HDFS节点故障的容错方案
HDFS节点故障的容错方案
本文主要探讨hdfs集群的高可用容错方案和容错能力的探讨。涉及NN、JN和DN相关组件,在出现单机故障时相关的容错方案。
更多关于分布式系统的架构思考请参考文档关于常见分布式组件高可用设计原理的理解和思考
1. NN高可用
1.1 选主逻辑
NN(Namenode)的HA机制主要依靠zkfc完成,zkfc在NN所在节点以独立进程的方式运行。其内部主要由主控模块(ZKFailoverController)、健康检测模块(HealthMonitor)、主从选举模块(ActiveStandbyElector)三个模块协同实现。
zkfc的启动选举流程如下图所示
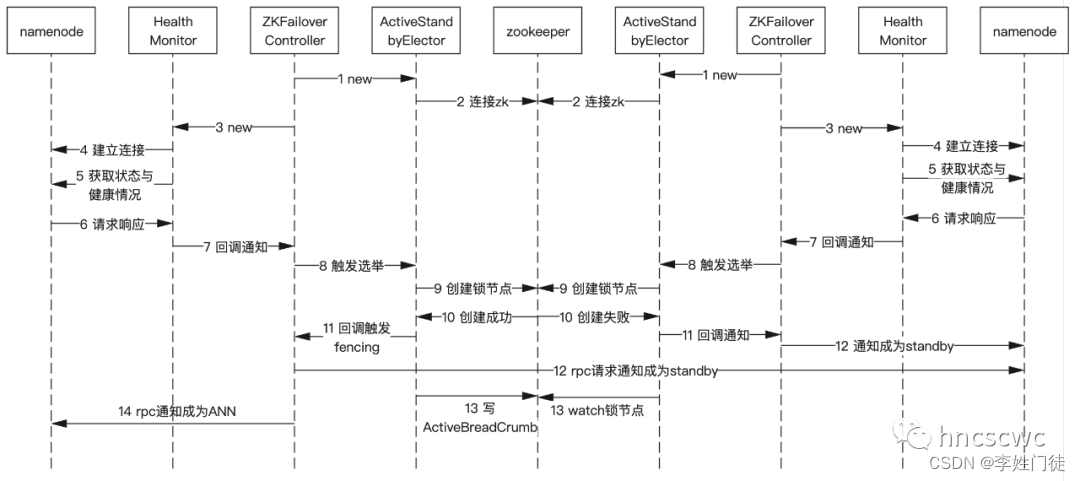
- zkfc启动后,首先构造选举模块,并向zookeeper建立连接
- 启动对NN的健康检测,向NN发送rpc请求,获取NN的状态和健康情况
- 假如NN是健康的,触发进行选举,即在zookeeper上创建临时锁节点(ActiveStandbyElectorLock),zk本身的机制保证只有一个zkfc能成功创建节点(有排他锁),因此只能有一个zkfc能够创建成功
- 对于成功创建节点的zkfc,会向其他的NN发送rpc请求进行fencing(本质上是告知对端成为standby),在zookeeper上创建持久记录NN主从相关信息的节点(ActiveBreadCrumb),向本地的 NN发送rpc请求告知其成为ActiveNN。
- 而创建节点失败的zkfc,则通过回调向本地的NN发送rpc请求,告知其成为standby,然后对ActiveNN在zookeeper中创建的锁节点进行watch。
1.2 HA切换
当ActiveNN异常时,需要进行HA切换出一个新的ActiveNN,整体逻辑如下:
- ActiveNN出现异常(包括进程退出,状态和健康情况的rpc请求无响应等)时,zkfc会主动退出选举,即结束与zookeeper的tcp连接,该连接对应的会话在zookeeper上创建的临时锁节点(ActiveStandbyElectorLock)超过ttl时间后会自动被删除。
- 其他NN节点上进行watch的zkfc感知到节点的变化,触发进行选举,尝试重新在zookeeper上创建临时锁节点(ActiveStandbyElectorLock),如果创建临时锁节点(ActiveStandbyElectorLock)成功
- 获取ActiveBreadCrumb节点的值(通常记录老ActiveNN的信息),从中得到老ActiveNN的信息,当发现老ActiveNN并非本节点时,zkfc就触发对其进行fencing,fencing的目标是确保老ActiveNN确实已经降级为standby角色
- fencing成功后,在ActiveBreadCrumb节点上写入当前NN的值,最后通过RPC接口调用当前的NN,升级为ActiveNN。
相关配置如下
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.ms</name>
<value>60000</value>
</property>
<property>
<name>ha.zookeeper.parent-znode</name>
<value>/hadoop-hdfs-ha</value>
</property>
默认的fencing动作sshfence会执行fuser等命令需要在相关的服务器上执行yum install psmisc -y安装相关依赖,否则可能会导致fencing失败。
1.3 注意点
1.3.1 fencing的处理
前面选举流程和HA切换流程中都提到了fencing(隔离),那么为什么好进行fencing,fencing的意义是什么?
就上面zkfc异常的场景,来深入分析下:
当ActiveNN所在节点的zkfc出现异常,或者仅仅是zkfc与zookeeper之间的网络不稳定,导致zkfc与zookeeper之间的会话超时,从而触发StandbyNN节点上的zkfc选举并成为新的ActiveNN。
如果不进行fencing,那么此时存在两个ActiveNN,并同时对外提供服务,这可能会导致hdfs的数据不能保证一致性,甚至出现错乱无法恢复。因此StandbyNN在成为新的ActiveNN之前,需要对老的ActiveNN进行fencing处理。
具体为zkfc直接向老的ActiveNN发送rpc请求,通知其成为StandbyNN,这个过程为优雅的fencing。
如果老的ActiveNN成功响应,那么zkfc会进而通知StandbyNN成为新的ActiveNN。如果老的ActiveNN没有进行响应,那么就会根据配置的方式再次进行fencing。
可配置的方式包括ssh和执行指定的脚本。
ssh的方式为zkfc通过ssh到老的ActiveNN节点上,然后执行kill动作,将老的ActiveNN杀掉,最后通知StandbyNN成为新的ActiveNN。如果ActiveNN所在节点的网络异常,无法成功ssh,因此也就无法将老的ActiveNN杀掉。
因此,通常的方式是执行自己编写的脚本,在脚本中进行相关的处理动作。zkfc通过脚本的返回结果决定通知StandbyNN成为新的ActiveNN,或者再次触发选举流程。
相关配置
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
1.3.2 健康状态的定义
前面提到了健康检测模块会定时向NN发送rpc请求,获取nn的状态(Active/Standby/Initializing)和健康状态,那么NN怎样判断自身是健康的呢?
跟踪其源码发现:NN对配置的本地目录(用于存储fsimage和editlog的目录和其他指定配置的目录)进行磁盘容量检查,如果目录对应的磁盘容量达到配置的最小值,则NN认为自身是健康的,否则认为是非健康的。
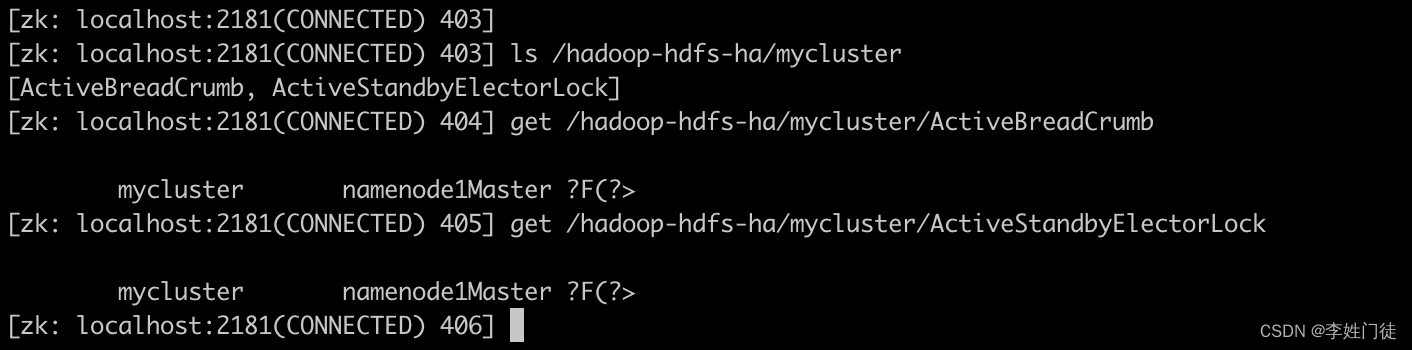
1.3.3 确保zk中的父节点存在
zkfc启动并成功连接zookeeper后,首先会存储锁节点的父亲节点是否存在,如果不存在,zkfc进程会直接退出。
zkfc启动时,可以指定hdfs zkfc -formatZK,这时zkfc会删除在zookeeper上存储的信息,并创建出必备的父亲节点,然后进程退出。再次启动时(不带参数)就能正确进行选举了。
另外,如果在zkfc运行过程中,将对应的父亲节点删除了,zkfc不会再自动创建出来,此时选举用的锁节点会持续创建失败导致无法正常选举,从而导致NN无法正常提供服务。
1.3.4 确保NN的ID与IP保持一致
NN正常选举成功后,ActiveNN会在zookeeper上创建ActiveBreadCrumb节点,记录ActiveNN/StandbyNN的ID与对应的IP信息。
由于该节点是持久化的,因此当NN重启或者重新选举后,会读取该节点的值,从中获取老的ActiveNN的IP信息,用于fencing处理。在此之前,会将节点记录的NN的ID与对应的IP和本地配置的情况进行比较,如果与配置中的不一致,会抛出异常不会再进行后续的处理。
通常出现该情况的场景是NN以容器的方式部署运行,当NN所在的容器下线重启后,NN分配的IP发生了变化,导致与记录在zookeeper中ActiveBreadCrumb节点的信息不一致。
2. DN高可用
DN节点是具体的数据存储节点,本身并不不需要高可用,相关的block是多副本并打散在不同的block节点,就能够实现数据高可用。但是当DN节点异常后,也应该能够被感知到,并进行隔离,避免将读写请求发送到异常的DN节点,同时将DN上的block副本按照预定的策略进行修复或者隔离。
2.1 感知DN节点异常
如下2种场景,能够感知到DN异常,
1,NN感知DN心跳超时,至少至少需要10min
2,由于NN感知DN异常时间较长,在这个时间段内,客户端还是有可能请求到异常的DN上。此时客户端进行读写时,客户端链接DN,但是DN不响应或者pipeline种的数据异常
2.1.1 NN感知DN心跳超时
DN定期向NN进行心跳汇报(有别于DN的全量block汇报),默认情况下,DN每间隔3s会给NN进行心跳汇报,相关配置如下。
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>
并且NN会通过心跳回包的时,搭便车,将常规的删除操作发送给DN。NN如果长时间没有收到DN的心跳汇报,则会判定DN已经宕机。相应的逻辑如下
- 通过心跳机制来判断死亡,如果 DN 默认3s时间间隔没有给namenode发送心跳,NN 并不会直接断定 DN 死了。
- NN 会给 DN 为10次的机会,如果 DN 在30秒的时间还没有向 NN 发送心跳,NN 就暂时的,记住是暂时的认为 DN 死亡了。
- 于是 NN 就会每隔5分钟向 DN 发送一次检查,如果发送了两次依旧还没有收到 DN 的消息,那么 NN 就判定这个 DN 节点挂掉了。
所以NN会在DN宕机后的时间为 10分钟+30秒,判定DN宕机。
相关的计算公式和参数
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval
默认的heartbeat.recheck.interval大小为5000毫秒,即5分钟
<property>
<name>heartbeat.recheck.interval</name>
<value>5000</value>
</property>
当NN判断DN宕机后
- NN剔除对应的DN列表,并标记对应DN上的block死亡,客户端请求不会到故障的DN上
- NN的副本保持功能,检测到异常节点DN上的block死亡,相关的block不满足副本要求,就会触发block,实现数据的自动迁移。
2.1.1 客户端链接DN异常
客户端直接或者间接连接DN时,客户端通过一定的流程绕过异常的DN继续进行读写。这种情况下,并不会导致异常DN上的相关数据进行复制或者进行处理。
整体流程如下
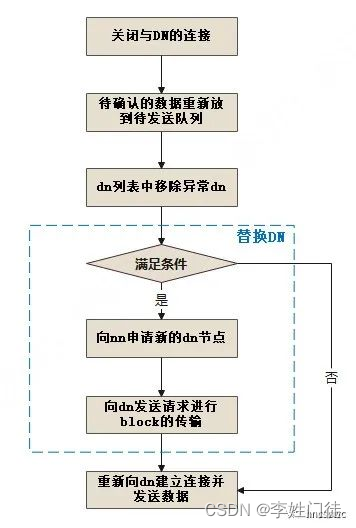
如上图所示,异常处理的流程为:
- 首先客户端会关闭当前与DN的连接。
- 接着将待确认的数据重新放回到待发送列表中。
- 接着从DN列表中移除异常DN。
- 然后进行替换DN的处理
具体包括先判断是否满足替换DN的条件,如果满足条件,则向NN请求增加一个DN,NN分配一个合适的DN并返回给客户端,客户端将新的DN放到DN列表末尾,并以当前DN列表中的第一个DN为源,向其他DN进行block数据的同步,也就是保证传输之前的数据一致性。
最后向DN列表中的首个DN发起连接重新进行数据传输的动作。
受下面几个配置项的影响
dfs.client.block.write.replace-datanode-on-failure.enable
是否启用替换DN的处理机制,默认值为true,也就是启用DN替换机制。
如果是false,当DN异常后,客户端移除异常的DN后使用剩余的DN继续进行写操作。
dfs.client.block.write.replace-datanode-on-failure.policy
替换DN的具体策略,仅当启动替换DN时该配置项才生效。可选的策略包括:
ALWAYS:始终执行替换DN的动作。
NEVER:始终不进行替换DN的动作。
DEFAULT:默认策略,
(1)移除异常后的DN列表个数大于block副本数除2(即副本数中还有多数的节点是非异常的)
(2)如果是append或hflushed添加的block,并且副本数大于DN列表数。
当副本数大于3并且满足上述任意条件时,执行替换DN的处理。
dfs.client.block.write.replace-datanode-on-failure.replication
允许的最小失败次数,如果配置为0,那么如果找不到可替换的DN时,会抛出异常。
2.2 异常DN上的数据处理
如下场景,均会导致保存在DN上的数据异常,需要进行处理,
1,DN节点或者进程异常
2,DN本身正常,但是部分block异常(比如磁盘异常)
DN本身会进行定时坏block和磁盘异常的扫描,如果发现了坏block或者磁盘异常,就行自我修复,从其他的DN拷贝对应的block或者隔离异常磁盘。新的block信息,会统一汇报给NN(默认6h一次)。
3. JN高可用
JN本身并进行大量的数据存储,JN的作用是在2个NN之间搭建数据桥梁,在数据写入流程环节中,AcriveNN把edilog写入JN是核心链路中的一环(StandbyNN从JN下载editlog不是)
- 客户端进行数据写入时,ActiveNN将数据写到editlog后,会同步给JN
- StandbyNN从JN下载对应的editlog进行数据同步。
JN节点之间通过Pasox协议进行选主,选主过程跟ZK类型,通常部署单数节点保证集群的一致性。
经过测试,如果JN异常后
1,客户端如果已经完成租约,能够进行数据写入
2,新的客户端无法继续写入数据
测试过程可以参考 写文件中的异常处理
4. 疑问和思考
4.1 DN的block汇报周期是6h,NN的元数据不实时准确,有影响吗?
值得说明的是,由于DN的汇报周期比较长(默认6h一次),客户端请求NN获取对应的数据时,可能会获取错误的DN列表。如果客户端发现DN并没有相关的数据,客户端会自动跳过该DN从下一个DN获取对应的块数据。
因此单个DN异常或者块数据跟NN不准确,并不影响客户端的的读写,因此6h的汇报周期是可以接受的,NN上的元数据不需要实时准确!
4.3 DN宕机后,被NN感知到后,是否会立刻触发block迁移?
是。如下是测试记录
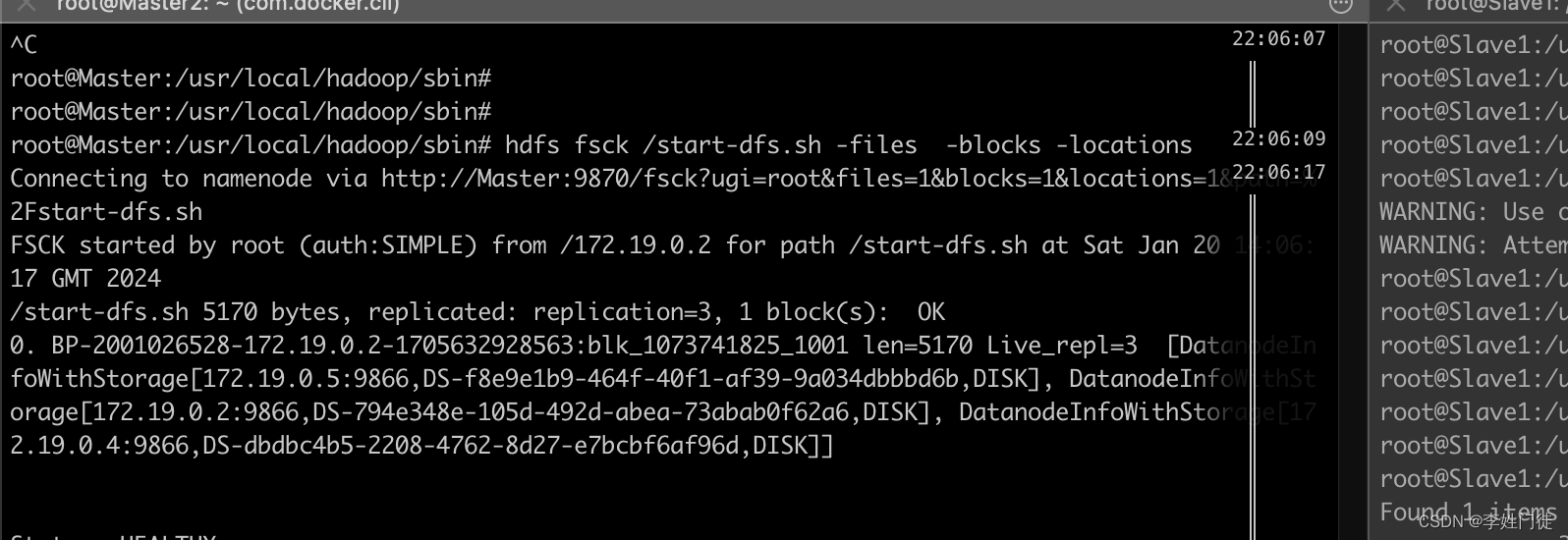
1, 原始的数据block存放的节点信息如下
hdfs fsck /start-dfs.sh -files -blocks -locations
分别部署在3个节点
172.19.0.2
172.19.0.3
172.19.0.4
2, 执行机器DN宕机
虽然DN已经长时间没有接收到DN的心跳,但是不到10min+30s,NN并不判断DN离线。
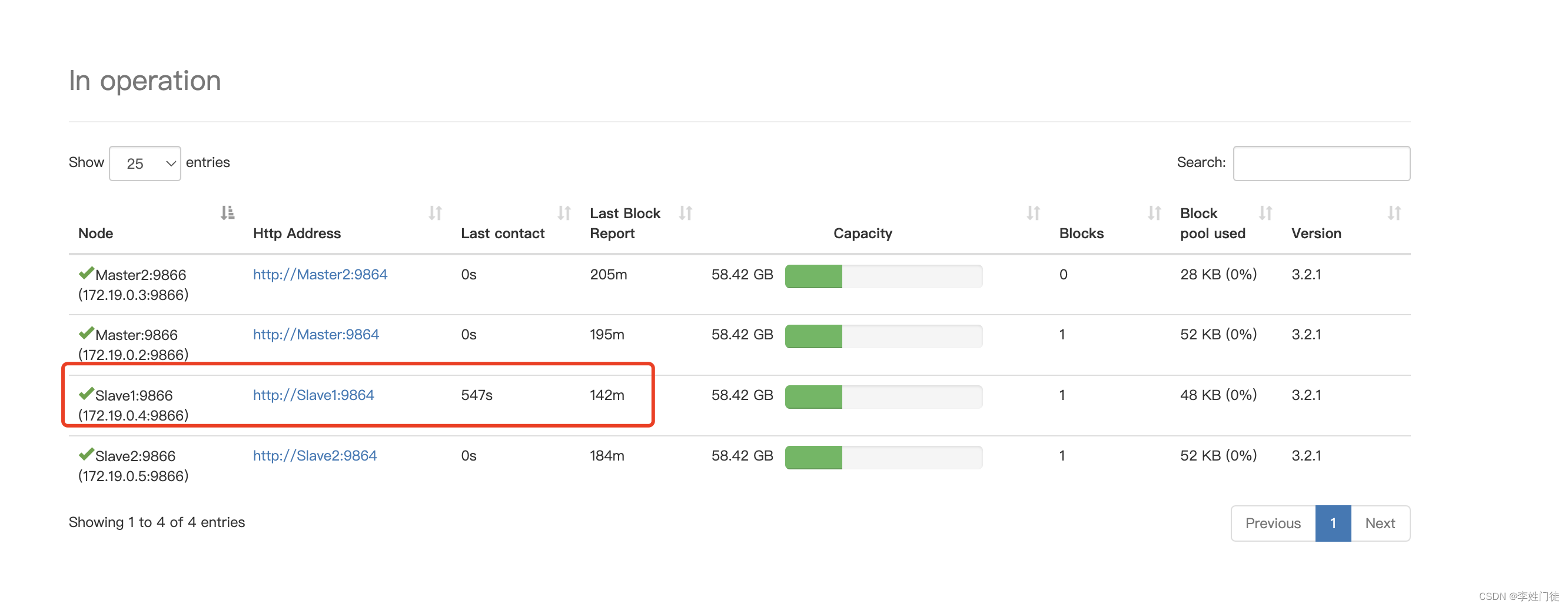
3,10min+30后NN判断DN离线
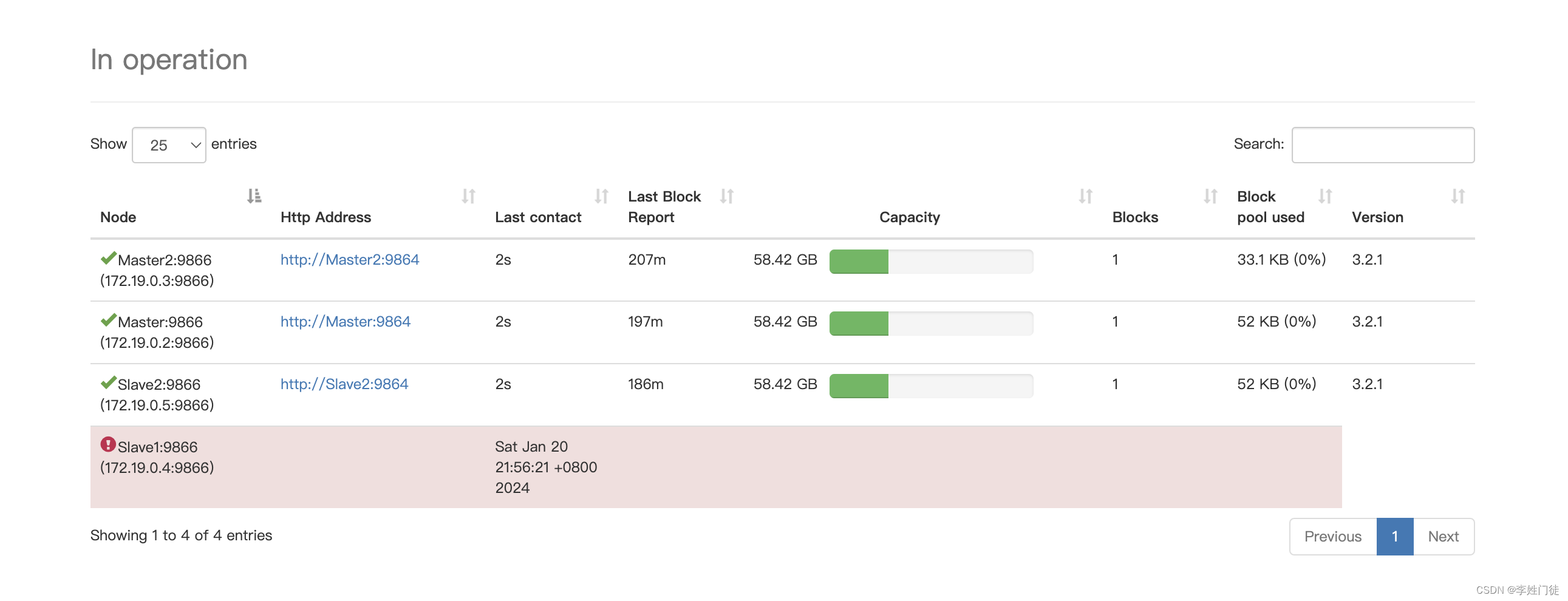
4,异常DN上的block被复制到其他的DN上

172.19.0.4 上的block被迁移到了172.19.0.5上了。
5. 参考文档
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Apache配置ssl证书-实现https访问
- Docker初步使用
- Pytest自动化测试 - 完美结合Allure
- 前置微小信号放大器如何为MEMS传感器测试提供激励信号
- 【华为OD题库-097】最大岛屿体积-java
- 2024年 13款 Linux 最强视频播放器
- 旅游景区项目信息化建设&运营方案:PPT47页,附下载
- Java 第13章 常用类 课堂练习
- App应用商店排名,年初冲刺班开课啦!
- 做测试不会 SQL?超详细的 SQL 查询语法教程来啦!