Java中的JVM指令和Arthas以及Dump文件(jvisualvm和MemoryAnalyzer工具)整体分析
前言
前天线上服务器突然内存和CPU都爆掉了,两者都处于一种高负载的状态,而且还是周末的情况下,起初运维同事怀疑是用户数量暴增,但是数据面板上并没有出现很大的暴增现象,之前的服务器4G的内存都跑不满后面升到8G还是不够,于是我用
jps
jmap -heap <pid>
查看了下堆状态,发现老年代的空间占用率99%(大小为5个G),新生代2个多G,于是我怀疑是某个业务一直在创建大量的对象,当然这只能是初步怀疑,接着我又去分析CPU,主要使用了以下命令
1.JVM指令
top查看进程CPU负载情况
ps -mp <pid> -o THREAD,tid,time | sort -rn查看高负载的进程中的线程详情,看看是哪个线程占用比较高,注意这里看到的tid是十进制下的,操作系统中进程的线程是十六进制,需要进行一下转换
printf '%x\n' <tid>得到十六进制
jstack -l <pid> | grep <tid> -A 300利用JDK原生命令查看java进程下某个线程的状态
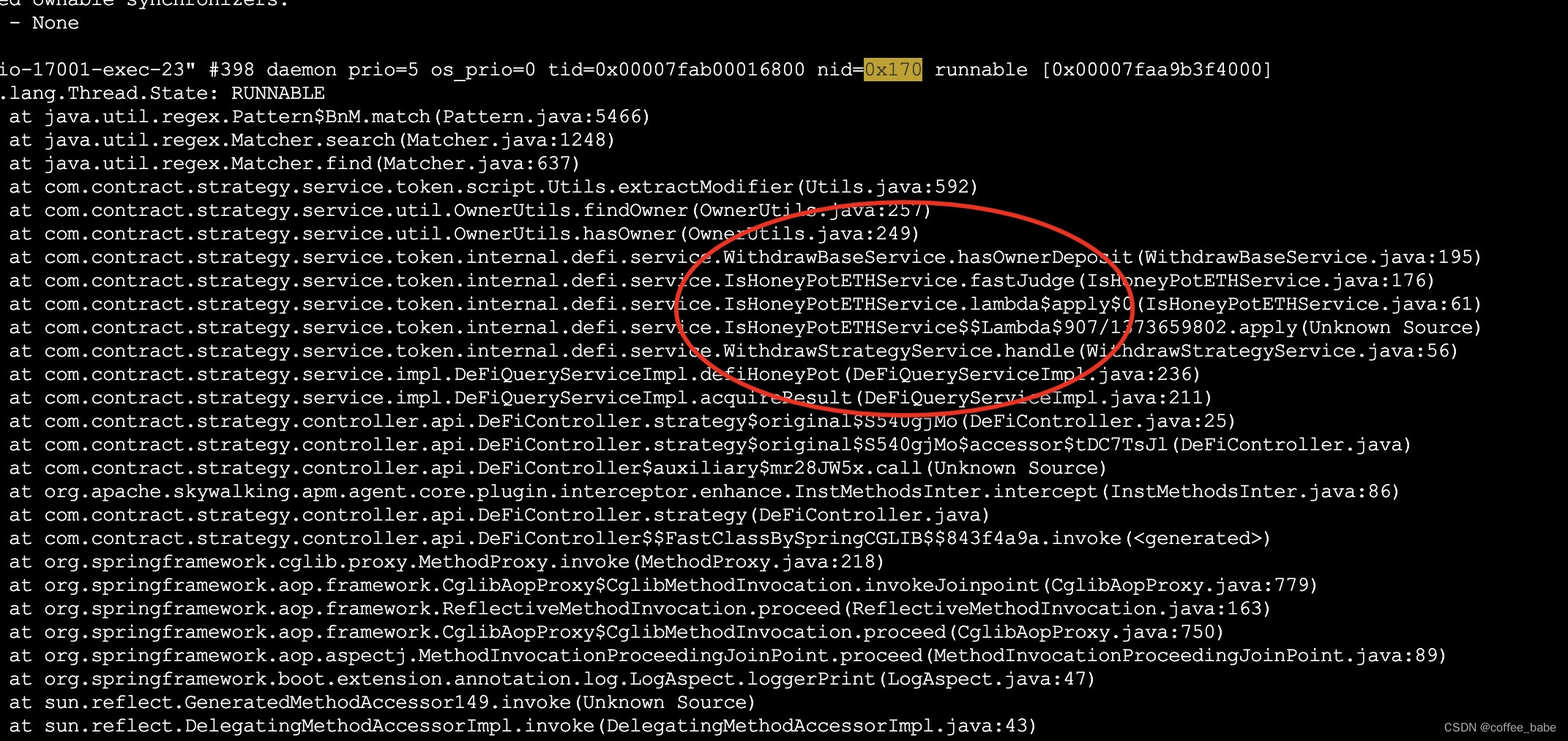
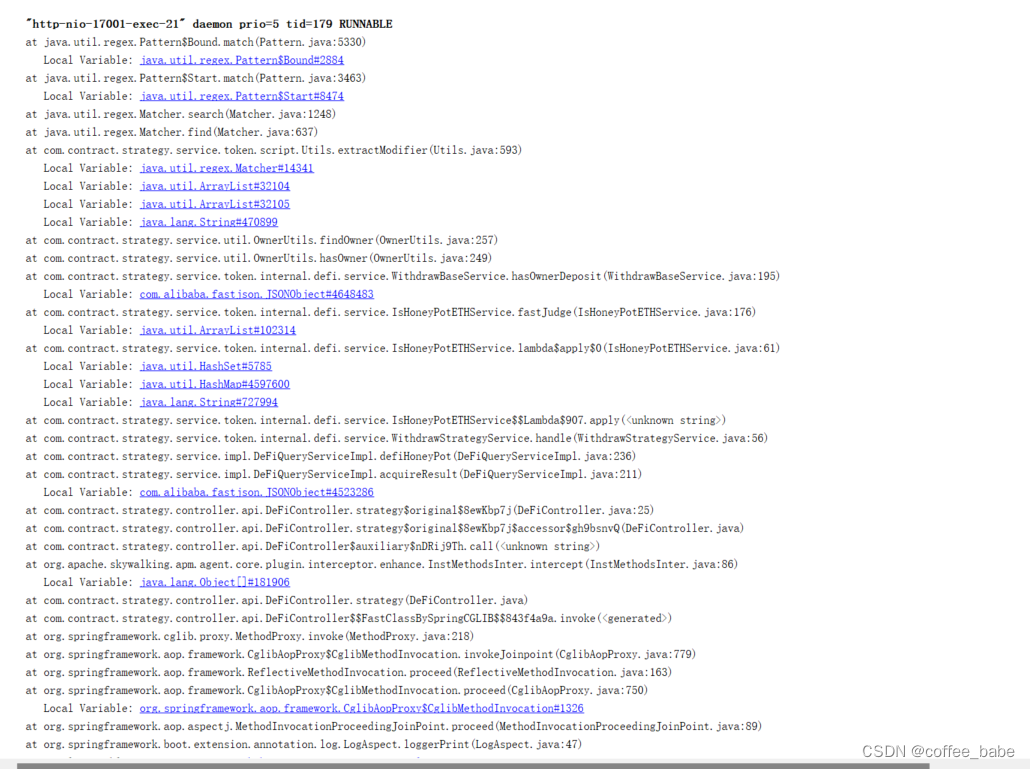
上面的堆栈情况我们可以清晰地定位到业务代码,我在这里花费了很多的时间去调整业务代码,调整了很多次发现仍然无法得到解决,于是我想着去调整下JVM的相关参数限定一下,具体操作如下:
-XX:CICompilerCount=2 JIT后台编译的线程数
-Xms3g JVM堆的初始化大小(之所以设置和Xmx一样大小,是防止JVM不断地扩缩容,导致内存无法在第一时间得到空间)
-Xmx3g JVM堆地最大大小
-Xmn2g JVM堆新生代的大小
-Xss1m JVM的调用栈大小(默认不调整的话是256k,这里可以适当地调大点)
-XX:OldSize=1g JVM的老年代的初始化大小
-XX:+UseCompressedClassPointers 使用类指针压缩
-XX:+UseCompressedOops 使用指针压缩
调整完了之后,内存是控制住了,但是CPU仍然高负载,运行十几分钟就会这样。我之所以去控制内存,是因为发现调整业务代码没有效果,接着我发现Pattern类中的位置使用了buffer,当时想的就是操作系统的内存不够,所以CPU上去了,想的是把内存控制住,CPU就会降下来,因为buffer大概率是要申请操作系统的内存

对了,设置完相关JVM参数,一定要使用jinfo <pid>命令查看一下是否确认生效,或者你可以使用jmap -heap <pid>查看,上面的图是无关的,只是做来演示.
2.Arthas工具排查
当然如果你会用Arthas当然会更好,这中间我也用过arthas,命令查看将会非常简单。
下载命令也比较简单
curl -O https://arthas.aliyun.com/arthas-boot.jar
java -jar arthas-boot.jar
你可以使用下面的命令来观测
dashboard
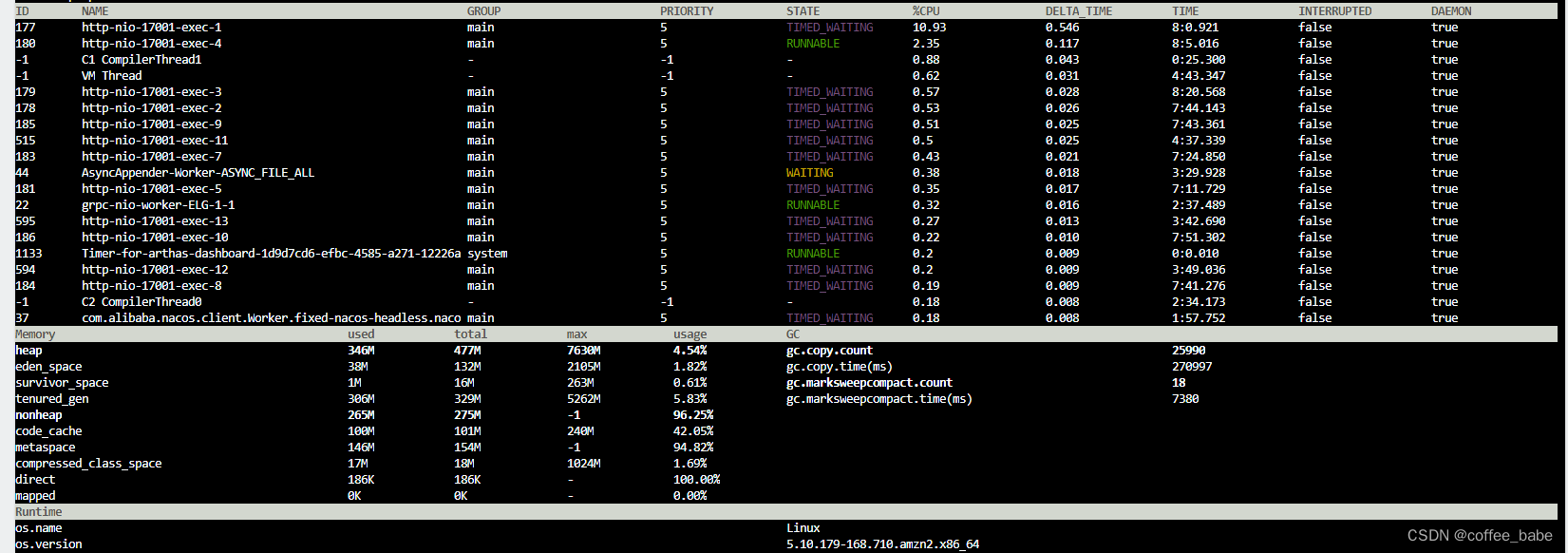
thread <tid>
观测线程状态
 我这里当时看到的和上面第一张图一样,某个业务代码报错了。现在是正常的了,所以这里是没问题的。当然你可以查看业务代码执行是否情况,是否有报错
我这里当时看到的和上面第一张图一样,某个业务代码报错了。现在是正常的了,所以这里是没问题的。当然你可以查看业务代码执行是否情况,是否有报错
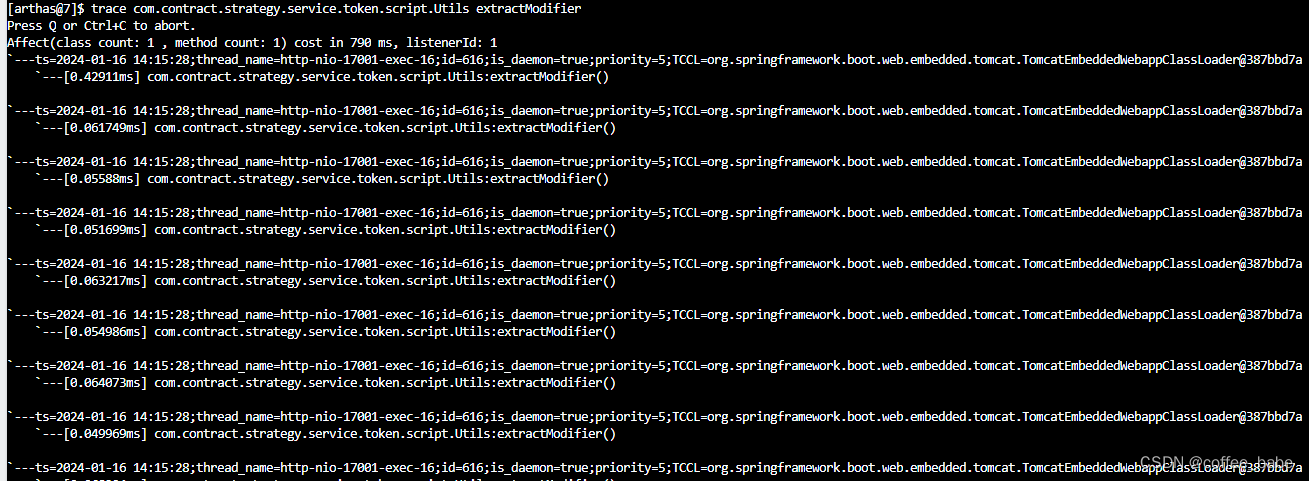
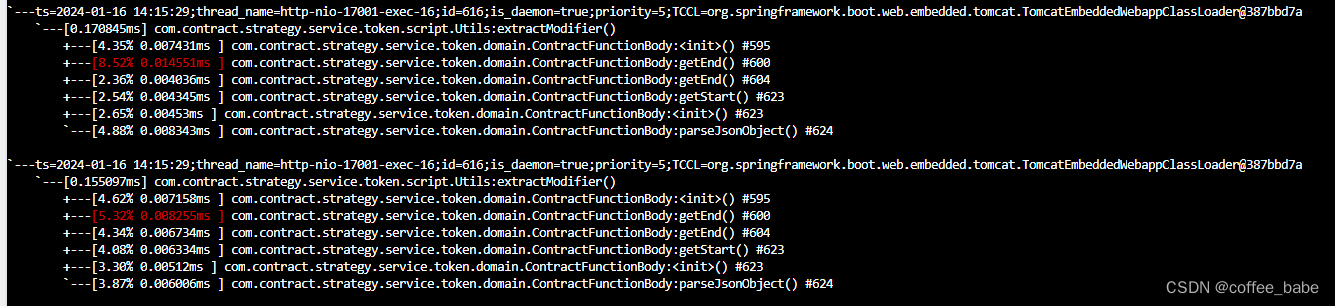
trace xxxx(全限定类名) xxx(方法名)1
使用这个命令来跟踪方法的调用情况,还会给你出具一份简单的统计耗时
tt -t xxxx(全限定类名) xxx(方法)
使用该命令来跟踪方法的入参和出参返回情况
IS_RET表示是否正常返回,IS_EXP是否异常返回

watch xxx(全限定类名) xxx(方法) "{params[1]}" -b
查看某个方法在调用前的某个参数

经过一系列的分析,发现没有看出问题,因为业务代码本身没有报错的,否则是可以直接看出来的,这期间花费的时间也挺多的,但是问题仍然没有得到有效解决
3.Dump文件分析
dump文件一般来说都比较大,我是使用jmap -dump:file=xxxxx.dump <pid>
我这里是生成了所有对象的快照,文件比较大,你也可以使用下方命令只导出存活对象的快照
jmap -dump:live,file=2024-01-16.dump <pid>
这里生成之后,你需要把它从服务器上下载下来
3.1 jvisualvm
它是一款JDK自带的一款分析工具,位置在你的bin目录下面,如图所示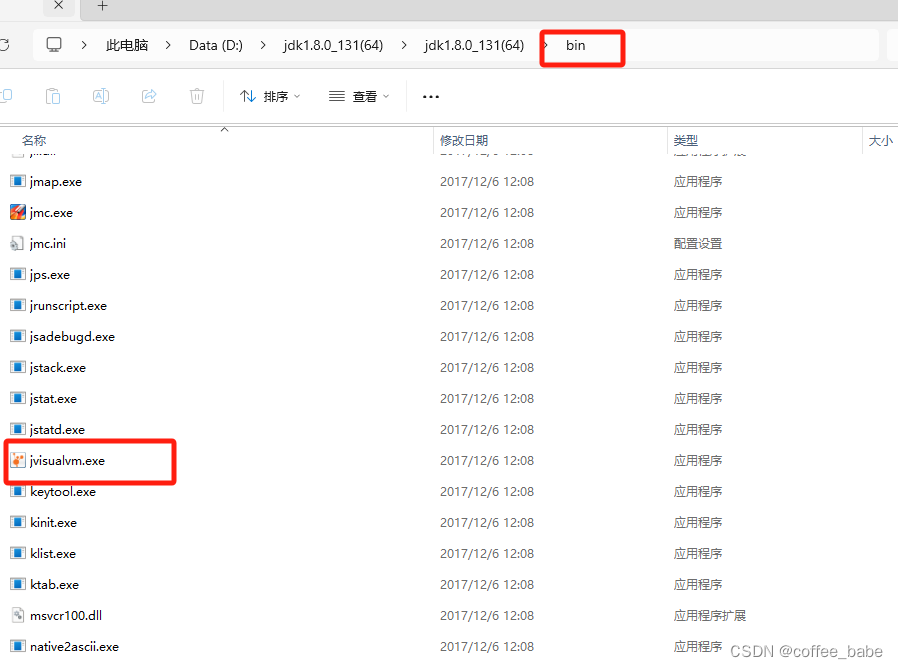
上面由于我生成了所有对象的快照,大小为6G,所以打开这款工具之前需要调整下参数,否则打开将会非常卡顿,调整下Xmx Xms这两个就行,我这里调整成了初始化2g,最大4g

一次点击左上角 文件 -> 装入 -> 你的dump文件,该过程会比较慢,需要耐心等待下
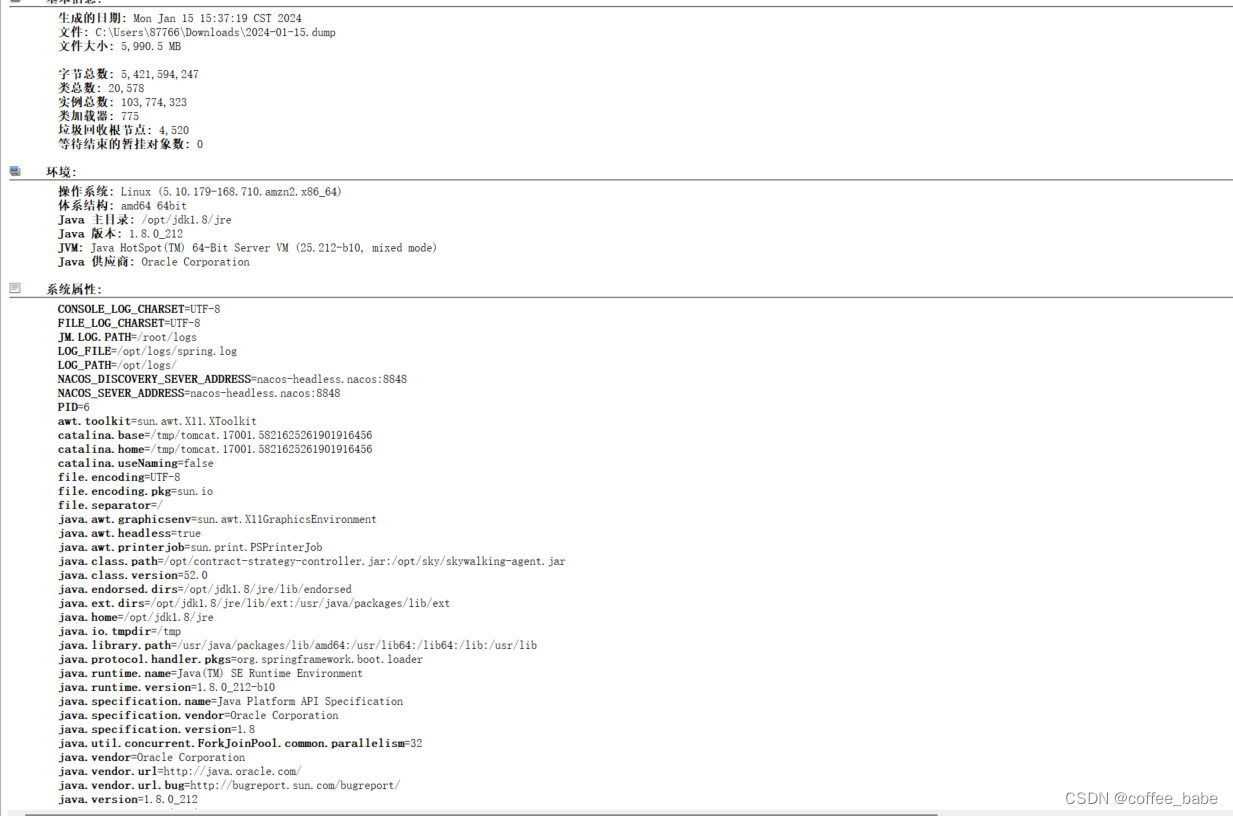
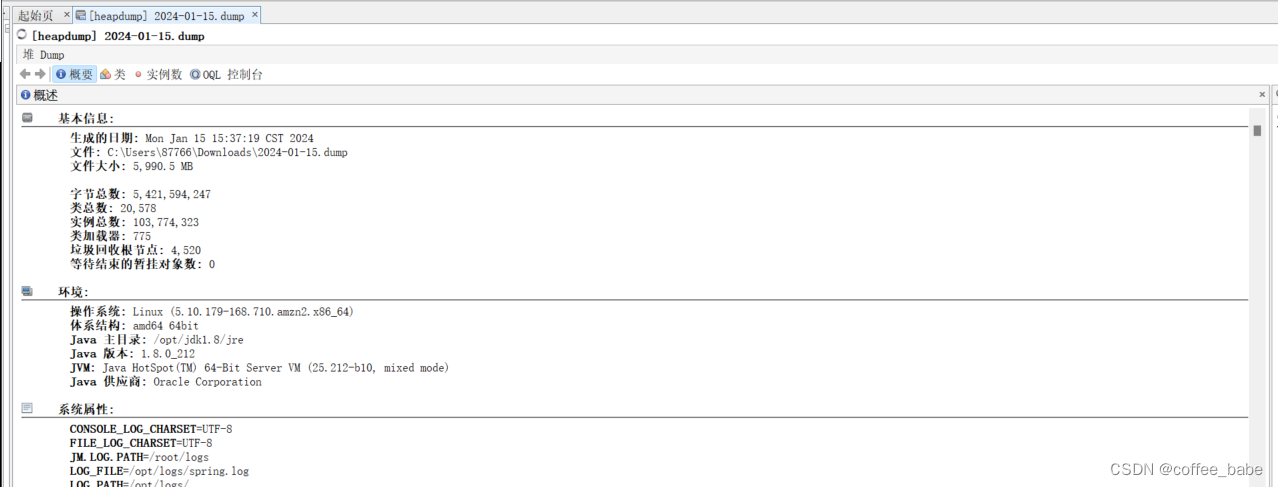
加载完成之后,你会看到一个概要 如下图,你的环境以及系统属性
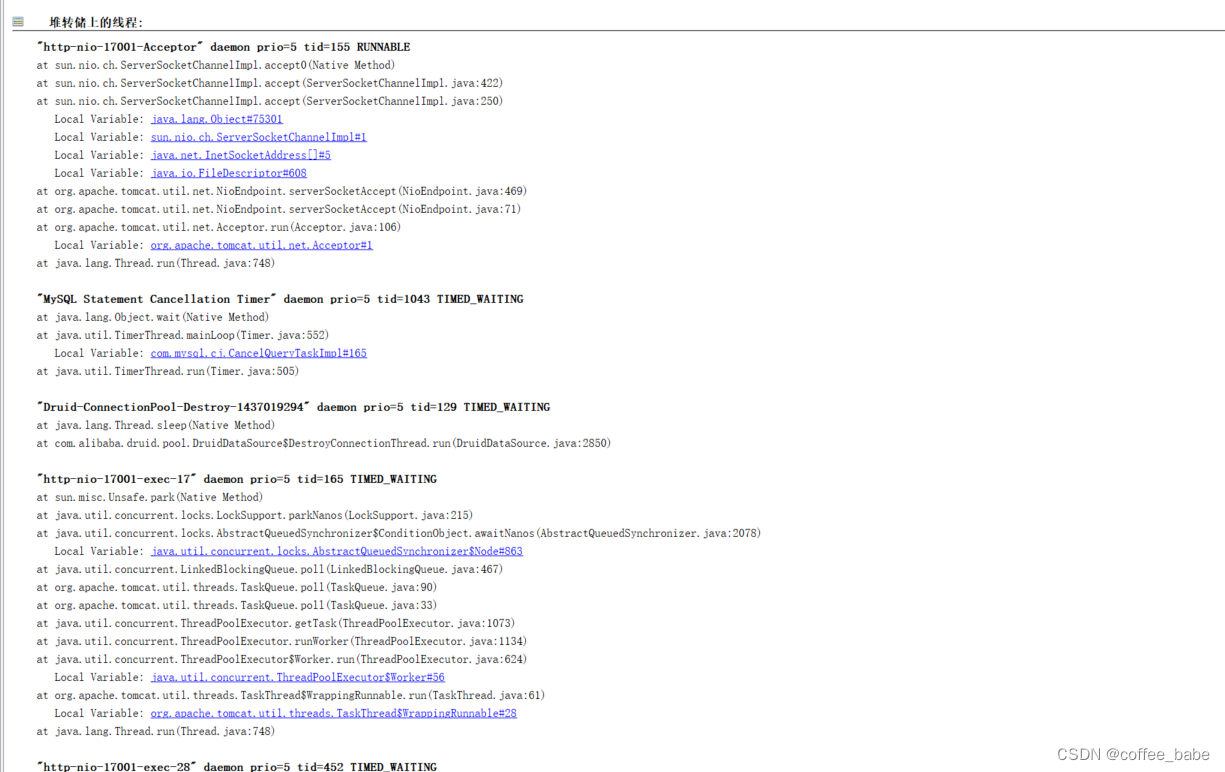
以及你的线程状态,我也在这里看到了排查CPU负载的那个线程状态
我们可以先来看下对象实例都是哪些对象
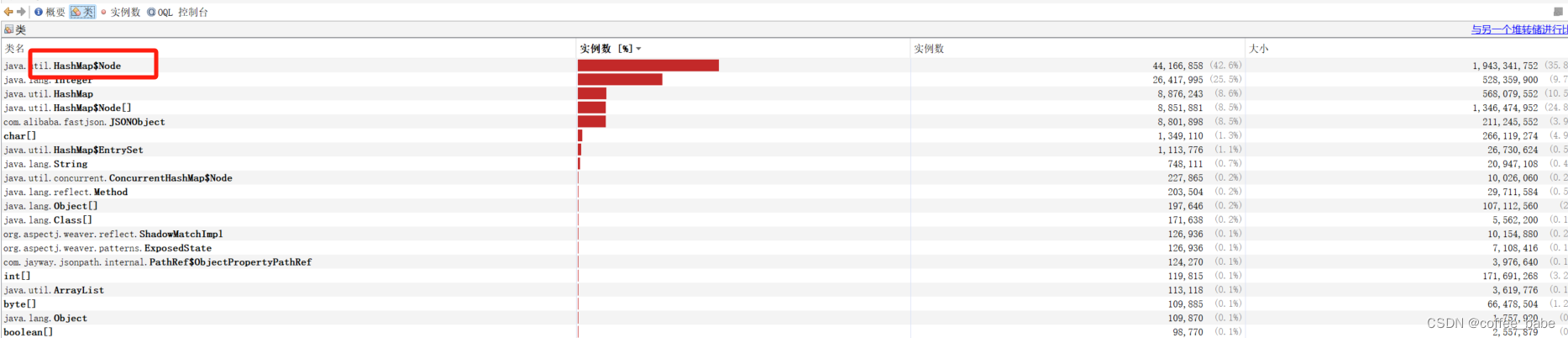
这里可以看到HashMap中存在了很多,占比达到了42%,我们进入到里面进去看看,双击即可,还是需要等待一下

可以看到实例确实很多,我们可以点击+号查看其中某一个实例,比如#1
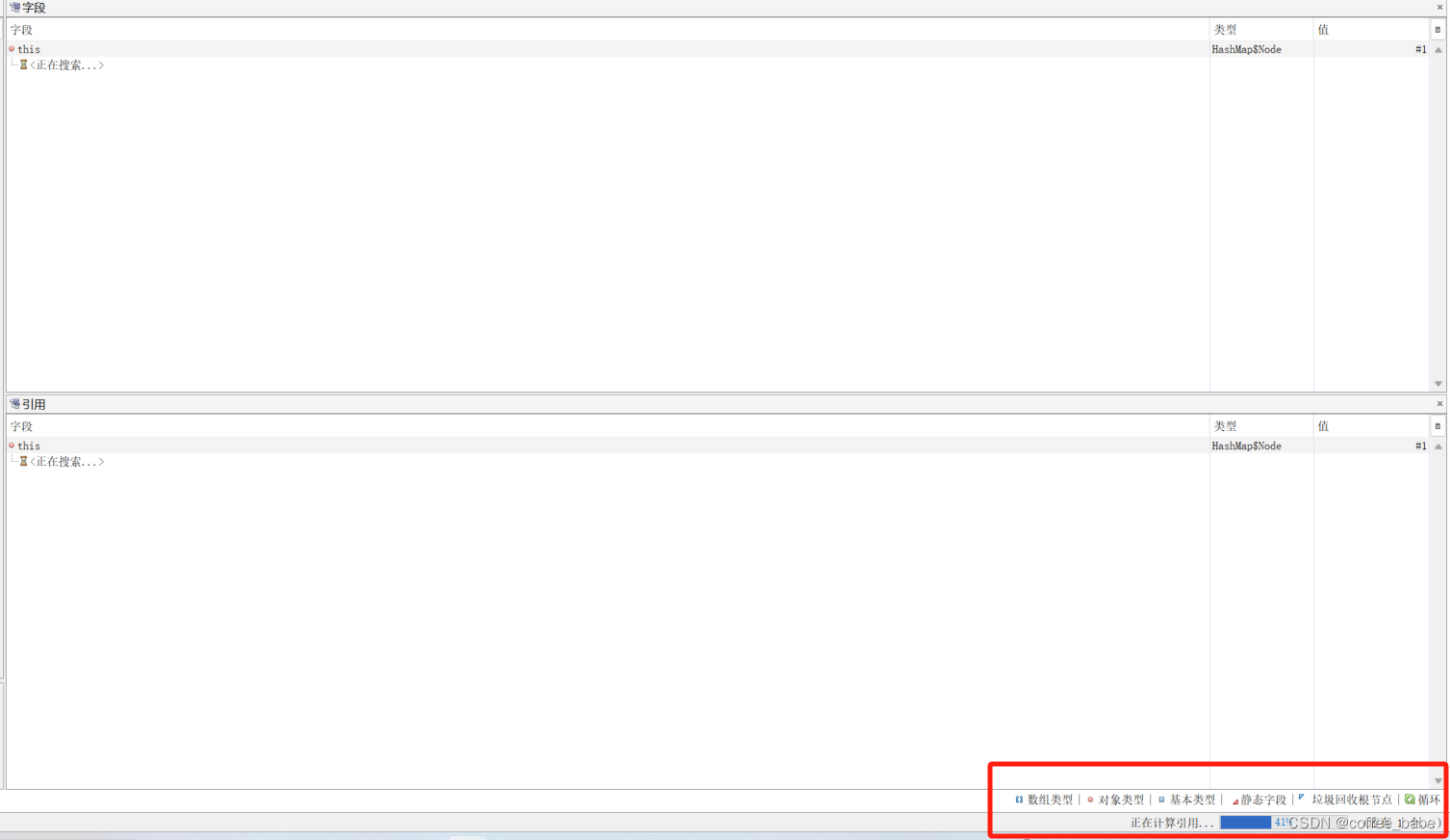
右下角会有一个进度条以及对象类型的颜色区别,加载完毕之后左边会显示这样
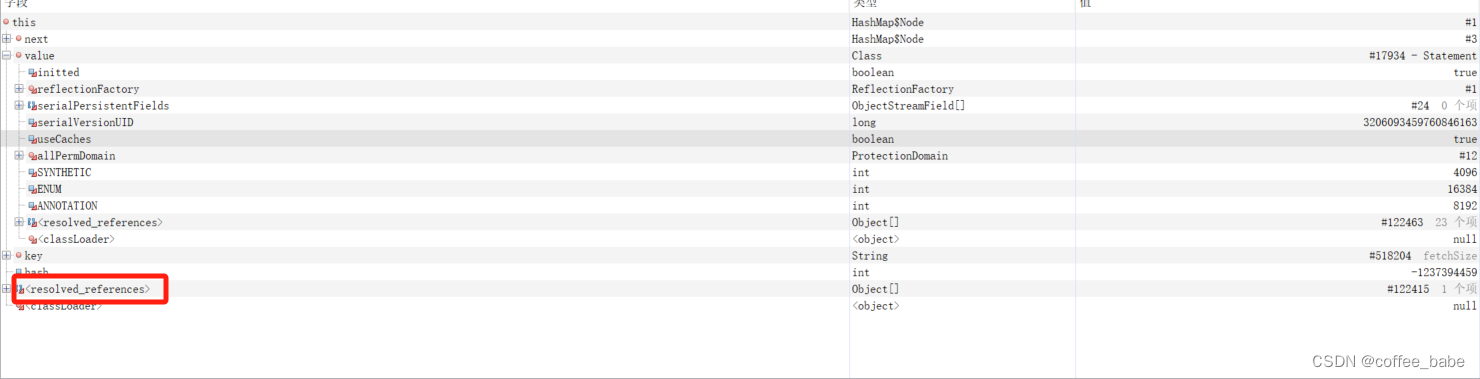
key和value也可以获取到一点线索,我们重点来关注下resolved_references,看下这个对象的引用关系都有哪些,由于大量反射机制也会关联很多,所以在jvisualvm中并不能很清晰地对这些引用实例做分析,需要你挨个去看,点击左边实例挨个去看,看看能不能找到一些蛛丝马迹,如果能找到一些,可以去看下相应的业务处理是否有问题,#1实例也不一定会立马看出来它的resolved_reference立马有问题,因为业务没有暴增,所以大概率是某个地方同事写的代码有问题导致的。
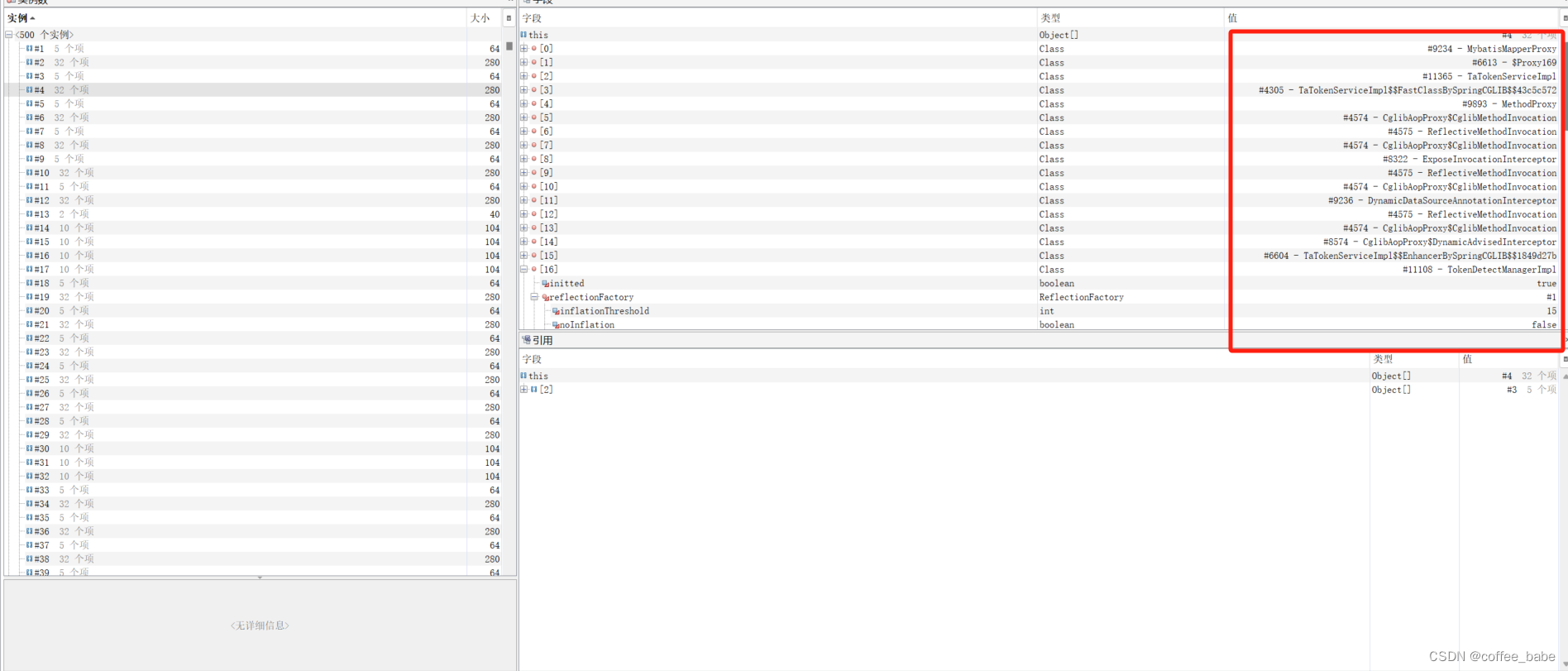
#1为了叫法区别,我们称它为1号实例吧,接着我们来看下3号实例的引用关系
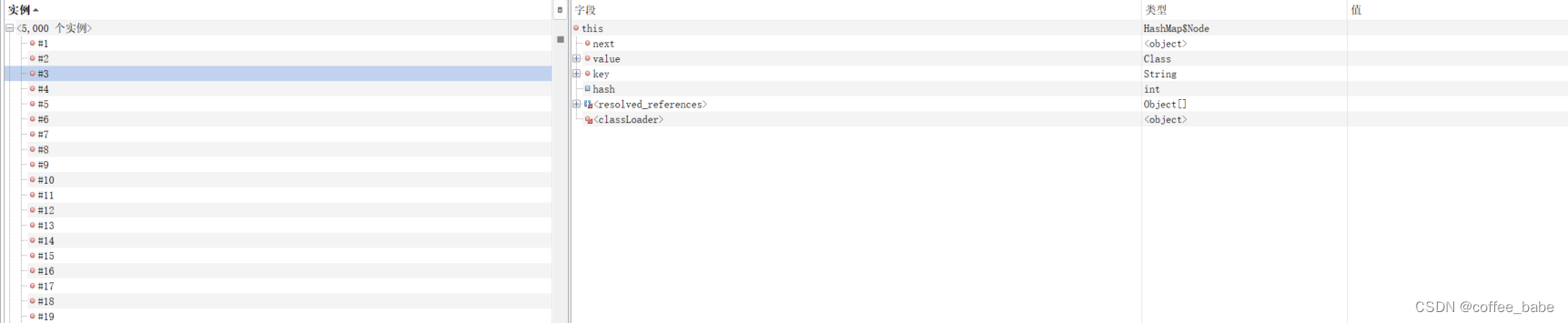
这里可以只是当作可以参考,并不能作为直接的原因,我在之前还可以看到sql语句的执行,但是我一时间找不到了,
也可以返回到上一级搜索自己项目的关键字进行对象查看,我这里发现没有出现很多的实例数,所以暂时没有定位出原因
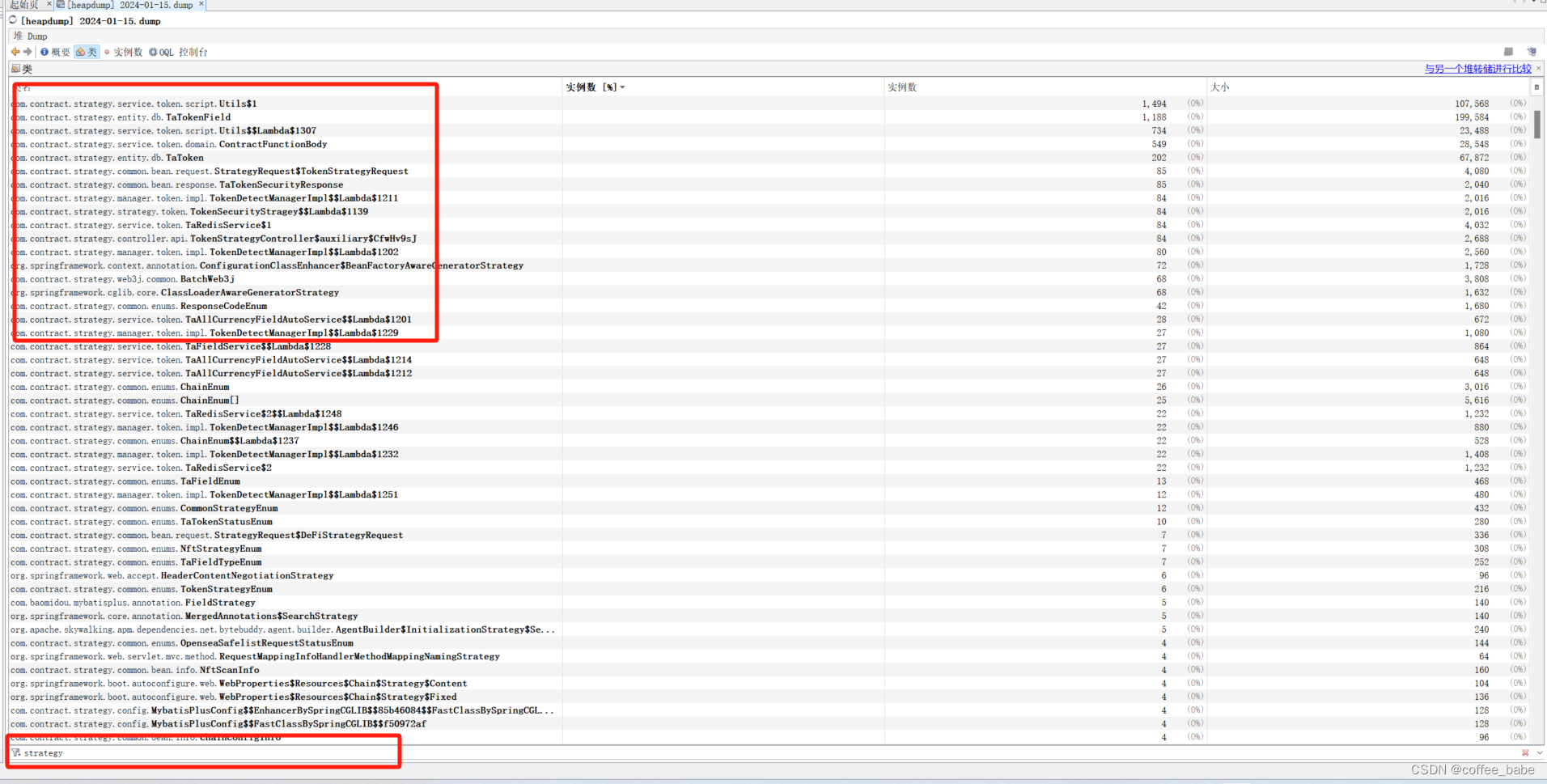
下面我会介绍另一种工具,它不会让我们在每个步骤发生卡顿,操作比较流程,功能也更强大
3.2 MemoryAnalyzer
它是一款由Eclipse团队开发的一款工具,非常好用,它会根据我们生成的dump文件出具一份报告帮我们定位问题,也是需要进行一些参数设置,有的时候会提示你系统的JDK版本过低,需要升级,然后你更换下JDK即可,这里不再赘述,由于我前面dump的文件扩展名是.dump这里需要改成.hprof,不然没法识别
我们还要把它的Xmx设置的大一点,也方便你操作流畅,否则你可能会在加载文件中遇到内存不足
-startup
plugins/org.eclipse.equinox.launcher_1.6.600.v20231106-1826.jar
--launcher.library
plugins/org.eclipse.equinox.launcher.win32.win32.x86_64_1.2.800.v20231003-1442
-vmargs
--add-exports=java.base/jdk.internal.org.objectweb.asm=ALL-UNNAMED
-Xmx10240m
我们可以默认勾选内存泄漏分析,它会帮我们自动定位
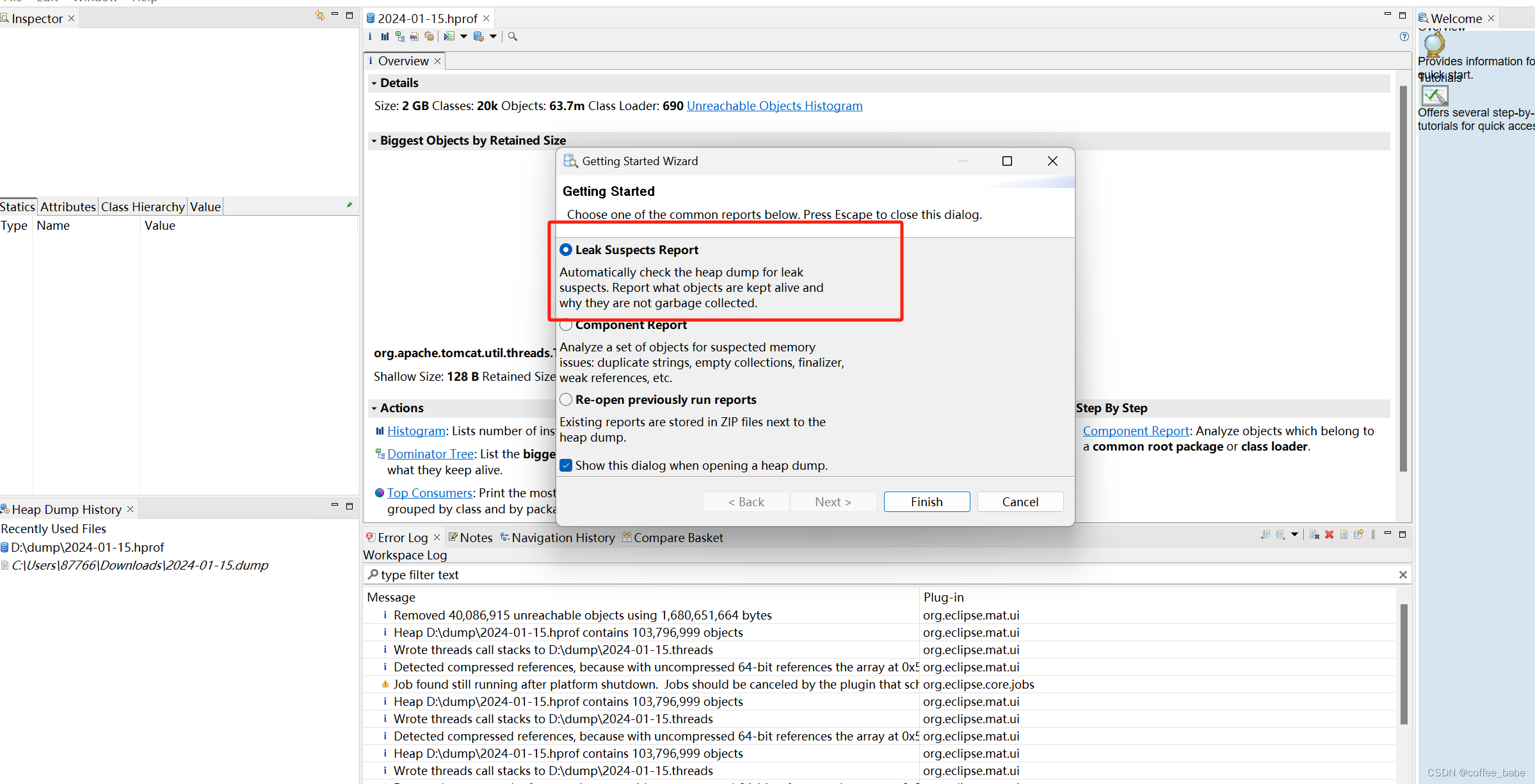
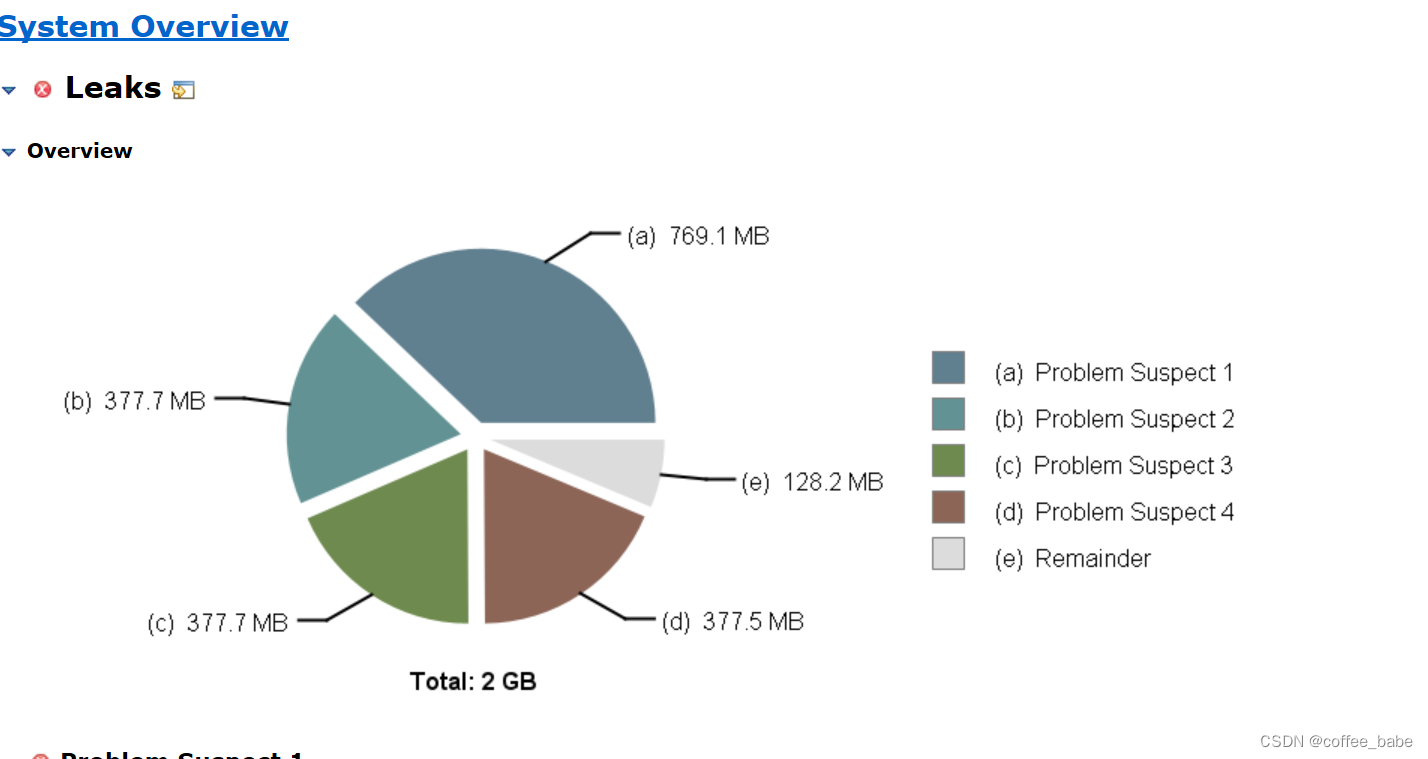
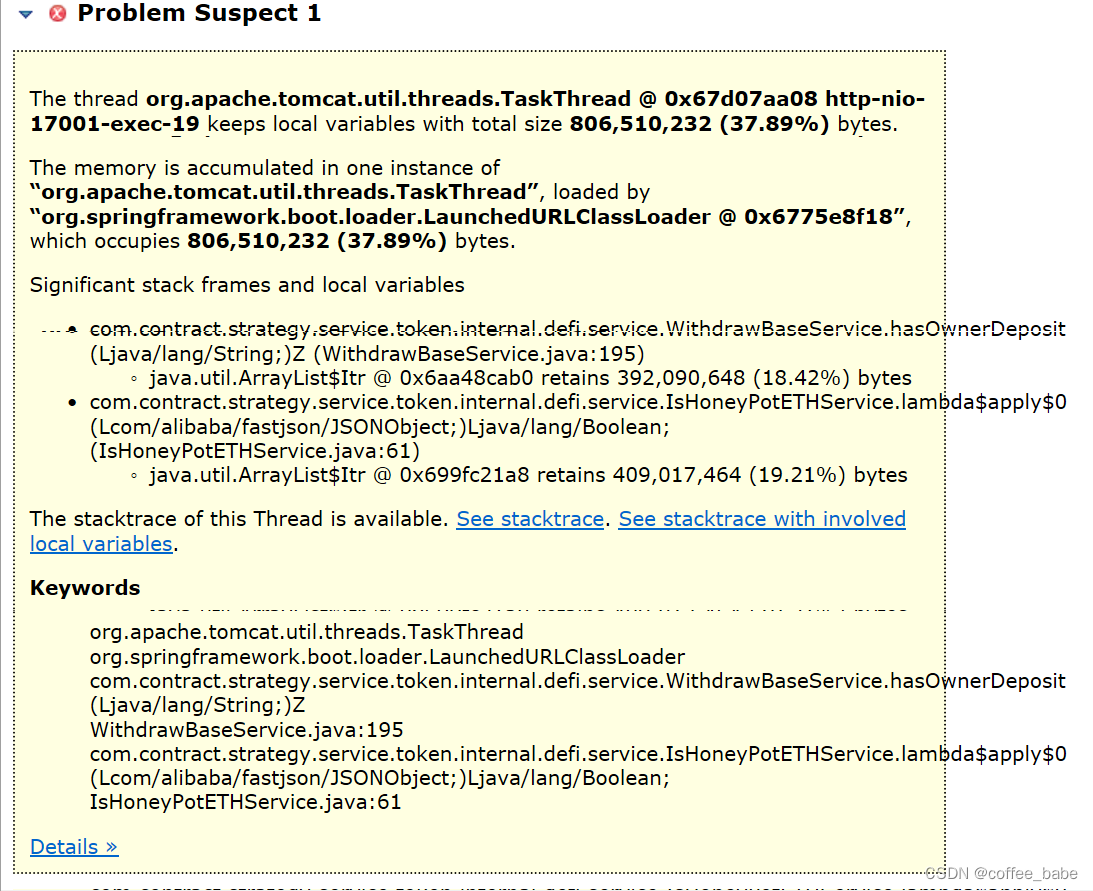
还可以查看堆栈情况
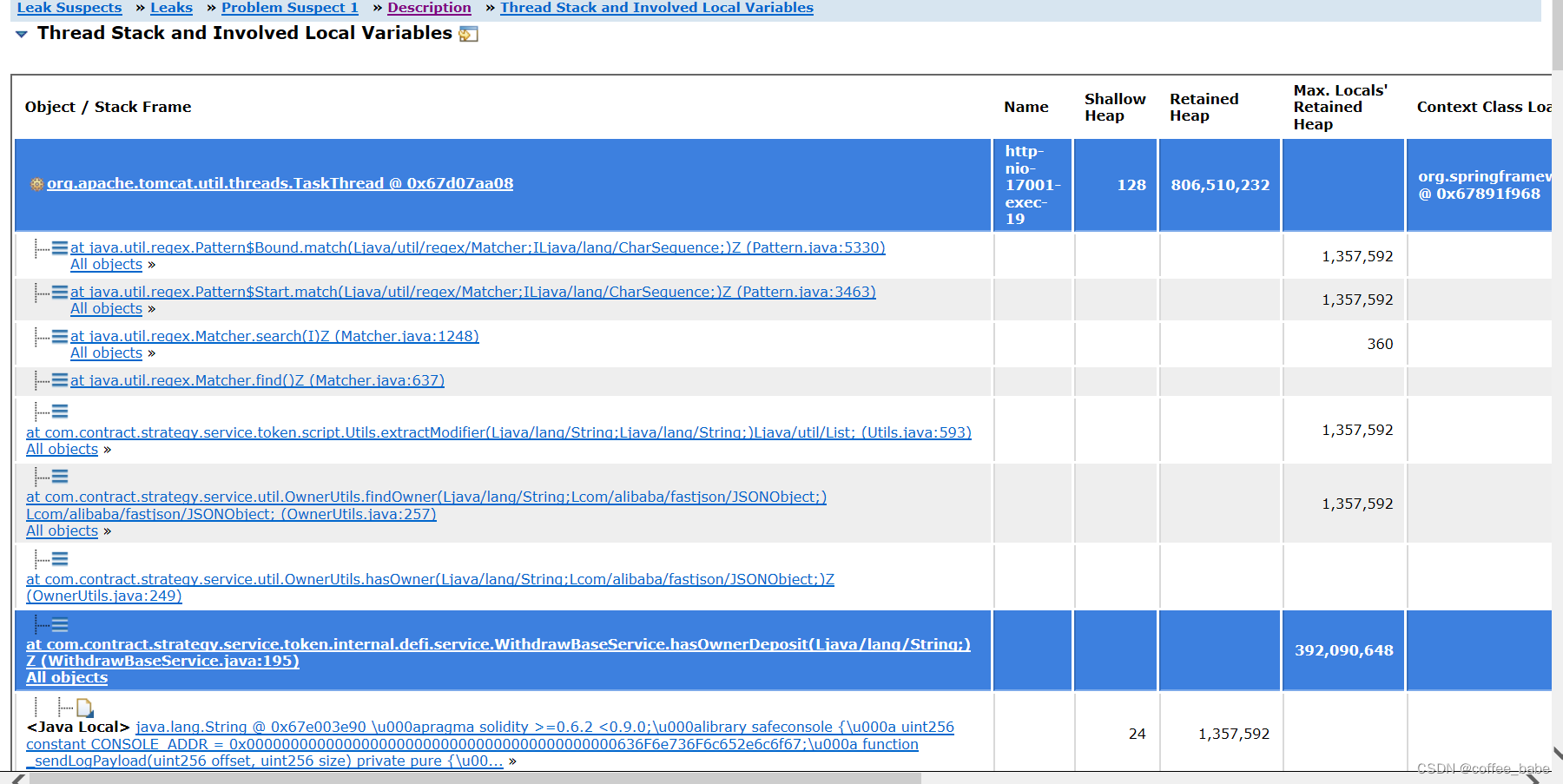
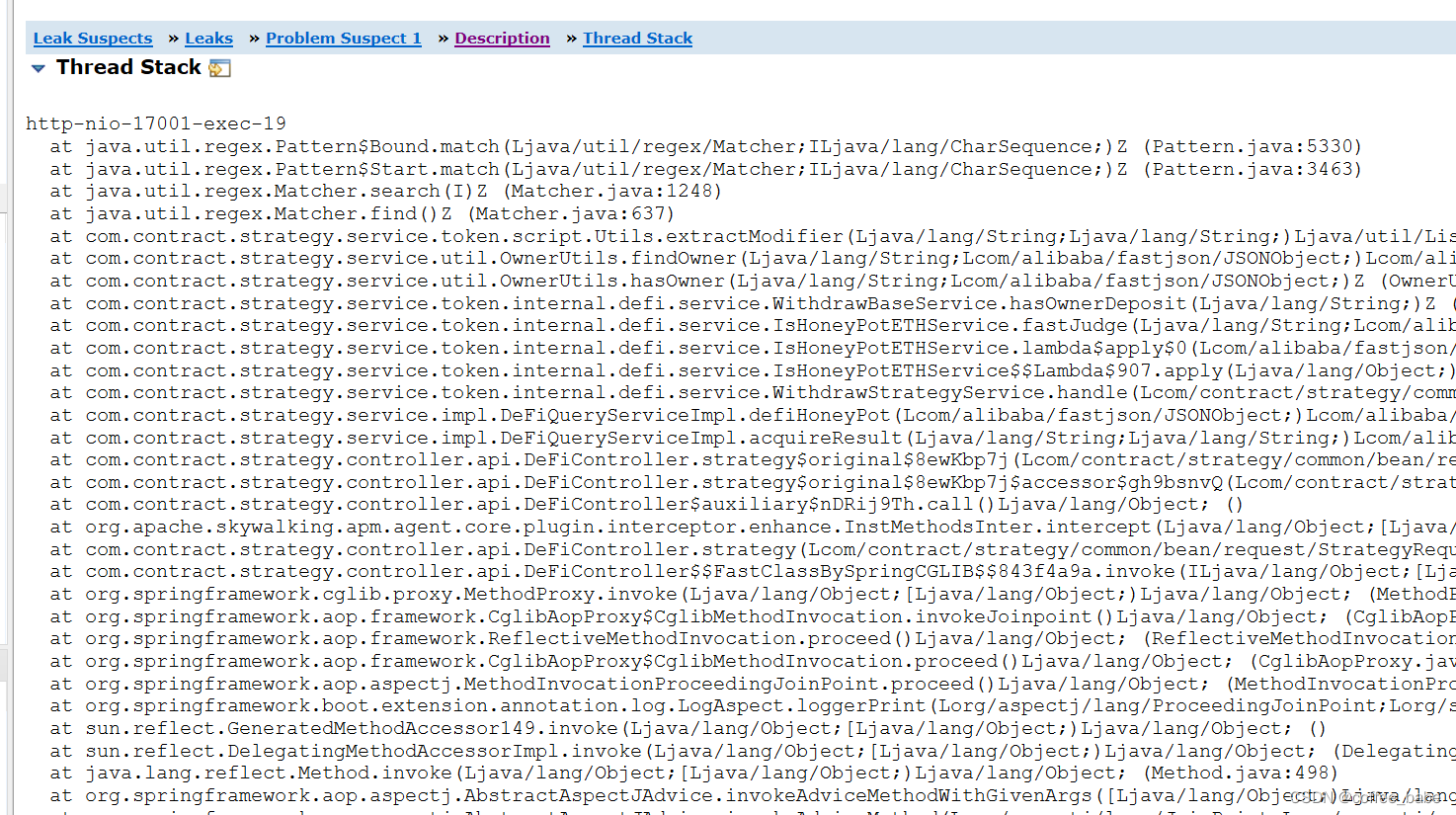

它这里帮我们分析出的业务代码中一个List数组中维持了18.42%的字节占比,看到这里我才有点明白是怎么回事,根本原因是我在一个for循环当中调用了一个方法栈比较深的逻辑判断,而这个for循环的数量又很多,所以导致出现了问题,以致于产生了内存泄漏,进行了二次调整,到这里我才终于把问题解决掉。
对于MAT这款工具的使用,我再多说几句
3.3 MAT番外篇
打开Histogram,我们在上方的输入框中输入业务关键字,可以根据对象数量来个倒序,如果你看到的业务对象很多可以接着操作,右键业务对象类 -> java basics -> open in dominator tree查看这些对象的分配树结构
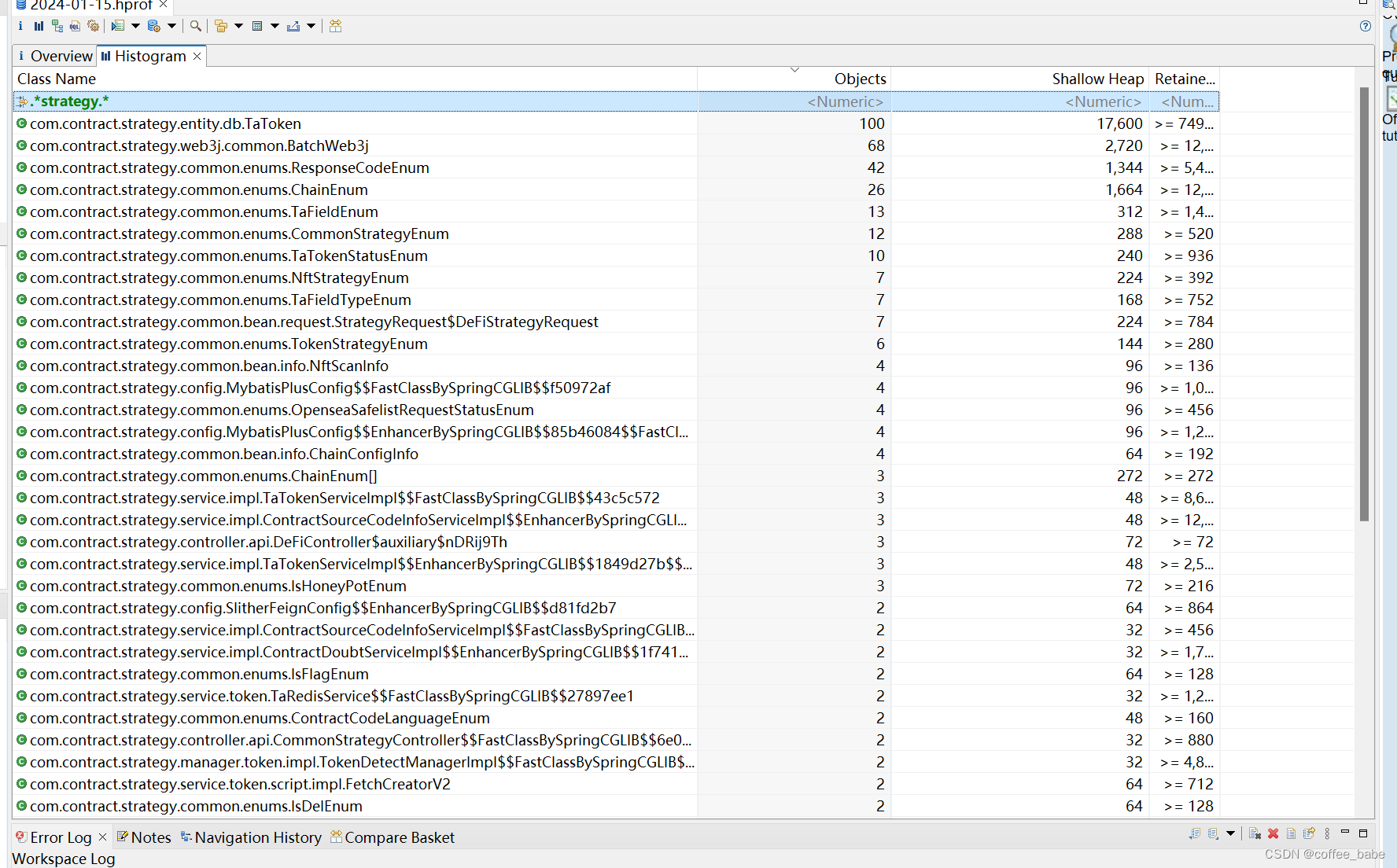
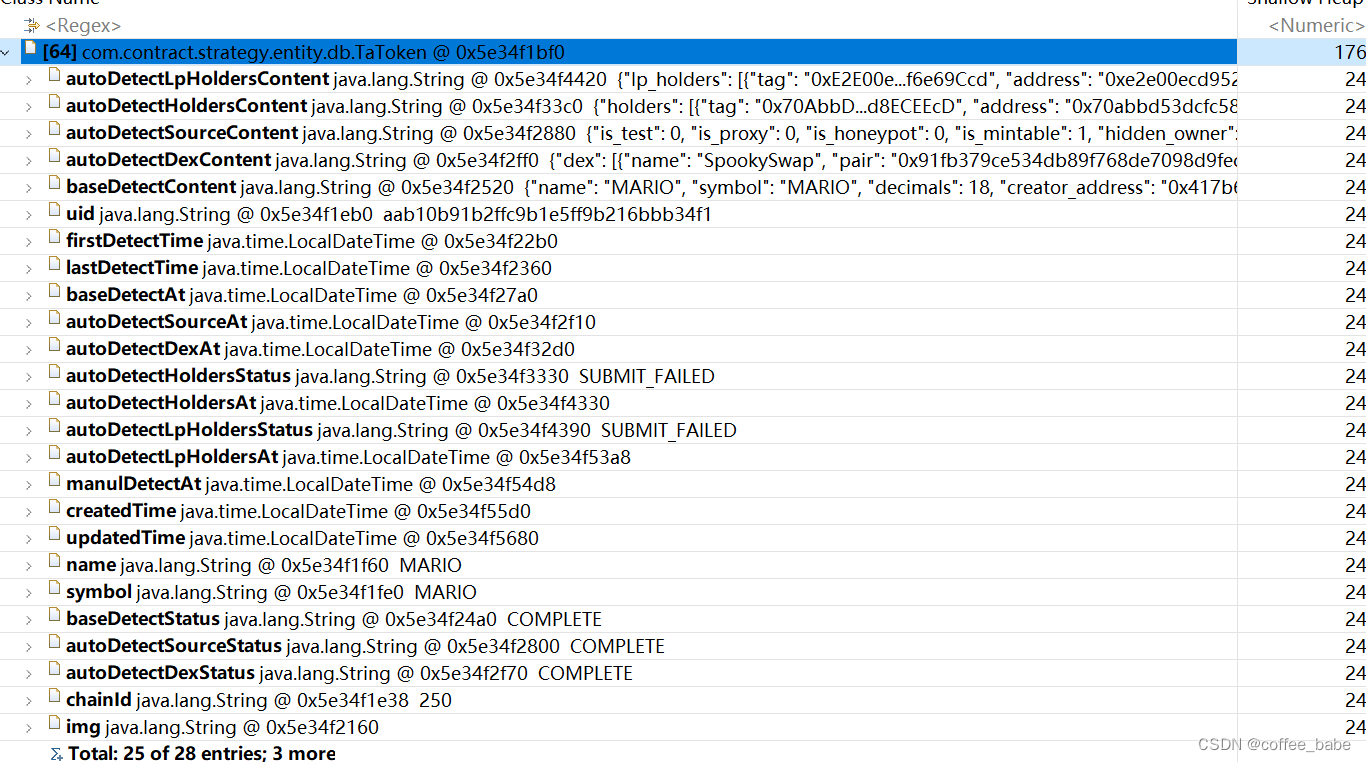
我们可以看到对象的每个字段,以及它们的属性以及值是什么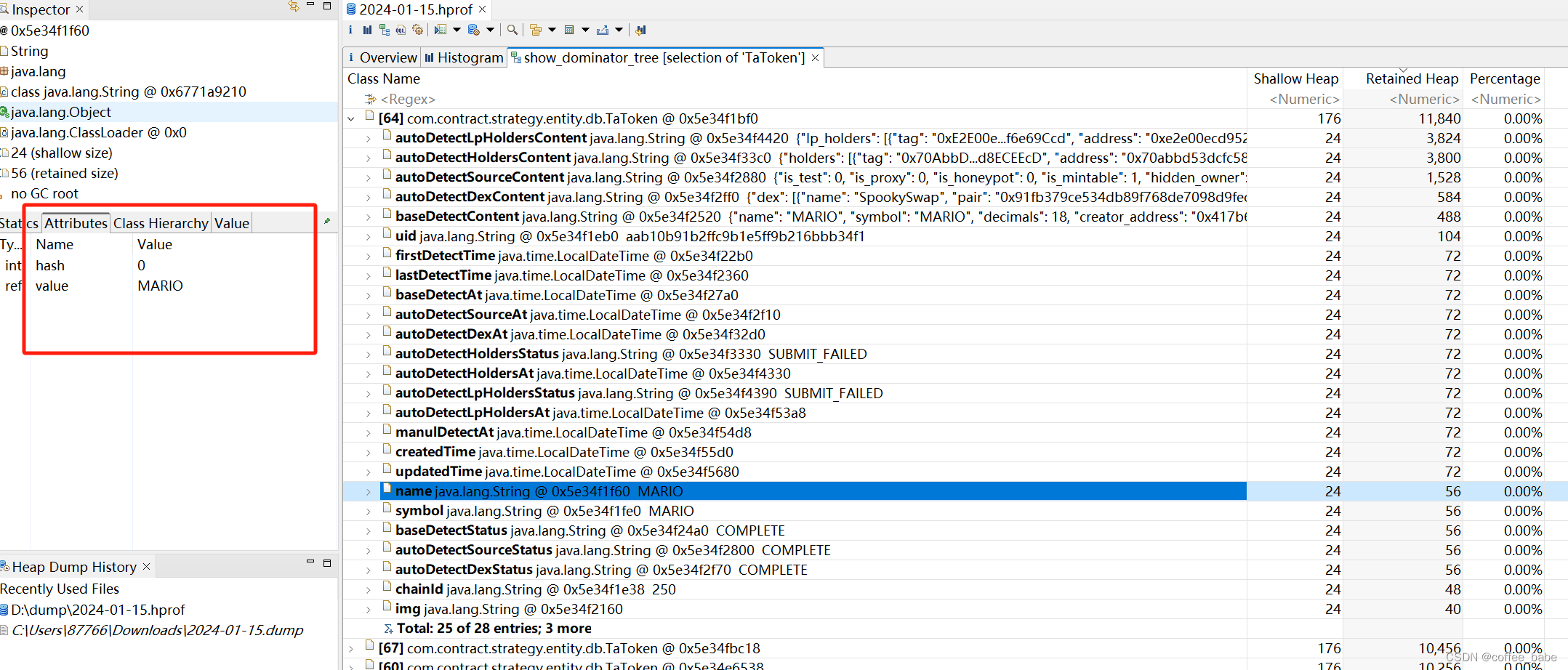
4.总结
讲了这么多,我们来总结一下,这篇博客基本上把市面上流行的排查手法都介绍了一遍,但是没有做精细化介绍,留给读者们去研究,拿本次楼主遇到的问题来说,我第一眼就看到了这个堆栈的异常情况,但是一直无法解决,其实服务器上的CPU查看线程状态的时候已经发现问题所在了,只是没有第一时间想到会是方法栈的本地变量居多引起的,我当时首先去改了业务的底层逻辑,上层逻辑还是维持不动,在经过了一番尝试无果后,于是利用其他工具进行分析,当然最终也是分析到了这个原因,local variable居多这个信息还是在MAT工具里面得到的结果,业务代码在此之前是没有进行过其他改动的并且可以正常运行的,如果是栈的本地变量居多的话,应该是出现stackoverflow的异常,解决完问题之后,也是了解到,期间也出现了一次OOM。如果我们可以确保底层业务逻辑没有太大问题的时候,可以考虑调整下堆栈的上一层调用,在影响业务范围可控的情况下依次尝试,当然问题会多种多样,关键还是要冷静分析,具体问题具体分析,不要让思维固化,要从多个角度去看待问题,才能解决问题
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 逻辑题15
- 342. 道路与航线(拓扑排序,Dijkstra综合应用)
- 配置BGP的基本示例
- win11 + insightface + pytorch + CUDA + cuDNN 实战安装
- 在VMware上安装Ubuntu:详细教程
- day08_数组进阶
- 【无标题】
- flask 接口处理带有图片和json数据的请求 发送图片到前端的实现
- keepalived知识补充
- Plane Geometry (Junior High School)