可视化实战丨基于pygal与requests分析GitHub最受欢迎的Python库
写在前面
本期内容: 基于pygal与requests分析GitHub最受欢迎的30个Python库
实验环境:
- python
- requests
- pygal
下载地址:https://download.csdn.net/download/m0_68111267/88719839
实验目标
在现实的应用中,我们经常会使用爬虫分析网络数据,本期博主将用pygal+requests简单对github最受欢迎的30个python库做可视化分析(以stars数量进行排序)。
实验内容
1.配置实验环境
在正式开始之前,我们需要先安装本次实验用到的依赖库:
requests:一个Python第三方库,用于发送HTTP请求,并且提供了简洁而友好的API。它支持各种HTTP方法,并具有自动化的内容解码、会话管理、文件上传下载等功能,是进行Web开发和网络爬虫的常用工具。
pygal:一个开源的Python图表库,用于制作统计图表和可视化数据。它支持多种图表类型,包括折线图、柱状图、饼图等,并且具有丰富的样式和可定制性。通过pygal,用户可以轻松地创建漂亮、交互式的图表,用于数据分析和展示。
安装命令:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pygal
2.GitHub知识点
GitHub官方提供了一个JSON网页,其中存储了按照某个标准排列的项目信息,我们可以通过以下网址查看关键字是python且按照stars数量排列的项目信息:
https://api.github.com/search/repositories?q=language:python&sort=stars
这个网址的JSON数据中,items保存了前30名stars最多的Python项目信息。
重点关注以下信息:
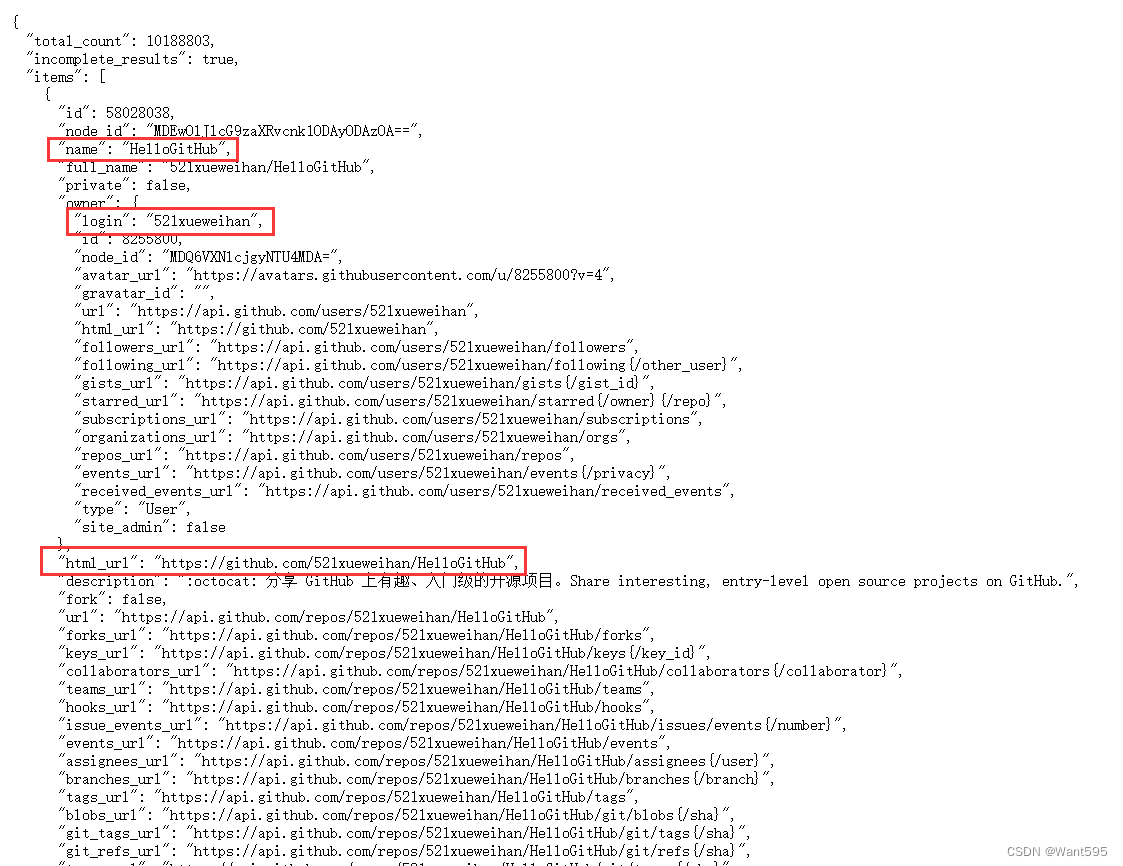
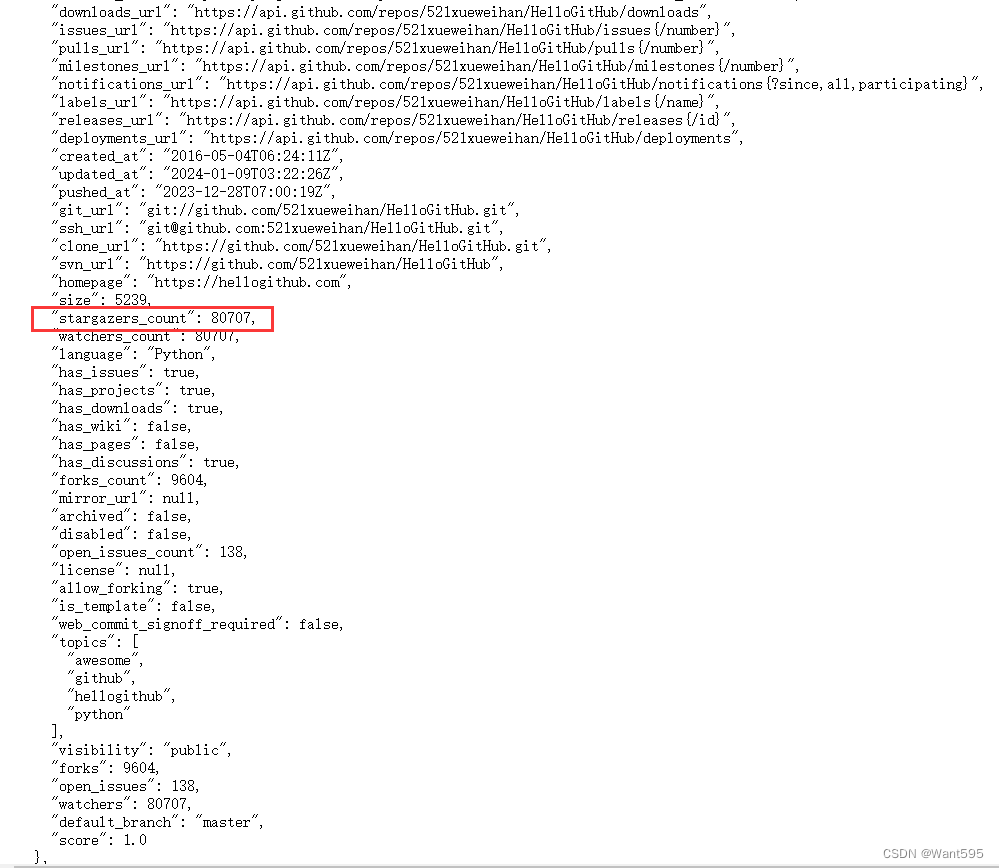
其中:
- name:表示库名称
- login:表示库的拥有者
- html_url:表示库的网址
- stargazers_count:该库被star的数量
3.爬取重要信息
我们先尝试着简单爬取一下本次实验所需要的几个重要信息
程序设计
"""
作者:Want595
微信号:Want_595
公众号:Want595
"""
import requests
url = 'https://api.github.com/search/repositories?q=language:python&sort=stars'
reponse = requests.get(url)
print(reponse.status_code, "响应成功!")
response_dict = reponse.json()
total_repo = response_dict['total_count']
repo_list = response_dict['items']
print("总仓库数:", total_repo)
print('top:', len(repo_list))
for repo_dict in repo_list:
print('\n名字:', repo_dict['name'])
print('作者:', repo_dict['owner']['login'])
print('Stars:', repo_dict['stargazers_count'])
print('网址:', repo_dict['html_url'])
print('简介:', repo_dict['description'])
程序分析
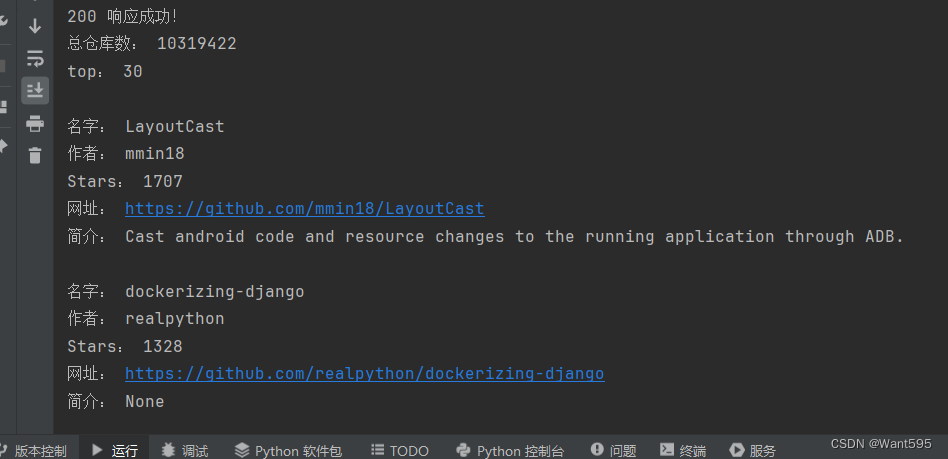
该代码使用Python的requests模块来访问GitHub的API,并搜索使用Python语言的仓库,并按照stars数量进行排序。代码首先发送GET请求,然后将响应转换为JSON格式。接着打印总仓库数和top仓库数。然后遍历仓库列表,并打印每个仓库的名称、作者、stars数量、网址和简介。这段代码的作用是获取GitHub上使用Python语言的仓库中的一些基本信息,并打印出来。
运行结果
4.可视化分析
程序设计
"""
作者:Want595
微信号:Want_595
公众号:Want595
"""
import requests
import pygal
from pygal.style import LightColorizedStyle, LightenStyle
url = 'https://api.github.com/search/repositories?q=language:python&sort=stars'
reponse = requests.get(url)
print(reponse.status_code, "响应成功!")
response_dict = reponse.json()
total_repo = response_dict['total_count']
repo_list = response_dict['items']
print("总仓库数:", total_repo)
print('top:', len(repo_list))
names, plot_dicts = [], []
……具体代码请下载后查看哦
程序分析
该程序使用了requests库向GitHub的API发送请求,获取了Python语言的仓库列表,并对返回的数据进行处理和分析。
具体的程序分析如下:
- 导入需要使用的库:requests、pygal以及相关的样式库。
- 设置GitHub的API请求URL,其中指定了查询语言为Python,并按照星标数(即stars)排序。
- 发送GET请求,并获取返回的响应对象。
- 打印响应状态码,用于验证请求是否成功。
- 将响应对象的JSON数据转换为字典形式。
- 获取仓库的总数和仓库列表。
- 打印总仓库数和仓库列表长度。
- 初始化用于绘图的变量:names(存储仓库名称)、plot_dicts(存储每个仓库的相关信息)。
- 遍历仓库列表,分别获取仓库名称、仓库的星标数、仓库的描述和仓库的URL,并将相关信息添加到对应的变量中。
- 初始化绘图的样式和配置。
- 创建柱状图对象,并设置标题、横坐标、数据等属性。
- 将数据添加到柱状图中。
- 将柱状图渲染为SVG文件。
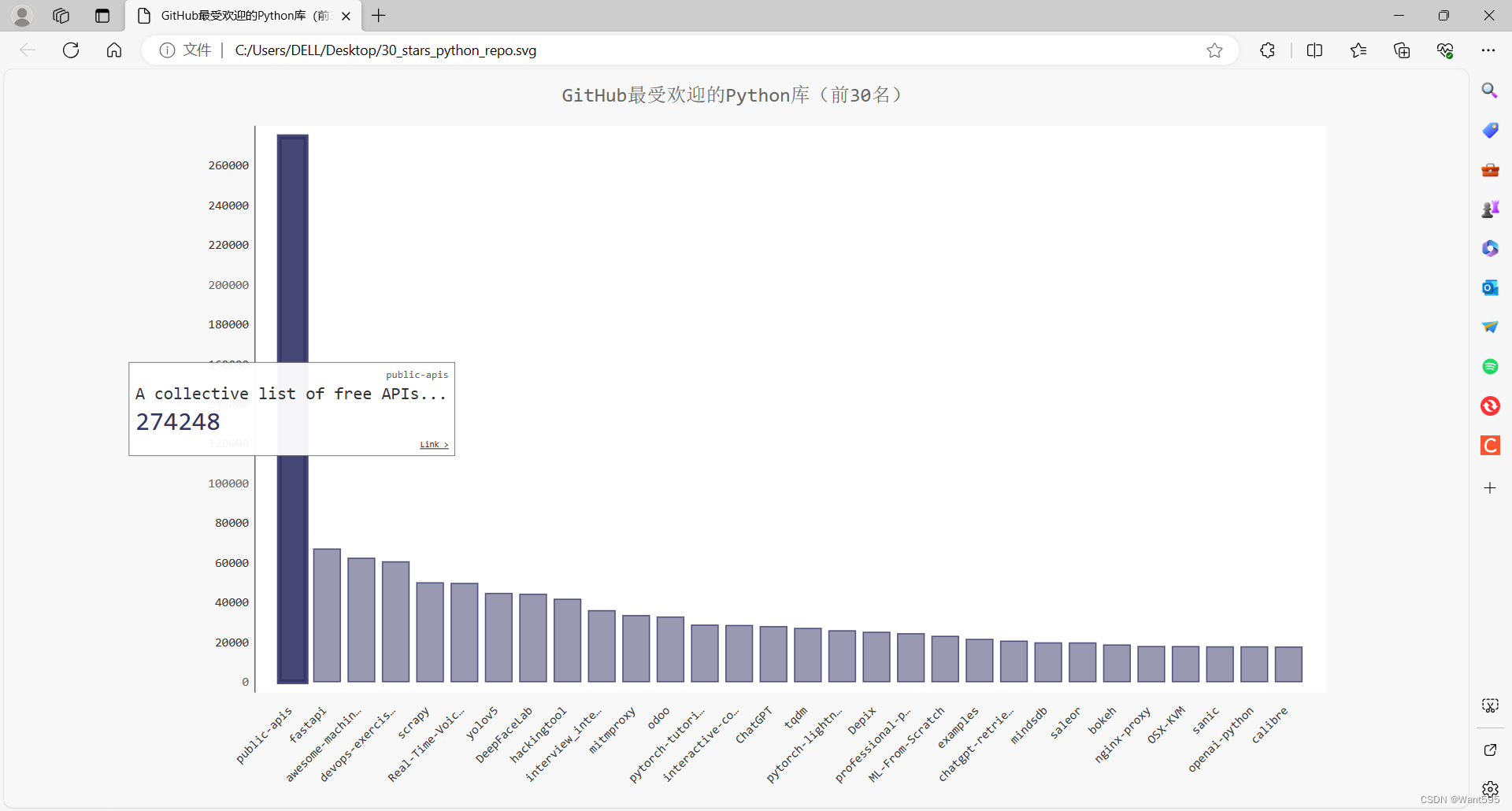
最终的结果是生成了一个包含前30名最受欢迎的Python库的柱状图,并将图表保存为SVG文件。
运行结果
写在后面
我是一只有趣的兔子,感谢你的喜欢!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 性能篇:List集合遍历元素用哪种方式更快?
- 有趣的代码——手机通讯录的简单实现
- 智慧机房建设浪潮:2024年动环监控系统厂家排名出炉
- 力扣 | 238. 除自身以外数组的乘积
- 计算机与人工智能:共创智能时代的新篇章
- CentOS7的安装配置
- AI实景无人直播
- Java利用aspose.cells对xlsx文件转PDF
- 如何在powershell查看.jar文件的java编译版本
- 基于ssm的校园预点餐系统(有报告)。Javaee项目。ssm项目。