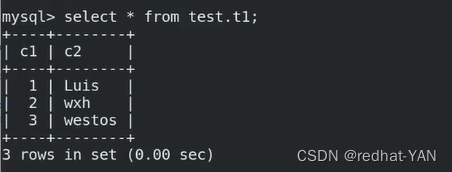
Mysql从入门到精通
系列文章目录
MySQL集群及高可用-mysql主从复制1Mysql从入门到精通
- 系列文章目录
- 一、mysql主从复制
- 二、mysql主从配置server1(主库master)
- 三、mysql主从配置server2(从库,slave)
- 四、测试
- 五、主机重启服务后,二进制日志文件变化
- 六、mysldump导入(备份)书库工具
- 七、主从复制两种形式
- 八、a->b->c形势的主从复制配置
- 九、测试a->b->c主从形势
- 十、主从意义与缺点
- 系列文章目录
- 一、 Mysql集群-Gtid官方文档
- 二、 主从架构与gtid架构对比
- 三、配置gtid(一组两从架构)
- 四、验证
- 系列文章目录
- 一、重启服务器需要检查的模块
- 二、主从工作原理
- 三、ok过程详情细节(半同步模式)原理
- 四、半同步模式5.7以前对比(AFTER_COMMIT与AFTER_SYNC)
- 系列文章目录
- 一、Mysql集群-半同步模式官方文档
- 二、Mysql集群-半同步模式配置
- 三、测试
- 系列文章目录
- 一、Mysql集群-并行复制(sql线程的优化)
- 二、Mysql集群-并行复制的配置
- 系列文章目录
- 一、Mysql集群-延迟复制
- 二、Mysql集群-延迟复制配置
- 系列文章目录
- 一、Mysql集群-慢查询
- 二、慢查询配置
- 三、测试
- 系列文章目录
- 一、Mysql集群-主复制
- 二、容错机制(组模式)
- 三、配置多主复制
- 四、测试
- 五、Mysql路由(通过连接不同端口实现路由)(读写分离)
- 六、测试
- 七、总结
- 系列文章目录
- 一、Mysql集群-高可用MHA
- 二、实验环境准备
- 三、Gtid模式一主两从
- 四、MHA配置
- 五、配置主配置文件
- 六、高可用手动切换
- 七、自动切换
- 八、书写脚本让perl程序一直监控数据库实例
一、mysql主从复制
学习的是5.7版本的Mysql
二、mysql主从配置server1(主库master)
按照官网需要编辑my.cnf
除了指定名称也有激活二进制的功能
server-id必须正整数
vim /etc/my.cnf

启动数据库脚本/etc/init.d/mysqld start
mysql -p 进入数据库

File:二进制日志的名称
二进制日志记录的是数据库的变更
每次变更都有Position的号与二进制日志标识
Binlog_Do_DB允许复制那个库
Binlog_Ignore_DB不允许复制那个库
Executed_Gtid_Set是否激活Gtid

数据库是源码编译的
数据所在位置
/usr/local/mysql/data/
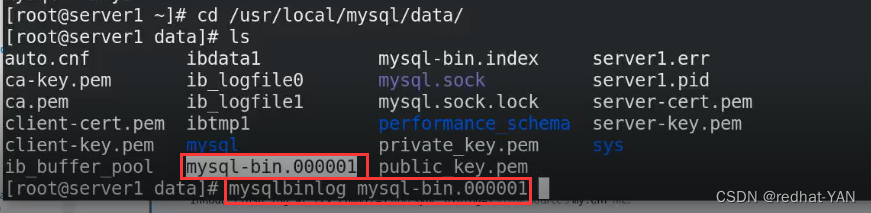
mysql的二进制日志有专属的命令查看
mysqlbinlog 二进制日志

授权
*.*表示所有库所有表(第一个*表示所有库,第二个表示所有表)
TO是给谁,repl用户,@是分隔符,%表示所有主机除了localhost
IDENTIFIED BY ‘密码’ 设置密码

repl用户用于复制,其余没有权限,你只授予了REPLICATION权限
8.0以后必须要先建立用户后授权

数据库变更了,Position号也变更了
三、mysql主从配置server2(从库,slave)
server2没有mysql,把server1的mysql拷贝过去
server1:
/etc/init.d/mysqld stop
cd /usr/local/
scp -r mysql/ server2:/usr/local/
cd /etc
scp my.cnf server2:/etc/
cd /etc/init.d/
scp mysqld server2:/etc/init.d/
server2
编辑主配置文件,salve不需要激活二进制日志
server-id必须递归式增长,和主库不一样,必须有不一样的id

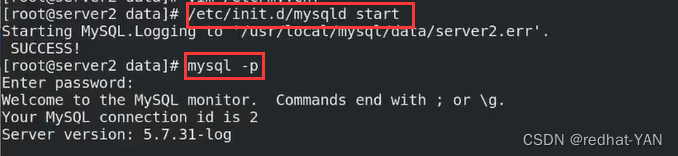
启动数据库脚本/etc/init.d/mysqld start

由于拷贝了主库的数据,所以启动不起来
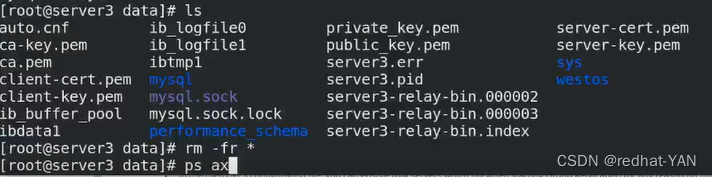
删掉整个数据rm -fr * /usr/local/mysql/data
编辑环境变量vim .bash_profile

source .bash_profile
建议同平台一致


初始化完毕后,启动数据库脚本/etc/init.d/mysqld start
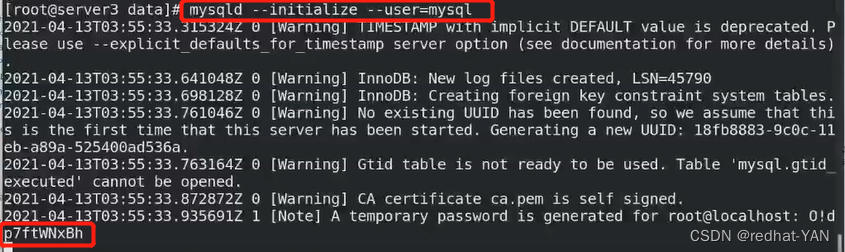
第一个密码是初始化给了个随机密码



文档中,备份时候要先锁表,备份的时候数据就不要往库里面写了,要不然数据不同步
锁表后可以读不能写
备完分拷贝到从机,然后解表(官网有详细步骤)
从库复制主库的二进制日志(存的是主库上执行的SQL语句),从库重新执行SQL语句,主库执行插入语句,从库复制发现没有该表,无法插入,所以,必须保证主从机必须保持一致才能主从复制


MASTER_LOG_POS 从二进制文件的那个位置开始,从机复制主机
如果从154开始,则在主库上的创建repl用户也会在从库执行
查看主机二进制日志名字,在主机的数据库
show master status;
 server2:
server2:
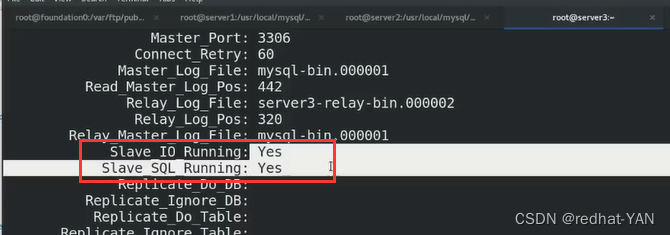
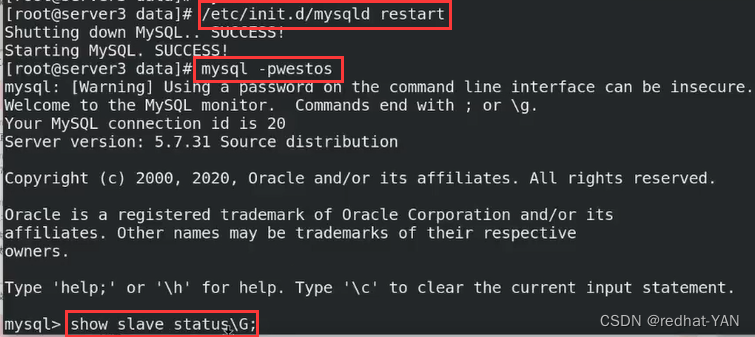
在从库中启动slave并且查看状态
mysql> start slave;
mysql> show slave status\G;
只要这两个状态是YES,那么主从复制就好了
slave开启两个线程,IO负责复制二进制日志,SQL负责将二进制日志变成SQL语句

IO 是NO一般问题
1.用户认证的问题,repl用户过不去,没有认证
2.防火墙,挡住网络连接
SQL NO
数据不一致造成
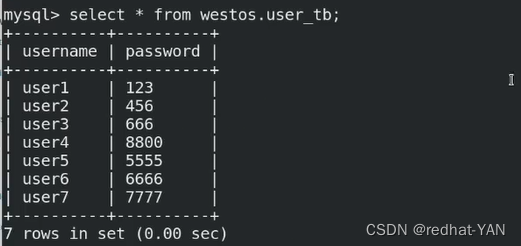
四、测试
server1创建一个库

从库上面什么都没干
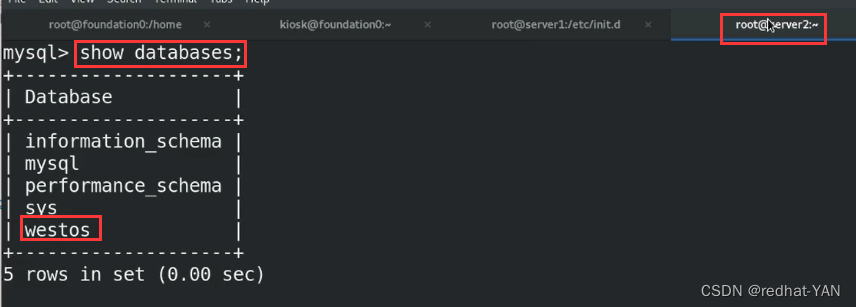

从库存放日志的号

0表示没有延迟,数值越大,slave与master延迟越高
但是仅仅用这个判断延迟不准确,因为没有考虑IO延迟

复制来的日志mysql-bin.000001会存到server2-relay-bin.000002
server1
Position号602

五、主机重启服务后,二进制日志文件变化
主机(master,server1)msql服务关闭后重启,二进制文件变化了

从机(server2)之前配置过主从复制,连接server1后读取的二进制日志文件自动更新到server1当前所用的二进制文件


六、mysldump导入(备份)书库工具
配置server3的数据库
参考第三步
注意server-id改成3
server1与server2数据一致,但是server3不一样
官网提供了mysqldump工具备份库里的数据
 备完分拷贝到从机,然后解表(官网有详细步骤)
备完分拷贝到从机,然后解表(官网有详细步骤)
server1:


server2:
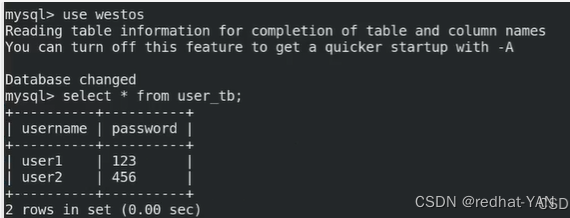
server1:

在westos库里面创建的表是从154开始的,所以server3从154开始复制能复制到表里面的数据,没有库,库的二进制日志在001上面了
把westos库导入到dump.db

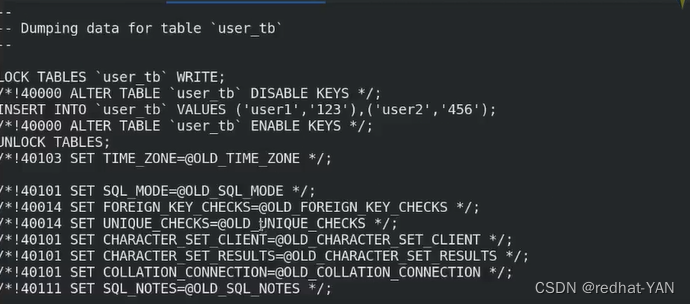
这个工具有个注意点,就是会先drop(删掉)你本来想合并表,结果被删掉了
先删掉然后重建
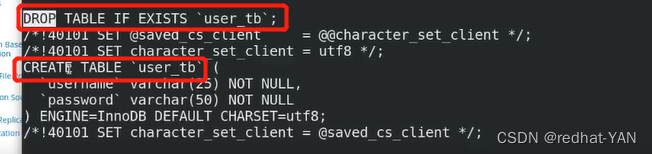

server3:




七、主从复制两种形式
1.a->b->c(a是b的组,b是c的组)
压力较小,写了主考一份slave,底下的需要考两份slave
需要添加一个参数才可以实现这种形势
2.a->b a->c
按照原先的方法继续配置一遍
八、a->b->c形势的主从复制配置
在我的服务器的G:\pub\docs\mysql\rhel6 mysql replication.pdf
底下有文档
实现1需要添加log_slave_updates这个参数

直接百度搜索这个参数,用法就出来了
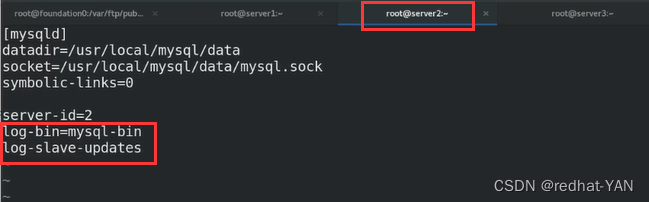
/etc/init.d/mysqld stop
/etc/init.d/mysqld start
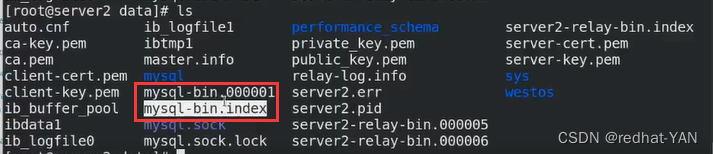
cd /usr/local/mysql/data
每次重启都会新建一个二进制文件,然后索引mysql-bin.index记录这些二进制文件
log_slave_updates 参数server2是把server1的二进制日志文件复制到自己的relay-bin(relog,它也有Index的索引文件)里面,SQL重做,然后生成bin二进制日志文件给server3用
进入server2的数据库,查看下是否2个线程是YES,然后授权(和第三步大体相同)
server2:

测试这个用户能用不

server3的my.cnf可以不变,因为它后面没有slave

server3:


九、测试a->b->c主从形势
在主机上面写,不要在slave上面写
写slave数据会不一致,因为slave一般会变成read only
一般都是写主,从机的数据都是来自于主
server1:

因为3的数据是从2过来的,所以现在3有1做的数据,证明测试成功

十、主从意义与缺点
a->b->c
a主,b主从,c是从
组从复制的最根本原因是主从热备,当主挂了,从可以成为新的组
当主挂了,可以做热备
主从问题点:
当主挂了,一般选择延迟最小的机器做为新主,然后集群所有机器奔着新主,你怎么给其余slave设置change master to
日志文件不对,所有机器slave都需要重新配置,号也不对了
这种方式会增加运维难道
所以,需要一种新的方式gtid的方式
END
系列文章目录
Mysql集群及高可用-Gtid模式2mysql集群及高可用
- 系列文章目录
- 一、mysql主从复制
- 二、mysql主从配置server1(主库master)
- 三、mysql主从配置server2(从库,slave)
- 四、测试
- 五、主机重启服务后,二进制日志文件变化
- 六、mysldump导入(备份)书库工具
- 七、主从复制两种形式
- 八、a->b->c形势的主从复制配置
- 九、测试a->b->c主从形势
- 十、主从意义与缺点
- 系列文章目录
- 一、 Mysql集群-Gtid官方文档
- 二、 主从架构与gtid架构对比
- 三、配置gtid(一组两从架构)
- 四、验证
- 系列文章目录
- 一、重启服务器需要检查的模块
- 二、主从工作原理
- 三、ok过程详情细节(半同步模式)原理
- 四、半同步模式5.7以前对比(AFTER_COMMIT与AFTER_SYNC)
- 系列文章目录
- 一、Mysql集群-半同步模式官方文档
- 二、Mysql集群-半同步模式配置
- 三、测试
- 系列文章目录
- 一、Mysql集群-并行复制(sql线程的优化)
- 二、Mysql集群-并行复制的配置
- 系列文章目录
- 一、Mysql集群-延迟复制
- 二、Mysql集群-延迟复制配置
- 系列文章目录
- 一、Mysql集群-慢查询
- 二、慢查询配置
- 三、测试
- 系列文章目录
- 一、Mysql集群-主复制
- 二、容错机制(组模式)
- 三、配置多主复制
- 四、测试
- 五、Mysql路由(通过连接不同端口实现路由)(读写分离)
- 六、测试
- 七、总结
- 系列文章目录
- 一、Mysql集群-高可用MHA
- 二、实验环境准备
- 三、Gtid模式一主两从
- 四、MHA配置
- 五、配置主配置文件
- 六、高可用手动切换
- 七、自动切换
- 八、书写脚本让perl程序一直监控数据库实例
一、 Mysql集群-Gtid官方文档
二、 主从架构与gtid架构对比
主从架构,你需要知道二进制日志文件名字,号从哪来开始
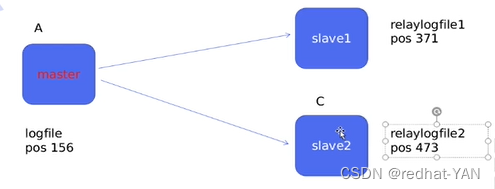
GTID,每个节点只关心gtid_next就行了

比如master挂了,slave2接管,slave1只关心它下一个gtid_next 75
,这个时候你不需要像主从一样,需要重新更改配置,调日志文件和号,只需要更改下ip地址
三、配置gtid(一组两从架构)
a->b->c上文做过了,本文做一组两从
server1:
vim /etc/my.cnf
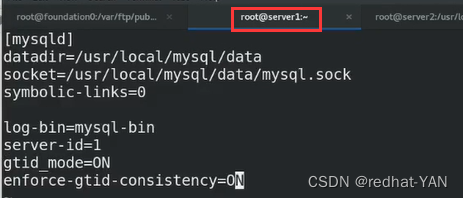
/etc/init.d/mysqld restart
server2:
vim /etc/my.cnf
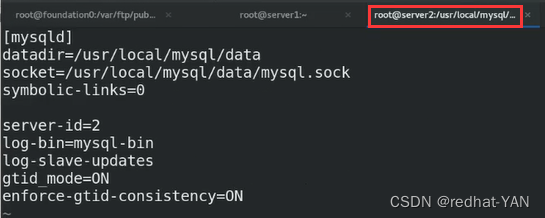
/etc/init.d/mysqld restart
同理server3相同方法配置my.cnf后重启
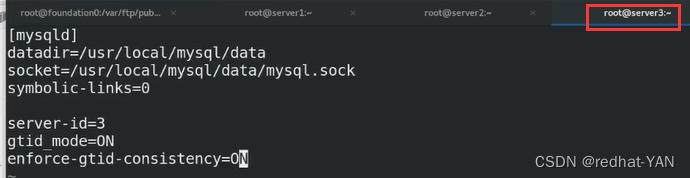
server2:
进入数据库后stop slave;

同理server3
把MASTER_HOST=‘172.25.0.2’就变成了a->b->c线性架构了
如果server1挂了,server2接管,只需要更改下server3的ip地址MASTER_HOST=‘172.25.0.2’
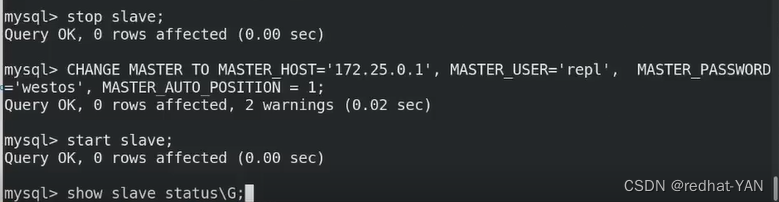
四、验证
server1:
进入数据库
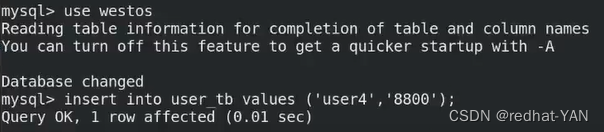
server2、3:
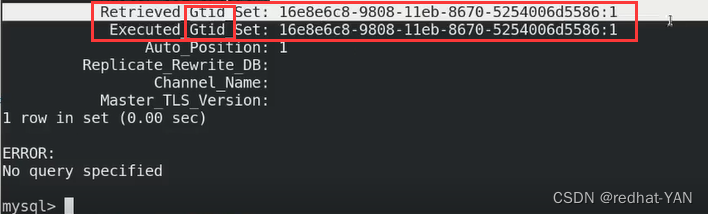
验证成功
END
系列文章目录
Mysql集群及高可用-主从工作原理3mysql集群及高可用
- 系列文章目录
- 一、mysql主从复制
- 二、mysql主从配置server1(主库master)
- 三、mysql主从配置server2(从库,slave)
- 四、测试
- 五、主机重启服务后,二进制日志文件变化
- 六、mysldump导入(备份)书库工具
- 七、主从复制两种形式
- 八、a->b->c形势的主从复制配置
- 九、测试a->b->c主从形势
- 十、主从意义与缺点
- 系列文章目录
- 一、 Mysql集群-Gtid官方文档
- 二、 主从架构与gtid架构对比
- 三、配置gtid(一组两从架构)
- 四、验证
- 系列文章目录
- 一、重启服务器需要检查的模块
- 二、主从工作原理
- 三、ok过程详情细节(半同步模式)原理
- 四、半同步模式5.7以前对比(AFTER_COMMIT与AFTER_SYNC)
- 系列文章目录
- 一、Mysql集群-半同步模式官方文档
- 二、Mysql集群-半同步模式配置
- 三、测试
- 系列文章目录
- 一、Mysql集群-并行复制(sql线程的优化)
- 二、Mysql集群-并行复制的配置
- 系列文章目录
- 一、Mysql集群-延迟复制
- 二、Mysql集群-延迟复制配置
- 系列文章目录
- 一、Mysql集群-慢查询
- 二、慢查询配置
- 三、测试
- 系列文章目录
- 一、Mysql集群-主复制
- 二、容错机制(组模式)
- 三、配置多主复制
- 四、测试
- 五、Mysql路由(通过连接不同端口实现路由)(读写分离)
- 六、测试
- 七、总结
- 系列文章目录
- 一、Mysql集群-高可用MHA
- 二、实验环境准备
- 三、Gtid模式一主两从
- 四、MHA配置
- 五、配置主配置文件
- 六、高可用手动切换
- 七、自动切换
- 八、书写脚本让perl程序一直监控数据库实例
一、重启服务器需要检查的模块
1.服务器重启后,重新启动数据库
2.server1查看master状态 show master status
3.server2、3查看slave状态show slave status\G;
io线程错误时候,一般是认证的问题
可以看错误日志,就在show slave status\G;这里可以查看到

二、主从工作原理

server1:
进入数据库
因为a->b,a->c(上个文章2,配置的gtid)
所以有2个Binlog Dump

server2、3:
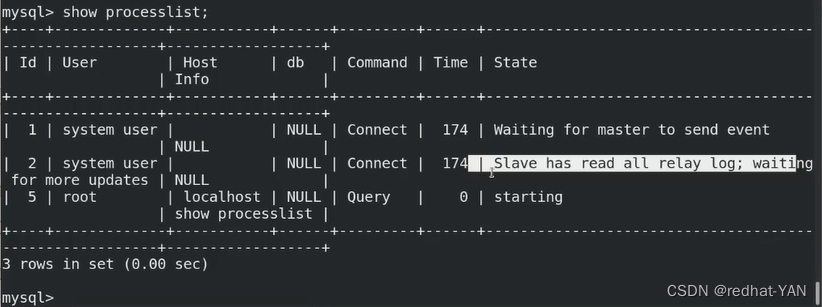
第一个Waiting是io线程,第二个Slave是SQL线程
master端并行的进行写入(读写都可)
1.slave 经过认证,建立主从复制
2.主有一个线程Binlog Dump,发现Binlog变更后,发送binlog update
3.slave io 和 sql线程,Io收到二进制日志后会存到本地数据目录的relaylog里面(SQL读,io写)

通过relay-bin.index来索引,存储所有的relaylog,这样数据库加载的时候不会丢失,按照顺序进行加载(同理Binlog日志)
整个过程是异步的
master端:send binlog update
slave端:io线程接收,存入disk,是理想状态
binlog发送过程可能出现网络问题,slave断开等等
所有需要一个确认机制ack
当slave端:io线程接收,存入disk后,给master发送ack,这个时候Master才会继续引擎提交
该方法称为半同步,默认情况半同步是10s,10s内master收不到ack,master会变成异步模式工作,这样可能导致集群主从不一致
如果想始终是半同步,那就调整半同步时间无穷大,这样的话master就无法工作了(写入不了)一直等待slave的ack,在ack到达之前,不会引擎提交(外部看不见ok),客户端一直卡着
对于数据库而言,你先引擎提交后,才能在客户端看见ok

master接收ack后,sql线程开始复原sql语句
Io和sql线程是独立工作的,io只复制接收和存储(通过网络发送的纯数据,数据量很小,所以非常快)性能高,sql负责读relog(单线程)
master有N个用户并行写入,sql单线程回放,master写入快,所以io存的越来越多,sql赶不上io的速度,会造成延迟,slave端show slave status\G;
这个值越来越大,表示延迟大

long-slave-updates参数做完sql回放后(relog),再次写入Binlog
就是a->b->c
三、ok过程详情细节(半同步模式)原理
用户在提交后(比如insert into)写入Binlog(在数据库系统里面,可以理解在缓存)
Binlog Dump 线程发现Binlog变更了,push 二进制日志给slave端的io线程
异步状态直接同步(就没有确认动作了)
做Sync是从内存刷磁盘,如果是机械盘,数据库变更,频繁变更,频繁刷磁盘,会形成热点,性能会下降很快,所以需要换固态
nosql快因为key value的引擎运行在内存中(如memache、redis)(redis相对于memache有持久化)只要有刷磁盘的动作都是消耗磁盘Io的动作,磁盘io不快,就会形成热点对数据库性能影响很大
数据库引擎提交,先刷再引擎提交(保证数据不丢失),默认情况同步二进制日志,每个事件刷一次,你每写一次,刷一次,目的就是保证数据一致性,一旦内部引擎提交后,其他用户线程是并发的,比如A用户插入的数据,其余用户就可以select看到
最后Io给予确认ack,当收到ack后才会发聩给客户端Ok

四、半同步模式5.7以前对比(AFTER_COMMIT与AFTER_SYNC)
横线上面都一样,但是是用户可以在master没有收到slave的ack的时候就开始提交
这样会造成一个问题
比如slave没有发ack,master这边用户提交了然后挂了,有主备切换,切到slave,slave变成新的master,就没有之前master提交的数据
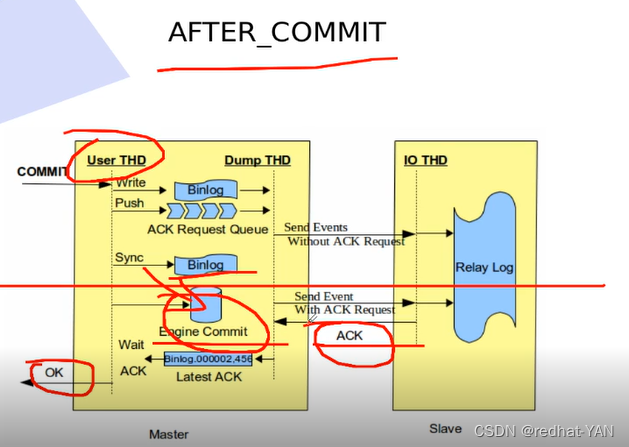
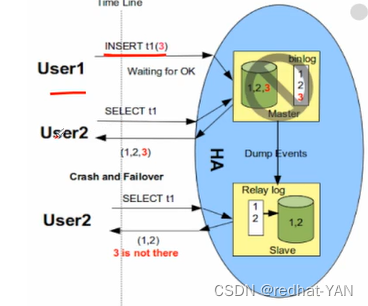
AFTER_SYNC
slave端没有接受到数据(没有发送ack),master端也看不到,即使刷盘,系统引擎没有提交,其他用户看不到这笔数据的
只有引擎提交后,其他用户才能查看到该数据
END
系列文章目录
Mysql集群及高可用-Io线程优化-半同步模式(AFTER_SYNC)mysql集群及高可用
- 系列文章目录
- 一、mysql主从复制
- 二、mysql主从配置server1(主库master)
- 三、mysql主从配置server2(从库,slave)
- 四、测试
- 五、主机重启服务后,二进制日志文件变化
- 六、mysldump导入(备份)书库工具
- 七、主从复制两种形式
- 八、a->b->c形势的主从复制配置
- 九、测试a->b->c主从形势
- 十、主从意义与缺点
- 系列文章目录
- 一、 Mysql集群-Gtid官方文档
- 二、 主从架构与gtid架构对比
- 三、配置gtid(一组两从架构)
- 四、验证
- 系列文章目录
- 一、重启服务器需要检查的模块
- 二、主从工作原理
- 三、ok过程详情细节(半同步模式)原理
- 四、半同步模式5.7以前对比(AFTER_COMMIT与AFTER_SYNC)
- 系列文章目录
- 一、Mysql集群-半同步模式官方文档
- 二、Mysql集群-半同步模式配置
- 三、测试
- 系列文章目录
- 一、Mysql集群-并行复制(sql线程的优化)
- 二、Mysql集群-并行复制的配置
- 系列文章目录
- 一、Mysql集群-延迟复制
- 二、Mysql集群-延迟复制配置
- 系列文章目录
- 一、Mysql集群-慢查询
- 二、慢查询配置
- 三、测试
- 系列文章目录
- 一、Mysql集群-主复制
- 二、容错机制(组模式)
- 三、配置多主复制
- 四、测试
- 五、Mysql路由(通过连接不同端口实现路由)(读写分离)
- 六、测试
- 七、总结
- 系列文章目录
- 一、Mysql集群-高可用MHA
- 二、实验环境准备
- 三、Gtid模式一主两从
- 四、MHA配置
- 五、配置主配置文件
- 六、高可用手动切换
- 七、自动切换
- 八、书写脚本让perl程序一直监控数据库实例
一、Mysql集群-半同步模式官方文档
半同步优化的是Io线程
二、Mysql集群-半同步模式配置
如果需要永久固定写入到/etc/my.cnf即可
确保开机自启动即可
server1:
在master端装载模块,show plugins;


server2、3:
在slave端装载模块

server1:
可以看见它的超时时间是10s,工作模式是AFTER_SYNC
生产环境建议超时时间设置无穷大
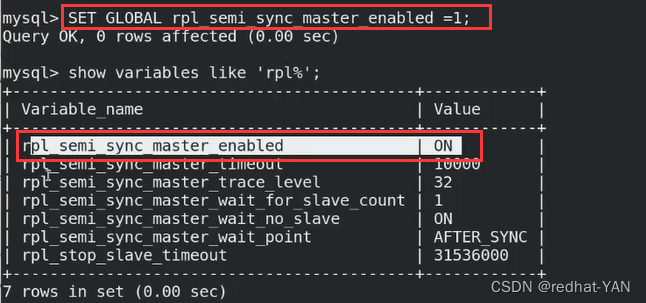
server2、3:
变量打开了
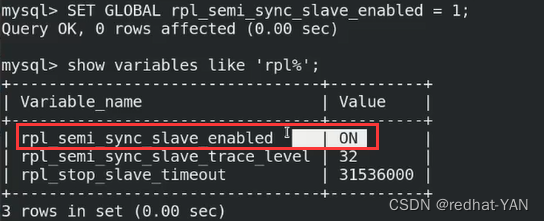
状态还没有打开,slave还没有激活
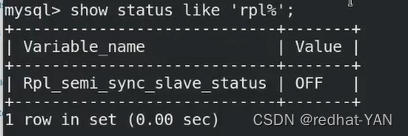
AFTER_SYNC是由io线程控制的,这个时候需要重启一下Io线程


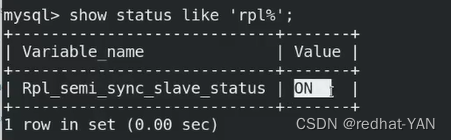
server3操作同理
server1:
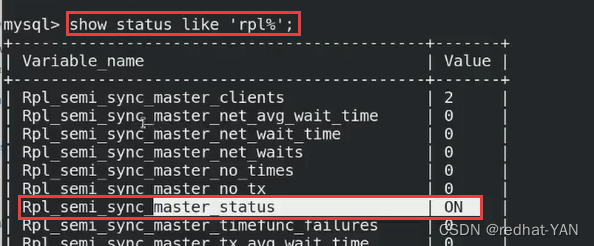
三、测试
server1:
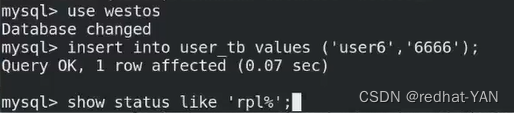
第一个红框是不是通过半同步方式(异步)完成的事件
第二个红框是通过半同步的方式完成的事件
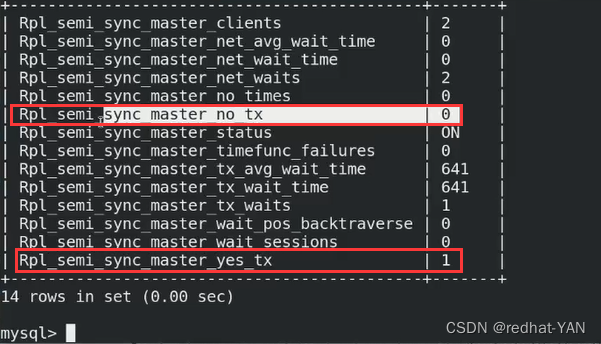
server2、3:
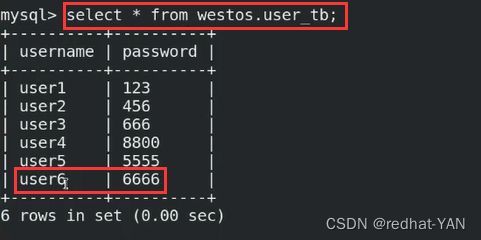
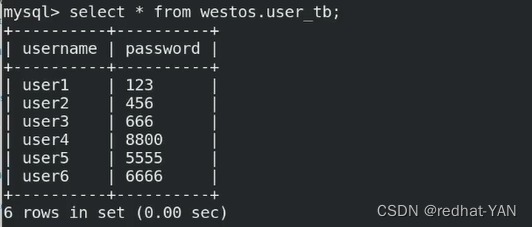
把server2的io停掉

server1:

因为是a->b a->c,尽管server2关闭了,但是还有server3
所以它还是半同步复制

server3:
server2:
server1:
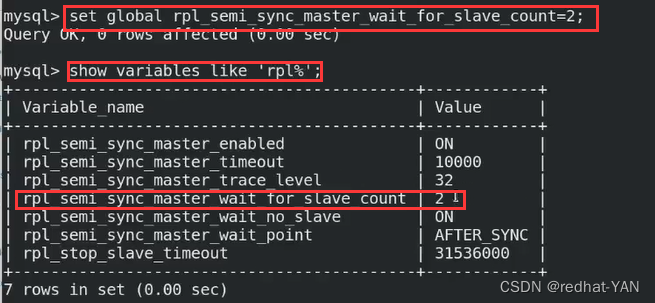
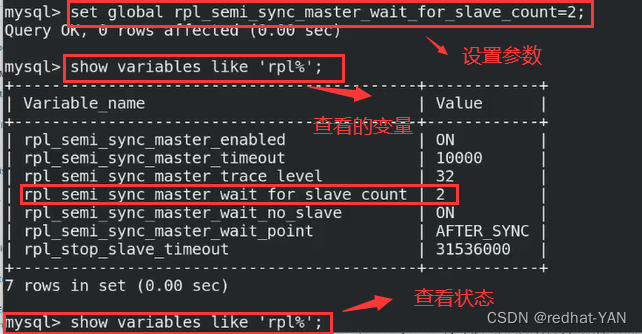
master认为只要有一个slave和我同步就行了
但是我们需要每个服务器都要是半同步,这样才能确保数据的一致性
需要设置参数,这个表示master要等待多少个slave,该数字和后端slave节点数量保持一致

客户端卡住了

server3数据同步了,server2没有,master在等待server2的ack,server2发送ack后,客户端才能写(或者过了设置的时间,没有设置时间,默认是10s变成异步模式)
等待10s后

这样的话,数据就不一致了

END
系列文章目录
Mysql集群及高可用-SQL线程的优化-并行复制5mysql集群及高可用
- 系列文章目录
- 一、mysql主从复制
- 二、mysql主从配置server1(主库master)
- 三、mysql主从配置server2(从库,slave)
- 四、测试
- 五、主机重启服务后,二进制日志文件变化
- 六、mysldump导入(备份)书库工具
- 七、主从复制两种形式
- 八、a->b->c形势的主从复制配置
- 九、测试a->b->c主从形势
- 十、主从意义与缺点
- 系列文章目录
- 一、 Mysql集群-Gtid官方文档
- 二、 主从架构与gtid架构对比
- 三、配置gtid(一组两从架构)
- 四、验证
- 系列文章目录
- 一、重启服务器需要检查的模块
- 二、主从工作原理
- 三、ok过程详情细节(半同步模式)原理
- 四、半同步模式5.7以前对比(AFTER_COMMIT与AFTER_SYNC)
- 系列文章目录
- 一、Mysql集群-半同步模式官方文档
- 二、Mysql集群-半同步模式配置
- 三、测试
- 系列文章目录
- 一、Mysql集群-并行复制(sql线程的优化)
- 二、Mysql集群-并行复制的配置
- 系列文章目录
- 一、Mysql集群-延迟复制
- 二、Mysql集群-延迟复制配置
- 系列文章目录
- 一、Mysql集群-慢查询
- 二、慢查询配置
- 三、测试
- 系列文章目录
- 一、Mysql集群-主复制
- 二、容错机制(组模式)
- 三、配置多主复制
- 四、测试
- 五、Mysql路由(通过连接不同端口实现路由)(读写分离)
- 六、测试
- 七、总结
- 系列文章目录
- 一、Mysql集群-高可用MHA
- 二、实验环境准备
- 三、Gtid模式一主两从
- 四、MHA配置
- 五、配置主配置文件
- 六、高可用手动切换
- 七、自动切换
- 八、书写脚本让perl程序一直监控数据库实例
一、Mysql集群-并行复制(sql线程的优化)
半同步优化的是io线程
master并行写入,一个sql回放会导致延迟越来愈大
直接百度查看 mysql5.7 mts 找到相应的参数即可
解决延迟问题
二、Mysql集群-并行复制的配置
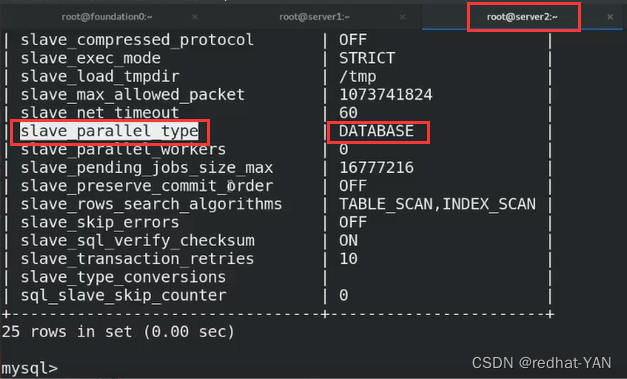
2.1 slave_parallel_type
server2:
进入数据库后
show variables like '%slave%';
DATABASE表示并行的基础是以数据库为基础,一个数据库开启一个线程
但是实际是一个数据库很多的写入,如果按照DATABASE来sql回放发挥不出并行的性能
变更slave_parallel_type需要先停掉sql线程 (或者先stop slave;全局环境变量;start slave;)
也可以写到主配置文件/etc/my.cnf重启数据库就可以(生产环境是不能随意重启,测试环境可以)
所以最好是热添加(热生效)set global 临时的
热生效配置后马上写入主配置文件/etc/my.cnf,要不然数据库服务重启后,前面设置的set global就会丢失

2.2 slave_parallel_workers
slave_parallel_workers原先的sql线程会变成为协调线程,重建16个worker,不能设置1,设置1还不如原先的性能(不设置sql的并行复制)
根据实际生产调整具体的worker是多少,官方测试是16
因为一旦走了并行,机制就变化了,通过协调线程来做转发,性能一部分用在了转发上面

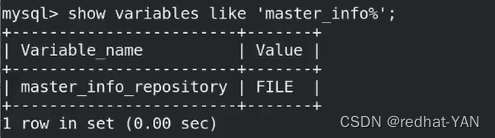
2.3 master_info_repository和relay_log_repository
启动并行复制后,每次复制的时候,主从的信息会保留在数据目录/usr/local/mysql/data 下面的master.info和relay-log.info
master.info
server3:
读取的文件,读取的号,master主机ip

relay-log.info
server3:

激活并行复制后,文件变更速度比原先快得多,频繁的刷文件,这样的话,性能会下降,配合并行复制mts,官方建议开启两个参数选项
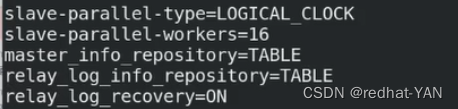
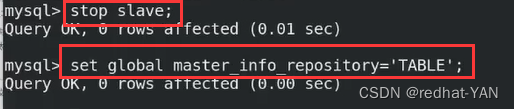
master_info_repository=TABLE
relay_log_repository=TABLE
信息保存方式2种,一种是文件,一种是表(放在数据库中),由数据库系统做刷盘动作,而不是直接写入文件保存,这样开启并行复制的时候性能能提升
server2:

slave状态没问题

master.info 和 relay-log.info 不存在了,变成数据库表了
进入数据库
use mysql
show tables;
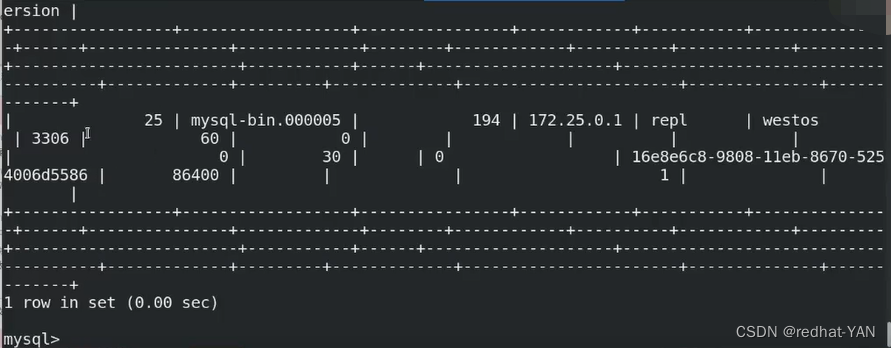
select * from slave_master_info;
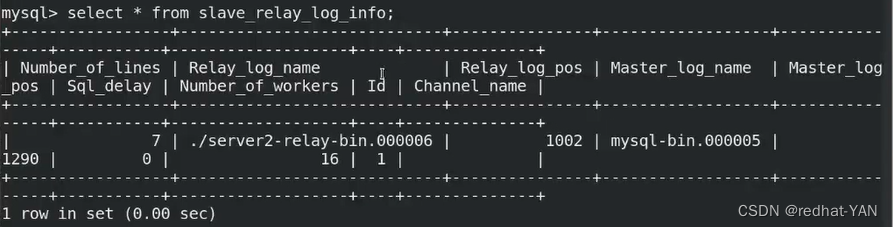
2.4 relay_log_recovery
slave 通过relay_log进行恢复
relay_log_recovery=ON
server2:
由于这个参数是只读,所以只能写到主配置文件中
有些参数不能热生效,必须写入配置文件中

server3:
由于是测试环境,所以直接在server3上的主配置文件/etc/my.cnf上面写上所有参数,重启数据库服务
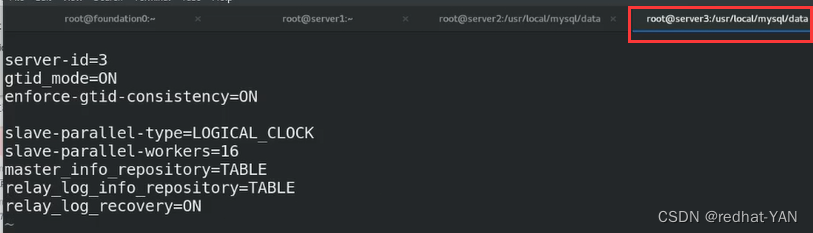


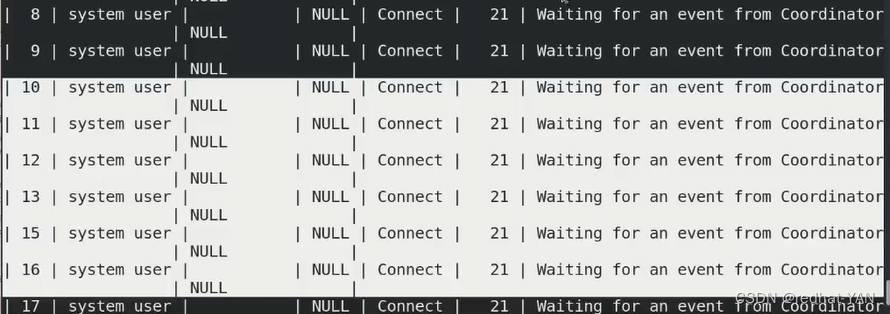
截取部分:
里面16个sql线程
END
系列文章目录
Mysql集群及高可用-SQL线程的优化-延迟复制6mysql集群及高可用
- 系列文章目录
- 一、mysql主从复制
- 二、mysql主从配置server1(主库master)
- 三、mysql主从配置server2(从库,slave)
- 四、测试
- 五、主机重启服务后,二进制日志文件变化
- 六、mysldump导入(备份)书库工具
- 七、主从复制两种形式
- 八、a->b->c形势的主从复制配置
- 九、测试a->b->c主从形势
- 十、主从意义与缺点
- 系列文章目录
- 一、 Mysql集群-Gtid官方文档
- 二、 主从架构与gtid架构对比
- 三、配置gtid(一组两从架构)
- 四、验证
- 系列文章目录
- 一、重启服务器需要检查的模块
- 二、主从工作原理
- 三、ok过程详情细节(半同步模式)原理
- 四、半同步模式5.7以前对比(AFTER_COMMIT与AFTER_SYNC)
- 系列文章目录
- 一、Mysql集群-半同步模式官方文档
- 二、Mysql集群-半同步模式配置
- 三、测试
- 系列文章目录
- 一、Mysql集群-并行复制(sql线程的优化)
- 二、Mysql集群-并行复制的配置
- 系列文章目录
- 一、Mysql集群-延迟复制
- 二、Mysql集群-延迟复制配置
- 系列文章目录
- 一、Mysql集群-慢查询
- 二、慢查询配置
- 三、测试
- 系列文章目录
- 一、Mysql集群-主复制
- 二、容错机制(组模式)
- 三、配置多主复制
- 四、测试
- 五、Mysql路由(通过连接不同端口实现路由)(读写分离)
- 六、测试
- 七、总结
- 系列文章目录
- 一、Mysql集群-高可用MHA
- 二、实验环境准备
- 三、Gtid模式一主两从
- 四、MHA配置
- 五、配置主配置文件
- 六、高可用手动切换
- 七、自动切换
- 八、书写脚本让perl程序一直监控数据库实例
一、Mysql集群-延迟复制
延迟复制优点
1.在主库上面误操作,比如延迟30min,你还可以在slave端做数据回滚
2.一旦使用主从复制延迟是必然存在的,前面的操作是不断优化,减少延迟,延迟多少时间会对业务造成影响,可以使用延迟复制进行测试(设置延迟,不断提高延迟,测试对业务的影响)
二、Mysql集群-延迟复制配置
server3:
server3作为延迟的slave
设置30s延迟,默认单位是s


查看slave的状态show slave status\G;
两个yes没问题

2.1测试,出现客户端出现卡顿,排查Io线程错误
server1:
客户端等待状态这个和io线程有关
调整的是sql线程,是sql回放延迟30s,与延迟复制无关

所以检查io线程,前面设置的是半同步
show status like 'rpl%';

因为刚才server3重启了(上文配置 relay_log_recovery参数)
server3:
原因:之前配置sync半同步的时候设置的参数是临时的set global,重启server3数据库服务后之前的半同步不存在了
所以你参数要写入/etc/my.cnf要不然重启后相应的参数就没有了
重启io(stop slave;start slave;这样也行)

再次查看状态rpl_semi_sync_slave_ebabled ON
server1:
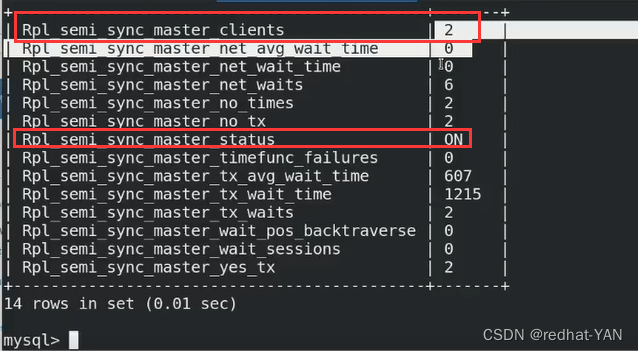
恢复正常,继续测试延迟复制
2.2继续测试延迟复制
没设置主键多个user9,无所谓

server3:
查看slave的状态show slave status\G;
达到30s才会运行

延迟30s以后开始执行

server2:
查看slave的状态show slave status\G;

server3:
30s后执行完成


数据同步完成

END
系列文章目录
Mysql集群及高可用-SQL线程的优化-慢查询mysql集群及高可用
- 系列文章目录
- 一、mysql主从复制
- 二、mysql主从配置server1(主库master)
- 三、mysql主从配置server2(从库,slave)
- 四、测试
- 五、主机重启服务后,二进制日志文件变化
- 六、mysldump导入(备份)书库工具
- 七、主从复制两种形式
- 八、a->b->c形势的主从复制配置
- 九、测试a->b->c主从形势
- 十、主从意义与缺点
- 系列文章目录
- 一、 Mysql集群-Gtid官方文档
- 二、 主从架构与gtid架构对比
- 三、配置gtid(一组两从架构)
- 四、验证
- 系列文章目录
- 一、重启服务器需要检查的模块
- 二、主从工作原理
- 三、ok过程详情细节(半同步模式)原理
- 四、半同步模式5.7以前对比(AFTER_COMMIT与AFTER_SYNC)
- 系列文章目录
- 一、Mysql集群-半同步模式官方文档
- 二、Mysql集群-半同步模式配置
- 三、测试
- 系列文章目录
- 一、Mysql集群-并行复制(sql线程的优化)
- 二、Mysql集群-并行复制的配置
- 系列文章目录
- 一、Mysql集群-延迟复制
- 二、Mysql集群-延迟复制配置
- 系列文章目录
- 一、Mysql集群-慢查询
- 二、慢查询配置
- 三、测试
- 系列文章目录
- 一、Mysql集群-主复制
- 二、容错机制(组模式)
- 三、配置多主复制
- 四、测试
- 五、Mysql路由(通过连接不同端口实现路由)(读写分离)
- 六、测试
- 七、总结
- 系列文章目录
- 一、Mysql集群-高可用MHA
- 二、实验环境准备
- 三、Gtid模式一主两从
- 四、MHA配置
- 五、配置主配置文件
- 六、高可用手动切换
- 七、自动切换
- 八、书写脚本让perl程序一直监控数据库实例
一、Mysql集群-慢查询
生产环境慢查询一般都打开
有时候sql的开发人员写的sql语句不符合线上要求,会对数据库造成影响,会整体拉慢sql查询
二、慢查询配置
server1:

打开后会在数据目录中生成慢查询日志
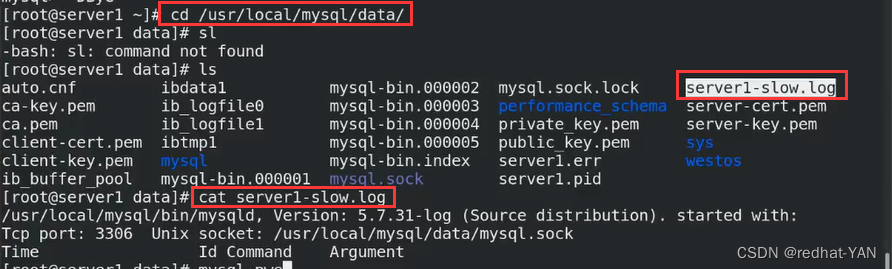
三、测试
server1:
默认10s,则为慢查询
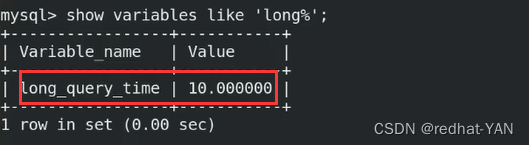
运行了10s
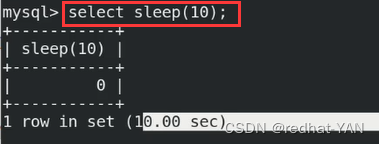
只要查询语句超过定义的时间都会被日志抓取记录出来
抓取出来分析sql语句的问题

END
系列文章目录
Mysql集群及高可用-多主复制与Mysql路由(读写分离)8
mysql集群及高可用
- 系列文章目录
- 一、mysql主从复制
- 二、mysql主从配置server1(主库master)
- 三、mysql主从配置server2(从库,slave)
- 四、测试
- 五、主机重启服务后,二进制日志文件变化
- 六、mysldump导入(备份)书库工具
- 七、主从复制两种形式
- 八、a->b->c形势的主从复制配置
- 九、测试a->b->c主从形势
- 十、主从意义与缺点
- 系列文章目录
- 一、 Mysql集群-Gtid官方文档
- 二、 主从架构与gtid架构对比
- 三、配置gtid(一组两从架构)
- 四、验证
- 系列文章目录
- 一、重启服务器需要检查的模块
- 二、主从工作原理
- 三、ok过程详情细节(半同步模式)原理
- 四、半同步模式5.7以前对比(AFTER_COMMIT与AFTER_SYNC)
- 系列文章目录
- 一、Mysql集群-半同步模式官方文档
- 二、Mysql集群-半同步模式配置
- 三、测试
- 系列文章目录
- 一、Mysql集群-并行复制(sql线程的优化)
- 二、Mysql集群-并行复制的配置
- 系列文章目录
- 一、Mysql集群-延迟复制
- 二、Mysql集群-延迟复制配置
- 系列文章目录
- 一、Mysql集群-慢查询
- 二、慢查询配置
- 三、测试
- 系列文章目录
- 一、Mysql集群-主复制
- 二、容错机制(组模式)
- 三、配置多主复制
- 四、测试
- 五、Mysql路由(通过连接不同端口实现路由)(读写分离)
- 六、测试
- 七、总结
- 系列文章目录
- 一、Mysql集群-高可用MHA
- 二、实验环境准备
- 三、Gtid模式一主两从
- 四、MHA配置
- 五、配置主配置文件
- 六、高可用手动切换
- 七、自动切换
- 八、书写脚本让perl程序一直监控数据库实例
一、Mysql集群-主复制
Mysql集群的组复制有2种模式
单组模式以及多组模式
组复制必须要inodb引擎,数据库表结构需要有主键(有主键约束)
可以下载mysql的官方译文来进行学习
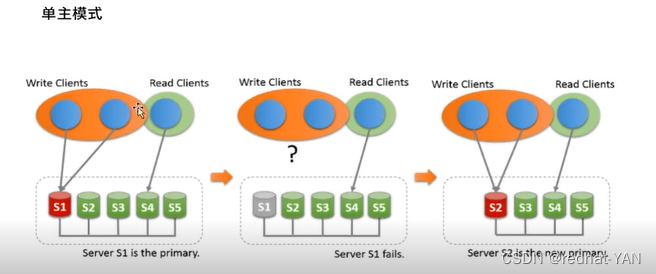
单主模式你只能在一个节点上去写,其余节点读(其实就是一组多从的架构)
但是当主挂了可以从slave端自动切换,内部高可用(这是个集群)
这种模式下,前面还需一层prox(实现读写分离),把所有数据库写的调度到master(也可读,但是一般都是调度到写),因为写不能在slave上面写,把所有读的调度到slave上面
主从有延迟,所以对实时性要求高的场景是不适合的
主从架构适用于读的请求远远高于写的请求
最多节点是9个,官网给出的

多主模式
所有节点都可以读写,完全去中心化,不需要找master

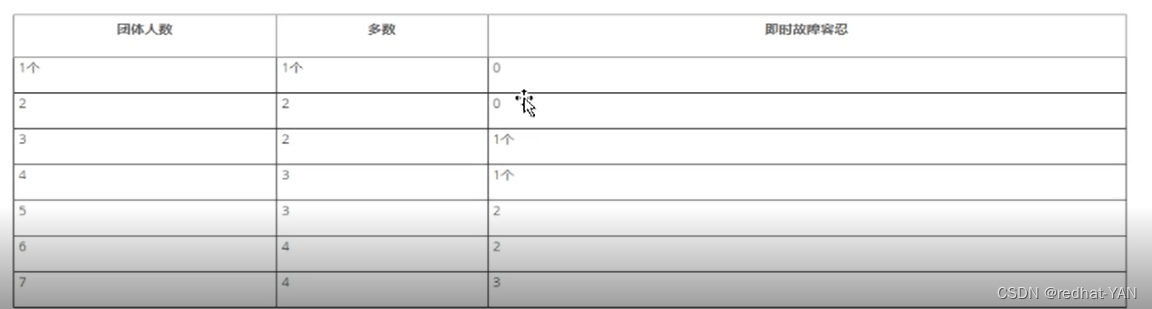
二、容错机制(组模式)
在有3个节点的集群,down一个集群还可以用,down两个集群就废了
三、配置多主复制
组复制对数据一致性的要求很高,这种多主复制,在任何一台节点上写的时候,会把这台节点上执行的sql语句发往集群中所有的节点进行校验,校验通过在所有节点上运行,集群内部任意一个节点校验失败,直接回滚不会执行该sql,所有节点都这样
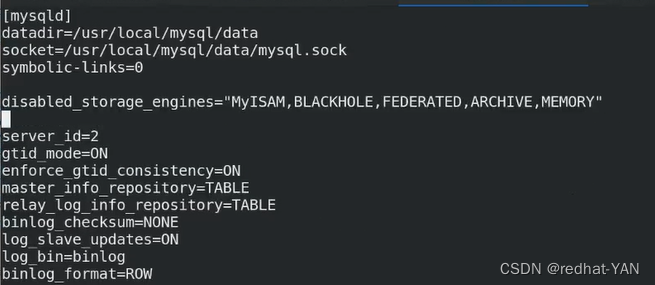
**主复制必须使用Inodb引擎,要禁用其它的存储引擎,**当初编译数据库的时候,只编译了inodb引擎,然后书写my.cnf和官网少个禁用Inodb引擎的参数(认为可以不加),导致后续的报错,必须要加这个参数!!!
server1:
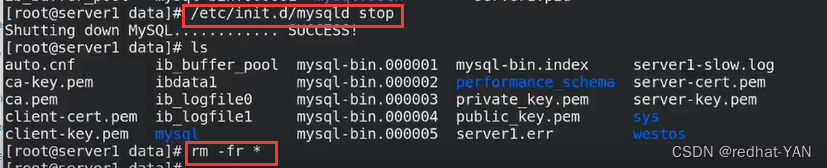
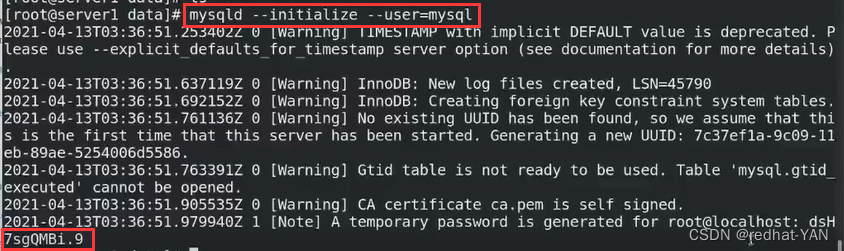
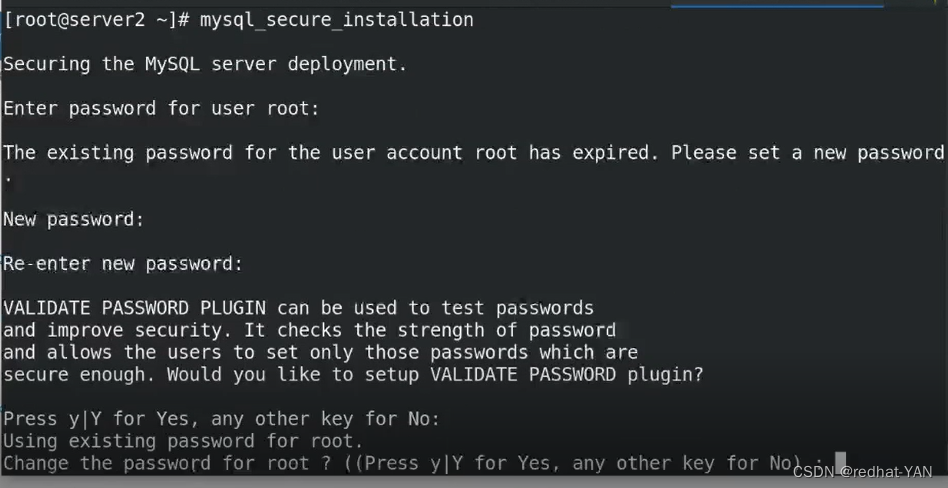
不再执行安全脚本,它会做其它的事情,我们要保证3个数据库一开始就一模一样,数据库的纯净,避免数据不一致的问题
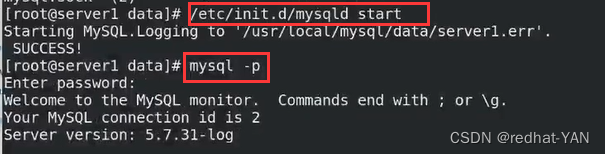
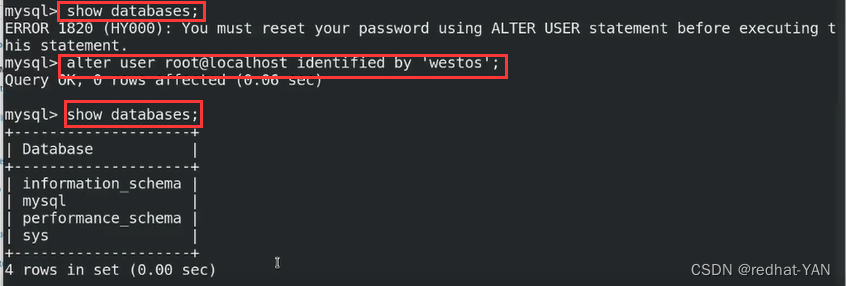
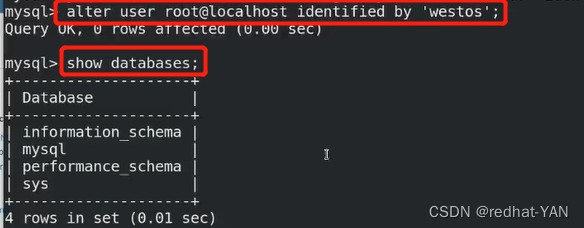
由于是临时密码登录的,所以做不了任何事情,所以需要修改下密码
需要禁用sql语句不记录到二进制日志


这些参数需要加入到/etc/my.cnf
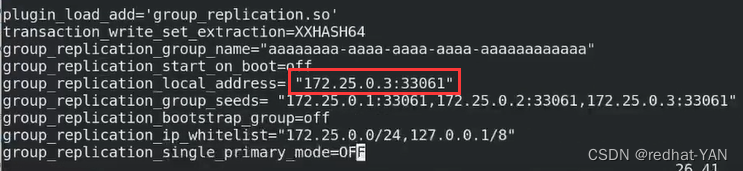
group_name是uuid形势的,你自己创建就行
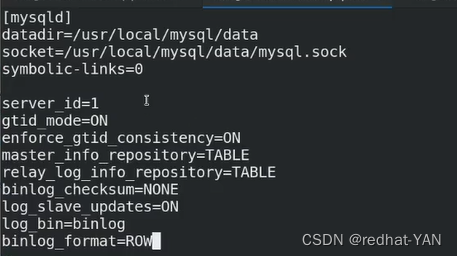
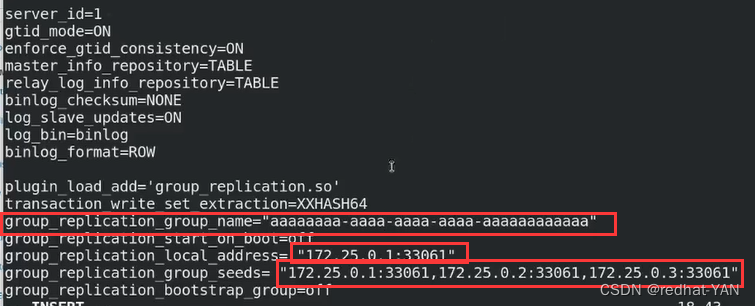
默认情况下是不允许其他主机除了Localhost加入到mgr里面
所以需要把这个网段加入进去,表示这个网段其它主机加入也是允许的
默认是单组模式,你要OFF禁用
打开更新检测,这两个是配套的

需要创建用于主复制的用户
也是基于主从,二进制日志的复制
刚才写的my.cnf
都是要打开二进制日志的

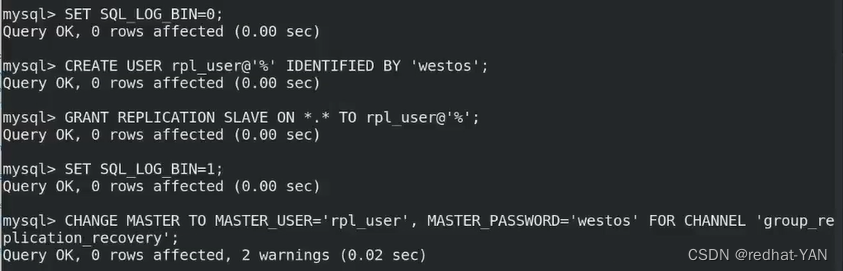
先关闭二进制日志,因为我们需要先创建用户,避免冲突
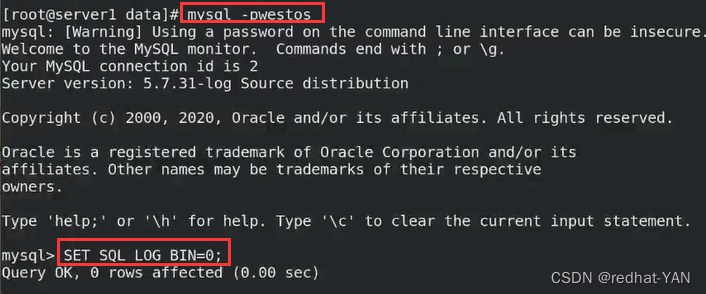
创建用于复制的用户,授权,刷新使之生效(刷新用户授权表)
激活二进制日志
配置复制的信道
确认下加载的plugins
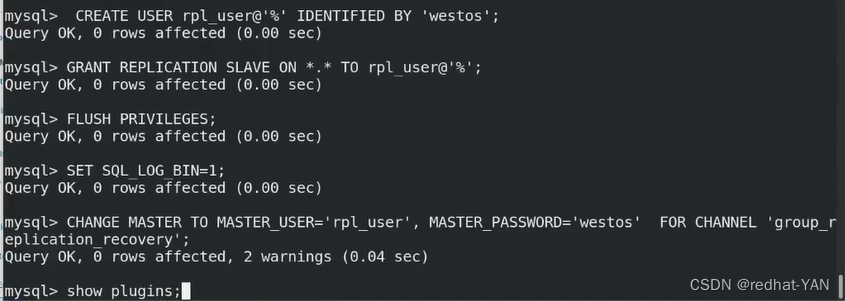
已经有了

集群是没有初始节点的,没有任何成员,所以需要一个引导节点

所以,将server1作为集群的初始节点
只有server1做这3步,其它节点负责join就行了
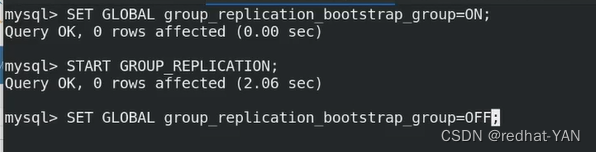
都是用uuid来标识成员Id,集群有成员了
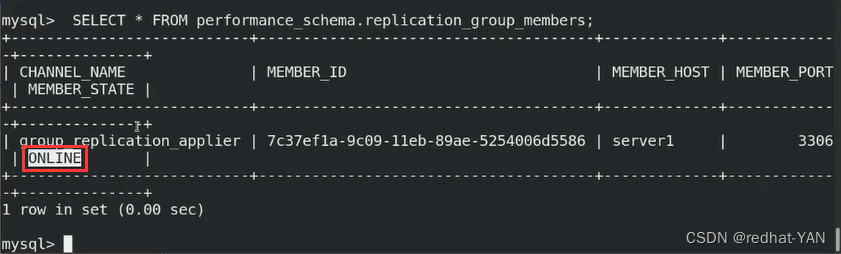
server2:
初始化,不要加很多选项,避免影响初始化

修改主配置文件,只改id和Local_adress其余不变
id更改
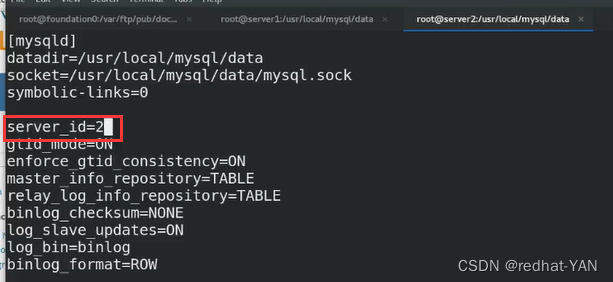
local_address更改
这个my.cnf不全,后续会报错
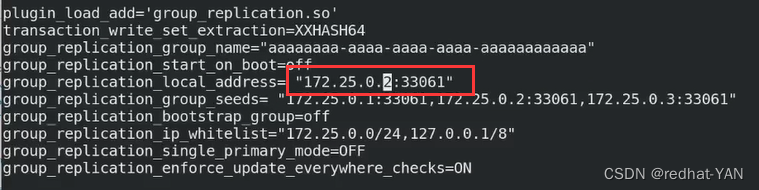
正确的:
需要再加入一个参数

操作和当初操作server1一样
不需要向server1一样修改参数,有个引导的节点,直接加入集群就行了
报错,查看错误日志

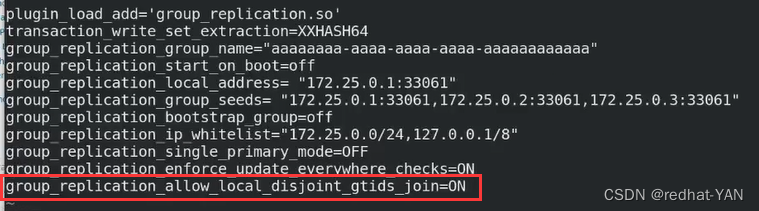
报错内容,数据冲突了,需要加入第二个红框的参数选项
加入join in的时候要放弃本地的数据,以master的数据为准,需要一个为准

在所有的slave端的/etc/my.cnf上多加上这个参数
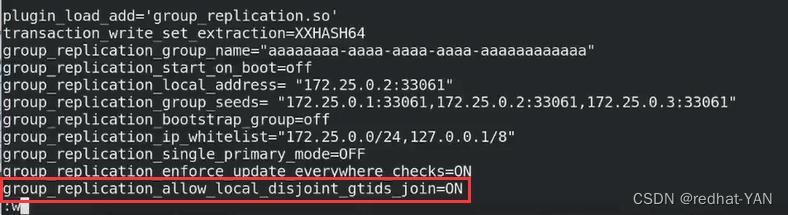
加入后不用重启,直接进入数据库,直接用热生效就行
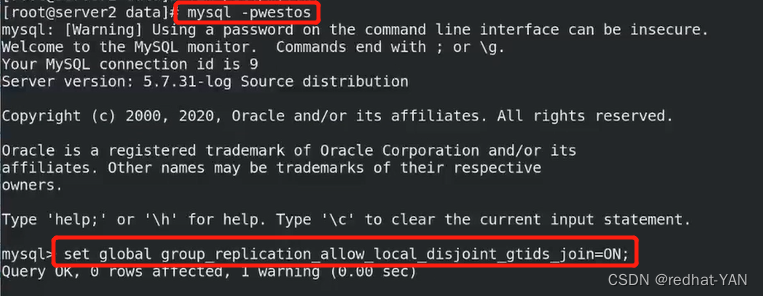

server1:
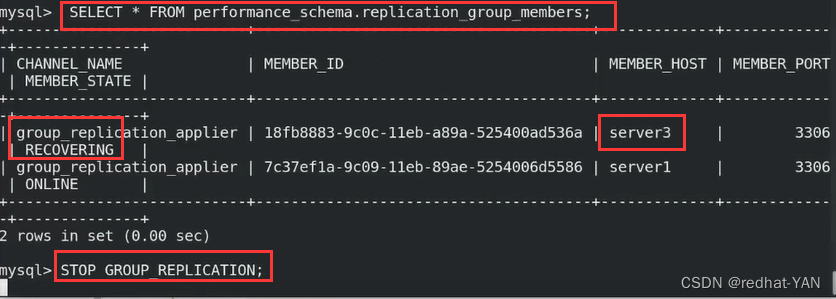
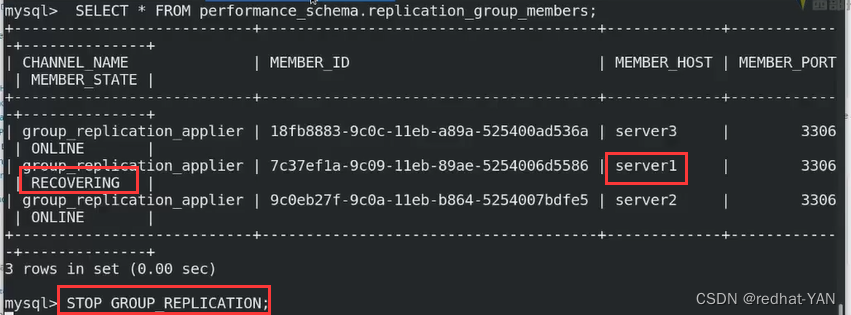
在数据库中,可以看到server2不是ONLINE,还是没有加入,处于恢复状态中
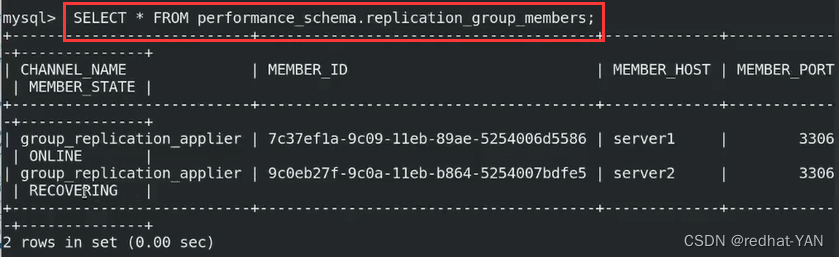
server2:

在数据目录下/usr/local/mysql/data
cat server2.err

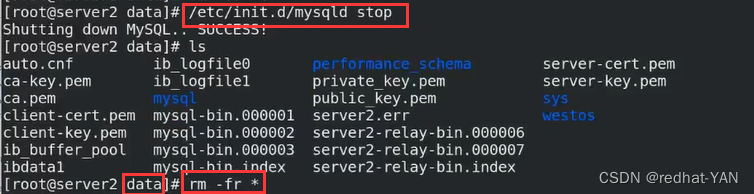
出现问题,重新做下server3
server3:
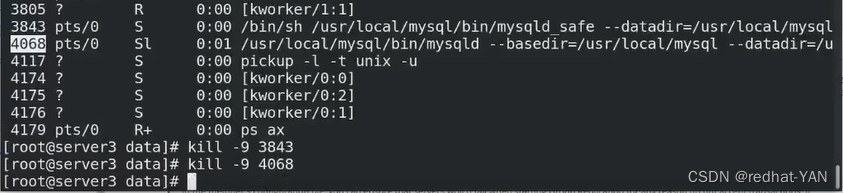
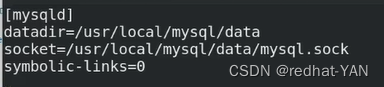
修改/etc/my.cnf
做初始化
把server2的参数复制给3,更改下id localhost_address




在server1的数据库中:
server3也是恢复状态,2和3问题点一样
server3:
查看错误日志
在数据目录下cat server3.err 发现是master的问题,server1不能做master

server2:
可以发现server2还是OFFLINE
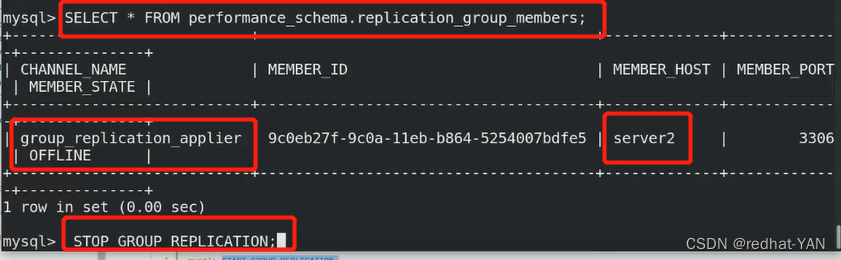
server3:
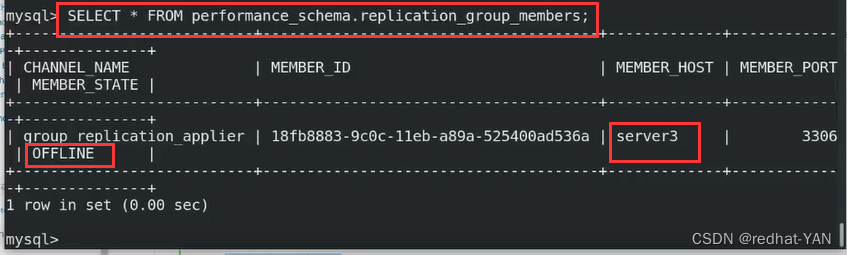
查看错误日志说是server1的问题
换一个做引导节点换成server2
server2:
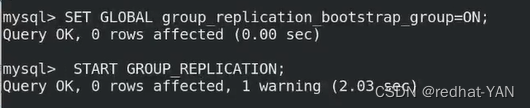
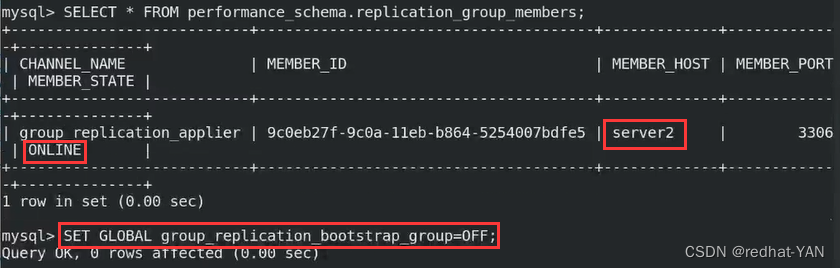
集群中一定要有解析
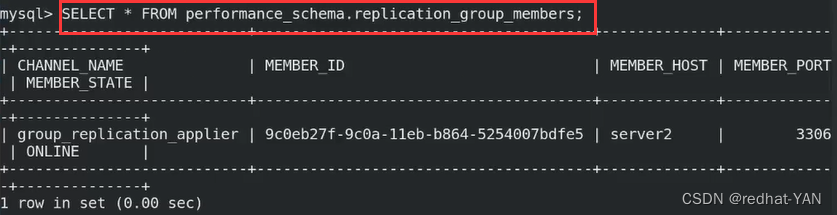
server3:

server2
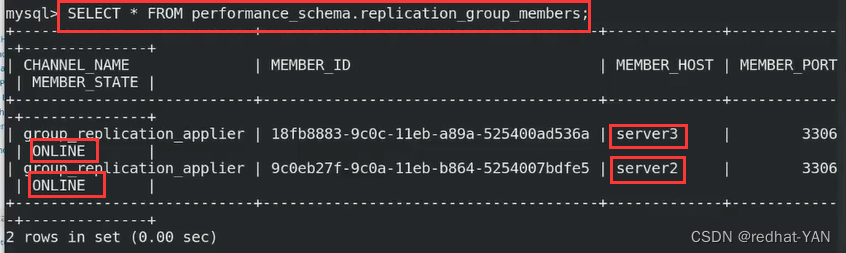 成功了
成功了
server1:

在server1上面添加相应的禁用数据库引擎

再添入这个参数,因为server1成为slave
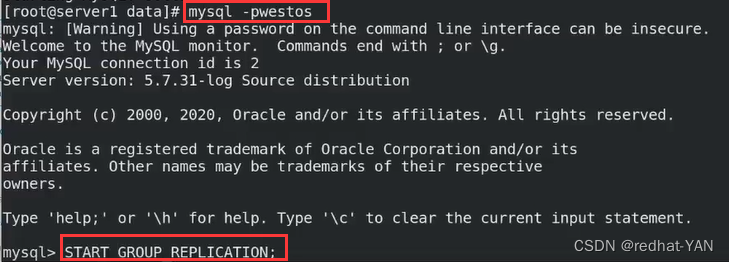
还是没有加入进去
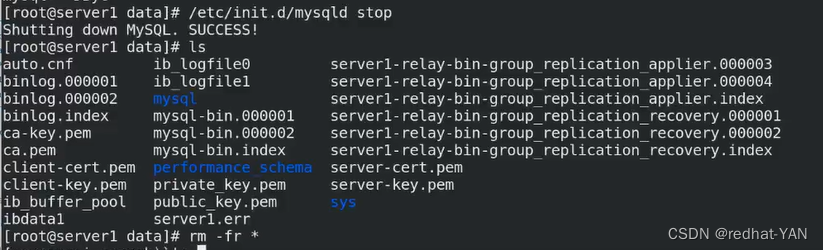
重新做一遍server1,估计是粗心导致最后server2和server3是好的
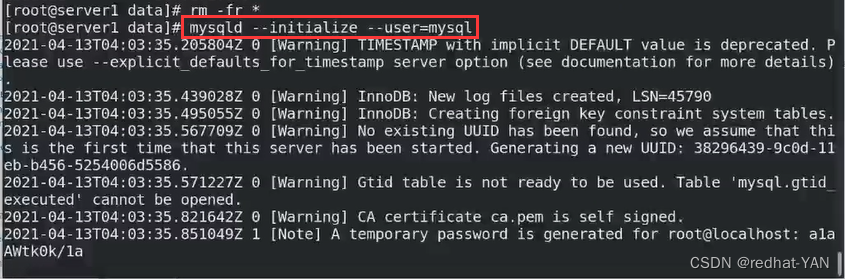
主配置文件就可以不用重新配了,之前配好的




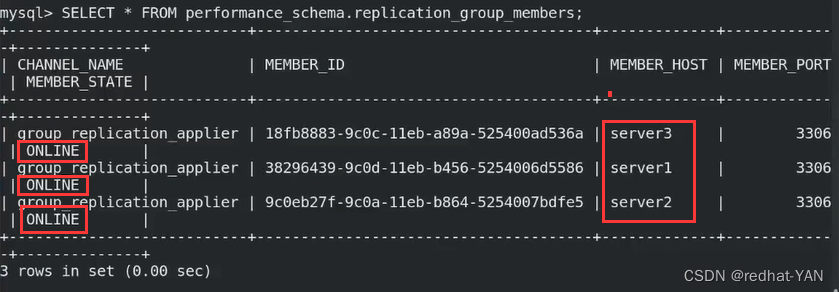
多主模式搭建成功
四、测试
给多组模式创建数据库,一个创建后,所有节点都有,测试成功
组模式的数据库表结构需要有主键(有主键约束)
server1:
进入数据库
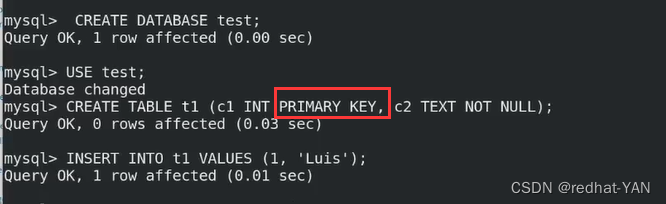
server2:
进入数据库
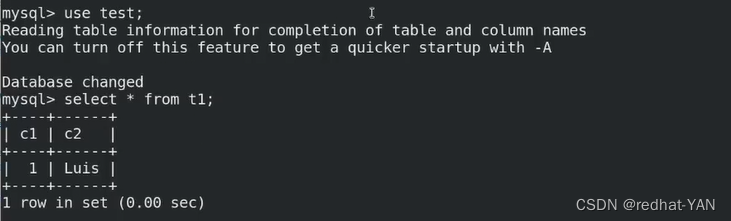
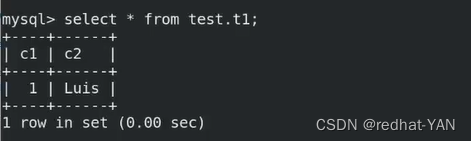
server3:
进入数据库
五、Mysql路由(通过连接不同端口实现路由)(读写分离)
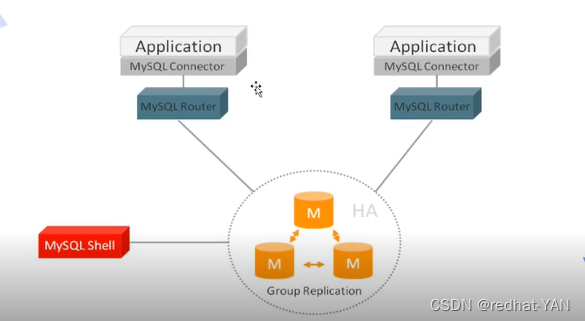
后端是集群(无论单组多组),前面加个接入层,通过中间件,对于业务会更加透明
通过中间件代理将应用流量分摊到集群后端的结点上
Mysql路由是官方提供的代理插件,使用场景,应用和数据库的接口(负载均衡)
MGR (组复制) 内部自带高可用,由Mysql路由根据不同端口,连接到不同集群实现负载均衡
另一个软件Mysql prox(连接端口一致)是根据用户的sql语句(如查询和插入)不同sql来转发到不同的服务器集群,是一种反向代理机制(nginx一样),就是客户端始终知道连接的是server4,后台连接是谁不知道
也可以使用MyCAT(ali做的Mysql中间件)
再开启一个虚拟机server4,下载软件mysql-router-community
我提前下载好了,在我/pub/docs/mysql,rpm安装


进入主配置目录/etc/mysqlrouter/mysqlrouter.conf
不用原本的修改配置文件,因为都是全局变量
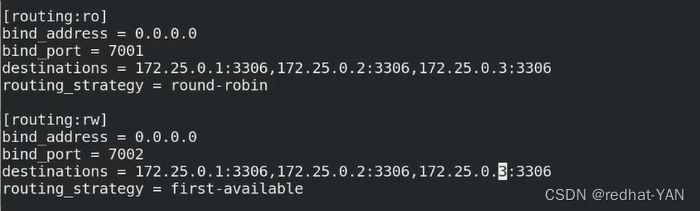
添加上这段,根据端口来定义不同的负载均衡的组,通过不一样的算法
bind_adress监听地址本机所有接口
由于配置的3个节点是多主模式,不管是读写都可以调度
round-robin算法是轮询的,第一个读1,第二个读2,第三个读3
first-available第一个可用加载第一个,第一个不可用加载第二个
因为数据库的写入是持续的,第一个可用就一直用第一个就行了
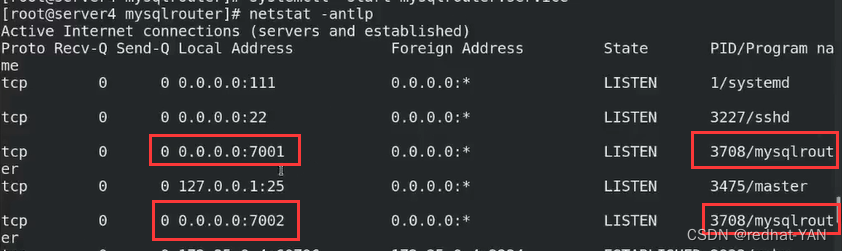
然后启动服务
开启服务后,开启两个端口7001和7002
六、测试
7001端口和7002端口算法不一样
7001端口 :
round-robin算法是轮询的,第一个读1,第二个读2,第三个读3
7002端口 :
first-available第一个可用加载第一个,第一个不可用加载第二个
因为数据库的写入是持续的,第一个可用就一直用第一个就行了
6.1 7001端口(轮询)测试
宿主机:
在宿主机上面查看有无mysql命令

没有需要安装mariadb,都是客户端,所以使用mariadb也可以
yum install mariadb
-P 端口 -u 用户 -p 密码
没有授权,连接不了(只有本地,远程连接不了)

server1:
在server1、server2、server3上面都可以授权不只是sever1,因为每个节点都可以读写
给user1(可以远程登录)授予查询所有权限

给user2(可以远程连接)授予插入和更新的所有权限在test库

刷新用户授权表

继续测试
宿主机:
7001是只读的,调度到1上(轮询机制)

server1:


同理给sevre2、3都安装lsof
server2:

server3:

第一次连接失败了,所以根据轮询连接到server2
宿主机退出数据库,再次进入
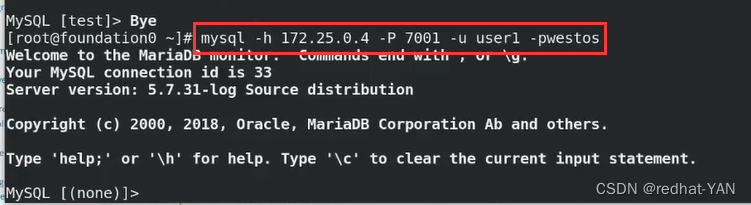
server3:

server2:

server1:

再次测试一次
退出数据库,重新进入数据库
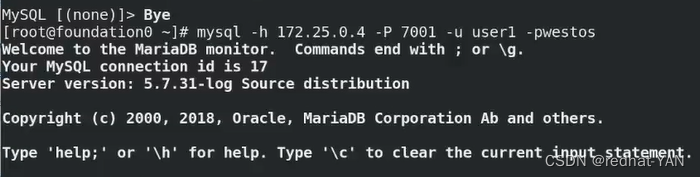
这个时候应该是server1有其它没有

6.2 7002端口(第一个服务器不可用才调度到第二个服务器)测试
换用户测试
宿主机:
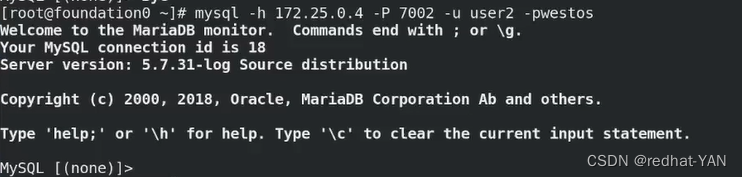
server1:

server2:

server3:

宿主机:

server1:
连接的还是server1

宿主机:
退出数据库再进入数据库
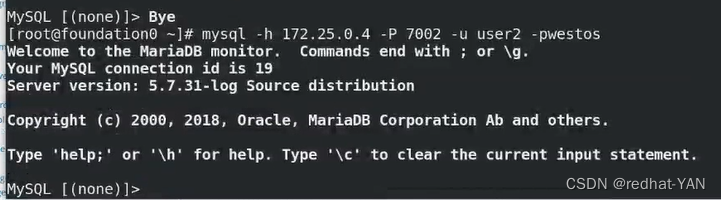
连接还是1
server1:

停止掉server1:
模拟发生故障,测试7002的算法,并且测试MGR集群的高可用

server2:

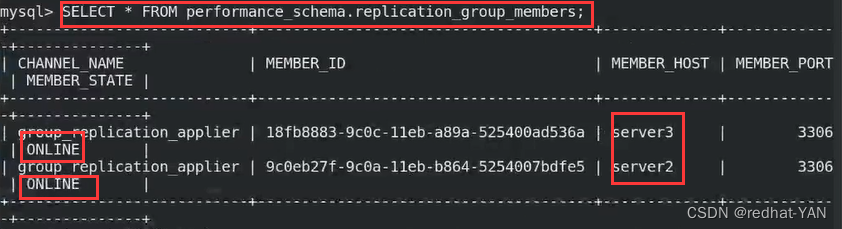
宿主机(客户端)
断开数据库连接,再查看一次,它自动连接上(客户端重新连接了)
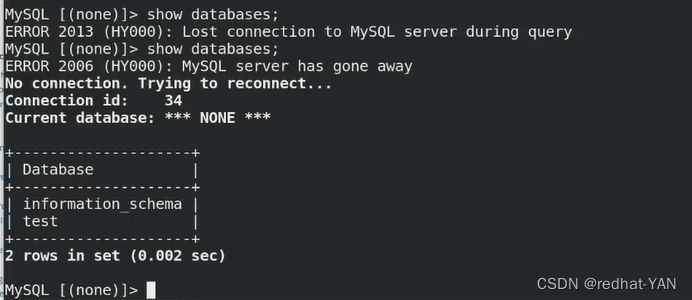
连接到server2上了

宿主机(客户端)
插入没有问题

后端集群还是可以用
server3:

恢复server1:
server1:


加入集群,否则不在集群中

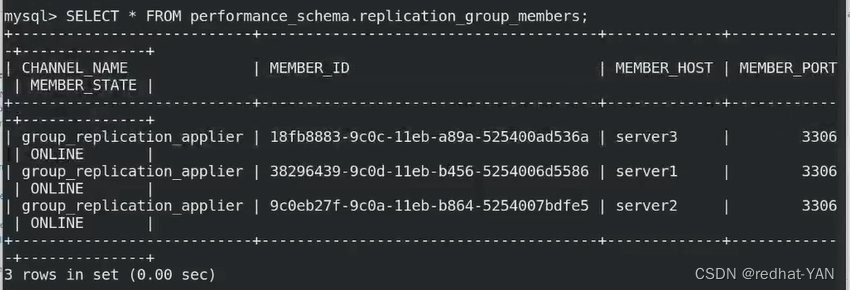 这个模式是GTID的形势(多主)
这个模式是GTID的形势(多主)
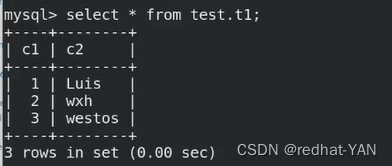
看看数据恢复没
数据恢复正常
停掉mysql路由为下面实验清理环境

七、总结
分表是垂直分(一个节点上深入优化)
分库是水平分(分到多个结点,水平扩容)
数据库读写分离,做更多优化需要分库分表
Mysql单表存储数据达到百万级,性能下降快
这个时候需要分库分表
一张大表拆成多个表,这样就不会达到百万
分库分到多个服务器(结点),水平扩容
可以通过MyCAT应用软件去做也可用通过后端数据库做好,在应用层(代码),在写代码直接高速读在那块读,写在那块写,应用直接接入数据库更快,效率最高,因为中间不需要代理,没有损耗
但是没有损耗意味着这种方式麻烦,开发应用的时候要完全知道数据库的变化,类似是写死了,代码写好了,一旦后续数据库变动,代码就需要更改很多
实际情况,后端数据库实例特别多,不好用直接代码写死,最好都是用代理层,提供一个统一的接入,接入后再由代理做相应的控制,这样好,而且还可以在代理层,做相应的缓冲(nosql),进一步减少数据库后端的压力,数据库是一个热点,应用都是从数据库里调数据,数据库一旦坏了,整个应用就报废了
END
系列文章目录
Mysql集群及高可用-Mysql高可用MHA
mysql集群及高可用
- 系列文章目录
- 一、mysql主从复制
- 二、mysql主从配置server1(主库master)
- 三、mysql主从配置server2(从库,slave)
- 四、测试
- 五、主机重启服务后,二进制日志文件变化
- 六、mysldump导入(备份)书库工具
- 七、主从复制两种形式
- 八、a->b->c形势的主从复制配置
- 九、测试a->b->c主从形势
- 十、主从意义与缺点
- 系列文章目录
- 一、 Mysql集群-Gtid官方文档
- 二、 主从架构与gtid架构对比
- 三、配置gtid(一组两从架构)
- 四、验证
- 系列文章目录
- 一、重启服务器需要检查的模块
- 二、主从工作原理
- 三、ok过程详情细节(半同步模式)原理
- 四、半同步模式5.7以前对比(AFTER_COMMIT与AFTER_SYNC)
- 系列文章目录
- 一、Mysql集群-半同步模式官方文档
- 二、Mysql集群-半同步模式配置
- 三、测试
- 系列文章目录
- 一、Mysql集群-并行复制(sql线程的优化)
- 二、Mysql集群-并行复制的配置
- 系列文章目录
- 一、Mysql集群-延迟复制
- 二、Mysql集群-延迟复制配置
- 系列文章目录
- 一、Mysql集群-慢查询
- 二、慢查询配置
- 三、测试
- 系列文章目录
- 一、Mysql集群-主复制
- 二、容错机制(组模式)
- 三、配置多主复制
- 四、测试
- 五、Mysql路由(通过连接不同端口实现路由)(读写分离)
- 六、测试
- 七、总结
- 系列文章目录
- 一、Mysql集群-高可用MHA
- 二、实验环境准备
- 三、Gtid模式一主两从
- 四、MHA配置
- 五、配置主配置文件
- 六、高可用手动切换
- 七、自动切换
- 八、书写脚本让perl程序一直监控数据库实例
一、Mysql集群-高可用MHA
主复制是内部高可用是官方的,节点最多9个
实际情况节点更多,也需要主从架构
MHA利用了主从复制原理
Mysql高可用的架构一般都利用了主从复制,所以Mysql的重点是弄懂它的二进制日志
数据的一致性、备份、恢复都是依靠二进制日志
去中心化的架构往往比较重量级,相对操作比较复杂
一个节点需要装MHA Manger 在数据库(一主两从)需要安装MHA node
即server4 安装MHA所有包
server1、2、3 安装MHA node(都是操作二进制日志的工具包)
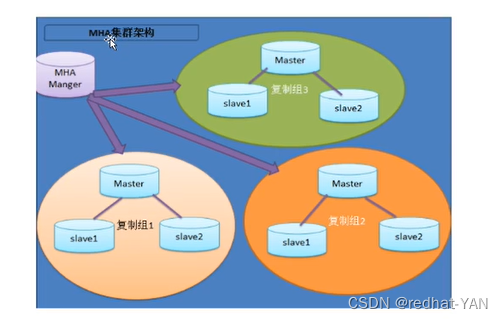
二、实验环境准备
1.在server4上停掉刚才做的Mysql路由服务system stop mysqlrouter.service
2.拆掉多主server1、2、3,即停掉mysql数据库
/etc/init.d/mysqld stop
3.清理掉server1、2、3数据目录里的数据(之前的数据是针对主复制的)
cd /usr/loacl/mysql/data
rm -fr *
4.server1、2、3修改配置/etc/my.cnf文件,恢复成主从架构,一主两从的架构
所有节点配置一样,因为组从高可用切换,原先是slave可能会变成master
server3:
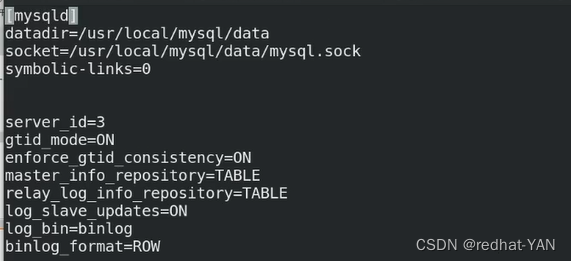
server1:
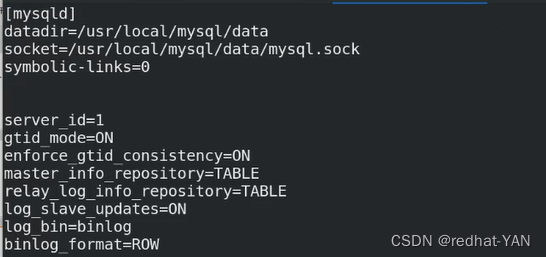
server2:
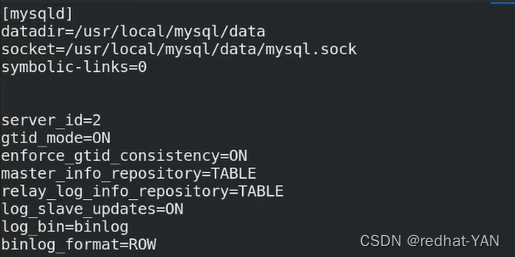
5.server1、2、3修改/etc/my.cnf后初始化mysql
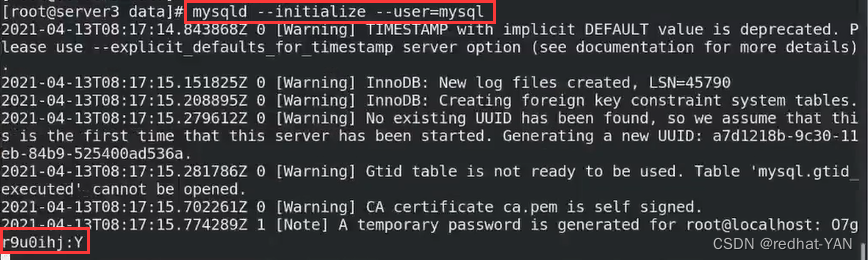
6.server1、2、3启动mysql/etc/init.d/mysqld start
三、Gtid模式一主两从
server1(master):
使用初始化后的临时密码后进入数据库
生产环境,在初始化后推荐使用安全初始化家脚本后进入数据库,
因为这样可以控制权限更安全
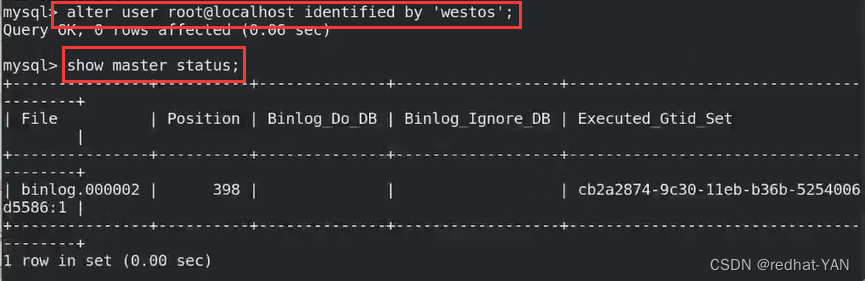
授权

server2(slave):
使用初始化后的临时密码后进入数据库

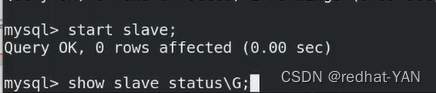

同理server3


四、MHA配置
下载MHA(还要下载它的依赖性,我是把MHA和它所需的依赖性都放在MHA包里面了)
我提前下载好直接取,我下载的是0.58版本(支持gtid),之前版本只支持pos号
server4:
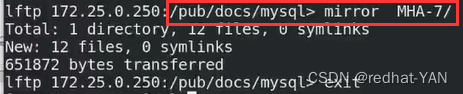
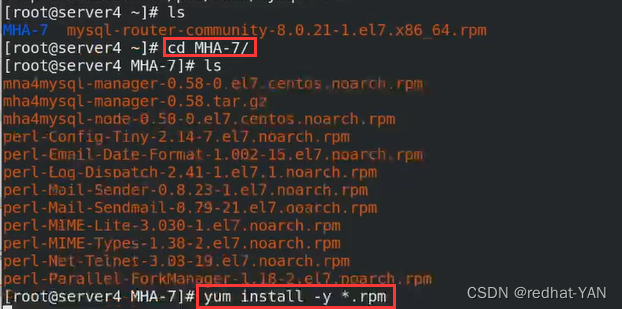
有大量的复制,所以需要做免密
ssh-keygen
后面提示全是回车就行
这个操作给server1、2、3
ssh-copy-id server1
ssh-copy-id server2
ssh-copy-id server3
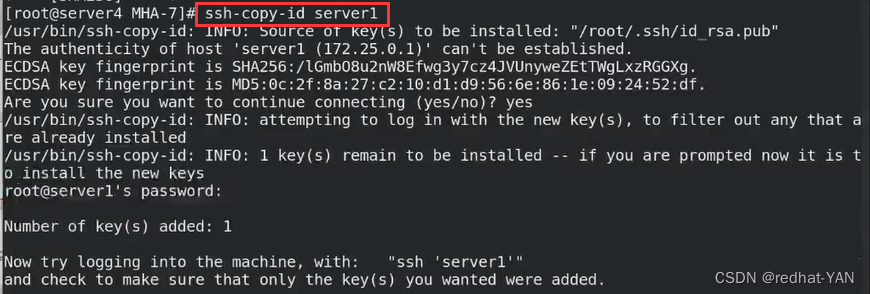
将node安装包给server1、2、3
server1:
安装Node包,同理server2、3(不截图了)

Node包都是一些操作二进制日志工具的包
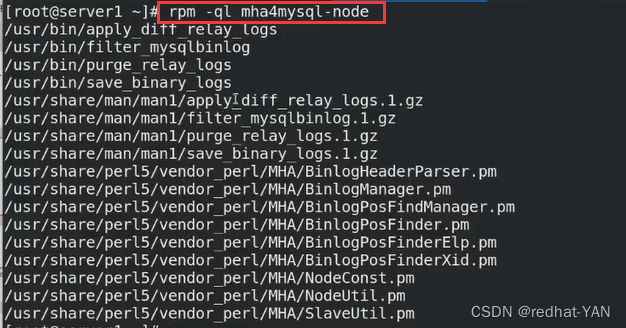
第一个diff是差异的工具(针对relay_log)
第二个filter过滤的工具(binlog)
第三个purge回收的工具(relay_log)
第四个save保存的工具(binlog)
server4:
Manager包
都是二进制指令,没有配置文件
check_ssh检测各个节点的连通性
check_repl检测主从复制是否完整
manager MHA后台管理节点
check_status检测MHA状态
master_monitor监控
master_switch手工的故障切换
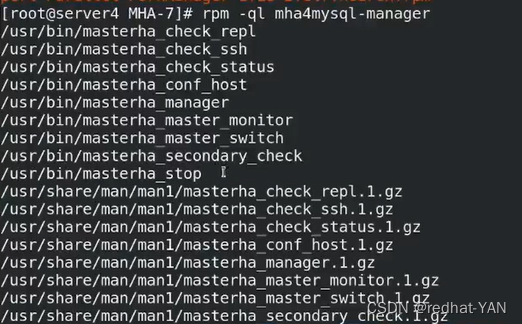
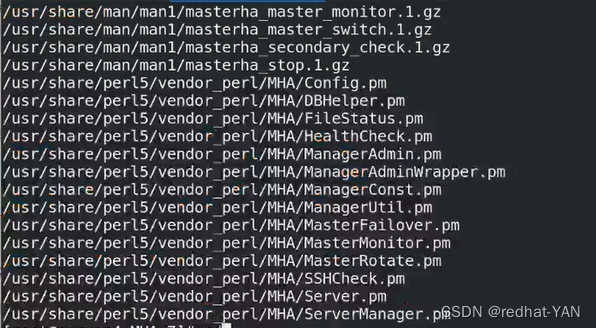
工具包总结:

五、配置主配置文件
server4:

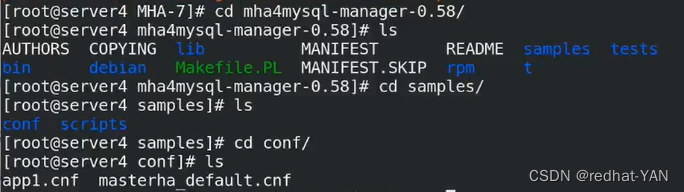
conf理解每个server(每个数据库实例的配置,写入每个数据库的主,从)
global(除了主从其它信息写入这)
app1.cnf针对数据库实例的配置,每个实例是一个管理进程,app1单独创建由manager来启动
manager进程可以读取不同的app1来启动
我的习惯是只写一个,因为目前只有一个实例
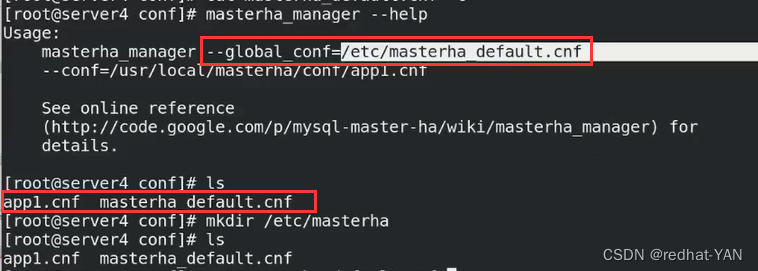
将两个配置写成一个


server default就是global
user是数据库用户管理员的名(管理员必须能远程登录)
需要通过管理员用户登录到远程数据库执行相应的指令,比如change master to
password数据库管理员的密码
ssh user 是操作系统的root(需要免密)主机节点server4装了很多工具包的指令,需要通过操作系统的root免密去调相应的二进制程序来做相应的操作(对你的二进制日志)
repl_user和repl_password主从里面的复制用户和密码
remote_workdir远程工作目录(随意指)
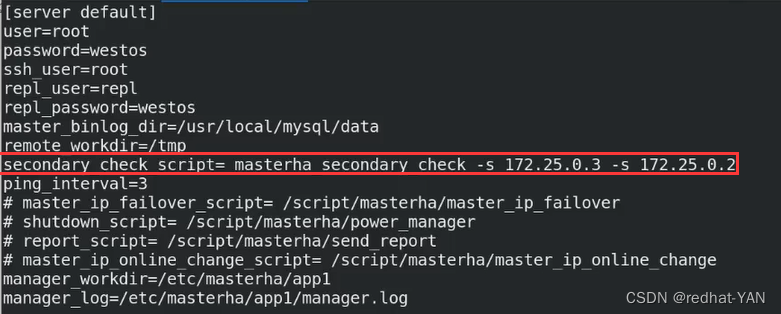
secondary脚本(二层网络检测)
如果manager和后端的网络出现故障,第一个ip是网内其它节点(判断是不是manager网络是否有问题),第二个再写远程数据库(判断是其它数据库出现问题)
manager出现故障,其实Mysql集群是好的,不可能在集群内做故障切换
我写的第二个是3,因为3一般是slave我不会切换它,第一个指向250(宿主机的地址)
ping是每隔3s
工作目录和日志设置到那块就去那块看
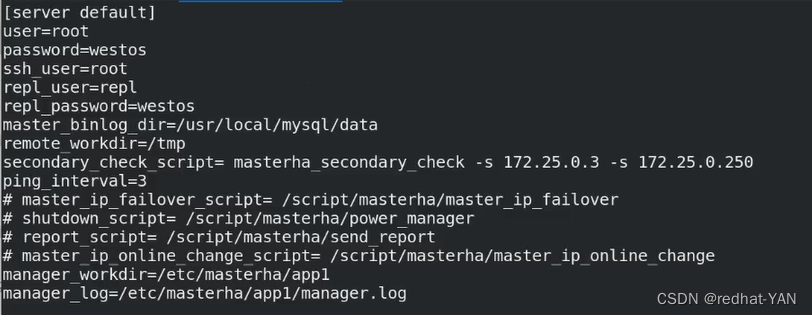
实例
server1是master
server2是备用master(1挂了会接管)
server3默认情况下不会接管
1挂了2接管,1恢复后,2挂了,1接管
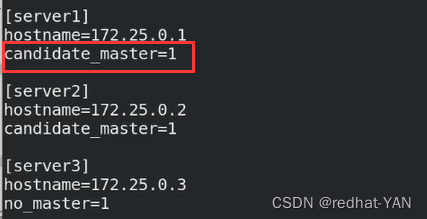
所以现在一主两从架构,主要1和2接管,3始终处于备用状态
校验各个节点的免密连接

我是两个文件写到一个文件了,所以会有Warning,但是没有关系,跳过了
1免密2,连接错误了Permission denied
2也连接1,可以发现是需要彼此间都需要免密
要求的manage可以对集群所有服务器都能免密,服务器间能互相免密
即server4对server1、2、3都能免密,server1、2、3间互相免密
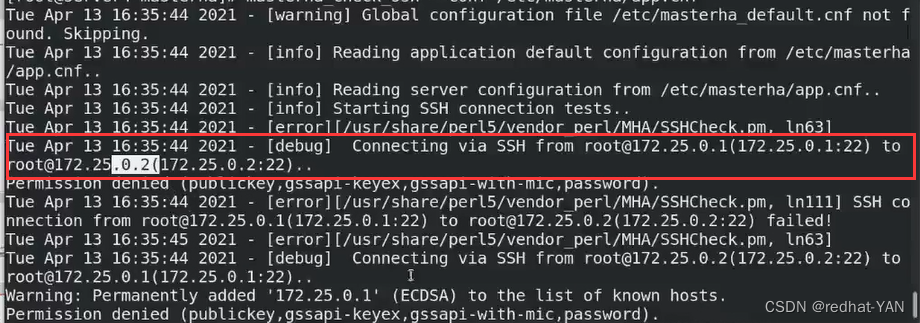
做免密,在server1、2、3 上面做ssh-keygen ssh-copy-id server1、2、3、 太麻烦
server4直接把这个目录(之前server4对1、2、3做过免密)给server1、2、3就行了(大家使用同一个公钥,密钥对一样)
彼此免密server4要对自己也免密
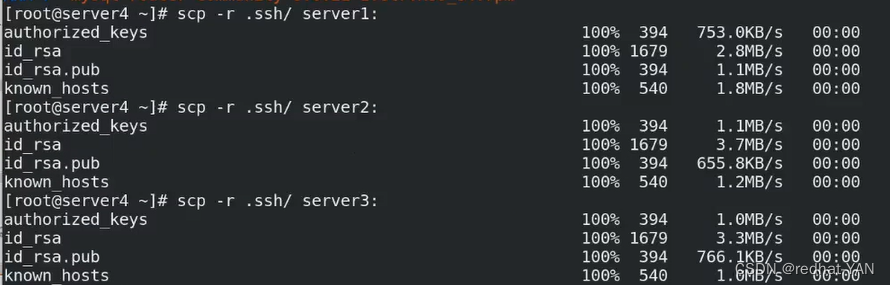
server4:

检测成功后检测主从
免密和主从的检测都必须通过后才能做后续的

root远程免密失败,默认情况下管理员没有远程登录的权限
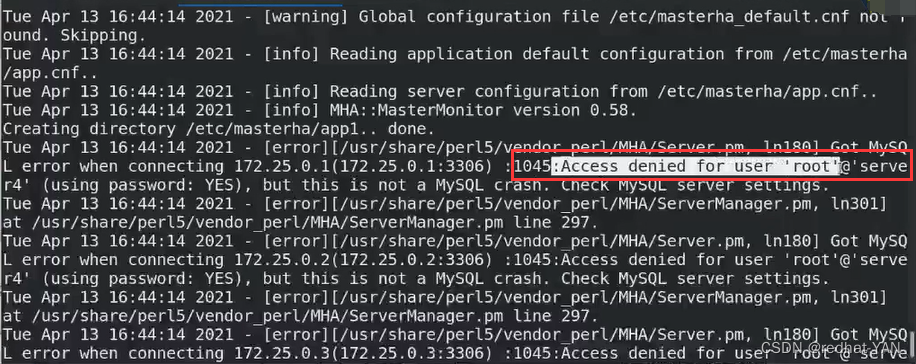
server1:
进入数据库后授权
server4:
再次检测脚本,但是告知shutdown脚本master_ip脚本没有

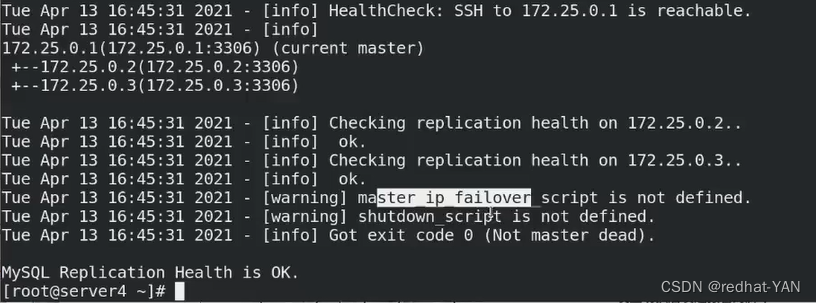
六、高可用手动切换
6.1状态一(master在线状态)
手动切换分为2种masterha_master_switch
第一种是维护状态(比如server1,要更换下硬件或者维护一下需要切换到server2)master端是活着的,第二种是挂掉了
数据库默认端口是3306但是有时候为了安全可能会变,根据实际情况自己写
orig_master_is_new_slave(数据库是活的,通过数据库的root SA,密码登上去把原来的master切换成新的slave)
running_updates_limit超时时间

server4:

刷新,这个时候不要写二进制日志了(别切换的过程中丢数据了)YES

询问你是不是要把master从1变成2,YES
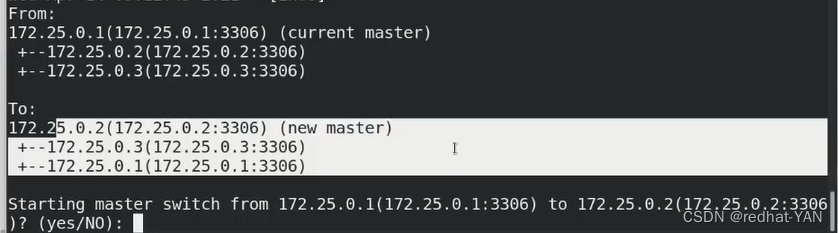
在线手动切花需要调动脚本,脚本的意义在于创建和回收vip(漂移vip),高可用必须要有vip支撑,要不然外部的客户端,原本访问1的,现在切到2,客户端不知道,让客户端重新连接不合适,所以切换的时候保持主从vip不变,YES
现在没有这个脚本,也没有VIP,就正常切换(不用考虑那么多)

切换的过程会做锁表动作,保证切换过程中,不能频繁写入,造成数据不一致的情况
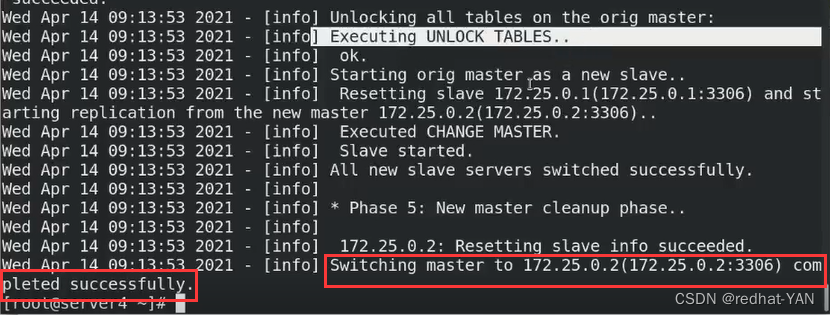
直接用chek_repl可以查看到当前的状态

server2是master
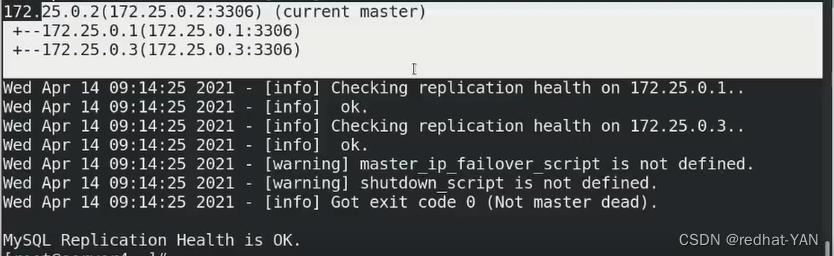
server2:
进入数据库后
可以发现slave是空的,所以再次验证它是master
server1、3
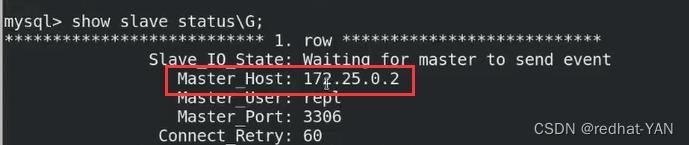
6.2状态二(master挂掉状态)
server2:

停掉后,外部没有监控不可能自动切换的,想用Mysql本身的高可用不用外部监控,只能用MGR
server1、3:



server4:
–ignore_last_failvor

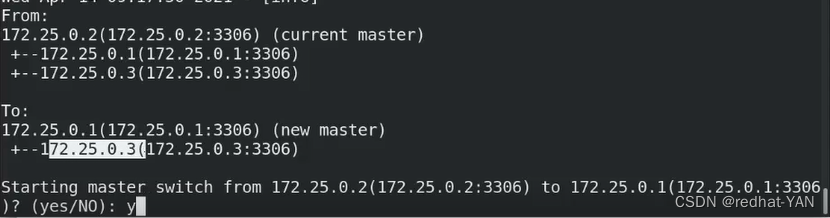
询问你是不是原先的master挂掉了YES

询问是是不是要把master从2变成1YES
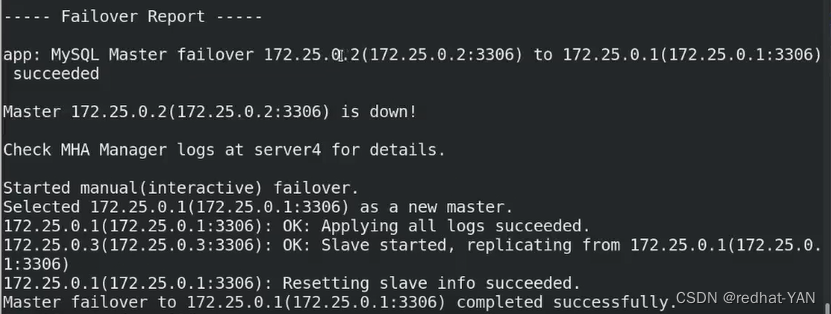
故障切换完成
执行完后,app1多出文件
空文件就是个锁定文件(避免服务的抖动)
(下次执行的时候,–ignore参数就是忽略这个文件)
–ignore_last_failvor
因为一旦发生故障切换后(现在就是故障切换2到1)活着的状态不会生成
切换是没问题的,但是不希望频繁切换,比如网络抖动出现1切2,2切别的机器
每次做完故障切换就会生成这个文件,它会在8h内再做切换,因为你频繁切换任务你服务不稳定,是抖动状态
如果你有这个频繁切换的需求就可以加上这个选项--ignore_last_failvor (忽略这个文件)或者进入目录后直接删掉

server3:

测试成功
手动切换没有日志
在cat /etc/masterha/app.cnf主配置文件中定义了
里面只有manager_log,因为手动切换的过程中就加载了日志,很详细

手动切换过程中的,记录的很详细
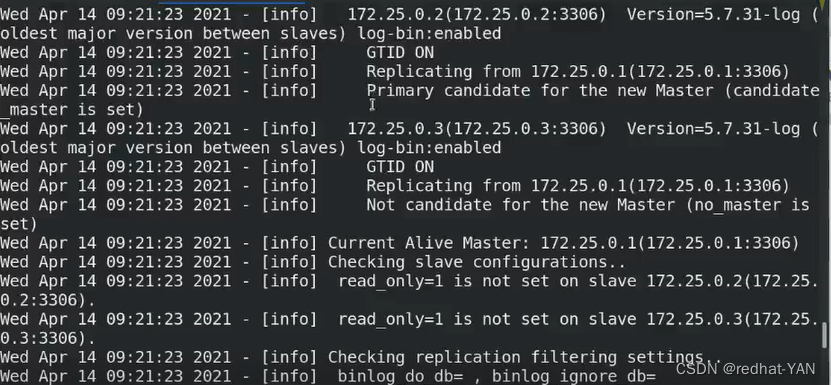
server2:
还原实验环境状态
恢复数据库服务

进入数据库
show slave status\G;


server4:
再次检测

状态是好的
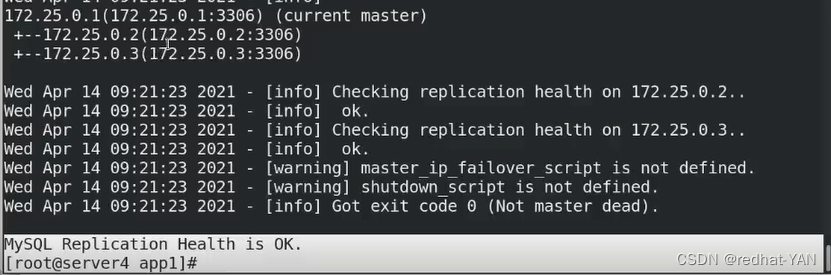
七、自动切换
server4:
由于上面有锁定文件,所以需要删掉


perl程序,perl运行的

这个进程做完一次故障切换后就自动退出了,避免来回的切
希望在后端保持监听(写个脚本或者demotools后台维护)持续在后端运行着
这个进程专门管控/etc/masterha/app.cnf这个文件写的的数据库实例的,一旦做完高可用就退出了,所以可以创建多个数据库实例的文件,然后启动多个进程,每个进程监控一个实例,推荐每个文件(进程)监控一个数据库实例,做完切换后自动退出
测试
1现在是Master

每3s检测一次节点的连通性,当发现server1出现故障的时候,开始自动切换Master
perl进程开始启动开了
检测,然后ssh
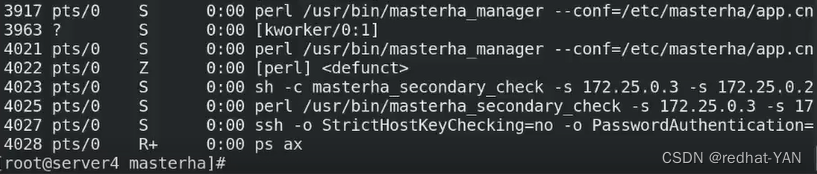
进程没停止,然后server2show slave status\G;仍然有信息
出错了
查看日志
免密有问题,监控主机0.250不可到达
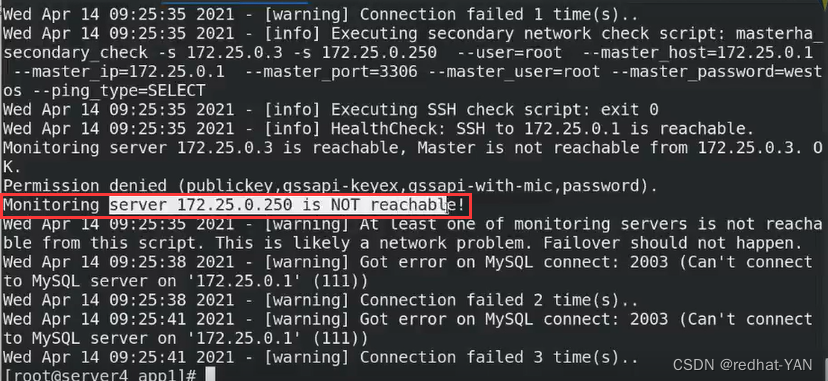


换成2和3,这样方便做实验(生产环境尽量是网内其它节点,判断是不是manager网络是否有问题)
重新测试



进程响应,一旦做完切换,进程就自动退出了
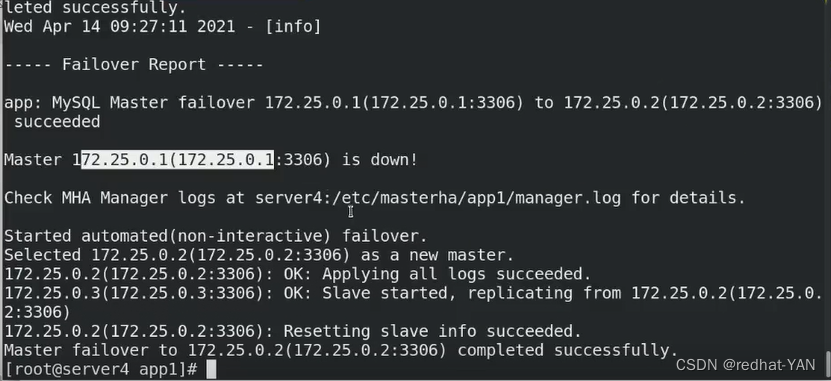
server3:
切换过去了

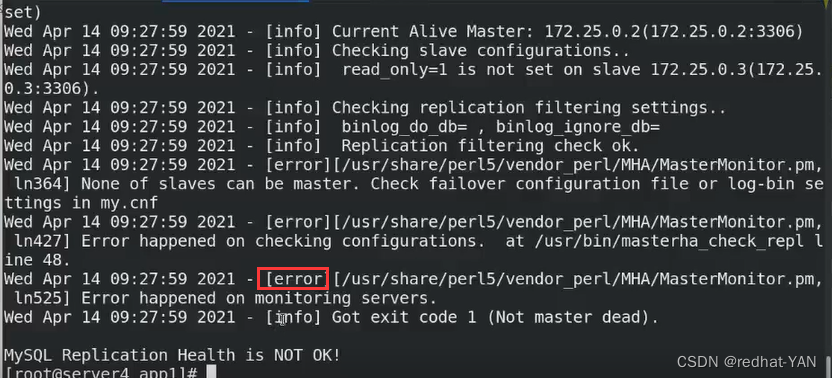
server4:

not ok
因为现在1挂了,不满足一主两从的结构
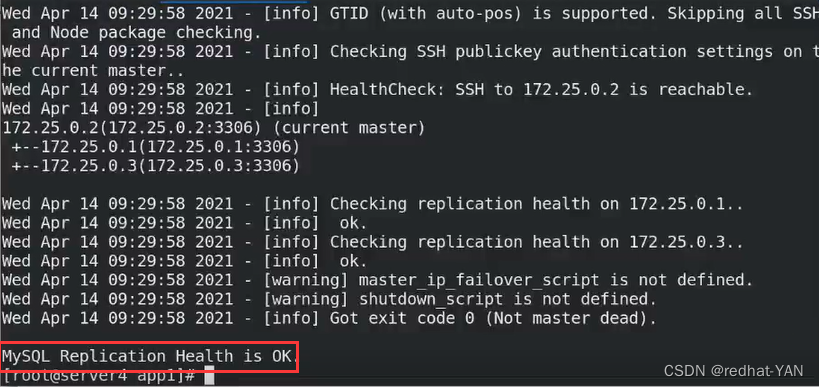
server1:
进入数据库


show slave status\G;

server4:

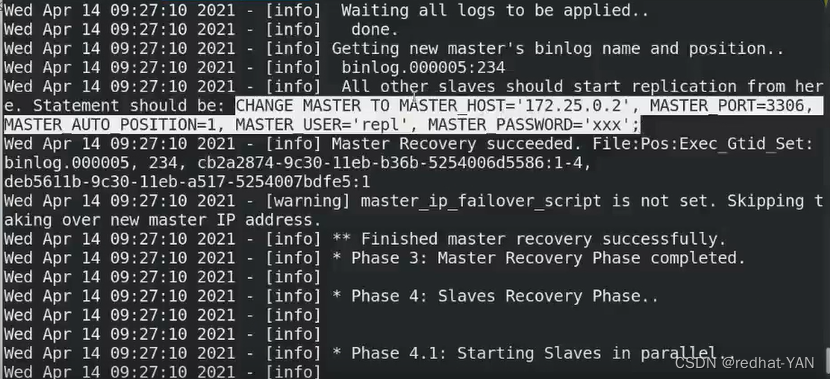
自动切换,不显示日志,需要到主配置文件中指定的日志目录查看
和手动切换记录的日志其实是差不多的

可以发现获取新master的二进制日志目录和pos号
通过远程方式连接数据库实例,执行相应的change master to 等
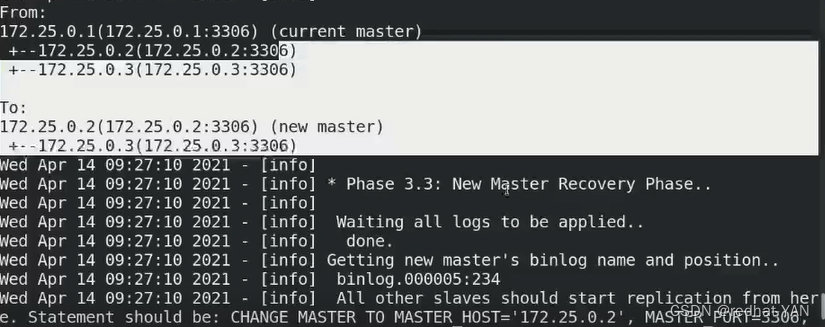
实际情况更推荐手动切换,数据库维护的过程中需要小心一些,数据库太核心了
万一数据一致性有问题,会造成损失
不是特别重要的实例可以自动切换,如果数据库实例特别重要,尽量用手动切换,确保数据一致性后再切换会更加的稳妥
八、书写脚本让perl程序一直监控数据库实例
server4:
用到上面没有用到的vip,脚本放在我的服务器中pub/docs/mysql/master_ip_failover

一个是自动切换,一个是手动切换
online是手动切换的时候,vip的飘逸调动的脚本
自动切换调用failover

由于是脚本所以需要加上x权限
这两个脚本是根据作者的源码例子改的
power_manager是不完整的,打开后,需要根据实际的情况来修改,因为不知道你是什么设备

send_report 需要接入到公司实际的邮件服务器上面

需要把vip改成自己的,启动vip的时候是通过ssh执行了ip的指令来添加/摘除到eh0接口上vip(根据自己的接口情况写),接口不是eth0需要更改
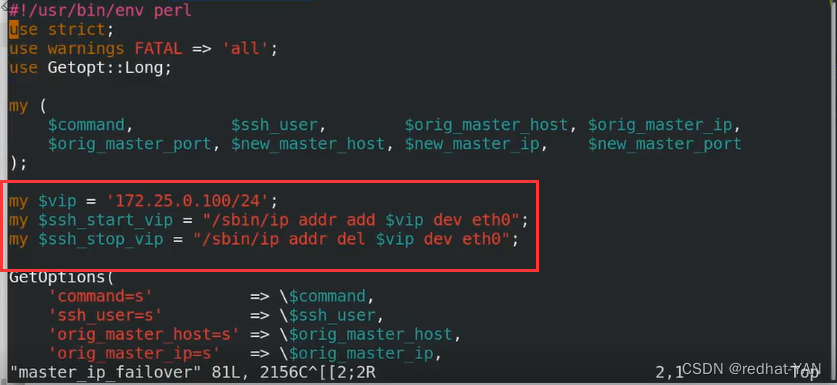
一样的

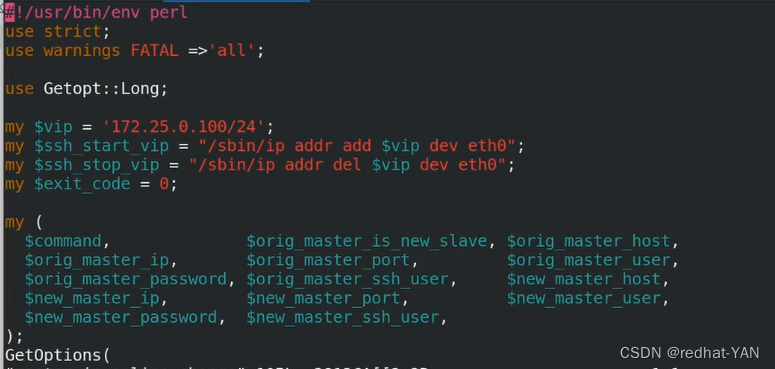
模拟
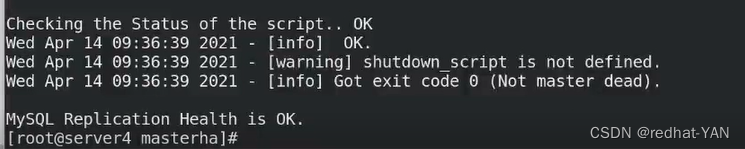
检测成功

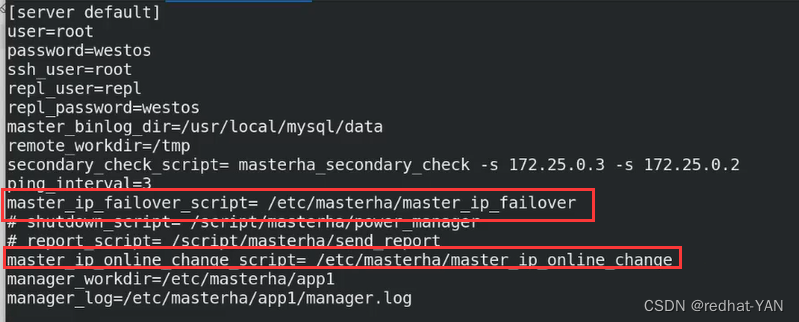
修改主配置文件将这两个参数打开

再次测试

2是master

宿主机:
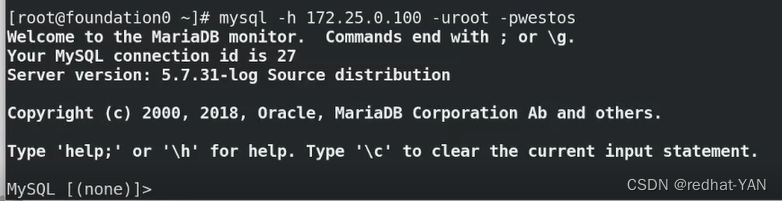
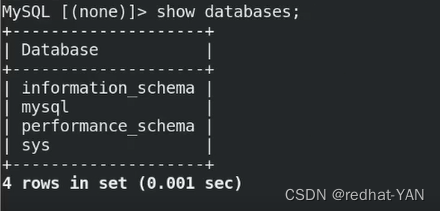
server4:
将master切换到1(手动切换)两个YES

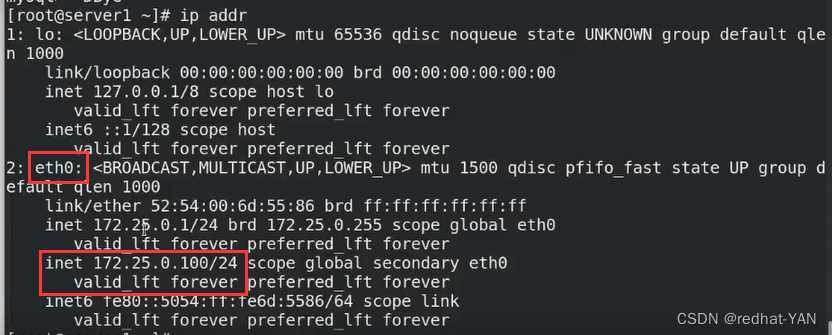
server1:
server1加入VIP了,调用脚本成功
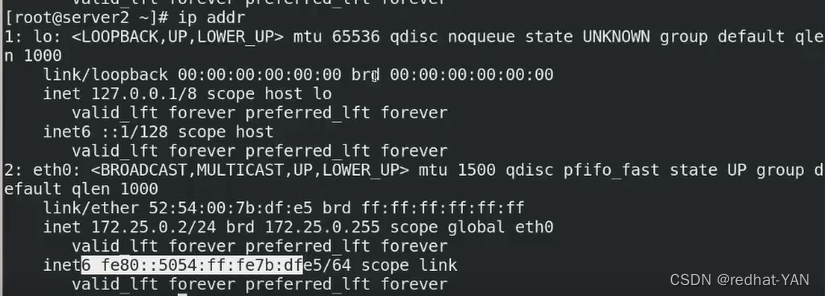
server2:
vip被摘取了
宿主机:
因为变更了数据库实例,因为VIP有2漂移到1上面了,会卡一下,但是没有关系,客户端数据库会重连的
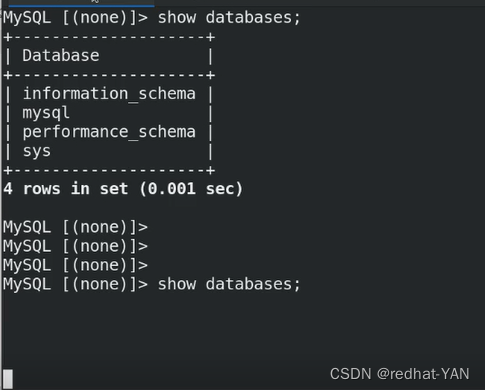
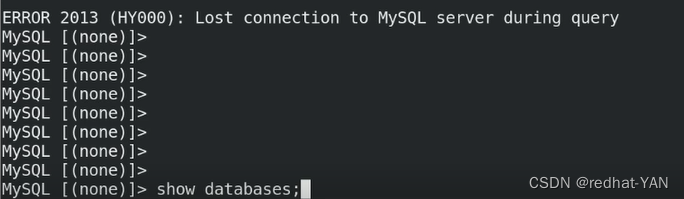
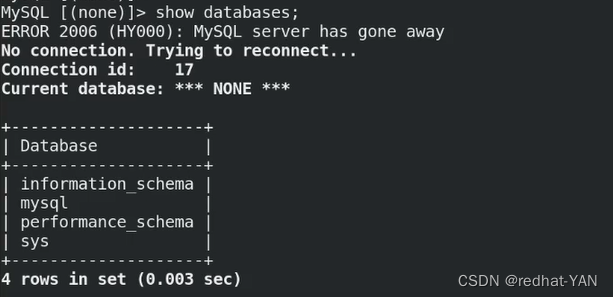
测试成功
再次做一次检测


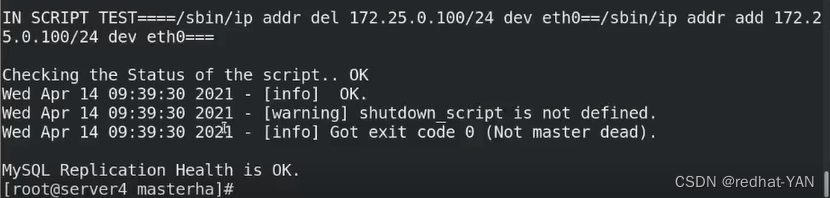
现在1是master,2、3是slave
测试自动切换
server4:
将锁定文件删掉
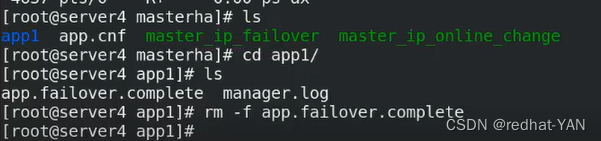


server1:

server2:
之前切换到server1的时候vip被摘取了
server1:
如果不想看见这些信息,当时的2个文件就不要写成一个文件,global文件也存在就没有这个信息

server4:
进程已经退出了

app1又生成锁定文件,manager.log记录了切换的过程

因为0.1已经挂了
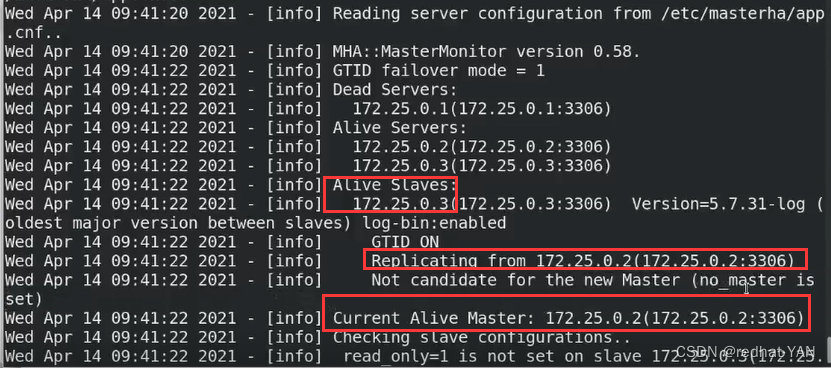

也可以看这个

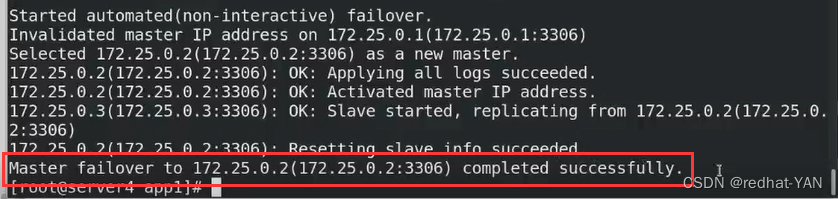
server3:
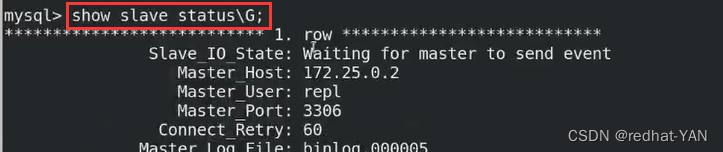
server2:
VIP已经漂移到server2了
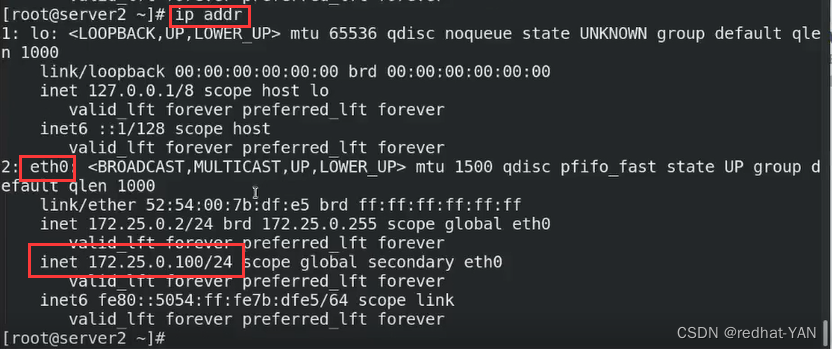
server1:
上面的VIP没有了
宿主机:
客户端是没有反应,是透明的

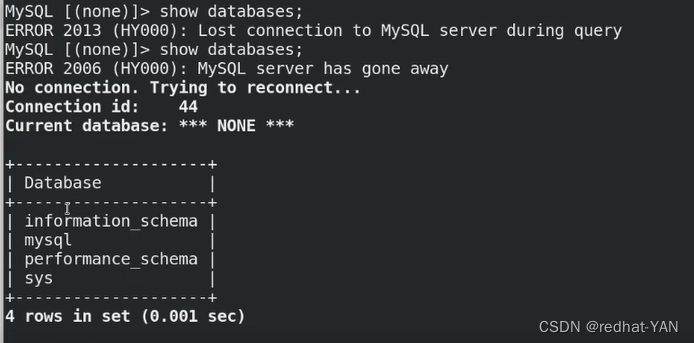
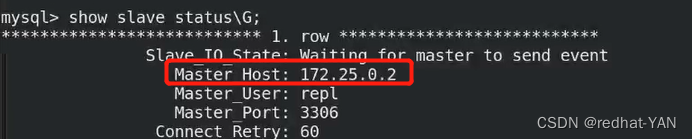
server1:
需要手工恢复加入集群


END

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!