Pytorch实战——3、数据加载与处理
🍅 写在前面
👨?🎓 博主介绍:大家好,这里是hyk写算法了吗,一枚致力于学习算法和人工智能领域的小菜鸟。
🔎个人主页:主页链接(欢迎各位大佬光临指导)
??近期专栏:机器学习与深度学习
???????????????????????LeetCode算法实例
transforms——Crop
-
torchvision.transforms.CenterCrop(size)- 功能:从图像中心裁剪图片
- size:所需裁剪图片尺寸
-
torchvision.transforms.RandomCrop(size, padding=None,
pad_tf_needed=False, fill=0, padding_mode=‘constant’)- 功能:从图片中随机裁剪出尺寸为size的图片
- size: 所需裁剪图片尺寸
- padding: 设置填充大小
当为a时,上下左右均填充a个像素;
当为(a, b)时,上下填充b个像素,左右填充a个像素;
当为(a, b, c, d)时,左、上、右、下分别填充a、b、c、d。 - pad_if_need: 若图像小于设定size,则填充
- padding_mode: 填充模式,有4种模式
ⅰ. constant: 像素值由fill设定
ⅱ. edge: 像素值由图像边缘像素设定
ⅲ. reflect: 镜像填充,最后一个像素不镜像
ⅳ. symmetric: 镜像填充,最后一个像素镜像 - fill: constant时,设置填充的像素值
-
torchvision.transforms.RandomResizedCrop(size, scale=(0.08, 1.0),
ratio=(3/4, 4/3), interpolation=2)- 功能:随机大小、长宽比裁剪图片
- size: 所需裁剪图片尺寸
- scale: 随机裁剪面积比例,默认(0.08, 1)
- ratio: 随机长宽比,默认(3/4, 4/3)
- interpolation: 插值方法
PIL.Image.NEAREST
PIL.Image.BILINEAR
PIL.Image.BICUBIC
-
torchvision.transforms.FiveCrop(size)
-
torchvision.transforms.TenCrop(size, vertical_flip=False)
- 功能:在图像的上下左右以及中心裁剪出尺寸为size的5张图片,TenCrop对这5张图片进行水平或者垂直镜像获得10张图片
- size: 所需裁剪图片尺寸
- vertical_flip: 是否垂直翻转
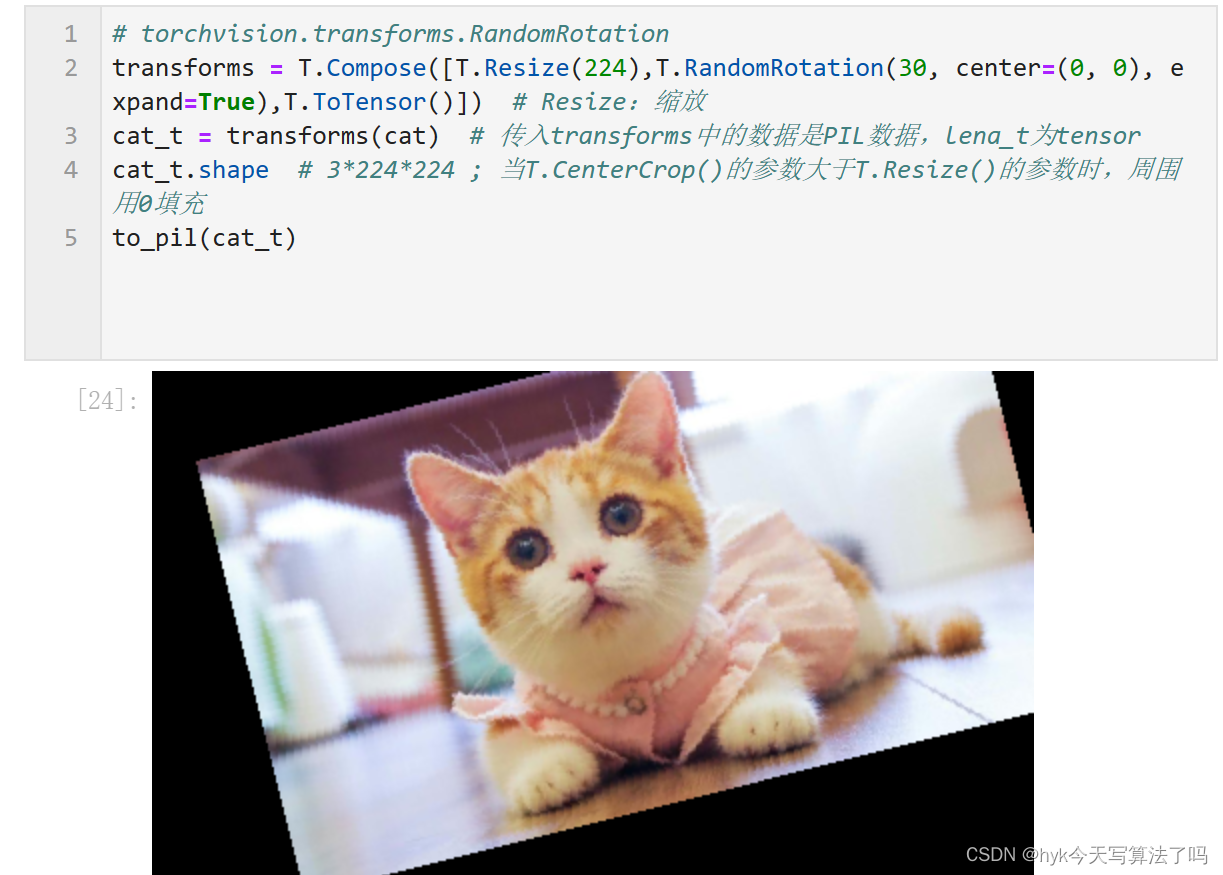
# torchvision.transforms.CenterCrop
transforms = T.Compose([T.Resize(224),T.CenterCrop(224),T.ToTensor()]) # Resize:缩放
cat_t = transforms(cat) # 传入transforms中的数据是PIL数据,lena_t为tensor
cat_t.shape # 3*224*224 ; 当T.CenterCrop()的参数大于T.Resize()的参数时,周围用0填充
to_pil(cat_t)

# torchvision.transforms.RandomCrop
transforms = T.Compose([T.Resize(224),T.RandomCrop(224, padding=(16, 64)),T.ToTensor()]) # Resize:缩放
cat_t = transforms(cat) # 传入transforms中的数据是PIL数据,lena_t为tensor
cat_t.shape # 3*224*224 ; 当T.CenterCrop()的参数大于T.Resize()的参数时,周围用0填充
to_pil(cat_t)

transforms——Flip
-
torchvision.transforms.RandomHorizontalFlip(p=0.5)
-
torchvision.transforms.RandomVerticalFlip(p=0.5)
- 功能:依据水平(左右)或垂直(上下)翻转图片
- p: 翻转概率
-
torchvision.transforms.RandomRotation(degrees, resample=False,
expand=False, center=None)- 功能:随机旋转图片
- degrees: 旋转角度
当为a时,在(-a, a)之间选择旋转角度;
当为(a, b)时,在(a, b)之间选择旋转角度。 - resample: 重采样方法
- expand: 是否扩大图片,以保持原图信息

图像变换
-
torchvision.transforms.Pad(padding, fill=0, padding_mode=‘constant’)
- 功能:对图像边缘进行填充
- padding: 设置填充大小
当为a时,上下左右均填充a个像素;
当为(a, b)时,上下填充b个像素,左右填充a个像素;
当为(a, b, c, d)时,左、上、右、下分别填充a、b、c、d。 - padding_mode: 填充模式,有4种模式,constant、edge、reflect和symmetric
= fill: constant时,设置填充的像素值,(R, G, B)or(Gray)
-
torchvision.transforms.ColorJitter(brightness=0, contrast=0,
saturation=0, hue=0)- 功能:调整亮度、对比度、饱和度和色相
- brightness: 亮度调整因子
- contrast: 对比度参数,同brightness
- saturation: 饱和度参数,同brightness
- hue: 色相参数
-
torchvision.transforms.Grayscale(num_output_channels=1)
-
torchvision.transforms.RandomGrayscale(p=0.1)
- 功能: 依概率将图片转换为灰度图
- num_output_channels: 输出通道数,只能设置为1或3
- p: 概率值,图像被转换为灰度图的概率
-
torchvision.transforms.RandomAffine(degrees, translate=None,
scale=None, shear=None, resample=0, fillcolor=0)- 功能:对图像进行仿射变换,仿射变换是二维的线性变换,由五种基本原子变换构成,分别是旋转、平移、缩放、错切和翻转
- degrees: 旋转角度设置
- translate: 平移区间设置,如(a, b),a设置宽(width),b设置高(height),图像在宽维度平移区间为 -img_width a < dx < img_width a
- scale: 缩放比例(以面积为单位)
- fill_color: 填充颜色设置
- shear: 错切角度设置,有水平错切和垂直错切
若为a,则仅在x轴错切,错切角度在(-a, a)之间;
若为(a, b),则a设置x轴角度,b设置y的角度;
若为(a, b, c, d),则a、b设置x轴角度,c、d设置y轴角度。 - resample: 重采样方式,有NEAREST、BILINEAR、BICUBIC
-
torchvision.transforms.RandomErasing(p=0.5, scale=(0.02, 0.33),
ratio=(0.3, 3.3), value=0, inplace=False)- 功能:对图像进行随机遮挡
- p: 概率值,执行该操作的概率
- scale: 遮挡区域的面积
- ratio: 遮挡区域长宽比
- value: 设置遮挡区域的像素值,(R, G, B)or(Gray)
- 参考文献:《Random Erasing Data Augmentaion》
-
torchvision.transforms.Lambda(lambd)
- 功能: 用户自定义lambda方法
- lambd: lambda匿名函数
例如:transforms.Lambda(lambda crops: torch.stack([transforms.Totensor()(crop) for crop in crops]))
自定义transforms
自定义transforms要素:
1、仅接收一个参数,返回一个参数
2、注意上下游的输出与输入
class Compose(object):
def __call__(self, img):
for t in transforms:
img = t(img)
return img
通过类实现多参数传入:
class YourTransforms(object):
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, img):
for t in self.transforms:
img = t(img)
return img
椒盐噪声又称为脉冲噪声,是一种随机出现的白点或者黑点,白点称为盐噪声,黑色为椒噪声。
信噪比(Signal-Noise Rate,SNR)是衡量噪声的比例,图像中为图像像素的占比。
class AddPepperNoise(object):
def __init__(self, snr, p):
self.snr = snr
self.p = p
def __call__(self, img):
# 添加椒盐噪声具体实现过程
img = None
return img
transforms方法汇总
裁剪:
a. transforms.CenterCrop
b. transforms.RandomCrop
c. transforms.RandomResizedCrop
d. transforms.FiveCrop
e. transforms.TenCrop
翻转和旋转:
a. transforms.RandomHorizontalFlip
b. transforms.RandomVerticalFlip
c. transforms.RandomRotation
图像变换:
a. transforms.Pad
b. transforms.ColorJitter
c. transforms.Grayscale
d. transforms.RandomGrayscale
e. transforms.RandomAffine
f. transforms.LinearTransformation
g. transforms.RandomErasing
h. transforms.Lambda
i. transforms.Resize
j. transforms.Totensor
k. transforms.Normalize
transforms的操作:
a. transforms.RandomChoice
b. transforms.RandomApply
c. transforms.RandomOrder
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 三体攻击问题(三维数组的前缀和 与 差分)(上篇)
- 【hcie-cloud】【17】华为云Stack灾备服务介绍【灾备方案概述、备份解决方案介绍】【上】
- HotRC DS600遥控器+F-06A接收机
- 再见2023,你好2024!
- 从零开始学习vivado——day 3 时序逻辑设计之计数器
- 200倍速!基于 HDF5 的证券数据存储方案
- ubuntu安装vim报Package vim has no installation candidate
- Linux awk命令教程:如何有效处理文本和数据分析(附案例详解和注意事项)
- Mysql的安装配置教程(详细)
- C# FANUC 读写fanuc机床系列