线上发布稳定性方案介绍

目录
一、方案说明
绝?多数的软件应??产安全事故发?在应?上下线发布阶段,尽管通过遵守业界约定俗成的可灰度、可观测和可滚回的安全?产三板斧,可以最?限度的规避发布过程中由于应??身代码问题对?户造成的影响。但对于?并发?流量情况下的短时间流量有损问题却仍然?法解决。因此,本文章将围绕发布过程中如何解决流量有损问题实现应?发布过程中的?损上下线效果相关内容展开?案介绍。
二、线上发布问题描述
2.1 无损上下线背景说明
据统计,应?的事故?多发?在应?上下线过程中,有时是应?本身代码问题导致。但有时我们也会发现尽管代码本身没有问题,但在应?上下线发布过程中仍然会出现短时间的服务调?报错,?如调?时出现 Connection refused 和 No instance 等现象。相关问题的原因有相关发布经历的同学或多或少可能有?定了解,?且?家发现该类问题?般在流量?峰时刻尤为明显,半夜流量少的时候就?较少见,于是很多?便选择半夜三更进?应?发布希望以此来规避线上发布事故。下面我们来分析下常见的流量有损现象出现的原因。
2.1.1 服务?法及时下线
服务消费者感知注册中?服务列表存在延时,导致应?特定实例下线后在?段时间内服务消费者仍然调?已下线实例造成请求报错。
2.1.2 初始化慢
应?刚启动接收线上流量进?资源初始化加载,由于流量太?,初始化过程慢,出现?量请求响应超时、阻塞、资源耗尽从?造成刚启动应?宕机。
2.1.3 注册太早
服务存在异步资源加载问题,当服务还未初始化完全就被注册到注册中?,导致调?时资源未加载完毕出现请求响应慢、调?超时报错等现象。
2.1.4 发布态与运?态未对?
使用kubernetes的滚动发布功能进行应用的发布,由于kubernetes滚动发布?般关联的就绪检查机制,是通过检查应?特定端?是否启动作为应?就绪的标志来触发下?批次的实例发布,但在微服务应?中只有当应?完成了服务注册才可对外提供服务调?。因此某些情况下会出现新应?还未注册到注册中?,?应?实例就被下线,导致?服务可?。
三、问题解决方案
3.1 无损下线方案
3.1.1 什么是无损下线
由于微服务应用自身调用特点,在高并发下,服务提供端应用实例的直接下线,会导致服务消费端应用实例无法实时感知下游实例的实时状态因而出现继续将请求转发到已下线的实例从而出现请求报错,流量有损。
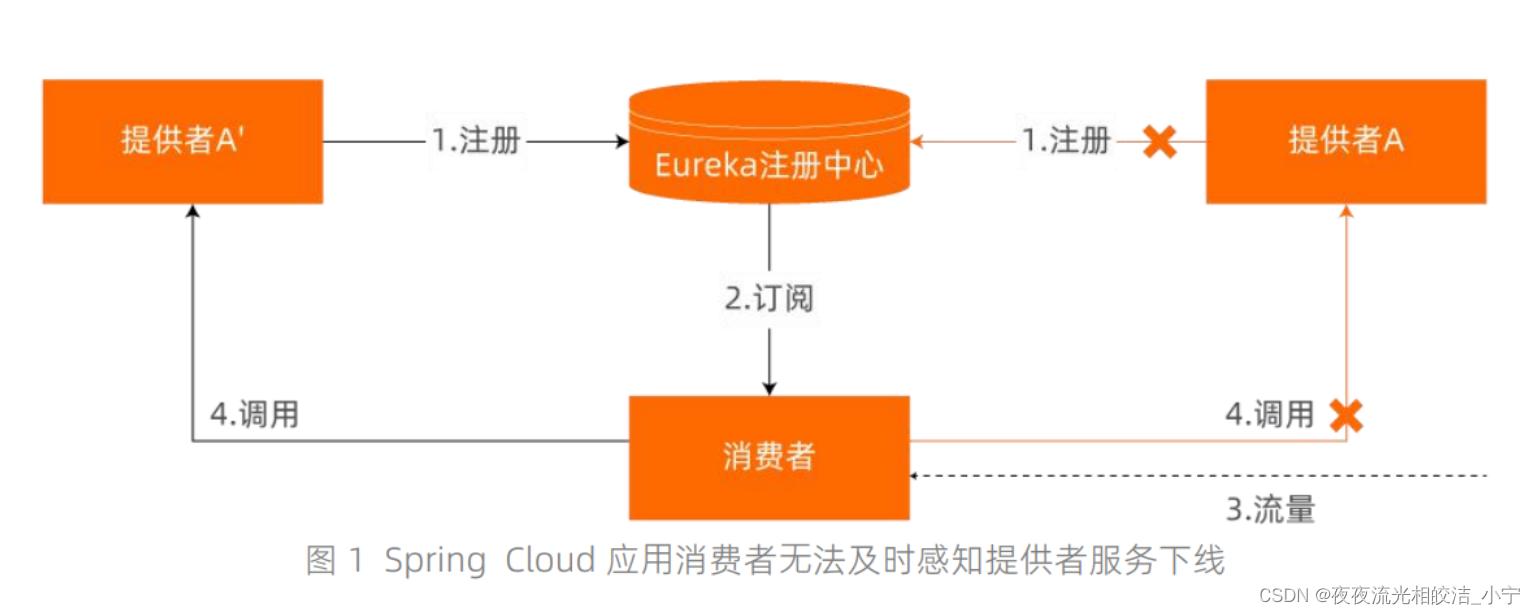
例如对于 Spring Cloud 应?如上图 1 所示,当应?的两个实例 A’和 A 中的 A 下线时,由于Spring Cloud 框架为了在可?性和性能??做平衡,消费者默认是 30s 去注册中?拉取最新的服务列表,因此 A 实例的下线不能被实时感知,流量较?时,消费者会继续通过本地缓存调?已下线的 A 实例导致出现流量有损。基于上述背景,业界提出了相应的?损下线(也叫优雅下线)的技术?案来应对上述问题。
3.1.2 传统解决方式
针对该类问题,业界一般的解决方式是通过将应用更新流程划分为手工摘流量、停应用、更新重启三个步骤。由人工操作实现客户端避免调用已下线实例,这种方式简单而有效,但是限制较多:不仅需要借助流控能力来实现实时摘流量,还需要在停应用前人工判断来保证在途请求已经处理完毕。这种需要人工介入的方式运维复杂度较高,只适用于规模较小的应用,无法解决当前云原生架构下,自动化的弹性伸缩、滚动升级等场景中的实例下线过程中的流量有损问题。
3.1.3 云原生场景解决方案
3.1.3.1 主动通知
一般注册中心都提供了主动注销接口供微服务应用正常关闭时调用,以便下线实例能及时更新其在注册中心上的状态。主动注销在部分基于事件感知注册中心服务列表的微服务框架比如Dubbo 中能及时让上游服务消费者感知到提供者下线避免后续调用已下线实例。但对于像Spring Cloud这类微服务框架服务消费者感知注册中心实例变化是通过定时拉取服务列表的方式实现。尽管下线实例通过注册中心主动注销接口更新了其自身在注册中心上的应用状态信息但由于上游消费者需要在下一次拉取注册中心应用列表时才能感知到,因此会出现消费者感知注册中心实例变化存在延时。在流量较大、并发较高的场景中,当实例下线后,仍无法实现流量无损。既然无法通过注册中心让存量消费者实例实时感知下游服务提供者的变化情况,业界提出了利用主动通知解决该类问题。主动通知过程如下图 2 所示。
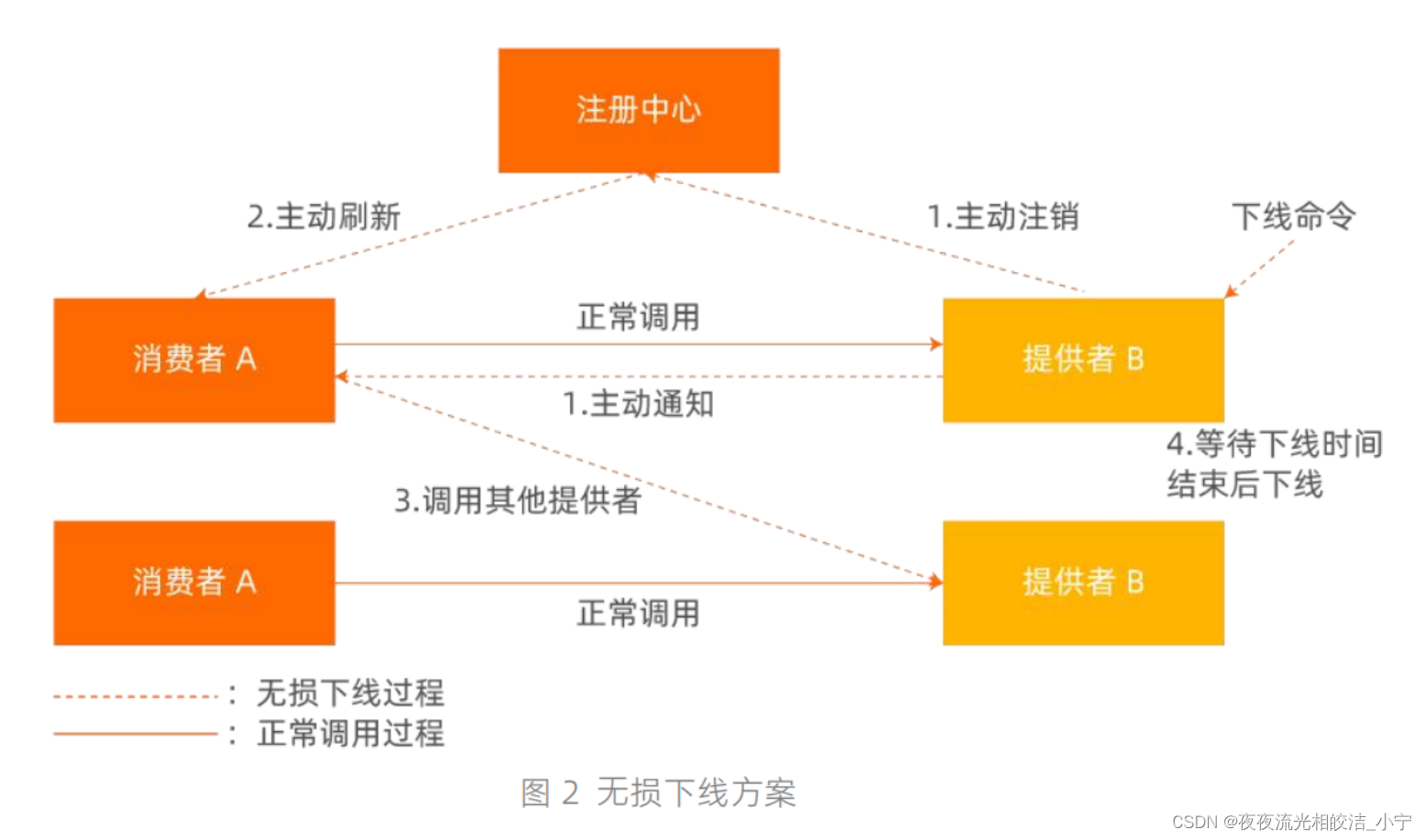
如图 2 所示,服务提供者 B 中某个实例在下线时为避免主动在注册中心中注销的服务实例状态无法实时被上游消费者 A 感知到,从而导致调用已下线实例的问题。在接收到下线命令即将下线前,提供者 B 对于在等待下线阶段内收到的请求,在其返回值中都增加上特殊标记让服务消费者接收到返回值并识别到相关标志后主动拉取一次注册中心服务实例从而实时感知 B 实例最Microservice 新状态,从而达到服务提供者的下线状态能够被服务消费者实时感知。
3.1.3.2 自适应等待
在并发度不?的场景下,主动通知?法可以解决绝?部分应?下线流量有损问题。但对于?并发?流量应?下线场景,如果主动通知完,可能仍然存在?些在途请求需要待下线应?处理完才能下线否则这些流量就?法正常被响应。为解决该类在途请求问题,可通过给待下线应?在下线前通过?适应等待机制在处理完所有在途请求后,再下线以实现流量?损。
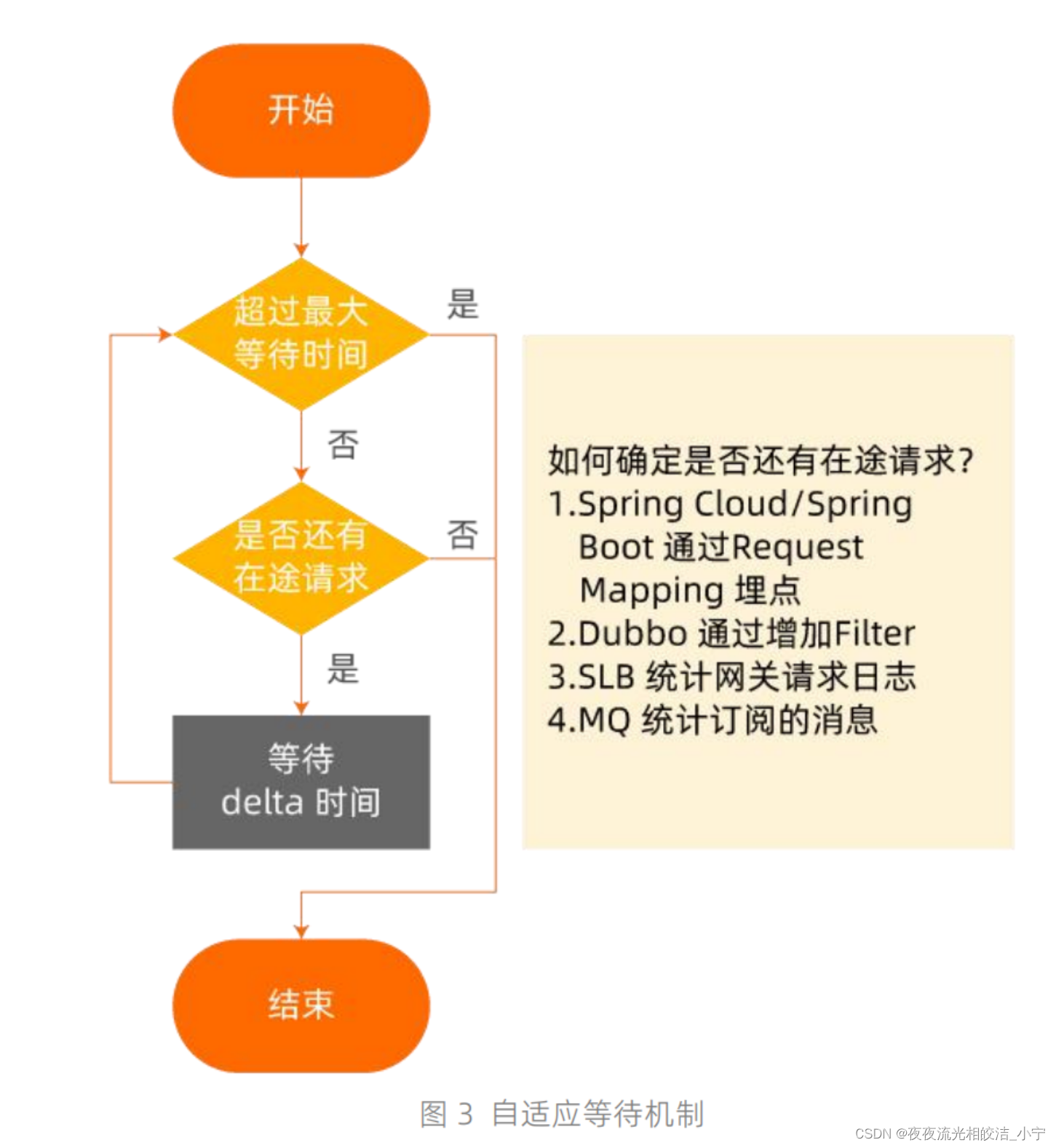
如上图 3 所示,?适应等待机制是通过待下线应?统计应?中是否仍然存在未处理完的在途请求,来决定应?下线的时机,从?让待下线应?在下线前处理完所有剩余请求。
3.2 无损上线方案
3.2.1 无损上线场景
延迟加载是软件框架设计过程中最常?的?种策略,例如在 Spring Cloud 框架中 Ribbon 组件的拉取服务列表初始化默认都是要等到服务的第?次调?时刻,例如下图 4 是Spring Cloud 第一次和第二次通过调用RestTemplate 调用远程服务消耗的时间对比:

由图 4 结果可?,第?次调?由于进?了?些资源初始化,耗时是正常情况的数倍之多。因此把新应?发布到线上直接处理?流量极易出现?量请求响应慢,资源阻塞,应?实例宕机的现象。
业界针对上述应??损上线场景,提出了包括延迟注册、?流量服务预热以及就绪检查等?系列解决?案,详细完整的?案如下图 5 所示:

3.2.2 延迟注册
对于初始化过程需要异步加载资源的复杂应?启动过程,由于注册通常与应?初始化过程同步Microservice 进?,从?出现应?还未完全初始化就已经被注册到注册中?供外部消费者调?,此时直接调?由于资源未加载完成可能会导致请求报错。通过设置延迟注册,可让应?在充分初始化后再注册到注册中?对外提供服务。例如开源微服务治理框架 Dubbo 原?就提供延迟注册功能。
3.2.3 小流量服务预热
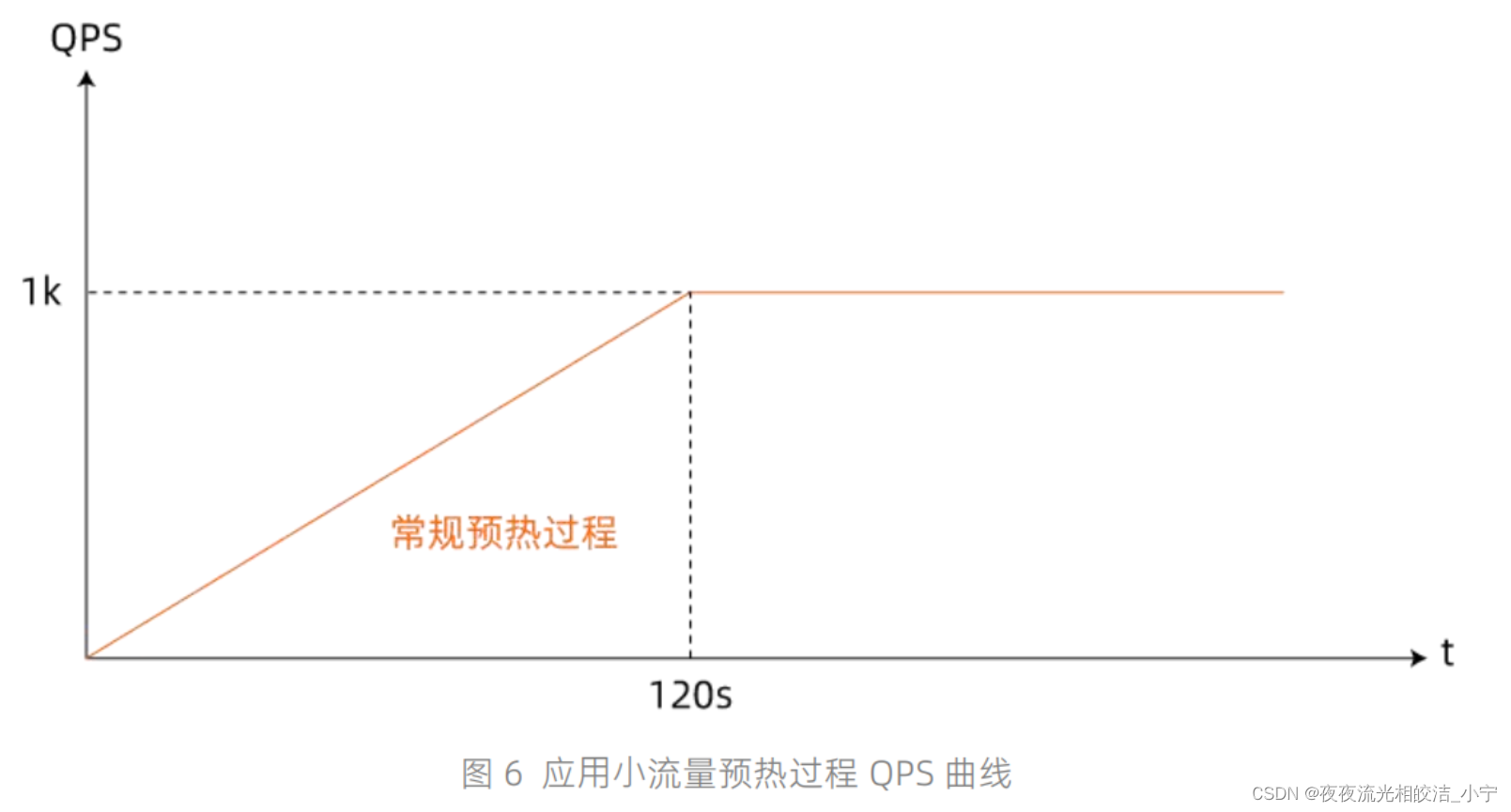
在线上发布场景下,很多时候刚启动的冷系统直接处理?量请求,可能由于系统内部资源初始化不彻底从?出现?量请求超时、阻塞、报错甚?导致刚发布应?宕机等线上发布事故出现。为了避免该类问题业界针对不同框架类型以及应??身特点设计了不同的应对举措,?如针对类加载慢问题有编写脚本促使 JVM 进?预热、阿?巴巴集团内部 HSF(High Speed Framework)使?的对接?分批发布、延迟注册、通过 mock 脚本对应?进?模拟请求预热以及?流量预热等。本节将对其中适?范围最?的?流量预热?法进?介绍。相?于?般场景下,刚发布微服务应?实例跟其他正常实例?样?起平摊线上总 QPS。?流量预热?法通过在服务消费端根据各个服务提供者实例的启动时间计算权重,结合负载均衡算法控制刚启动应?流量随启动时间逐渐递增到正常?平的这样?个过程帮助刚启动运?进?预热,详细 QPS 随时间变化曲线如图 6 所示
开源 Dubbo所实现的?流量服务预热过程原理如下图 7 所示:

服务提供端在向注册中?注册服务的过程中,将?身的预热时? WarmupTime、服务启动时间StartTime 通过元数据的形式注册到注册中?中,服务消费端在注册中?订阅相关服务实例列表,调?过程中根据WarmupTime、StartTime 计算个实例所分批的调?权重。刚启动StartTime 距离调?时刻差值较?的实例权重下,从?实现对刚启动应?分配更少流量实现对其进??流量预热。
开源 Dubbo?所实现的?流量服务预热模型计算如下公式所示:
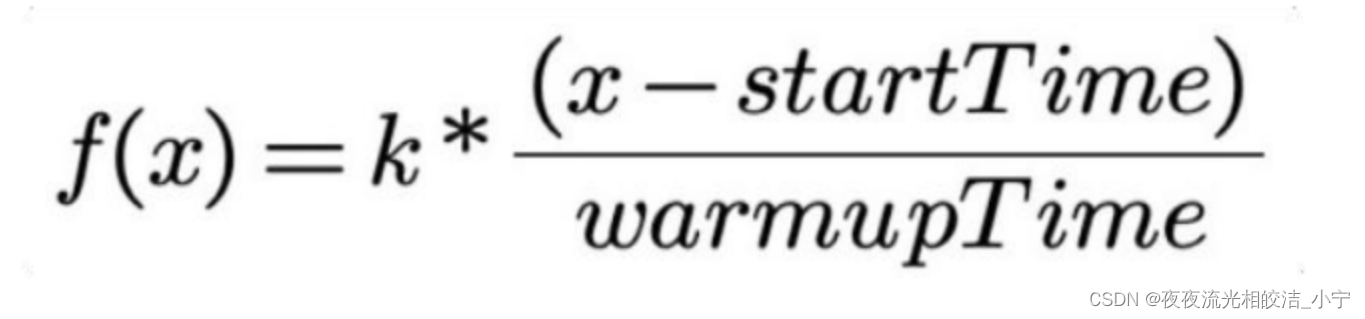
模型中应用 QPS 对应的 f(x) 随调用时刻 x 线性变化,x 表示调用时刻的时间,startTime 是应用开始时间,warmupTime 是用户配置的应用预热时长,k 是常数,一般表示各实例的默认权重。

通过?流量预热?法,可以有效解决,?并发?流量下,资源初始化慢所导致的?量请求响应慢、请求阻塞,资源耗尽导致的刚启动应?宕机事故。
3.2.4 微服务就绪检查
当前容器+Kubernetes的应用运维部署方案已经成为业界的事实标准,特别是针对微服务应用来说,该运维部署方案更是带来了极大的便利,所以在介绍微服务就绪检查之前,有必要针对Kubernetes探针技术做个介绍,方便后续内容的理解。
3.2.4.1 Kubernetes 探针技术
在云原?领域,Kubernetes 为了确保应? Pod 在对外提供服务之前应?已经完全启动就绪或者应?Pod?时间运?期间出现意外后能及时恢复,提供了探针技术来动态检测应?的运?情况,为保证应?的?损上线和?时间健康运?提供了保障。
3.2.4.1.1 存活探针
Kubernetes 中提供的存活探测器来探测什么时候进?容器重启。例如,存活探测器可以捕捉到死锁(应?程序在运?,但是?法继续执?后?的步骤)。在这样的情况下重启容器有助于让应?程序在有问题的情况下更可?。
3.2.4.1.2 就绪探针
Kubernetes 中提供的就绪探测器可以知道容器什么时候准备好了并可以开始接受请求流量,当 ?个 Pod 内的所有容器都准备好了,才能把这个 Pod 看作就绪了。这种信号的?个?途就是控制哪个 Pod 作为 Service 的后端。在 Pod 还没有准备好的时候,会从 Service 的负载均衡器中被剔除的。
3.2.4.1.3 启动探针
Kubernetes 中提供的启动探测器可以知道应?程序容器什么时候启动了。 如果配置了这类探测器,就可以控制容器在启动成功后再进?存活性和就绪检查,确保这些存活、就绪探测器不会影响应?程序的启动。 这可以?于对慢启动容器进?存活性检测,避免它们在启动运?之前就被杀掉。
3.2.4.1.4 探针使用小结
- 当需要在容器已经启动后再执?存活探针或者就绪探针检查,则可通过设定启动探针实现。
- 当容器应?在遇到异常或不健康的情况下会??崩溃,则不?定需要存活探针,Kubernetes能根据 Pod 的 restartPolicy 策略?动执?预设的操作。
- 当容器在探测失败时被 Kill 并重新启动,则可通过指定?个存活探针,并指定 restartPolicy?为 Always 或 OnFailure。
- 当希望容器仅在探测成功时 Pod 才开始接收外部请求流量,则可使?就绪探针
Kubernetes探针技术使用实例官网:
3.2.4.2 Kubernetes 探针检测技术的不足
当前容器+Kubernetes 的应?运维部署?式已经成为了业界的事实标准,相关技术为微服务应?运维部署带来巨?便利的同时,在某些特殊的应?部署场景中也有?些问题需要解决。?如,使?Kubernetes 的滚动发布功能进?应?发布,由于 Kubernetes 的滚动发布?般关联的就绪检查机制,是通过检查应?特定端?是否启动作为应?就绪的标志来触发下?批次的实例发布,但在微服务应?中只有当应?完成了服务注册才可对外提供服务调?。因此某些情况下会出现新应?还未注册到注册中?,?应?实例就被设置下线,导致?服务可?。
3.2.4.3 业界较好的微服务就绪检查方案
针对这样?类微服务应?的发布态与应?运?态?法对?的问题导致的应?上线事故,当前业界也已经有相关解决?案进?应对。?如阿?云微服务引擎 MSE 就通过就绪检查关联服务注册的?法,通过字节码技术植?应?服务注册逻辑前后,然后在应?中开启?个探测应?服务是否完成注册的端?供 Kubernetes 的就绪探针进?应?就绪态探测进?绑定?户的发布态与运?态实现微服务的就绪检查,避免出现相关状态不?致导致的应?发布上线流量有损问题。
好了,本次分享就到这里,如果帮助到大家,欢迎大家点赞+关注+收藏,有疑问也欢迎大家评论留言!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Python中的文件读取方法:read、readline和readlines
- YOLOv5-第Y2周:训练自己的数据集
- QT+OSG/osgEarth编译之七十六:glsl+Qt编译(一套代码、一套框架,跨平台编译,版本:OSG-3.6.5插件库osgdb_glsl)
- 技术帖 | 飞凌嵌入式T113-i开发板的休眠及唤醒操作
- 第九部分 使用函数 (三)
- gateway网关
- Codeforces Global Round9 (VP)(寒假ACM模拟赛1)
- Kali虚拟机下su(进入root状态)的两个错误
- 力扣labuladong——一刷day80
- 蓝牙免提协议(HFP)