Python连接数据库的梳理
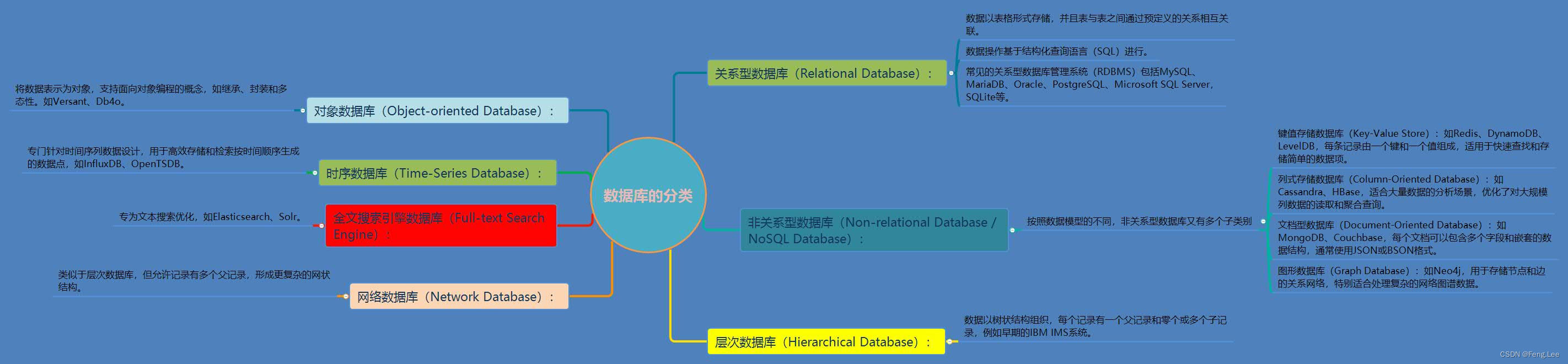
我们通常用的数据库类型主要有关系型数据库,非关系型数据库等,其中关系型数据库主要有Microsoft SQL Server ,MySQL,Oracle,SQLite等,常用的非关系型数据库包括Redis、DynamoDB,MongoDB等
 ???????
???????
一? 关系型数据库
1.使用pymysql库连接MySQL数据库:
import?pymysql# 创建连接conn?=?pymysql.connect(host='localhost',?user='username',?password='password',?db='database_name')# 创建游标cursor?=?conn.cursor()# 执行SQL语句cursor.execute("SELECT?*?FROM?test_table")# 获取查询结果rows?=?cursor.fetchall()# 关闭游标和连接cursor.close()conn.close()
2.使用sqlite3库连接SQLite数据库:
import?sqlite3# 连接SQLite数据库(内存中的数据库或本地文件)conn?=?sqlite3.connect('my_database.db')# 创建一个游标对象cursor?=?conn.cursor()# 执行SQL语句cursor.execute("CREATE?TABLE?IF?NOT?EXISTS?my_table?(id?INTEGER?PRIMARY?KEY,?name?TEXT)")# 插入数据cursor.execute("INSERT?INTO?my_table?VALUES?(?,??)",?(1,?'Alice'))# 提交事务conn.commit()# 查询数据cursor.execute("SELECT * FROM my_table")rows?=?cursor.fetchall()# 关闭连接conn.close()
3.使用psycopg2库连接PostgreSQL数据库:???????
import?psycopg2# 创建连接conn = psycopg2.connect(dbname="test_database",user="username",????password="password",host="localhost")# 创建游标cursor?=?conn.cursor()# 执行SQL语句cursor.execute("SELECT?*?FROM?test_table")# 获取查询结果rows?=?cursor.fetchall()# 提交事务(如果进行了写操作)conn.commit()# 关闭游标和连接cursor.close()conn.close()
4.Python 连接Oracle数据库
安装 cx_Oracle 库:?确保已经安装了Oracle Instant Client以及相应的SDK(对于较新版本的cx_Oracle)。可以使用pip来安装cx_Oracle:
pip install cx_Oracle连接 Oracle 数据库:?以下是一个Python脚本的基本示例,演示如何建立与Oracle数据库的连接:???????
import?cx_Oracle# 设置Oracle数据库连接参数dsn = cx_Oracle.makedsn('hostname', 'port', 'service_name') # 例如:makedsn('mydbserver', '1521', 'orclpdb1')username = 'your_username'password?=?'your_password'# 创建数据库连接connection?=?cx_Oracle.connect(username,?password,?dsn)# 创建游标对象cursor?=?connection.cursor()# 执行SQL查询或命令cursor.execute("SELECT?*?FROM?your_table")# 获取查询结果for row in cursor:????print(row)# 关闭游标和连接cursor.close()connection.close()
二??非关系型数据库
1.Python 连接?MongoDB数据库
MongoDB是一种非关系型数据库,以文档的方式存储数据,在Python中连接MongoDB需要使用第三方库pymongo,以下代码是Pyton链接MongoDB数据库
需要安装MongoDB库???????
pip install pymongofrom?pymongo?import?MongoClient# 创建MongoDB客户端对象,这里假设MongoDB服务运行在本地默认端口27017上client?=?MongoClient('localhost',?27017)# 检查是否成功连接try:client.server_info() # 如果连接成功,会返回服务器信息print("Connected to MongoDB successfully!")except Exception as e:????print(f"Failed?to?connect?to?MongoDB:?{e}")# 连接到一个数据库(假设数据库名为'db_name')db?=?client['db_name']# 选择一个集合(相当于SQL中的表,假设集合名为'collection_name')collection?=?db['collection_name']# 插入一条文档数据document = {'name': 'John Doe', 'age': 30, 'city': 'New York'}collection.insert_one(document)# 查询所有文档for doc in collection.find():????print(doc)# 关闭连接(PyMongo库通常不需要手动关闭连接,它会在程序结束时自动关闭)# client.close()
注意:
-
在生产环境中,你可能需要配置用户名、密码以及认证机制(如SCRAM-SHA-1)来访问MongoDB。
-
MongoDB使用的是JSON-like的数据结构——BSON,因此插入和查询的数据是字典形式。
此外,MongoDB Atlas云服务或企业内部部署的MongoDB实例可能需要指定连接字符串,而非单独的主机名和端口。例如:
client = MongoClient('mongodb+srv://username:password@cluster0.mongodb.net/test?retryWrites=true&w=majority')2.Python 连接Redis数据库
安装 redis-py 库:
pip install redis连接 Redis数据库:?以下是一个Python脚本的基本示例,演示如何建立与Redis数据库的连接:
import?redis# 创建Redis连接对象,这里假设Redis服务运行在本地默认端口6379上r?=?redis.Redis(host='localhost',?port=6379,?db=0)# 检查是否成功连接if r.ping():print("Connected to Redis successfully!")else:????print("Failed?to?connect?to?Redis.")# 设置一个键值对r.set('key',?'value')# 获取键对应的值value = r.get('key')print(f"The?value?of?key?is:?{value}")# 关闭连接(redis-py库通常不需要手动关闭连接,它会自动管理连接池)# r.close()
请根据实际情况调整host和port参数以指向你的Redis服务器地址和端口号。同时,可以通过db参数指定要连接的数据库编号(Redis支持多个数据库,默认为0)
3.Python链接HBase数据库
安装 happybase 库:
pip install happybase连接 HBase 数据库:?以下是一个Python脚本的基本示例,演示如何建立与HBase的连接:
from?happybase?import?Connection# 创建HBase连接对象,这里假设HBase thrift服务运行在本地默认端口9090上connection?=?Connection('localhost',?9090)# 检查是否成功连接try:connection.tables()print("Connected to HBase successfully!")except Exception as e:print(f"Failed to connect to HBase: {e}")# 打开一个表(假设已经存在名为'table_name'的表)table?=?connection.table('table_name')# 插入一行数据table.put(b'row_key',?{'family:qualifier':?b'value'})# 获取一行数据row = table.row(b'row_key')print(row)# 关闭连接connection.close()
注意:
-
在实际生产环境中,可能需要配置Hadoop的安全认证(如Kerberos)才能访问HBase。
-
happybase是基于HBase的Thrift接口进行操作,因此你需要确保HBase集群开启了Thrift服务,并且能够通过网络访问。
此外,如果你正在使用的是较新的HBase版本,可能需要使用Phoenix SQL接口,并配合pyphoenix等库进行连接和操作。
三 Python 连接数据库需要注意的事项?
-
正确安装和配置库:
根据所使用的数据库类型(如MySQL、PostgreSQL、Oracle、Redis、MongoDB等),确保已正确安装并导入相应的Python库。 -
连接管理:
连接资源是有限的,因此应合理管理数据库连接。打开连接后及时关闭,避免资源泄漏。一些库(如pymysql或psycopg2)提供了连接池功能,可以复用连接以提高性能。 -
SQL注入防护:
在构造SQL语句时,尽量使用参数化查询或预编译语句来防止SQL注入攻击。例如,在pandas的read_sql_query函数或者通过ORM方式操作数据库时都会自动处理这个问题。 -
事务处理:
对于涉及到多条SQL命令的操作,需要妥善处理事务,确保数据的一致性。通常要在执行一系列修改操作前后调用begin()和commit()方法(如果所有操作成功则提交事务,否则回滚)。部分库会提供自动提交的功能,但根据具体业务场景可能需要手动控制。 -
错误处理与异常捕获:
在执行数据库操作时,务必进行适当的错误处理,尤其是捕获并处理可能出现的异常,如网络中断、权限不足、表不存在、字段缺失等。 -
数据清洗与验证:
在将数据写入数据库之前,应对数据进行必要的清洗和格式校验,避免不符合数据库约束的数据导致插入失败或其他问题。 -
性能优化:
对于大量数据的操作,考虑使用批量插入或批处理查询来提高效率,减少数据库I/O次数。适当创建索引以加速查询速度,但注意过多索引可能会影响写入性能。 -
安全敏感信息处理:
不要硬编码数据库用户名、密码等敏感信息在代码中,建议采用环境变量或密钥管理服务存储。 -
兼容性和版本匹配:
确保使用的Python库版本与数据库服务器版本兼容,避免因版本不匹配带来的未知问题。 -
资源释放:
使用完游标、连接等资源后,务必确保它们被正确关闭或释放,防止内存泄漏和其他资源占用问题。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- EasyRecovery MAC版怎么使用?数据恢复软件EasyRecovery使用图文教程
- Rust学习笔记005:结构体 struct
- k8s 定义 TCP 的存活探测
- 【算法】递归算法理解(持续更新)
- BDD - Python Behave 配置文件 behave.ini
- 机器学习---clustering
- 旅游MR混合现实情景实训教学系统教学
- springboot笔记
- nodejs+vue+ElementUi医院预约挂号系统3e3g0
- Bootstrap Blazor中的富文本编辑器(Editor)如何禁用?