【我的方向】轻量化小目标检测
文章目录
轻量化
为什么要研究轻量级神经网络?
随着深度神经网络和智能移动设备的快速发展,网络结构轻量化设计逐渐成为前沿且热门的研究方向,而轻量化的本质是在保持深度神经网络精度的前提下优化存储空间和提升运行速度。目前,针对轻量化深度学习网络的研究主要集中于人工设计的轻量化网络和基于神经网络结构搜索的自动轻量化网络。
发展现状:
如何在尽可能保持神经网络模型精度的前提下,最大程度地降低模型延迟和存储空间是目前研究的热点问题。现有性能较好的人工设计的轻量化方法不仅耗费大量的人力资源,而且得具备丰富的深度学习经验才能使得各项性能指标都达到要求。(接下来讲的论文就是用现有的轻量级模型[efficientNet]作为主干网络+特征融合技术可以对目标检测达到很好的效果,而参数量、计算量都很小)。基于神经网络结构搜索的轻量化方法仅专注于提高神经网络模型的准确率,却忽视了底层硬件设备的限制,这样得到的高效模型由于对硬件要求较高。
主要从以下三个方面学习:
- 1、压缩已经训练好的模型:知识蒸馏、权重量化、剪枝、注意力迁移
- 2、直接训练好的轻量级网络:MobileNet(1,2,3)、shuffleNet(1、2)、squeezeNet、 EfficientNet、Xception、NasNet
- 3、加速卷积运算:im2col、低秩分解、CUDA加速
1人工设计的轻量化方法
1.1组卷积
组卷积对输入特征图按通道进行分组卷积,再将分组卷积得到的结果按通道进行连接得到最终的输出特征,具有轻量化效果。(2012年AlexNet由于受到硬件设备的限制,创新性地使用组卷积并将一个网络在两个硬件设备上进行训练)。但是,组卷积也有局限性,会导致特征图之间的信息不流畅,输出的特征图没有包含所有输入特征图的信息,后续的shuffleNet提出的通道重排可以解决这个问题。

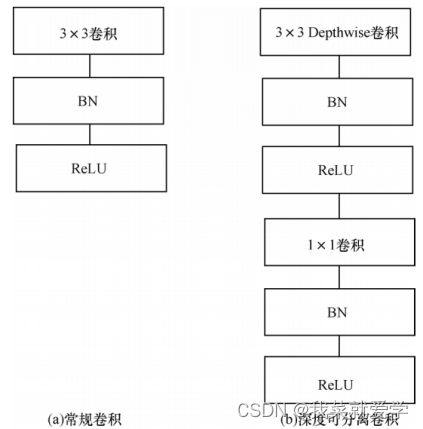
1.2深度可分离卷积
Depthwise卷积使用卷积核对输入特征按通道进行分别卷积,即第一通道的
卷积核与第一通道的输入特征进行卷积。Depthwise卷积在获得特征的空间信息后,将得到的输出特征进行Pointwise卷积,即利用1×1的卷积核对Depthwise卷积的输出进行卷积,以获取特征中不同通道之间的信息,通过该组合方式达到轻量化效果。
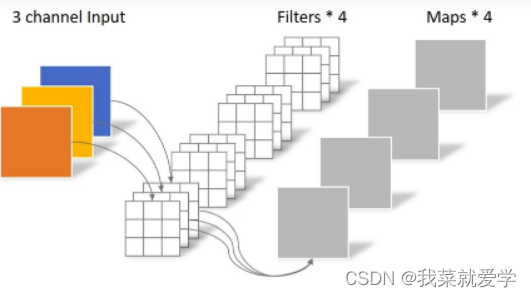

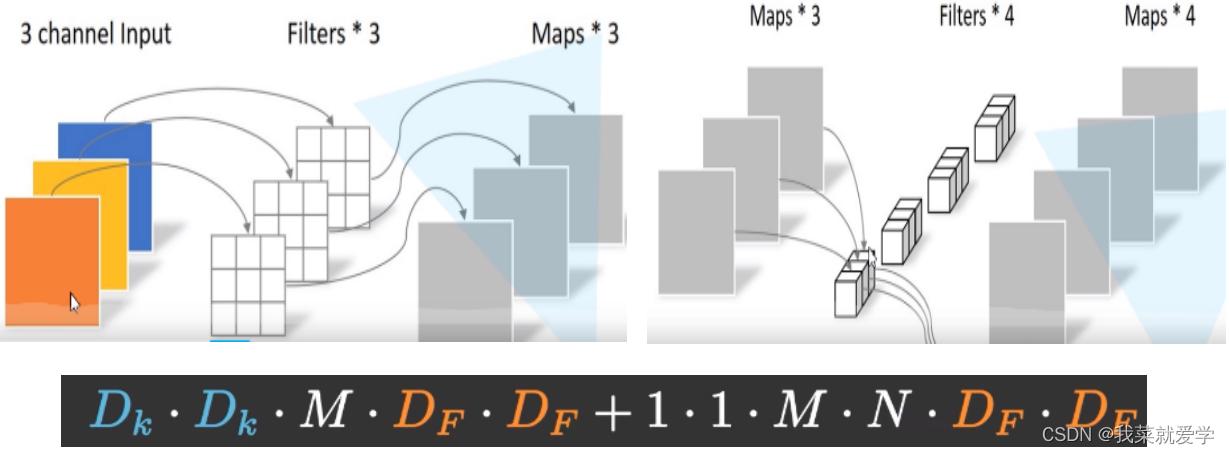
1.3基于深度可分离卷积的MobileNet
MobileNetv1的基本思想是使用深度可分离卷积代替常规卷积,利用深度卷积代替传统卷积中的滤波器进行特征提取。
MobileNetv2作为MobileNet的改进网络,引入ResNet网络的残差思想,同时解决了常规ResNet中大量使用ReLU激活函数导致神经元失活的缺陷。若不想让ReLU因“抹0”丢失信息,让输入的值都为正值。但是若是输入的值都为正值,又变成了恒等 映射的线性变换。神经网络能拟合源于非线激活,所以扩展多余的维度,“抹0”去除冗余信息,再用ReLU非线性激活。
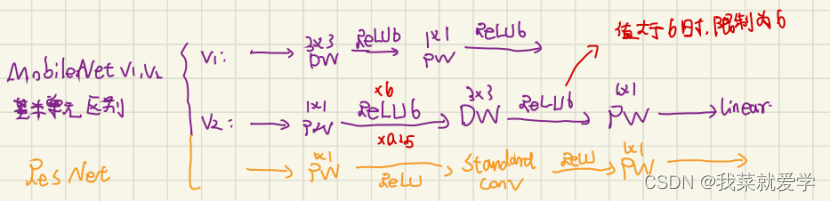
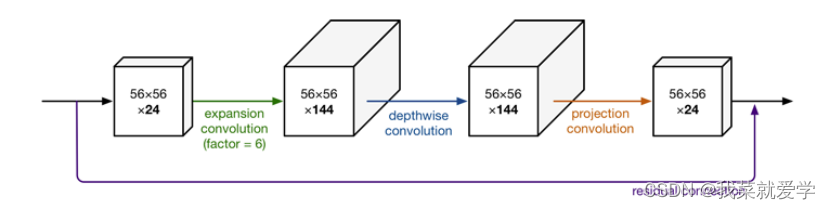
瓶颈结构的shortcut:
若是输入的通道与输出的通道数一样或者步长设置为1就走带残差的block.
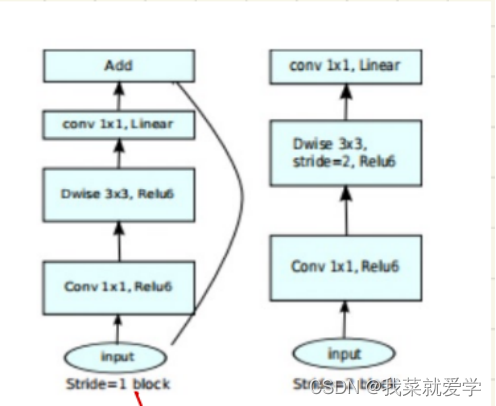
下面是对CIFAR10的数据集测试普通卷积、MobileNetv1、MobileNetv2的参数、计算量对比:
MobileNetV3是通过神经结构搜索的架构,也就是通过炼丹练出来的模型。网络结构是基于NAS实现的MnasNet,同时也使用了深度可分离卷积和线性瓶颈的倒残差结构,激活函数使用的是h-wish。
1.4 ShuffleNet
ShuffleNet是一个效率极高且可运行在手机等移动设备上的网络。常规组卷积最大的局限性为在训练过程中不同分组之间没有信息交换,这样会大幅降低深度神经网络的特征提取能力。因此,在MobileNet中使用大量的 1× 1 Pointwise(通道之间相关联)卷积来弥补这一缺陷,而 ShuffleNet 采用通道变换来解决该问题。通道变换的核心思想是对组卷积之后得到的特征图在通道上进行随机均匀打乱,再进行组卷积操 作,这样就保证了执行下一个组卷积操作的输入特 征来自上一个组卷积中的不同组。(之前讲的yolov7也用到这个思想)
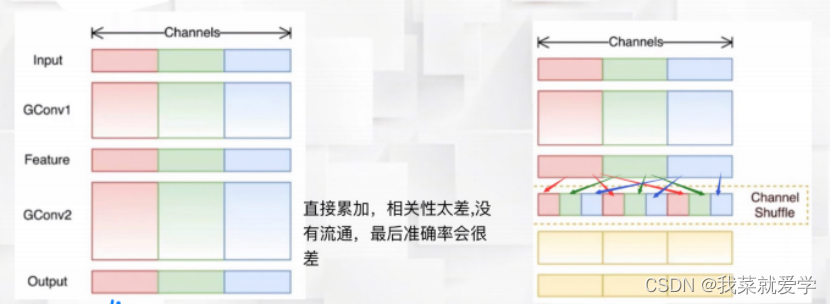
分组原理:假设输入一维12个数据,分为3组,每个组4个值,分组重排先将这个矩阵升维,重构3行4列,然后对矩阵转置,得到4行3列,再安装行展开。
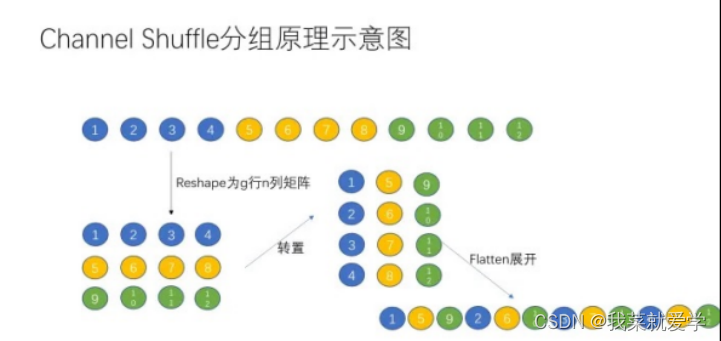
1.5 ShuffleNet V2
在 ShuffleNetV2被提出之前,轻量化网络中衡量模型复杂度的通用指标为每秒浮点运算次数(FLOPS)。FLOPS代表运算力,对于网络性能评估是一个间接指标,因为运算力不完全等同于运行速度。通过实验可以发现,相同 FLOPS 的两个模型的运行速度却存在差异,导致该差异的原因包括 GPU、内存使用量 (MAC)
-
1)尽量使用和输入特征通道数相同的卷积核个数来最小化内存使用量。以上文提及的深度可分离卷积中的 Pointwise 卷积为例,假设输入特征尺寸为 h×w×cin,输出通道数为 cout,于是在 Pointwise 卷积中 可得到:

仅当 c1 = c2 时,MAC取最小值,这个理论分析也通过实验得到证实.
-
2)重视元素级操作。激活函数(例如 ReLU)和 特征图的相加(add)虽然对于浮点运算力的影响很小,但它们对于内存使用量会产生较大的影响。
-
3)过量使用组卷积也会增加MAC,注意分组数。
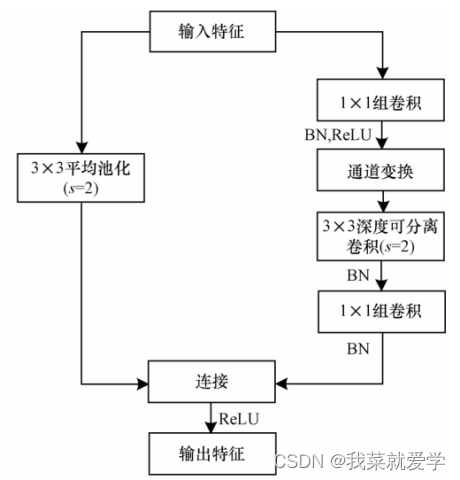
在ShuffleNetv1的模块中,大量使用了1x1组卷积,这样的话会增加MAC,另外v1采用了类似ResNet中的瓶颈层,输入和输出通道数不同(这里是MobileNetv2提出的),这违背了输入输出通道数一致原则。ShuffleNet V2 结构如下图所示,通道分离本质 上是将输入特征按通道分成两部分,一部分通道数 为 c’,另一部分为 c - c’。左分支等同于恒等映射,对应残差网络中的 Shortcut,右分支包含了 3 个连续的卷积操作,且满足输入特征和输出特征通道相同的原则。
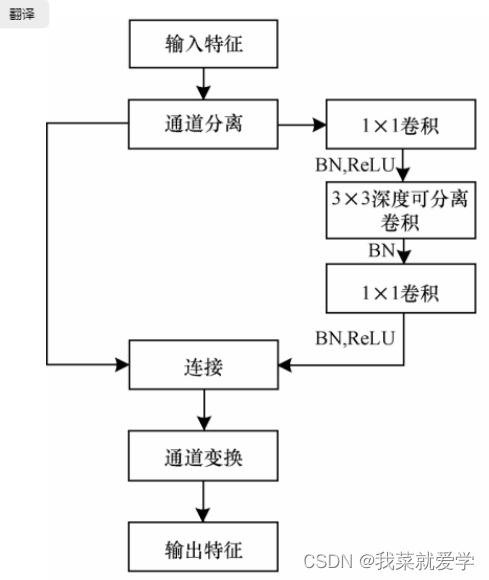
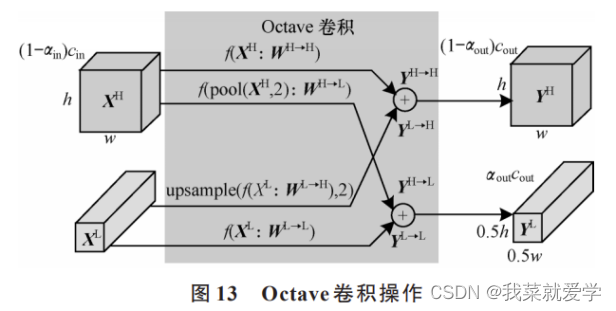
基于 Octave 卷积的改进基线网络
图片中不同的信息都以不同的频率传递,主要分为高频信息和低频信息,其中:高频通常用于细节编码,高频信息代表图片中的细节特征;低频通常用于全局编码,低频信息代表图片中的全局特征,即较低空间分辨率下变化较慢的特征。
卷积层之间的特征图可以看作是高频信息和低频信息的混合特征图。在传统卷积方式中,无论高频信息还是低频信息都是用同一种方式存储的,这对于其中的低频信息而言就会造成存储冗余并增加计算成本。Octave 卷积是针对这一问题提出的新型卷积方式,将特征图根据不同的频率进行因式分解,对不同频率的信息进行不同的存储和操作,再在不同频率的信息之间进行信息交换。
在 Octave 卷积的输入特征图中,当αin =0 ,αout = 0 时,Octave 卷积就等同于常规卷积。当 αin = 0 且 αout ≠ 0 时,代表当输入特征图为常规卷积特征图时 ,将其转化用于普通卷积的 Octave 特征图,通常应用于 Octave 卷积的第一层。当 αin ≠ 0 且 αout ≠ 0 时,代表当输入是 Octave 特征图时进行 Octave 卷积操作,通常应用于 Octave 卷积的中间层。当 αin ≠ 0 且 αout = 0 时,代表在获得传统特征图时需进行 Octave 卷积,其作用是将 Octave 特征图经过卷积之后得到传统特征图,通常 应用于 Octave 卷积的最后一层。
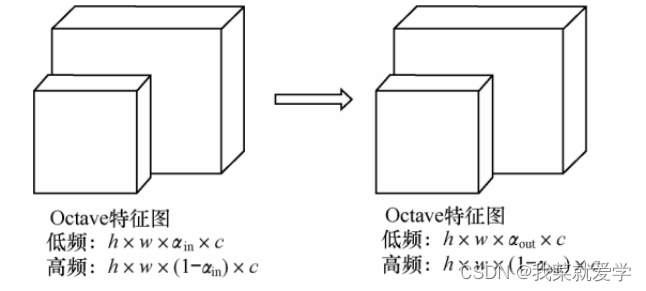
Octave 卷积通常对低频信息和高频信息进行分别存储和处理,如果不能实现不同频率信息之间的信息交换,则非常影响网络性能。在获得高频信息时,对输入特征图中的高频信息进行常规卷积操作,同时对低频信息进行上采样, 将两者结合得到卷积之后的高频信息。在获得低频信息时,对输入特征图中的低频信息进行常规卷积操作,同时对高频信息进行池化,将两者结合得到卷,积之后的低频信息。
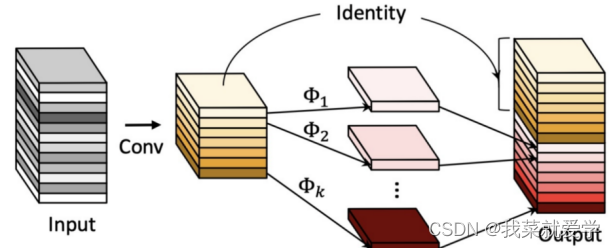
基于 Ghost特征的 GhostNet
传统深度神经网络的轻量化方法研究主要集中于减少参数量及改进卷积方式。2020年,HAN对深度神经网络特征图进行分析,发现常规卷积中特征图的冗余性在神经网络结构中很少被关注,为了从特征图冗余的角度实现网络结构轻 量化 ,GhostNet 应运而生。如下图所示,红色、绿色和黄色的每一对都是相似的特征图,如果可以将这些相似特征图通过廉价的操作变换实现 ,那么可能实现低的运算量。

这里作者是先使用1 x 1卷积进行通道压缩,然后深度可分离卷积生成相似特征图与前面的特征层堆叠。这里与mobileNet类似,把传统卷积换成Ghost卷积块。
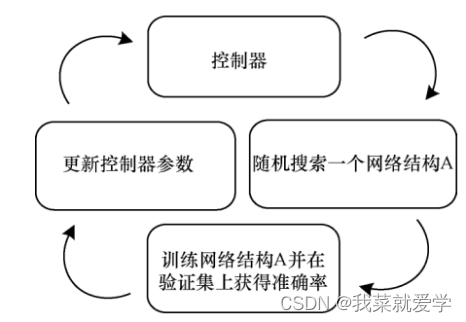
基于神经网络结构搜索的轻量化方法
随着强化学习的快速发展,基于神经网络结构搜索的轻量化方法应运而生。
神经网络结构搜索的主要目的是利用强化学习方法,在搜索空间中搜索到最适合的基本单元中的超参数,再将搜索到的基本单元进行堆叠得到神经网络结构搜索的轻量化网络。
基于自动模型压缩的轻量化方法
模型压缩主要分为细粒度修 剪和粗粒度修剪两部分,细粒度修剪针对权重中的冗 余部分进行修改,粗粒度修剪则是针对通道、行列、块等整个区域按照一定的稀疏率进行压缩。
- 1)剪枝
剪枝的本质剪去神经网络中不必要的冗余权值和分支,仅保留对于神经网络的目标任务有效用的权值参数。 - 2)权值共享
权值共享是使用同一组参数来避免过多参数导致的训练和模型冗余。 - 3)权值量化
权值量化旨在用较小的比特值来表示权值,大概就是把float32换成float8,以达到减少存储量的目的。 - 4)哈夫曼编码
哈夫曼编码是将两个权值最低的节点作为左右子树形成新的节点,再选取两个权值最低的节点作为左右子树形成新的节点,以此类推,达到根据使用频率来最大化节省存储空间的目的。
4 相关论文
《Mobile-Former: Bridging MobileNet and Transformer(连接 MobileNet 和Transformer)》 CVPR-2022:《移动成型器:桥接MobileNet和Transformer》
Mobile-Former是一种 MobileNet 和 Transformer 的并行设计,中间有一个双向桥,这种结构利用了 MobileNet 在本地处理和全局交互中的 Transformer 的优势,同时可以实现局部和全局特征的双向融合。结合提出的轻量级交叉注意力对桥梁进行建模,Mobile-Former 不仅计算效率高,而且具有更强的表示能力。它在低 FLOP 状态下性能优于 MobileNetV3。
小目标检测
小目标检测(Small Object
Detection)是指在图像中检测尺寸较小的目标物体,通常是指物体的尺寸小于图像大小的1/10或者更小,COCO为例,面积小于等于1024像素的目标。
学习的方向:
- 1)基于特征金字塔的方法:这种方法通过构建特征金字塔来捕获不同尺度的特征信息,然后将不同尺度的特征信息进行融合以提高目标检测的准确率。常见的基于特征金字塔的方法包括FPN(Feature Pyramid Network)、SSD(Single Shot Detector)等。
- 2)基于注意力机制的方法:这种方法通过引入注意力机制来提高小目标的检测性能,例如SENet(Squeeze-and-Excitation Network)、CBAM、SKNet等。
- 3)基于联合训练的方法:这种方法通过联合训练来提高小目标的检测性能,例如CornerNet、CenterNet等。
- 4)基于弱监督学习的方法:这种方法通过利用弱监督学习技术来减少标注数据的需求,例如WOD(Weakly Supervised Object Detection)等。
- 5)基于增强数据的方法:这种方法通过增加数据的多样性和难度来提高小目标的检测性能,例如使用数据增强技术 (随机裁剪、颜色抖动)、增加负样本等。
相关论文
“RepPoints V2: Verification Meets Regression for Object Detection”
(CVPR 2021) 《RepPoints V2:验证符合对象检测的回归》
该论文提出了一种基于验证和回归相结合的物体检测方法,该方法能够更好地检测小物体。该算法通过引入重复点表示对象,同时结合验证和回归来提高检测准确性。传统的物体检测方法通常使用预定义的锚点框来检测和定位物体。然而,由于不同目标的形状和尺寸差异很大,使用单一的锚点框往往难以准确检测和定位目标。为了解决这个问题,本文提出了一种新的物体检测方法,名为 RepPoints V2。RepPoints V2 使用了两个关键组件来提高检测精度:验证模块和回归模块。验证模块可以对候选目标进行验证,从而减少误检率。回归模块可以对候选目标进行精确定位,从而提高检测精度。与传统的锚点框方法相比,RepPoints V2 能够更好地适应不同尺寸和形状的目标,从而提高检测的准确性。
“Beyond NMS: Fast and Accurate Object Detection with Hard Positive
Generation” (CVPR 2021) 《超越NMS:使用硬阳性生成实现快速准确的对象检测》
该论文提出了一种新的目标检测框架,能够更快、更准确地检测小目标。该方法通过引入硬正样本生成技术来减少虚假正样本的数量,从而提高检测精度和速度。在传统的目标检测方法中,通常使用非极大值抑制(NMS)来去除冗余的检测结果,从而提高检测精度和效率。然而,NMS 方法有时会过度去除正样本,从而导致检测精度下降。为了解决这个问题,本文提出了一种新的目标检测方法,名为 Hard Positive Generation。Hard Positive Generation 方法通过在候选框中生成正样本,从而提高正样本的覆盖率。在生成正样本时,Hard Positive Generation 方法使用了类似于分类器的技术,即将正样本与负样本进行分类,从而减少误检率。与传统的 NMS 方法相比,Hard Positive Generation 方法能够更准确地检测目标,从而提高检测精度。
轻量化与小目标结合的看法
在小目标检测中,由于目标的尺寸相对较小,因此需要模型具有高效性和准确性。同时,因为资源受限,轻量级模型可以更好地适应于嵌入式设备、移动设备等资源有限的环境中。目前,一些针对小目标检测的轻量级模型已经被提出。这些模型通常采用一些有效的优化策略,例如深度可分离卷积、通道注意力等技术,以实现高效的检测性能。此外,一些基于知识蒸馏的方法也被应用于轻量级模型中,以提高其性能。
- 1、YOLOv7-tiny:yolov7的轻量化模式。
- 2、EfficientDet:一种基于EfficientNet网络结构的目标检测算法,采用了BiFPN和Swish等轻量化模块,同时优化了网络架构和训练方法,从而实现了高效的小目标检测。
- 3、CenterNet:一种基于中心点的目标检测算法,采用了轻量化的Hourglass网络结构和Dilated Convolution模块来提高检测精度和计算效率。
- 4、BlazeFace:一种基于MobileNetV2网络结构的人脸检测算法,采用了轻量化的网络设计和特征融合方法来实现实时的人脸检测。
- 5、“HR-RCNN: High-Resolution and Lightweight Networks for Object Detection” (CVPR 2021): 该论文提出了一种高分辨率轻量级目标检测框架 HR-RCNN,该框架使用深度可分离卷积、跨层连接和特征金字塔等技术来提高检测性能和计算效率。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!