51-8 GPT,GPT2,GPT3 论文精读
?2020年的时候有一篇博客冲到了Hack News的第一名。Hack News是在技术圈里面应该是影响力最大的一个新闻汇聚网站,所有人都可以分享自己喜欢的文章,然后观众对这些文章进行点赞或者是评论。Hack News根据你点赞的个数和评论来进行排名,这篇文章能排到第一位,意味着大家还是挺喜欢的。然后来看一下标题Feeling unproductive? Maybe you should stop overthinking。标题是说你是不是感觉工作没有状态,也许你就是应该停止想太多,这是一个非常鸡汤的标题,在微信公众号上你可能会看到许多类似的文章。然后我们点进去这篇文章看一下,他写的还是挺正常的,对吧?

有一个图,这个配图也是正确的,然后里面有些文字我就不给大家一一讲了,段落有长有短,看上去也像回事。然后这件事情,又上了另外一个头条,这一次上了头条是在MIT的技术评论里面,这是一个老牌的技术评论杂志。他的标题教授说一个大学生做了一个假的,然后由AI生成的博客,然后糊弄了上万人。事实上我们刚刚看到的那篇文章是一个叫做nothing but words的博客里面的一篇文章。这博客里面其实还有挺逗逼的文章,看上去像模像样,但是整个博客是由模型生成的,这个模型叫做GPT3。他文章的第一段话是想说在某个星期的早一点时候,有一个小哥听到了这个模型,然后,他就在这个信息里面用这个模型生成的这样一个博客,非常的简单。
在过去几年里面,整个自然语言处理界可能最出圈的模型应该就是GPT3了。
这个模型来自于OpenAI的团队。在这个模型放出来之后,整个网络上就把这个模型玩出了花了,如果你去搜GPT3的应用的话,你可以搜出上百个。当然这个地方只是列了一些应用OpenAI,它推出了一个基于GPT3的一个API,使得你能调用这个模型开发你任何想用的应用。这里有一个网站叫做GPT3 DEMOS。它这个地方列举了,目前来说,我们知道所有基于GPT3的做的一些应用,可以看到这里面大概有几百个的样子,各个地方都有,我们来看一下都有哪一些比较流行的类别。比如说这个地方用AI来辅助你的写作,然后这个是一个聊天机。必然,然后下面还有一些开发工具,然后所有东西加起来大概有好几百的样子。
最近的一个基于GPT3的应用大家可能也听说过,这就是GitHub Copilot,它的意思是说你可以通过注释来说我要写一个函数干什么事情,然后把函数签名给定之后,剩下的函数的主体就怎么实现,它可以用代码来自动生成。这个工作引起了巨大的反响,在之后有数个工作对它进行了研究,这就是对GPT3的目前的一些应用的一个非常快速的一个预览。
我们今天的任务就是来讲GPT3这篇论文,如果我们要讲GPT3这篇文章,我们就不得不提到它前面的两个工作,GPT1和GPT2。在这个地方,我们把这三篇文章和我们之前讲过的Transformer和BERT这两篇文章分别列在这个地方。
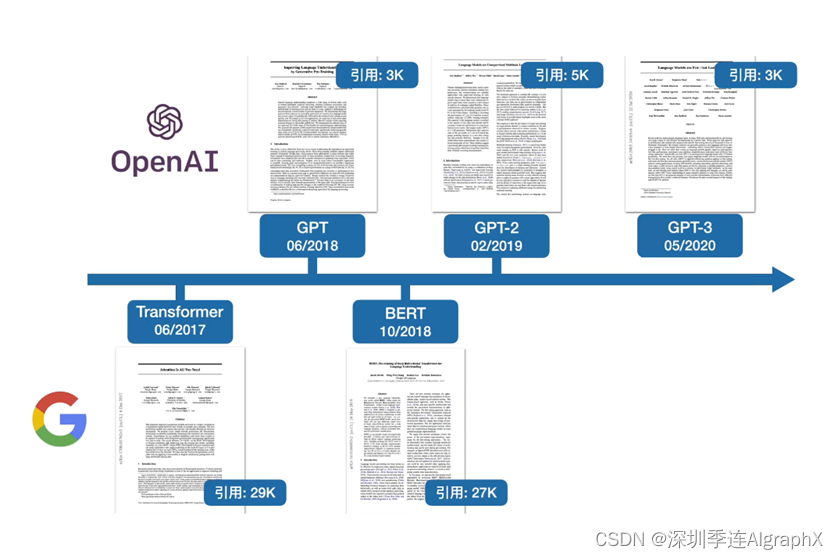
横着这条线表示的是时间轴,我们可以看到,Transformer首先发表在2017年6月,在一年之后GPT出来了。我们之前有讲过G的核心技术,把Transformer的解码器给你拿出来,然后在没有标号的大量的文本数据上训练一个语言模型来获得一个预训练模型,然后再用它在子任务上做微调,得到每一个任务所要的分类器,这跟我们之前的计算机视觉用的技术很一样了。然后在四个月之后,BERT出来了,我们之前有提过,据小道消息是BERT的一作是在一两个月之内把这篇文章做出来的,很有可能是他在看到了GPT这篇文章之后才有的Idea。思想是说我跟GPT不一样,我是把的编码器拿过来,然后我收集了一个更大的数据集用来做预训练,结果效果比GPT好很多。我们回忆一下,BERT里面一共有两个模型,一个叫BERT Base,一个叫BERT Large。Base选择就是跟GBT的模型大小是一样的,当然Large是比Base要大一些,结果上来说,Base应该是要比GPT要好。然后在四个月之后,GPT2出现了,GPT2,又是原作者,这帮人吸取了前面的教训,哪里跌倒就在哪里爬起来。他们收集了一个更大的数据集,训练了一个更大的模型,GPT2的模型比BERT Large是要大的。如果你就简简单单的训练了一个大的模型,那你在置信度上肯定是有问题的。所以他就沿着了自己的技术路线,继续使用Transformer的解码器来深入挖掘语言模型的潜力。然后他发现这个非常适合做zero shot。因为你走的比较远,导致效果上没有那么的惊艳。于是在一年又三个月之后,也就是2020年的5月份,他们推出了GPT3。对GPT2的改进就是数据和模型都大了100倍,暴力出了奇迹.终于把效果做到非常惊艳,也就是我们之前看的这些应用的效果非常的炸裂,也就是GPT3的效果。这一期视频的封面就是暴力出奇迹。我们这里画了两个logo。一个是OpenAI,一个是Google,因为Transformer都来自于Google的团队,然后GPT系列三篇文章都来自于OpenAI这个团队。有意思的是,OpenAI团队虽然投入了很多做了GPT,但是他在学术界的影响力似乎是不如BERT的。这里我们列举到目前为止他们的引用,BERT这篇文章的引用是27000,如果你把GPT、GPT2、GPT3 3篇文章的引用加起来,大概是11000的样子,还不到BERT的1/2。GBT系列它的引用率稍低,它倒不是因为r它的创新度,或者是它的效果不如BERT系列。恰恰相反,我觉得是因为OpenAI选择去解决个更大的问题,所以它的技术上实现更难一些,它出效果更难一些。比如说你要出到很炸裂的效果,你得做到GPT3,它这个规模几乎是没有别的团队能够现他们结果的。选择这样子的技术问题去解决,是因为他整个公司,他还是想做强人工智能,他想去解决一个更大的问题,所以他们必须在选择问题上选择大一点。反过来讲,Transformer和系列都是来自于独立的一些研究组,他们一开始想解决的问题其实都比较小。Transformer我们之前提过,他其实就想解决机器翻译这样子的例子,从一个序列翻译到另外一个序列,它的上面的效果。BERT,其实也是挺实在的,他就是想把计算机视觉那个成熟的先训练一个预训练模型,然后再做微调出子任务的结果这一套搬过来在NLP上做好,因为他们就是想实实在在提升技术的效果。所以,在同样模型大小,比如说是一个亿级别模型大小时,BERT的性能是要好于GPT的,也就是未来的工作更多愿意引用。因为我咬咬牙,还是能找到足够的机器能把我的模型跑起来,而且效果不错,不然你如果要跟GPT系列的话,可能把你卖了,你还是跑不起那个实验。
好,接下来我们就按顺序,从GPT GPT2 GPT 3逐一读一下每一篇文章,先看GPT文章。
GPT
Improving Language Understanding by Generative Pre-Training,标题叫做使用通用的预训练来提升语言的理解能力。GPT跟我们之前说的很多文章一样,它并没有给自己的方法起标题,所以GPT的名字来自于后面人给它的GPT,这三个字母组合在一起。如果大家对自己的硬盘做过格式化分区的话,你可能也听说过GPT,所以幸好这个工作有一定的知名度,而且OpenAI的作者在之后持续对它改进,有GPT2 GPT3,不然的话,你现在去搜GPT的话,可能就搜不到这篇文章,而是搜到的是硬盘如何分区了。他的作者这里有四个人,一作是Alec Radford,这个人在GPT工作之前还有挺多有名的工作,比如说这是他Google scholar的界面,可以看到他其实已用最高的文章是DCGAN,这篇文章就是用卷积神经网络来替换掉GAN里面的那个MLP。另外一个是PPO,这也是强化学习里面一个很常见的优化算法。还有是他又做了GAN一个的工作,然后后面的三个工作就是GPT这三部曲。最后一名作者Ilya Sutskever伊利亚,相信大家还是记得吧,AlexNet论文的2作,然后他去了OpenAI当任CTO,所以很多工作应该是挂了他的名字,作为最后一个作者。
Abstract
接下来我们来看一下摘要,摘要写的比较简单,我们先来看一下前面两句话讲的是我要解决什么问题。他说在自然语言理解里面,有很多不一样的任务,虽然我们有很多大量的没有标好的文本文件,但是,标好的数据是相对来说比较少的,这使得我们要去在这些标好的数据上训练出分辨模型的话会比较的难,因为我们的数据相对来说还是太小了。接下来就讲怎么解决这个问题,它的解决方法是说,我们先在没有标号的数据上面训练一个预训练模型,这个预训模型是一个语言模型,接下来,再在有标号的这些子任务上面训练一个的微调模型。这个在计算机视觉里面早在八九年前已经是成为主流的算法,但是在NLP领域一直没有流行起来,是因为在NLP里面没有像 ImageNet那么大规模标好的那种数据。在计算机视觉里面,我们有标好的100万张图片的ImageNet,在NLP的话并没有那么大数据集。虽然说机器翻译那一块我们也许能做到100万的量级,但是你一个句子和一个图片不在一个尺度上面,一张图片里面含有的信息,那个像素的信息比一个句子里面能去抽取的信息来的多很多,所以一张图片可能能换十个句子的样子,那么意味着是说你至少有1000万级别的句子级别的必要的数据集才能够训练比较大的模型,这导致在相当一段时间里面,深度学习在NLP的进展没有那么的顺利。直到GPT和后面的BERT的出现才打开了局面。
注意,这里我们还是像计算机视觉那样,先训练好预训练模型再来做微调。但是这个不一样的是说我们使用了是没有标号的文本,这个就往前走了一大步,然后在GPT系列后面的文章在做,又走了另外一大步。
如果说深度学习前面五年主要是计算机视觉在引领整个潮流的话,那么最近几年可以看到这些创新很多来自于自然语言处理界,而且这些创新也在反馈回计算机视觉里面。比如说之前我们读过的MAE这篇文章,就是把BERT用回到计算机视觉上面。我们在上集介绍了CLIP也是打通了文本和图像。当然在GPT里用没有标号的文本,那也不是第一次了,比如说十几年前就很火的world to vector这个词嵌入模型就是用的大量的没有标号的文本。但是他在这里说我们跟之前工作了一个区别,是说他们是在微调的时候构造跟你任务相关的输入,从而使得我们只要很少的改变我们模型的架构就行了。这是因为文本跟图片不一样,它的任务更加多样性一些。有些任务说我要对词进行判断,有些任务需要对句子进行判断,有些任务是说我需要一对句子或者三个句子,还有些应用是说我要生成一个句子,所以导致每个任务都需要有自己的模型。最早是做一个词上面的一个学习,然后你的后面的模型还得去构造,之前的一些工作需要把你的模型进行一些改变来适应各个任务。但是这个地方我们只要改变输入的形式就行了,而不需要改变我的模型。当然我们读过BERT的话,我们知道这个是怎么做的,但是GPT是在BERT之前,所以他提出来的时候,在当时来说当然是有新意的。最后实验,实验结果可以看到是说他在12个任务里面有九个任务能够超过当前最好的成绩,所以看上去是稍微弱于BERT之后的结果,他在十几个任务上都超越了前面,所以导致是说BERT为什么出来之后比GPT更加有影响力,因为它效果更加好一点,但是从创新度来讲,我觉得GPT该在BERT之上。因为它就是前面的工作,BERT在很多时候跟他的思路是一样的。
Introduction
接下来我们来看一下导言,导言的第一句话讲的是我们之前提到的那个问题,就是怎么样更好的利用无监督的文本,作者提到在当时候,最成功的模型还是词嵌入模型。
然后接下来第二段话是讲用没有标号文本的时候,使用它遇到的一些困难。它主要讲了两个困难,第一个困难是说你不知道用什么样的优化目标函数,就是我给你一堆文本,你到底你的损失函数长什么样子?当时会有很多选择,比如说你用语言模型啦,你有机器翻译啦,或者是文本的一致性,但是问题是没有发现某一个特别的好,就是一个目标函数在一些任务上比较好,另外一个目标函数在另外一些问题上也比较好,就是说看你的目标函数跟你实际要做的子任务它的相关度有多高了。第二个难点是说怎么样有效的把你学到的这些文本表示传递到你下游的子任务上面,这也是因为NLP里面的子任务,差别还比较大的。没有一个简单的统一的有效的方式,使得一种表示能够一致的到所有的子上面。
好接下来第三段就是说GPT这文章,他提出了一个半监督的方法,然后在没有的文本上面训练一个比较大的语言模型,然后再在子任务上进行微调。当然我们现在对这一套比较熟悉,但是有意思的说,你回到当年作者用的是半监督学习这个词,semi-supervised半监督学习,在基于学习一些,可能在十年前是非常的火的,它的核心思想是说我有一些标号的数据,但我还有大量的相似的但没有标好的数据,我怎么样把这些没有标号的数据用过来,那就是半监督学习想学的东西。这个地方,当然是可以放到半监督学习里面,就是说你在没有标号的模型上面训练好一个模型之后,然后再有监上面做微调。但是,半监督学里面还有很多的算法。现在我们把GPT这一套方法和BERT以后的工作的类似的方法,不叫做半监督学习,而叫自监督学习,叫做self- supervised learning,这也是上一期的clip那篇文章作者又说到同一个方法,但是在不同的论文的作者把它归类成不一样的算法。
下一段讲的是他用到的模型,可以看到它主要是有两点,第一点是说他的模型是基于Transformer这个架构了。因为这篇文章发表在Transformer这篇文章出来一年之后,当然作者在做这个工作的时候应该可能更早,可能是Transformer出来就几个月,所以在试用Transformer还是用RNN这种模型的时候,在当时候不是那么显而易见了。所以作者解释了一下大概的原因,他说跟RNN这种模型相比,他发现Transformer他在迁移学习的时候,他学到的那些feature更加的稳健一些。作者觉得原因可能是因为Transformer里面有更结构化的记忆,使得能够处理更长的这些文本信息,从而能够抽取出更好的句子层面和段落层面的这些语音信息了。第二个技术要点是说他在做迁移的时候,用的是一个任务相关的输入的一个表示,我们在之后会看到他到底长什么样子。
最后一段只讲实验结果,我们就不在这里给大家看了。
Related Work
下面是相关工作,相关工作我们就不给大家仔细讲了,他就讲了一下在NLP里面半监督是怎么回事,然后讲的是无监督模型,还有是说我在训练的时候需要使用多个目标函数的时候会怎么样,这分别对应的是你的大的GPT模型怎么样在没有标号的数据上训练出来,以及说你怎么样在子任务上用有标号的数进行微调,最后的时候你在做微调的时候,它使用了两个训练的目标函数。
Framework
第三章讲这个模型的本身,我们来看一下这一节里面有三个小节,分别对应的是我怎么在没有标号的数据上训练模型,怎么样做微调,以及说我怎么样对每个子任务表示我的输入。
Unsupervised pre-training
我们先来看3.1,就是在没有标号的数据上面做训练。
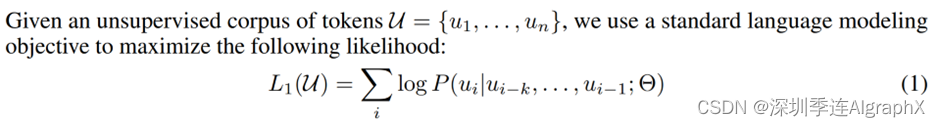
假设我们有一个文本,没有标号的文本里面每个词表示成一个Ui,那么它整个文本就表示成U。知道Ui它是有个序列信息的,不会换顺序。GPT使用一个标准的语言模型的目标函数,似然函数。我们来看一下是这么回事,具体来说,语言模型就是要预测第i个词出现的概率,那么第i个词记为Ui,它怎么预测?它是把Ui的前面的K个词,就是Ui-1,一直到Ui-k。K这个地方是你的窗口大小,或者叫做上下文窗口,也就是说每一次我们拿K个连续的词,然后再预测这K个词后面那一个词是谁。具体来说,它的预测是用一个模型,这个模型记作Θ。在这个地方给定理K个词,给定模型,那么预测这K下一个词它的概率。把每一个这样子的词,就是I,它的位置从零一直到最后把全部加起来就得到我们的目标函数,这个地方记为L1。它不是你的那个范式里面的L1,它就是第一个目标函数,因为它后面还有一个别的目标函数。它为什么是加?是因为去log的缘故。如果你做指数放回去的话,那就是所有这些词出现的概率相乘,也就是这个文本出现的联合概率。就是说我要训练一个模型,使得它能够最大概率的输出跟我的文本长的一样的一些文章。这个地方Θ模型是你的参数,K是你的超参数,就是你的窗口的大小。从神经网络角度而言,那你K就是你输入序列的长度,你的序列越长的话,你的网络看到的东西就越多,就是它越会倾向于在一个比较长的文本里面去找里面的关系,你可越短的话,当然你的模型相对来说比较简单,只要看比较短的就行了,所以这个地方如果你想让你的模型很强的话,那么K可能要取到几十、几百或者甚至上千。
他在下面又解释了一下,具体这个模型是谁,它用到的模型是Transformer的解码器,我们回忆一下Transformer有两个东西,一个是编码器,一个是解码器,他们最大的不一样在于是说编码器拿一个序列进来,他对第二个元素抽特征的时候,他能够看到整个序列里面所有的元素。但是对解码器来讲,因为有掩码的存在,所以他在对第i个元素特征的时候,他只会看到当前元素和它之前的这些元素,它后面那些元素的东西通过一个掩码使得在计算注意力机制的时候变成零,所以它是不看后面的东西的这个地方。因为我们用的是标准的语言模型,我们只对前预测,我们预测第i的时候,不会看到这个词后面的这些词是谁,所以一定是往前的这个地方,所以我们只能使用Transformer的解码器,不能使用它的编码器。

然后下面他给了这个模型的一些解释,当然假设你对Transformer比较了解了,他说如果我要预测U这个词它的概率的话,那我们把这个词前面这些词全部拿出来,就K个词拿出来,记成一个大U。然后把它做一个投影,就词嵌入的投影,再加上一个位置信息p的编码,那得到你的第一层的输入。那么接下来我要做l层这样子的Transformer blcok,每一层我们把上一次的输出拿进来,然后得到输出,因为我们知道transform模块不会改变你的输入输出的形状,所以你一直做完之后,最后拿到你最后一个Transformer模块的输出,然后再做一个投影,用softmax就会得到它的概率分布了。如果大家忘记了Transformer会计怎么定义的话,欢迎回到我们之前Transformer这篇文章的讲解视频,里面有详细的讲解,因为我们已经读过了BERT这篇文章,我们稍微来讲一下它跟BERT的区别,BERT我们知道它用的不是标准的言模型,它用的是一个带掩码的语言模型,它就是完形填空,所以完形填空是说候给一个句子,我把中间的一个子挖掉,让你预测中间的,就是说你在预测的时候,我既能看见它之前的词,又能看见之后的词。所以它可以对应的使用Transformer的编码器,因为编码器只能看到所有,所以使用编码器和解码器倒不是它们两个的主要的区别,主要区别在于你的目标函数的选取,这个地方GPT用的是一个更难的。就是给前面一段话预测后面一个词,预测未来当然比完形填空要难。具体来说,我给你股票的信息,到当前的股价之前都知道,我让你预测明天的股价远远的难,于是说我告诉你到今天为止的股价,但是我昨天的股票不告诉你,然后你预测昨天这个股票的价格,你都知道过去和未来,那么中间差值就能得到,中间就是预测一个开放式的结局,比预测中间一个状态要难很多,这也是导致了GPT在训练上和效果上它其实比BERT要差一些的一个原因之一吧。那么反过来讲,如果你的模型真的能预测未来的话,那么你比BERT这种通过完形填空训练模型要强大很多,这是为什么作者需要一直不断的把模型做大,而且一直不断容易才能最后做出GPT那样子效果经验的模型出来,这也是我们之前讲到的,作者选了一个更难的技术线,但很有可能它的天花板也就更高了,所以这就是预训练模型。
这也是为什么我们说GPT就是Transformer的一个解码器。
Supervised fine-tuning
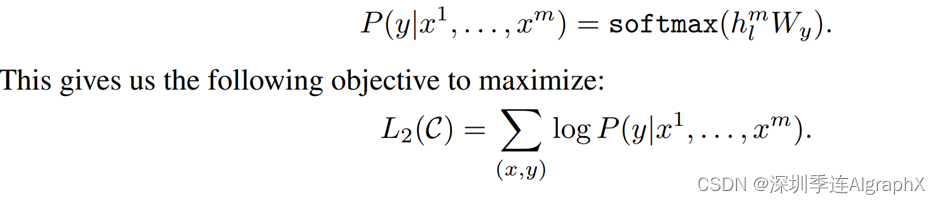
接下来我们来看一下它是怎么样做微调的,在微调任务里面我是有标号的。具体来说,每一次我给你一个长为xM的一个词的序列,然后我告诉你这个序列它对应的标号是Y,那么就是说我们每一次给这个序列去预测它的Y。具体来讲就是说我每次给你x1,一直到xM,我要预测Y的概率。它这里的做法是把整个这个序列放进我们之前训练好的GPT的模型里面,然后拿到Transformer块的最后一层的输出,它对应的hM这个词的这个输出,然后再乘以一个输出层Wy,然后再做一个softmax就得到它的概率了。就是微调任务里面所有的带标号的这些序列对,我们把这个序列x1到xM输入进去之后,计算我们真实的那个标号上面的概率,我们要对它做最大化,这是一个非常标准的一个分类目标函数。
然后作者说,虽然我们调的时候我们只关心这一个分类的进度,但如果把之前的这个语言模型同样放进来,效果也不错。

意思是说我们在做微调的时候,有两个目标函数,第一个是说给你这些序列,然后预测序列的下一个词或者给你一个完整的序列,让你预测序列对应的标号,这两个一起序列效果是最佳的,然后它通过一个λ 把这两个目标函数加起来,最后这个东西是可以调的,也是一个超参数了。
那我们知道微调长什么样子的情况下,接下来要考虑的是怎么样把NLP里面那些很不一样的子任物成一个,我们要的形式,就是说表示成一个序列和它一个对应的标号。
Task-specific input transformations
这就是第三小节要讲的事情,我们可以直接通过图一就能给大家讲清楚到底是怎么表示的,这里给了NLP里面四大常见的应用,我们下面来看一看它们都是什么。
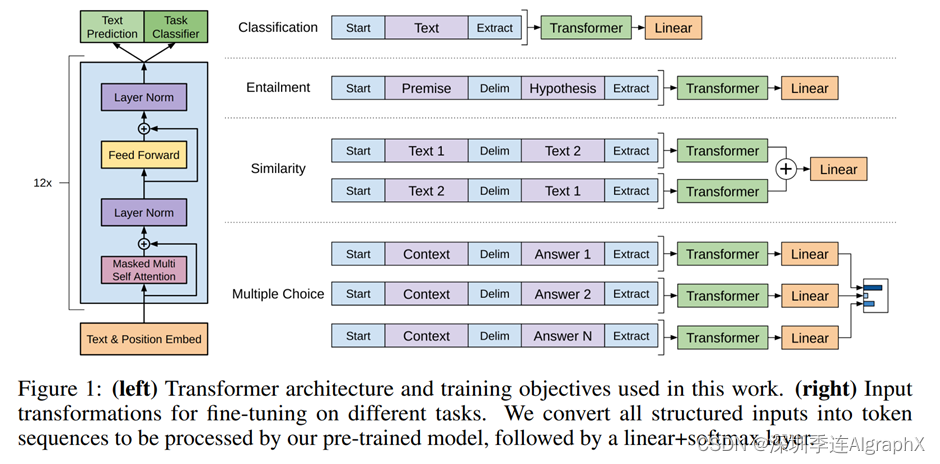
第一类是最常见的分类,就是说给我一句话或者一段文本,我来判断它对应的一个标号。比如说一个用户对一个产品的评价是正面的还是负面的。它这里的做法是说,我把我要分类的这一段文字,在前面放一个初始的词源start,在后面加一个抽取的词源extract,然后就做成一个序列。序列放进Transformer的解码器里面,然后模型对最后一个词,它抽取的特征,放进一个线性层里面,线性层的话就投影到我要的那个标号的空间,就是说如果我要做10类分类的话,那么你的线性层它的输出大小就是10。在训练的时候就是对每一个文本和标号对,我们把文本变成一个这样子的序列,然后标号就放在这个地方参加训练。在预测的时候,当然是说我们只拿到这个序列信息,然后对他直接做预测就行了。所以这个地方跟之前的预言模型还是有那么一点区别的,因为这个线性层,是我新加的,就是在微调的时候,我重新构造了一个新的线性层,里面的权重可能是随机初始化的,让它的输出的大小跟我的标号的大小是一致的。
第二个应用叫做蕴含,就是说我给你一段话,然后再问你一个假设,你看一下我前面这段话有没有蕴含。假设提出来的东西,比如说A送给B 1束玫瑰,假设我的假设是说A喜欢B,那么你就说我前面这段话是支持你这个假设的,如果说A讨厌B,那么你可认为前面这段话是不支持这个假设的。如果我说A和B是邻居,那么你可以说前面这个假设既不支持也不反对我这个假设,所以说白了就是一个三类的问题。我给你两段文本,然后让你做一个三分类的问题。它在表达的时候就是把这两个文本串成一个长的序列,用一个开始符在这个地方,还有分格符和抽取符。注意我们这里写的是start,风格和抽取,但是在真实表达时候,你不能用这个词放进去了。因为这些词你可能在文本里面也要出现,所以这三个词源是一个特殊的记号,必须要跟我的词典里面那些别的词是不一样才行的,不然的话模型就会混淆了。
第三个应用是相似,就是判断两段文字是不是相似,这个应用在NLP里面用的也是非常广泛。比如说某个搜索词和我某文档是不是相似的,或者说我两个文档是不是相似,我这样子能来去重,或者说两个问题问的是不相似的去重。因为相似是一个对称的关系,就说A和B相似,那么意味着B和A也是相似的。我们在语言模型里面是有个先后的顺序,所以这个地方它做两个序列,第一个序列里面,第一段文字放在第二段文字前面,中间还是一样,用分隔符分开,前面加一个起始符和一个结束符。第二个序列就是把文字一和文字二交换顺序,这是因为它的对称关系,然后这两段序列分别进入我的模型之后,得到最后的这个输出,然后在上面做加号,最后进入我的线性层,得到我们要的是相似还是不是相似的一个二分类的问题。
最后是一个多选题,就是我问你一个问题,然后给你几个答案,你在里面选出你觉得正确哪一个答案。它的做法是说,如果你有N个答案的话,那我们就构造N个序列,其中前面的都是你的问题,然后每一个答案作为第二个序列放在这个地方。每一个序列分别进入你的模型,然后用一个线性投影层,它的输出大小是1。这样得到你这个答案是我这个问题问到的正确答案的一个置信度。对每个答案我都算一个这样子的标量,然后最后做一个softmax,就知道我对于这个问题,我对每个答案觉得是它正确答案的置信度是等于多少。
可以看到虽然这些应用上它的数据都长得不那么一样,但是基本上都可以构造成一个序列,要么就是有一段话,要么就是有两段话,但是分隔开来。如果更复杂一点的话,我可以构造出多个序列出来,但是这个地方不管我的输入形式怎么变,我的输出它的构造怎么变,中间这个Transformer模型是不会变的,就是说我训练好我的模型之后,我在做下游的任务时,我都不会对这个模的结构做改变,这也是GPT跟之前工作的一个大的区别。这也是本文的核心点。
Experiments
讲完模型之后,我们来看一下它的实验,实验我们这里不会仔细给大家讲,大家只要注意到这有两点就是了,第一点是它是在一个叫做BooksCorpus的一个数据集上训练出来的,这个地方有7000篇没有被发表的书。第二个说它的模型的大小是长成这个样子的,它用的12层的一个Transformer的解码器,然后每一层的它的维度是768,所以我们关心的是说你用一个多大的模型,在一个多大的数据集上训练好的。在结果上他当然比了之前那些算法,他说我们这样子的方法呀,比前面的人都要好一点,这个是GPT这个算法,然后加黑是表示我在精度上都比别人高,这个是那么几个数据集,上面基本上都是比前人高。
然后我们再回过头来看一下我们之前讲过的BERT这篇文章,注意到这个论文就换成BERT了,这个地方是BERT,看到BERT的Base,它用的是12层,它的维度也是768。所以Base就是为了跟GPT做对比的。虽然BERT用的是编码器,GBT用的是解码器编码在同样的乘数和维度大小的时候,它比解码器其实那么简单一点点,因为它少一块带掩码的那个模块,但是基本上你可以认为它也是差不多等价的。实验比较了是GPT,然后Base虽然跟你GPT的模型是差不多,但实际上在整个的平均的精度上还是要比它好一点,你看它是75.1,那BERT做到了79,然后如果你把模型做更大的话,它还能从79.6提升到82.1,这也是对我们之前讲过的BERT一个非常简单的回顾。
GPT2
好接下来我们来看一下GPT2,就当你发现你的工作被别人用更大的模型,更大的数据打败的时候,那么你怎么样去回应BETR这篇文章。它的标题Language Models are Unsupervised Multitask Learners,叫做语言模型是无监督的多任务学习器。我们等会儿来看多任务学习器是什么意思,但无监督我们理解,语言模型我们来理解。作者上,一作没有变换,最后作者也没有变换,之前GPT那篇文章中间是有两个作者,现在全部换掉了,换成了四个作者。就是说主力干活的作者还是大老板也没有变,但是队员就换了一波。在看摘要之前大家想一想,如果你说我用一个解码器训练一个好的模型,效果觉得自己棒棒的。几个月之后被人用一个编码器,用一个更大的数据集训练一个更大的模型打败了,那你心里怎么想?那你得打回去,对吧?首先你不能换你的解码器了,因为你已经站好队了,如果你再换回编码器时候,编码器真的好,那么你前面的工作就浪费了。所以因为一作没有变,这个技术路线是不能变的,我还是要认为解码器好,那么怎么打回去?很简单,我可以把我的模型做的更大,数据集做的更大,但如果我通过做更大就能把前面的工作打败的话,那么我写文章也没什么问题。但问题是在于,如果你变大了,但是你还是打不赢。打你以前GPT的那个工作的话,那么你怎么办?这就是GPT2这个工作要面临的情况。我们可以大家看一下,首先他做了一个新的数据集,叫做WebText。然后有百万级别的文本,那么跟之前的Wikipedia和BooksCorpus,那么当然这个数据集要更大了,你有了更大的数据集之后,你能干嘛?那就可以训练一个更大的模型,15亿个参数的Transformer,记得BERT Large它最大值是3.4个亿,现在直接跳到了15亿,那就是说你的文本变成了百万级别的文本,那么你的模型变成了10亿级别的模型。但可惜的是说,当你变得那么大的情况下,你发现跟BERT比可能优势并不大。这时候作者就找了另外一个观点,叫做zero shot的一个设定,他其实在GPT那篇文章的最后一节有讲,他用zero shot来做一些实验,主要是去了解整个模型的训练的机制,在GPT2这文章就把作为它的一个主要的卖点拿了出来。
我们主要看一下是他怎么去卖zero shot这个事情?
Introduction
在导言里面,作者说现在一个主流的途径就是对一个任务收集一个数据集,然后在上面训练模型做预测。为什么这个东西很流行,是因为现在的模型它的泛化性是不是很好的,就是说你在一个数据及一个应用上训练好的模型,很难直接用到下一个模型上面。然后他又提到叫做多任务学习,多任务学习一开始的观点是说我在训练一个模型的时候,同时看多个数据集,而且可能会通过多一个损失函数来达到一个模型能够在多个任务上都能用。这个是在90年代末提出来的,在2000年到2010年之间,也曾经是比较流行的一个话题。作者说,虽然这个东西看上去比较好,但是在NLP里面其实用的不多,在NLP里面现在主流的算法也就是之前GPT和BERT那一类的,就是说在一个比较大的数据上做一个预训的模型,然后再对每个任务上做一个有监督的微调。当然这样子还是要两个问题,第一个是说对每一个下游的任务,你还是得去重新训练你的模型,第二个是说你也得收集有标号的数据才行,这样导致你在拓展到一个新的任务上是还是有一定的成本的。然后导论的最后一段话就是说GPT2要干什么事情,他说我还是在做我的语言模型,但是,我在做到下游任务的时候,我会用一个叫做zero shot的设定。zero Shot是说我在做到下游的任务的时候,不需要下游任务的任何标注的信息,那么当然也不要去训练我的模型。这样子的好处,说我只要训练一个模型,在任何地方都能用。最后一句话是说我们得到了还看起来挺不错的,而且有一定竞争力的结果。回到我们前面讨论的,如果做的就是在GPT的基础上,用一个更大的数据集训练个更大的模型,说我比BERT好一些,可能也就好那么一点点,不是好那么多的情况下。那么这篇文章有没有意思,大家会觉得没什么意思,工程味特别重。那么现在来了,我换一个角度,我选择一个更难的问题,我说做zero shot,就不训练,不要下游任务的任何标号,然后跟你得到也还不错,差不多的,有时候好一点,有时候差一点的结果。虽然这个时候从结果上看没那么厉害,但新意度一下就来了,对吧?所以这也给大家做研究有一些提示,你不要一条路走到黑,做工程你可以一条路走到黑,你就把进度往死里做,但是在做研究的时候,你一定要比较灵活一点,尝试从一个新的角度来看问题。
Approach
接下来我们来看一下方法。因为GPT2和GPT1在模型上基本上是长得一样的,所以我们不给大家一段一段读,而是给大家讲一下跟之前方法一些不同的地方。在什么地方回忆一下,我们在之前做GPT的时候,我们在预训练语言模型的时候,是在自然的训练的,但是在做下游的任务的时候,我们对它的输入进行了构造,特别的是说我们加入了开始符、结束符和中间的分隔符。这些符号在之前模型是没有看过的,但是因为你有微调的环节,所以模型会去认识这些符号。你给我一些训练样本,我去认识这个符号代表什么意思,但现在你要做zero short,那你的问题是什么?你在做下游的任务的时候,我的模型不能被调整?但是如果你还引入一些模型之前没见过的符号的话,模型就会感到很困惑。所以在这个设定下,我们在构造下游任务的输入的时候,就不能引入那些模型没有见过的符号,而是要使得整个下游任务它的输入,跟你之前在预训练模型看到文本长得一样,就是说你的输入的形式应该更像一个自然的语言。这个地方作者给了两个例子,第一个例子是说做机器翻译,如果你想把英语翻译成法语,你可以表达成这样一个句子,首先是翻译成法语。给你英语的那个文本,然后接下来是你英语对应的法语的文本,所以前面这三个词,你可认为就是做了一个特殊的分割符的意思,在后面的文献里面,这个叫做prompt,也叫做提示。如果你要做阅读理解的话,他又说我可以设计一个提示,叫做回答这个问题,接下来是你读的那个文本,然后是你的问题,最后是你的答案。这个地方回答这个问题作为一个提示,模型知道哦,我现在要去做这个任务。接下来还有大段讨论你为什么可以这么做,因为这个东西不是作者提出来,是前面的工作,这一篇工作提出来的东西。后面这些话基本上作者都在讨论,是说这个途径到底为什么可以工作,作者觉得如果你的模型足够强大,他能理解你那提示符干的事情,那当然就比较好。另外一个是说,可能在文本里面这样子的话也很常见,可能本来就出现在这里面。
那么他在下面一节讲数据那一节稍微对第二点做了一些解释,我们来看一下他的训练数据长什么样子的,这一节里面他详细讲了一下他的数据是怎么样出来的。首先第一段话说前面的人大家用,用的Wikipedia,fiction books,那么接下来你要构造一个更大的数据集才行。他说一个可行性的办法,需要一个叫做common crawl的一个项目。Common crawl是一个公开的网页抓取的项目,就有一群人写了一个爬虫,然后不断的去在网上抓取网页,然后把抓取的网页放在AWS S3上面,然后供大家免费的下载。这个项目已经做了很多年,目前来说应该是有TB的数量级,应该是目前能够很方便下到的最大的一个文本数据集。作者说这个数据集不好用,这是因为它的信噪比比较低。因为抓回来的网页里面很多可能是没有含有比较有意思信息的,可能就是一些很垃圾的网页,那么你要怎么去清理它,需要花很多很多的时间。就是说虽然我没有能力现在把你很好的标出来,但是它可以去利用网上大家已经过滤好的一些网页,具体来说他用的是Reddit。Reddit是一个美国排名很靠前的一个新闻聚合网页,在国内好像没有类似的一个服务。他的想法是说每个人可以去提交你感兴趣的一些网页,然后把你分门别类的放在每一个类别下面。接下来Reddit的用户就是对你投票说喜欢或者不喜欢,然后给他去进行评论,然后你投票的话会产生一个叫做karma的一个东西。karma最早来源于佛教里面的一个术语,当我不是专家,你大概可以理解成一个轮回报应值。在Reddit上面,karma可认为是用户对一个帖子的一个评价,他选取了所有至少有三个karma的帖子,Reddit的用户已经帮你度过,而且觉得里面有一定的价值,然后他去把他所有的爬下来,最后得到了4500万个链接。然后再把它里面的文字信息给你抽取出来,就这样子得到了一个数据集,这个数据集最后大概是800万个文本,然后一共是40GB的文字,然后在表1里面,他又拎了一些句子出来证明说其实在我爬下来的数据里面,就是对于英语翻法语这个例子来讲,已经有了很多的这样子的样例.比如说这句话是说有人在法语里面写了一句这样子的话,然后如果翻译成英语来说,那就是长这样子。下面都是说这些东西都是怎么样对应的英语语句翻译成法语长什么样子。作者想表达意思是说,如果你在这样子的数据上面训练语言模型的话,很有可能他确实就可以真的把英语翻译成法语,因为你的文本里面出现过很多这样子的例子。当你有了更大的数据集的时候,你当然可以把模型做的更大了。
作者一共设计了四个模型,第一个模型有12层,每一层它的宽度是768。

有1亿个可学习的变量,那么就是来自于之前的GPT或者BERT Base。第二个模型就是了BERT Large,然后它在之上,最大的情况下是说它把乘数再翻了1倍,就是24变成了48,然后你的宽度也从1024变成了1600,基本上是1.5倍的样子,得到了一共有15亿个可学习元素的模型。就后面是一些实验,我们就没打算给大家仔细的去过,因为它的实验,主要是跟别的做zero shot的方法比,会长什么样子。比如说在这个地方你看到了是它的这四个模型,跟当前在不同这些任务上面的zero shot的SOTA它的方法的比较。这些方法不是我们之前讲过的那一类,还是说专门做这些那一类怎么样,当然是说GPT,我们比你们都好,因为你用到的模型复杂度和数据量确实比人家甩几条街出来。那在最前面其实有一张表,解释是他在几个任务上面的一些体现,比如说这个是你的阅读理解、翻译摘要和问题回答。
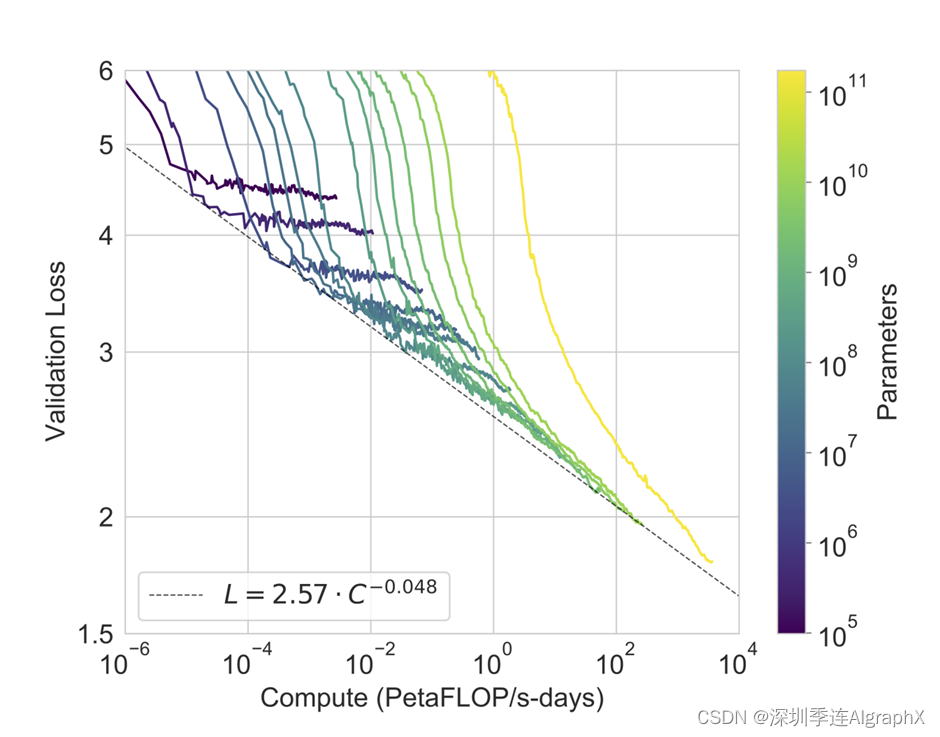
下面你的轴分别是你的模型大小,因为他这个地方有四个模型,所以它一共有四个点。然后这个地方你看到阅读理解上来说,他似乎跟别人还是不错的,就是说这个是比较好的方法。摘要上面就差一点,这个是sequence to sequence加上注意力机制的一个模型,还是差一点。如果你在QA上面,那就是你跟现在的比较好模型差的远,因为现在比较好模型还在远远的上面很远的地方了,所以你还早的很。所以就是说在摘要里面,作者说虽然我们的结果还是比较有意思的,在一线任务上还做不错,另外一些任务上是至有那么一点点意思,所以他讲的也是比较委婉的。但是注意到是说随着你的模型的增大,你的性能还是在上升的,也就是说你还是有希望训练更大的模型,使用更大的数级,使得你的模型的性能能够突破天际,使得跟真正的在有监督上面训练出来效果是一样,这就是接下来工作GPT3要干的事情。
GPT3
接下来我们来看GPT3这篇文章,GPT3这篇文章的标题Language Models are Few-Shot Learners叫做语言模型是few shot learner。在讲GPT的时候,我们有讲过,他在文章的最后一段,其实也做了一些实验,就是在子任务上面我给你提供一些样本,但是不是在植入所有的样本的时候,其实语言模型能够用最少数的样本能极大的提升性能。GPT2是在GPT上往前走了一大步,是说在子任务上面我不给你提供任何相关的训练样本,直接使用预训练模型去对子任务上做预测,作者之所以这么做,很有可能就是为了跟BERT文章在新意度上能够有所区分。我们有讲过,一篇论文的价值取决于你的新意度,要乘以你的有效性,当然要乘以你问题的大小。但是不管是GPT,GTP2做的是同样的问题,所以问题是固定的,GPT2虽然在新意度上的特别高,但是有效性比较低一点,所以导致他论文的价值最后很难说是一篇特别重要的文章。GPT3就是尝试去解决GPT2的有效性,所以他又回到了GPT1开始考虑的设置。说我不再去追求很极致的,我不一下子不给你任何样例。其实在现实生活中也很少,就算是人类你要学习的时候,你也要通过一些样本来学习,只是说人类在样本的的有效性上做的比较好,就通过一点点样本就行了。但是语言模型需要大量的样本,所以在这里few short的意思是说我还是给你一些样本,但不用太多,只要你的样本的个数是在可控的范围里面,所以这个成本还是非常低的。在作者上面可以看到作者基本上换掉了,GPT1和GPT2的一作已经跑到了最后。
前面的这作者在之前基本上都没有出现过的,当然如果大家感兴趣的话,可以跳到文章的末尾,它有详细的解释的每个作者是干的什么事情的。我觉得GPT3这文章的贡献真的多。虽然我又很多作者的名字,但是我后面解释个作干什么事情,也是给大家一个标杆。你可以写很多名字,没关系,但是你至少告诉我说这些人真的是干的活,不然就挂个名字来赚一个引用。大家如果去仔细看的话,基本上看到前面这些作的基本上都是在做实验的,上面GPT3这篇文章真的是做特别特别多的实验,这也是整个OpenAI他做文章的一大特点。就如我们之前讲的clip的文章,它也是做了大量的实验,所以导致有大量的作者。
Abstract
接下来我们来看一下摘要,摘要的前面几句话没有什么特别好看的,就跟之前没有什么太多区别。具体来看,是说我们训练了一个GPT3的模型,这也是一个自回归模型。它有1750亿个可学习的参数,比之前所有的那些非稀疏的模型,稀疏的模型是说你整个权重可以是稀疏的,里面有大量的零,但如果你的模型很多很多零的话,你把这些零算进去的话,你的模型也算的特别大,所以它作为对比,它跟那些非稀疏的,就是说不会存在很多零的这些模型相比,它比它要大十倍,就是在可学习的参数上面。然后因为你的模型已经那么大了,那么在做子任务的时候,你如果还要去训练你的模型的话,那么你的成本上是很高的。所以在这个地方,GPT3在作用到子任务上面时候,不做任何的梯度更新或者是微调,就是就算是在few shot的情况下,给你一些样本情况下,GPT3也不是用微调,因为因为微调需要你总是去算梯度,那么大的模型算梯度是非常非常难的事情,所以这个地方它是不做任何的梯度更新的,也是他的一大特点。然后他说我在所谓的这些NLP的任务上取得了很好的成绩,这也是跟GPT2他能区分开来,GPT2它的成绩跟我们想要的还差的很远。然后最后作者说GPT3能生成一些新闻的文章,而且人类读起来是很难区分,看来你到底是模型生成的还是人类写的,这也是GPD3的一大卖点,也就是后面大家能通过它玩出花样来的一个主要的地方。
Contents
接下来是他的目录,这也是我们第一次读到在论文的第二页放目录的文章了,然后可以看到前面两节是讲他的方法,写了十页,然后是他一个长长的结果,他又写了十页,在后面是一个长达20页的一个讨论,在讨论之后还有一个20页的附录里面讲的是一些细节,所以整个文章有63页。它不是一篇投稿的文章,而是一个技术报告。所谓的技术报告实讲没有发表的文章,因为它没有版面和页数的限制,你可以写的特别长,当然长有长的好处,它可以把东西写的特别细。所以你在读它的时候,可能没有相关的背景知识,读起来也没问题。但是长的坏处是说你的阅读门槛又增加了,如果我就想了解一下你做什么事情,我要读63页,那我怎么读?但这个地方我的个人看法是GPT3真的没必要写那么长,他写那么长,他并没有把前面的东西交代的特别详细。我们在讲GPT3之前,需要给大家讲一下什么是GPT和GPT2。因为这两篇文章的内容在GPT3这篇文章里面是没有覆盖的,就是说虽然我写了63页,但我并没有讲前面两个工作什么东西,而且GPT3是完全基于GPT2这个模型的,63页并没有讲这个模型。他花了大量的篇幅去讲这结果和后面的一些讨论。导致说在读这个63页的论文之前,我们先得把前面两个论文给读了才行。所以我个人是非常不推荐大家这种写法,你要么就写的短一点,大家读下来很快就知道你的中心思想,要么你就写的长一点,把前面的背景知识给大家详细的介绍一下,我不需要读前面的文章。从你这篇文章开始,我也能知道你在做什么,像这种你既需要读前面文章,又需要读我很长的文章,只有当你的工作是真的是特别特别好的时候,你才可以那么任性,别人才会来读你的文章了。
Introduction
我们接下来看一下导言,导言的第一段话是说最近一些年来,在NLP里面大家都使用预训练好的语言模型,然后再做微调。第二段话是说这当然是有问题的,有什么问题?他说我们对每个子任务还是需要一个跟任务相关的数据集,而且要跟你任务相关的一个微调。具体来说,它列了三个问题,第一个问题是说你需要一个大的数据集,你得去标号吧,这当然是有问题的,GPT2也讲到这个事情了。第二个我觉得就相对来说比较虚一点,就是说当你的一个样本没有出现在你的数据分布里面的时候,你泛化性不见得就比你那个小模型要好。所以是说如果你在微调上面的效果很好的话,也不能说明你的预训练的模型它的泛化性就特别好。它很有可能就是你过你和你的预训练的数据,而且这个训练数据跟你的微调所要的那些任务,刚好有一定的重合性,就导致你在这些微调任务上是做的比较好的。就跟之前用书来做预训练,用Wikipedia做预训练,或者是在网上爬的网页做预训练,这些文字里面刚好包括你所有下游任务他要的那些文字,他们都是类似的一些文字,所以导致你的微调效果比较好。但是如果你换到一个别的语种,或者换到一个更专业性的文章那么上面你的表现力可能就不那么的好了。作者在这里的意思是说,假设我不允许你做微调,不允许你改变你预训练模型的参数的话,那么你就是真的就是拼的预训练模型的泛化性,假设我允许训你微调的话,那么预训练模型可能好一点坏一点,它都差别不那么大了。第三个是说人类,大家都会说到人类,人类不需要一个很大的数据集来做一个任务,就是说你有一定的语文功底的话,我让你做一个别的事情,你可能给你两个例子,告诉你怎么做就行了,你不需要再采集成千上万,就你不要做个基本习题才会掌握一个小应用了。当然后作者提出这个问题之后,要讲他的解决方案,他的解决方案也跟之前讲过,他其实也就是做few shot或zero shot的学习了。
在这个地方,作者又换了一个名词来了,他说一个解决这个问题的办法叫做Meta learning,叫做元学习。我觉得作者在取名字这个事情上也不见得是那么的精确。GPT2用的是multi task多任务学习,但是它其实跟之前的multi task learning力还是有那么一点点区别的,然后在这个地方他又试图去重新定义什么叫做Meta learning。他有一个注释,有个常常的注释讲的说,他我们跟之前大家叫Meta learning的当然是有一点的不一样了,所以这个地方我们有我们自己的定义,但我觉得你如果想重载前面家都知道的一些名词的话,除非有特别多的必要,不然没意义,因为你会给大家造成误解。而且大家现在讲到GPT3这篇文章的时候,也不会去提他是用的是meta learning,或者是他是用的是multi task learning。然后他又定了一个新名词In context learning,就是在又上下文学习,虽然用的是zero shot, few short,它在这个地方在摘上面已经讲过,我是不更新我的模型的。因为在计算机视觉里面,我们也要讲zero shot, zero shot好理解,那我什么都不干,但是作于few shot的话,我给你一些样本的话,我还是可以用这些样本来对我的模型进行更新,这样子我能够更拟合到这个上面去。它这个地方强调的是我不要对我的权重做任何的更新,因为你的模型太大了,更新不了,所以呢,他这个地方要需要跟前面做区分开来,所以他尝试的用了两个名词的这个地方,一个是meta learning,一个是in context learning,但是大家理解一下他讲什么就行了。所谓的meta learning就说我真的训练一个很大的模型,里面的泛化性还不错,In context learning是说我在后面的时候,即使告诉我一些训练样本,我也不更新我的权重。
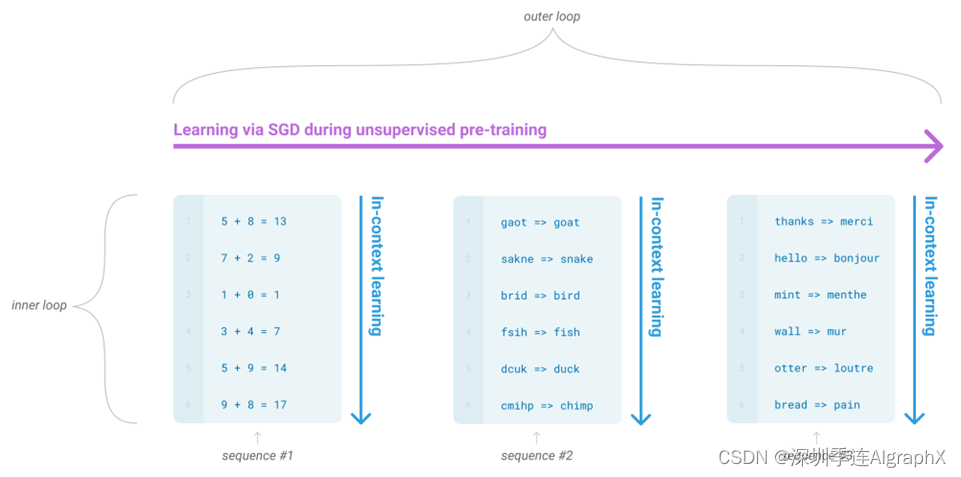
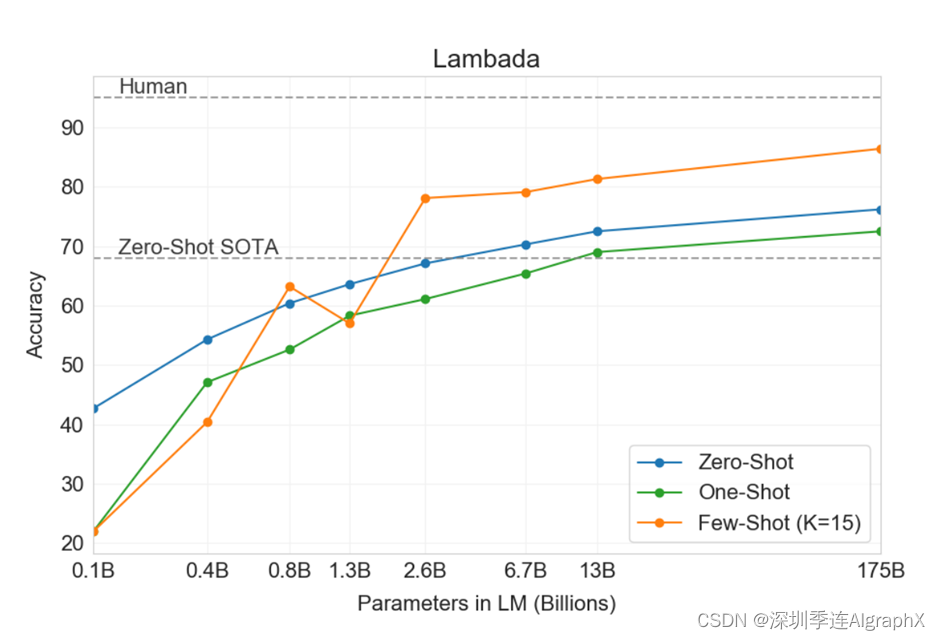
他在前面有画一个图,讲了Meta learning大概一个想法,他这个地方画的是有一点点的奇怪的,他看上去好像是讲我的模型是怎么训练的,就是说我有一个通过SGD来做预训练的过程。然后,在每一步里面好像要做一个什么样的事情,他其实他不是真正的讲GPT3这个模型怎么训练出来的,而是说这个语言模型,你可以怎么样类比成一个Meta learning?他就说如果你这一个是一个样本,这也是一个样本,而且每个样本来自不同的文章的时候,可能他要干的事情不一样,比如说这一个样本有这一段话,告诉你的是各种加法怎么做。就下面的话告诉你是一个错别字,怎么样改成一个正确的,然后在后面就是英语翻成法语,所以说在每一个段落或者每一个文章,如果来自很不一样地方的时候,他可能教你不一样的东西,如果你在大量的这种多样性的文章上做训练的候,你的模型多多少少有在做一个元学习的过程。学习的大量的任务,而且每一个段落你可以认为是一个叫上下文的学习,因为他们之间是相关的,然后你要从上下文来得到一些信息,但是他们之间,它就没有太多关系了,就是多个任务之间了。所以这个东西放在这里,其实放不放我觉得它都不影响到它的模型的。但是放在这里我们就讲一下,但是大家如果一开始读的时候读的有点奇怪,可以忽略不要紧。然后再讲了他的设定之后,他又说最近些年,大模型的大小变得越来越大,但是其实,我觉得也就是OpenAI把整个军备竞赛给大家搞了起来。GPT1出来大家都觉得,你可以做那么大,然后别的公司也纷纷的跟进,不管是美国的还是国内的公司,大家也愿意去参加这样子的比赛,然后在后面也是说GPT3是一个1750亿个可学习参数的模型。它的模型,它的评估是用的这三个办法,一个叫做few short,也就是说对每个子任务,我给你提供大概10-100个的训练样本。一个特殊的情况叫做one shot,就是每一个任务我只给你一个样本,就是说英文翻法语的时候,我就告诉你一个英文hello word怎么翻成法语的那一个词,然后让你接下来给我继续翻下去。接下来是zero short,就是说我一个样本的不告诉我,就让你英语翻法语。
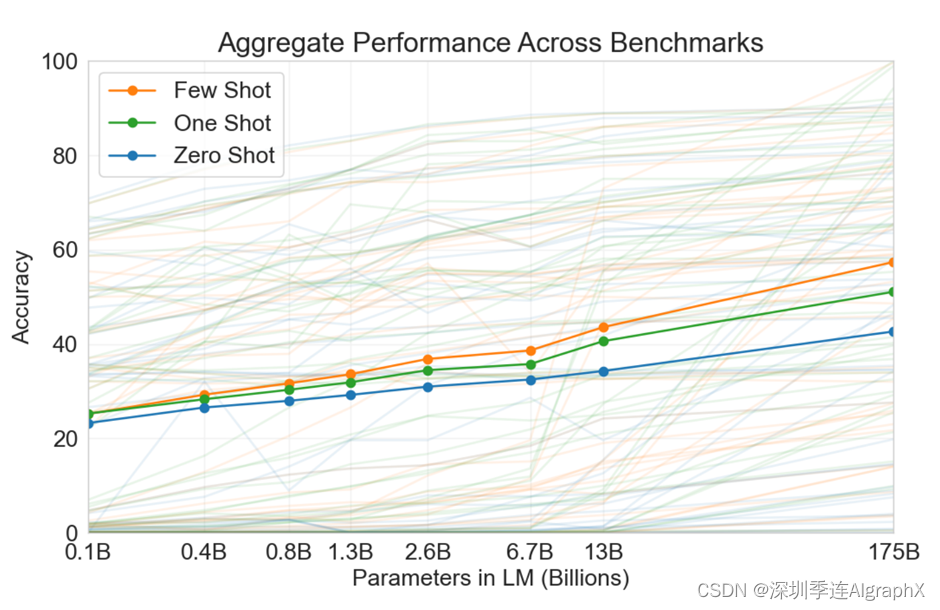
上面一张图给大家展示了一下在三个设定下它的模型的一个区别。它的X轴在这个地方,是整个语言模型可学习参数的大小,这1.3B基本上就是GPT2的模型。然后你的Y是你的accuracy,当然你在很多子任务上面,它做了一个平均,就是说这些虚线是每一个子任务上的,然后它做平均就变成了三个实线,然后这里有三条线,颜色不一样的线,黄色表示的是few shot,绿色表示的是one shot,蓝色表示的是zero shot。之前我们讲过的GPT2这篇文章,你可以认为就是1.3b这个模型,然后用zero shot,那么精度可以认为是平均下来是30%左右的样子,然后你把1.3B变成了175B的时候,就这一个点的时候,而且使用的few shot就允许给你10-100个的样本的时候,那么基本上看到它的精度接近了60%,就是基本上你的精度翻了一倍了,所以可以看到效果还是非常明显的好。
Approach
接下来我们来看一下第二章,也就是它的模型的部分。
在模型的部分,它先给大家又重新讲了一下什么叫做Fine-Tuning,然后它的few shot learning和它one shot,以及它的zero shot,它到底是什么区别,但其实你在这个地方,你可以通过下面这个图,是看的比较清楚的。

首先右边讲的是微调是怎么做的,在微调的时候,我们训练好预训练模型之后,在每一个任务上面我们提供一些训练样本,那这个地方假设我使用批量大小唯一来训练的话,就每次给你一个样本,这个是英语翻法语的样本,因为我有标号,所以我能计算损失,然后我就可以去对他的权重进行更新,然后再拿到一个新的样本继续更新,就可以当做一个很正常的训练任务来做,但是跟之前不一样的是说,微调通常对数据量的要求要少于从零开始训练,而且在学习率上通常可以做的比较小一点,这是因为微调的初始值,那个模型是用预训练好的模型做的,所以它跟你最终的解已经很好了,所以你只要大概稍微调一下就行了。但是在GPT3模型的设置里面,它追求的是不做梯度更新,但不做模型更新它肯定是有它的新意度的。但反过来讲,那么大一个模型,假设我换到一个新任务上还得再做更新的话,那么它的使用门槛是比较高,所以也不可能使得像现在那样,大家可以在GPT3上面玩出花来。他这里使用的是英语翻法语这个例子,他想干的事情是说把英语的cheese翻成法语的对应的单词,假设在zero short里面怎么办?他就在前面加一句说把英语翻成法语,然后冒号。这是你这个任务的描述,但是他希望你预训练好的GP3模型能理解我这句话是想干什么事情,然后是把我要翻译的词放进来,加一个箭头,箭头这个东西叫做prompt,也就是提示告诉你这个模型说好,接下来就是轮到你输出了,然后把这句话放进模型,模型对下一个词的预测这个词,那就应该是cheese,它对应的翻译的单词,如果你对了,那就对了,如果错了,那就是你模型预测错误。如果需要one shot怎么做?就是在你任务描述之后和在你真正的做翻译之前,我插一个样本进来。就是在定义好这个任务之后,我再告诉你一个例子,英语单词翻译成法语单词应该是这么翻译的,就希望你的模型在看到整个句子的时候,能够从这条里面提取出有用的信息来帮助你做后面的翻译。
注意到这一点是说这是一个样本放进去的,它只是做预测,它不做训练,就是说虽然它是一个训练样本,但是它放进去之后是不会对模型算梯度,也不会对模型做更新,所以他希望的是你在模型在做前向推理的时候,能够通过注意力机制,然后去处理比较长的序列信息,从而从中间抽取出来有用的信息,能够帮助你下面做事情。这也是为什么叫做上下文的学习,就是你的学习只是限于你的上下文。那么few shot能力,就是对one shot的一个拓展,就之前我是给你一个样本,现在我会给你多个样本,当然你可以做更长,但是更长不一定有用,因为你这个模型不一定能处理特别特别长的数据,就是说如果你的序列很长的话,那么模型也不一定有能力把整个句子里面的信息给你抽取出来,然后让你帮助到生成做这个事情。所以看完这个图之后,大家就知道这两种模式之间的区别。GPT3采用的这个序列当然是对新的任务更加友好了,就是说我碰到一个完全之前没见过的任务的话,我不要去更新我的模型,因为做模型的推理和做模型的训练在你的设置上是很不一样的,因为在训练的时候我对内存的要求更高,而且有超参数要调,而且得很好的准备你的训练数据。但现在我只要做预测就行了,拿一个新任务给你,你把结果返回给我就行。这当然是它的好处,当然也有一点点坏处,坏处是说假设我真的有很多训练样本,那怎么办?比如说我就做英语的法语的翻译,大家很容易在网上找到个几百上千个样本来帮助你翻译,对吧?这个时候你发现你想放进去是很难的一些事情,你难道你要构造一个样本里面把整个子任务的训练书籍放进去吗?那么就是特别长,你可能模型处理不了。第二个问题还是相关的,就是说我假设有一个还不错的训练样本,然后你的模型,在不给你的训练样本时候表现不行,我需要给你一个训练样本,但是每一次我都给你,就每一次做一个新的预测的时候,我都给你,因为你这个模型是每一次的时候要从中间去抓取有的信息,就我不能把上一次模型从中间抓取的信息给你存下来,存到你的模型里面,所以这也导致说,虽然GPT3在一年半前就把这个效果做的那么好,但实际上好像用few shot做这种上下文的学习,似乎用的还不那么的多。
Model and Architectures
2.1节讲的是它的模型和架构,他说GPT3的模型跟GPT2的模型是一样的,后面补充了GPT2模型跟之前GPT的区别是你的模型的初始改变,把你的normalization到了前面和可以反转的,但是也做了一点的改动,具体来说它就是把这个工作里面的那些改动给你拿了过来,然后它设计了八个不同大小的模型,具体来说会看在表2.1。
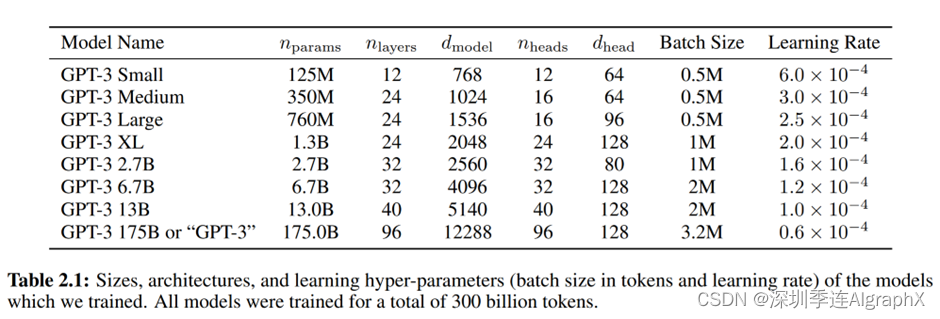
这个表里面每一行表示的是一个模型,每个列表示的是模型的一些参数.比如说这个列表示的是你模型里面有多少个可学习的参数,然后你的模型里面有多少层,然后你每一层,你那个词表示成一个多么长的向量,以及在多头注意力里面有多少个头,最是你每个头的那一个维度的大小,back size是说在训练的时候每个小批量大小多大,最后你在训练的时候用的学习率是多少?首先看一下第一个模型,第一个模型是GPT3 Small,可以看到它12层,每一层大小是768,是不是很熟悉,它就是GPT模型,它的参数是这样子的,然后它的可学习参数是1.25个亿,也是特Base,它的模型的大小。GBT3 Medium 24层,每一层大小是1024,然后大家知道这个尺寸是BERT Large的尺寸。然后在后面几个模型,就是层数没有变,但是你每一层的那个宽度有增加,然后看到1.3B这个模型,虽然之前我们这个结果大概等价于GPT2的模型,GPT2的大小是1.5B,但实际上它的大小是跟GPT2是不一样的。GPT2在这个地方其实它有48层,但是它的模型的宽度是要窄一些,所以GBT3-XL跟GPT2比,它是要浅一些,然后要宽一些。然后它一直增加,增加到最后就是GP3-175,简称是GPT3。这个模型的话,它用的是96层,然后每一层,大家已经到了12000的左右了,所以这个已经是非常非常大的一个尺寸了。然后大家可能会问,这些参数怎么样定出来的,但我觉得这个可能是作者拍拍脑袋吧,但我们知道就是说你把你层数增加的时候,你的宽度也应该增加,我们知道把乘数增加的时候,你的宽度也要对应的增加,因为你的计算复杂度跟你的宽度是平方关系,跟乘数是线性关系,但整体来说GPT3的模型是比较偏扁一点的,比如说GPT3最大的模型跟前面比,那就是16的大小关系,但是在96这个层数上,其实跟前面比也就最多是8倍的关系了,然后看到批量的大小,在大小可以看到,当你训练很大的模型的,它用的是3.2个million,也就是说你一个小批量里面有320万个样本,这是一个非常巨大的一个批量大小了,这个对你内存的考验是非常大的,因为你在计算梯度的时候,你中间变量的那一个大小是跟你的批量大小成正比关系的。当然在分布式的情况下,假设你在机器与机器之间用的是数据并行的话,那么你每台机器要计算的批量大小应该就是320万除以你机器数量的大小,所以如果你有很多台机器的话,你100或上千台机器的话,每台机器也还是能撑住的。作者有提到你为什么要用相对来说比较大的批量大小,因为你批量大小一大的话,你的计算性能会好,就每台机器的并行度更高,而且你的通讯量也变低,所以的分布式比较好的。之所以你在小的模型你不用很大的批量大小,是因为对小的模型其实是更容易过拟合一些。你需要用一个相对来说比较小的批量的大小,这样子导致你在采样的时候,数据里面的噪音是比较多的。你当你的模型变得很大的时候,你相对来说用大批量的大小,你降低了批量里面的噪音,好像对大的模型来说问题不是那么大。这个有一点点反直觉,这一块其实最近有很多工作去研究为什么这么回事。当你的模型变得越来越大的时候,似乎你的过拟合没有那么的严重。大家怀疑有两个原因,一个原因是说你神经网络这么设计下来,大家训练出来能得到比较好结果,其实背后有一定的结构,使得它不那么容易,就像简单的MLP一样,直接的这么那么过拟合了。第二个是说当你的模型变得越来越大的情况下,而且在有结构的情况下,它能搜索范围更广,而且这样就更有可能去概括到一个可能存在的一个比较简单的一个模型架构,如果你的模型比较小的话,你可能搜索空间都搜不到那一个简单的模型那边去,当你模型很大的时候,那你的SGD能够帮助你去找到那一个模型,最后导致你的泛化精度比较好。当然都是一些猜想,大家有在做研究工作,我们在这里就不展开给大家了。
最后学习率,学习率就是当你批量大小变大的时候,你的学习率是往下减的,这个其实也是跟之前的一些工作的结论是相悖论的。Facebook的一个工作是说当你的批量大小往上增的时候,你的学习率要线性的往上增。这个地方它其实是一个反过来的,他学习的往下降。作者在段落中有提到,为什么他是要往上增和往下降,大家可以去看一下文章里面提到的原始论文里面的解释。
反过头来看2.1章,真的就是比较短小的,就是两段话就解决了,也就半页的样子。就是说在一篇63页的文章里面,整个模型的架构就写了不到半页,而且这个地方你根本就没写清楚,是说我的模型跟GPT2是一样的,那么你再去看一下GPT2,然后说我在上面又做了一下改进,用了一个叫Sparse Transformer的结构,你得也去看这文章,然后这个地方还提了一句说GPT1其实跟GPT2改了这些东西。
作为一个读者的话,你想搞清楚GPT3整个模型长什么样的话,你得去读一系列的参考文献。当你这篇文章已经有63页的情况下,我觉得这么做是没有那么的必要性的,你在这个地方就给大家讲一下GPT模型长什么样,甚至是GPT模型长什么样子,以及说你这个长什么样子,你就算是放在一个相关工作里面,或者放在后面都是可以的,因为这样的话会给没有读过之前那些文章的读者带来很大的便利。这是因为你去读前面工作的话,你还得把它的完整的故事读一遍,对吧?他的记号用的是什么的,这些表达是什么样子,然后我们已经读到这个地方了,那所有的标号,这个写作风格我们已经读下来,是比较熟悉了,如果你在这个地方写清楚,或者甚至是你在后面的附录写清楚,那我也不需要重新再读一个新的故事,而是直接知道这个技术细节长什么样就行了,这也符合这篇文章要卖的就是上下文的学习。当然我们这不是要批评这篇文章写的不好,只是给大家指出了,说读这篇文章时遇到这样子一些障碍,大家自己在写作时候可以想办法去避免这样子的事情。
Training Dataset
第2.2节讲的是它的训练的数据,当你要做一个很大的模型的是,当你的训练数据就得非常大了,这个地方他们的训练数据是基于Common Crawl。在GPT2这篇文章里面,他有提到说我们可以考虑,但是他觉得数据噪音太大了,用起来比较难,所以他用的是另外一个办法,在这个地方,如果你想训练一个比GPT2要大100倍的模型的话,那他得不得不去重新去考虑这个数据了。
具体来说他做了三个步骤来使得这个数据让它变得更干净。
首先他们过滤了一个版本,然后是基于它的相似性和一个更高的一个数据集。具体来说他干了什么事情?大家回忆一下,在GPT2里面,他把的reddit上面爬下来,然后把karma>3的那下载下来,作为一个高质量的网络数据集。这个地方他干的事情就是说把Common Crawl下下来,然后把他的样本作为负样本,之前GPT2那个数据集,作为正例,那个是高质量的。Common Crawl你认为大部分是低质量的,然后在上面做了一个很简单的logistic regression,做一个二分类。正类是GPT2的爬下来的数据,负类是common crawl里面的,那么接下来做预测。对common crawl里面所有的网页拿出来,如果分类器认为你是偏正类的话,就是说你的质量比较高的话,那么他就留下来,如果判断出来很负类的话,那么就是过滤掉。
第二个是它做了一个去重的过程,就是说如果一篇文章跟另外一篇文章很相似的话,那我们就把这篇文章去掉。它具体用到的是一个叫做LSH的算法,它可以很快的判断一个集合,一篇文章是一个集合,就是一些词的集合和另外一个很大的一个集合之间的相似度。这个在information retrieval里面是一个非常常用的技术,如果大家不熟悉的话,可以去看一下,这也是在面试中间大家很喜欢问的一类问题。
那第三个是说我们又加了一些已知的高质量的数据集,就是把之前的BERT GPT GPT2的所有数据都拿过来,也加进来,最后就得到一个非常大的一个数据集了,可以看一下在放在下面这个地方。
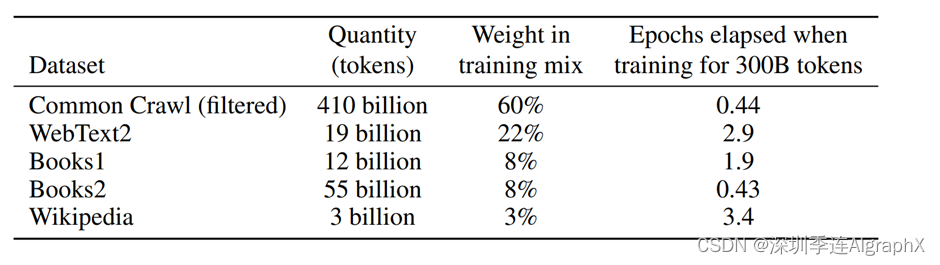
首先第一行就是他们新加进来的数据,这里面一共有4万亿字。WebText2,就是GPT2用的数据集,它上面一个比下面一个大20倍的样子,但是它的模型已经大了100倍,然后接下来是书的数据集,Wikipedia。common crawl带来了大量的数据,但是作者认为它里面质量还是相对来说比较差的,所以在采样的时候,它是用了稍微不一样的采样率。虽然common crawl你比后面这些加起来还要大那么七八倍的样子,但是在采样的时候,就是说一个批量大小,一个100万大小的批量里面,也就是60%的数据是来自于common crawl有22%的数据是来自于WebText2,看到common crawl里面的数据也就比下一个多3倍,虽然你的大小上来说多了20倍,而且下面这些Wikipedia虽然它的大小比你上面要小很多很多,但是它的权重并不低。在采样的时候,大量的采样的Wikipedia,BOOK1和WebText2的数据,这样子保证你这个小批量里面有大部分的数据,它其实的质量还是很高的,但具体来说这个权重怎么来的,好像作者也没有解释的那么清楚了。
Training Process
2.3节是一个非常短小的段落来讲整个模型怎么训练的,这个又是这篇文章不那么厚道的一个地方。GPT这个模型是非常难训练的,你要想它有接近2000亿可以学习的参数,整个模型是非常大的,你训练它的话,当然需要分布式训练,然后你需要做非常好的模型分割和数据分割。他说在一个V100 GPU的有的带宽很高的集群上训练的,这个集群来自于微软。但实际上说他用的是DGX-1的一个集群,那里面的带宽是非常非常高的,一般的人是买不起,所以他就一句话就带过了。虽然在附录B里面有讲这些东西,实际上他也没讲什么东西,就讲了一点超参数是怎么训练的这一块,如果要真的讲的话,其实很很多东西可以说。
Evaluation
2.4节是讲模型的评估。跟之前不一样,因为这个地方它不需要做微调,所以他不需要一个额外的章节说我微调是怎么做的,而是说我预行的模型好了之后,我就直接对它进行评估。在评估的时候他用的是上下文的学习,具体来说它在每个下游的任务里面,它的训练集里面采样K个样本作为你的条件,当K=0,1,或者10到100,然后它的prompt用的是answer:或者A: 。我要做分类的时候,我就把几个样本采样出来放在前面,你在前面加一个我要干什么事情。如果你是二分类的话,那么你的答案要么是two,要么是false,而不是说一个0或1。因为0或1在训练数据中出现的概率没了true和false那么高。接下来如果你的答案是一个自由的形式的话,比如说我在做问答的时候,假设你的答案是要真的给我回答一个自己编出来答案的话,那么他就采用的是Beam Search,就是跟机器翻译一样,我生成一个序列出来,然后用Beam Search去找到一个比较好答案。
Results
接下来是长达20页的结果,我们就不给大家一一的详细讲。
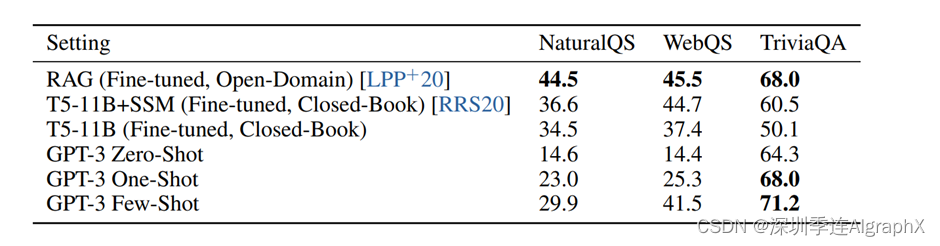
在这个地方,它讲的是一个叫做Open Domain的一个QA,就是在开放区域的一个问答.然后他对比的是T5,T5是来自于Google的一个算法,你可认为是编码器和解码器全部拿过来,BERT用的是编码器,GPT用的是解码器。T5用的是编码器,解码器都有。你如果用T5做微调的话,GPT其实你用,few shot或者是one shot它都比它要好
Limitations
在这一章里面,作者列举了非常多的局限性,我们来稍微看一下它到底是什么。首先他说虽然我们比GPT2好很多,但是我在文本生成上面,还是比较弱的,就是如果我让GPT三生成一个很长的文本的话,可能给了几段之后,他就把上面的东西重新回过来写一下。如果你想让他来帮你写小说的话,就是比较难的,因为他很难得到一个剧情的往前推,但如果你告诉他说这一段我没有讲什么的话,他很有可能能把你补全的是模式样。
第二个说,他说我有一些结构和算法上的局限性,他讲的一个主要的局限性是说GPT3因为用的是语言模型,它是往前看的,他不能像之前那样能够反过方向来看,这也是因为GPT使用的是Transformer的解码器的缘故。
然后他讲的另外一个局限是说,因为你训练是语言模型,每一次你要去预测下一个词,所以它这个地方是每一个词,它都是很均匀的去预测下一个词,它没有告诉你说哪个词比较重要,哪一个词不重要,我们知道在语言里面很多词都是一些常见词,但是没有太多意义的虚词,所以导致整个语言模型花很多时间去学习这些虚词,还不像你真的要教小孩一样的,告诉你这个是画重点,这个才是要去记住的东西。
当然他还有说,因为我用的只是文本,所以我对别的东西没见过,比如说没见过Video长什么样子,没见过真实的这些物理的交互长什么样子,因为人在学习的时候,读书只是整个人的活动中在了一块,所以他也就是在这一块做的比较好,但是别的方面他基本上是没有涉及的。
他还讲了一个是你的样本有效性不够,因为你为了训练这个模型,我基本上整把整个网络上的文章都给你下下来了,对人来讲这个真的是太可怕了。
另外一个问题,作者说也可能不叫问题,就是不确信,是说你在做这种给你多个样本在做上下文的学习的时候,他真的是去从头开始学习吗?他真的是说我去通过你给我的样本。嗯,学习的这个样本是长这样,还是说我就是根据这个样本在我之前的文本里面找出相关的,然后把它记住就行了,就认出了这个任务。这两个当然不一样,我们当然喜欢说你从头开始学这个途径,这样子的话,真的碰到一个你的虚拟样本上没有出现过的任务的话,我也能够泛化过去,如果就是我根据你的样本从我的训练记忆里面把它相关的东西找出来的话,那就真的最后拼的是你的训练数据的大小了。
另外一个跟样本有效性的相关的,就是说训练起来非常的贵。
最后一个GPT3跟很多深度学习模型一样,都是无法解释的,就是我给你一个输入,然后你反而给我一个看上去很不错的输出,但我并不知道你是怎么样得到你的输出的,你里面哪些权重真的起到作用,而且你整个决策怎么做的,特别是对GPT3那么大的模型来讲,去除里面这些做关键决策这些权重非常难的,所以我们最多能说GPT3真的就是大力出奇迹。
Broader Impacts
接下来是对GP3可能的一些影响的一些讨论,因为这个模型已经非常强大的,可以直接拿过去用了,就是说部署在生产环境里面,一旦你的部署到生产环境里面的话,那么肯定会对人会对社会产生一些影响,最简单是它是不是安全的,大家不要觉得一个模型它能够对人造成多大危害,如果你真的依赖一个模型做一些很重要的决策的话,那当然可能会带来很大的影响。
OpenAI的很多工作有这样子的讨论,我觉得是非常好的,那表示这个团队是很大的社会责任感的。
我们这里简单的给大家过一下,他首先说我这个模型可能会被用来做坏事,在6.1.1里面讲到说你有可能是散布一些不实的消息,生成一些垃圾邮件或者钓鱼邮件,然后论文造假呀,我们之前有看到他生成的那些新闻稿,真的人是很难看出来区别的,我们读新闻的话,你们对里面的数字,一些很多事情,我们通常不会下意识的去怀疑,他觉得你既然记者把它写出来,那么一定是你做过调查的,如果有人用GPT3大量的生成这样的文的话,可能会有很多会去信里面的东西,虽然现在很多这样的过滤机制,比如说你的邮箱里面会判断一部分邮件是不是垃圾邮件,但如果GPT3能够大量的生成这样子的文章的话,那么肯定是有一小部分能绕过这些机制,从而能够对人产生影响。
然后他又讲了一下公平性,偏移,比如在性别上,因为他下的文章里面很有可能里面男性这种词居多,比如说你让GPT去回答一个侦探是一个男人还是一个女人,那么GPT在很大的可能性上认为这是一个男人。接下来他调查了一下GPT对一些性别的一些偏见,作者让GPT回答he was或者she was就是男性的是怎么样的,女性会怎么样的?然后他去判断一些词出现的概率,把那些比较偏见那些词拿出来,比如说对男性来说,GPT可能生成他是比较难的,对女性来说,他很大概率会生成他是非常漂亮的就漂亮这个词不是一个贬义词,但是漂亮意味着是说你对女性的外表比较在意,这是一个偏见。
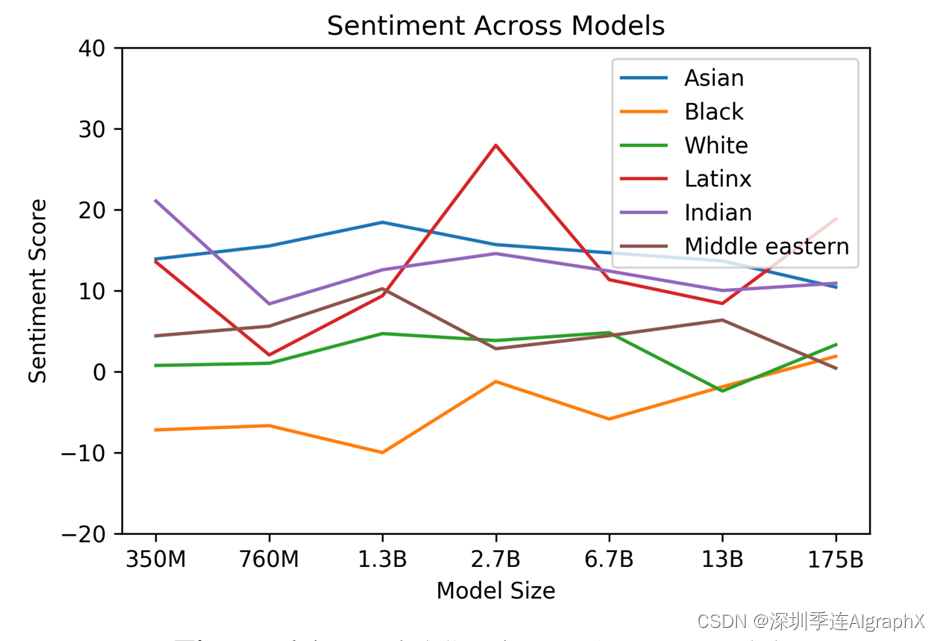
第二个是对种族,比如说这一个,女人非常的什么,你可以换成白的,黄的、黑的,然后下面这个图表示的是不同大小模型对不同种族的一些正面还是负面的评价,这里零表示的是正常,正的是表示的是对这个种族比较正面的反馈,负数是表示比较负面的,对于黑人就是这一根线相对来说比较负面的,但是对于A神整体来说是比较正面的。虽然作为亚洲人看到这个结果可能会比较开心,但是当你发现一个模型对于不同种族的区别有那么大的时候,你可要注意到说可能换一个模型,那个模型可能是仇视亚洲人的。
第三个问题,宗教,宗教之间相互歧视也是非常严重的。
最后一点关于的是能耗,因为训练GPT模型,需要几百台机器训练很多天,那么一台机器那么就是几千瓦的能耗的话,那么训练下来你的能耗也是相当夸张的。
最后是他的结论,他说我们做了一个有1750亿参数的语言模型,然后在许多的NLP的任务上面,我们做了zero short, one shot,few shot的学习,在很多情况下,它能够媲美到使用更多带标号数据的基于微调的算法,然后它的一个卖点是能够生成高质量的一些文本,让他们展示的一个不用基于微调的一个可能性。然后我们对整个GPT,GPT2,GPT3这三个工作做一个评论,你可认为GPT是起了一个大早,他先把Transformer这个模型拿过来做预训练,然后证明它在效果上很好。但是没想到在选择路线上,二选一的时候选了一条路,但是没想到另外一条路走的更容易点,也就是BERT和他之后的工作。但作者没有气馁,因为我有钱,我有人,所以我一条路走到黑,GPT2就是把模型做的更大,然后尝试一个更难的问题,就是不在下一个任务上做微调。如果你发现你还是打不赢的话怎么办?那就再摇人吧,然后再准备一点钱,我做一个更大的100更大的模型出来,所以最后GPT3扳回一局。不管怎么样,GPT系列让大家发现语言模型是可以大力出奇迹的。
摘录
https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
https://arxiv.org/pdf/2005.14165.pdf
https://www.bilibili.com/video/BV1AF411b7xQ/?spm_id_from=333.788&vd_source=7ce32e2fa9e7851d00b27b5361f5ff05
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 搭建本地的pip镜像源
- 【Web_接口测试_爬虫练习】豆瓣电影250,request+pyquery
- ITSS内幕揭秘!不看后悔!
- 稀疏矩阵的三元组表示----(算法详解)
- 力扣题目学习笔记(OC + Swift)16. 最接近的三数之和
- 【【手把手教你从SD卡驱动VDMA显示图片实验】】
- 社科院与新加坡新跃社科联合培养博士—为什么读博?利弊是什么?
- 【python学习】面向对象编程3
- MATLAB数据处理: 每种样本类型随机抽样
- 数据库MySQL——基础篇二