06--视图、索引、事务、权限
1、视图(view)
1.1 什么是视图
视图是一种根据查询(也就是SELECT表达式)定义的数据库对象,用于获取想要看到和使用的局部数据
视图有时也被成为“虚拟表”。
视图可以被用来从常规表(称为“基表”)或其他视图中查询数据。
相对于从基表中直接获取数据,视图有以下好处:
- 访问数据变得简单
- 可被用来对不同用户显示不同的表的内容
用来协助适配表的结构以适应前端现有的应用程序
视图作用:
- 提高检索效率
- 隐藏表的实现细节【面向视图检索】
1.2 创建视图
案例:查询工资等级为3级的员工
-- 查询工资等级为3级的员工
select e.*,g3.grade from emp e,(select * from salgrade where grade = 3) g3 where e.sal > g3.losal and e.sal < g3.hisal;
-- 创建视图
create view grade3 as select e.*,g3.grade from emp e,(select * from salgrade where grade = 3) g3 where e.sal > g3.losal and e.sal < g3.hisal;
select * from grade3;为什么使用视图?
因为需求决定以上语句需要在多个地方使用,如果频繁的拷贝以上代码,会给维护带来成本,视图可以解决这个问题。
注意:只有DQL语句才能以视图对象的方式创建出来。
对 视图进行增删改查,会影响到原表数据。(通过视图影响原表数据的,不是直接操作的原表)
可以对视图进行CRUD操作。
1.3 删除视图
-- 删除视图
drop view geade3;
drop view if exists grade3;2、索引(index)
2.1 索引原理
索引被用来快速找出一个列上某一特定值的记录。
没有索引,MySQL不得不首先以第一条记录开始,然后读完整个表直到它找出相关的行。表越大,花费时间越多。对于一个有序字段,可以运用二分查找(Binary Search),这就是为什么性能能得到本质上的提高。MYISAM引擎和INNODB引擎都是用B+Tree作为索引结构(主键,unique 都会默认的添加索引)
2.2 索引的应用
2.2.1 创建索引
什么时候需要给字段添加索引?
- 表中该字段中的数据量庞大
- 经常被检索,经常出现在where子句中的字段
- 经常被DML操作的字段不建议添加索引
-- 创建索引
create index 索引名 on 表名(字段名);
-- 创建索引
create index stuIndex on stu(age);2.2.2 查看索引
show index from stu;2.2.3 删除索引
-- 删除索引
drop index stuIndex on stu;
alter table stu drop index stuIndex;2.3 查看SQL语句的执行
explain select name,age from stu where age = 18;2.4 索引分类
B树索引、普通索引、主键索引、唯一键索引、空间索引、全文索引。
单一索引:给单个字段添加索引
复合索引: 给多个字段联合起来添加1个索引
主键索引:主键上会自动添加索引
唯一索引:有unique约束的字段上会自动添加索引
2.5 索引失效
索引什么时候失效?
select name from stu where name like '%宇%';
模糊查询的时候,第一个通配符使用的是%,这个时候索引是失效的。
索引作用: 提高查询的效率
一般用于数据量比较大的情况下我们建立索引,如果数据量太小也必要去建立索引
3、事务(transaction)
3.1 事务概述
一个事务是一个完整的业务逻辑单元,不可再分。
事务可以保证多个操作原子性,要么全成功,要么全失败。对于数据库来说事务保证批量的DML要么全成功,要么全失败。
事务具有四个特征ACID
| 特征 | 介绍 | |
| A | 原子性(Atomicity) | 整个事务中的所有操作,必须作为一个单元全部完成(或全部取消)。 |
| C | 一致性(Consistency) | 在事务开始之前与结束之后,数据库都保持一致状态。 |
| I | 隔离性(Isolation) | 一个事务不会影响其他事务的运行。 |
| D | 持久性(Durability) | 在事务完成以后,该事务对数据库所作的更改将持久地保存在数据库之中,并不会被回滚。 |
事务中存在一些概念:
a) 事务(Transaction):一批操作(一组DML)
b) 开启事务(Start Transaction)
c) 回滚事务(rollback)
d) 提交事务(commit)
e) 添加保存点(savepoint)
注意:rollback,或者commit后事务就结束了。
只有DML语句支持事务。
3.2 事务的提交与回滚
3.2.1 测试1
1) 创建表
create table user(
id int (11) primary key not null auto_increment ,
username varchar(30),
password varchar(30)
);2) 查询表中数据

3) 开启事务start transaction;

4) 插入数据
insert into user (username,password) values ('zhangsan','123');
5) 查看数据
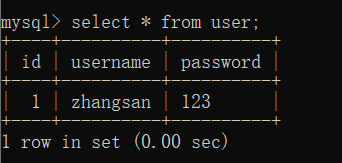
7) 修改数据

8) 查看数据
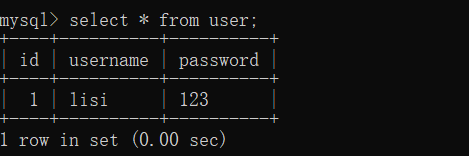
9) 回滚事务

10) 查看数据
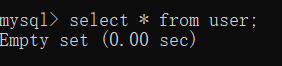
3.2.2 测试2
1) 创建表
create table user(
id int (11) primary key not null auto_increment ,
username varchar(30),
password varchar(30)
);2) 窗口1查询表中数据
3) 窗口2查询表中数据
4) 窗口1开启事务start transaction;
5) 窗口1插入数据
insert into user (username,password) values ('zhangsan','123');
6) 窗口1查看数据
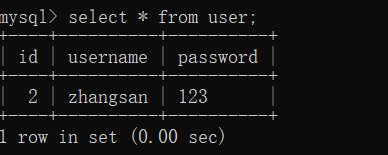
7) 窗口2查看数据
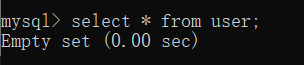
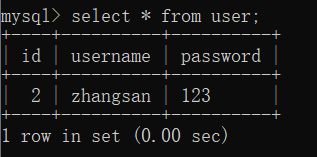
8) 窗口1提交事务

9) 窗口1查看数据
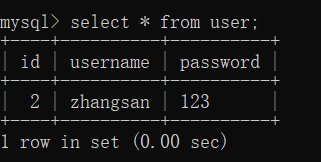
10) 窗口2查看数据
3.3 事务的隔离级别
3.3.1 隔离级别
事务的隔离级别决定了事务之间可见的级别。
当多个客户端并发地访问同一个表时,可能出现下面的一致性问题:
脏读取(Dirty Read)
一个事务开始读取了某行数据,但是另外一个事务已经更新了此数据但没有能够及时提交,这就出现了脏读取。
不可重复读(Non-repeatable Read)
在同一个事务中,同一个读操作对同一个数据的前后两次读取产生了不同的结果,这就是不可重复读。
幻像读(Phantom Read)
幻像读是指在同一个事务中以前没有的行,由于其他事务的提交而出现的新行。
3.3.2 四个隔离级别
InnoDB 实现了四个隔离级别,用以控制事务所做的修改,并将修改通告至其它并发的事务:
读未提交(READ UMCOMMITTED)
允许一个事务可以看到其他事务未提交的修改。
读已提交(READ COMMITTED)
允许一个事务只能看到其他事务已经提交的修改,未提交的修改是不可见的。
可重复读(REPEATABLE READ)
确保如果在一个事务中执行两次相同的SELECT语句,都能得到相同的结果,不管其他事务是否提交这些修改。(银行总账)
该隔离级别为InnoDB的缺省设置。
串行化(SERIALIZABLE)【序列化】
将一个事务与其他事务完全地隔离。
oracle数据库默认的隔离级别是:读已提交。
mysql数据库默认的隔离级别是:可重复读。
3.3.3 隔离级别与一致性问题的关系
| 隔离级别 | 脏读数据 | 不可重复读 | 幻象读 |
| 读未提交 | 可能 | 可能 | 可能 |
| 读已提交 | 不可能 | 可能 | 可能 |
| 可重复度 | 不可能 | 不可能 | 对InnoDB不可能 |
| 串行化 | 不可能 | 不可能 | 不可能 |
4、用户权限DCL
4.1 新建用户
-- 查询用户
select * from mysql.user;
-- 新建用户
create user 'sanshi'@'localhost' identified by '123456';
create user 'sanshi'@'%' identified by '123456'; -- % 代表任意ip新创建的用户可以登录但是只可以看见一个库 information_schema
4.2 用户授权
命令详解
*.*表示所有数据库下的所有表
%代表任何ip
权限主要包括:
create:创建新的数据库或表
alter:修改数据库的表
drop:删除数据库/表
insert:添加表数据
delete:删除表数据
update:更新表数据
select:查询表数据
index:创建/删除索引
all:允许任何操作
usage:只允许登录
-- 添加权限
grant select on *.* to 'sanshi'@'localhost';
-- 语法
grant 权限1,权限2 on 数据库名.表名 to '用户名'@'ip';4.3 回收权限
-- 回收权限
revoke select on *.* from 'sanshi'@'localhost';
revoke 权限1,权限2 on 数据库名.表名 from 用户;4.4 删除用户
-- 删除用户
drop user '用户名'@'主机名';
-- 删除用户
drop user 'sanshi'@'%' ;4.5 修改密码
-- 使用以下命令进行修改密码
set password for 'root'@'localhost' = password('abc');
-- 修改已登录用户密码
set password=password('新密码');5、数据导入导出
使用第三方工具
5.1 数据备份--导出
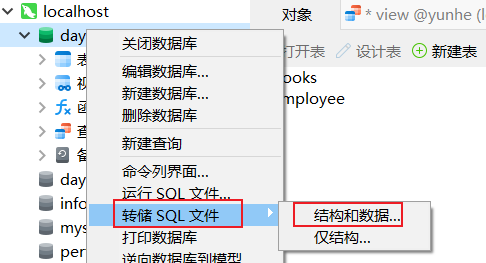
5.2 数据导入
新建数据库
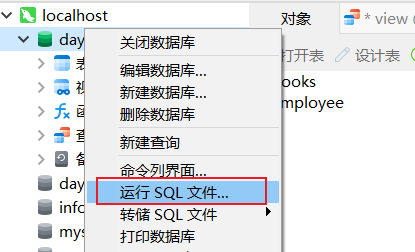
6、数据库三大范式
第一范式:数据库表中不能出现重复记录,每个字段是原子性的不能再分,每一行必须唯一,也就是每个表必须有主键,这是我们数据库设计的最基本要求。
第二范式:是建立在第一范式基础上的,另外要求所有非主键字段完全依赖主键,不能产生部分依赖
第三范式:建立在第二范式基础上的,非主键字段不能传递依赖于主键字段。(不要产生传递依赖)
第一范式:任何一张表都应该有主键,并且每一个字段原子性不可再分。
第二范式:建立在第一范式的基础之上,所有非主键字段完全依赖主键,不能产生部分依赖。
第三范式:建立在第二范式的基础之上,所有非主键字段直接依赖主键,不能产生传递依赖。
7、横表/纵表
7.1 纵表/横表概述
纵表:
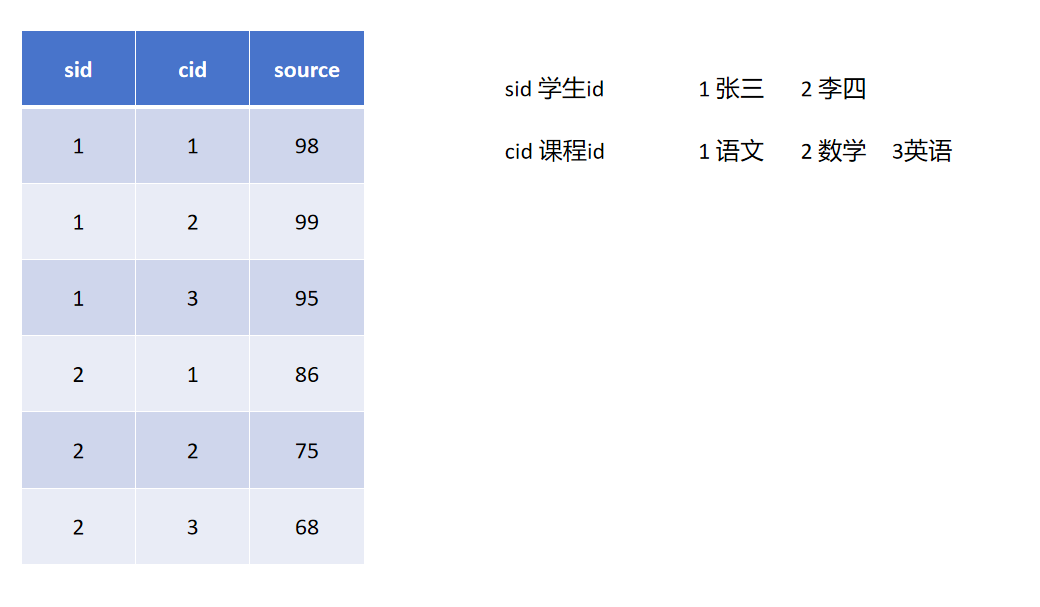
纵表
优点:如果现在要给这个表加一个字段,只需要添加一些记录。
缺点:数据描述不是很清晰,而且会造成数据库数据很多。另如果需要分组统计,要先group by,较繁琐。
横表:
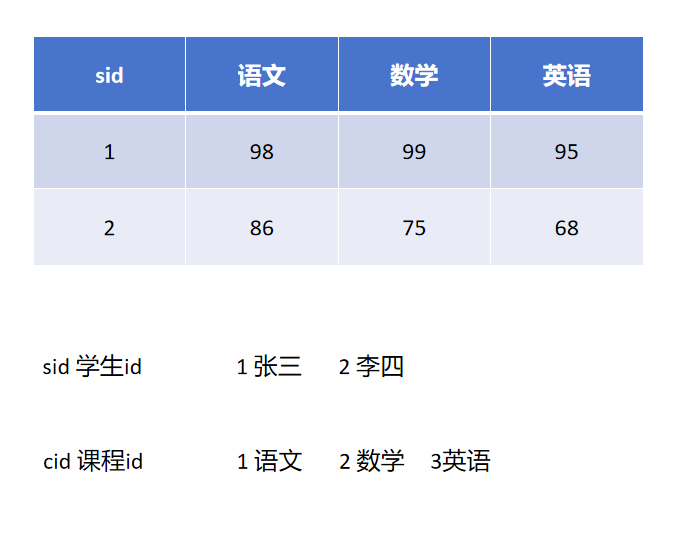
横表
优点:一行表示了一个实体记录,清晰可见,一目了然。
缺点:如果现在要给这个表加一个字段,那么就必须重建表结构。
7.2 纵表转横表
有如下纵表
create table proper(
student_name varchar(20),
course_name varchar(20),
score double
);
INSERT INTO `proper`(`student_name`, `course_name`, `score`) VALUES ('张三', '语文', 67);
INSERT INTO `proper`(`student_name`, `course_name`, `score`) VALUES ('张三', '数学', 78);
INSERT INTO `proper`(`student_name`, `course_name`, `score`) VALUES ('李四', '语文', 90);
INSERT INTO `proper`(`student_name`, `course_name`, `score`) VALUES ('李四', '英语', 89);将其转为横表
select
-- 第一列显示的字段
p.student_name,
-- 当course_name的名字是‘语文’,把对应的成绩显示
sum(case p.course_name when '语文' then p.score end ) as 语文,
sum(case p.course_name when '数学' then p.score end ) as 数学,
sum(case p.course_name when '英语' then p.score end ) as 英语
from proper p
-- 对名字进行分组
group by p.student_name7.3 横表转纵表
有如下横表
create table score_horizontal (
student_name varchar(20),
chinese varchar(20),
math varchar(20),
english varchar(20)
);
INSERT INTO `score_horizontal`(`student_name`, `chinese`, `math`, `english`) VALUES ('张三', '67', '78', NULL);
INSERT INTO `score_horizontal`(`student_name`, `chinese`, `math`, `english`) VALUES ('李四', '90', NULL, '89');将其横表转为纵表
select s.student_name,'chinese' as 科目,s.chinese as 成绩
from score_horizontal s
union all
select s.student_name,'math' as 科目,s.math as 成绩
from score_horizontal s
union all
select s.student_name,'english' as 科目,s.english as 成绩
from score_horizontal s;本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 用 AI 定制龙年红包封面保姆级教程
- item_get-1688商品详情在跨境电商中的品牌形象塑造与传播
- 01 Redis的特性
- Git 命令使用总结
- 如何在 SwiftUI 中实现音频图表
- C++初阶 | [八] (上) vector
- Pandas中concat的用法
- “豚门”、“吗喽”,为啥品牌宣传瞄上网红动物?
- Kotlin(十六) 高阶函数的简单应用
- 什么是链路聚合?怎么配置链路聚合?配置LACP模式的链路聚合示例(交换机之间直连)