论文笔记:基于CLIP引导学习的多模式假新闻检测
背景
??对于我们这一代人来说,在线社交网络在很大程度上取代了以报纸和杂志为代表的传统信息交流方式。人们喜欢在社交媒体上寻找朋友或分享观点。然而,在线网络也促进了假新闻的广泛和快速传播。
??文中提出了一个FND-CLIP框架,即基于对比语言-图像预训练(CLIP)的多模态假新闻检测网络。其中的多模态特征由两个模态的相似性加权的CLIP特征串联得到。引入了一个模态关注模块来自适应地重新加权和聚合特征。
??图一是使用模型的几个例子,每条新闻的三个注意力得分分别是文字得分、图像得分和融合得分。

模型
??文中提出,进行假新闻检测的一般流程为:
y
^
=
F
c
l
s
(
F
M
i
x
(
F
T
x
t
(
x
T
x
t
)
,
F
i
m
g
(
x
I
m
g
)
)
)
\hat{y}=F_{cls}(F_{Mix}(F_{Txt}(x_{Txt}),F_{img}(x_{Img})))
y^?=Fcls?(FMix?(FTxt?(xTxt?),Fimg?(xImg?)))??其中,
F
c
l
s
F_{cls}
Fcls?是分类头,
F
M
i
x
F_{Mix}
FMix?、
F
I
m
g
F_{Img}
FImg?、
F
T
x
t
F_{Txt}
FTxt?分别是融合模型、文本模型和图像模型,
y
^
\hat{y}
y^?是最终预测标签。
x
T
x
t
x_{Txt}
xTxt?、
x
I
m
g
x_{Img}
xImg?是预训练模型提取出的特征。
??那么如何保证两种模式提供的特征在后期都能被利用,否则语义空间的空白会使融合的特征无法准确地表示图像和文本之间的相关性。本文采用了一种简单而有效的方法,选择CLIP模型来生成跨模态特征和度量跨模态相似性,在特征提取和对齐之后,本文使用一个轻量级的网络来实现
F
c
l
s
F_{cls}
Fcls?,该网络可以预测出整数。
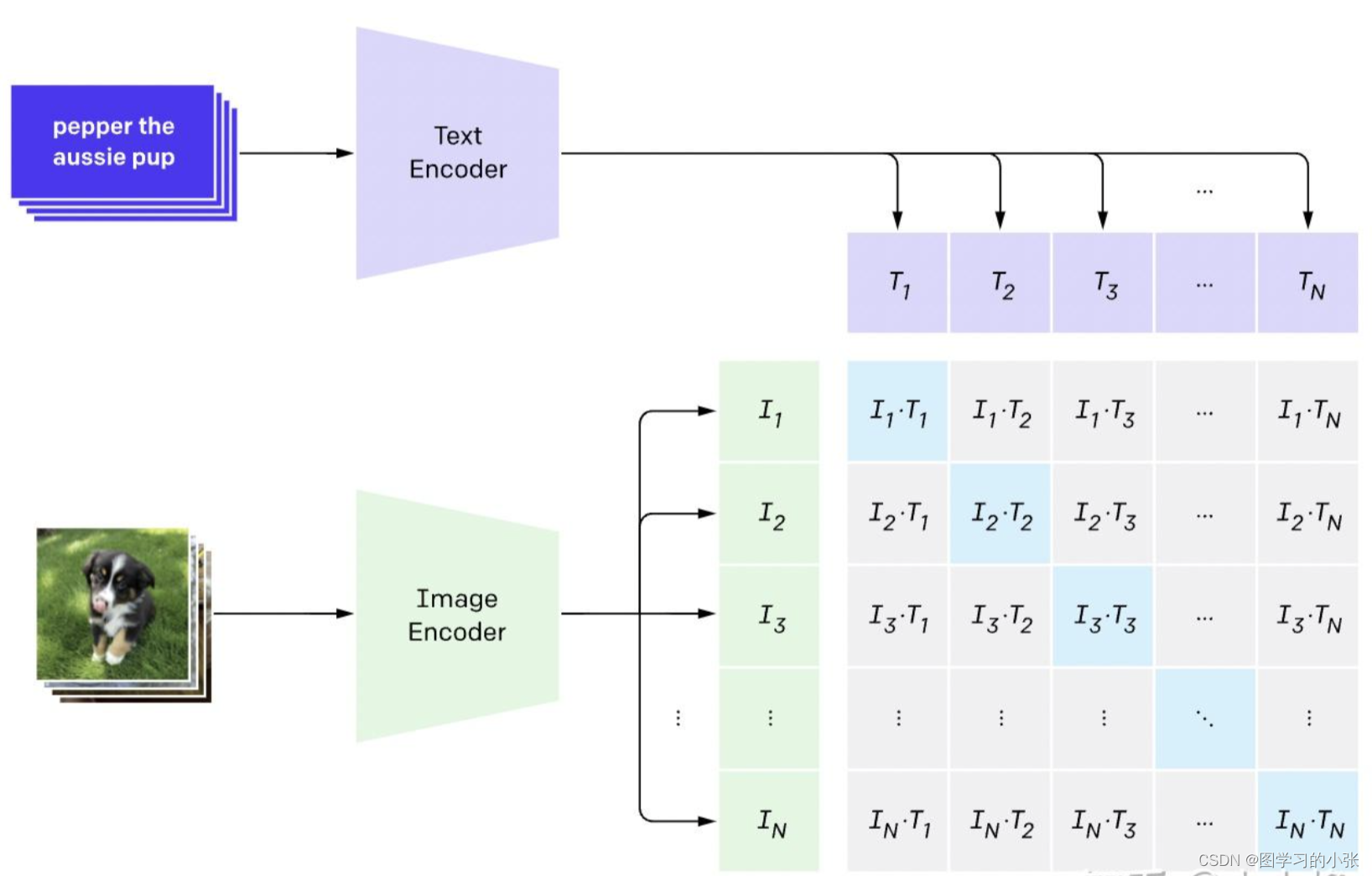
??CLIP(Contrastive Language-Image Pre-training)一种基于对比文本-图像对的预训练模型。他分别有一个图像和一个文本编码器,输出的结果从一开始就是对齐的。模型结构:
??本文的模型结构:
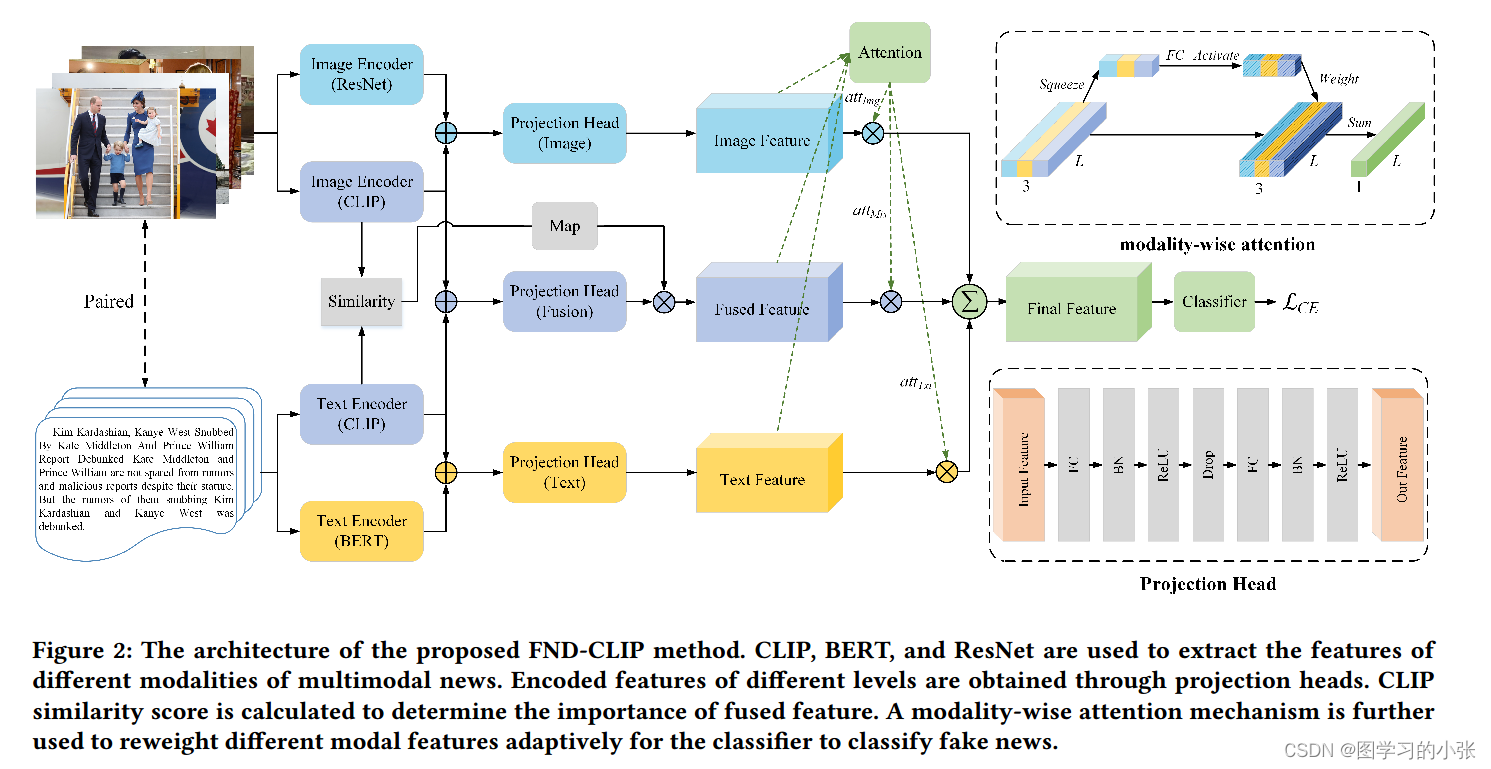 ??那我们来看看本文的模型,其实尊都非常简单,就是BERT和ResNet提取的特征和CLIP两个编码器提取的特征分别拼起来作为单模态特征,CLIP两个编码器输出的特征作为融合模态的特征,由于CLIP两个编码器的结果本身就是对齐的,在计算一个余弦相似度调节融合特征的强度。现在我们就获得了两个单模态和一个融合模态,使用了一个改于SeNet的注意力网络对它们融和,然后过分类头就行了。
??那我们来看看本文的模型,其实尊都非常简单,就是BERT和ResNet提取的特征和CLIP两个编码器提取的特征分别拼起来作为单模态特征,CLIP两个编码器输出的特征作为融合模态的特征,由于CLIP两个编码器的结果本身就是对齐的,在计算一个余弦相似度调节融合特征的强度。现在我们就获得了两个单模态和一个融合模态,使用了一个改于SeNet的注意力网络对它们融和,然后过分类头就行了。
??公式推导(懒得写了,放图片看吧):
-
得到两个单模特征:
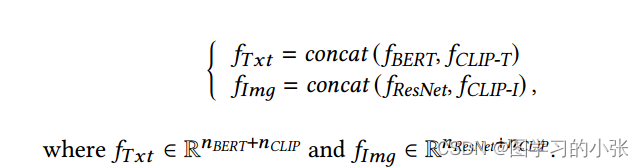
-
得到融合特征:
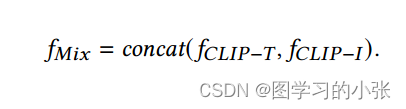
-
计算相似度并加权,得到最终的三个模态:
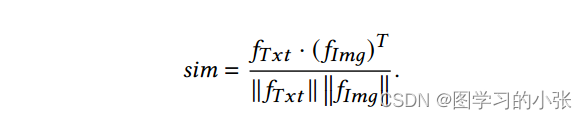
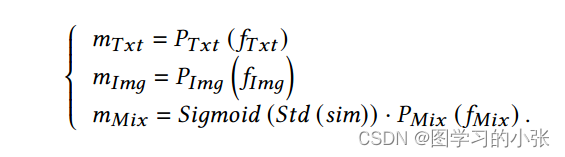
-
根据attention机制的结果得到最终特征:
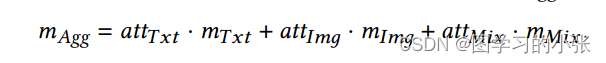
??损失函数用的是交叉熵,可以看这篇:交叉熵损失(Cross Entropy Loss)学习笔记
实验
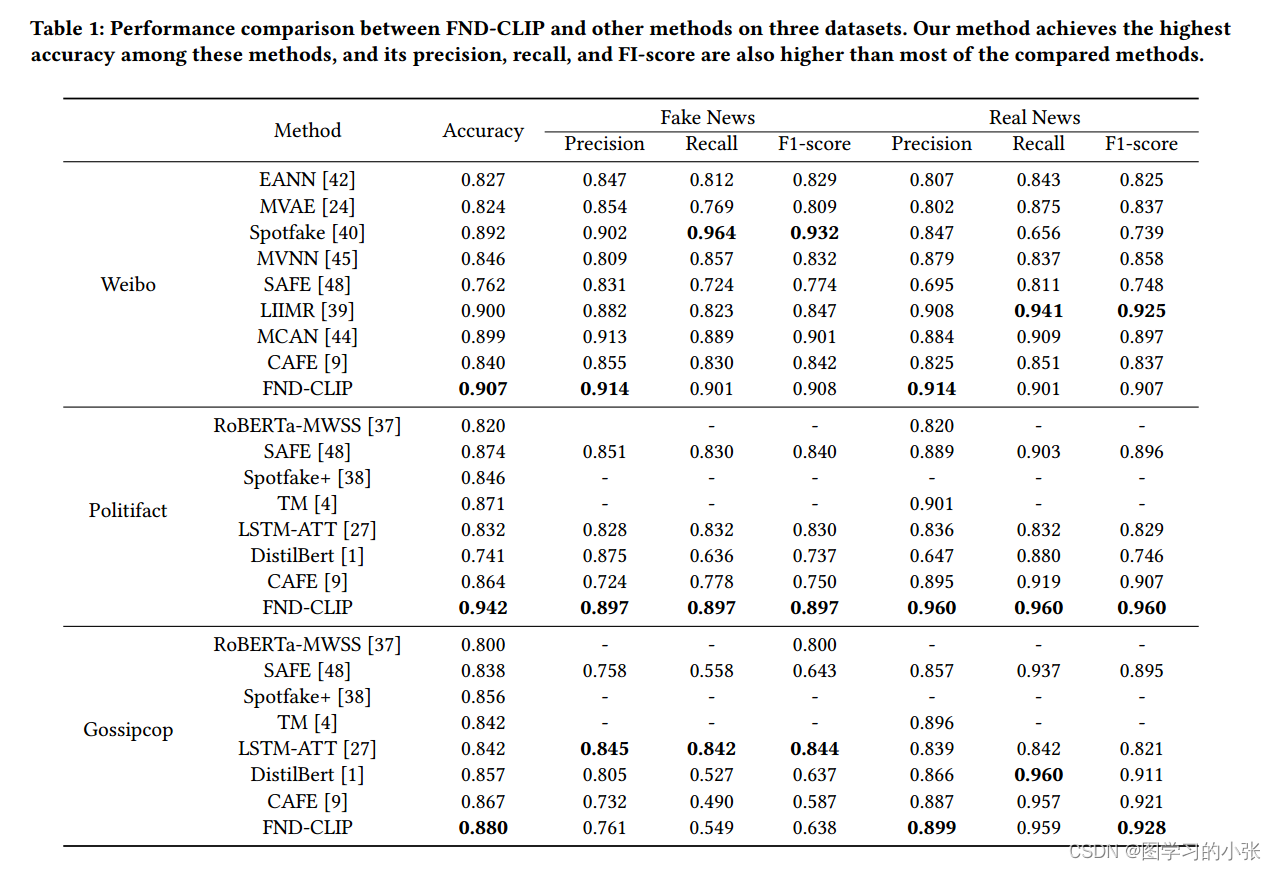
??在微博和Fakenewsnet里面那两个数据集上的实验:
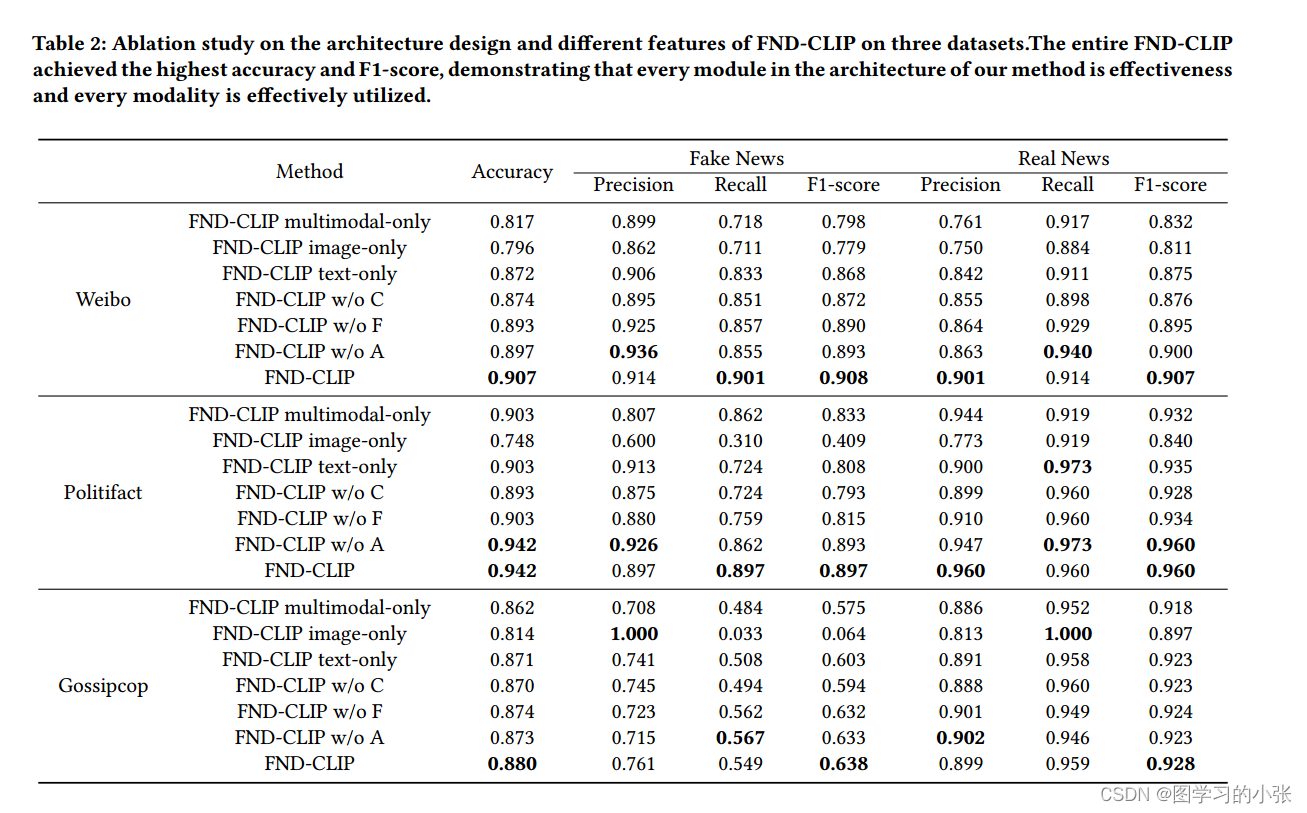
??消融实验:
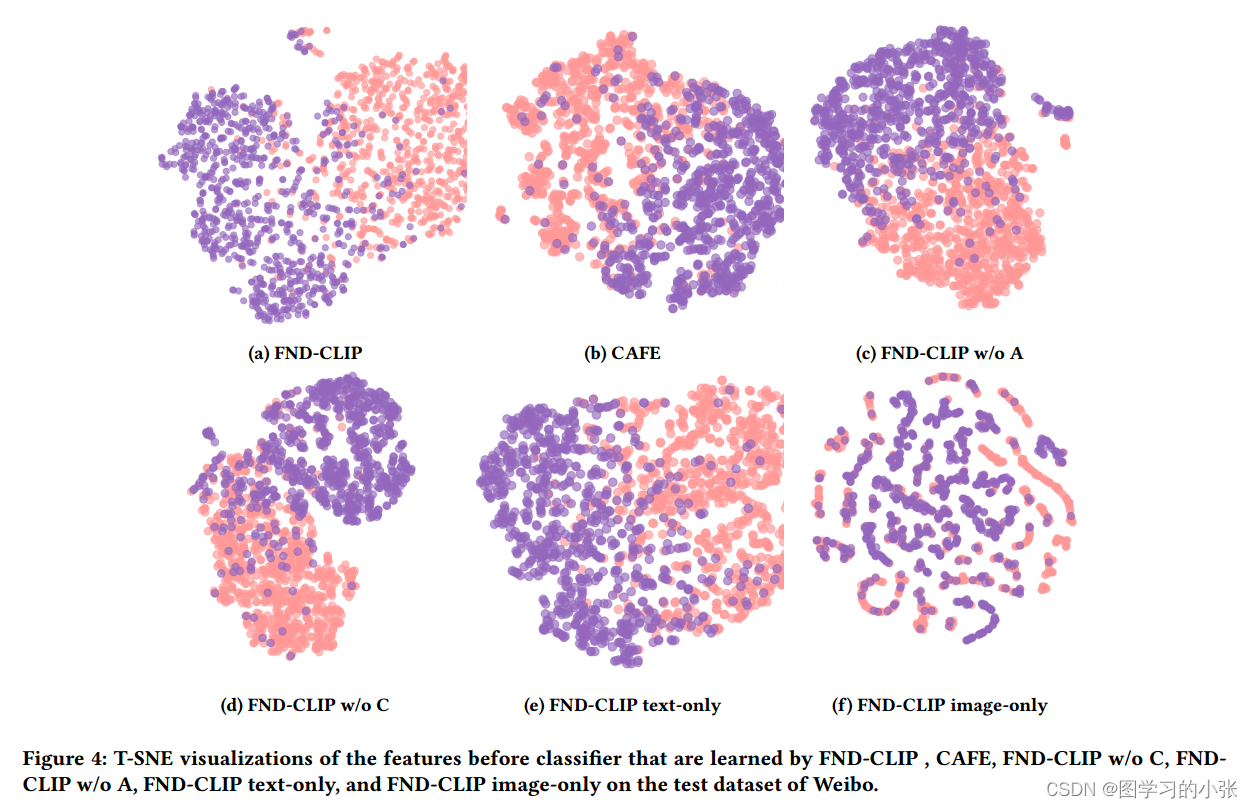
??分类结果的可视化:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于SpringBoot的洗衣店管理系统
- Synchronized 和 ReentrantLock 的实现原理是什么?它们有什么区别?
- uniapp嵌套webview,无法返回上一级?
- go进行http,get或postJson请求
- 线程池的简单介绍及使用
- 【数据结构】单链表的基本操作 (C语言版)
- 井盖不锈钢二维码标识牌
- Ubuntu 22.04 安装MySql
- 工程管理系统功能设计与实践:实现高效、透明的工程管理
- 基于ssm线上学习网站论文