 4
[-1, 1, MP_Concat, [256, 1, 1]], # 5-P3/8
[-1, 1, ELAN_E, [512, 128,1, 1, None, 1, [-1, -3, -5, -6]]], # 6
[-1, 1, MP_Concat, [512, 1, 1]], # 7-P4/16
[-1, 1, ELAN_E, [1024, 256, 1, 1, None, 1, [-1, -3, -5, -6]]], # 8
[-1, 1, MP_Concat, [1024, 1, 1]], # 9-P5/32
[-1, 1, ELAN_E, [1024, 256, 1, 1, None, 1, [-1, -3, -5, -6]]], # 10
]
# yolov7 head
head:
[[-1, 1, SPPCSPC, [512]], # 11
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[8, 1, Conv, [256, 1, 1]], # route backbone P4
[[-1, -2], 1, Concat, [1]],
[-1, 1, ELAN_E, [256, 128,1, 1, None, 1, [-1, -2, -3, -4, -5, -6],False]], # 16
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[6, 1, Conv, [128, 1, 1]], # route backbone P3
[[-1, -2], 1, Concat, [1]],
[-1, 1, ELAN_E, [128, 64,1, 1, None, 1, [-1, -2, -3, -4, -5, -6],False]], # 21
[-1, 1, MP_Concat, [256, 1, 1]],
[[-1, 16], 1, Concat, [1]],
[-1, 1, ELAN_E, [256,128, 1, 1, None, 1, [-1, -2, -3, -4, -5, -6],False]], # 24
[-1, 1, MP_Concat, [512, 1, 1]],
[[-1, 11], 1, Concat, [1]],
[-1, 1, ELAN_E, [512, 256,1, 1, None, 1, [-1, -2, -3, -4, -5, -6],False]], # 27
[21, 1, RepConv, [256, 3, 1]],
[24, 1, RepConv, [512, 3, 1]],
[27, 1, RepConv, [1024, 3, 1]],
[[28,29,30], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
?在common.py中添加
class ELAN_E(nn.Module):
# Yolov7 ELAN with args(ch_in, ch_out, kernel, stride, padding, groups, activation)
def __init__(self, c1, c2, in_c, k=1, s=1, p=None, g=1, layer=[],
backbone=True, act=True):
super().__init__()
self.layer = layer
if backbone:
c_ = in_c
c_out = c_ * len(self.layer)
self.cv1 = Conv(c1, c_, k=k, s=s, p=p, g=g, act=act)
self.cv2 = Conv(c1, c_, k=k, s=s, p=p, g=g, act=act)
self.cv3 = Conv(c_, c_, k=3, s=s, p=p, g=g, act=act)
else:
c_ = in_c
c_out = c_ * 4 + c2 * 2
self.cv1 = Conv(c1, c2, k=k, s=s, p=p, g=g, act=act)
self.cv2 = Conv(c1, c2, k=k, s=s, p=p, g=g, act=act)
self.cv3 = Conv(c2, c_, k=3, s=s, p=p, g=g, act=act)
self.cv4 = Conv(c_, c_, k=3, s=s, p=p, g=g, act=act)
self.cv5 = Conv(c_, c_, k=3, s=s, p=p, g=g, act=act)
self.cv6 = Conv(c_, c_, k=3, s=s, p=p, g=g, act=act)
self.cv7 = Conv(c_out, c2, k=k, s=s, p=p, g=g, act=act)
def forward(self, x):
x1 = self.cv1(x)
x2 = self.cv2(x)
x3 = self.cv3(x2)
x4 = self.cv4(x3)
x5 = self.cv5(x4)
x6 = self.cv6(x5)
inter_x = [x1, x2, x3, x4, x5, x6]
result = [inter_x[i] for i in self.layer]
x7 = torch.cat(result, 1)
return self.cv7(x7)
class MP_Concat(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
super().__init__()
c2 = c2 // 2
self.m = nn.MaxPool2d(kernel_size=2, stride=2)
self.cv1 = Conv(c1, c2, k=k, s=s, p=p, g=g, act=act)
self.cv2 = Conv(c1, c2, k=k, s=s, p=p, g=g, act=act)
self.cv3 = Conv(c2, c2, k=3, s=2, p=p, g=g, act=act)
def forward(self, x):
x1 = self.m(x)
x2 = self.cv1(x1)
x3 = self.cv2(x)
x4 = self.cv3(x3)
x5 = torch.cat((x2, x4), 1)
return x5
class SPPCSPC(nn.Module):
# CSP https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=(5, 9, 13)):
super(SPPCSPC, self).__init__()
c_ = int(2 * c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(c_, c_, 3, 1)
self.cv4 = Conv(c_, c_, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
self.cv5 = Conv(4 * c_, c_, 1, 1)
self.cv6 = Conv(c_, c_, 3, 1)
self.cv7 = Conv(2 * c_, c2, 1, 1)
def forward(self, x):
x1 = self.cv4(self.cv3(self.cv1(x)))
y1 = self.cv6(self.cv5(torch.cat([x1] + [m(x1) for m in self.m], 1)))
y2 = self.cv2(x)
return self.cv7(torch.cat((y1, y2), dim=1))
class RepConv(nn.Module):
# Represented convolution
# https://arxiv.org/abs/2101.03697
def __init__(self, c1, c2, k=3, s=1, p=None, g=1, act=True, deploy=False):
super(RepConv, self).__init__()
self.deploy = deploy
self.groups = g
self.in_channels = c1
self.out_channels = c2
assert k == 3
assert autopad(k, p) == 1
padding_11 = autopad(k, p) - k // 2
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
if deploy:
self.rbr_reparam = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=True)
else:
self.rbr_identity = (nn.BatchNorm2d(num_features=c1) if c2 == c1 and s == 1 else None)
self.rbr_dense = nn.Sequential(
nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False),
nn.BatchNorm2d(num_features=c2),
)
self.rbr_1x1 = nn.Sequential(
nn.Conv2d(c1, c2, 1, s, padding_11, groups=g, bias=False),
nn.BatchNorm2d(num_features=c2),
)
def forward(self, inputs):
if hasattr(self, "rbr_reparam"):
return self.act(self.rbr_reparam(inputs))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.act(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return (
kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid,
bias3x3 + bias1x1 + biasid,
)
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch[0].weight
running_mean = branch[1].running_mean
running_var = branch[1].running_var
gamma = branch[1].weight
beta = branch[1].bias
eps = branch[1].eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, "id_tensor"):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros(
(self.in_channels, input_dim, 3, 3), dtype=np.float32
)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def repvgg_convert(self):
kernel, bias = self.get_equivalent_kernel_bias()
return (
kernel.detach().cpu().numpy(),
bias.detach().cpu().numpy(),
)
def fuse_conv_bn(self, conv, bn):
std = (bn.running_var + bn.eps).sqrt()
bias = bn.bias - bn.running_mean * bn.weight / std
t = (bn.weight / std).reshape(-1, 1, 1, 1)
weights = conv.weight * t
bn = nn.Identity()
conv = nn.Conv2d(in_channels=conv.in_channels,
out_channels=conv.out_channels,
kernel_size=conv.kernel_size,
stride=conv.stride,
padding=conv.padding,
dilation=conv.dilation,
groups=conv.groups,
bias=True,
padding_mode=conv.padding_mode)
conv.weight = torch.nn.Parameter(weights)
conv.bias = torch.nn.Parameter(bias)
return conv
def fuse_repvgg_block(self):
if self.deploy:
return
print(f"RepConv.fuse_repvgg_block")
self.rbr_dense = self.fuse_conv_bn(self.rbr_dense[0], self.rbr_dense[1])
self.rbr_1x1 = self.fuse_conv_bn(self.rbr_1x1[0], self.rbr_1x1[1])
rbr_1x1_bias = self.rbr_1x1.bias
weight_1x1_expanded = torch.nn.functional.pad(self.rbr_1x1.weight, [1, 1, 1, 1])
# Fuse self.rbr_identity
if (isinstance(self.rbr_identity, nn.BatchNorm2d) or isinstance(self.rbr_identity,
nn.modules.batchnorm.SyncBatchNorm)):
# print(f"fuse: rbr_identity == BatchNorm2d or SyncBatchNorm")
identity_conv_1x1 = nn.Conv2d(
in_channels=self.in_channels,
out_channels=self.out_channels,
kernel_size=1,
stride=1,
padding=0,
groups=self.groups,
bias=False)
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.to(self.rbr_1x1.weight.data.device)
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.squeeze().squeeze()
# print(f" identity_conv_1x1.weight = {identity_conv_1x1.weight.shape}")
identity_conv_1x1.weight.data.fill_(0.0)
identity_conv_1x1.weight.data.fill_diagonal_(1.0)
identity_conv_1x1.weight.data = identity_conv_1x1.weight.data.unsqueeze(2).unsqueeze(3)
# print(f" identity_conv_1x1.weight = {identity_conv_1x1.weight.shape}")
identity_conv_1x1 = self.fuse_conv_bn(identity_conv_1x1, self.rbr_identity)
bias_identity_expanded = identity_conv_1x1.bias
weight_identity_expanded = torch.nn.functional.pad(identity_conv_1x1.weight, [1, 1, 1, 1])
else:
# print(f"fuse: rbr_identity != BatchNorm2d, rbr_identity = {self.rbr_identity}")
bias_identity_expanded = torch.nn.Parameter(torch.zeros_like(rbr_1x1_bias))
weight_identity_expanded = torch.nn.Parameter(torch.zeros_like(weight_1x1_expanded))
# print(f"self.rbr_1x1.weight = {self.rbr_1x1.weight.shape}, ")
# print(f"weight_1x1_expanded = {weight_1x1_expanded.shape}, ")
# print(f"self.rbr_dense.weight = {self.rbr_dense.weight.shape}, ")
self.rbr_dense.weight = torch.nn.Parameter(
self.rbr_dense.weight + weight_1x1_expanded + weight_identity_expanded)
self.rbr_dense.bias = torch.nn.Parameter(self.rbr_dense.bias + rbr_1x1_bias + bias_identity_expanded)
self.rbr_reparam = self.rbr_dense
self.deploy = True
if self.rbr_identity is not None:
del self.rbr_identity
self.rbr_identity = None
if self.rbr_1x1 is not None:
del self.rbr_1x1
self.rbr_1x1 = None
if self.rbr_dense is not None:
del self.rbr_dense
self.rbr_dense = None
?在BaseModel的fuse函数中添加
def fuse(self): # fuse model Conv2d() + BatchNorm2d() layers
LOGGER.info('Fusing layers... ')
for m in self.model.modules():
if isinstance(m, (Conv, DWConv)) and hasattr(m, 'bn'):
m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
delattr(m, 'bn') # remove batchnorm
m.forward = m.forward_fuse # update forward
if isinstance(m, (VanillaStem, VanillaBlock)):
# print(m)
m.deploy = True
m.switch_to_deploy()
# 添加以下代码
if isinstance(m, RepConv):
# print(f" fuse_repvgg_block")
m.fuse_repvgg_block()
# m.switch_to_deploy()
self.info()
return self?在parse_model中添加模块名
if m in {
Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x,
ELAN, SPPCSPCSIM,VanillaBlock,VanillaStem,MP_Concat,ELAN_E,RepConv,SPPCSPC}:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x}:
args.insert(2, n) # number of repeats
n = 1之后修改yolo.py的cfg路径,如果运行成功能看到最上面的图。
贫穷打工牛马项目之余改的,感觉改的还不是很优雅,欢迎小伙伴多提意见。
文章来源:https://blog.csdn.net/athrunsunny/article/details/134985116
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章