基于Python的城市热门美食数据可视化分析系统
发布时间:2023年12月28日
温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :)?
1. 项目简介
????????本项目利用网络爬虫技术从XX点评APP采集北京市的餐饮商铺数据,利用数据挖掘技术对北京美食的分布、受欢迎程度、评价、评论、位置等情况进行了深入分析,方便了解城市美食店铺的运营状况、消费者需求、市场趋势和竞争格局等。 本系统利用 Flask 搭建 web 后端分析服务,利用 Bootstrap 和 Echarts 等搭建交互式可视化分析系统。
2. 城市热门餐饮美食数据采集
? ? ? ? 利用Python网络爬虫技术,采集某点评网站的北京市各地区餐饮美食店铺数据:
# 。。。。。
# 省略其他代码
# 采集的商铺数量
total_shop_count = 0
# 批量插入数据的数组
batch_insert_datas = []
for a_link in a_links:
if 'http' not in a_link['href']:
continue
cate = a_link.text.strip()
base_url = a_link['href']
print(f'采集 `{cate}` 类别的美食数据,{base_url}')
for page in range(1, 26):
url = base_url + 'p{}'.format(page)
print(f'>采集:{url}')
headers['Referer'] = referer_url
resp = requests.get(url, headers=headers)
resp.encoding = 'utf8'
referer_url = url
soup = BeautifulSoup(resp.text, 'lxml')
shop_list = soup.find('div', id='shop-all-list')
if shop_list is None:
print("没有找到符合条件的商户~")
continue
shops = shop_list.find_all('li')
for shop_li in shops:
try:
# 商铺链接
href = shop_li.find('div', class_='tit').a['href']
# 商铺图片
# 。。。。。
# 省略其他代码
shop_info = (name, image_url, href, star, review_num, mean_price, food_type, addr, recommend_food)
batch_insert_datas.append(shop_info)
except:
print(page)
print(shop_li)
continue
if len(batch_insert_datas) % 10 == 0:
sql = "INSERT INTO meishi_info (name, image_url, href, star, review_num, mean_price, food_type, addr, recommend_food) VALUES (?,?,?,?,?,?,?,?,?);"
cursor.executemany(sql, batch_insert_datas)
conn.commit()
total_shop_count += len(batch_insert_datas)
print(f'已采集和解析商铺数量:{total_shop_count}')
batch_insert_datas.clear()
# 。。。。。
# 省略其他代码3. 城市热门美食数据可视化分析系统
3.1 首页及注册登录

3.2 热门店铺名称词云分析

3.3 餐饮店铺菜系分析?
3.3.1?不同菜系商铺数量分布情况
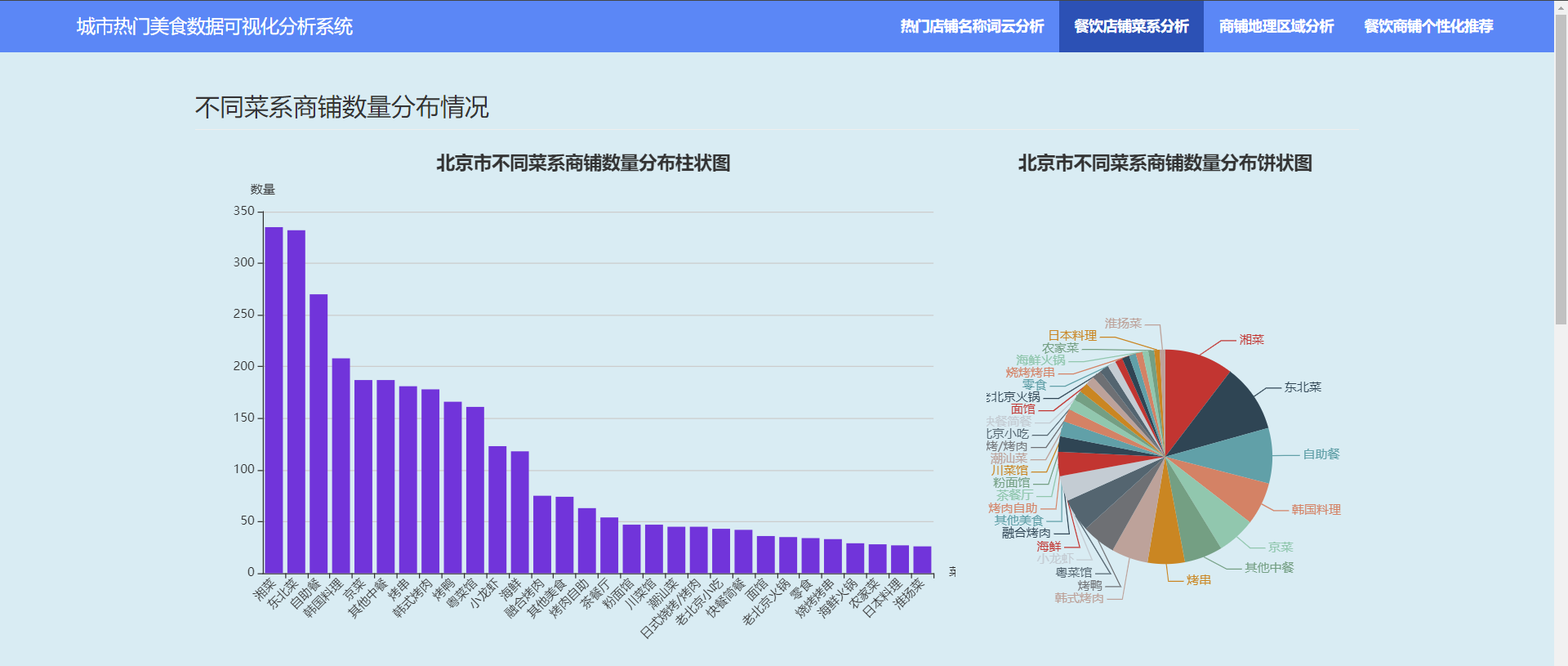
3.3.2?不同菜系评分分布情况
 3.3.3?不同菜系平均人均消费价格分布情况?
3.3.3?不同菜系平均人均消费价格分布情况?

3.4?商铺地理区域分析
3.4.1?餐饮店铺人均价格和评分在不同地区的分布情况
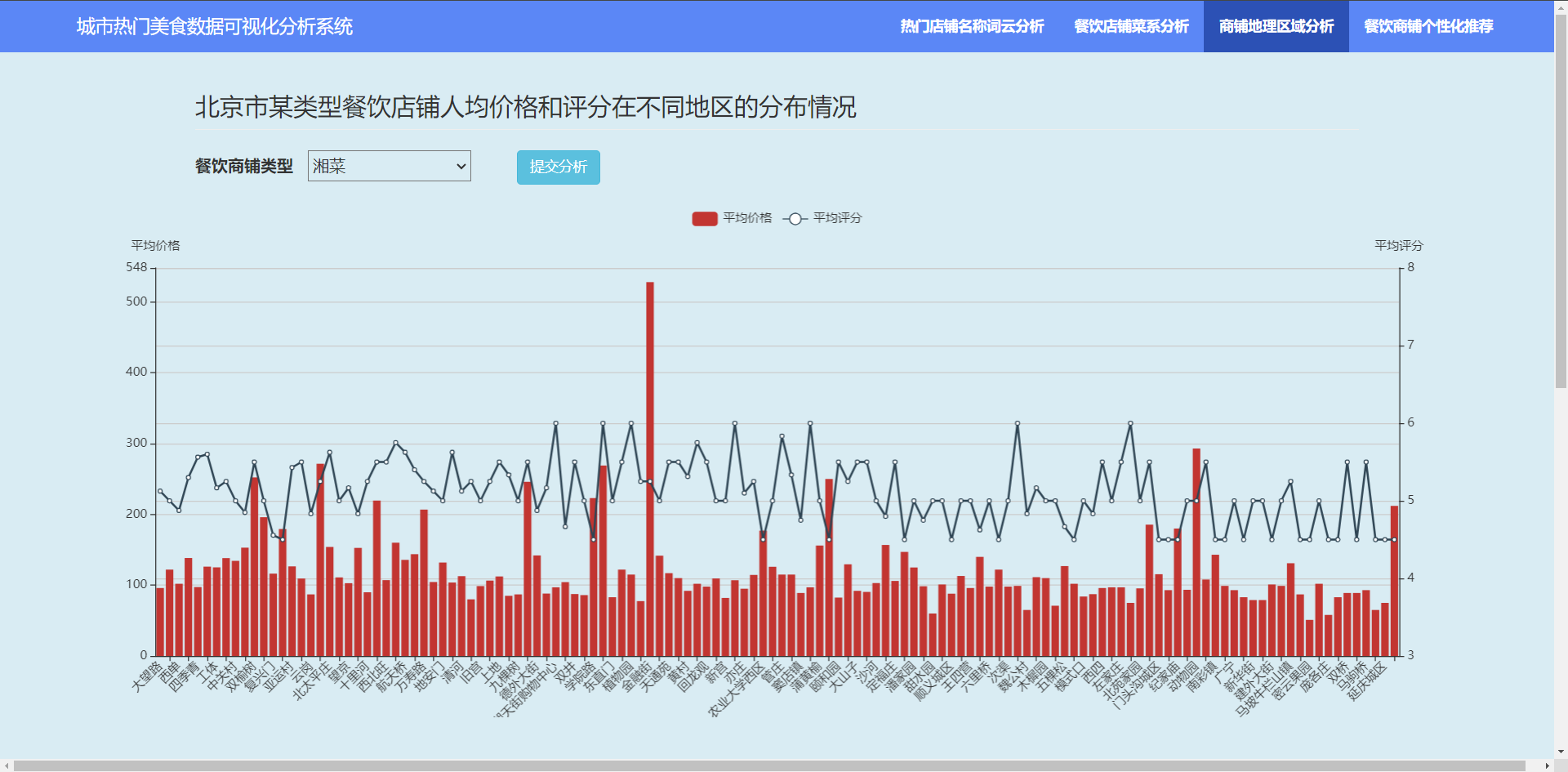
3.4.2 不同类型餐饮店铺的人均价格和评分的分布情况?
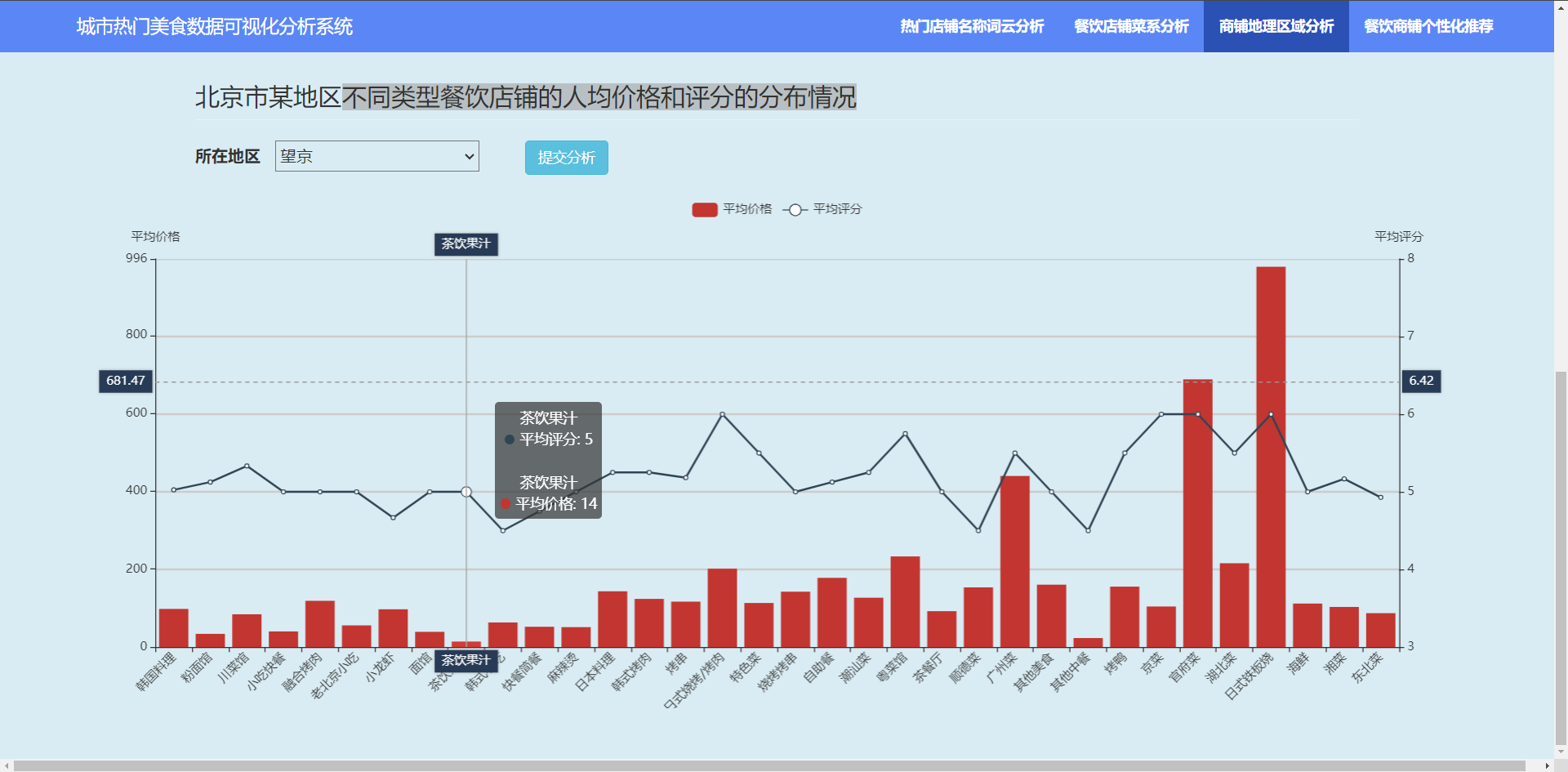
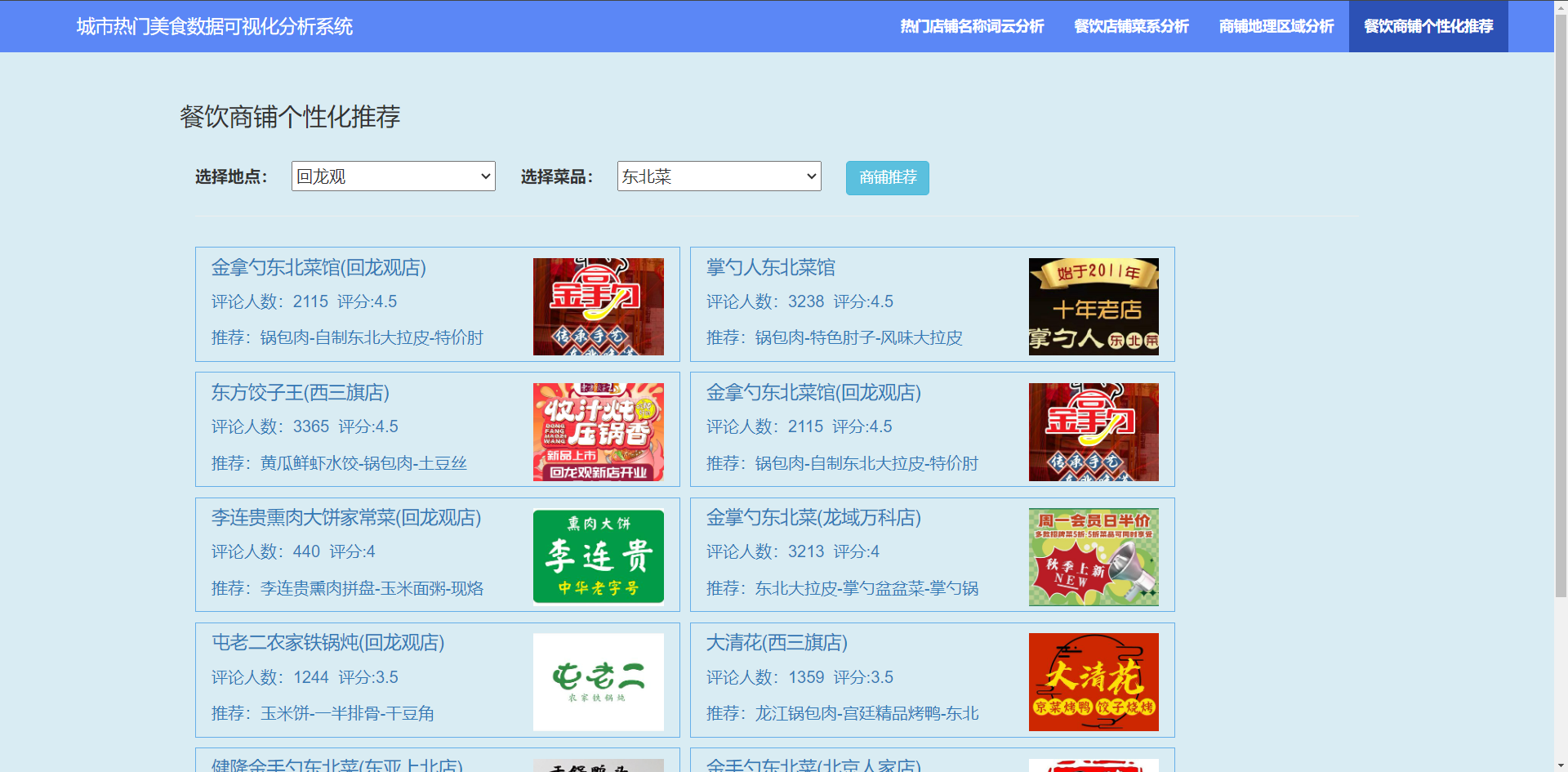
3.5?餐饮商铺个性化推荐
4. 总结
????????本项目利用网络爬虫技术从XX点评APP采集北京市的餐饮商铺数据,利用数据挖掘技术对北京美食的分布、受欢迎程度、评价、评论、位置等情况进行了深入分析,方便了解城市美食店铺的运营状况、消费者需求、市场趋势和竞争格局等。 本系统利用 Flask 搭建 web 后端分析服务,利用 Bootstrap 和 Echarts 等搭建交互式可视化分析系统。
??欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。技术交流、源码获取认准下方?CSDN 官方提供的学长 QQ 名片 :)
精彩专栏推荐订阅:

文章来源:https://blog.csdn.net/andrew_extra/article/details/135257026
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 如何预防变种.halo勒索病毒感染您的计算机?
- Qt超简单实现贪吃蛇
- JAVA网络初始及网络编程
- C++力扣题目617--合并二叉树
- 改进YOLO系列 | YOLOv5/v7 引入高效的混合特征编码器 AIFI
- 第十三讲 单片机驱动彩色液晶屏 bin档的烧录方法
- docker(Dockerfile、 关键字解释、Dockerfile编写、构建) -day04
- HarmonyOS—创建和运行Hello World
- Python 为UnityAndroid端自动化接入Tradplus广告SDK
- LeetCode刷题(文章链接汇总)