多语言历史报纸广告事件抽取(ACL2023)
发布时间:2024年01月12日

1、写作动机:
首先,获取大规模的、有注释的历史数据集是困难的,因为只有领域专家才能可靠地为它们打标签。其次,大多数现成的NLP模型是在现代语言文本上训练的,这使得它们在应用于历史语料库时效果显著降低。这对于研究较少的任务以及非英语语言尤为棘手。
2、主要贡献:
?构建了一个新的多语言数据集,包括英语、法语和荷兰语的“寻求自由事件”,由奴隶主发布的广告,报道了试图通过逃离奴役寻求自由的被奴役人,基于现有的英语语言“逃奴广告”数据集的标注。
?将从历史文本中提取事件的过程框架化为抽取式问答。即使有限的标注数据,通过利用现代语言的现有资源,这种形式化也能够取得出乎意料的好结果。
?证明了对于历史语言的跨语言低资源学习是非常具有挑战性的,实际上,将历史数据集机器翻译到目标语言通常是最有效的解决方案。
3、数据集:
奴隶主发布在报纸上的广告,内容是捉拿自行解放的奴隶。三种语言:英语、法语、荷兰语。
4、模型:
使用RoBERTa(英语),CamemBERT(法语),RobBERT(荷兰语),XLM-RoBERTa(多语言)模型,在大型抽取性问答数据集上进行了微调。
baseline :T0++(具有强大零样本能力的编码器-解码器transformer,用于在多种语言的历史文本中进行命名实体识别标记)、OneIE(一个英语事件抽取框架)
5、实验:
5.1实验设置:
零样本、少样本、半监督、跨语言训练方式。
5.2实验结果
零样本推理:
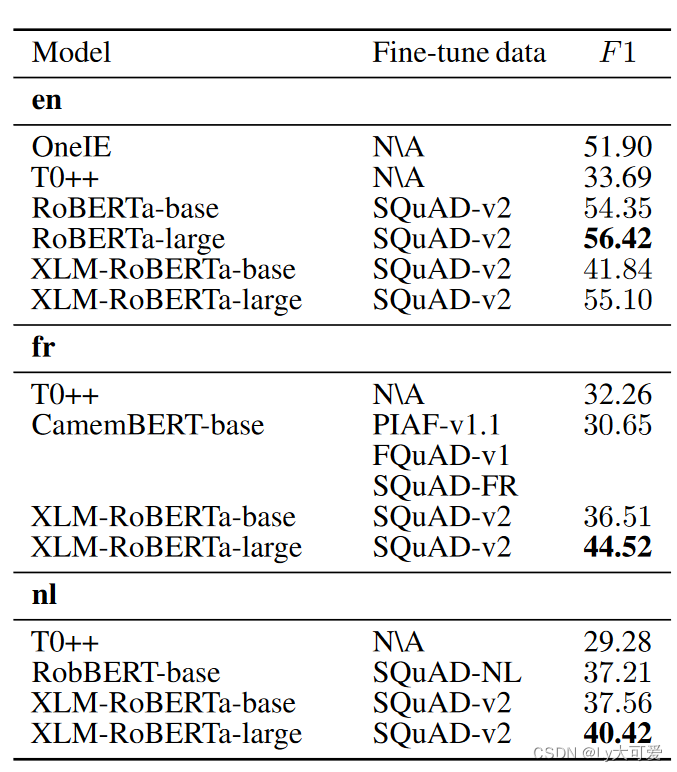
少样本推理:

半监督推理和跨语言推理:
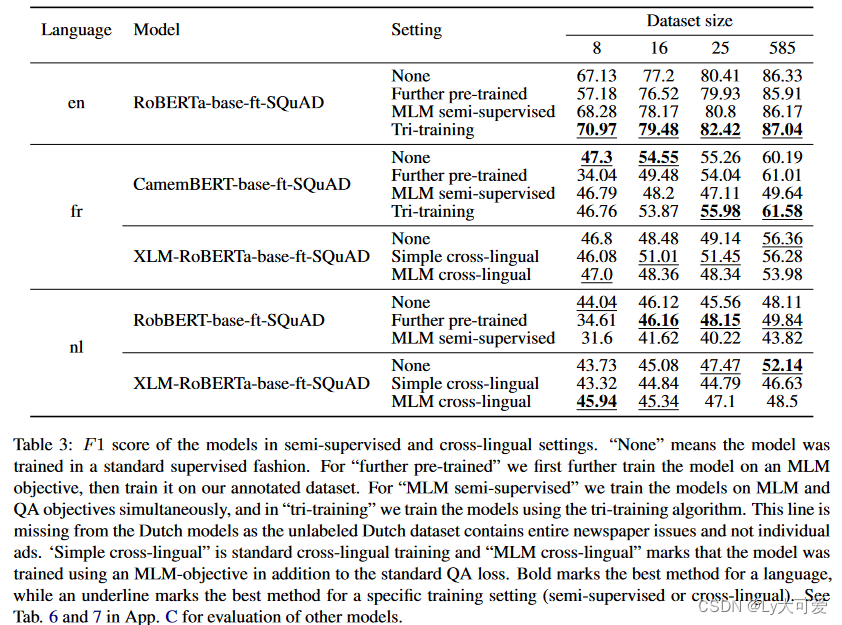
6、局限性:
一种事件类型、一个语系、依赖翻译工具、受到OCR错误影响。
文章来源:https://blog.csdn.net/weixin_45785795/article/details/135534027
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!