? javascript实用
发布时间:2024年01月22日
? javascript实用
检测是否存在某个值
检测某个字符串之中是否存在某个字符串 indexOf
let ta="ABCDE";let tb=ta.indexOf('A');console.log(tb,'tb');
// 输出-1 'tb'
// 0不存在
let ta="ABCDE";let tb=ta.indexOf('AA');console.log(tb,'tb');
// 输出-1 'tb'
// -1 存在
使用按位非操作符(~)
上面的检测可以写成
if (~ta.indexOf("A")) {
console.log('子字符串存在');
} else {
console.log('子字符串不存在');
}
// 输出 子字符串存在
if (~ta.indexOf("F")) {
console.log('子字符串存在');
} else {
console.log('子字符串不存在');
}
// 输出 子字符串不存在
原理分析~操作符
为什么使用~操作符后,就不用写>-1了呢?我们来看看其背后的隐式转换和~操作符原理
不存在时得到的结果是: ~-1
step1. 转成32位的二进制:11111111111111111111111111111111
注:在二进制中**-1**表示为所有位都是1的二进制数
step2. 按位取反:00000000000000000000000000000000
存在时得到的结果,假设是3
step1. 转成32位的二进制00000000000000000000000000000011
step2. 按位取反11111111111111111111111111111100
step3. 二进制到十进制的转换
取反后得到的是一个新的二进制数,但这个二进制数以1开头,表示它是一个负数。在计算机中,负数通常使用补码形式表示,所以我们需要将这个二进制数转换为它的补码对应的十进制数。
补码的计算过程是:
取反(已经在步骤2里完成了)。
加1。
结果如下:
11111111111111111111111111111100
+ 1
-----------------------------------
11111111111111111111111111111101
得到的新二进制数仍然是负数的补码表示,它对应的十进制数是-4。
简单的通过数学表达式来表示:~N = -N - 1,赔了夫人又折兵
总结梳理:
使用~str.indexOf(xxx)后得到的结果一定是小于等于0的数字
而if括号内的表单式会将数字隐式转换为布尔值
因此只有~-1 ==> 0 ==> false,其它情况都是true
非常有趣的隐式转换
为什么加!后,结果不变
[] == 0 // true
![] == 0 // true
分析:
在[] == 0中,对于复杂类型转化过程是先执行toString再通过Number转成数字,因此结果是Number([].toString())==0
在![] == 0中,![]优先执行将数组转成布尔值再取反返回false,再转成数字,因此结果也是0

为什么"5">15为false,而"5">"15"为true
原因是:两个字符串数字比较的不是数字本身,而是通过charCodeAt获取到的Unicode编码的索引:
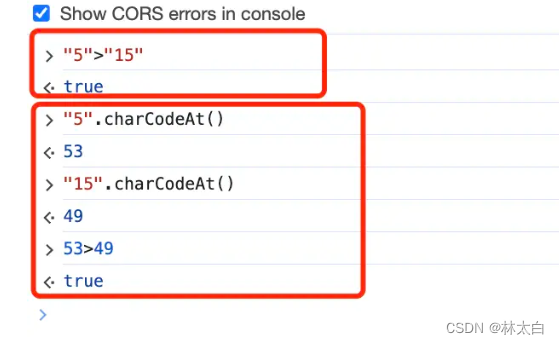
非常容易踩坑的引用类型隐式转换
[] == [] //false(引用地址不一样、无异议)
[] == ![] //true(比较的转化后的数字)
{} == {} //false同上
{} ==!{} //false,哈哈和上面的数组对比结果是相反的
1 掌握操作符和隐式转换的行为有助于我们编写更可靠、更易于维护的代码。
2 实际开发中,应合理的使用隐式转换,在可能引起混淆的地方采用显式类型转换,提高清晰度和稳定性。
3 合理的使用操作符可以帮助我们编写更简洁的代码,还可以提高代码的可读性(如+操作符快捷转换数字、??控制合并操作符对处理数字0非常有用)。
折叠已经注释的代码块
javascript 注释折叠
使用region注释,将代码块收(折叠)起来
#region
在这里插入代码片
#endregion
文章来源:https://blog.csdn.net/weixin_43615570/article/details/135714616
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- web前端javascript笔记——(14)Navigator 、History、Location
- Java中String、StringBuffer和StringBuilder的区别
- Unity中Shader旋转矩阵(四维旋转矩阵)
- java是值传递还是引用传递
- QOS(Quality of Service)基本原理及配置示例
- Windows10安全中心图标的关闭方法
- Linux之shell编程(BASH)
- 张驰咨询:深入探讨DFSS优化设计、提升质量的有效路径
- cocos uuid 相关问题一
- MySQL深入——11