【大数据进阶第三阶段之Hive学习笔记】Hive基础入门
目录
1、什么是Hive
Hive:由Facebook开源用于解决海量结构化日志的数据统计。
Hive设计的初衷是:对于大量的数据,使得数据汇总,查询和分析更加简单。它提供了SQL,允许用户更加简单地进行查询,汇总和数据分析。同时,Hive的SQL给予了用户多种方式来集成自己的功能,然后做定制化的查询,例如用户自定义函数(User Defined Functions,UDFs).
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
本质是:将HQL转化成MapReduce程序
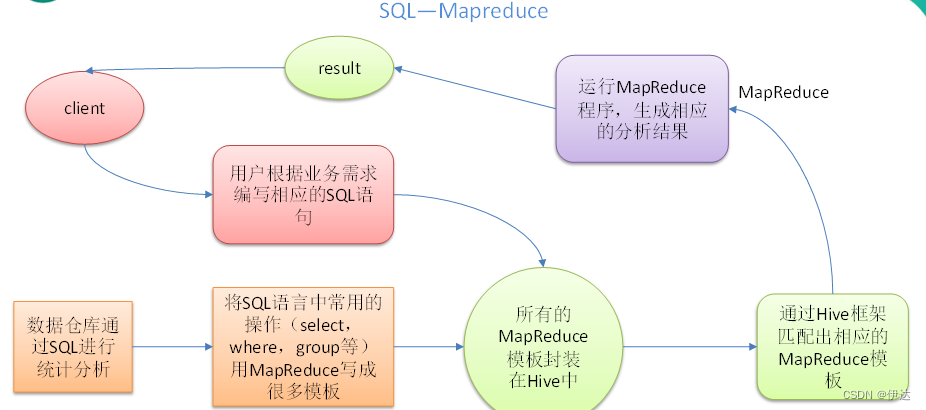
1)Hive处理的数据存储在HDFS
2)Hive分析数据底层的实现是MapReduce
3)执行程序运行在Yarn上
2、Hive的优缺点
2.1、 优点
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
- 避免了去写MapReduce,减少开发人员的学习成本。
- Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
- Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
- Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
2.2、 缺点
2.2.1、Hive的HQL表达能力有限
(1)迭代式算法无法表达
(2)数据挖掘方面不擅长
2.2.2、Hive的效率比较低
(1)Hive自动生成的MapReduce作业,通常情况下不够智能化
(2)Hive调优比较困难,粒度较粗
3、Hive架构原理
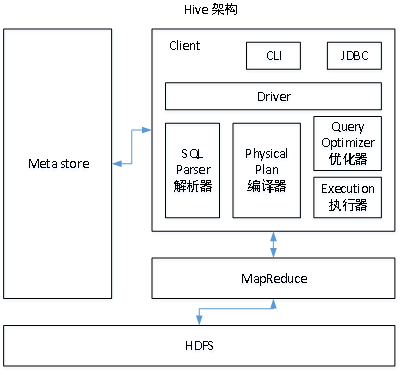
3.1、用户接口:Client
CLI(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问hive)
3.2、元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
3.3、Hadoop
使用HDFS进行存储,使用MapReduce进行计算。
3.4、驱动器:Driver
- 解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
- 编译器(Physical Plan):将AST编译生成逻辑执行计划。
- 优化器(Query Optimizer):对逻辑执行计划进行优化。
- 执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
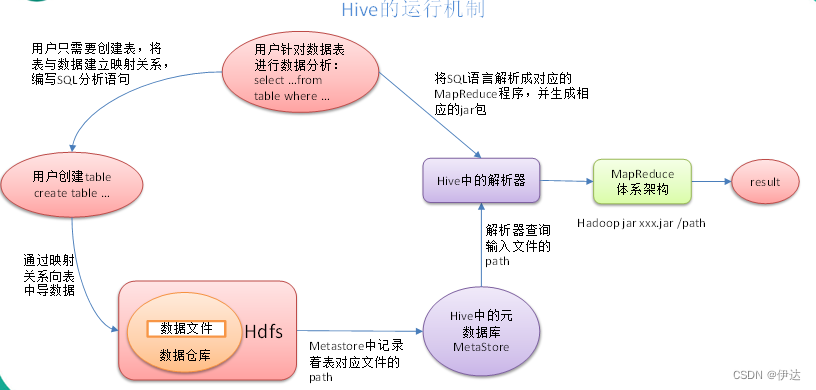
Hive运行机制
Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
?
4、Hive和数据库比较
?? ?由于Hive采用类似SQL的查询语言HQL,因此很容易将Hive理解为数据库。其实从结构来看,Hive 和数据库除了用于类似的查询语言,
再无类似之处。
?4.1、 数据更新
?? ?由于Hive是针对数据仓库应用设计的,而数据仓库的内容是读多写少。因此,Hive中不建议对数据的改写,所有数据都是在加载的时候确定好的。而数据库中的数据通常是需要进行
修改的,因此可以采用insert into ... values添加数据,使用update ... set修改数据
4.2、执行延迟
??? ?Hive在查询数据的时候,由于没有索引,需要扫描整个表。因此延迟较高。由于Hive底层使用的MR框架,而MR本身具有较高的延迟,因此在利用MR执行Hive查询的时候,也有较高的延迟。
4.3、数据规模
由于Hive简历在集群上可以利用MR进行并行计算,因此可以支持很大规模的数据。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- HarmonyOS应用开发学习笔记 Want概述Ability跳转
- Mybatis-Generator-1.4.2
- PyTorch 进阶指南,这个宝典太棒了
- 力扣:77. 组合(回溯, path[:]的作用)
- TDD-LTE TAU流程
- 常用界面设计组件 —— 字符串与输入输出组件(QT)
- 使用Python进行Yolo目标检测的带txt标签进行数据增强
- day07 四数相加Ⅱ 赎金信 三数之和 四数之和
- MySQL篇—性能压测工具mysqlslap介绍
- 【Leetcode 78】子集 —— 回溯法