redis复习总结
我的redis
1. redis集群
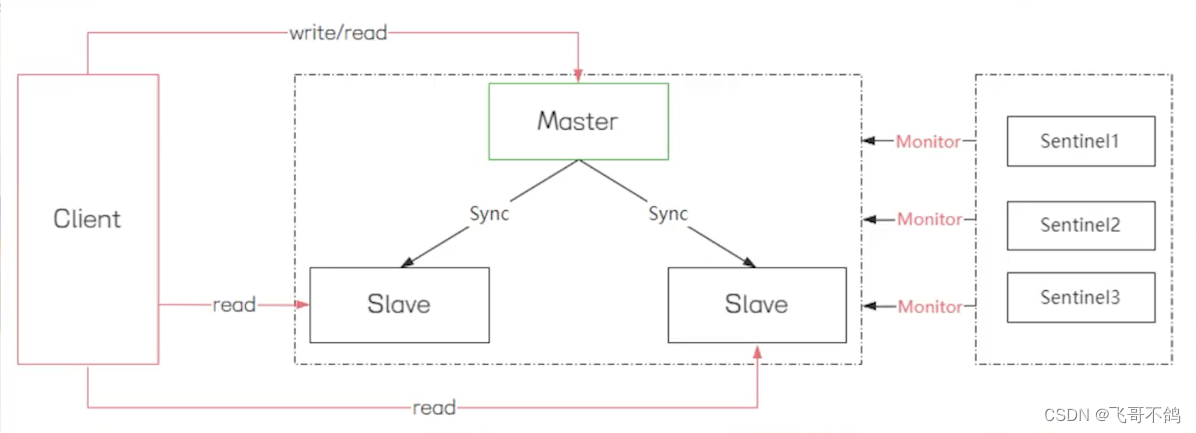
主从集群【哨兵集群】:主从集群是指中,存在一个master节点和多个slave节点。master节点负责接收客户端的读写,slave节点负责读操作。主节点一旦接收到数据的变更,就会将数据同步至slave节点。
但这样的模式下,如果master节点下线,集群不会自动选取主节点。因此redis提供了哨兵机制,用于监控redis集群。如果哨兵发现master节点下线,则会自行从slave节点中选出新的主节点。同样,哨兵也可以组成集群,用于哨兵间的相互监督。
但是主从集群无法解决动态扩容问题,因此就有了redis cluster
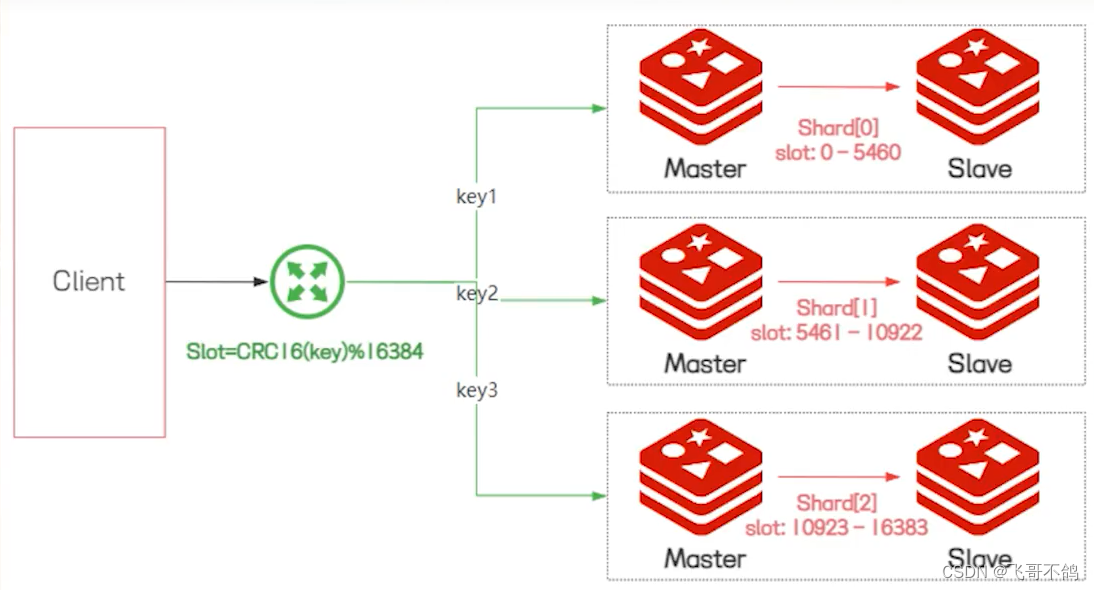
redis cluster:redis cluster实现了redis数据的分布式存储。每个节点存储不同的数据,实现数据分片的功能。
redis cluster提供了slot槽,每个节点都会分配一个slot槽。但存储数据时,redis会根据key进行计算,得到一个slot值。根据slot值从不同的redis节点中查询或存储数据。
对于每个节点来说,节点本身也可以实现主从复制的模式。
二者区别:
- 哨兵集群实现了主从复制,实现读写分离;而cluster集群的slave节点只是个冷备节点,当master挂了才会进行读写操作
- 哨兵集群没法动态扩容;cluster集群通过slot槽实现数据分片的功能,能够动态扩容
- 从集群方式来看,哨兵是一主多从,而cluster是多主多从
2. redis内存淘汰策略
-
Random算法
-
TTL算法
-
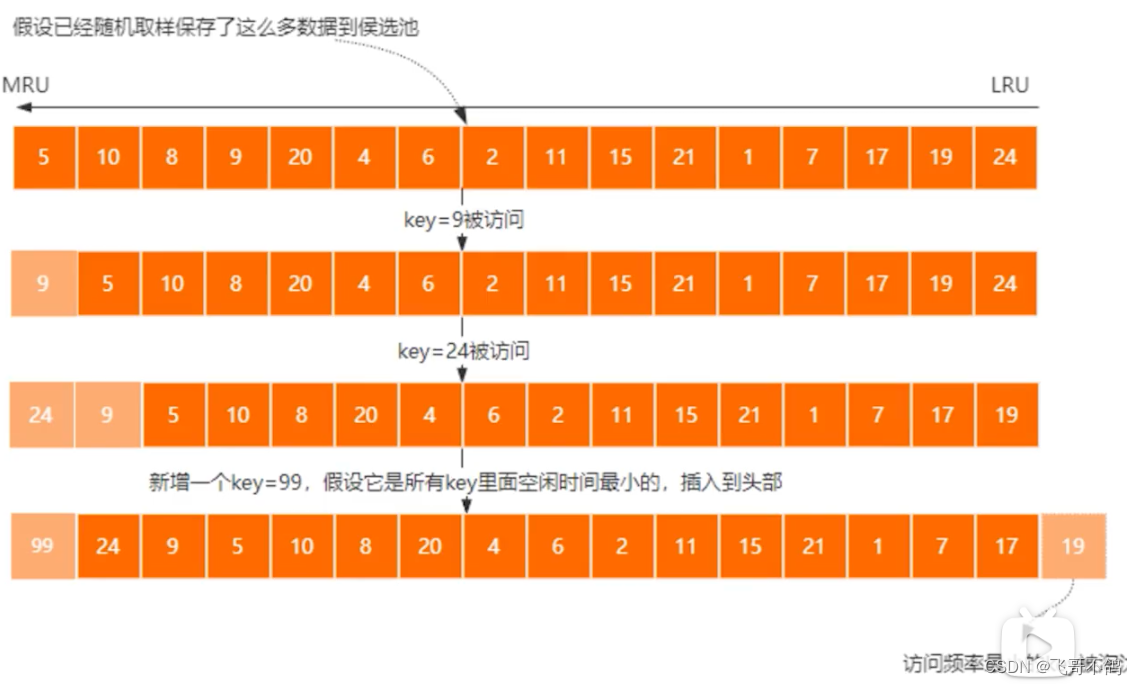
LRU算法:Least Recently Used,最近最少使用。redis会维护一个候选池,池中数据会根据时间进行排序。每次抽取5个key,存入候选池中。当候选池满了之后,会将访问时间最大的key删除。
-
LFU算法:Least Frequently Used,最近最小频率使用。LFU算法是一个二维的双向链表,一个是维护访问频率,另一个是维护相同访问频率的不同key。当key被访问后,会改变它的访问频数,移动该节点。通过维护访问频次来实现低频使用key的数据淘汰。但使用频率也有缺点,比如一个key一开始访问频率高,但后续访问频率低,这样的话就没办法很好的淘汰这个key。因此,LFU算法也会参考key的上次访问时间,来标记key是否为热点数据。

3. redis 6.0 多线程
redis多线程不是多指令的多线程,而是对网络io的多线程。对于redis来说,性能瓶颈主要集中在网络,cpu,内存,而网络这方面是最值得优化的地方。以前redis是使用一个线程处理socket连接都是一个线程处理,现在采用多线程的方式加快网络处理速度。
4. redis 主从复制原理
redis主从复制提供了两种方案,分别是全量复制,增量复制
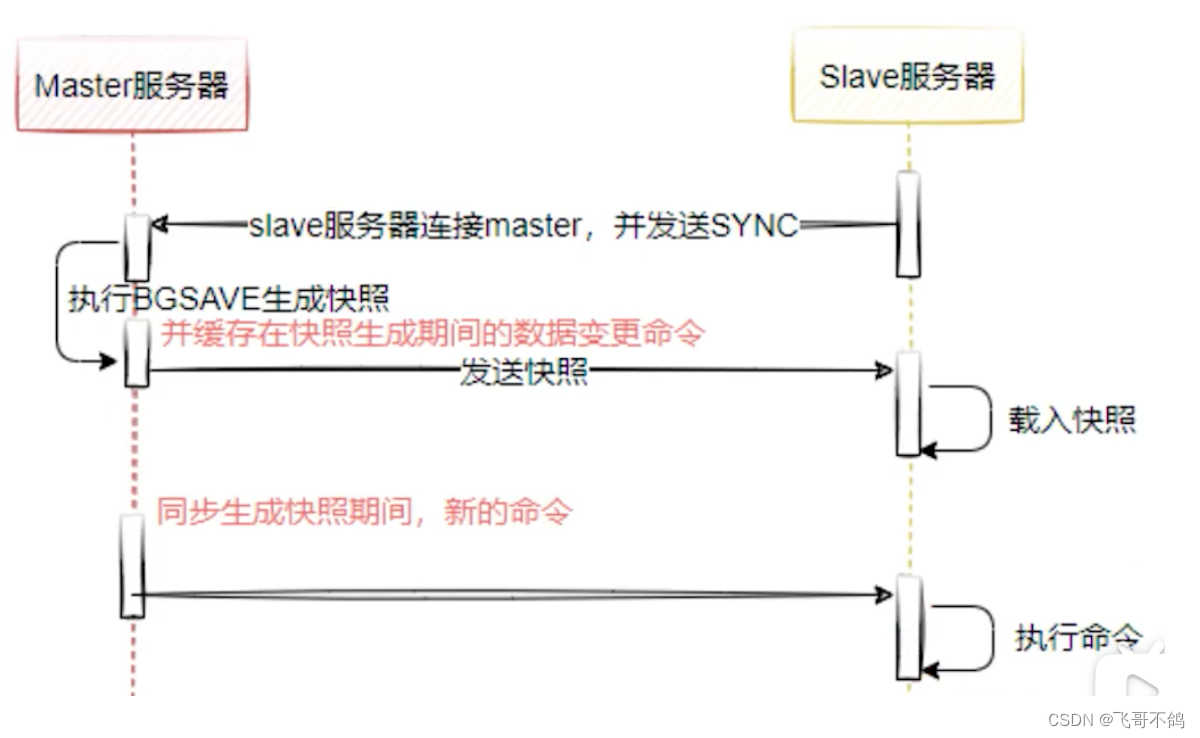
全量复制主要原理如下:slave节点连接master节点,发送同步请求。master节点会执行BGSAVE生成数据快照。然后将数据发送给slave节点。master节点同时还会缓存同步期间变更的数据,再于slave节点进行同步。
增量复制:master节点会将变更的数据同步给slave节点。增量复制是通过维护offset这样一个偏移量来实现数据的同步。
5. redis缓存穿透
客户端请求的数据,数据库不存在。redis始终不会生效
- 缓存空对象
- 请求为null,直接缓存空对象。但可能会缓存大量垃圾数据。所以需要设置TTL。并且可能存在短期不一致性。
- 布隆过滤器
- 在客户端请求redis前,增加过滤层。
6. 缓存雪崩
短时间内,大量缓存key同时失效,或者redis宕机,导致请求直接到达数据库
- 给TTL添加随机值
- 添加多级缓存
7. 缓存击穿
短期内,热点key失效,导致大量请求访问数据库
【防止多个线程同时查询数据库,重构redis】
- 互斥锁
- 当一个线程更新redis时,加锁防止其余线程同时更新redis
- 逻辑过期
- 当监测发现redis的key过期时,对redis加锁。同时开启新的线程,同步redis数据。然后返回旧的过期数据。只有当开启的线程结束,redis锁才会被释放。再次期间内,其余请求均获取锁失败,返回旧数据。
在这里插入图片描述
8. 秒杀存在的问题
- 超买超卖
- CAS解决:
- 执行逻辑:查询当前库存,假设为x。执行update减少库存时,判断库存是否任然为x。如果是,则表明没有被其它线程干扰,执行sql;否则执行失败
- 存在问题:假设同一时间有100个线程查询库存,且皆为x。此时只有一个线程能够成功扣减库存。此时库存为x - 1。而其它99个线程发现库存已经不为x,那么剩余99个线程均执行失败。
- CAS解决:
- 一人一单:
- 查询资格
- 库存是否足够
- 是否购买过
- 下单
- 查询资格 + 下单应为原子操作。也就是说,两部操作需要加锁
- 查询资格
- 秒杀优化
-
数据库异步下单
-
redis扣减库存 + redis下单
-
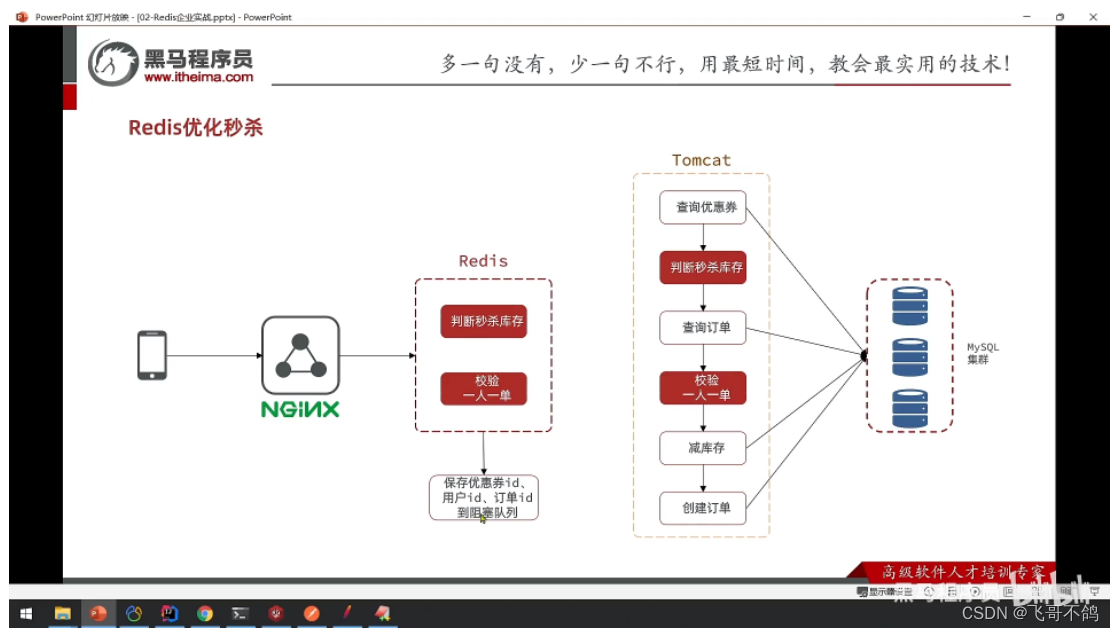
-
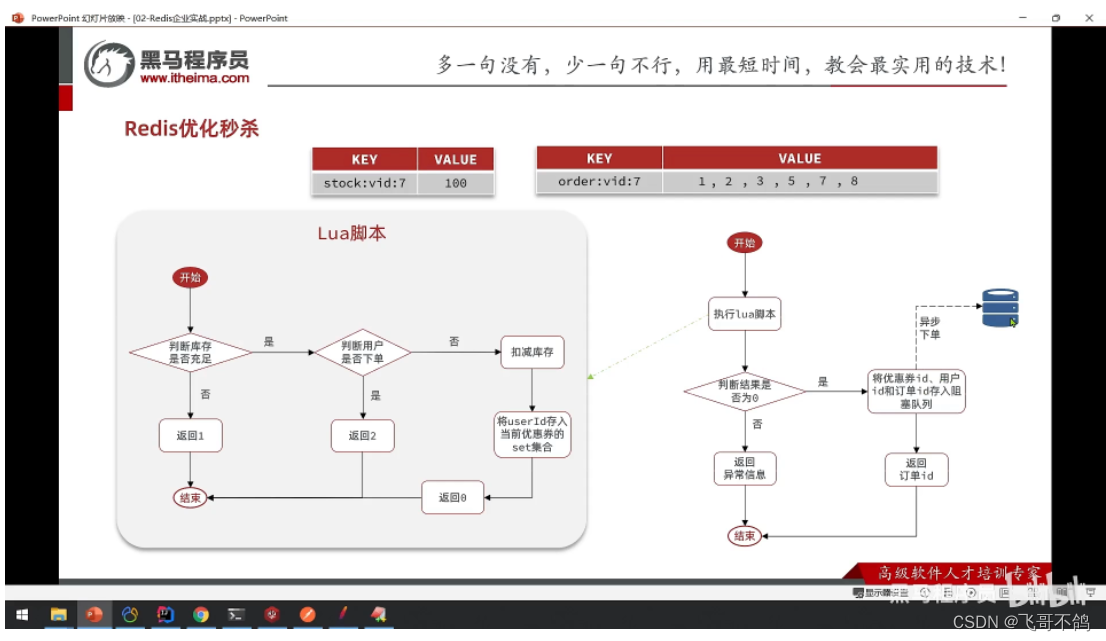
-
9.intSet集合底层源码
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
- encoding:编码格式,用于确定存储数据的编码格式
- length:标识存储数据个数
- contents:存储数据地址(指针)
添加元素
/* Insert an integer in the intset */
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {
/* 判断插入数据的编码类型, 如果过大, 需要重新修改is的encoding */
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
if (success) *success = 1;
/* Upgrade encoding if necessary. If we need to upgrade, we know that
* this value should be either appended (if > 0) or prepended (if < 0),
* because it lies outside the range of existing values. */
// 如果当前插入元素的编码大于is的现有编码, 进行数据编码升级
if (valenc > intrev32ifbe(is->encoding)) {
/* This always succeeds, so we don't need to curry *success. */
return intsetUpgradeAndAdd(is,value);
} else {
/* Abort if the value is already present in the set.
* This call will populate "pos" with the right position to insert
* the value when it cannot be found. */
// 二分查找, 确定新元素因该插入的位置, 同时保证元素的唯一性
if (intsetSearch(is,value,&pos)) {
if (success) *success = 0;
return is;
}
// 扩容
is = intsetResize(is,intrev32ifbe(is->length)+1);
// 移动pos+1后面元素
if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1);
}
_intsetSet(is,pos,value);
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
return is;
}
is数据结构升级
/* Upgrades the intset to a larger encoding and inserts the given integer. */
static intset *intsetUpgradeAndAdd(intset *is, int64_t value) {
uint8_t curenc = intrev32ifbe(is->encoding);
uint8_t newenc = _intsetValueEncoding(value);
int length = intrev32ifbe(is->length);
int prepend = value < 0 ? 1 : 0;
/* First set new encoding and resize */
// 设置新的编码
is->encoding = intrev32ifbe(newenc);
// 数组扩容
is = intsetResize(is,intrev32ifbe(is->length)+1);
/* Upgrade back-to-front so we don't overwrite values.
* Note that the "prepend" variable is used to make sure we have an empty
* space at either the beginning or the end of the intset. */
// 倒序重拍元素
while(length--)
_intsetSet(is,length+prepend,_intsetGetEncoded(is,length,curenc));
/* Set the value at the beginning or the end. */
// 赋值新元素
if (prepend)
_intsetSet(is,0,value);
else
_intsetSet(is,intrev32ifbe(is->length),value);
// 重置长度
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
return is;
}
10. dict结构底层源码
struct dict {
dictType *type;
// 数组, 存储hash表
dictEntry **ht_table[2];
unsigned long ht_used[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
/* Keep small vars at end for optimal (minimal) struct padding */
int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error) */
signed char ht_size_exp[2]; /* exponent of size. (size = 1<<exp) */
};
struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
// 解决hash冲突
struct dictEntry *next; /* Next entry in the same hash bucket. */
};
hash扩容时机
/* Expand the hash table if needed */
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
// 如果正在rehash, 则直接返回
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
if (DICTHT_SIZE(d->ht_size_exp[0]) == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
if (!dictTypeExpandAllowed(d))
return DICT_OK;
if ((dict_can_resize == DICT_RESIZE_ENABLE &&
d->ht_used[0] >= DICTHT_SIZE(d->ht_size_exp[0])) ||
(dict_can_resize != DICT_RESIZE_FORBID &&
d->ht_used[0] / DICTHT_SIZE(d->ht_size_exp[0]) > dict_force_resize_ratio))
{
return dictExpand(d, d->ht_used[0] + 1);
}
return DICT_OK;
}
- rehash:
- 已经在rehash
- ht_used[0] >= 1 << ht_size_exp[0] 【存储的节点个数 >= hash数组长度】
- ht_used[0] / (1 << ht_size_exp[0]) > 5 【必须rehash】
- 不进行rehash
- size == 0
- dict_can_resize 不能进行rehash
rehash操作: 延迟rehash
申请新的hash表,将其赋值给dict的另外一个hash表用于存储。未来数据的增删改查,需要在旧hash,新hash中判断。如果数据在旧hash表中,则需要进行数据迁移。直到rehash结束。rehash动作完成后,更换新旧hash表在dict中存储位置。0号hash表为新表,1号hash表置为null
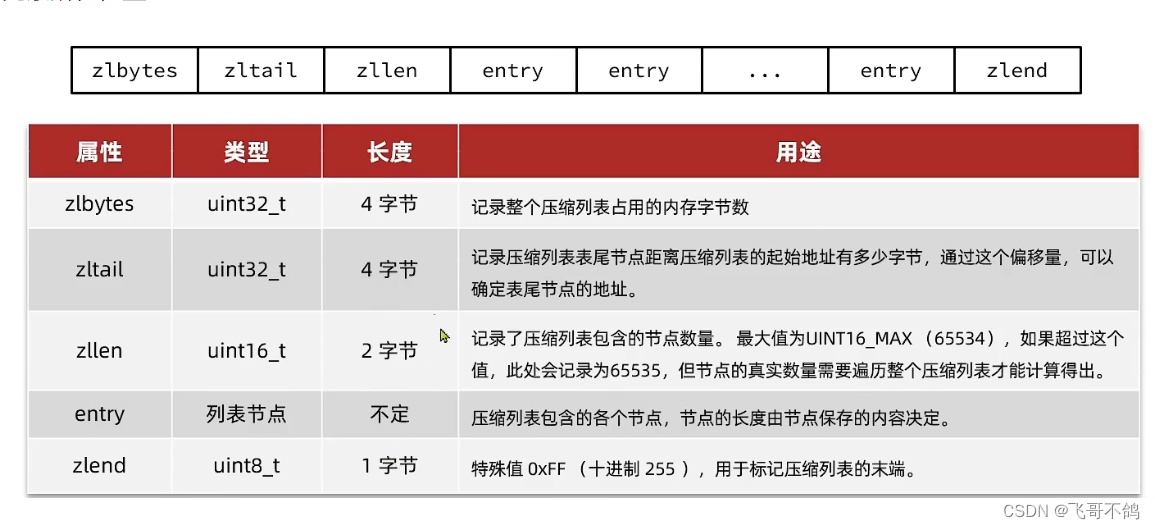
11.zipList结构底层源码
zipList:是一块特殊的双端列表。原有的使用链表方式创建的双端链表需要存储pre,next指针,需要占用大量的内存,而zipList则不用存储指针。zipList向内存申请一块连续的空间,通过对内存空间字节数划分的方式来确定每个元素所在位置
12.quickList结构
为了解决zipList存在的如下问题:
- 需要连续空间,内存占用较多
- 数据量大,超出ZipList上限
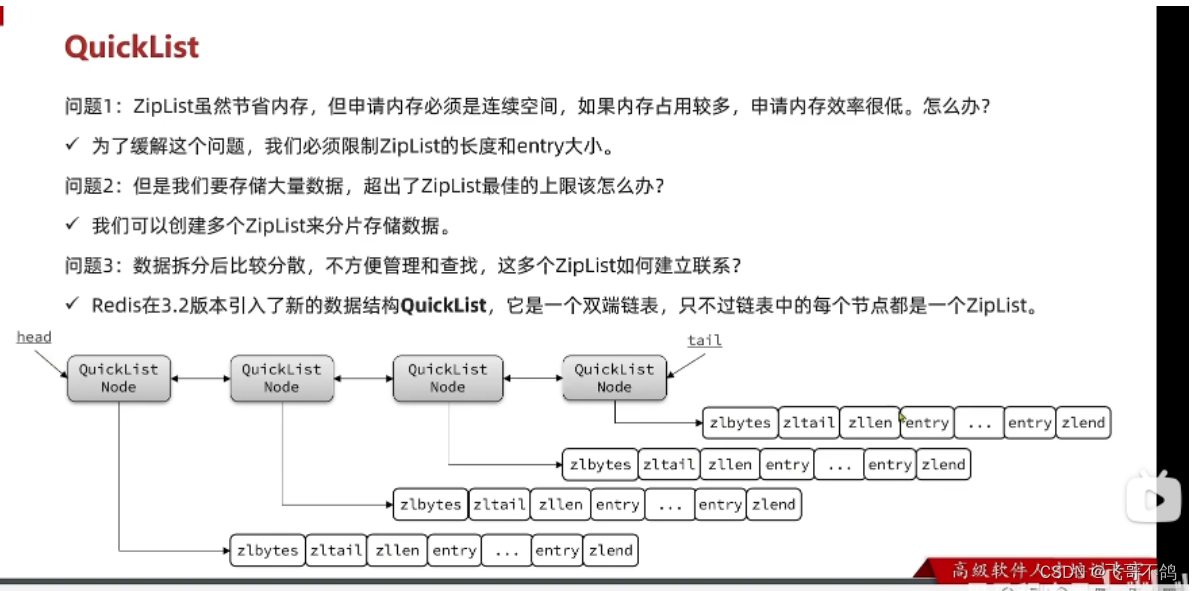
quickList,采用数据分片的一种思想。通过双向链表,将多个zipList连接到一起,通过这样的方式实现长数据存储,内存连续的问题。此外,quickList多用于链表双端的操作。因此中间的zipList可以采用算法进行数据压缩,进一步减少内存占用。
13.skipList
普通的链表,遍历时指针每次只能移动一位,时间复杂度是O(N)。如果遍历的时候,能够增加指针跳跃的跨度,就能提高遍历的速度。跳表所采取的解决方案是,向上建立索引结构。约上层的索引,指针遍历跨度越大。这其实是一种二分的思想,每次跨度跳跃当前区间范围的一半,通过这样的方式略去不可能的半个区间。以此达到提高检索效率的目的
为了尽量保持二分,每层节点个数应为下层的1/2。在添加节点的时候,由随机函数确定应该插入多少层节点。
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
14.redisObject
redis的数据类型都被封装为redisObject,
15.List结构
quickList,包装redisObject

16.Set结构
intSet / dict
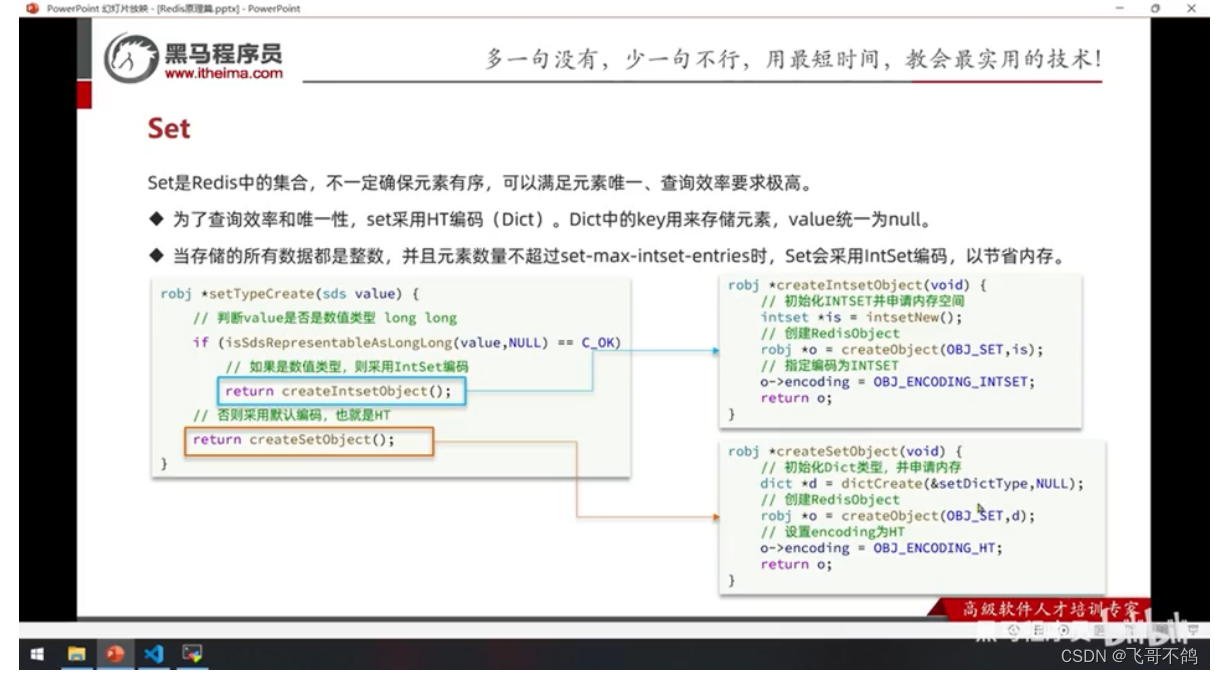
17.ZSet
按照score排序 + key唯一 + kv存储
-
skipList 【按照score排序】
-
dict 【按照key查询,且唯一】
-
quickList 【entry1 + entry2 分别存储key,value;每次添加元素时,手动排序】
18.RDB 【redis data dump】
- bgsave 后台数据备份
底层fork一个子进程,读取内存数据,将内存数据写入RDB文件。在备份数据时,会对数据开放读取权限,如果主进程需要修改内存数据,那么底层则会对进行拷贝。
19.AOP 【append only file】
- aof记录命令,将命令写入aof文件中
- 写入频率,每秒钟进行数据写入。指令命令先写入内存的aof缓冲区,每间隔一秒钟,将内存数据刷入磁盘中。
20.生产消费者模型
1. List模型
采用list存储数据,生产者从左端压入数据;消费者从右端消费数据。
缺点:只支持一对生产消费者;数据没有持久化;如果List数据为空,消费者会直接返回。如果要持续监测List集合中是否存在数据,则需要while监控。但while监控又会造成cpu大量空转,浪费性能。
2. pub / subscribe
消费者订阅队列,生产者将数据投放至队列中,实现数据实时转发。如果消费者端一直没有接收到数据,消费者则会阻塞,让出cpu。
缺点:数据是实时转发,没有做数据的持久化操作。如果消费者挂了,曾经生产的数据会全部丢失。
3. redis的Stream
stream提供订阅,发布模式
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- OPC【4】:物理包
- 【GAMES101】Lecture 09 重心坐标
- VSCode Python开发环境配置
- 计算机项目-PHP实现的乡村振兴网站-大数据技术
- 质数筛选算法(C语言实现)-----埃筛法以及欧拉筛法
- 苹果MAC电脑怎么清理缓存和垃圾清理呢?
- 不要在TypeScript中使用Function类型
- 代理IP连接不上?网速过慢?自检与应对方法来了
- 项目记录:RabbitMq+Redis配置消息队列
- Docker安装常用软件集合