机器学习(六) — 评估模型
Evaluate model
1 test set
- split the training set into training set and a test set
- the test set is used to evaluate the model
1. linear regression
compute test error
J t e s t ( w ? , b ) = 1 2 m t e s t ∑ i = 1 m t e s t [ ( f ( x t e s t ( i ) ) ? y t e s t ( i ) ) 2 ] J_{test}(\vec w, b) = \frac{1}{2m_{test}}\sum_{i=1}^{m_{test}} \left [ (f(x_{test}^{(i)}) - y_{test}^{(i)})^2 \right ] Jtest?(w,b)=2mtest?1?i=1∑mtest??[(f(xtest(i)?)?ytest(i)?)2]
2. classification regression
compute test error
J t e s t ( w ? , b ) = ? 1 m t e s t ∑ i = 1 m t e s t [ y t e s t ( i ) l o g ( f ( x t e s t ( i ) ) ) + ( 1 ? y t e s t ( i ) ) l o g ( 1 ? f ( x t e s t ( i ) ) ] J_{test}(\vec w, b) = -\frac{1}{m_{test}}\sum_{i=1}^{m_{test}} \left [ y_{test}^{(i)}log(f(x_{test}^{(i)})) + (1 - y_{test}^{(i)})log(1 - f(x_{test}^{(i)}) \right ] Jtest?(w,b)=?mtest?1?i=1∑mtest??[ytest(i)?log(f(xtest(i)?))+(1?ytest(i)?)log(1?f(xtest(i)?)]
2 cross-validation set
- split the training set into training set, cross-validation set and test set
- the cross-validation set is used to automatically choose the better model, and the test set is used to evaluate the model that chosed
3 bias and variance
- high bias: J t r a i n J_{train} Jtrain? and J c v J_{cv} Jcv? is both high
- high variance: J t r a i n J_{train} Jtrain? is low, but J c v J_{cv} Jcv? is high
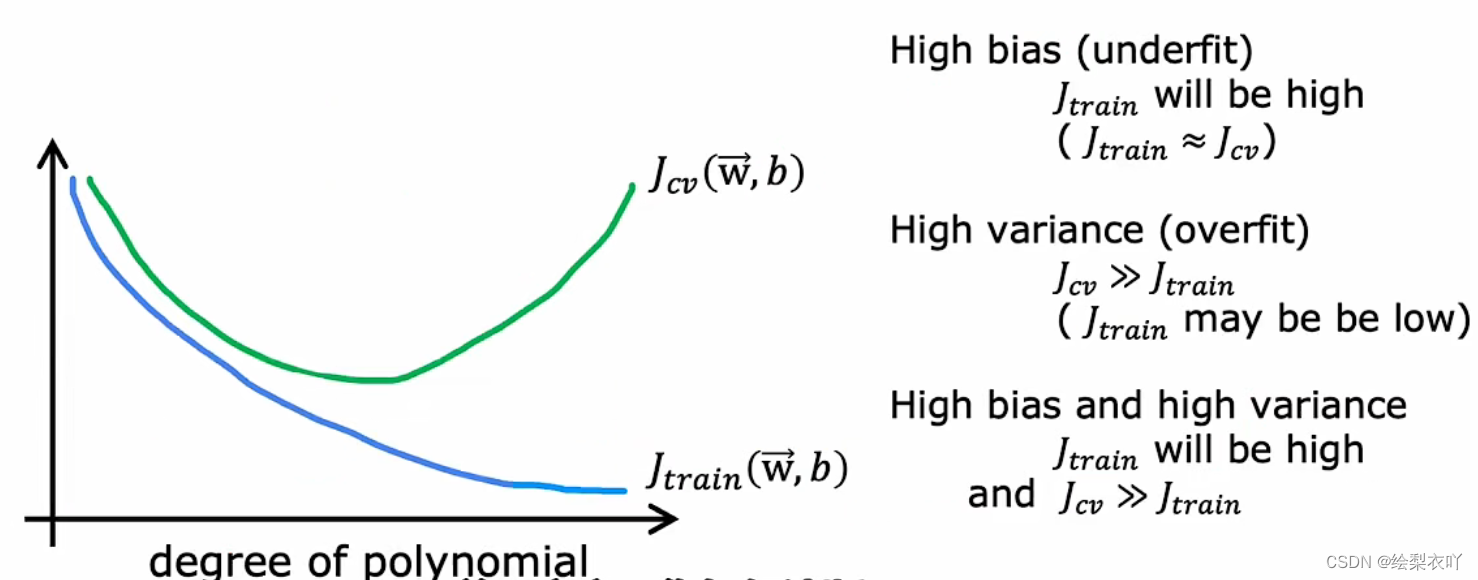
- if high bias: get more training set is helpless
- if high variance: get more training set is helpful
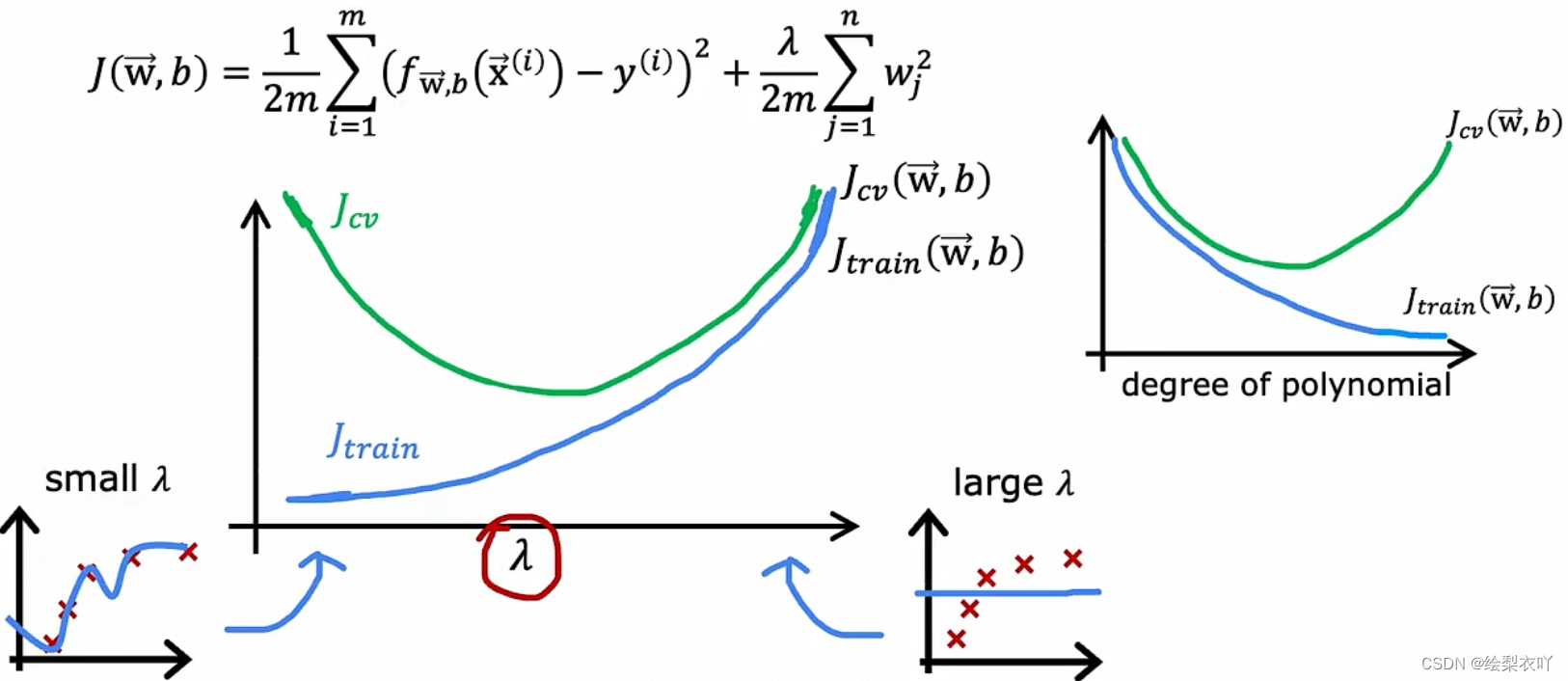
4 regularization
- if λ \lambda λ is too small, it will lead to overfitting(high variance)
- if λ \lambda λ is too large, it will lead to underfitting(high bias)
5 method
- fix high variance:
- get more training set
- try smaller set of features
- reduce some of the higher-order terms
- increase λ \lambda λ
- fix high bias:
- get more addtional features
- add polynomial features
- decrease λ \lambda λ
6 neural network and bias variance
- a bigger network means a more complex model, so it will solve the high bias
- more data is helpful to solve high variance
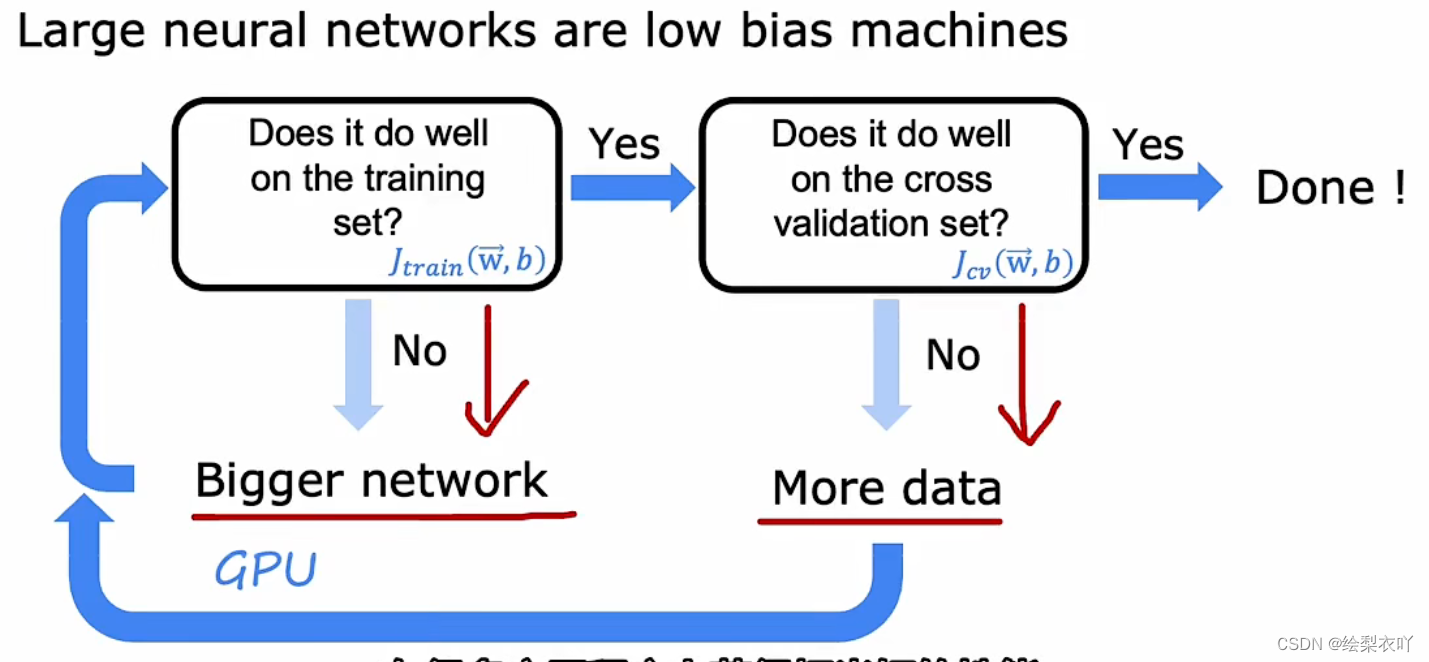
- it turns out that a bigger(may be overfitting) and well regularized neural network is better than a small neural network
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Word标尺怎么调出来?4个方法教会你!
- 免费分享一套微信小程序扫码点餐(订餐)系统(uni-app+SpringBoot后端+Vue管理端技术实现) ,帅呆了~~
- 提升职场竞争力:Python基于多个表格文件计算单元格数据的平均值
- 代码随想录算法训练营Day7 | 233.用栈实现队列、225.用队列实现栈
- java 13 练习题:基本数据类型与变量
- 指针理解B部分
- 操作系统期末复习知识点
- Qt5 CMake环境配置
- smali语言详解之一般/构造方法(函数)的声明与返回值关键字
- 分布式微服务springcloud+Eureka协同过滤购物商城系统设计与实现744jn