[笔记]深度学习入门 基于Python的理论与实现(三)
代码仓库
3. 神经网络
神经网络的出现就是为了解决设定权重的工作,即机器自动从数据中学习,确定合适的、能符合预期的输入与输出的权重。
3.1 从感知机到神经网络
神经网络和感知机有很多共同点,这里主要介绍差异
3.1.1 神经网络例子
下图 3-1 表示神经网络,我们将最左边的一列称为输入层,最右边的一列称为输出层,中间的一列称为中间层。中间层有时也称为
隐藏层。‘隐藏’的意思是,隐藏层的神经元(和输入层、输出层不同)肉眼看不见。另外,本书的层号从零开始计算,为了方便用 python
实现神经网络

- 图 3-1 的网络一共由 3 层神经元组成,当实际上只有 2 层神经元有权重,因此本书将其称为‘2 层网络’。也有的书会把它称为 3 层网络。
那么,神经网络中的信号是如何传递的呢?
3.1.2 复习感知机
思考下图中的网络结构
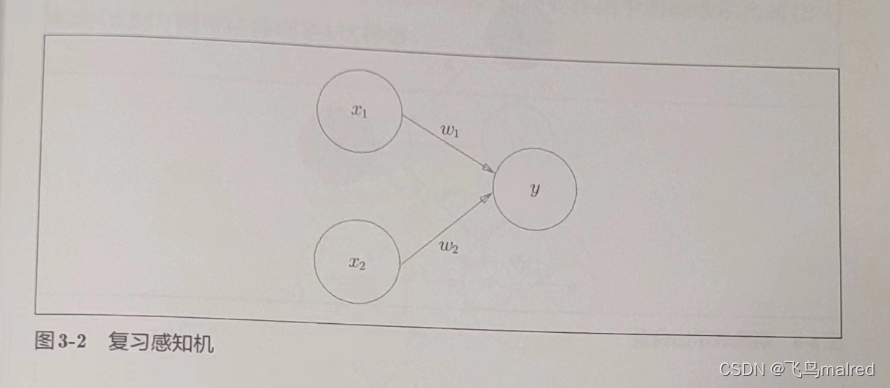

b 是被称为偏置的参数,用于控制神经元被激活的容易程度;而 w1 和 w2 是表示各个信号的权重的参数,用于控制各个信号的重要性
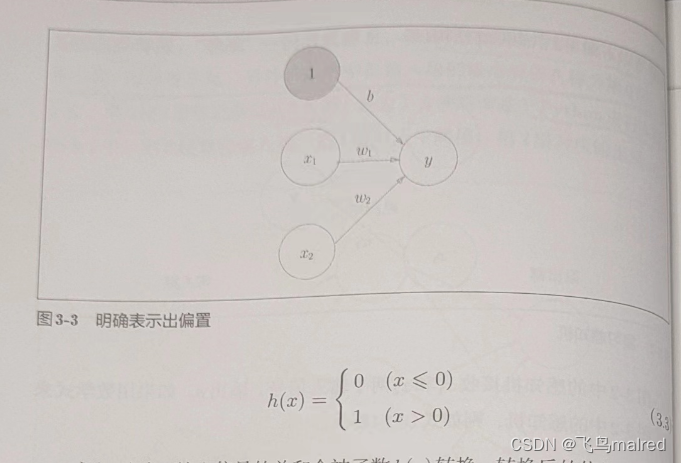
在图 3-2 中没有把 b 画出来,如果要明确表示 b,可以像图 3-3 那样。图 3-3 添加了权重为 b 的输入信号 1。这个感知机将 x1、x2、1
三个信号作为神经元的输入,将其和各自的权重相乘后,传送至下一个神经元。在下一个神经元中,计算这些加权信号的总和。如果这个总和超过
0,则输出 1,否则输出 0。
为了简化式子(3.1),我们引入一个新函数 h(x)来表示这种分情况的动作(超过 0 则输出 1,否则输出 0)。
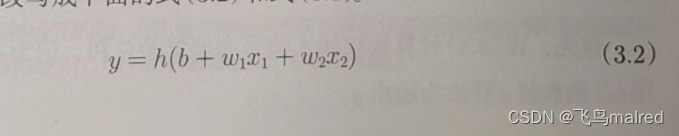
在式子(3.2)中,输入信号的总和会被函数 h(x)转换,转换后的值就是输出 y。
3.1.3 激活函数登场
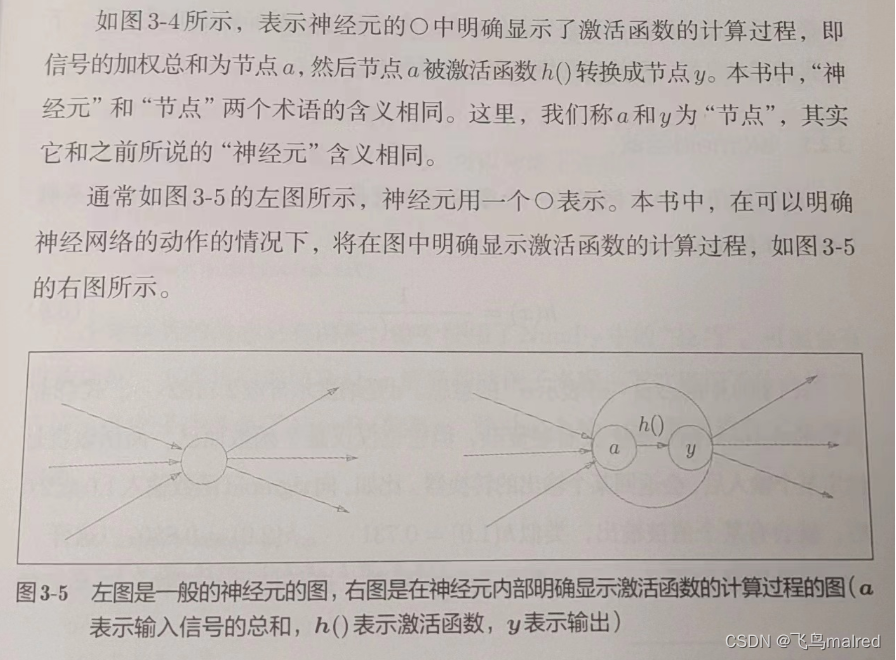
h(x)函数会将输入信号的总和转换为输出信号,这种函数一般称为激活函数(activation function)。它的作用在于决定如何来激活输入信号的总和。
改写式子(3.2),将其分为两个阶段处理,先计算输入信号的加权总和,然后用激活函数转换这一总和。
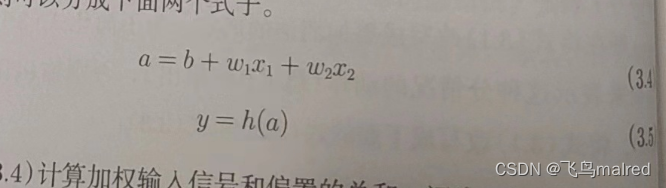
首先式子(3.4)计算加权输入信号和偏置的总和,记为 a,然后式子(3.5)用 h()函数将 a 转换为输出 y
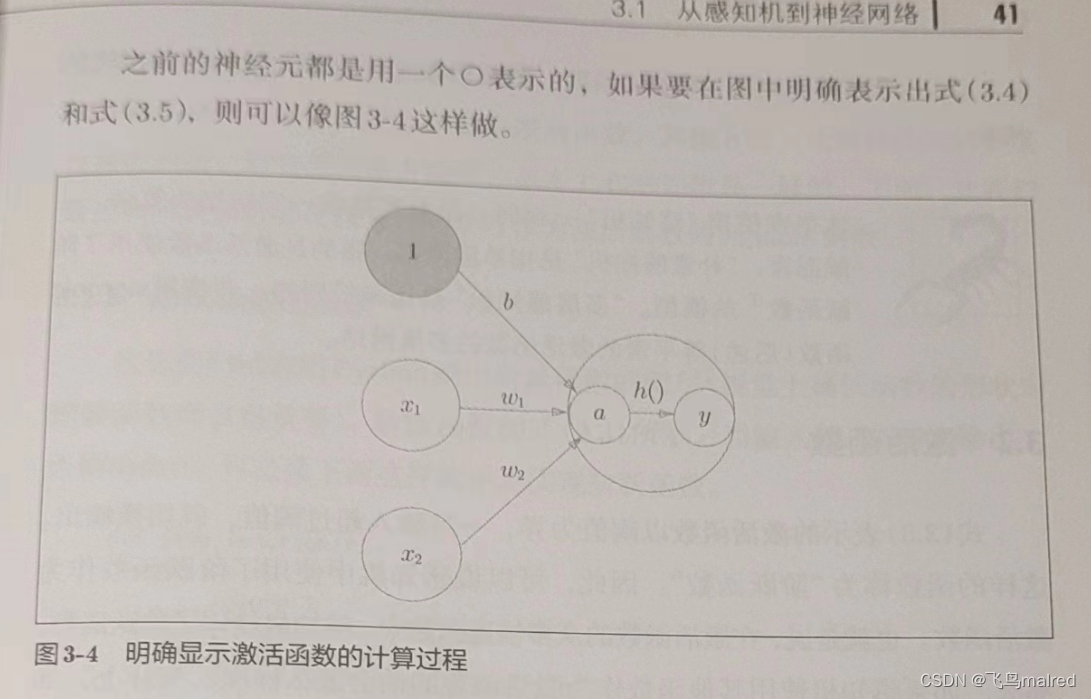
- 本书在使用‘感知机’一词时,没有严格统一它所指的算法。一般而言,‘朴素感知机’是指单层网络,指的是激活函数使用了阶跃函数的模型。‘多层感知机’是指神经网络,即使用
sigmoid 函数等平滑的激活函数的多层网络。
3.2 激活函数
式子(3.3)表示的激活函数以阈值为界,一旦输入超过阈值,就切换输出。这样的函数称为‘阶跃函数’。感知机中使用了阶跃函数作为激活函数。如果使用其他的激活函数,就可以进入神经网络的世界了。
3.2.1 sigmoid 函数
神经网络中最常使用的一个激活函数就是 sigmoid 函数
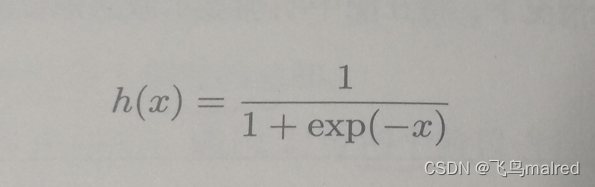
exp(-x)是 e^(-x)的意思。e 是纳皮尔常数 2.7182···。函数,就是给定某个输入后,会返回某个输出的转换器。
神经网络中用 sigmoid 函数作为激活函数,进行信号的转换,转换后的信号被传送给下一个神经元。感知机和神经网络的主要区别就在于这个激活函数。其他方面,比如多层连接的构造、信号的传递方法等,基本和感知机一致。
3.2.2 阶跃函数的实现
def step_function(x):
if x > 0:
return 1
else:
return 0
改为支持 numpy 数组的实现
def step_function(x):
y = x > 0
return y.astype(np.int)
上面使用了 numpy 的技巧
import numpy as np
x = np.array([-1.0, 1.0, 2.0])
y = x > 0
print(y) # [False True True]
在条件运算后,符合条件的变为 true,不符合的变为 false,生成一个布尔型数组。但是阶跃函数需要输出 int 类型,所以需要转换
y = y.astype(np.int)
print(y) # [0 1 1]
3.2.3 阶跃函数的图形
import numpy as np
import matplotlib.pylab as plt
plt.switch_backend('TkAgg')
# 阶跃函数
def step_function(x):
return np.array(x > 0, dtype=np.int)
x = np.arange(-5.0, 5.0, 0.1)
y = step_function(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1) # 指定y轴的范围
plt.show()
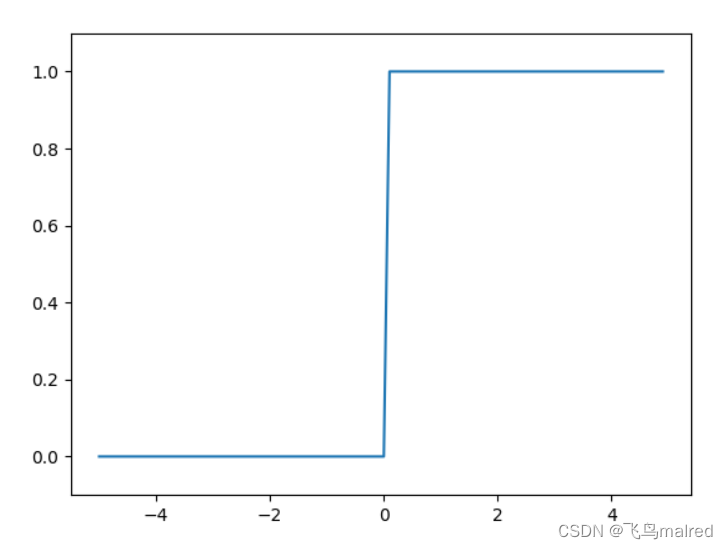
阶跃函数以 0 为界,输出从 0 开始切换为 1(或者从 1 切换为 0),值呈阶梯式变化,所以称为阶跃函数
3.2.4 sigmoid 函数的实现
def sigmoid(x):
# exp(-x) -> e^(-x)
return 1 / (1 + np.exp(-x))
x = np.array([-1.0, 1.0, 2.0])
# [0.26894142 0.73105858 0.88079708]
print(sigmoid(x))
该函数可以支持 np 数组,因为 np 有广播机制,可以支持标量和数组的运算,会将标量的计算运用到每个数组元素
画图
x = np.arange(-5.0, 5.0, 0.1)
y = sigmoid(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1) # 指定y轴的范围
plt.show()
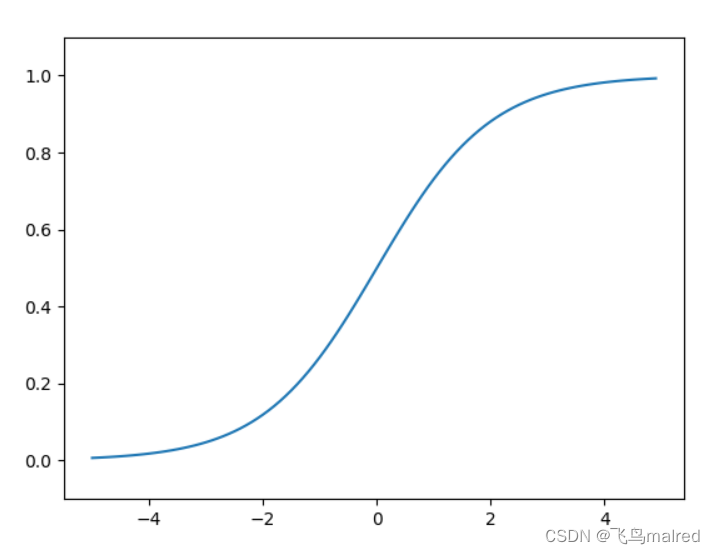
3.2.5 sigmoid 函数和阶跃函数的比较
首先,平滑性不同:sigmoid 函数是一条平滑的曲线,输出随着输入发生连续性的变化。而阶跃函数以 0 为界,输出发生急剧性的变化。sigmoid
函数的平滑性对神经网络的学习具有重要意义。
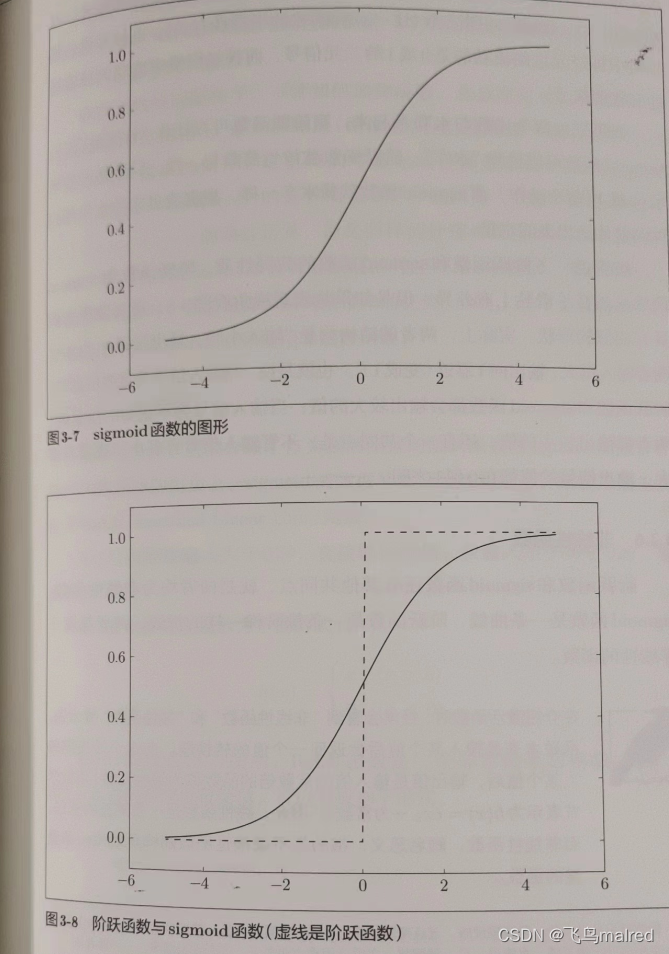
另一个不同点是,阶跃函数只能返回 0 或 1,而 sigmoid 可以返回 0.731…、0.880…等实数。也就是说,感知机中神经元之间流动的是
0 或 1 的二元信号,而神经网络中流动的是连续的实数值信号。
虽然它们在平滑性上有差异,但是从宏观视角看,有着相似的形状。它们的结构都是‘输入小时,输出接近 0(为 0);随着输入增大,输出向
1 靠近(变成 1)’。即,当输入信号为重要信息时,阶跃函数和 sigmoid
函数都会输出较大的值;当输入信号为不重要的信息时,两者都输出较小的值。还有一个共同点,不管输入信号多小或多大,输出信号都在
0
到 1 之间。
3.2.6 非线性函数
还有一个共同点,sigmoid 函数是一条曲线,阶跃函数是一条像阶梯一样的折线。两者都属于非线性函数
- 函数是输入某个值后会返回一个值的转换器。而这个转换器输入某个值后,输出值是输入值的常数倍的函数称为线性函数(h(x)
=cx)。因此,线性函数是一条笔直的直线。
神经网络的激活函数必须使用非线性函数。因为使用线性函数的话,加深神经网络的层数就没意义了。
线性函数的问题在于,无论如何加深层数,总是存在与之等效的‘无隐藏层的神经网络’。比如线性函数 h(x)=cx 作为激活函数,把 y(x)
=h(h(h(x)))的运算对应 3 层神经网络。这个运算会进行 y(x)=c * c * c * x 的乘法运算,但是同样的处理可以由 y(x)=ax (
a=c^3)
这一没有隐藏层的神经网络来表示。也就是说,线性函数作为激活函数,无法发挥多层网络带来的优势
3.2.7 ReLU 函数
在神经网络的发展历史上,很早就开始使用 sigmoid 函数了,最近则主要使用 ReLU(Rectified Linear Unit)函数
ReLU 函数在输入大于 0 时,直接输出该值;在输入小于等于 0 时,输出 0

ReLU 的代码实现很简单
def relu(x):
# 大于0输出x,小于0输出0
return np.maximum(0, x)
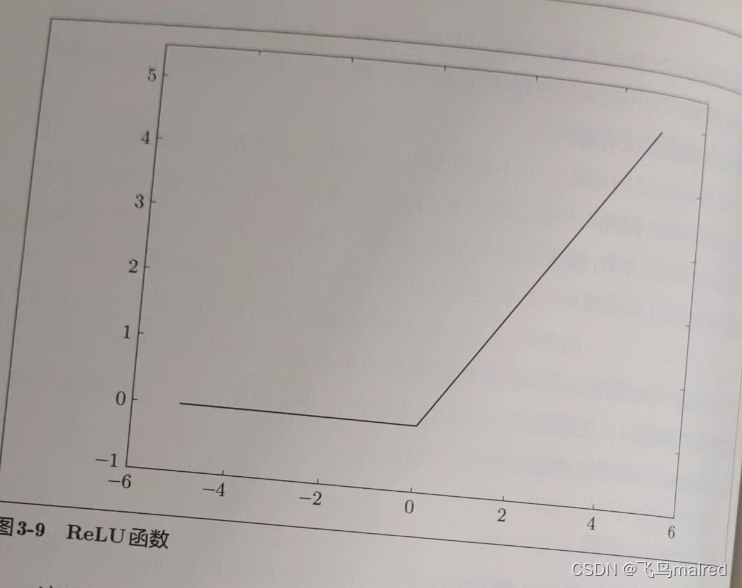
这里使用了 numpy 的 maximum 函数,它会从输入的数值中选择较大的那个值进行输出
3.3 多维数组的运算
掌握多维数组的运算,就可以高效地实现神经网络。
3.3.1 多维数组
多维数组就是‘数字的集合’,数字排成一列的集合、排成长方形的集合、排成三维状或(更一般化的)N 维状的集合……
import numpy as np
A = np.array([1, 2, 3, 4])
# [1 2 3 4]
print(A)
# 1
print(np.ndim(A))
# 4
print(A.shape[0])
数组的维数可以通过 np.ndim()函数获得。此外,数组的形状可以通过实例变量 shape 获得。A.shape 的结果是个元组
下面生成二维数组
B = np.array([[1, 2], [3, 4], [5, 6]])
# [[1 2]
# [3 4]
# [5 6]]
print(B)
# 2
print(np.ndim(B))
# (3, 2)
print(B.shape)
3x2 表示第一个维度有 3 个元素,第二个维度有 2 个元素。第一个维度是第 0 维,第二个维度是第 1 维(索引从 0
开始)。二维数组也称为矩阵(matrix)。数组的横向排列称为行(row),纵向排列称为列(column)。
3.3.2 矩阵乘法
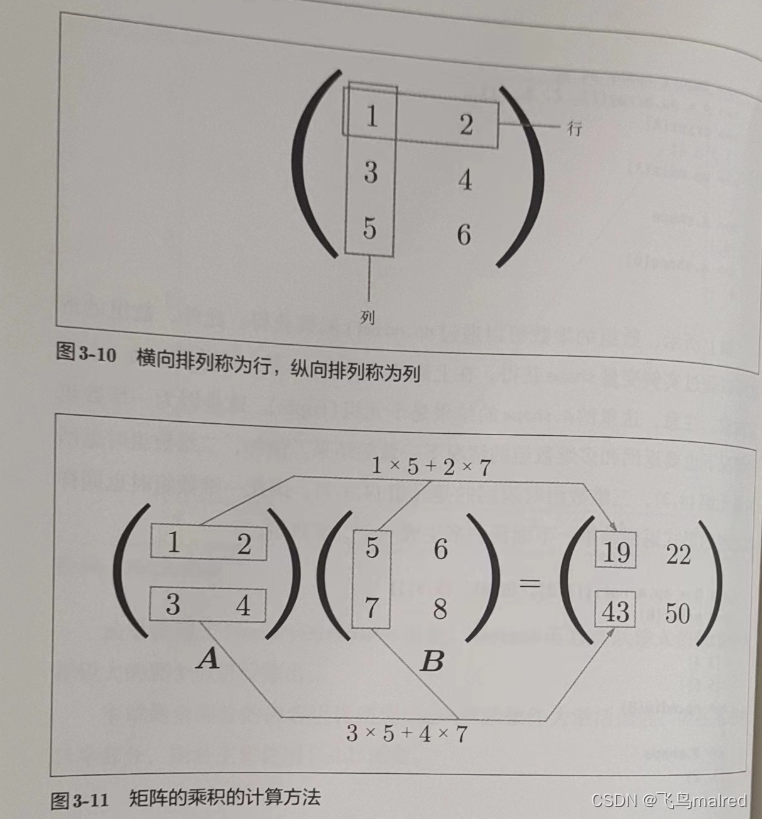
矩阵的乘积是通过左边矩阵的行(横向)和右边矩阵的列(纵向)以对应元素的方式相乘后再求和而得到的。并且,运算的结果保存为新的多维数组的元素。比如
A的第一行和B的第一列的乘积结果是新数组的第一行第一列的元素。
A = np.array([[1, 2], [3, 4]])
# (2, 2)
print(A.shape)
B = np.array([[5, 6], [7, 8]])
# (2, 2)
print(B.shape)
# [[19 22]
# [43 50]]
print(np.dot(A, B))
乘积也叫点积,可以用 np.dot()计算。和一般的运算(+或*等)不同,矩阵的乘积运算中,操作数(A、B)的顺序不同,结果也会不同。
A = np.array([[1, 2, 3], [4, 5, 6]])
# (2, 3)
print(A.shape)
B = np.array([[1, 2], [3, 4], [5, 6]])
# (3, 2)
print(B.shape)
# [[22 28]
# [49 64]]
print(np.dot(A, B))
注意矩阵的形状,A的第一维的元素个数(列数)必须和B的第 0 维的元素个数(行数)相等,才能进行乘法计算
C = np.array([[1, 2], [3, 4]])
# (2, 2)
print(C.shape)
# (2, 3)
print(A.shape)
# File "<__array_function__ internals>", line 6, in dot
# ValueError: shapes (2,3) and (2,2) not aligned: 3 (dim 1) != 2 (dim 0)
print(np.dot(A, C))
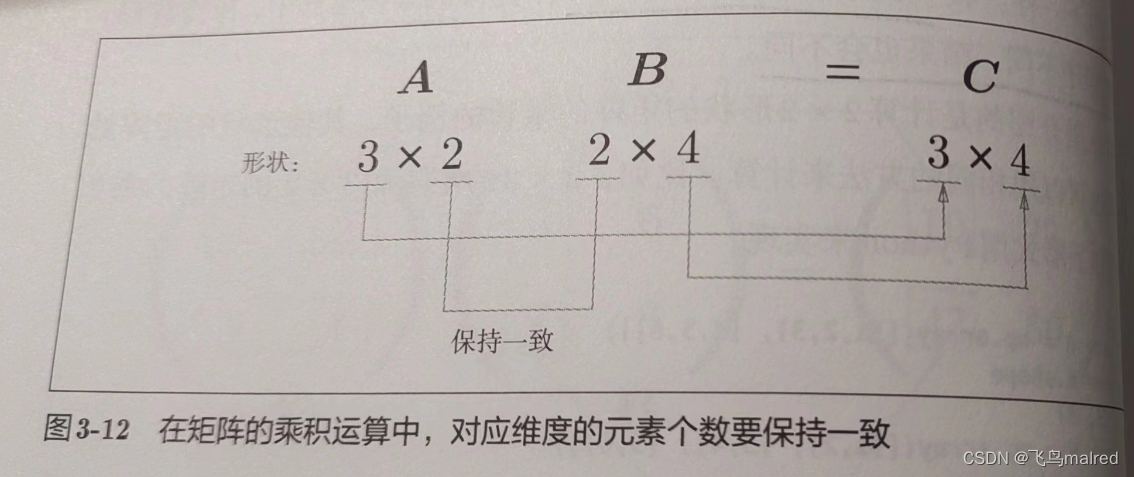
运算结果的形状是由A的行数和B的列数构成的。
A = np.array([[1, 2], [3, 4], [5, 6]])
# (3, 2)
print(A.shape)
B = np.array([7, 8])
# (2,)
print(B.shape)
# [23 53 83]
print(np.dot(A, B))

3.3.3 神经网络的内积
我们使用 numpy 矩阵来实现神经网络,这里省略了偏置和激活函数
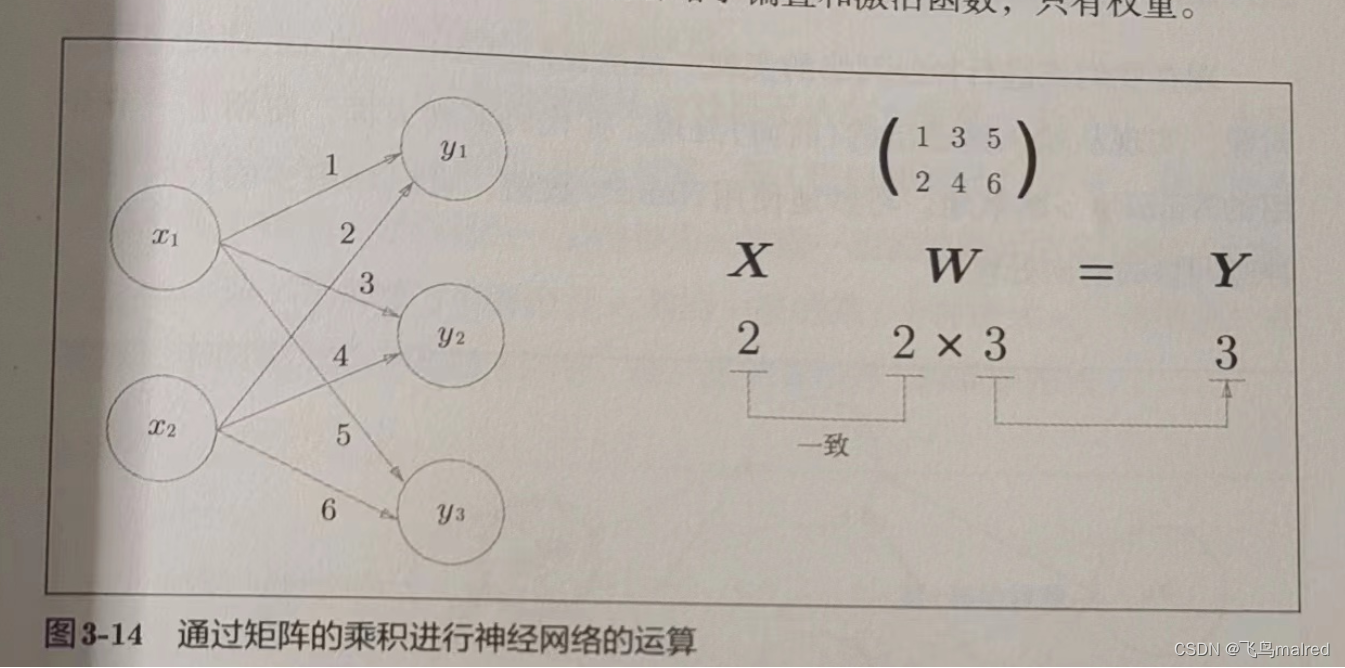
X = np.array([1, 2])
# (2,)
print(X.shape)
W = np.array([[1, 3, 5], [2, 4, 6]])
# [[1 3 5]
# [2 4 6]]
print(W)
# (2, 3)
print(W.shape)
# (1,2) * (2,3) -> (1,3)
Y = np.dot(X, W)
# [ 5 11 17]
print(Y)
使用 np.dot 可以一次运算出结果,这种技巧很重要。
3.4 三层神经网络的实现
我们实现从输入到输出的(前向)处理。
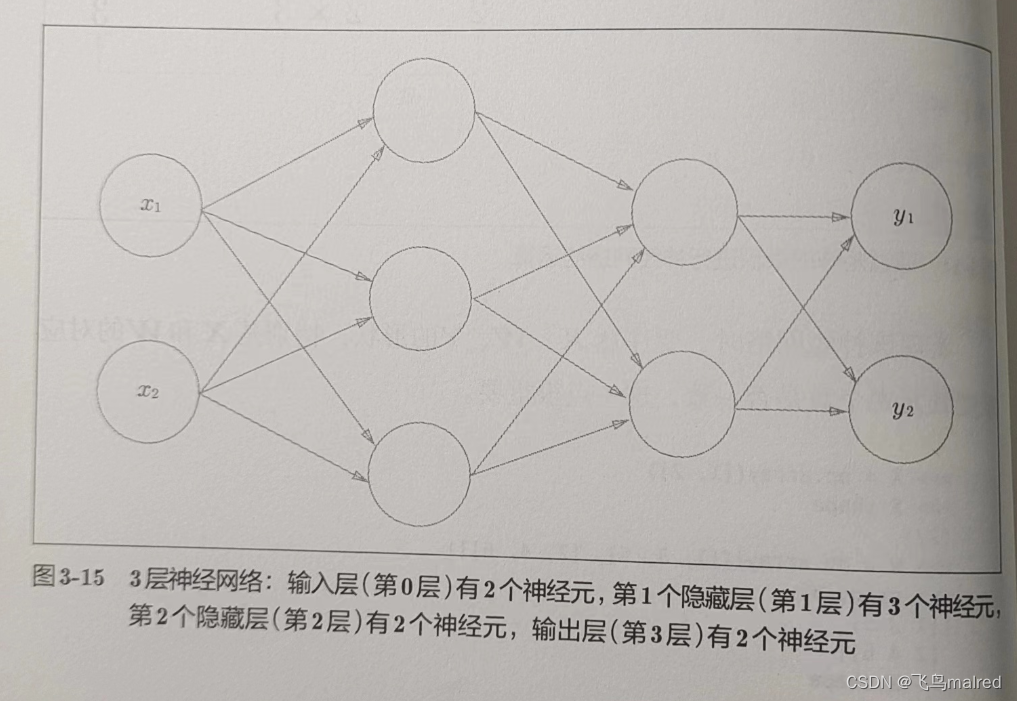
3.4.1 符号确认
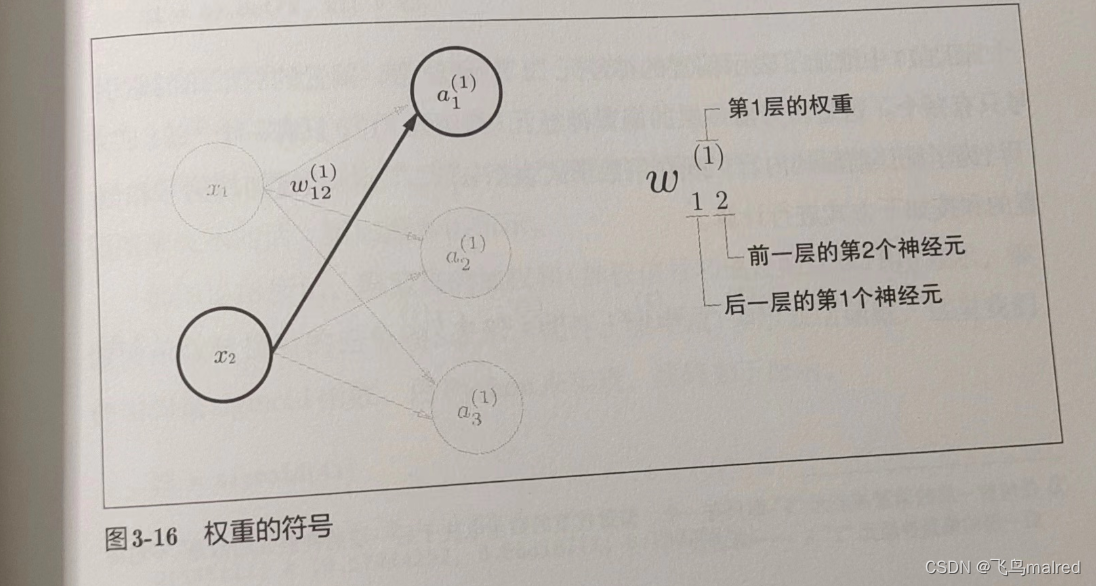
我们引入 w12^(1)和 a1^(1)等符号。
在下图中,权重和隐藏层的神经元的右上角有一个"(1)"
,它表示权重和神经元的层号(即第一层的权重、第一层的神经元)。此外,权重的右下角有两个数字,它们是后一层的神经元和前一层的神经元的索引号。比如
w12^(1)表示前一层的第 2 个神经元 x2 到后一层的第 1 个神经元 a1^(1)的权重。权重右下角按照“后一层的索引号、前一层的索引号”的顺序排列。
3.4.2 各层间信号传递的实现
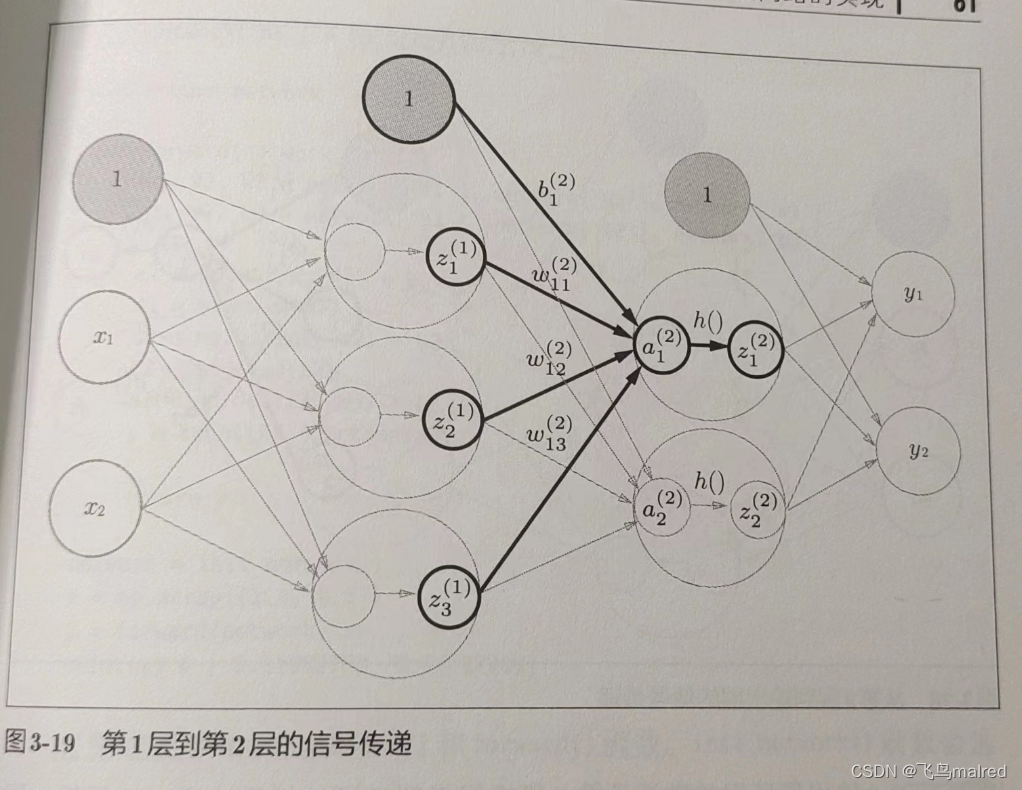
看一下从输入层到第 1 层的第 1 个神经元的信号传递过程。
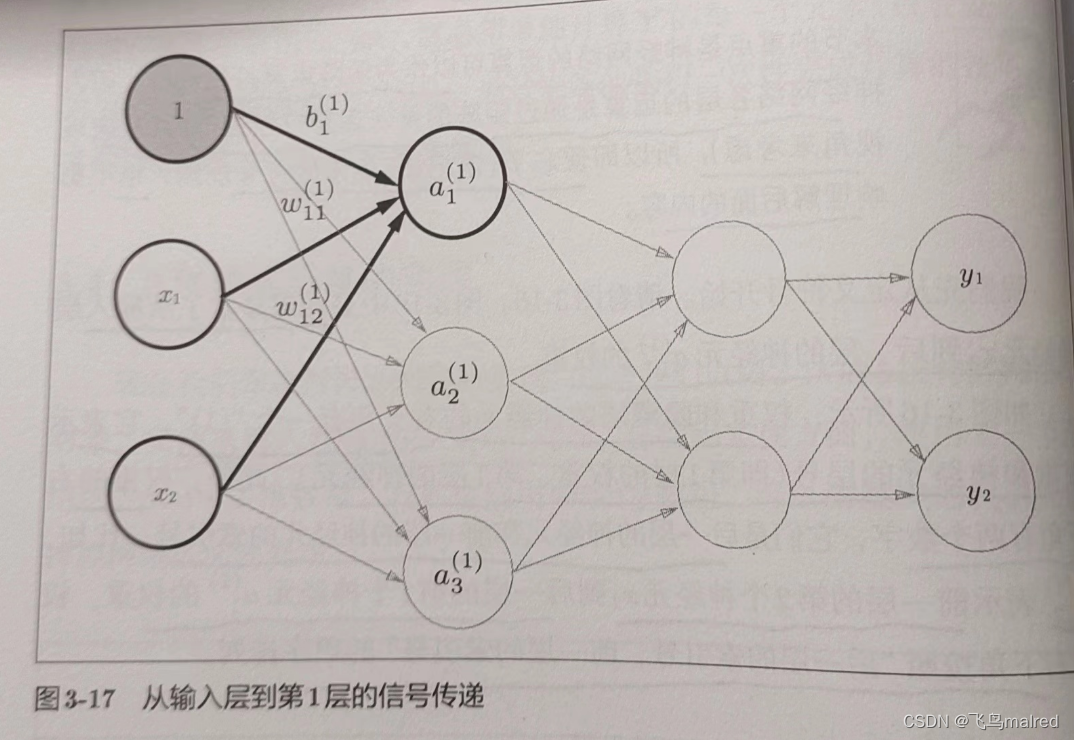
图中新增了表示偏置的神经元"1"。它的右下角的索引号只有一个,因为前一层的偏置神经元(神经元‘1’)只有一个。
- 任何前一层的偏置神经元‘1’都只有一个。偏置权重的数量取决于后一层的神经元的数量(不包括后一层的偏置神经元‘1’)————译者注
用数学式表示 a1^(1)。通过加权信号和偏置的和按如下方式进行计算
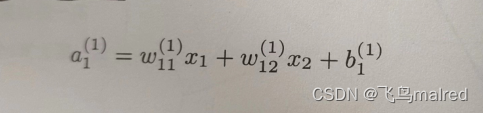
用矩阵的乘法运算,可以间第一层的加权和表示成下面的式
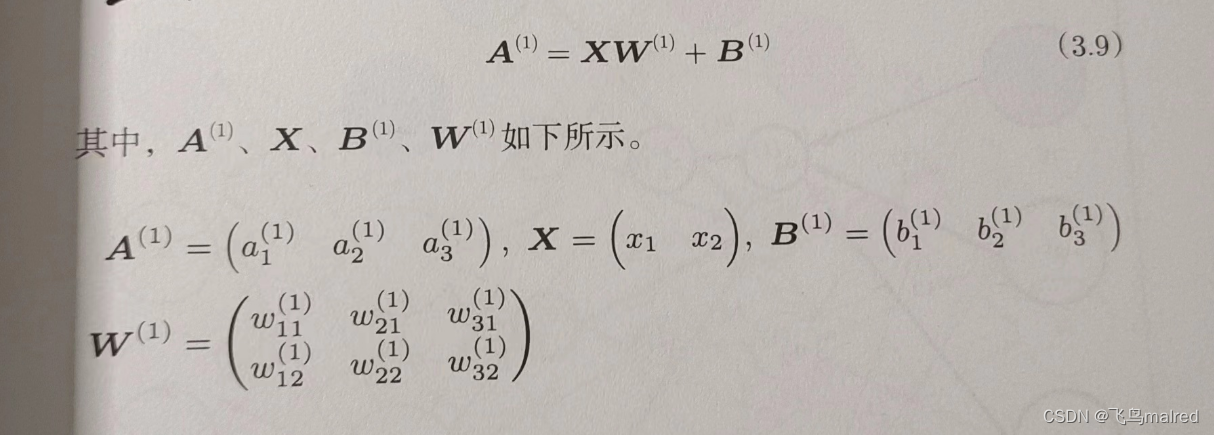
X = np.array([1.0, 0.5])
W1 = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
B1 = np.array([0.1, 0.2, 0.3])
print(W1.shape) # (2, 3)
print(X.shape) # (2,)
print(B1.shape) # (3,)
A1 = np.dot(X, W1) + B1
接下来,隐藏层的加权和(加权信号和偏置的总和)用 a 表示,被激活函数转换后的信号用 z 表示。此外,图中 h()表示激活函数,这里使用的是
sigmoid 行数。
Z1 = sigmoid(A1)
print(A1) # [0.3 0.7 1.1]
print(Z1) # [0.57444252 0.66818777 0.75026011]
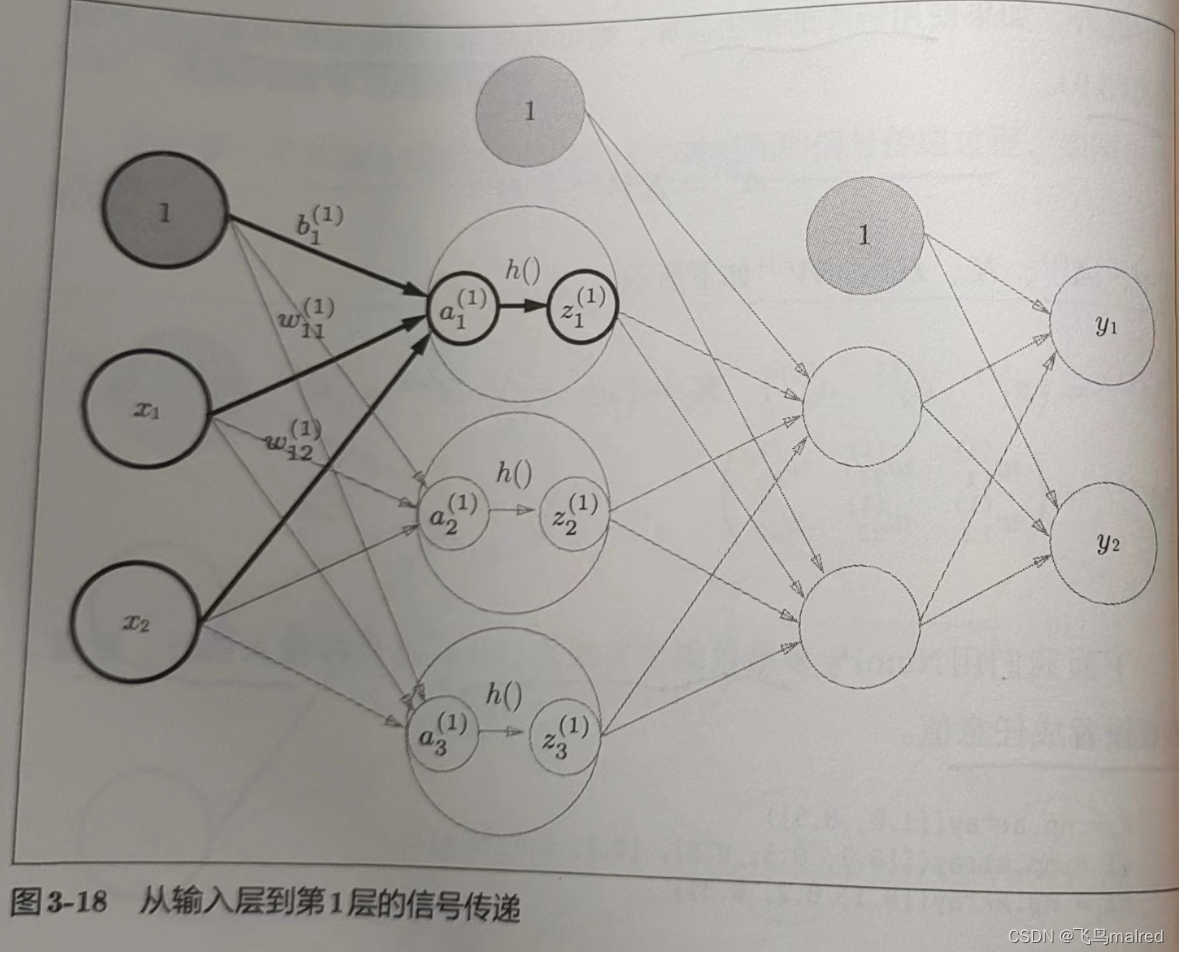
下面来实现第 1 层到第 2 层的信号传递
W2 = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
B2 = np.array([0.1, 0.2])
print(Z1.shape) # (3,)
print(W2.shape) # (3, 2)
print(B2.shape) # (2,)
A2 = np.dot(Z1, W2) + B2
Z2 = sigmoid(A2)
最好是第 2 层到输出层的信号传递。输出层的实现也和之前的实现基本相同。不过,最后的激活函数和之前的隐藏层有所不同
def identity_function(x):
return x
W3 = np.array([[0.1, 0.3], [0.2, 0.4]])
B3 = np.array([0.1, 0.2])
A3 = np.dot(Z2, W3) + B3
Y = identity_function(A3) # 或 Y = A3
这里定义了 identity_function(也叫恒等函数),会将输入按原样输出,其实没必要定义这个,这里是为了和之前的流程保持统一。输出层的激活函数用
σ()表示(σ 读作 sigma),不同于隐藏层的激活函数 h()
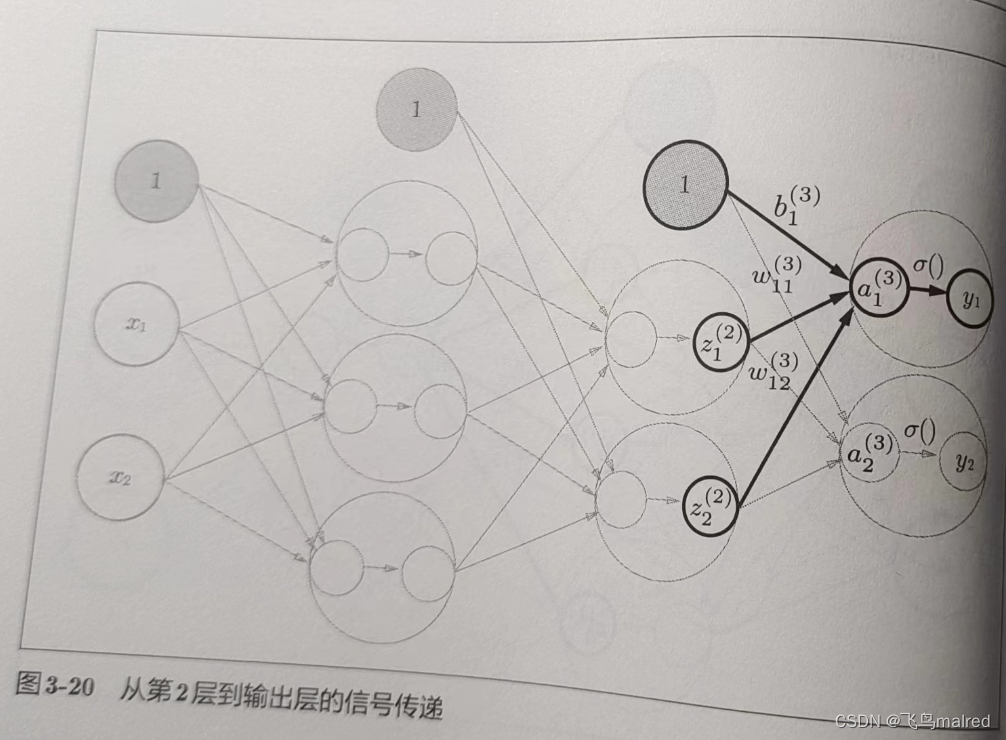
- 输出层所用的激活函数要根据求解问题的性质决定。一般地,回归问题可以使用恒等函数,二元分类问题可以使用 sigmoid
函数,多元分类问题可以使用 softmax 函数。
3.4.3 代码实现小结
def init_network():
network = {}
network['W1'] = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
network['b1'] = np.array([0.1, 0.2, 0.3])
network['W2'] = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
network['b2'] = np.array([0.1, 0.2])
network['W3'] = np.array([[0.1, 0.3], [0.2, 0.4]])
network['b3'] = np.array([0.1, 0.2])
return network
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = identity_function(a3)
return y
network = init_network()
x = np.array([1.0, 0.5])
y = forward(network, x)
print(y) # [0.31682708 0.69627909]
3.5 输出层的设计
神经网络可以用在分类问题和回归问题上,根据情况改变输出层的激活函数。一般地,回归问题用恒等函数,分类问题用 softmax 函数。
- 机器学习的问题大致可以分为分类问题和回归问题。分类问题是数据属于哪一个类别的问题。回归问题是根据某个输入预测一个(连续的)数值的问题
3.5.1 恒等函数和 softmax 函数
恒等函数将输入按原样输出,对于输入的信息,不加任何改动地直接输出。

exp(x)表示 e^x 的指数函数(e 是纳皮尔常数 2.7182···),假设输出层共有 n 个神经元,计算第 k 个神经元的输出 yk。softmax
函数的分字是输入信号 ak 的指数函数,分母是所有输入信号的指数函数的和。
用图表示 softmax 函数的话,可以看出,softmax 函数的输出通过箭头与所有输入信号相连。输出层的各个神经元都受到所有输入信号的影响。
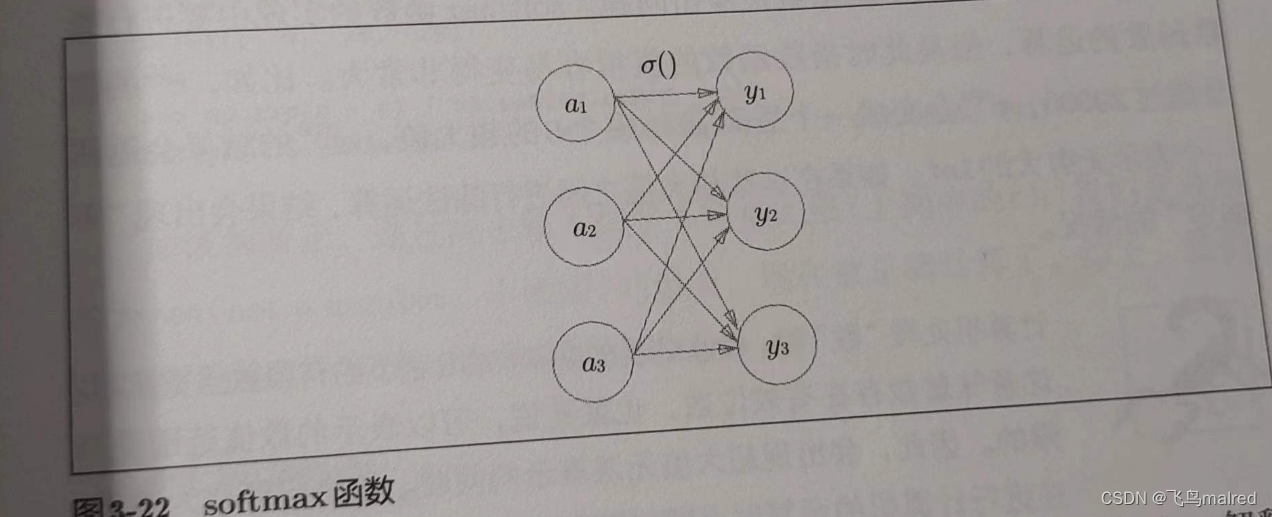
# softmax
a = np.array([0.3, 2.9, 4.0])
exp_a = np.exp(a) # 指数函数
# [ 1.34985881 18.17414537 54.59815003]
print(exp_a)
sum_exp_a = np.sum(exp_a) # 指数函数的和
# 74.1221542101633
print(sum_exp_a)
y = exp_a / sum_exp_a
# [0.01821127 0.24519181 0.73659691]
print(y)
def softmax(a):
exp_a = np.exp(a)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
3.5.2 实现 softmax 函数时的注意事项
上面的实现虽然可以表示 softmax,但是会导致溢出问题。因为 softmax 涉及指数运算,而指数运算的值通常很大,比如 e^10 的值超过
20000,e^100 后面带 40 多个 0,e^1000 的结果返回一个表示无穷大的 inf。
- 计算机在处理‘数’时,数值必须在 4~8 字节的有限数据宽度内。这意味着数存在有效位数,可以表示的数值范围是有限的。因此,会出现超大值无法表示的问题(溢出问题)
可以改进 softmax 函数
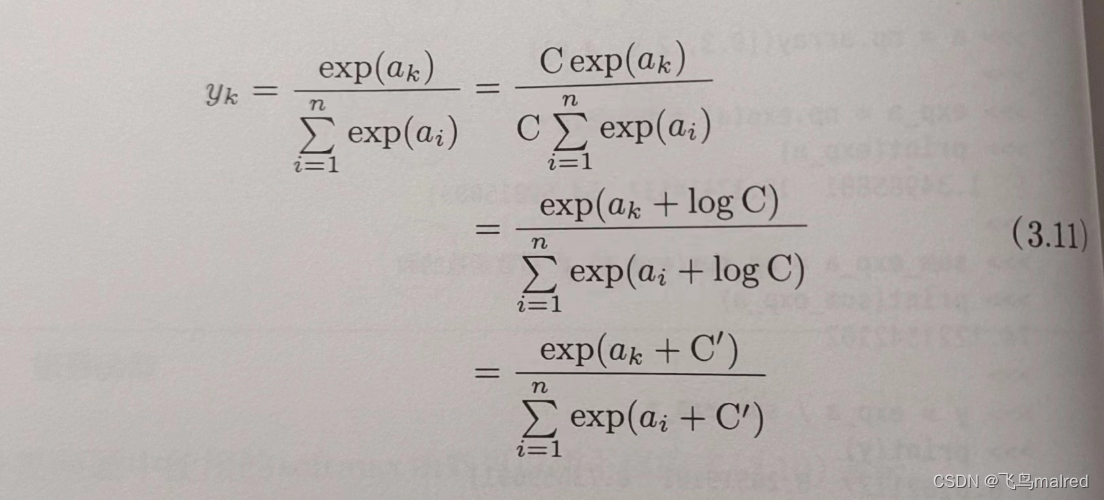
在 softmax 函数的分子分母上都乘 C(任意常数),然后把 C 移动到指数函数 exp 中,记为 logC,最后,把 logC 替换为 C’
这里的 C’可以是任何值,但是为了防止溢出,一般会使用输入信号中的最大值。
a = np.array([1010, 1000, 990])
# [nan nan nan]
print(np.exp(a) / np.sum(np.exp(a))) # softmax函数的计算
c = np.max(a)
# [ 0 -10 -20]
print(a - c)
# [9.99954600e-01 4.53978686e-05 2.06106005e-09]
print((np.exp(a - c) / np.sum(np.exp(a - c))))
def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
3.5.3 softmax 函数的特征
a = np.array([0.3, 2.9, 4.0])
y = softmax(a)
# [0.01821127 0.24519181 0.73659691]
print(y)
# 1.0
print(np.sum(y))
softmax 的输出是 0~1 之间的实数。而且输出值的总和为 1。这是一个重要特性,因为有了这个性质,我们才把 softmax 函数的输出解释为‘概率’
需要注意的是,即使用了 softmax 函数,各个元素间的大小关系也不会改变。这是因为指数函数(y=exp(x))是单调递增函数。
一般而言,神经网络只把输出值最大的神经元所对应的类别作为识别结果。并且,即使使用 softmax
函数,输出值最大的神经元的位置也不会变。因此,神经网络进行分类时,输出层的 softmax 函数可以省略。
- 求解机器学习问题的步骤分为‘学习’和‘推理’两个阶段。推理阶段一般会忽略输出层的 softmax 函数。在输出层使用 softmax
函数是因为它和神经网络的学习有关
3.5.4 输出层的神经元数量
输出层的神经元数量需要根据待解决的问题来决定。对于分类问题,输出层的神经元数量一般设定为类别的数量。
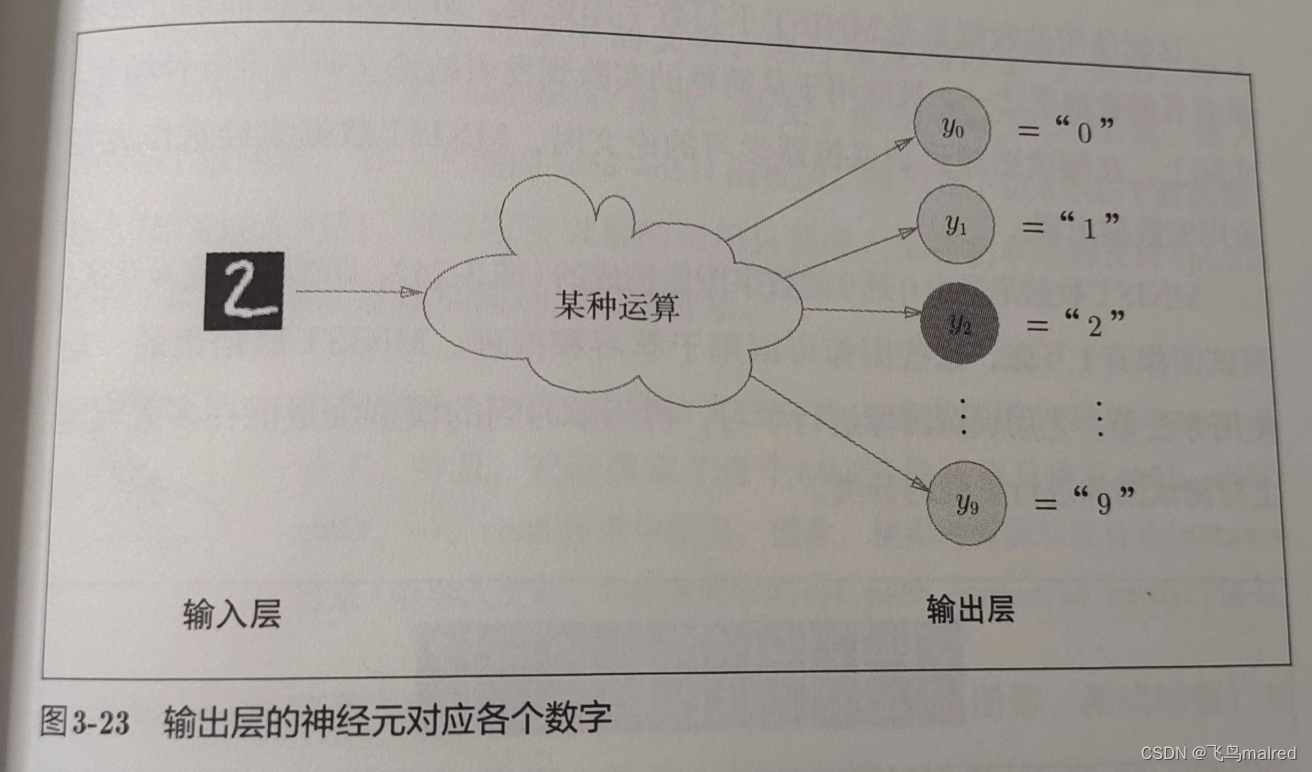
3.6 手写数字识别
我们假设学习已经结束,使用学习到的参数,先实现神经网络的‘推理处理’。这个推理处理也称为神经网络的前向传播(forward
propagation)
- 使用神经网络解决问题时,也需要首先使用训练数据(学习数据)进行权重参数的学习;进行推理时,使用刚才学习到的参数,对输入的数据进行分类
3.6.1 MNIST 数据集
MNIST 数据集是由 0 到 9 的数字图像构成的。训练图像有 6 万多张,测试图像有 1
万多张,这些图像可用于学习和推理。一般使用方法是,先用训练图像进行学习,再用学习到的模型度量能在多大程度上对测试图像进行正确的分类
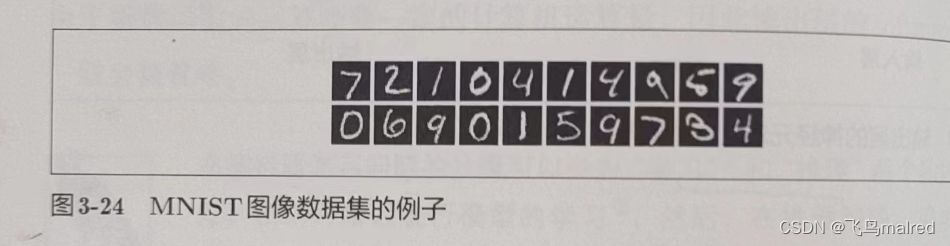
MNIST 的图像数据是 28x28 像素的灰度图像(1 通道),各个通道的取值在 0 到 255 之间。每个图像数据都相应地标有‘7’、‘2’、‘1’等标签。
本书提供了脚本 mnist.py 来下载 MNIST 数据集并进行了转化为 numpy 数组等处理
# coding: utf-8
try:
import urllib.request
except ImportError:
raise ImportError('You should use Python 3.x')
import os.path
import gzip
import pickle
import os
import numpy as np
url_base = 'http://yann.lecun.com/exdb/mnist/'
key_file = {
'train_img':'train-images-idx3-ubyte.gz',
'train_label':'train-labels-idx1-ubyte.gz',
'test_img':'t10k-images-idx3-ubyte.gz',
'test_label':'t10k-labels-idx1-ubyte.gz'
}
dataset_dir = os.path.dirname(os.path.abspath(__file__))
save_file = dataset_dir + "/mnist.pkl"
train_num = 60000
test_num = 10000
img_dim = (1, 28, 28)
img_size = 784
def _download(file_name):
file_path = dataset_dir + "/" + file_name
if os.path.exists(file_path):
return
print("Downloading " + file_name + " ... ")
urllib.request.urlretrieve(url_base + file_name, file_path)
print("Done")
def download_mnist():
for v in key_file.values():
_download(v)
def _load_label(file_name):
file_path = dataset_dir + "/" + file_name
print("Converting " + file_name + " to NumPy Array ...")
with gzip.open(file_path, 'rb') as f:
labels = np.frombuffer(f.read(), np.uint8, offset=8)
print("Done")
return labels
def _load_img(file_name):
file_path = dataset_dir + "/" + file_name
print("Converting " + file_name + " to NumPy Array ...")
with gzip.open(file_path, 'rb') as f:
data = np.frombuffer(f.read(), np.uint8, offset=16)
data = data.reshape(-1, img_size)
print("Done")
return data
def _convert_numpy():
dataset = {}
dataset['train_img'] = _load_img(key_file['train_img'])
dataset['train_label'] = _load_label(key_file['train_label'])
dataset['test_img'] = _load_img(key_file['test_img'])
dataset['test_label'] = _load_label(key_file['test_label'])
return dataset
def init_mnist():
download_mnist()
dataset = _convert_numpy()
print("Creating pickle file ...")
with open(save_file, 'wb') as f:
pickle.dump(dataset, f, -1)
print("Done!")
def _change_one_hot_label(X):
T = np.zeros((X.size, 10))
for idx, row in enumerate(T):
row[X[idx]] = 1
return T
def load_mnist(normalize=True, flatten=True, one_hot_label=False):
"""读入MNIST数据集
Parameters
----------
normalize : 将图像的像素值正规化为0.0~1.0
one_hot_label :
one_hot_label为True的情况下,标签作为one-hot数组返回
one-hot数组是指[0,0,1,0,0,0,0,0,0,0]这样的数组
flatten : 是否将图像展开为一维数组
Returns
-------
(训练图像, 训练标签), (测试图像, 测试标签)
"""
if not os.path.exists(save_file):
init_mnist()
with open(save_file, 'rb') as f:
dataset = pickle.load(f)
if normalize:
for key in ('train_img', 'test_img'):
dataset[key] = dataset[key].astype(np.float32)
dataset[key] /= 255.0
if one_hot_label:
dataset['train_label'] = _change_one_hot_label(dataset['train_label'])
dataset['test_label'] = _change_one_hot_label(dataset['test_label'])
if not flatten:
for key in ('train_img', 'test_img'):
dataset[key] = dataset[key].reshape(-1, 1, 28, 28)
return (dataset['train_img'], dataset['train_label']), (dataset['test_img'], dataset['test_label'])
if __name__ == '__main__':
init_mnist()
使用方式
import sys, os
sys.path.append(os.pardir) # 为了导入父目录中的文件而进行的设定
from dataset.mnist import load_mnist
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)
# 输出各个数据的形状
print(x_train.shape) # (60000, 784)
print(t_train.shape) # (60000,)
print(x_test.shape) # (10000, 784)
print(t_test.shape) # (10000,)
load_mnist 函数有三个参数,比如 load_mnist(normalize=True, flatten=True, one_hot_label=False)中,
- 第一个参数 normalize 设置是否将输入图像正规化(正则化)为 0.0~1.0 的值。如果为 False,则输入图像的像素会保持原来的 0~255。
- 第 2 个参数 flatten 设置是否展开输入图像(变成 1 维数组)。如果为 False,则输入图像为 1x28x28 的三位数组,如果为
True,则输入图像会保存为由 784 个元素构成的一维数组。 - 第三个参数设置是否将标签保存为 onehot 表示(one-hot representation)。one-hot 表示是仅正确解标签为 1,其余为 0
的数组,如[0,0,1,0,0,0,0,0,0,0]。当 one_hot_label 为 False 时,只是像 7、2 这样简单地保存正确解标签;当为 True 时,则保存为
onehot 表示
python 有 pickle 这个便利的功能。可以将程序运行中的对象保存为文件。如果加载保存过的 pickle
文件,可以立刻复原之前程序运行中的对象。load_mnist 就是利用了这个功能,在第二次读取时快速读取保存在本地的数据集 pkl
我们用 PIL(Python Image Library)来显示图像
import sys, os
sys.path.append(os.pardir) # 为了导入父目录中的文件而进行的设定
import numpy as np
from dataset.mnist import load_mnist
from PIL import Image
def img_show(img):
pil_img = Image.fromarray(np.uint8(img))
pil_img.show()
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)
img = x_train[0]
label = t_train[0]
print(label) # 5
print(img.shape) # (784,)
img = img.reshape(28, 28) # 把图像的形状变成原来的尺寸
print(img.shape) # (28, 28)
img_show(img)
这里使用了 flatten=True,所有读入的是一维数组,在显示图像时需要(通过 reshape)转为原本的尺寸(28x28),而图像被保存为 numpy
数组,所以需要通过 Image.fromarray()来转换为图像

3.6.2 神经网络的推理处理
接下来实现推理处理。首先,输入层有 784 个神经元(图像大小 28x28=784),输出层有 10 个神经元(0~9,是 10
分类)。此外,这个神经网络有两个隐藏层,第一个隐藏层有 50 个神经元,第二个隐藏层有 100 个神经元。(50 和 100 可以设置为任意值)
先定义函数
def get_data():
(x_train, t_train), (x_test, t_test) = \
load_mnist(flatten=True, normalize=True, one_hot_label=False)
return x_test, t_test
def init_network():
with open('sample_weight.pkl', 'rb') as f:
network = pickle.load(f)
return network
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = softmax(a3)
return y
init_network()会读入保存在 pickle 文件 sample_weight.pkl 中的学习到的权重参数。这个文件以字典变量的形式保存了权重和偏置参数。这里假设学习已经完成,所以直接加载
pkl 文件
现在我们用这 3 个函数实现神经网络的推理处理。然后,评价它的识别精度(accuracy),即能在多大程度上正确分类
x, t = get_data()
network = init_network()
accuracy_cnt = 0
for i in range(len(x)):
y = predict(network, x[i])
p = np.argmax(y) # 获取概率最高的元素的索引
if p == t[i]:
accuracy_cnt += 1
print(f'Accuracy: {str(float(accuracy_cnt) / len(x))}')
我们设置 normalize 为 True 后,函数内部会进行转换,将图像的各个像素除以 255,使得数据的值在 0.0~1.0
之间。先这样把数据限定到某个范围内的处理称为正规化(normalization)。此外,对神经网络的输入数据进行某种既定的转换称为
预处理(pre-processing)
- 预处理很实用。实际上,很多预处理都会考虑到数据的整体分布。比如,利用数据整体的均值或标准差,移动数据,使数据整体以 0
为中心分布,或者进行正规化,把数据延展控制在一定范围内。除此之外,还有将数据整体的分布形状均匀化的方法,即数据白化
(whitening)等。
3.6.3 批处理
现在我们来关注输入数据和权重参数的‘形状’
x, _ = get_data()
network = init_network()
W1, W2, W3 = network['W1'], network['W2'], network['W3']
# (10000, 784)
print(f'x shape: {x.shape}')
# (784,)
print(f'x[0] shape: {x[0].shape}')
# (784, 50)
print(f'w1 shape: {W1.shape}')
# (50, 100)
print(f'w2 shape: {W2.shape}')
# (100, 10)
print(f'w3 shape: {W3.shape}')
我们确认了这些多维数组的对应维度的元素个数是一致的(省略了偏置),最终结果也确实是元素个数为 10 的一维数组
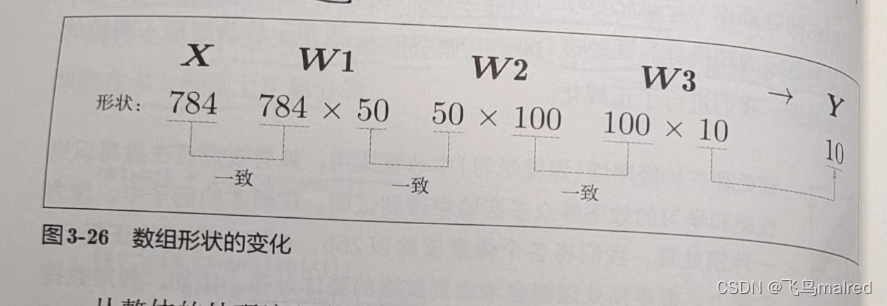
但是当我们批量进行处理,假设一批有 100 个,则输入的 shape 为(100, 784),输出形状则为(100,10),也就是说,输入的 100
张图像的结果被一次性输出了。比如 x[0]和 y[0]中保存了第 0 张图像及其推理结果
这种打包式的输入数据称为‘批’(batch)
批处理对计算机的计算大有益处,可以大幅缩短每张图像的处理时间。因为大多数处理数值计算的库都进行了能够高效处理大型数组运算的最优化。并且,神经网络的运算中,当数据传送成为瓶颈时,批处理可以减轻数据总线的负荷(严格的讲,相对于数据读入,可以将更多的时间用在计算上)也就是说,批处理一次性计算大型数组比分开逐步计算各个小型数组速度更快
x, t = get_data()
network = init_network()
batch_size = 100 # 批数量
accuracy_cnt = 0
# 0~len(x) 每次 i+=batch_size
for i in range(0, len(x), batch_size):
x_batch = x[i:i + batch_size]
y_batch = predict(network, x_batch)
# 在每行找最大值所在列
p = np.argmax(y_batch, axis=1)
accuracy_cnt += np.sum(p == t[i:i + batch_size])
# Accuracy: 0.9352
print(f'Accuracy: {str(float(accuracy_cnt) / len(x))}')
# range的例子
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(list(range(0, 10)))
# [0, 3, 6, 9]
print(list(range(0, 10, 3)))
argmax 的例子
x = np.array([[0.1, 0.8, 0.1], [0.3, 0.1, 0.6], [0.2, 0.5, 0.3], [0.8, 0.1, 0.1]])
y = np.argmax(x, axis=1)
# [1 2 1 0]
print(y)
比较结果
# 比较结果
y = np.array([1, 2, 1, 0])
t = np.array([1, 2, 0, 0])
# [ True True False True]
print(y == t)
# y和t相同元素的个数
# 3
print(np.sum(y == t))
3.7 小结
本节介绍了神经网络的前向传播。神经网络和感知机在信号的按层传递上是相同的,但是在向下一个神经元发送信号的时候,改变信号的激活函数有很大差异,神经网络使用的是平滑变化的,而感知机是急剧变化的阶跃函数。
- 神经网络中的激活函数使用平滑变化的 sigmoid 函数或 ReLU 函数
- 巧妙利用 Numpy 多维数组,可以高效实现神经网络
- 机器学习的问题大体上可以分为回归问题和分类问题
- 关于输出层的激活函数,回归问题中一般用恒等函数,分类问题中一般用 softmax 函数
- 分类问题中,输出层的神经元的数量设置为要分类的类别数
- 输入数据的集合称为批。通过以批为单位进行推理处理,能够实现高速的运算
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【深度视觉】第三章:卷积网络诞生前:卷积、边缘、纹理、图像分类等
- DC电源模块的设计与制造技术创新
- springboot(ssm儿童慈善管理系统 儿童捐赠平台 Java系统
- 进程管理:处理机调度例题
- 黑客(网络安全)技术自学——高效学习
- 电脑上如何安装多个python (基础教学,成为万能安装小能手)
- 阿里推荐 LongAdder ,不推荐 AtomicLong !
- 物联网介绍
- Python实现商品数据管理系统
- Java基础知识整理,驼峰规则、流程控制、自增自减