【LMM 007】Video-LLaVA:通过投影前对齐以学习联合视觉表征的视频多模态大模型
论文标题:Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
论文作者:Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, Li Yuan
作者单位:Peking University, Peng Cheng Laboratory, Sun Yat-sen University, Tencent Data Platform, AI for Science (AI4S)-Preferred Program, Peking University, FarReel Ai Lab
论文原文:https://arxiv.org/abs/2311.10122
论文出处:–
论文被引:–(12/31/2023)
论文代码:https://github.com/PKU-YuanGroup/Video-LLaVA,1.6k star
Abstract
大型视觉语言模型(Large Vision-Language Model,LVLM)提高了视觉语言理解中各种下游任务的性能。现有的大多数方法都是将图像和视频编码成独立的特征空间,然后将其作为输入输入到大型语言模型中。然而,由于图像和视频缺乏统一的标记化(unified tokenization),即投影前的未对齐,大型语言模型(Large Language Model,LLM)要从几个较差的投影层中学习多模态交互就变得很有挑战性。在这项工作中,我们将视觉表征统一到语言特征空间中,从而推动基础 LLM 向统一的 LVLM 发展。因此,我们建立了一个简单而稳健的 LVLM 基线——Video-LLaVA,它可以从图像和视频的混合数据集中学习,并相互促进。Video-LLaVA 在 5 个图像问题解答数据集和 4 个图像基准工具包的 9 个图像基准中取得了优异的性能。此外,在 MSRVTT,MSVD,TGIF 和 ActivityNet 上,我们的 Video-LLaVA 也分别比 Video-ChatGPT 高出 5.8%,9.9%,18.6% 和 10.1%。值得注意的是,大量实验证明,Video-LLaVA 在统一的视觉表示中使图像和视频互惠互利,性能优于专门为图像或视频设计的模型。我们希望这项工作能为 LLM 的多模态输入提供一些启示。
1. Introduction
最近,LLM 在人工智能界迅速流行起来,如 GPT-3.5,GPT-4 [36],PaLM [2, 4] 和 BLOOM [38]。它们依靠强大的语言理解能力来遵循人类提供的指令并做出相应的反应。通常情况下,LLM 只能在用户提供的文本输入范围内做出响应,而这是不够的,因为人类与世界的交互涉及多种渠道,如视觉和文本。为此,最近的研究[1, 49, 55]将图像映射成类似文本的标记,使 LLMs 具备理解图像的能力。尽管效果显著,但让 LLMs 理解视频比单纯的图像理解任务更具挑战性。不过,最近的研究[27, 35, 52]已经在实现视频与语言之间的交互方面取得了初步进展。
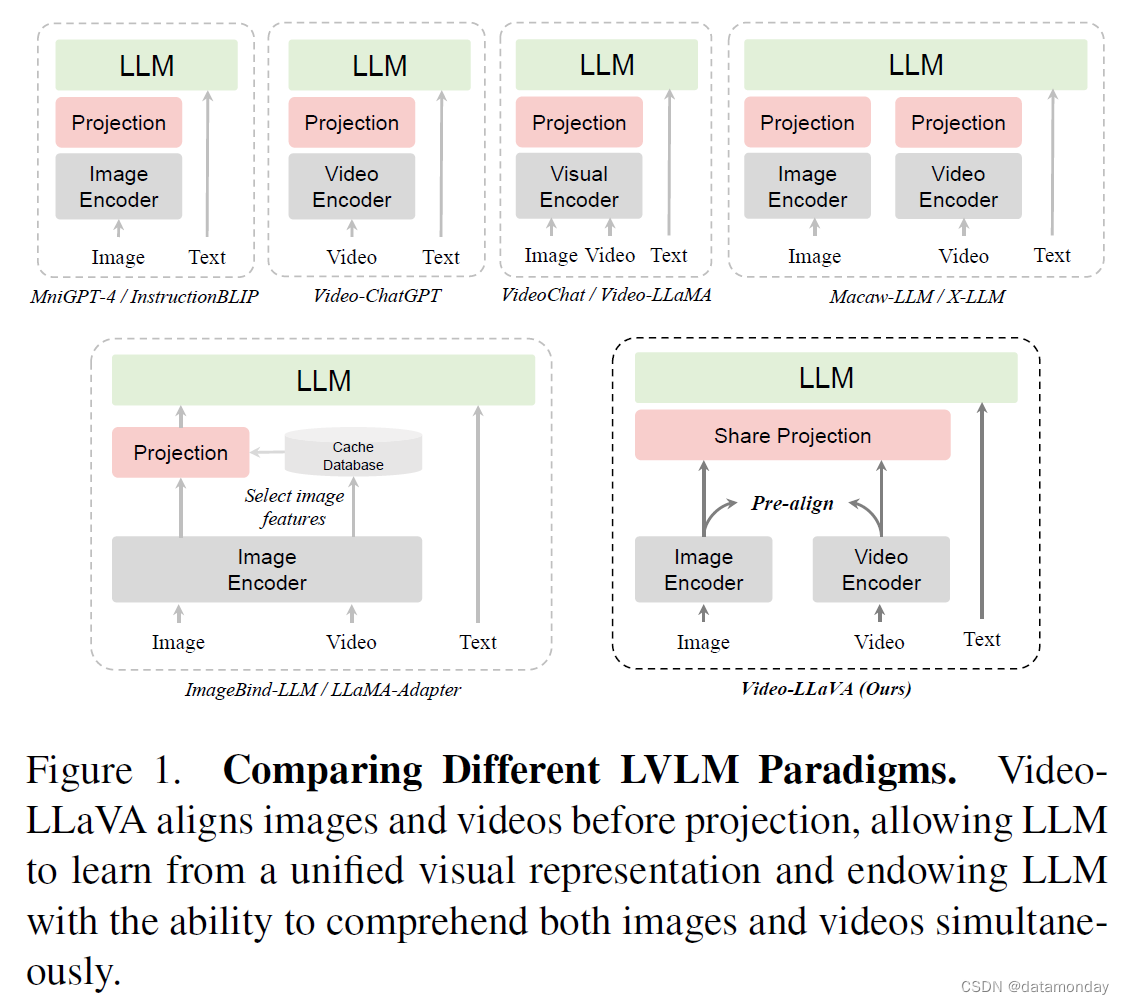
然而,目前大多数 LVLM [9, 23, 26, 33] 主要只能处理单一的视觉模态,即图像语言或视频语言。如图 1 所示,我们比较了不同的 LVLM 范式,其中
- VideoChat [27] 和 Video-LLaMA [52] 利用共享视觉编码器处理图像和视频。然而,由于图像和视频的媒体类型存在固有差异,学习统一的表示方法具有挑战性,其性能明显落后于专门的视频专家模型 Video-ChatGPT。
- 因此,XLLM [7] 和 Macaw-LLM [34] 为每种模态分配了特定模态编码器,试图让 LLM 通过多个投影层理解图像或视频。但它们的性能不如专用的视频专家模型,如 Video-ChatGPT [35]。我们将这一现象归咎于投影前未对齐。由于图像特征和视频特征都存在于各自的空间中,这就给 LLM 从几个糟糕的投影层中学习它们之间的交互带来了挑战。
- ALBEF [24] 和 ViLT [21] 在多模型模型中也讨论过类似的现象,如先对齐再融合。
- 最近,ImageBind-LLM[15]侧重于通过将每种模态预先对齐到一个共同的特征空间,使 LLM 能够同时处理多种模态输入[11]。基于大型图像语言模型,ImageBind-LLM 通过从免训练图像缓存数据库中检索,将其他模态转换为最相似的图像特征。然而,ImageBind-LLM 的间接对齐方法可能会导致性能下降,而且 LLM 对实际视频数据一无所知。
在这项工作中,我们引入了 Video-LLaVA,它是同时处理图像和视频的 LVLM 的一个简单但功能强大的基线。具体来说,如图 1 所示,Video-LLaVA 首先将图像和视频的表示对齐到统一的视觉特征空间。由于视觉表征在投影之前已经对齐,因此我们采用共享投影层为 LLM 映射统一的视觉表征。为了提高计算效率,Video-LLaVA 对图像和视频进行了联合训练,仅训练了1个epoch就取得了显著效果。
因此,Video-LLaVA 极大地提高了 LLM 同时理解图像和视频的能力。在图像理解方面,VideoLLaVA 在 5 个图像基准测试中超越了 mPLUG-owl7B 和 InstructBLIP-7B 等先进的 LVLM。此外,通过使用 4 个基准工具包进行更全面的评估,Video-LLaVA-7B 在 MMBench 中甚至比 IDEFICS-80B 高出 6.4%。此外,在视频理解方面也可以观察到类似的趋势,在 MSVD,MSRVTT,TGIF 和 ActivityNet 视频问题解答数据集上,Video-LLaVA 分别以 5.8%,9.9%,18.6% 和 10.1% 的优势超过了 Video-ChatGPT。广泛的消融实验表明,在投影之前进行对齐会产生更大的优势。此外,图像和视频的联合训练可以促进 LLM 理解中的统一视觉表示。
我们的主要贡献总结如下:
- 我们介绍了功能强大的 LVLM 基线 Video-LLaVA。在训练过程中,Video-LLaVA 将视觉信号与语言特征空间结合起来,统一视觉表征,并在投影前进行对齐。我们使 LLM 能够同时在图像和视频上执行视觉推理功能。
- 广泛的实验证明,统一的视觉表征有利于 LLM 学习同时处理图像和视频,验证了模态的互补性,与专门为图像或视频设计的模型相比,优势明显。
2. Related Work
2.1. Large Language Models
当著名的商业模型 ChatGPT [36] 问世后,人工智能社区通过指令调优和增加模型大小,发布了开源的大型语言模型(LLM)。这些模型包括 LLaMA [44],Vicuna [8],Alpaca [43],以及最近的 LLaMA 2 [45]。这些模型通过指令集进行调优,以模拟人类与人工智能助手之间的对话。此外,InstructGPT [37] 基于 GPT-3 [5],通过与人类偏好保持一致,训练了 1750 亿个参数。然而,LLM 只能在文本中进行交互。在这项工作中,我们引入了 Video-LLaVA,它以 LLM 强大的推理能力为基础,将模态交互扩展到图像和视频。
2.2. Large Vision-Language Models
在将 LLM 扩展到多模态,特别是涉及图像和视频时,主要方法可分为两类(见表 1):
- i) LLMs as scheduler
- ii) LLMs as decoder
LLMs as scheduler
在基于调度器的方法中,各种视觉模型被视为即插即用(plug-and-play)的模块。LLM 根据具体的视觉任务要求(如积木的组装)对它们进行调度。其中一些方法侧重于图像,如 VisualChatGPT [46] 和 HuggingGPT [40],而 MM-REACT [48] 和 ViperGPT [42] 也能处理视频。这些基于调度器的 LVLM 的主要特点是不需要端到端训练,因此无需对每种模态进行预对齐和联合训练。
LLMs as decoder
关于将 LLM 视为解码器的方法,这是我们的主要关注点。
- MiniGPT-4 [55] 通过几个线性投影层将图像标记与大型语言模型的输入对齐。然而,这种对齐方式很弱,缺乏来自人类指令的反馈。
- 随后,mPLUG-Owl [49] 采用了两阶段训练方法。在第一阶段,使用自动回归预训练方式将图像与语言对齐;第二阶段则使用人类指令数据集进行指令调优。
- 随着大型语言模型后端规模的不断扩大,InstructBLIP [9] 和 LLaVA [29, 30] 等方法收集了更大的人类指令数据集来训练更大的 LVLMs(例如 13B 参数)。指令数据集的每个答案都严格遵守给定的指令。然后,他们再利用人类指令数据集进行端到端训练,使 LLM 具备视觉推理能力。
- 此外,Video-ChatGPT [35] 设计了一个 100k 视频指令数据集,成功地增强了 LLM 理解视频的能力。
- VideoChat[27]和Video-LLaMA[52]通过联合训练实现了这一目标,使LLM能够同时处理图像和视频。
- 将 LLM 扩展到其他视觉模态通常需要预先对齐,如 LLaMA-Adapter [10, 53] 和 ImageBind-LLM [15]。
- 它们通过 ImageBind [11] 的模态编码器将其他模态绑定到图像空间。
这些模型证明,统一的特征空间有利于增强 LLM 的多模态推理能力。与之前的研究不同,Video-LLaVA 不仅能预先对齐图像和视频特征,还能对图像和视频进行联合训练,从而帮助 LLM 从统一的视觉表征中学习多模态推理能力。
3. Video-LLaVA
3.1. Model Structure
Framework Overview

如图 2 所示,Video-LLaVA 由用于从原始视觉信号(如图像或视频)中提取特征的 LanguageBind 编码器 fVM [54],Vicuna 等大型语言模型 fL,视觉投影层 fP 和单词嵌入层 fT 组成。我们最初使用 LanguageBind 编码器获取视觉特征。LanguageBind 编码器能够将不同的模态映射到文本特征空间,从而为我们提供统一的视觉表征。随后,共享投影层对统一的视觉表征进行编码,然后将其与标记化文本查询相结合,并输入大型语言模型以生成相应的响应。
United Visual Representation
我们的目标是将图像和视频映射到一个共享的特征空间,使大型语言模型能够从统一的视觉表征中学习。我们假设相同的信息可以通过多种媒体传达。例如,一只奔跑的狗可以同时通过语言,图像或视频来表达。因此,我们可以将不同模态的信息压缩到一个共同的特征空间中,让模型从密集的特征空间中提取信息,促进模态之间的交互和互补。因此,我们选择了 LanguageBind [54]的模态编码器,该编码器可将图像和视频与文本特征空间对齐。
Alignment Before Projection
具体来说,LanguageBind 从 OpenCLIP [18]初始化,在共享特征空间中自然地对齐图像和语言。随后,它使用 VIDAL-10M [54] 中的 300 万个视频-文本对,将视频表示与语言空间对齐。通过共享语言特征空间,图像和视频表征最终汇聚到一个统一的视觉特征空间,我们称之为图像和视频的新兴对齐。因此,我们的视频编码器和图像编码器都是从 LanguageBind 编码器动物园初始化的,为 LLM 预先对齐输入,减少不同视觉信号表征之间的差距。统一的视觉表征在通过共享投影层后被输入 LLM。
3.2. Training Pipeline
总的来说,Video-LLaVA 生成输出的过程与大型语言模型(如 GPT 系列)类似。在给定文本输入 XT 和视觉信号 XV 的情况下,输入信号会根据公式 (1) 被编码成一个词块序列。通过最大化公式 (2) 中的似然概率,该模型最终实现了多模态理解能力。
其中,L 是生成序列 XA 的长度,θ 是可训练参数。我们对图像和视频进行动态联合训练,即一个批次同时包含图像和视频样本。
Understanding Training
在这一阶段,模型需要在广泛的图像/视频/文本对数据集中获得解读视觉信号的能力。每个视觉信号对应一轮对话数据(Xq, Xa),其中 XT = Xq,Xa 是地面实况。这一阶段的训练目标是原始的自动回归损失,即模型学习查看视觉的基本能力。在此过程中,我们会冻结模型的其他参数。
Instruction Tuning
在这一阶段,模型需要根据不同的指令做出相应的反应。这些指令通常涉及更复杂的视觉理解任务,而不仅仅是描述视觉信号。请注意,对话数据 X1 q, X1 a, … , XNq, XNac 是由多轮数据组成的。
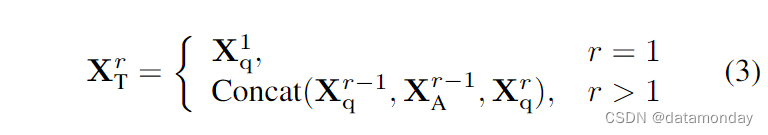
其中 r 代表回合数。如公式 (3) 所示,当 r > 1 时,我们会将前几轮的对话与当前指令合并,作为本轮的输入。训练目标与前一阶段相同。在这一阶段之后,模型将学会根据不同的指令和请求生成相应的响应。LLM 也参与了这一阶段的训练。
4. Experiments
4.1. Experimental Setup
Model Settings
我们采用 Vicuna-7B v1.5 作为大型语言模型。视觉编码器来自 LanguageBind,由 ViT-L/14 初始化。文本标记符来自 LLaMA,大约有 32,000 个类。共享投影层由 2 个全连接层组成。
Data Details
在这里插入图片描述
如图 3 所示,在理解预训练阶段,我们使用了来自 CC3M [39],经 Liu 等人[30]过滤的 558K LAION-CCSBU 图像-文本对子集,其中包含 BLIP [25] 字幕。视频-文本对来自 Valley [33] 提供的子集,在总共 703k 对视频-文本对中,我们可以从 WebVid [3] 中获取 702k 对。在指令调优阶段,我们从两个来源收集了指令数据集,包括来自 LLaVA v1.5 [29] 的 665k 图像-文本指令数据集和来自 Video-ChatGPT 的 100k 视频-文本指令数据集。
Training Details
在训练过程中,我们对每张图像进行了大小调优和裁剪,因此每张处理过的图像大小为 224×224。我们从每段视频中均匀抽取 8 个帧,并对每个帧进行图像预处理。每批数据都是图像和视频的随机组合。在第一阶段,我们使用带有余弦学习率计划的 AdamW 优化器,以 256 的批次大小训练一个 epoch。在第二阶段,我们将批次大小减小到 128。两个阶段的初始学习率均设为 1e-3,热身率为 0.03。其他超参数设置见附录。
4.2. Quantitative Evaluation
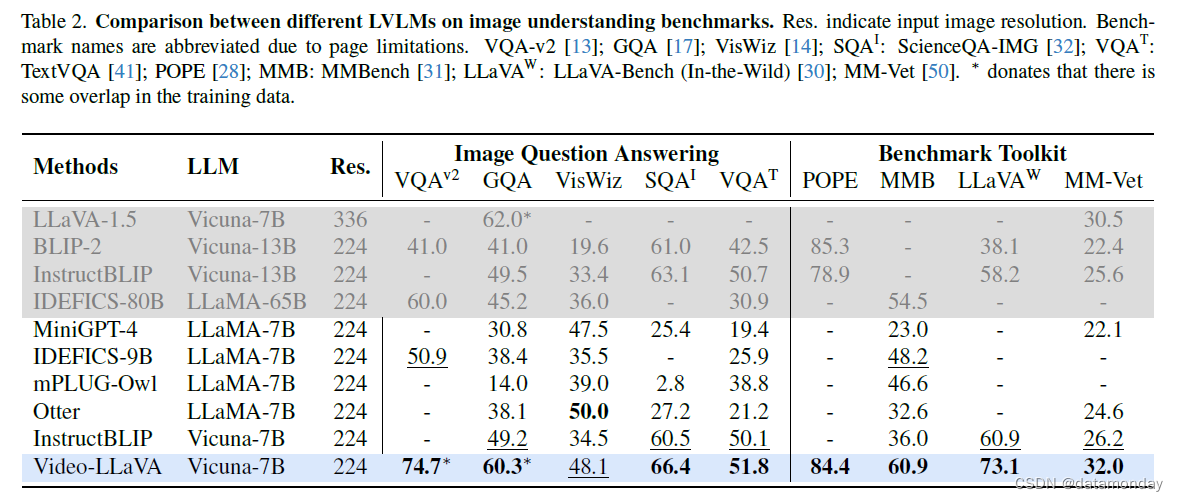
如表 2 所示。如表 2 所示,Video-LLaVA 在 8/9 项图像理解基准测试中取得了最佳性能,在另一项测试中排名第二。
Zero-shot Image Question-answering
首先,我们在5个学术图像问题解答基准上评估了我们的图像理解方法。与最先进的模型 InstructBLIP-7B 相比,VideoLLaVA 展示了强大的图像理解能力,在所有五个问题解答基准测试中均表现优异。此外,与基于 13B 或 65B LLM 调优的几种更强大的 LVLM 相比,Video-LLaVA 的结果也很有竞争力,例如在 VisWiz 上比 InstructBLIP-13B 高出 14.7%,凸显了它在自然视觉环境中的强大理解能力。
Evaluation under Benchmark Toolkits
此外,我们还利用几个用于可视化指令调优的基准工具包对 LVLM 进行了评估。这些基准工具包通过强大的评估指标对模型的能力进行了详细评估。在 MMBench,LLaVA-Bench 和 MM-Vet 上,Video-LLaVA 的性能分别比 InstructBLIP-7B 高出 24.9%,12.2% 和 5.8%。值得注意的是,与大型 LLM 模型相比,Video-LLaVA-7B 仍然表现出先进的性能,在 MM-Vet 上超过 InstructBLIP-13B 6.4%,在 MMBench 上超过 IDEFICS-80B [22] 6.4%。这些结果表明,Video-LLaVA 对场景的语义方面有很强的理解能力,能够回答有关图像的开放式和自由形式的自然语言问题。
Zero-shot Video Understanding
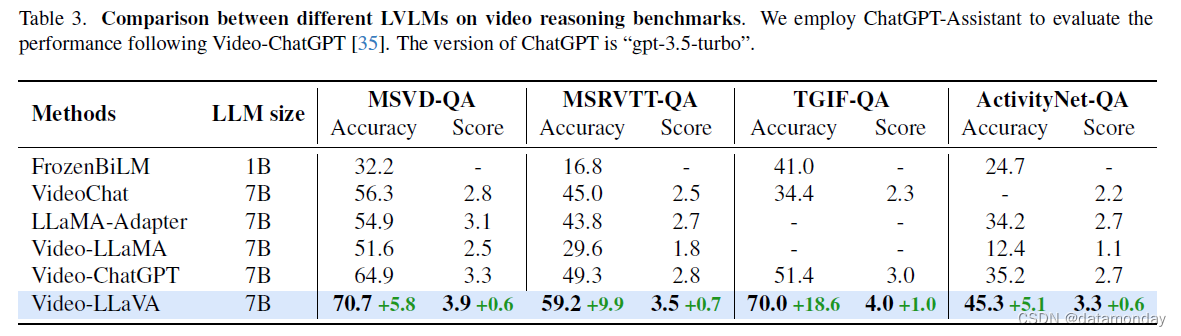
如表 3 所示,我们在 MSVD-QA [6],MSRVTT-QA [47],TGIF-QA [19] 和 ActivityNet-QA [51] 等四个数据集上对大型视频语言模型的视频答题能力进行了定量评估。视频理解的评估流程遵循 Video-ChatGPT。我们使用 GPT-Assistant 评估准确率和得分。Video-LLaVA 在问题解答准确率方面一直优于 Video-ChatGPT,是一种先进的大型视频语言模型。
此外,在 MSRVTT,MSVD,TGIF 和 ActivityNet 上,Video-LLaVA 分别以 5.8%,9.9%,18.6% 和 10.1% 的优势超过了功能强大的基线 Video-ChatGPT。此外,我们还与最近的 SOTA 模型 Chat-UniVi [20] 进行了比较。尽管 Chat-UniVi 使用了更多的数据集,如 MIMIC-IT [23],VideoLLaVA 仍然取得了具有竞争力的结果,在 MSVD,MSRVTT 和 TGIF 数据集上超过了 Chat-UniVi。总之,这些结果验证了 Video-LLaVA 理解视频并根据指令提供上下文适当响应的能力。
Object Hallucination Evaluation
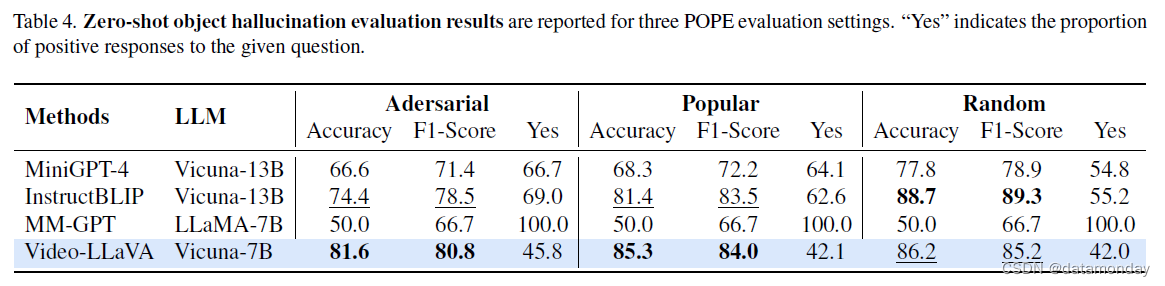
如表 4 所示,我们利用基于轮询的查询方法 [28] 衍生出的评估管道,报告了零样本物体幻觉的评估结果。如表 4 所示,我们利用基于轮询的查询方法[28]衍生出的评估管道,报告了零样本物体幻觉的评估结果。Video-LLaVA 在随机,流行和对抗三个子集中都表现出了极具竞争力的性能。具体来说,与 7B 基础模型相比,在所有三个 POPE 幻觉评估子集中,Video-LLaVA 的性能始终优于 MMGPT [12]。此外,与更大的 13B LLM 相比,Video-LLaVA 甚至全面超越了 Mini-GPT4。Video-LLaVA 在物体幻觉检测方面的成功表现验证了统一视觉表征与文本描述生成之间的一致性。
Exhibition Board


在图 4 中,我们选择了几个经典案例来探讨 Video-LLaVA 的多模态理解能力。在图像理解方面,我们将其与 GPT-4 进行比较。前两幅图像来自 GPT-4,最后一幅图像来自 LLaVA。与 GPT-4 相比,Video-LLaVA 的响应更全面,更直观,更符合逻辑。例如,在第一幅图像中,Video-LLaVA 不仅预测了即将发生的事情,还识别出手套是红色的,球是蓝色的,而 GPT-4 却无法识别。在视频理解方面,我们并没有仔细挑选视频。视频来自 Video-ChatGPT,这是一种先进的大型视频语言模态。总的来说,我们发现Video-LLaVA 和 Video-ChatGPT 生成的句子非常相似。然而,Video-LLaVA 擅长根据给定指令从视频中提取关键信息,突出显示的紫色文字就是证明。此外,利用统一的视觉表征,我们观察到 Video-LLaVA 展示了同时理解由图像和视频组成的输入的能力。如图 4 中粗体字体所示,这有力地证明了 LLM 后端对图像和视频都具有强大的处理能力。这些结果表明,Video-LLaVA 具有同时理解图像和视频的能力,而且是从统一的视觉表征中学习的。
4.3. Ablation Results
4.3.1 Alignment Before Projection
为了验证分离式视觉表征造成的性能下降,我们进行了实验来探索从不同视觉表征学习 LLM 的性能。我们将 Language-Bind 图像编码器定义为统一视觉表征,而 MAE 编码器 [16] 则是分离视觉表征,它是一种著名而有效的图像特征提取器。我们只用相同比例的 MAE 图像编码器替换图像编码器,并保留 LanguageBind 视频编码器。我们在 13 个基准测试中比较了联合视觉表示法和分离视觉表示法,其中包括 9 个图像理解基准测试和 4 个视频理解基准测试。
For Image Understanding
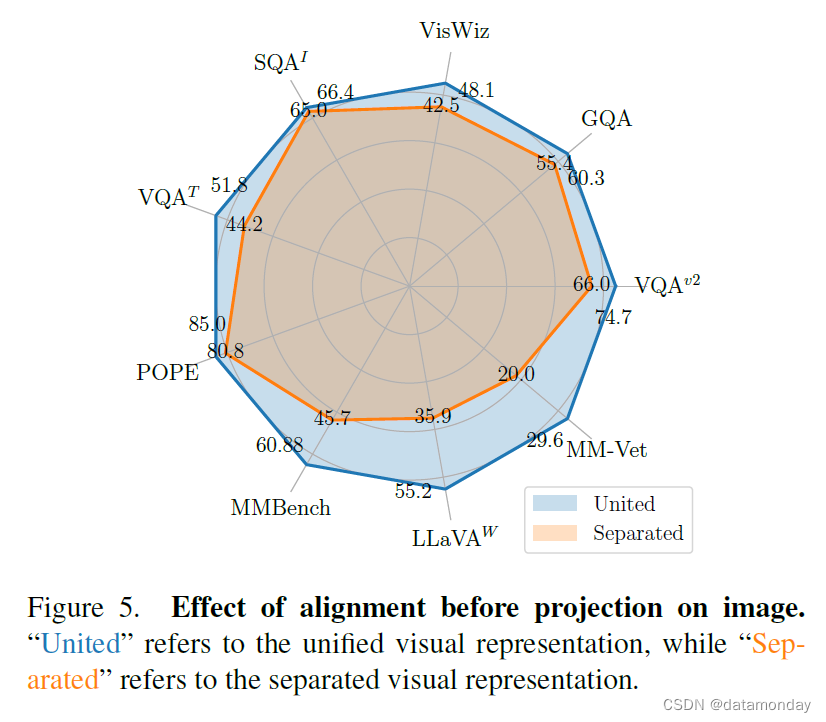
在图 5 中,统一可视化表示法在 5 个图像问答数据集和 4 个基准工具包中全面超越了分离式视觉表征,表现出强劲的性能。此外,我们还观察到,在 POPE,MMBench,LLaVA-Bench 和 MMVet 基准工具包上,统一视觉表示法的性能提升幅度很大。这说明统一视觉表示法不仅能提高图像问答的性能,还能在图像理解的其他方面带来好处,如减少物体幻觉和提高 OCR 能力。
For Video Understanding

由于用 MAE 编码器替换了图像编码器,在 LLM 初始学习视觉表征时,视频特征和图像特征不再是统一的。在图 6 中,与分离式视觉表征相比,统一式视觉表征在 4 个视频答题数据集上的性能都有显著提高。分离式视觉表征不仅在问题解答中表现出较低的准确率,而且在答案得分上也表现出类似的趋势。这些结果表明,统一视觉表征可以帮助 LLM 进一步学习和理解视频。
4.3.2 Joint Training
本小节旨在验证图像和视频在联合训练过程中的互补性,这可以在统一视觉表征的基础上相互增强 LLM 对图像和视频的理解。
For Image Understanding
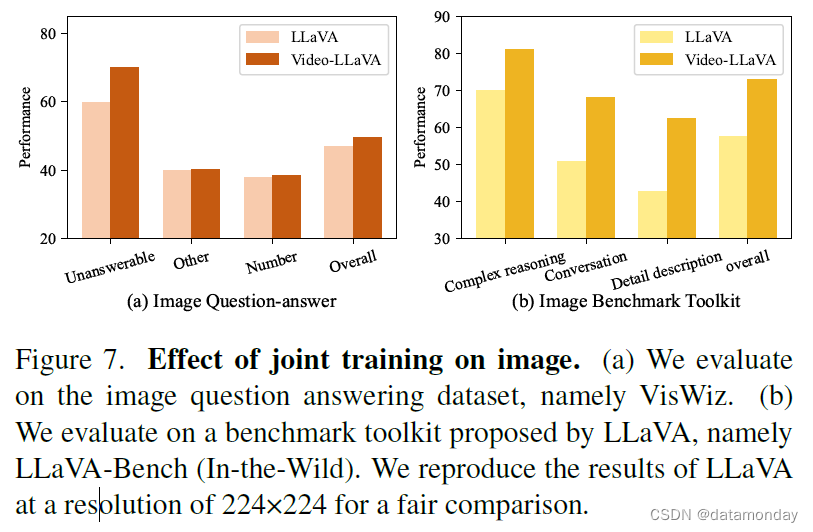
如图 7 所示,我们发现图像和视频都能从联合训练中获益,显示出视觉理解能力的共同提高。与 LLaVA 相比,我们在 VisWiz 上对图像问题解答进行了评估,主要集中在三个方面:
- i)无法回答,预测视觉问题是否无法回答;
- ii)数字,与数字理解相关的任务;
- iii)其他,额外的视觉理解任务。在无法回答和数字任务中,Video-LLaVA 的表现优于 LLaVA,这表明通过视频进行联合训练可以减轻图像中的物体幻觉,增强对图像中数字信号的理解。在 LLaVA-Bench 上也观察到了类似的趋势,视频数据显著提高了 LLM 在复杂推理和图像对话任务中的表现。
For Video Understanding
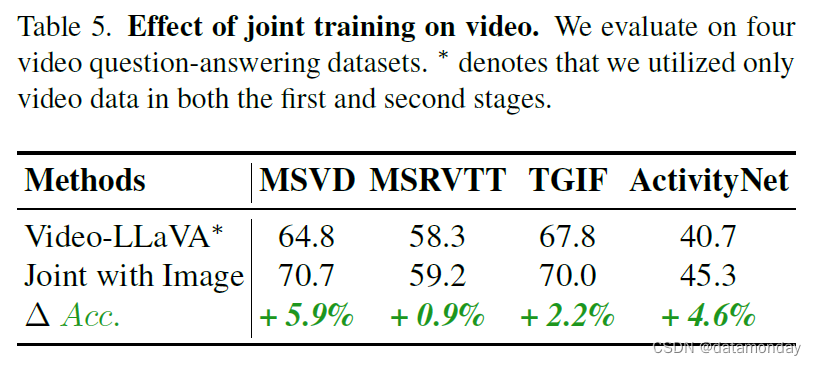
在表 5 中,我们在四个视频问题解答数据集上评估了我们的模型。在表 5 中,我们在四个视频问题解答数据集上评估了我们的模型。与不使用图像训练的 Video-LLaVA? 相比,使用图像和视频联合训练的模型在所有四个视频数据集上都取得了全面的改进。这些结果表明,图像和视频的联合训练有助于 LLM 理解视觉表征。
5. Conclusion and Future Directions
在这项工作中,我们介绍了视频-语言基线模型(Video-LLaVA),这是一种简单但功能强大的大型视觉语言基线模型。我们提出了一个新颖的框架,利用 LanguageBind 编码器将视觉信号预先绑定到语言特征空间,从而解决投影前的未对齐问题。为了让 LLM 能够同时理解图像和视频,我们对图像和视频进行了联合训练,使 LLM 能够从统一的视觉表征中学习多模态交互。广泛的实验证明,对图像和视频进行联合训练可相互提高性能。此外,我们还验证了在投影前对齐视觉表征有助于 LLM 学习。值得注意的是,LLM 从统一的视觉表征中学习后,表现出了同时参与图像和视频的非凡能力,展示了对统一视觉概念的强大理解力。这些结果共同证明了Video-LLaVA训练框架的有效性。作为一个统一的视觉训练框架,Video-LLaVA 的性能甚至超过了专门为图像或视频设计的专家模型。
Future work
虽然Video-LLaVA 在图像和视频方面都表现出很强的竞争力,但我们发现它在把握时间关系和时空定位方面存在困难。Video-LLaVA 可以作为基线,扩展到更多与视觉相关的模态,如深度和红外图像。此外,我们还可以探索如何有效结合时间戳嵌入,使大型视觉语言模型能够回答与时间关系相关的问题。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- GO——flag
- 听力损失是不是只和年龄有关?听损还能恢复吗?……15秒带你看清真相
- 约瑟夫环问题
- 新项目介绍!Solana顶级借贷协议Solend宣布扩展至Sui上
- java面试题-mysql关键字select、from、where等执行的顺序
- HOJ 项目部署-前端定制 默认勾选显示标签、 在线编辑器主题和字号大小修改、增加一言功能 题目AC后礼花绽放
- ChatGLM3在windows上部署
- 通用Mapper怎么开接口扫描
- Prometheus监控nginx
- 获得淘宝商品评论 API