CLIP 对比学习 源码理解快速学习
最快的学习方法,理清思路,找视频讲解,看源码逻辑:
CLIP 源码讲解 唐宇
输入: 图像-文本成对配对的数据
训练模型的过程(自己理解):
怎么做的?:利用数据内部特征,相似与不相似,学习到能够同时表示图像和文本的潜在特征(相当于把图像和文本在同一个潜在空间里进行特征学习和表示)
为什么能学到呢?:相当于我已知这个图像跟这个文本是配对的,是相似的,或者说这两个东西是一个意思,然后把这两个当成正样本,计算正样本的相似度要越大越好,即学习到的图像和文本的潜在特征表示进行运算后得到的相似度要越大越好,所以反向约束表示图像和文本的特征要能够彼此互通,图像的特征向量能够跟文本的特征向量在语义上能够互相认识彼此,从而认出彼此是相似的。
对比损失函数:

si,i :正样本相似度
si,k:负样本相似度
优化方向:分母的负样本相似度越小越好,小到0可忽略不计,这时正样本上下抵消为1,log1=0,loss为0.
τ是一个神秘的参数,大部分论文都默认采用较小的值来进行自监督对比学习(例如0.05)
- 对比损失是一个具备困难负样本自发现性质的损失函数,这一性质对于学习高质量的自监督表示是至关重要的。关注困难样本的作用是:对于那些已经远离的负样本,不需要让其继续远离,而主要聚焦在如何使没有远离的负样本远离,从而使得表示空间更均匀(Uniformity)
- τ的作用是调节模型困难样本的关注程度:τ 越小,模型越关注于将那些与本样本最相似的负样本分开
累加是相当于i要跟多个非i的剩余负样本计算,比如有5-5的图像文本对,1-1为正样本,1跟2~5都为负样本,都要计算相似度,所以要累加。
模型能力(用训练好的模型进行推理):
- 给一个模型没见过的图像,和几个没见过的文本,能够判断图像跟哪个文本是更加配对的~ 具有泛化能力,相当于我模型已经能够编码图像和文本并且让图像和文本能够互相认识彼此。
- 给一个模型没见过的文本,和几个没见过的图像,能够判断文本跟哪个图像更加配对,同理。
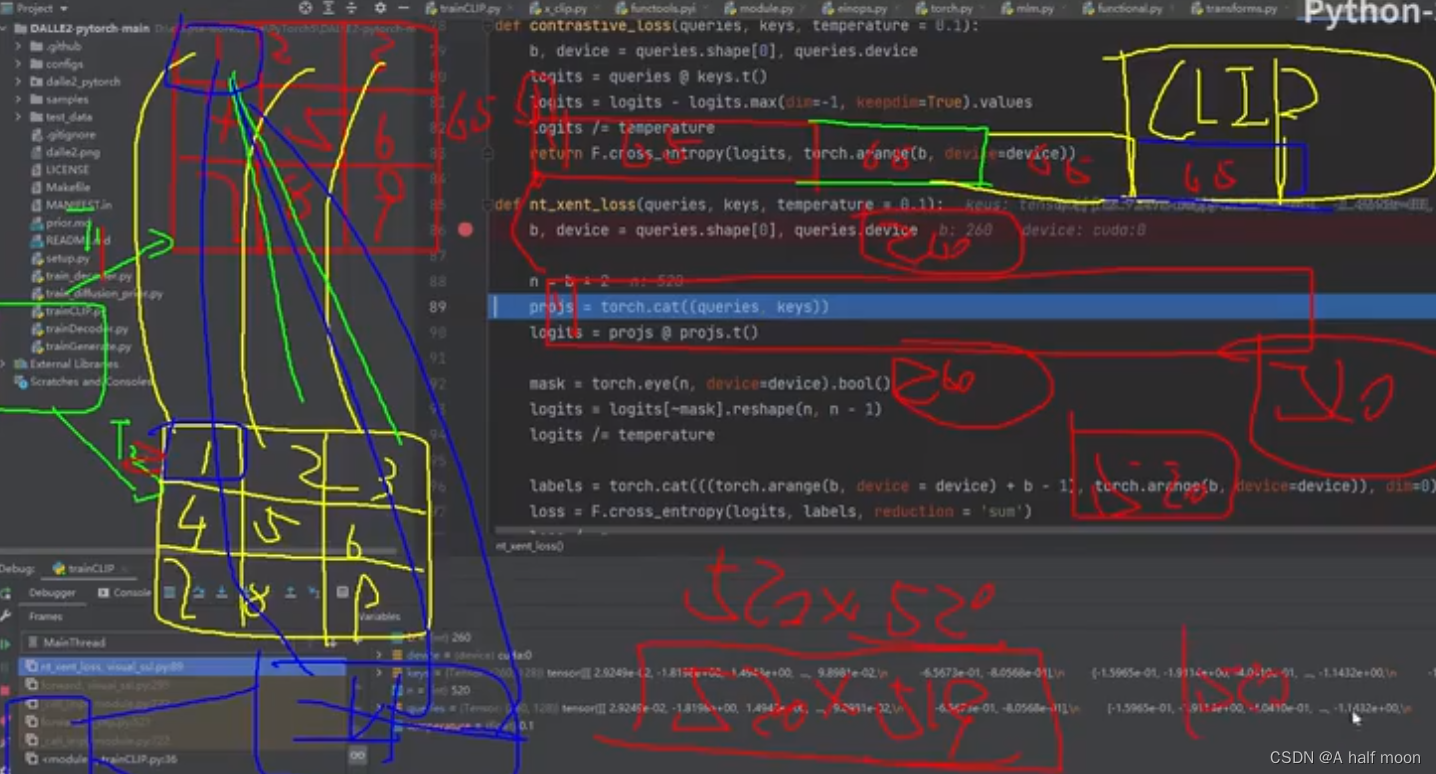
对应CLIP源代码实现细节: (图略有些糊)
-
计算图像和文本的表示向量
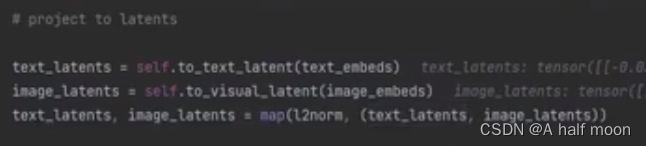
-
计算对比损失
2.1. 计算相似度(具体有两种情况,但最终都是一样,计算图像和文本相似度)
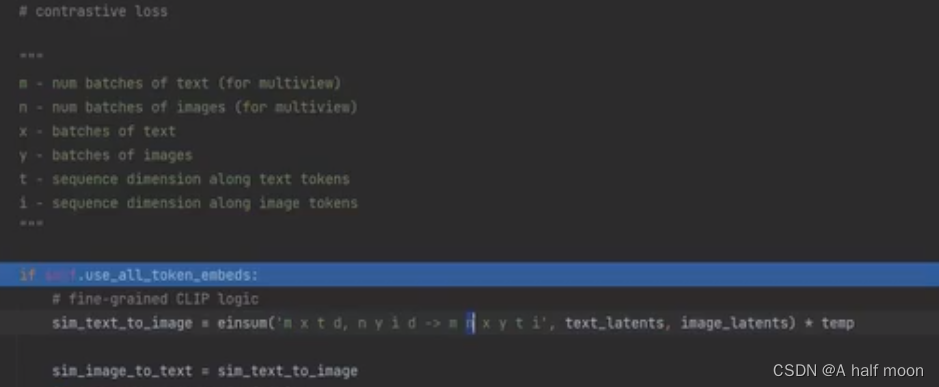

2.2 按照损失公式的运算计算对比损失(exp,log等操作)
exp 运算

计算分子(正样本相似度), 需要用matrix_diag 标记区分

matrix_diag 对角矩阵(矩阵斜线上都为true(表示正样本),其余为false ,(表示负样本))
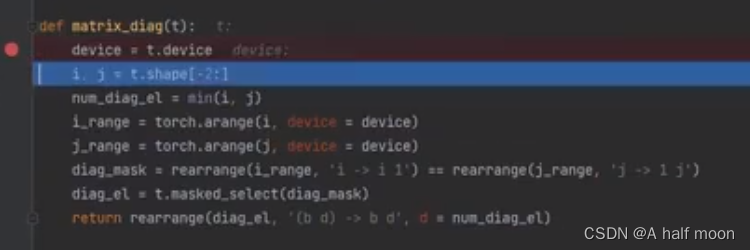
计算分母(负样本相似度)t.masked_fill(pos_mask,0) 把斜对角线上设置为0(正样本),其余设置为1

最终计算contrastive loss,loss计算加上 -log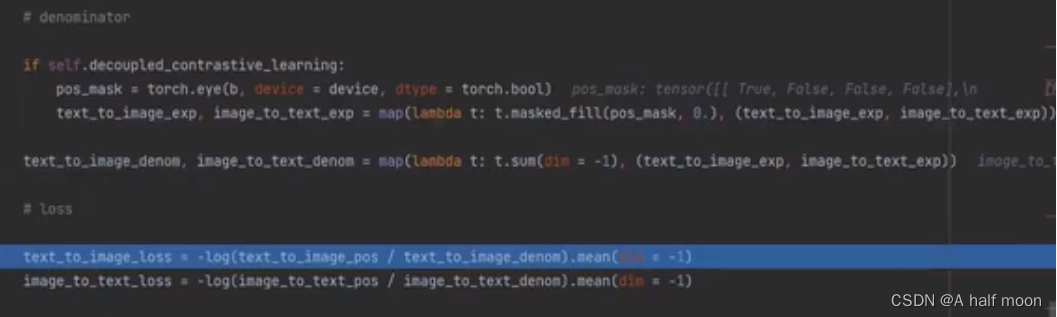
取平均作为最终的loss

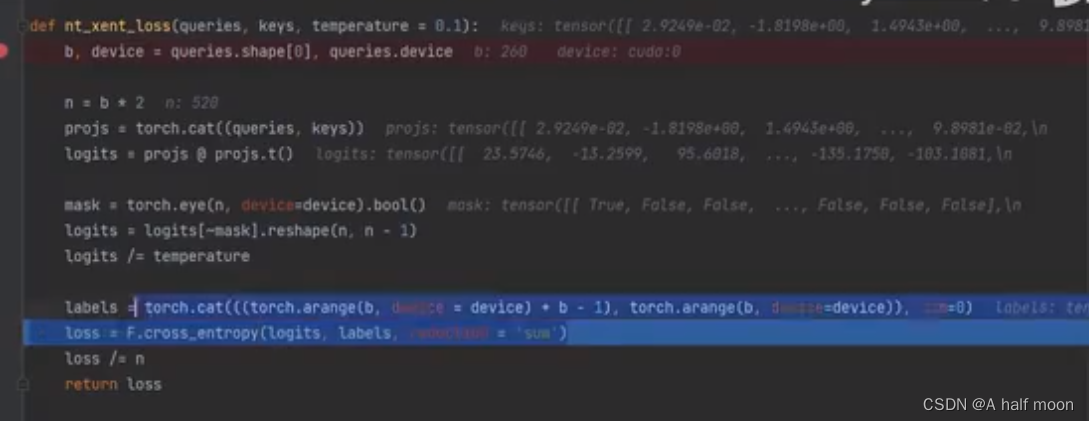
SimCLR 内部成对正样本计算:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- CSS3背景样式详解(图像大小,图像位置等)
- 【从零开始学习Redis | 第一篇】快速了解Redis
- 二.有命管道(FIFO)
- Educational Codeforces Round 161 (Rated for Div. 2)补题
- spring data mongo 在事务中,无法自动创建collection
- Spring Cloud中的提供者与消费者
- Windows实现MySQL5.7主从复制(详细版)
- 【Linux】 Top命令解析
- 全部本地化!ChatGLM+oneapi+fastgpt+微秘+微信 部署实操
- 算法与数据结构--二叉搜索树与自平衡二叉搜索树