Pandas.DataFrame.groupby() 数据分组(数据透视、分类汇总) 详解 含代码 含测试数据集 随Pandas版本持续更新
关于Pandas版本: 本文基于 pandas2.1.2 编写。
关于本文内容更新: 随着pandas的stable版本更迭,本文持续更新,不断完善补充。
Pandas稳定版更新及变动内容整合专题: Pandas稳定版更新及变动迭持续更新。
本节目录
Pandas.DataFrame.groupby()
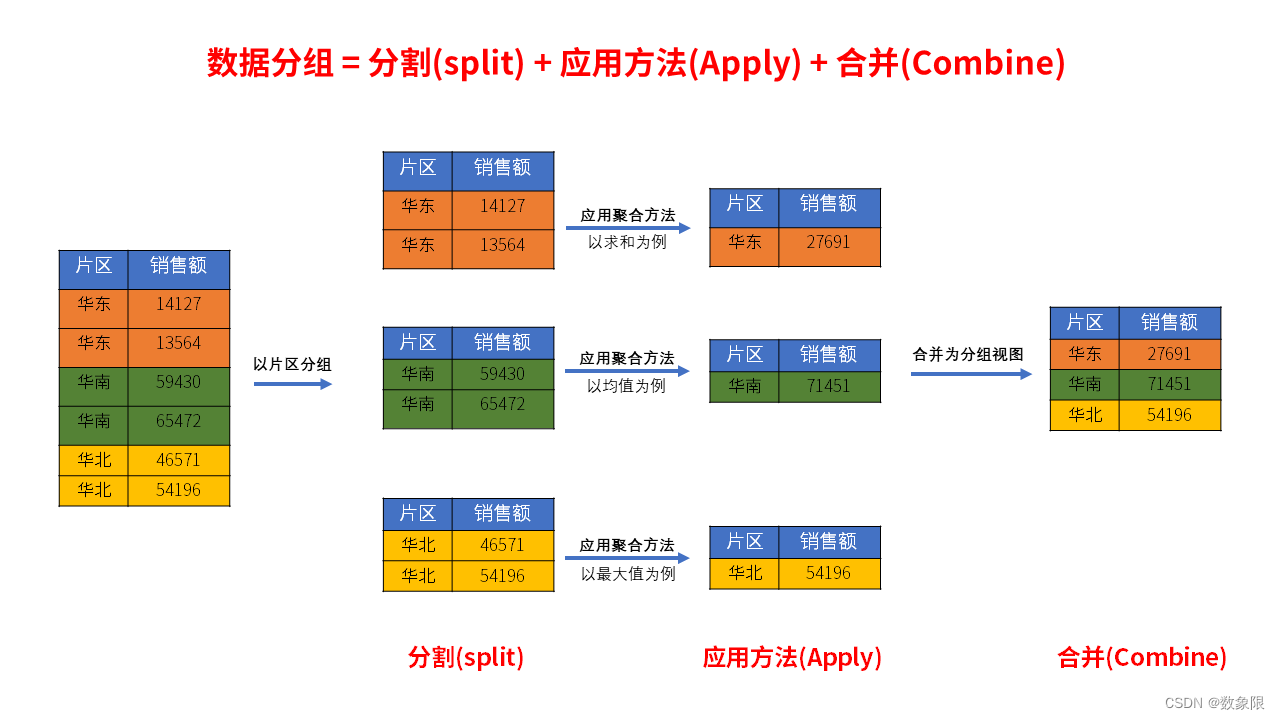
DataFrame.groupby() 方法用于使用映射器或指定的列,对 DataFrame 进行数据分组,可以实现类似Excel的数据透视、分类汇总的效果。
-
DataFrame.groupby()的底层逻辑是:- 1、根据指定的规则(由
by参数指定)分割DataFrame为groupby对象; - 2、应用指定的方法,汇总、聚合被分割的数据。
- 3、应用聚合方法之后,
DataFrame.groupby()会自动的将聚合后的数据合并为新的DataFrame。
?? 注意:
1、数据分割实际上是基于行索引进行的。
2、你指定的分割依据(分组依据)需要尽可能的,和行索引等长。
- 1、根据指定的规则(由
语法:
DataFrame.groupby (by=None, axis=_NoDefault.no_default, level=None, as_index=True, sort=True, group_keys=True, observed=_NoDefault.no_default, dropna=True)
返回值:
- pandas.api.typing.DataFrameGroupBy
- 返回包含分组信息的
groupby对象。
- 返回包含分组信息的
参数说明:
by 指定分组依据
-
**by:**mapping, function, label, pd.Grouper or list of such
by参数用于指定分组的依据(即分割DataFrame的依据):
- label(列名):用于把某列指定为分组依据
- 当某列的数据具有分类特性,指定这个列的列名,作为分组依据
DataFrame。例1
- 当某列的数据具有分类特性,指定这个列的列名,作为分组依据
- mapping(映射):用于直接把行索引的值指定为分组依据
- dict(字典):适用于行索引的值可以拿来做分组(常用于分组名称的重命名) 例3
- 传递一个字典,字典的键是行索引里的可以作为分组的值,字典的值你自定义的分组名;
- 注意!如果只传递字典,你需要提前准备好行索引。并且行索引里的值,应该是可以有效分组的。
- Series(序列):适用于你有一个和
DataFrame行索引等长的Series时 例4- 这个
Series里的值,应该是可以有效分组的; - 这个
Series建议和DataFrame行索引等长; - 如果这个
Series必须和DataFrame行索引不等长,会自动进行对齐(.align()),二者数据量如果差距太大,会产生很多缺失值,造成分组后计算不精准的结果。
- 这个
- dict(字典):适用于行索引的值可以拿来做分组(常用于分组名称的重命名) 例3
- function(函数): 函数将作用于行索引的每个值,并使用处理后的值,作为分组依据。 例5
- pd.Grouper:通常用于按照时间间隔分组,直接作用于行索引 例6
- list of such:多个列构成多维度分组汇总
- 列名列表: 常用于多维度分组汇总,列表里的第1个列名,默认作为顶层行索引,和其他列名构成多层索引。 例7
axis 指定分割方向
-
axis: {0 or ‘index’, 1 or ‘columns’}, default 0
axis参数用于指定分割方向(可以参照此图,了解什么是分割 数据分组流程示意图):- 0 or ‘index’: 默认为按行索引分割。
- 1 or ‘columns’: 按列分割。
? 弃用于 Pandas 2.1.0 :
-
axis=1在Pandas 2.1.0版本标记为弃用。使用以下替代方法实现:- 先 转置 再 分组
frame.T.groupby(...)例8
- 先 转置 再 分组
-
这样做的目的是:使分组后数据尽可能的保持更多的操作性和可读性。
level 指定多层索引的层级编号或层级名称
-
level: int, level name, or sequence of such, default None 例9
如果
DataFrame具有多层索引,可以用level参数指定级别的编号或名称,不能和by参数同时使用。
as_index 排序方法(升序或降序)
-
as_index: bool, default True 例10
as_index参数控制是否将组标签作为索引返回。- 当
as_index=True时,组标签将成为输出DataFrame的索引。 - 当
as_index=False时,组标签不会成为索引,而是返回一个类似SQL风格的输出。
- 当
sort 是否对组名排序
-
sort: bool, default True 例11
sort参数用于控制是否对分组名进行排序,默认sort=True会对组名进行排序。此参数不会影响每个组内观察值的顺序:- True: 对分组名进行排序。
- False: 关闭分组名排序,如果关闭,则组将按其在原始 DataFrame 中的顺序显示,可以获得更高的性能。
📌 改动于 Pandas 2.0.0 :
自 Pandas2.0.0 开始,当使用
有序分类数据进行分组,当sort=False将不再对其进行排序。在之前的版本中(2.0.0 之前),即使设置了
sort=False,对于有序分类,仍然会对分类进行排序。而在 2.0.0 版本中,这个行为发生了变化,即设置sort=False不再影响有序分类的排序,保留原始顺序。这个改动的目的是为了提供更一致的行为,使得在使用
sort=False时,无论分类是否有序,都不再对分类进行排序,从而减少用户的困惑。
group_keys 是否返回组键
-
group_keys: bool, default True
分组的键指的是
groupby对象 各分组的行索引。当使用
groupby调用apply与by参数生成分组结果时, 并且 结果行索引数量 和groupby对象分组数量 不匹配(不匹配则意味着无法汇总),则默认会将groupby对象各分组的行索引 和 结果行索引 组合为多层行索引,以便观察。 例12- 当
group_keys=True时(默认值),分组的键会作为结果的索引。这意味着返回的对象会是一个带有分组键的多层次索引的DataFrame(或者Series,具体取决于你应用groupby的对象是DataFrame还是 Series)。 - 当
group_keys=False时,分组的键不会作为索引,而是返回一个不带有分组键的普通DataFrame(或者Series)。 例12-3
📌 **改动于 Pandas 1.5.0 :
当使用
groupby调用apply与by参数生成分组结果时,并且结果行索引数量 和groupby对象分组数量 不匹配(不匹配则意味着无法汇总),则需要显式指定group_keys是否包含组键。📌 **改动于 Pandas 2.0.0 :
group_keys默认为True。 - 当
observed 只显示观测值或显示所有值
-
observed: bool, default False
观察值是指在实际数据中存在的唯一分类值。当应用
groupby操作时,有时可能会遇到分类分组器中存在的分类值,但在实际数据中并未出现的情况。observed参数允许你控制在分组操作中如何处理这些未观察到的分类值:- True: 只显示分类分组器(groupers)的观察值(observed values),而不显示未观察到的值。
- False: 则显示所有分类分组器的可能值,包括未在实际数据中观察到的值。
? 弃用于 Pandas 2.1.0 :
自2.1.0版本以来已弃用:在panda的未来版本中,默认值将更改为True。
dropna 其他排序置
-
dropna: bool, default True 例13
dropna用于控制groupby对象的行数索引是否可以包含缺失值:- 如果为
True,并且组键包含缺失值,则将 缺失值与行/列一起删除。 - 如果为
False,则保留缺失值。
?? 注意 :
舍弃缺失值的动作,是在分组前完成的,也就是说,在生成
groupby分组对象的时候,就已经没有缺失值了。例13-2 - 如果为
相关方法:
?? 相关方法
Convenience method for frequency conversion and resampling of time series.
示例:
测试文件下载:
本文所涉及的测试文件,如有需要,可在文章顶部的绑定资源处下载。
若发现文件无法下载,应该是资源包有内容更新,正在审核,请稍后再试。或站内私信作者索要。
例1:如果没有指定聚合计算方法,分组结果将是一个 groupby 对象,只能通过 for 循环观察数据内容
- 例1-1、准备演示数据
import pandas as pd
# 读取一个演示文件
df = pd.read_excel("../../../../数据集/团队成员季度销售额.xlsx")
# 观察数据内容
df.sample(5)
| 姓名 | 片区 | 1季度 | 2季度 | 3季度 | 4季度 | year | |
|---|---|---|---|---|---|---|---|
| 18 | 邹小琴 | 华南 | 4038 | 6053 | 4691 | 1178 | 2023 |
| 4 | 左美华 | 华南 | 579 | 2944 | 3408 | 7365 | 2023 |
| 84 | 祝成云 | 华东 | 1186 | 3155 | 1975 | 1922 | 2023 |
| 47 | 紫薇 | 华北 | 1728 | 4802 | 1857 | 6988 | 2023 |
| 40 | 邹博文 | 华北 | 3434 | 5814 | 1334 | 9061 | 2023 |
- 例1-2、用 片区列 分组,但是不传递聚合计算方法
grouped = df.sample(5).groupby(by="片区")
grouped
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000001F9031CB800>
由上面结果可以发现,无法直接观察 GroupBy 对象
- 例1-3、使用
for循环观察分组内容
for group_name, group_data in grouped:
print(f"Group: {group_name}")
print(group_data)
print("\n")
Group: 华中
姓名 片区 1季度 2季度 3季度 4季度 year
73 庄海彬 华中 2534 968 4128 5454 2023
59 卓小珍 华中 3274 5837 3025 7993 2023
Group: 华北
姓名 片区 1季度 2季度 3季度 4季度 year
95 张华丽 华北 4584 1072 3029 8976 2023
48 紫湉 华北 3046 3918 6908 6444 2023
Group: 华南
姓名 片区 1季度 2季度 3季度 4季度 year
97 王娟 华南 661 6784 3660 8621 2023
例2:分组后,指定汇总计算方式,即可自动完成最终的合并过程,并生成新的 DataFrame
- 例2-1、构建演示数据并观察数据内容
import pandas as pd
# 读取一个演示文件
df = pd.read_excel("../../../../数据集/团队成员季度销售额.xlsx")
# 观察数据内容
df.sample(5)
| 姓名 | 片区 | 1季度 | 2季度 | 3季度 | 4季度 | year | |
|---|---|---|---|---|---|---|---|
| 71 | 庄骏 | 华中 | 4713 | 2588 | 6480 | 6224 | 2023 |
| 27 | 邹立文 | 华北 | 1547 | 4927 | 4693 | 8526 | 2023 |
| 38 | 邹凤艳 | 华北 | 2055 | 5330 | 6468 | 7229 | 2023 |
| 0 | 左院梅 | 华南 | 1491 | 1083 | 5000 | 9461 | 2023 |
| 77 | 祝艳斌 | 华东 | 5161 | 1639 | 1291 | 7528 | 2023 |
- 例2-2、以片区列 作为分组依据,只传递一种求和的计算方法。
grouped = df.groupby(by="片区").sum()
grouped
| 姓名 | 1季度 | 2季度 | 3季度 | 4季度 | year | |
|---|---|---|---|---|---|---|
| 片区 | ||||||
| 华东 | 转身,泪倾城筑梦祝艳斌祝艳祝小娟祝仙花祝卫平祝玛拉初祝海英祝成云竹林听雨竹合竹猪哥传说诸子燕... | 53720 | 62152 | 77185 | 85271 | 36414 |
| 华中 | 梓英籽艺子鱼子墨子岚子和子菡资格卓越卓小珍卓向吴追影追忆追梦状之元巍笑吧庄臻庄永奇庄晓运庄... | 86249 | 119934 | 119501 | 153889 | 54621 |
| 华北 | 邹美金邹灵美邹林华邹立文邹黎邹娟利邹杰邹建军邹建华邹吉宏邹积杰邹海利邹贵滨邹广坤邹凤艳邹昌乐... | 72776 | 125467 | 120002 | 186550 | 58667 |
| 华南 | 左院梅左艳艳左薇左娜左美华左梅香左火英左儿左成娟醉霖~棉花糖最终幻想走向幸福邹邹邹子龙邹忠珠... | 60822 | 109654 | 89342 | 143896 | 52598 |
以片区为分组依据,并传递了求和方法后,姓名列因为是字符串,所以相当于拼接。1季度、2季度、3季度、4季度、year等列,完成了求和计算。
- 例2-3、指定计算方法,作为汇总方式,即可观察数据分组后的数据了。
grouped = df.groupby(by="片区").sum()
grouped
| 姓名 | 1季度 | 2季度 | 3季度 | 4季度 | year | |
|---|---|---|---|---|---|---|
| 片区 | ||||||
| 华东 | 转身,泪倾城筑梦祝艳斌祝艳祝小娟祝仙花祝卫平祝玛拉初祝海英祝成云竹林听雨竹合竹猪哥传说诸子燕... | 53720 | 62152 | 77185 | 85271 | 36414 |
| 华中 | 梓英籽艺子鱼子墨子岚子和子菡资格卓越卓小珍卓向吴追影追忆追梦状之元巍笑吧庄臻庄永奇庄晓运庄... | 86249 | 119934 | 119501 | 153889 | 54621 |
| 华北 | 邹美金邹灵美邹林华邹立文邹黎邹娟利邹杰邹建军邹建华邹吉宏邹积杰邹海利邹贵滨邹广坤邹凤艳邹昌乐... | 72776 | 125467 | 120002 | 186550 | 58667 |
| 华南 | 左院梅左艳艳左薇左娜左美华左梅香左火英左儿左成娟醉霖~棉花糖最终幻想走向幸福邹邹邹子龙邹忠珠... | 60822 | 109654 | 89342 | 143896 | 52598 |
- 例2-4、不同的列指定不同的汇总方式,没有指定汇总方式的列,不会出现在汇总结果。例如 姓名列。
grouped = df.groupby(by="片区").agg(
{"1季度": "max", "2季度": "mean", "3季度": "sum", "4季度": "min"} # 最大值 # 平均值 # 总和
) # 最小值
grouped
| 1季度 | 2季度 | 3季度 | 4季度 | |
|---|---|---|---|---|
| 片区 | ||||
| 华东 | 5161 | 3452.888889 | 77185 | 1066 |
| 华中 | 5308 | 4442.000000 | 119501 | 1684 |
| 华北 | 4584 | 4326.448276 | 120002 | 1136 |
| 华南 | 5070 | 4217.461538 | 89342 | 1055 |
- 例2-5、用于分组的分类数据,在完成数据分组后,会作为索引使用(行索引或列名,具体视分组方向而定)
grouped.axes
[Index(['华东', '华中', '华北', '华南'], dtype='object', name='片区'),
Index(['1季度', '2季度', '3季度', '4季度'], dtype='object')]
例3:使用字典数据分组(直接把行索引里的值用字典的方式,指定为分组依据)
- 例3-1、构建演示数据并观察数据内容
import pandas as pd
# 读取一个演示文件
df = pd.read_excel("../../../../数据集/团队成员季度销售额.xlsx")
# 将 片区列,设置为索引
df.set_index("片区", inplace=True)
# 观察数据内容
df.sample(5)
| 姓名 | 1季度 | 2季度 | 3季度 | 4季度 | year | |
|---|---|---|---|---|---|---|
| 片区 | ||||||
| 华东 | 李先锋 | 4057 | 4953 | 6776 | 1723 | 2023 |
| 华南 | 邹小琴 | 4038 | 6053 | 4691 | 1178 | 2023 |
| 华中 | 子墨 | 3393 | 1562 | 3607 | 7273 | 2023 |
| 华北 | 邹娟利 | 3840 | 2815 | 6551 | 3217 | 2023 |
| 华南 | 邹秀珍 | 3205 | 1772 | 1534 | 6995 | 2023 |
- 例3-2、
by参数传入字典,字典的键是DataFrame行索引里的值,字典的值是分组名;
grouped = df.groupby(by={"华东": "东部战区", "华南": "南部战区", "华北": "北部战区", "华中": "中部战区"}).agg(
{"1季度": "max", "2季度": "mean", "3季度": "sum", "4季度": "min"} # 最大值 # 平均值 # 总和
) # 最小值
grouped
| 1季度 | 2季度 | 3季度 | 4季度 | |
|---|---|---|---|---|
| 片区 | ||||
| 东部战区 | 5161 | 3452.888889 | 77185 | 1066 |
| 中部战区 | 5308 | 4442.000000 | 119501 | 1684 |
| 北部战区 | 4584 | 4326.448276 | 120002 | 1136 |
| 南部战区 | 5070 | 4217.461538 | 89342 | 1055 |
例4:使用Series数据分组(用Series替换当前行索引,并使用里面的值作为分组依据)
- 例4-1、构建演示数据并观察数据内容
import pandas as pd
# 读取一个演示文件
df = pd.read_excel("../../../../数据集/团队成员季度销售额.xlsx")
# 观察数据内容
df.sample(5)
| 姓名 | 片区 | 1季度 | 2季度 | 3季度 | 4季度 | year | |
|---|---|---|---|---|---|---|---|
| 60 | 卓向吴 | 华中 | 4713 | 1691 | 2398 | 9270 | 2023 |
| 43 | 自在 | 华北 | 2354 | 4605 | 5928 | 8614 | 2023 |
| 63 | 追梦 | 华中 | 2689 | 6790 | 4247 | 7637 | 2023 |
| 17 | 邹秀珍 | 华南 | 3205 | 1772 | 1534 | 6995 | 2023 |
| 42 | 自在小英 | 华北 | 2100 | 2230 | 3409 | 3572 | 2023 |
- 例4-2、使用Series,构建数据分组。(为了方便,我们把片区列拿过来作为Series做演示)
# 提取片区列作为Series
s = df["片区"].copy(deep=True)
# 使用Series,构建数据分组
grouped = df.groupby(by=s).max()
grouped
| 姓名 | 片区 | 1季度 | 2季度 | 3季度 | 4季度 | year | |
|---|---|---|---|---|---|---|---|
| 片区 | |||||||
| 华东 | 转身,泪倾城 | 华东 | 5161 | 6753 | 6776 | 9284 | 2023 |
| 华中 | 邹世军 | 华中 | 5308 | 7377 | 7204 | 9270 | 2023 |
| 华北 | 邹黎 | 华北 | 4584 | 7421 | 6945 | 9230 | 2023 |
| 华南 | 醉霖~棉花糖 | 华南 | 5070 | 7412 | 5971 | 9461 | 2023 |
- 例5-1、构建演示数据并观察数据内容
import pandas as pd
# 读取一个演示文件
df = pd.read_excel("../../../../数据集/团队成员季度销售额.xlsx")
# 将 片区列,设置为索引
# df.set_index('片区',inplace=True)
# 观察数据内容
df.sample(5)
| 姓名 | 片区 | 1季度 | 2季度 | 3季度 | 4季度 | year | |
|---|---|---|---|---|---|---|---|
| 38 | 邹凤艳 | 华北 | 2055 | 5330 | 6468 | 7229 | 2023 |
| 35 | 邹海利 | 华北 | 3875 | 5799 | 4057 | 8344 | 2023 |
| 83 | 祝海英 | 华东 | 1018 | 1430 | 4845 | 7155 | 2023 |
| 92 | 邹世军 | 华中 | 4343 | 4866 | 2743 | 7617 | 2023 |
| 11 | 走向幸福 | 华南 | 4312 | 2189 | 4431 | 7493 | 2023 |
- 例5-1、当前行索引是自然索引,我想按照行索引的单数、双数进行分组,可以这样做:
# 定义区分单数双数的函数
def rename_index(index):
if index % 2 == 0:
return "双数"
else:
return "单数"
# 应用这个函数,处理行索引进行分组
grouped = df.sample(12).groupby(by=rename_index)
# 查看group对象里的内容
for group_name, group_data in grouped:
print(f"Group: {group_name}")
print(group_data)
print("\n")
Group: 单数
姓名 片区 1季度 2季度 3季度 4季度 year
37 邹广坤 华北 3015 5912 2120 3750 2023
77 祝艳斌 华东 5161 1639 1291 7528 2023
97 王娟 华南 661 6784 3660 8621 2023
89 诸子燕 华东 2454 1824 3306 4198 2023
79 祝小娟 华东 4419 6753 2838 1066 2023
11 走向幸福 华南 4312 2189 4431 7493 2023
63 追梦 华中 2689 6790 4247 7637 2023
Group: 双数
姓名 片区 1季度 2季度 3季度 4季度 year
34 邹积杰 华北 2175 4902 4874 3110 2023
92 邹世军 华中 4343 4866 2743 7617 2023
8 左成娟 华南 1747 5823 1480 7025 2023
76 筑梦 华东 1856 3905 5808 6265 2023
98 刘贤 华东 3960 6437 3148 1517 2023
从上面这个结果可以发现,函数处理并没有影响到 groupby 对象
- 例5-2、函数处理行索引的结果,会展现在汇总计算后,合并的新
DataFrame里
# 给分组对象一个计算方式,完成最终数据合并,并观察
grouped.max()
| 姓名 | 片区 | 1季度 | 2季度 | 3季度 | 4季度 | year | |
|---|---|---|---|---|---|---|---|
| 单数 | 邹广坤 | 华南 | 5161 | 6790 | 4431 | 8621 | 2023 |
| 双数 | 邹积杰 | 华南 | 4343 | 6437 | 5808 | 7617 | 2023 |
从上面可以发现,如果 by 参数传递了函数,被修改的 行索引 只会作为分组依据、和分组名称,出现在汇总计算后,合并的新 DataFrame 里。
- 例6-1、构建演示数据并观察数据内容
from datetime import datetime
import numpy as np
import pandas as pd
# 创建一个包含时间序列的DataFrame
date_rng = pd.date_range(start="2022-01-01", end="2022-01-19", freq="D")
df = pd.DataFrame(date_rng, columns=["date"])
# 添加一列随机数值
df["value"] = np.random.randn(len(date_rng))
# 观察数据内容
df
| date | value | |
|---|---|---|
| 0 | 2022-01-01 | 0.632771 |
| 1 | 2022-01-02 | 1.218292 |
| 2 | 2022-01-03 | -0.864251 |
| 3 | 2022-01-04 | 0.628204 |
| 4 | 2022-01-05 | -0.625454 |
| 5 | 2022-01-06 | 1.021081 |
| 6 | 2022-01-07 | 0.685509 |
| 7 | 2022-01-08 | 1.096754 |
| 8 | 2022-01-09 | -1.131979 |
| 9 | 2022-01-10 | 0.384067 |
| 10 | 2022-01-11 | 0.447377 |
| 11 | 2022-01-12 | 0.005861 |
| 12 | 2022-01-13 | 1.126507 |
| 13 | 2022-01-14 | -0.153360 |
| 14 | 2022-01-15 | 0.447708 |
| 15 | 2022-01-16 | 0.470841 |
| 16 | 2022-01-17 | -1.143815 |
| 17 | 2022-01-18 | -0.407859 |
| 18 | 2022-01-19 | 0.308274 |
- 例6-2、构建以‘周’为周期的grouper对象,并观察其数据内容
# 创建grouper对象
grouper = pd.Grouper(key="date", freq="W")
grouper
TimeGrouper(key='date', freq=<Week: weekday=6>, axis=0, sort=True, dropna=True, closed='right', label='right', how='mean', convention='e', origin='start_day')
- 例6-3、按周进行分组,求每周的均值
# 按轴分组,并计算每组的均值
result = df.groupby(grouper).mean()
result
| value | |
|---|---|
| date | |
| 2022-01-02 | 0.925532 |
| 2022-01-09 | 0.115695 |
| 2022-01-16 | 0.389857 |
| 2022-01-23 | -0.414467 |
例7:by参数传递列名列表,构成多层索引,作为多维度的数据汇总
- 例7-1、构建演示数据并观察数据内容
import pandas as pd
# 读取一个演示文件
df = pd.read_excel("../../../../数据集/团队成员日销售额.xlsx")
# 只保留需要的列
df = df[["职级", "片区", "业绩"]]
# 观察数据内容
df.sample(5)
| 职级 | 片区 | 业绩 | |
|---|---|---|---|
| 82 | 经理 | 华中 | 14494.9 |
| 14 | 经理 | 华南 | 27318.5 |
| 67 | 组长 | 华东 | 843.3 |
| 22 | 经理 | 华南 | 853.8 |
| 43 | 组长 | 华北 | 545.8 |
- 例7-2、传递列名列表,多维度数据分组汇总。观察各职级销售人员,在不同地区的销售表现
df.groupby(by=["职级", "片区"]).sum()
| 业绩 | ||
|---|---|---|
| 职级 | 片区 | |
| 组长 | 华东 | 17526.0 |
| 华中 | 4043.1 | |
| 华北 | 6524.8 | |
| 经理 | 华东 | 148805.5 |
| 华中 | 125646.0 | |
| 华北 | 58211.8 | |
| 华南 | 1067600.6 | |
| 销售员 | 华东 | 7896.9 |
| 华中 | 11233.6 | |
| 华北 | 1772.2 | |
| 华南 | 8281.1 |
- 例8-1、读取演示数据并观察内容
import pandas as pd
# 读取一个演示文件
df = pd.read_excel("../../../../数据集/团队成员日销售额_用于转置.xlsx")
# 观察数据内容
df
| Unnamed: 0 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ... | 90 | 91 | 92 | 93 | 94 | 95 | 96 | 97 | 98 | 99 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 职级 | 销售员 | 经理 | 经理 | 销售员 | 销售员 | 销售员 | 销售员 | 销售员 | 销售员 | ... | 经理 | 经理 | 销售员 | 组长 | 销售员 | 销售员 | 销售员 | 经理 | 销售员 | 销售员 |
| 1 | 片区 | 华南 | 华南 | 华南 | 华南 | 华南 | 华南 | 华南 | 华南 | 华南 | ... | 华中 | 华中 | 华中 | 华中 | 华中 | 华中 | 华中 | 华中 | 华中 | 华中 |
| 2 | 业绩 | 523.9 | 16647.5 | 825896.9 | 1051.1 | 672.5 | 1542.2 | 540.9 | 752.5 | 585 | ... | 18261 | 8089 | 6825 | 1112.9 | 888.7 | 721.3 | 941.3 | 17740.2 | 692.1 | 1165.2 |
3 rows × 101 columns
可以发现,在这个演示数据中,如果需要分组,则需要 axis=1 , 但是这不符合Pandas新版本特性。
- 例8-2、先转置,再用片区分组
df.T.groupby(by=1).max()
| 0 | 2 | |
|---|---|---|
| 1 | ||
| 华东 | 销售员 | 99327.4 |
| 华中 | 销售员 | 18261 |
| 华北 | 销售员 | 9388 |
| 华南 | 销售员 | 825896.9 |
| 片区 | 职级 | 业绩 |
分组完毕,by=1 是因为片区的哪一列,此时列名就是1
例9:多层索引需要使用 level 参数传递层级信息指定分组依据
- 例9-1、读取演示数据,构建多层索引,观察数据内容
import pandas as pd
# 读取一个演示文件
df = pd.read_excel("../../../../数据集/团队成员日销售额.xlsx")
# 只保留需要的列
df = df[["职级", "片区", "业绩"]]
# 构建多层索引
df.set_index(["片区", "职级"], inplace=True)
# 观察数据内容
df.sample(5)
| 业绩 | ||
|---|---|---|
| 片区 | 职级 | |
| 华中 | 经理 | 1459.4 |
| 华南 | 销售员 | 540.9 |
| 销售员 | 773.4 | |
| 华中 | 经理 | 744.0 |
| 组长 | 1304.8 |
- 例9-2、 只使用片区作为分组依据,则只需要传递层级编号,或层级名称即可。
df.groupby(level="片区").sum()
| 业绩 | |
|---|---|
| 片区 | |
| 华东 | 174228.4 |
| 华中 | 140922.7 |
| 华北 | 66508.8 |
| 华南 | 1075881.7 |
df.groupby(level=0).sum()
| 业绩 | |
|---|---|
| 片区 | |
| 华东 | 174228.4 |
| 华中 | 140922.7 |
| 华北 | 66508.8 |
| 华南 | 1075881.7 |
- 例9-3、 如果需要使用多列内容,使用列表传递层级编号或层级名称即可(可以混用)
df.groupby(level=[0, "职级"]).sum()
| 业绩 | ||
|---|---|---|
| 片区 | 职级 | |
| 华东 | 组长 | 17526.0 |
| 经理 | 148805.5 | |
| 销售员 | 7896.9 | |
| 华中 | 组长 | 4043.1 |
| 经理 | 125646.0 | |
| 销售员 | 11233.6 | |
| 华北 | 组长 | 6524.8 |
| 经理 | 58211.8 | |
| 销售员 | 1772.2 | |
| 华南 | 经理 | 1067600.6 |
| 销售员 | 8281.1 |
例10:分组名称不再作为索引,使用SQL风格展示分组后的数据
import pandas as pd
# 读取一个演示文件
df = pd.read_excel("../../../../数据集/团队成员日销售额.xlsx")
# 只保留需要的列
df = df[["职级", "片区", "业绩"]]
df
# 用片区进行分组,并关闭索引返回
df.groupby(by="片区", as_index=False).max()
| 片区 | 职级 | 业绩 | |
|---|---|---|---|
| 0 | 华东 | 销售员 | 99327.4 |
| 1 | 华中 | 销售员 | 18261.0 |
| 2 | 华北 | 销售员 | 9388.0 |
| 3 | 华南 | 销售员 | 825896.9 |
由上面结果可以发现,片区列,没有再作为行索引。
- 例11-1、默认情况下,数据分组后输出的
DataFrame会开启组名排序
import pandas as pd
# 构建演示数据
df = pd.DataFrame({"cat": ["b", "b", "a", "a"], "value": [1, 3, 2, 4]})
# 用cat列构建分组,保持分组名排序开启,
grouped = df.groupby(by="cat").mean()
grouped
| value | |
|---|---|
| cat | |
| a | 3.0 |
| b | 2.0 |
- 例11-2、 当
sort=False数据分组后输出的DataFrame不再对组名排序
# 用cat列构建分组,关闭分组名排序
grouped2 = df.groupby(by="cat", sort=False).mean()
grouped2
| value | |
|---|---|
| cat | |
| b | 2.0 |
| a | 3.0 |
例12:应用apply,如果结果行数 > 分组数量,则无法完成汇总,各分组的行索引(组键)会和分组名组成多层索引
- 例12-1、首先来观察以下,各个分组的行索引
import pandas as pd
# 构建演示数据
df = pd.DataFrame({"cat": ["b", "b", "a", "a"], "value": [1, 3, 2, 4]})
# 用cat列构建分组,保持分组名排序开启,
grouped = df.groupby(by="cat")
# 打印每个组的内容
for name, group in grouped:
print(f"Group {name}:")
print(group)
print("\n")
Group a:
cat value
2 a 2
3 a 4
Group b:
cat value
0 b 1
1 b 3
留意上面结果,a和b两个分组的行索引2、3、0、1。
- 例12-2、当 调用
apply,但是结果行数 > 分组数量时,会产生由分组名、各分组行索引构成的多层索引,
import pandas as pd
# 构建演示数据
df = pd.DataFrame({"cat": ["b", "b", "a", "a"], "value": [1, 3, 2, 4]})
# df['cat'] = df['cat'].astype('category')
# 用cat列构建分组,保持分组名排序开启,
grouped = df.groupby(by="cat").apply(lambda x: x)
grouped
| cat | value | ||
|---|---|---|---|
| cat | |||
| a | 2 | a | 2 |
| 3 | a | 4 | |
| b | 0 | b | 1 |
| 1 | b | 3 |
- 例12-3、 当
group_keys=False时,分组的键不会作为索引,而是返回一个不带有分组键的普通DataFrame(或者Series)。
import pandas as pd
# 构建演示数据
df = pd.DataFrame({"cat": ["b", "b", "a", "a"], "value": [1, 3, 2, 4]})
# df['cat'] = df['cat'].astype('category')
# 用cat列构建分组,保持分组名排序开启,
grouped = df.groupby(by="cat", group_keys=False).apply(lambda x: x)
grouped
| cat | value | |
|---|---|---|
| 0 | b | 1 |
| 1 | b | 3 |
| 2 | a | 2 |
| 3 | a | 4 |
- 例12-4、再来看一下,正常应该是什么样的
import pandas as pd
# 构建演示数据
df = pd.DataFrame({"cat": ["b", "b", "a", "a"], "value": [1, 3, 2, 4]})
# df['cat'] = df['cat'].astype('category')
# 用cat列构建分组,保持分组名排序开启,
grouped = df.groupby(by="cat").apply(lambda x: x.mean())
grouped
| value | |
|---|---|
| cat | |
| a | 3.0 |
| b | 2.0 |
例13:组键(分组名、或可理解为结果的行索引、也可以理解为各分组的行索引)缺失值处理
- 例13-1 构建演示数据并观察
import pandas as pd
# 构建演示数据
l = [["a", 12, 12], [None, 12.3, 33.0], ["b", 12.3, 123], ["a", 1, 1]]
df = pd.DataFrame(l, columns=["a", "b", "c"])
df
| a | b | c | |
|---|---|---|---|
| 0 | a | 12.0 | 12.0 |
| 1 | None | 12.3 | 33.0 |
| 2 | b | 12.3 | 123.0 |
| 3 | a | 1.0 | 1.0 |
- 例13-2 在分组完成时,默认就已经舍弃了缺失值
grouped = df.groupby(by="a")
# 打印每个组的内容
for name, group in grouped:
print(f"Group {name}:")
print(group)
print("\n")
Group a:
a b c
0 a 12.0 12.0
3 a 1.0 1.0
Group b:
a b c
2 b 12.3 123.0
由上面结果可以发现,当完成分组的时候,就已经没有缺失值了,这一步发生在合并每个分组产生结果之前。
- 例13-3
dropna=True可以保留缺失值
grouped = df.groupby(by="a", dropna=False).mean()
grouped
| b | c | |
|---|---|---|
| a | ||
| a | 6.5 | 6.5 |
| b | 12.3 | 123.0 |
| NaN | 12.3 | 33.0 |
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 电力电子技术
- 【HarmonyOS开发】OpenHarmony如何实现?次开发,多端部署
- (delphi11最新学习资料) Object Pascal 学习笔记---第2章第五节(日期和时间)
- 武侠小说中的AI思想探析与未来启示
- 学生成绩管理系统半成品
- .h5文件简介
- Docker与微服务:构建和部署微服务架构的完整指南
- 算法通关村第十九关-黄金挑战动态规划
- 保留几位小数的函数、全排列函数、?反斜杠的作用、二进制、八进制、十六进制的输入?、求三角形面积的三种方法、求平方根、N次方如何表示
- Unity-.meta文件