现代密码学 考点汇总(上)
现代密码学 考点汇总(上)
写在最前面
字数超了,只能分为为两部分
很好,完美避开所有考点
考试范围
一、给一个简单的方案,判断是否cca安全
判断方式:要么证明是cca安全(通过规约),要么找一个攻击方式去攻击
一样一个题
1、对称加密、
2、消息认证码MAC
3、哈希函数、
4、非对称的多样加密的方案
【数字签名不考,因为和mac功能和证明方式、实验都类似】
二、随机预言机模型之下的简单应用
随机预言机性质、随机预言机模型之下的简单应用
性质之下构造函数的性质
笔记汇总
0. 规约证明

-
规约证明
- 我们现在站在敌手的角色来思考,希望解决“破解”加密方案这个问题,并且在此之前我们已经知道有个一“假设”问题是不可解决的;
- 为了证明一个加密方案 Π \Pi Π在假设 X X X下是安全的,就是证明“破解”问题不可解。
- 将解决“假设” X X X问题的算法 A ′ \mathcal{A}' A′规约到“破解” Π \Pi Π的算法 A \mathcal{A} A。如果加密方案可以被破解,则假设问题也可以解决。然而,由于假设问题是难以解决的,这导致矛盾,说明加密方案不可以被破解。
- 先令一个概率多项式时间的算法 A \mathcal{A} A能够以概率 ε ( n ) \varepsilon(n) ε(n)破解 Π \Pi Π ;
- 假设:一个问题 X X X是难以解决的,即不存在多项式时间算法来解决 X X X; A ′ \mathcal{A}' A′是一个解决 X X X的概率算法;
- 规约:解决假设问题 X X X可以通过破解加密方案 Π \Pi Π,即将 A ′ \mathcal{A}' A′规约到 A \mathcal{A} A, A ′ \mathcal{A}' A′通过以 A \mathcal{A} A作为子函数可以以概率 1 / p ( n ) 1/p(n) 1/p(n)有效地解决问题 X X X;
- 矛盾:若加密方案可以被有效破解,即 ε ( n ) \varepsilon(n) ε(n)是不可忽略的,则 A ′ \mathcal{A}' A′可以以不可忽略的概率 ε ( n ) / p ( n ) \varepsilon(n)/p(n) ε(n)/p(n)解决问题 X X X,这与假设矛盾,因而 ε ( n ) \varepsilon(n) ε(n)一定是可忽略的。
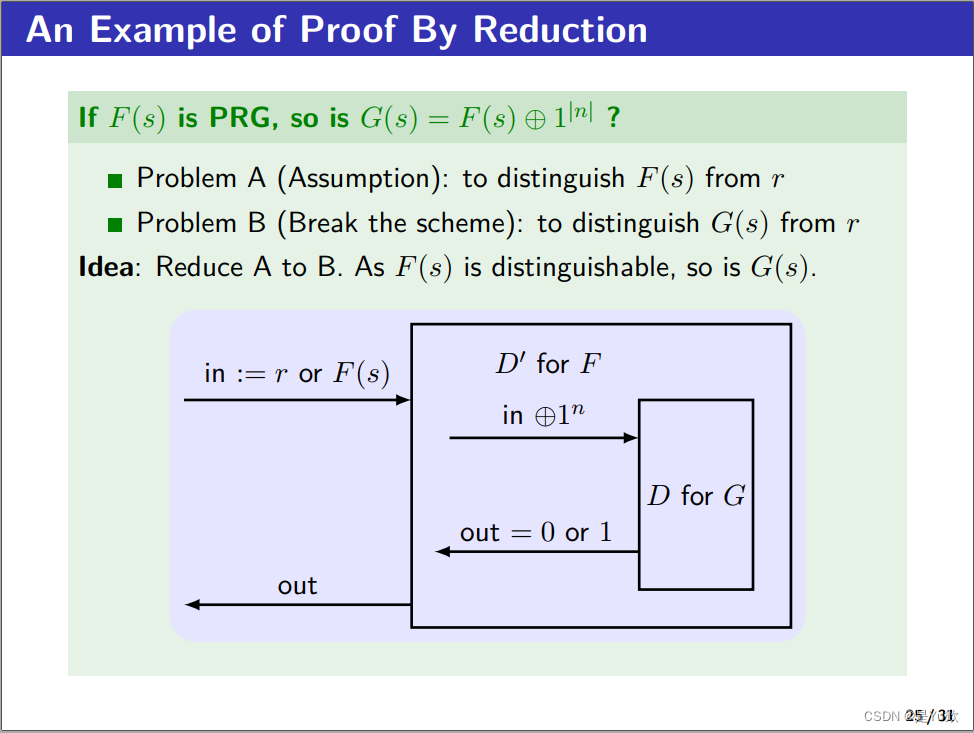
一个规约法证明PRG(伪随机生成器)的例子
-
一个规约法证明PRG的例子
-
假设 F F F是PRG,证明 G G G也是PRG。
-
问题A:如何区分 F F F;问题B:如何区分 G G G;
-
从A规约到B:区分 F F F的算法输入按位取反后作为区分 G G G的算法输入,区分 G G G的算法输出作为区分 F F F的算法输出。
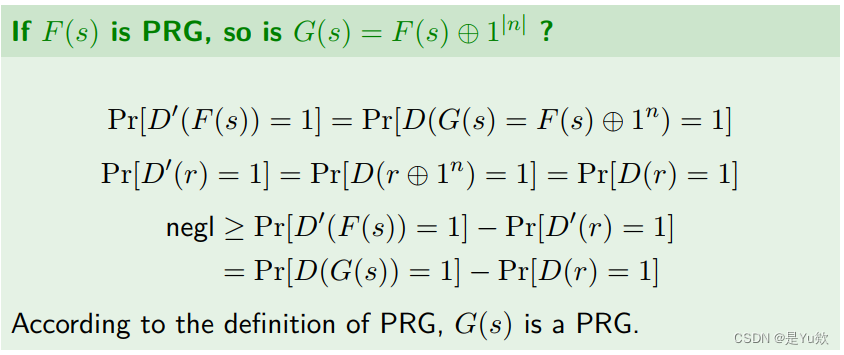
-
由此,建立了不可区分定义中概率的联系。
-
定长加密方案,并证明不可区分加密方案
-
一个安全的定长加密方案
- ∣ G ( k ) ∣ = ? ( ∣ k ∣ ) |G(k)| = \ell(|k|) ∣G(k)∣=?(∣k∣), m ∈ { 0 , 1 } ? ( n ) m \in \{0,1\}^{\ell(n)} m∈{0,1}?(n), 一个PRG以长度为 n n n的密钥作为种子,输出与明文相同长度的pad;
- G e n \mathsf{Gen} Gen: k ∈ { 0 , 1 } n k \in \{0,1\}^n k∈{0,1}n,密钥作为种子,长度小于明文长度;
- E n c \mathsf{Enc} Enc: c : = G ( k ) ⊕ m c := G(k)\oplus m c:=G(k)⊕m,加密方法和一次一密一样;
- D e c \mathsf{Dec} Dec: m : = G ( k ) ⊕ c m := G(k)\oplus c m:=G(k)⊕c,解密也是;
- 定理:该定长加密方案是窃听下不可区分的。
- 直觉上,这个方案和一次一密是类似的,除了密钥更短并且用伪随机生成器生成的比特串来与明文异或。因为伪随机对于任何敌手都可以认为是真随机,所以对于敌手而言,该方案与一次一密是一样的。由此,我们得到了一个安全的加密方案,同时避免了一次一密的最大局限性——密钥过长。
-
证明不可区分加密方案
- 思路:区分伪随机性为难题假设,破解加密方案为规约的子函数。针对伪随机生成器 G G G的区分器 D D D以 A \mathcal{A} A为子函数,使得当 A \mathcal{A} A破解了 Π \Pi Π则 D D D可以区分出 G G G,与 G G G的伪随机性矛盾。注意这里我们用了符号 Π ~ \tilde{\Pi} Π~来表示 Π \Pi Π的一个变体,来刻画加密方案中可能使用了真随机串来加密;
- 回顾针对伪随机生成器的区分器 D D D的问题是,输入一个串 w w w,输出一个比特;这里关键问题是输出的比特从何而来?
- 将
D
D
D规约到
A
\mathcal{A}
A。回顾窃听者不可区分实验中,
A
\mathcal{A}
A与一个挑战者进行3轮交互:
- A \mathcal{A} A选择两个不同明文 m 0 , m 1 m_0, m_1 m0?,m1?,并发送给挑战者;
- 挑战者生成密钥,并随机挑选一个明文 m b m_b mb?加密后得到挑战密文 c c c,并发送给 A \mathcal{A} A;
- A \mathcal{A} A输出对所加密明文的猜测 b ′ b' b′,若 b = b ′ b=b' b=b′,则 A \mathcal{A} A成功;否则,失败;
- 区分器
D
D
D成为窃听不可区分实验中的挑战者,特别之处在于:在第2步,不需要生成密钥,而是直接以输入串
w
w
w作为pad来加密,
c
:
=
w
⊕
m
b
c := w \oplus m_b
c:=w⊕mb?;根据
w
w
w的两种可能,分两种情况:
- 当 w w w是由 G G G生成的,即伪随机串,则 c c c就是加密方案 Π \Pi Π中密文, A \mathcal{A} A面对的就是 Π \Pi Π;
- 当 w w w是真随机串,则 c c c不同于加密方案 Π \Pi Π中密文,而与一次一密中一样, A \mathcal{A} A面对的就是 Π ~ \tilde{\Pi} Π~一次一密;
- 回答前面关于 D D D输出什么的问题:破解加密方案的 A \mathcal{A} A成功时, D D D输出1;否则, D D D输出0。
-
证明不可区分加密方案(续)
- 规约完毕,证明
A
\mathcal{A}
A在实验中成功的概率是可忽略的
- 当 w w w为真随机串 r r r,就是一次一密, Pr ? [ D ( r ) = 1 ] = Pr ? [ P r i v K A , Π ~ e a v ( n ) = 1 ] = 1 2 \Pr[D(r)=1] = \Pr[\mathsf{PrivK}^{\mathsf{eav}}_{\mathcal{A},\tilde{\Pi}}(n)=1]=\frac{1}{2} Pr[D(r)=1]=Pr[PrivKA,Π~eav?(n)=1]=21?;
- 当 w w w为伪随机串 G ( k ) G(k) G(k), Pr ? [ D ( G ( k ) ) = 1 ] = Pr ? [ P r i v K A , Π e a v ( n ) = 1 ] = 1 2 + ε ( n ) \Pr[D(G(k))=1] = \Pr[\mathsf{PrivK}^{\mathsf{eav}}_{\mathcal{A},\Pi}(n)=1] = \frac{1}{2} + \varepsilon(n) Pr[D(G(k))=1]=Pr[PrivKA,Πeav?(n)=1]=21?+ε(n);
- 根据伪随机生成器定义,上下两个公式相减, ∣ Pr ? [ D ( r ) = 1 ] ? Pr ? [ D ( G ( k ) ) = 1 ] ∣ = ε ( n ) ≤ n e g l ( n ) \left|\Pr[D(r)=1] - \Pr[D(G(k))=1]\right| = \varepsilon(n) \le \mathsf{negl}(n) ∣Pr[D(r)=1]?Pr[D(G(k))=1]∣=ε(n)≤negl(n);
- 所以 ε ( n ) \varepsilon(n) ε(n)是可忽略的,即 Π \Pi Π是窃听者不可区分的。
- 小结:通过规约将 A \mathcal{A} A的不可区分实验成功的概率与 D D D的区分器实验输出1的概率建立等式;分析输入真随机串时 D D D输出1的概率(即不可区分实验成功概率)是1/2;根据PRG的定义,输入伪随机串时 D D D输出1的概率(1/2+ ε ( n ) \varepsilon(n) ε(n))与输入真随机串时 D D D输出1的概率(1/2)的差异时可忽略的。
- 规约完毕,证明
A
\mathcal{A}
A在实验中成功的概率是可忽略的
CCA安全加密方案
-
选择密文攻击 Chosen-Ciphertext Attacks (CCA)
-
CCA不可区分实验 P r i v K A , Π c c a ( n ) \mathsf{PrivK}^{\mathsf{cca}}_{\mathcal{A},\Pi}(n) PrivKA,Πcca?(n):
- 挑战者生成密钥 k ← G e n ( 1 n ) k \gets \mathsf{Gen}(1^n) k←Gen(1n);(为了下一步的预言机)
- A \mathcal{A} A 被给予输入 1 n 1^n 1n 和对加密函数 E n c k ( ? ) \mathsf{Enc}_k(\cdot) Enck?(?)和解密函数 D e c k ( ? ) \mathsf{Dec}_k(\cdot) Deck?(?)的预言机访问(oracle access) A E n c k ( ? ) \mathcal{A}^{\mathsf{Enc}_k(\cdot)} AEnck?(?) 和 A D e c k ( ? ) \mathcal{A}^{\mathsf{Dec}_k(\cdot)} ADeck?(?),输出相同长度 m 0 , m 1 m_0, m_1 m0?,m1? ;
- 挑战者生成随机比特 b ← { 0 , 1 } b \gets \{0,1\} b←{0,1},将挑战密文 c ← E n c k ( m b ) c \gets \mathsf{Enc}_k(m_b) c←Enck?(mb?) 发送给 A \mathcal{A} A;
- A \mathcal{A} A 继续对除了挑战密文 c c c之外的预言机的访问,输出 b ′ b' b′;如果 b ′ = b b' = b b′=b,则 A \mathcal{A} A成功 P r i v K A , Π c c a = 1 \mathsf{PrivK}^{\mathsf{cca}}_{\mathcal{A},\Pi}=1 PrivKA,Πcca?=1,否则 0。
定义:一个加密方案是CCA安全的,如果实验成功的概率与1/2的差异是可忽略的。
-
-
理解CCA安全
-
在现实世界中,敌手可以通过影响被解密的内容来实施CCA。如果通信没有认证,那么敌手可以以通信参与方的身份来发送特定密文。
-
CCA安全性意味着“non-malleability”(不可锻造性,即改变但不毁坏),不能修改密文来获得新的有效密文。
-
之前的方案中没有CCA安全,因为都不是不可锻造。
-
对基于PRF的CPA安全加密方案的CCA攻击:
-
A \mathcal{A} A 获得挑战密文 c = < r , F k ( r ) ⊕ m b > c = \left<r, F_k(r)\oplus m_{b}\right> c=?r,Fk?(r)⊕mb??,并且查询与 c c c只相差了一个翻转的比特的密文 c ′ c' c′,那么
m ′ = c ′ ⊕ F k ( r ) m' = c' \oplus F_k(r) m′=c′⊕Fk?(r) 应该与 m b m_{b} mb? 除了什么之外都相同?(见下方补充)
-
-
问题:上述操作模式也不是CCA安全的(作业)
-
由此,可以总结出CCA下敌手的常用策略:
- 修改挑战密文 c c c为 c ′ c' c′,并查询解密预言机得到 m ′ m' m′
- 根据关系,由 m ′ m' m′来猜测被加密明文 m b m_b mb?
-
补充
在这个情况下, A \mathcal{A} A 获得了挑战密文 c = < r , F k ( r ) ⊕ m b > c = \left<r, F_k(r)\oplus m_{b}\right> c=?r,Fk?(r)⊕mb?? 并查询了一个只在一个比特上与 c c c 不同的密文 c ′ c' c′。我们来分析一下 m ′ = c ′ ⊕ F k ( r ) m' = c' \oplus F_k(r) m′=c′⊕Fk?(r) 与 m b m_{b} mb? 的关系。
首先,我们明确 c c c 的构成:
- c c c 包含两个部分:一个随机数 r r r 和使用密钥 k k k 的函数 F k ( r ) F_k(r) Fk?(r) 与明文 m b m_{b} mb? 的异或结果。
- 因此, c = < r , F k ( r ) ⊕ m b > c = \left<r, F_k(r)\oplus m_{b}\right> c=?r,Fk?(r)⊕mb??。
现在,如果 A \mathcal{A} A 查询了一个与 c c c 只在一个比特上不同的密文 c ′ c' c′,那么 c ′ c' c′ 也可以写成两部分,但其中一部分与 c c c 有一个比特的差异。这个差异可以在 r r r 部分,也可以在 F k ( r ) ⊕ m b F_k(r)\oplus m_{b} Fk?(r)⊕mb? 部分。
当 A \mathcal{A} A 计算 m ′ = c ′ ⊕ F k ( r ) m' = c' \oplus F_k(r) m′=c′⊕Fk?(r) 时,他们实际上是在解开 F k ( r ) ⊕ m b F_k(r)\oplus m_{b} Fk?(r)⊕mb? 的异或操作。这是因为异或操作是可逆的,且当两次使用相同的值时会取消彼此的效果(即 A ⊕ B ⊕ B = A A \oplus B \oplus B = A A⊕B⊕B=A)。
因此,如果 c ′ c' c′ 的变化发生在 F k ( r ) F_k(r) Fk?(r) 部分,则 m ′ m' m′ 将与 m b m_{b} mb? 完全相同,因为 F k ( r ) F_k(r) Fk?(r) 部分的变化被异或操作取消了。但如果变化发生在 r r r 部分,则这个变化不会影响到 F k ( r ) ⊕ m b F_k(r)\oplus m_{b} Fk?(r)⊕mb? 部分,因此 m ′ m' m′ 将与 m b m_{b} mb? 在一个比特上不同。
综上所述, m ′ m' m′ 与 m b m_{b} mb? 将在以下方面相同:
- 如果变化发生在 F k ( r ) F_k(r) Fk?(r) 部分,那么 m ′ m' m′ 与 m b m_{b} mb? 完全相同。
- 如果变化发生在 r r r 部分,那么 m ′ m' m′ 与 m b m_{b} mb? 除了那个翻转的比特之外都相同。
1. 对称加密
CPA安全实验、预言机访问(oracle access)
-
CPA安全实验
- CPA不可区分实验
P
r
i
v
K
A
,
Π
c
p
a
(
n
)
\mathsf{PrivK}^{\mathsf{cpa}}_{\mathcal{A},\Pi}(n)
PrivKA,Πcpa?(n):
- 挑战者生成密钥 k ← G e n ( 1 n ) k \gets \mathsf{Gen}(1^n) k←Gen(1n);(这里与窃听者不可区分实验相比,密钥的生成提前了,这是为了下一步提供加密预言机)
- A \mathcal{A} A 被给予输入 1 n 1^n 1n 和对加密函数 E n c k ( ? ) \mathsf{Enc}_k(\cdot) Enck?(?)的预言机访问(oracle access) A E n c k ( ? ) \mathcal{A}^{\mathsf{Enc}_k(\cdot)} AEnck?(?) ,输出相同长度 m 0 , m 1 m_0, m_1 m0?,m1? ;
- 挑战者生成随机比特 b ← { 0 , 1 } b \gets \{0,1\} b←{0,1},将挑战密文 c ← E n c k ( m b ) c \gets \mathsf{Enc}_k(m_b) c←Enck?(mb?) 发送给 A \mathcal{A} A;
- A \mathcal{A} A 继续对 E n c k ( ? ) \mathsf{Enc}_k(\cdot) Enck?(?)的预言机的访问,输出 b ′ b' b′;如果 b ′ = b b' = b b′=b,则 A \mathcal{A} A成功 P r i v K A , Π c p a = 1 \mathsf{PrivK}^{\mathsf{cpa}}_{\mathcal{A},\Pi}=1 PrivKA,Πcpa?=1,否则 0。
- 敌手对加密函数预言机访问是指,敌手以任意明文作为输入,可以从预言机得到对应密文。此处,密钥是已经提前生成的,因此才能通过加密函数预研机得到密文,但仍对敌手保密。
预言机是一个形象的比喻,它是一个黑盒,只接收输入并返回输出;访问者不需要了解其内部构造。 - 该实验与窃听者不可区分实验的区别在于,敌手可访问加密预言机,在实验过程中始终可以,包括在产生两个明文阶段,以及在收到挑战密文后猜测被加密明文阶段,获得任意明文被同一密钥加密的密文;而且密文是逐个获得,可以根据之前的明文和密文对来“适应性地”构造新的查询。
- CPA敌手比多重加密的敌手更“强大”,因为多重加密敌手是可以一次性地获得一组密文,而CPA敌手可以根据已经获得的明文和密文“多次适应性地”再次获得密文。
- CPA不可区分实验
P
r
i
v
K
A
,
Π
c
p
a
(
n
)
\mathsf{PrivK}^{\mathsf{cpa}}_{\mathcal{A},\Pi}(n)
PrivKA,Πcpa?(n):
-
CPA安全
-
Π \Pi Π 是CPA不可区分加密方案 (CPA安全的),如果任意概率多项式时间算法 A \mathcal{A} A,存在可忽略的函数 n e g l \mathsf{negl} negl使得,
Pr ? [ P r i v K A , Π c p a ( n ) = 1 ] ≤ 1 2 + n e g l ( n ) \Pr\left[\mathsf{PrivK}^{\mathsf{cpa}}_{\mathcal{A},\Pi}(n)=1\right] \le \frac{1}{2} + \mathsf{negl}(n) Pr[PrivKA,Πcpa?(n)=1]≤21?+negl(n)
-
定理:CPA安全也是多重加密安全的。证明略。直觉上,CPA敌手比多重加密敌手更强大。
-
之前的方案也难以实现CPA安全;
-
多重加密安全意味着CPA安全?(作业)显然是否定的。那么,思考两种安全定义的区别成为解题的关键。
-
操作模式
伪随机函数PRF
-
伪随机函数(Pseudorandom Function)概念
- 为了实现CPA安全,之前的PRG提供的随机性不够用了,需要新的数学工具为加密提供额外的随机性。为此引入伪随机函数(PRF),是对伪PRG的泛化:PRG从一个种子生成一个随机串,PRF从一个key生成一个函数;
- 带密钥的函数Keyed function
F
:
{
0
,
1
}
?
×
{
0
,
1
}
?
→
{
0
,
1
}
?
F : \{0,1\}^* \times \{0,1\}^* \to \{0,1\}^*
F:{0,1}?×{0,1}?→{0,1}?
- F k : { 0 , 1 } ? → { 0 , 1 } ? F_k : \{0,1\}^* \to \{0,1\}^* Fk?:{0,1}?→{0,1}?, F k ( x ) = def F ( k , x ) F_k(x) \overset{\text{def}}{=} F(k,x) Fk?(x)=defF(k,x)
- 两个输入到一个输出,看上去像,但不是加密函数;输入key,得到一个一输入到一输出的函数;
- 查表Look-up table
f
f
f:
{
0
,
1
}
n
→
{
0
,
1
}
n
\{0,1\}^n \to \{0,1\}^n
{0,1}n→{0,1}n 需要多少比特信息存储?
- 查表是一个直接描述输入与输出间映射的表格,一个条目对应一个输入与一个输出;当该映射是随机产生的,是一个真随机函数;
- 函数族Function family
F
u
n
c
n
\mathsf{Func}_n
Funcn?: 包含所有函数
{
0
,
1
}
n
→
{
0
,
1
}
n
\{0,1\}^n \to \{0,1\}^n
{0,1}n→{0,1}n.
∣
F
u
n
c
n
∣
=
2
n
?
2
n
|\mathsf{Func}_n| = 2^{n\cdot2^n}
∣Funcn?∣=2n?2n
- 一个PRF是函数族中一个子集,key确定下的PRF是函数族中一个元素,一个查表是函数族中一个元素;
- 长度保留Length Preserving: ? k e y ( n ) = ? i n ( n ) = ? o u t ( n ) = n \ell_{key}(n) = \ell_{in}(n) = \ell_{out}(n) = n ?key?(n)=?in?(n)=?out?(n)=n;密钥长度与函数输入、输出长度相同为 n n n;没有特殊说明时,只讨论长度保留的函数;
-
伪随机函数定义
- 直觉上,一个PRF生成的带密钥的函数与从函数族中随机选择的真随机函数(查表)之间是不可区分的;然而,一个真随机函数具有指数长度,无法“预先生成”,只能“on-the-fly”(边运行、边生成)的使用,引入一个对函数 O \mathcal{O} O的确定性的预言机访问(oracle access) D O D^\mathcal{O} DO。
- 这里的预言机是一个抽象的函数。访问预言机,就是给出任意输入,得到该函数的输出。访问预言机的能力不包括了解正在访问的预言机具体内部构造。
- 一个带密钥的函数是一个伪随机函数(PRF),对任意PPT区分器
D
D
D,
∣
Pr
?
[
D
F
k
(
?
)
(
1
n
)
=
1
]
?
Pr
?
[
D
f
(
?
)
(
1
n
)
=
1
]
∣
≤
n
e
g
l
(
n
)
\left|\Pr[D^{F_k(\cdot)}(1^n)=1] - \Pr[D^{f(\cdot)}(1^n)=1]\right| \le \mathsf{negl}(n)
?Pr[DFk?(?)(1n)=1]?Pr[Df(?)(1n)=1]
?≤negl(n),其中
f
f
f是
F
u
n
c
n
\mathsf{Func}_n
Funcn?中随机函数。
- 这里区分器 D D D是一个算法,可以访问预言机,但并不知道预言机背后是什么。
- 这里不可区分性关键是,对真随机查表和伪随机函数,区分器输出相同结果概率的差异。区分器输出1或0本身没有,也无需,有特定语义。
- PRF和PRG的关系在后面会学习,可以由PRG来构造PRF。
PRF例题:一个固定长度的一次一密方案是一个PRF吗?
-
PRF例题
- 问题一个固定长度的一次一密方案是一个PRF吗?
- 对于一个PRF,在密钥保密和没有预言机访问时,给指定输入,能以不可忽略的概率猜测输出相关信息吗?
- 如果是PRF,则给出该函数与查表的相似性;否则,给出一个区分器可以区分出该函数不是随机的。
-
以PRF实现CPA安全
- 新随机串 r r r,每次新生成一个随机串;
- F k ( r ) F_k(r) Fk?(r): ∣ k ∣ = ∣ m ∣ = ∣ r ∣ = n |k| = |m| = |r| = n ∣k∣=∣m∣=∣r∣=n. 长度保留;
- G e n \mathsf{Gen} Gen: k ∈ { 0 , 1 } n k \in \{0,1\}^n k∈{0,1}n.
- E n c \mathsf{Enc} Enc: s : = F k ( r ) ⊕ m s := F_k(r)\oplus m s:=Fk?(r)⊕m, c : = < r , s > c := \left<r, s\right> c:=?r,s?. 密文包括两部分新随机串,以及异或输出;
- D e c \mathsf{Dec} Dec: m : = F k ( r ) ⊕ s m := F_k(r)\oplus s m:=Fk?(r)⊕s.
- 定理:上述方案是CPA安全的。
从PRF到CPA安全的证明
-
从PRF到CPA安全的证明
- 思路:从PRF的区分器算法 D \mathcal{D} D规约到加密方案敌手算法 A \mathcal{A} A,区分器 D \mathcal{D} D作为敌手 A \mathcal{A} A的挑战者,敌手 A \mathcal{A} A实验成功时区分器 D \mathcal{D} D输出1。分两种情况,当输入真随机函数 f f f时,相当于一次一密;当输入伪随机函数 F k F_k Fk?时,为加密方案。
- 规约:
D
\mathcal{D}
D输入预言机,输出一个比特;
A
\mathcal{A}
A的加密预言机访问通过
D
\mathcal{D}
D的预言机
O
\mathcal{O}
O来提供,
c
:
=
<
r
,
O
(
r
)
⊕
m
>
c := \left<r, \mathcal{O}(r) \oplus m \right>
c:=?r,O(r)⊕m?;
D
\mathcal{D}
D输出1,当
A
\mathcal{A}
A在实验中成功。
- 这里有两个预言机: D \mathcal{D} D访问的预言机 O \mathcal{O} O, A \mathcal{A} A访问的加密预言机 E n c k \mathsf{Enc}_k Enck?,后者不能直接访问前者的预言机。
-
从PRF到CPA安全的证明(续)
-
考虑真随机函数 f f f的情况,分析不可区分实验成功概率 Pr ? [ P r i v K A , Π ~ c p a ( n ) = 1 ] = Pr ? [ B r e a k ] \Pr[\mathsf{PrivK}_{\mathcal{A},\tilde{\Pi}}^{\mathsf{cpa}}(n) = 1] = \Pr[\mathsf{Break}] Pr[PrivKA,Π~cpa?(n)=1]=Pr[Break]。敌手 A \mathcal{A} A访问加密预言机可以获得多项式 q ( n ) q(n) q(n)个明文与密文对的查询结果并得到随机串和pad { < r i , f ( r i ) > } \{ \left< r_i, f(r_i) \right> \} {?ri?,f(ri?)?};当收到挑战密文 c = < r c , s : = f ( r c ) ⊕ m b > c=\left<r_c, s:=f(r_c)\oplus m_b\right> c=?rc?,s:=f(rc?)⊕mb??时,根据之前查询结果中随机串是否与挑战密文中随机串相同,分为两种情况:
- 当有相同随机串时,根据 r r r可以得到 f ( r c ) f(r_c) f(rc?), m b = f ( r c ) ⊕ s m_b=f(r_c)\oplus s mb?=f(rc?)⊕s,但这种情况发生的概率 q ( n ) / 2 n q(n)/2^n q(n)/2n是可忽略的;
- 当没有相同随机串时,输出是随机串,相当于一次一密,成功概率=1/2;
-
Pr ? [ D F k ( ? ) ( 1 n ) = 1 ] = Pr ? [ P r i v K A , Π c p a ( n ) = 1 ] = 1 2 + ε ( n ) . \Pr[D^{F_k(\cdot)}(1^n)=1] = \Pr[\mathsf{PrivK}_{\mathcal{A},\Pi}^{\mathsf{cpa}}(n) = 1] = \frac{1}{2} + \varepsilon(n). Pr[DFk?(?)(1n)=1]=Pr[PrivKA,Πcpa?(n)=1]=21?+ε(n).
-
Pr ? [ D f ( ? ) ( 1 n ) = 1 ] = Pr ? [ P r i v K A , Π ~ c p a ( n ) = 1 ] = Pr ? [ B r e a k ] ≤ 1 2 + q ( n ) 2 n . \Pr[D^{f(\cdot)}(1^n)=1] = \Pr[\mathsf{PrivK}_{\mathcal{A},\tilde{\Pi}}^{\mathsf{cpa}}(n) = 1] = \Pr[\mathsf{Break}] \le \frac{1}{2} + \frac{q(n)}{2^n}. Pr[Df(?)(1n)=1]=Pr[PrivKA,Π~cpa?(n)=1]=Pr[Break]≤21?+2nq(n)?.
-
Pr ? [ D F k ( ? ) ( 1 n ) = 1 ] ? Pr ? [ D f ( ? ) ( 1 n ) = 1 ] ≥ ε ( n ) ? q ( n ) 2 n . \Pr[D^{F_k(\cdot)}(1^n)=1] - \Pr[D^{f(\cdot)}(1^n)=1] \ge \varepsilon(n) - \frac{q(n)}{2^n}. Pr[DFk?(?)(1n)=1]?Pr[Df(?)(1n)=1]≥ε(n)?2nq(n)?. 根据伪随机函数定义, ε ( n ) \varepsilon(n) ε(n) 是可忽略的.
-
小结:通过规约将 A \mathcal{A} A的不可区分实验成功的概率与 D D D的区分器实验输出1的概率建立等式;分析输入真随机函数预言机时 D D D输出1的概率(即不可区分实验成功概率)是1/2+一个可忽略函数;根据PRF的定义,输入伪随机函数预言机时 D D D输出1的概率(1/2+ ε ( n ) \varepsilon(n) ε(n))与输入真随机函数预言机时 D D D输出1的概率(1/2)的差异时可忽略的。
-
-
CPA安全例题
- E n c k ( m ) = P R G ( k ∥ r ) ⊕ m \mathsf{Enc}_k(m) = PRG(k\|r) \oplus m Enck?(m)=PRG(k∥r)⊕m, r r r 是新的随机串。这是CPA安全的吗?
- 从PRF到CPA安全:变长消息
- 对于任意长度消息 m = m 1 , … , m ? m = m_1, \dots , m_{\ell} m=m1?,…,m??, c : = < r 1 , F k ( r 1 ) ⊕ m 1 , r 2 , F k ( r 2 ) ⊕ m 2 , … , r ? , F k ( r ? ) ⊕ m ? > c := \left< r_1, F_k(r_1) \oplus m_1, r_2, F_k(r_2) \oplus m_2, \dots, r_\ell, F_k(r_\ell) \oplus m_\ell\right> c:=?r1?,Fk?(r1?)⊕m1?,r2?,Fk?(r2?)⊕m2?,…,r??,Fk?(r??)⊕m???
- 推论:如果 F F F是一个 PRF,那么 Π \Pi Π 对任意长度消息是 CPA 安全的。
- 问题:这个方案有什么缺点?
- 有效性: ∣ c ∣ = 2 ∣ m ∣ |c| = 2|m| ∣c∣=2∣m∣. 密文长度是明文长度的二倍,并且需要大量的真随机串。
伪随机排列PRP
-
伪随机排列(Pseudorandom Permutations)
-
为了提高对任意长度消息加密的效率,以及更高级的加密基础工具,学习伪随机排列PRP的概念;
-
双射 Bijection: F F F 是一到一的(一个输入对应一个唯一输出)且满射(覆盖输出集中每个元素);
-
排列 Permutation: 一个从一个集合到自身的双射函数;
-
带密钥的排列 Keyed permutation: ? k , F k ( ? ) \forall k, F_k(\cdot) ?k,Fk?(?)是排列;类似带密钥的函数;
-
F F F 是一个双射 ?? ? ?? F ? 1 \iff F^{-1} ?F?1 是一个双射;函数和逆函数都是双射;
-
定义:一个有效的带密钥的排列 F F F 是PRP,如果对于任意PPT的区分器 D D D,
∣ Pr ? [ D F k ( ? ) , F k ? 1 ( ? ) ( 1 n ) = 1 ] ? Pr ? [ D f ( ? ) , f ? 1 ( ? ) ( 1 n ) = 1 ] ∣ ≤ n e g l ( n ) \left|\Pr[D^{F_k(\cdot),F_k^{-1}(\cdot)}(1^n)=1] - \Pr[D^{f(\cdot),f^{-1}(\cdot)}(1^n)=1]\right| \le \mathsf{negl}(n) ?Pr[DFk?(?),Fk?1?(?)(1n)=1]?Pr[Df(?),f?1(?)(1n)=1] ?≤negl(n)
-
问题:一个PRP也是一个PRF吗?
-
-
PRP例题
- 对1比特的PRP、PRF的分析;
- 交换引理:如果
F
F
F 是一个 PRP 并且
?
i
n
(
n
)
≥
n
\ell_{in} (n) \ge n
?in?(n)≥n,那么
F
F
F 也是一个 PRF。
- 一个随机排列和一个查表是不可取分的,PRP和随机排列不可取分,因此,PRP和查表是不可取分的。
-
操作模式概念(Modes of Operation)
- 操作模式是使用PRP或PRF来加密任意长度消息的方法;
- 操作模式是从PRP或PRF来构造一个PRG的方法;
- 将一个消息分成若干等长的块(分组,block),每个块以相似方式处理;
-
Electronic Code Book (ECB) 模式
- 在窃听者出现时,是否是不可区分的?
- F F F 可以是任意PRF吗?
-
对ECB的攻击
- 为什么仍然可以识别企鹅?
-
Cipher Block Chaining (CBC) 模式
- I V IV IV初始向量,一个新的随机串;
- 是CPA的吗?可并行化吗?F可以是任意PRF吗?
-
Output Feedback (OFB) Mode模式
- 是CPA安全吗?可并行化吗?F可以是任意PRF吗?
-
Counter (CTR) Mode模式
- c t r ctr ctr是一个初始向量,并且逐一增加;
- 是CPA安全吗?可并行化吗?F可以是任意PRF吗?
-
CTR模式是CPA安全

-
定理:如果 F F F是一个PRF,那么随机CTR模式是CPA安全的。
-
证明:其安全性与之前基于PRF的CPA安全证明类似,从PRF的伪随机假设规约到CPA安全加密方案。其中,对 c t r ctr ctr的安全性直觉在于, c t r ctr ctr也是在加密前不可预测的,且每个块所用 c t r ctr ctr都是不同的;
-
当加密预言机是由真随机查表构成时,敌手多次访问加密预言机得到的 c t r ctr ctr序列与挑战密文的 c t r ctr ctr序列之间有重叠的概率 2 q ( n ) 2 2 n \frac{2q(n)^2}{2^n} 2n2q(n)2?是可以忽略的;若没有重叠,则相当于一次一密;
-
规约与之前证明基于PRF的CPA安全加密方案一样,证明过程也类似。
-
-
初始向量不应该可预测
- 如果 I V IV IV是可预测的,那么CBC/OFB/CTR模式不是CPA安全的。
- 为什么?(作业)
- 在SSL/TLS 1.0中的漏洞:记录 # i \#i #i的 I V IV IV是上一个记录 # ( i ? 1 ) \#(i-1) #(i?1)的密文块。
- OpenSSL中API:需要用户输入 I V IV IV,但 I V IV IV应在函数内实现。当 I V IV IV不充分随机时不安全。
-
非确定性加密
- 有三种通用的实现CPA安全的非确定性加密方法:
- 随机化的: r r r随机生成,如构造5;需要更多熵,长密文
- 有状态的: r r r为计数器,如CTR模式;需要通信双方同步计数器
- 基于Nonce的: r r r只用一次;需要保证只用一次,长密文
CCA安全加密方案
-
选择密文攻击 Chosen-Ciphertext Attacks (CCA)
-
CCA不可区分实验 P r i v K A , Π c c a ( n ) \mathsf{PrivK}^{\mathsf{cca}}_{\mathcal{A},\Pi}(n) PrivKA,Πcca?(n):
- 挑战者生成密钥 k ← G e n ( 1 n ) k \gets \mathsf{Gen}(1^n) k←Gen(1n);(为了下一步的预言机)
- A \mathcal{A} A 被给予输入 1 n 1^n 1n 和对加密函数 E n c k ( ? ) \mathsf{Enc}_k(\cdot) Enck?(?)和解密函数 D e c k ( ? ) \mathsf{Dec}_k(\cdot) Deck?(?)的预言机访问(oracle access) A E n c k ( ? ) \mathcal{A}^{\mathsf{Enc}_k(\cdot)} AEnck?(?) 和 A D e c k ( ? ) \mathcal{A}^{\mathsf{Dec}_k(\cdot)} ADeck?(?),输出相同长度 m 0 , m 1 m_0, m_1 m0?,m1? ;
- 挑战者生成随机比特 b ← { 0 , 1 } b \gets \{0,1\} b←{0,1},将挑战密文 c ← E n c k ( m b ) c \gets \mathsf{Enc}_k(m_b) c←Enck?(mb?) 发送给 A \mathcal{A} A;
- A \mathcal{A} A 继续对除了挑战密文 c c c之外的预言机的访问,输出 b ′ b' b′;如果 b ′ = b b' = b b′=b,则 A \mathcal{A} A成功 P r i v K A , Π c c a = 1 \mathsf{PrivK}^{\mathsf{cca}}_{\mathcal{A},\Pi}=1 PrivKA,Πcca?=1,否则 0。
定义:一个加密方案是CCA安全的,如果实验成功的概率与1/2的差异是可忽略的。
-
-
理解CCA安全
-
在现实世界中,敌手可以通过影响被解密的内容来实施CCA。如果通信没有认证,那么敌手可以以通信参与方的身份来发送特定密文。下一页有具体真实案例。
-
CCA安全性意味着“non-malleability”(不可锻造性,即改变但不毁坏),不能修改密文来获得新的有效密文。
-
之前的方案中没有CCA安全,因为都不是不可锻造。
-
对基于PRF的CPA安全加密方案的CCA攻击:
-
A \mathcal{A} A 获得挑战密文 c = < r , F k ( r ) ⊕ m b > c = \left<r, F_k(r)\oplus m_{b}\right> c=?r,Fk?(r)⊕mb??,并且查询与 c c c只相差了一个翻转的比特的密文 c ′ c' c′,那么
m ′ = c ′ ⊕ F k ( r ) m' = c' \oplus F_k(r) m′=c′⊕Fk?(r) 应该与 m b m_{b} mb? 除了什么之外都相同?(见下方的补充)
-
-
问题:上述操作模式也不是CCA安全的(作业)
-
由此,可以总结出CCA下敌手的常用策略:
- 修改挑战密文 c c c为 c ′ c' c′,并查询解密预言机得到 m ′ m' m′
- 根据关系,由 m ′ m' m′来猜测被加密明文 m b m_b mb?
-
补充
在这个情况下, A \mathcal{A} A 获得了挑战密文 c = < r , F k ( r ) ⊕ m b > c = \left<r, F_k(r)\oplus m_{b}\right> c=?r,Fk?(r)⊕mb?? 并查询了一个只在一个比特上与 c c c 不同的密文 c ′ c' c′。我们来分析一下 m ′ = c ′ ⊕ F k ( r ) m' = c' \oplus F_k(r) m′=c′⊕Fk?(r) 与 m b m_{b} mb? 的关系。
首先,我们明确 c c c 的构成:
- c c c 包含两个部分:一个随机数 r r r 和使用密钥 k k k 的函数 F k ( r ) F_k(r) Fk?(r) 与明文 m b m_{b} mb? 的异或结果。
- 因此, c = < r , F k ( r ) ⊕ m b > c = \left<r, F_k(r)\oplus m_{b}\right> c=?r,Fk?(r)⊕mb??。
现在,如果 A \mathcal{A} A 查询了一个与 c c c 只在一个比特上不同的密文 c ′ c' c′,那么 c ′ c' c′ 也可以写成两部分,但其中一部分与 c c c 有一个比特的差异。这个差异可以在 r r r 部分,也可以在 F k ( r ) ⊕ m b F_k(r)\oplus m_{b} Fk?(r)⊕mb? 部分。
当 A \mathcal{A} A 计算 m ′ = c ′ ⊕ F k ( r ) m' = c' \oplus F_k(r) m′=c′⊕Fk?(r) 时,他们实际上是在解开 F k ( r ) ⊕ m b F_k(r)\oplus m_{b} Fk?(r)⊕mb? 的异或操作。这是因为异或操作是可逆的,且当两次使用相同的值时会取消彼此的效果(即 A ⊕ B ⊕ B = A A \oplus B \oplus B = A A⊕B⊕B=A)。
因此,如果 c ′ c' c′ 的变化发生在 F k ( r ) F_k(r) Fk?(r) 部分,则 m ′ m' m′ 将与 m b m_{b} mb? 完全相同,因为 F k ( r ) F_k(r) Fk?(r) 部分的变化被异或操作取消了。但如果变化发生在 r r r 部分,则这个变化不会影响到 F k ( r ) ⊕ m b F_k(r)\oplus m_{b} Fk?(r)⊕mb? 部分,因此 m ′ m' m′ 将与 m b m_{b} mb? 在一个比特上不同。
综上所述, m ′ m' m′ 与 m b m_{b} mb? 将在以下方面相同:
- 如果变化发生在 F k ( r ) F_k(r) Fk?(r) 部分,那么 m ′ m' m′ 与 m b m_{b} mb? 完全相同。
- 如果变化发生在 r r r 部分,那么 m ′ m' m′ 与 m b m_{b} mb? 除了那个翻转的比特之外都相同。
填充预言机Padding-Oracle攻击真实案例
-
Padding-Oracle(填充预言机)攻击真实案例
- CAPTCHA服务商为Web网站提供验证用户是否为人类的服务。为此,一个CAPTCHA服务器与Web服务器间事先共享一个密钥
k
k
k,服务工作原理如下:
- 当Web服务器验证用户是否为人类时,生成一个消息 w w w并以 k k k加密,向用户发送一个密文 E n c k ( w ) Enc_k(w) Enck?(w);
- 用户将密文 E n c k ( w ) Enc_k(w) Enck?(w)转发给CAPTCHA服务器;(可实施填充预言机攻击)
- CAPTCHA服务器用密钥 k k k将密文解密,根据解密结果返回给用户信息:一个由 w w w生成的图像,或者坏填充错误;
- 用户根据图像获得 w w w 并将 w w w 发送给Web服务器。
- 在第2步,当恶意用户可以利用CAPTCHA服务器会返回给用户坏填充错误这一漏洞,来实施填充错误攻击。
- CAPTCHA服务商为Web网站提供验证用户是否为人类的服务。为此,一个CAPTCHA服务器与Web服务器间事先共享一个密钥
k
k
k,服务工作原理如下:
-
Padding-Oracle(填充预言机)攻击
- 在PKCS #5 padding(填充)标准中,为了将一个消息的长度“填充”到块长度的整数倍,在最后一个块中填充 b b b个字节的 b b b;必要时,添加一个哑块(dummy block,不包含消息的一个填充块)。存在一种攻击手段:当填充错误时,解密服务器返回一个“坏填充错误”,这相当于提供了一个解密预言机,最终可以获得整个明文;
- 具体攻击原理:
- 更改密文(包含 I V IV IV部分)并发送给解密服务器;
- 一旦触发了“坏填充错误”,则说明对密文的更改导致了填充部分内容的更改;否则,对密文的更改导致了原明文部分的更改;
- 通过仔细修改密文来控制填充部分,从而获得消息长度和内容。
-
填充预言机攻击:获得消息长度
- 攻击的第一步判断消息是否为空:在单个块的CBC中,通过更改
I
V
IV
IV的首个字节,攻击者能够获知是否
m
m
m是否为空。因为如果
m
m
m是空的话,更改
I
V
IV
IV首个字节将更改解密出的填充内容,解密服务器就会返回坏填充错误(1比特信息),具体分析如下:
- 如果 m m m是空的,那么明文会添加一个哑块 { b } b \{b\}^b {b}b;
- PRP的输入为 I V ⊕ { b } b IV\oplus \{b\}^b IV⊕{b}b;设 I V IV IV的首个字节为 x x x,则PRP的输入为 ( x ⊕ b ) ∥ ( { ? } b ? 1 ⊕ { b } b ? 1 ) (x \oplus b) \| (\{\cdot\}^{b-1} \oplus \{b\}^{b-1}) (x⊕b)∥({?}b?1⊕{b}b?1);
- 将 I V IV IV的首个字节从 x x x改成 y y y变为 y ∥ ( { ? } b ? 1 ) y \| (\{\cdot\}^{b-1}) y∥({?}b?1),不改变 c 1 c_1 c1?解密得到的PRP的输入不会变,而解密出的明文会改变为 ( x ⊕ y ⊕ b ) ∥ { b } b ? 1 (x \oplus y \oplus b) \| \{b\}^{b-1} (x⊕y⊕b)∥{b}b?1;
- 上述明文首个字节一定不是 b b b,这是填充格式错误,会触发服务器返回错误;
- 如果上面的尝试没有触发错误,那么说明消息非空;下一步,发现消息长度是否为1字节,方法与上一步一样,区别在于只改变 I V IV IV的第2个字节;如此继续,获得消息的长度;(作业)
- 攻击的第一步判断消息是否为空:在单个块的CBC中,通过更改
I
V
IV
IV的首个字节,攻击者能够获知是否
m
m
m是否为空。因为如果
m
m
m是空的话,更改
I
V
IV
IV首个字节将更改解密出的填充内容,解密服务器就会返回坏填充错误(1比特信息),具体分析如下:
-
填充预言机攻击:获得消息内容
- 一旦获得消息的长度,也就知道了填充的长度 b b b,采用下面的方法来获得消息的最后一个字节内容,进而获得整个消息;
- 更改密文中倒数第二块,来获得消息的最后一个字节 s s s;
- 明文的最后一个块 m l a s t = ? s ∥ { b } b m_{last} = \cdots s \| \{b\}^{b} mlast?=?s∥{b}b,密文的倒数第二个块 c l a s t ? 1 = ? t ∥ { ? } b c_{last-1} = \cdots t \| \{\cdot \}^{b} clast?1?=?t∥{?}b;
- 最后一块的PRP输入为 c l a s t ? 1 ⊕ m l a s t = ? ( s ⊕ t ) ∥ ( { b } b ⊕ { ? } b ) c_{last-1} \oplus m_{last} = \cdots (s \oplus t) \| (\{b\}^b \oplus \{\cdot \}^{b}) clast?1?⊕mlast?=?(s⊕t)∥({b}b⊕{?}b);
- 敌手更改 c l a s t ? 1 c_{last-1} clast?1? 为 c l a s t ? 1 ′ = ? u ∥ ( { ? } b ⊕ { b } b ⊕ { b + 1 } b ) c_{last-1}' = \cdots u \| (\{\cdot \}^{b} \oplus \{b\}^{b} \oplus \{b+1\}^{b}) clast?1′?=?u∥({?}b⊕{b}b⊕{b+1}b);其中, u u u是敌手猜测的某个字节;
- 解密获得最后一块明文 m l a s t ′ = c l a s t ? 1 ⊕ m l a s t ⊕ c l a s t ? 1 ′ = ? ( s ⊕ t ⊕ u ) ∥ { b + 1 } b m'_{last} = c_{last-1} \oplus m_{last} \oplus c_{last-1}' = \cdots (s \oplus t \oplus u)\| \{ b+1 \}^b mlast′?=clast?1?⊕mlast?⊕clast?1′?=?(s⊕t⊕u)∥{b+1}b;
- 如果没有返回坏填充错误,那么意味着填充了 b + 1 b+1 b+1个字节的 b + 1 b+1 b+1,所以 s ⊕ t ⊕ u = ( b + 1 ) s \oplus t \oplus u = (b+1) s⊕t⊕u=(b+1) ,而 s = t ⊕ u ⊕ ( b + 1 ) s = t \oplus u \oplus (b+1) s=t⊕u⊕(b+1) 。
-
总结
- 略
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Day56| Leetcode 583. 两个字符串的删除操作 Leetcode72. 编辑距离
- 折叠指定日期前的查询,让查询列表更简洁
- std::mem_fn函数
- 民安智库:满意度调查在组织管理中的应用与价值
- .NET 7 WinForms News Crack
- 李沐机器学习系列2--- mlp
- 欧姆龙 NJ/NX PLC如何连接博达透传网关实现远程维护上下载
- Docker 安装 Centos和宝塔
- 【PostgreSQL】从零开始:(三十八)约束-唯一约束
- JAVA:某盘API上传下载文件示例_七侠镇莫尛貝_20240117