【深度学习:Embeddings 】机器学习中Embeddings的完整指南

人工智能嵌入提供了生成优质训练数据的潜力,提高了数据质量并最大限度地减少了手动标记要求。通过将输入数据转换为机器可读的格式,企业可以利用人工智能技术来转变工作流程、简化流程并优化性能。
机器学习是一种强大的工具,有潜力改变我们的生活和工作方式。然而,任何机器学习模型的成功在很大程度上取决于用于开发模型的训练数据的质量。高质量的训练数据通常被认为是获得准确可靠的机器学习结果的最关键因素。
在本博客中,我们将讨论高质量训练数据在机器学习中的重要性以及人工智能嵌入如何帮助改进它。我们将涵盖:
【深度学习:Embeddings 】机器学习中Embeddings的完整指南
高质量训练数据的重要性
高质量训练数据在机器学习中的重要性在于它直接影响机器学习模型的准确性和可靠性。为了使模型能够准确地学习模式并做出预测,需要对大量多样化、准确且无偏见的数据进行训练。如果用于训练的数据质量低或包含不准确和偏差,则会产生不太准确且可能存在偏差的预测。
用于训练模型的数据集的质量适用于每种类型的 AI 模型,包括基础模型,例如 ChatGPT 和 Google 的 BERT。 《华盛顿邮报》仔细研究了用于训练一些世界上最流行、最强大的大型语言模型 (LLM) 的庞大数据集。文章特别回顾了 Google 的 C4 数据集的内容,发现质量和数量同样重要,尤其是在训练 LLM 时。
在图像识别任务中,如果用于训练模型的训练数据包含标签不准确或不完整的图像,则模型可能无法准确地识别或分类预测中的相似图像。
同时,如果训练数据对某些群体或人口统计有偏见,那么模型可能会学习并复制这些偏见,从而导致对某些群体的不公平或歧视性待遇。例如,谷歌在最近的一次事件中也陷入了偏见陷阱,其视觉人工智能模型产生了种族主义结果。
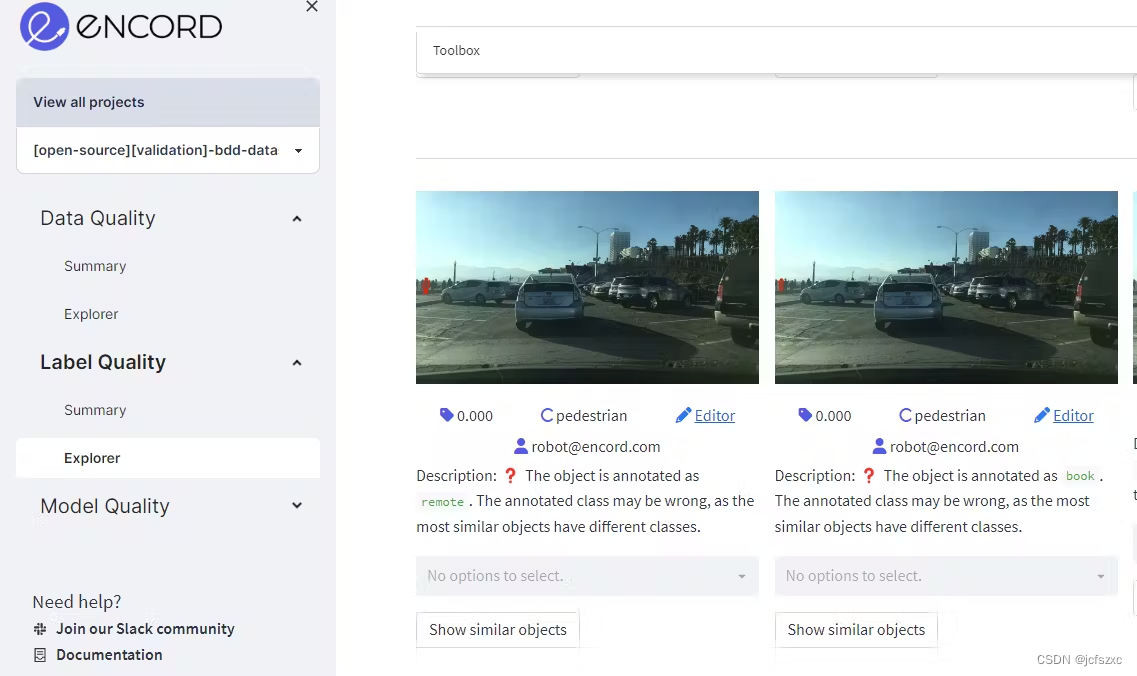
BDD 数据集中的图像有一个行人标记为“远程”和“书本”,这显然是错误注释的。
因此,使用高质量的训练数据对于确保准确且公正的机器学习模型至关重要。这包括选择适当且多样化的数据源,并确保数据在用于训练之前经过清理、预处理和准确标记。
什么是机器学习中的嵌入?
在人工智能中,嵌入是低维空间中一组数据点的数学表示,可捕获其潜在的关系和模式。嵌入通常用于以机器学习算法可以轻松处理的方式表示复杂的数据类型,例如图像、文本或音频。
嵌入与其他机器学习技术的不同之处在于,嵌入是通过在大型数据集上训练模型来学习的,而不是由人类专家明确定义。这使得模型能够学习数据中人类难以或不可能识别的复杂模式和关系。
一旦学习,嵌入可以用作其他机器学习模型的特征,例如分类器或回归器。这使得模型能够根据数据中的潜在模式和关系(而不仅仅是原始输入)做出预测或决策。
嵌入的类型
机器学习中可以使用多种类型的嵌入,包括
图像嵌入
图像嵌入用于表示低维空间中的图像。这些嵌入捕获图像的视觉特征,例如颜色和纹理,允许机器学习模型执行图像分类、对象检测和其他计算机视觉任务。
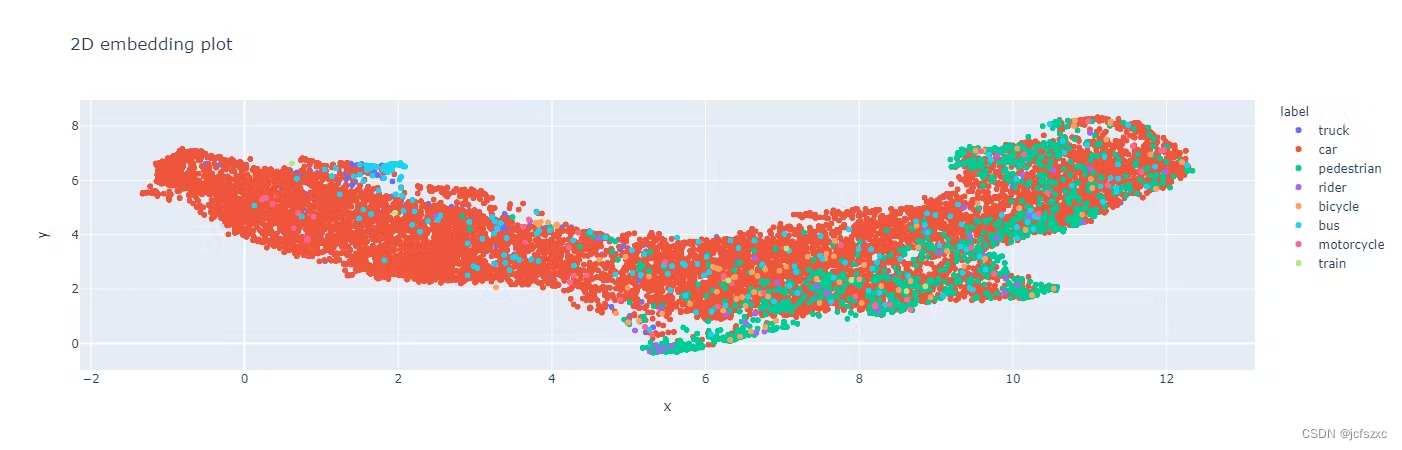
图像嵌入可视化的示例。此处,BDD 数据集在 Encord 平台上的 2D 嵌入图中可视化。
词嵌入
词嵌入用于将词表示为低维空间中的向量。这些嵌入捕获单词之间的含义和关系,使机器学习模型能够更好地理解和处理自然语言。
图嵌入
图嵌入用于将图(互连节点的网络)表示为低维空间中的向量。这些嵌入捕获图中节点之间的关系,允许机器学习模型执行节点分类和链接预测任务。

左:代表社交网络的著名Karate图。右图:使用 DeepWalk 对图的节点进行连续空间嵌入。
通过捕获低维空间中数据的本质,嵌入可以有效地计算和发现复杂的模式和关系,而这些模式和关系在其他情况下可能不明显。这些好处使得人工智能嵌入的各种应用成为可能,如下所述。
嵌入的应用
人工智能嵌入在数据创建和机器学习方面有许多应用,包括
提高数据质量
人工智能嵌入可以通过减少噪音、消除异常值和捕获语义关系来帮助提高数据质量。这在数据需要更加结构化或包含缺失值的情况下特别有用。例如,在自然语言处理中,词嵌入可以将具有相似含义的单词更紧密地表示在一起,从而实现更好的语义理解并提高各种语言相关任务的准确性。
减少手动数据标记的需要
人工智能嵌入可以根据数据的嵌入表示自动标记数据。这可以节省时间和资源,特别是在处理大型数据集时。
减少计算量
嵌入通过在低维空间中表示高维数据来减少计算量。例如,一张256 x 256的图像在图像处理中包含65,536个像素,如果直接使用,会产生很多特征。使用 CNN,可以将图像转换为 1000 维特征向量,从而巩固信息。这种压缩显着降低了计算要求,大约减少了 65 倍,从而可以在不牺牲基本细节的情况下实现更高效的图像处理和分析。
增强自然语言处理 (NLP)
词嵌入广泛应用于情感分析、语言翻译和聊天机器人开发等 NLP 应用中。将单词映射到向量表示使机器学习算法更容易理解单词之间的关系。

改进推荐系统
协同过滤是一种推荐系统,使用用户和项目嵌入来进行个性化推荐。通过将用户和项目数据嵌入向量空间中,该算法可以识别相似的项目并将其推荐给用户。
增强图像和视频处理
图像和视频嵌入可用于对象检测、识别和分类。将图像和视频映射到矢量表示使机器学习算法更容易识别和分类其中的不同对象。
因此,人工智能嵌入的应用多种多样,并提供许多好处,包括提高数据质量和减少手动数据标记的需要。现在,让我们深入研究一下在利用 AI 嵌入生成高质量训练数据时这有何好处。
嵌入在数据创建中的好处
以下是在数据创建中使用嵌入的一些好处:
创建更大且多样化的数据集
通过自动识别数据中的模式和关系,嵌入可以帮助填补空白并识别手动标记可能遗漏的异常值。例如,嵌入可以通过利用数据中学习到的模式和关系来帮助填补空白。
人工智能模型可以通过分析周围的表示来对缺失值做出明智的估计或预测,从而实现更完整、更可靠的数据分析。这可以通过提供更全面、更具代表性的训练数据来帮助提高机器学习模型的准确性。

减少偏差
在训练数据中使用人工智能嵌入可以通过更细致地理解数据中的关系和模式来帮助减少偏见,从而识别和减轻潜在的偏见来源。这有助于确保机器学习模型在公平且有代表性的数据上进行训练,从而实现更准确和公正的预测。
提高模型性能
AI 嵌入具有多种优势,例如提高效率、更好的泛化性以及增强各种机器学习任务的性能。它们能够有效地计算和发现复杂的模式,减少过度拟合,并捕获数据的底层结构,以便更好地概括新的、未见过的数据。
如何使用嵌入创建高质量的训练数据
数据准备
第一步是准备用于嵌入的数据。数据准备步骤对于嵌入至关重要,因为输入数据的质量决定了嵌入结果的质量。
第一步是收集要用于训练模型的数据。这可以包括文本数据、图像数据或图形数据。收集数据后,您需要对其进行清理和预处理,以消除任何噪音或不相关的信息。例如,在文本数据中,数据清洗涉及:
- 将文本标记为单个单词或短语。
- 删除停用词。
- 纠正拼写错误。
- 删除标点符号。
您可能需要调整图像大小或将图像裁剪为图像数据的统一大小。
如果数据有噪声、非结构化或包含不相关的信息,则嵌入可能无法准确表示数据,并且可能无法提供所需的结果。正确的数据准备有助于提高嵌入的质量,从而产生更准确、更高效的机器学习模型。
例如,图像数据准备的预处理步骤涉及去除图像重复项和没有信息的图像,例如极暗或过亮的图像。
使用机器学习技术嵌入
大多数机器学习算法需要数值数据作为输入。因此,您需要将数据转换为数字格式。这可能涉及创建文本数据的词袋表示、将图像转换为像素值或将图形数据转换为数字矩阵。
将数据转换为数字格式后,您可以使用机器学习技术将其嵌入。嵌入过程涉及将数据从高维空间映射到低维空间,同时保留其语义。一些流行的嵌入技术是:
主成分分析 (PCA) 和单值分解 (SVD)
主成分分析 (PCA) 是一种降维技术,可将原始数据转换为一组新的、不相关的特征(称为主成分)。它捕获数据中最重要的信息,同时丢弃不太重要的信息。
为了执行 PCA 嵌入,原始数据首先被居中并缩放至均值和单位方差为零。接下来,计算中心数据的协方差矩阵。然后计算协方差矩阵的特征向量和特征值,并根据特征向量对应的特征值对特征向量进行降序排序。然后选择前 k 个特征向量来形成新的特征空间,其中 k 是嵌入空间的所需维数。
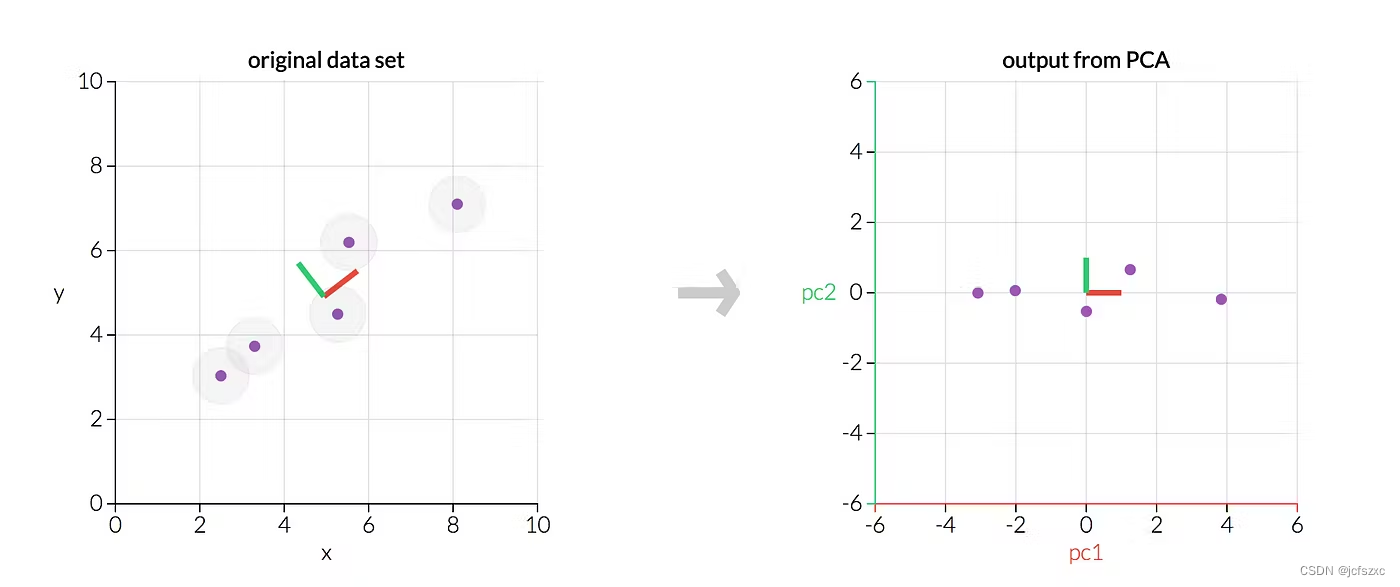
我们使用 PCA 转换五个数据点的示例。左图是我们的原始数据;正确的图表将是我们转换后的数据。两个图表显示相同的数据,但右图反映了转换后的原始数据,因此轴现在是主成分。
最后,使用选定的特征向量将原始数据投影到新的特征空间上以获得嵌入表示。 PCA 是一种广泛使用的嵌入技术,特别是图像和音频数据的嵌入技术,并已用于面部识别和语音识别等各种应用中。
奇异值分解 (SVD) 在 PCA 中使用,因此我们仅简要介绍这一点。SVD 将矩阵分解为三个矩阵:U、Σ 和 V.U 表示左奇异向量,S 表示奇异值,V 表示右奇异向量。
A n × p = U n × n S n × p V p × p T A_{n\times p} = U_{n\times n} S_{n\times p} V_{p\times p} ^T An×p?=Un×n?Sn×p?Vp×pT?
奇异值和向量捕获原始矩阵中最重要的信息,允许降维和嵌入创建。与 PCA 类似,SVD 可用于为各种类型的数据创建嵌入,包括文本、图像和图形。
SVD 已用于各种机器学习任务,例如推荐系统、文本分类和图像处理。它是一种创建高质量嵌入的强大技术,可以提高机器学习模型的性能。
自动编码器
自动编码器是用于无监督学习的神经网络模型。它们由将输入数据映射到较低维表示(编码)的编码器网络和尝试从编码重建原始输入数据的解码器网络组成。自动编码器旨在学习输入数据的压缩且有意义的表示,从而有效地捕获基本特征。
自动编码器由编码器神经网络组成,该网络将输入数据压缩为低维表示或嵌入。解码器网络根据嵌入重建原始数据。通过在数据集上训练自动编码器,编码器网络学习提取有意义的特征并将输入数据压缩为紧凑的表示。这些嵌入可用于下游任务,例如聚类、可视化或迁移学习。
词向量
Word2Vec 是一种用于创建词嵌入的流行技术,它表示高维向量空间中的单词。该技术的工作原理是在大量文本数据上训练神经网络,以预测给定单词出现的上下文。由此产生的嵌入捕获单词之间的语义和句法关系,例如相似性和类比。
Word2Vec 在各种自然语言处理任务中都很有效,例如语言翻译、文本分类和情感分析。它还在推荐系统和图像分析中具有应用。
实现 Word2Vec 有两种主要方法:连续词袋 (CBOW) 模型和 Skip-gram 模型。 CBOW 在给定周围上下文的情况下预测目标单词,而 Skip-gram 在给定目标单词的情况下预测上下文。两种模型都有其优点和缺点,它们之间的选择取决于具体应用和数据的特征。
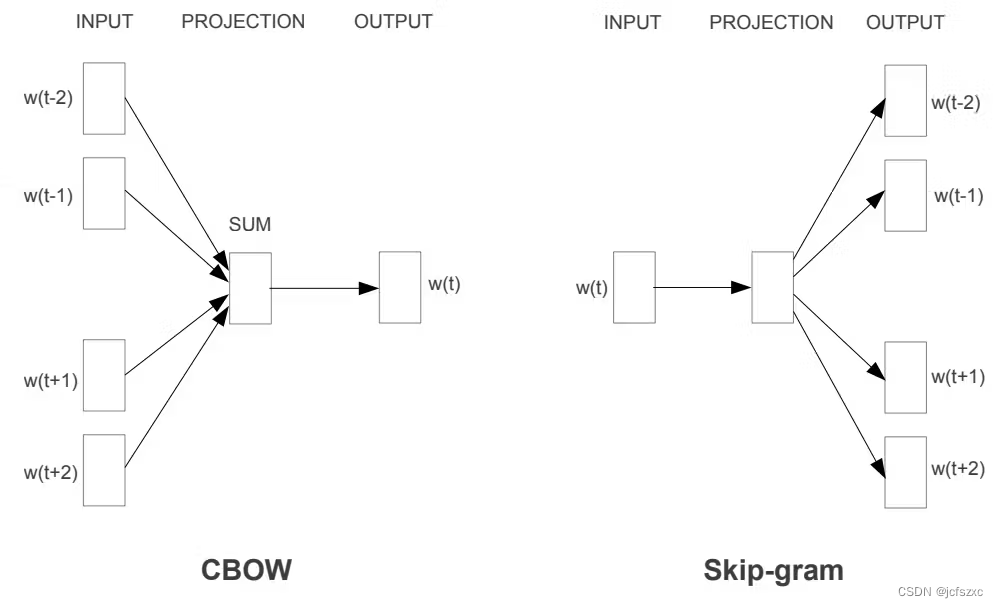
左:CBOW 架构。右:Skip-gram 架构。 CBOW 架构根据上下文预测当前单词,而 Skip-gram 则在给定当前单词的情况下预测周围的单词。
GloVe
GloVe 代表单词表示的全局向量,是另一种流行的嵌入技术,用于将单词表示为向量。与 Word2Vec 一样,GloVe 也是一种基于神经网络的方法。然而,与基于浅层神经网络的 Word2Vec 不同,GloVe 使用全局矩阵分解技术来学习词嵌入。
在 GloVe 中,单词的共现矩阵是通过计算两个单词在给定上下文中同时出现的次数来构建的。矩阵的行代表单词,列代表单词出现的上下文。然后,该矩阵被分解为两个单独的矩阵,一个用于单词,另一个用于上下文。这两个矩阵的乘积产生最终的词嵌入。

众所周知,GloVe 在各种 NLP 任务上表现良好,例如单词类比、单词相似度和命名实体识别。此外,GloVe 还通过将图像特征转换为类似单词的实体并应用 GloVe 嵌入来用于图像分类任务。
BERT
BERT(来自 Transformers 的双向编码器表示)是 Google 开发的一种流行语言模型,已用于各种自然语言处理 (NLP) 任务,包括嵌入。 BERT 是一种深度学习模型,它使用 Transformer 架构通过考虑单词的上下文来生成单词嵌入。这使得 BERT 能够捕获单词的语义,以及句子中单词之间的关系。

BERT 是一种预训练模型,经过大量文本数据的训练,使其成为生成高质量词嵌入的强大工具。基于 BERT 的嵌入在一系列 NLP 任务中非常有效,包括情感分析、文本分类和问答。此外,BERT 允许微调特定的下游任务,这可以带来更准确的结果。
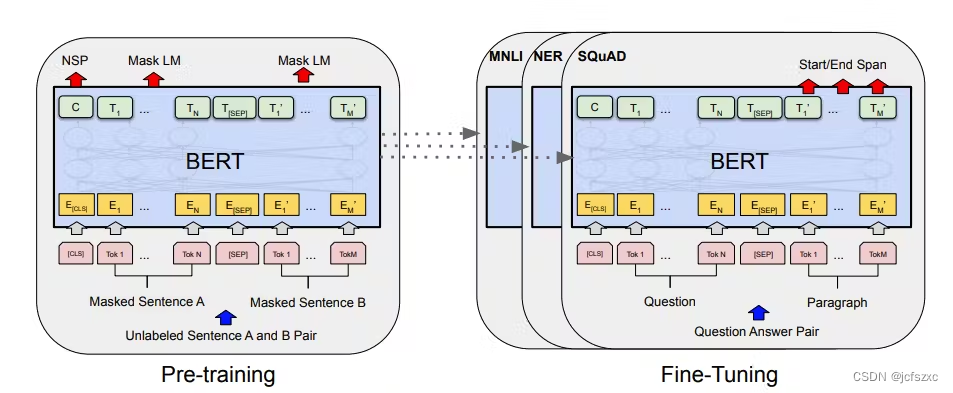
总的来说,BERT 是一个强大的工具,用于生成高质量的词嵌入,可用于广泛的 NLP 应用。 BERT 的一个缺点是它的计算成本可能很高,需要大量资源进行训练和推理。然而,预训练的 BERT 模型可以针对特定用例进行微调,从而减少昂贵的训练需求。
t-SNE
t-SNE(t-分布式随机邻域嵌入)是一种广泛使用的用于可视化高维数据的降维技术。虽然 t-SNE 主要用于可视化,但它也可用于生成嵌入。该过程涉及应用 t-SNE 来降低数据的维度并获得捕获原始高维数据的固有结构的低维嵌入。

t-SNE 的工作原理是创建一个概率分布,用于测量高维空间中数据点与低维空间中相应概率分布之间的相似性。然后,它最小化这些分布之间的 Kullback-Leibler 散度,以找到保留点之间成对相似性的嵌入。
t-SNE 生成的嵌入可用于各种目的,例如聚类、异常检测或作为下游机器学习算法的输入。然而,值得注意的是,t-SNE 的计算成本很高,并且生成的嵌入应该仔细解释,因为它们强调局部结构并且可能无法保留点之间的精确距离
UMAP
UMAP(统一流形逼近和投影)是一种常用于生成嵌入的降维技术。与 PCA 或 t-SNE 等传统方法不同,UMAP 专注于保留数据中的局部和全局结构,同时保持计算效率。

UMAP 的工作原理是构建数据的低维表示,同时保留邻域关系。它通过将数据建模为拓扑结构并近似数据所在的流形来实现这一点。该算法迭代地优化低维嵌入,以保留附近点之间的成对距离。
将 UMAP 应用于数据集会生成嵌入,以捕获数据中的底层结构和关系。这些嵌入可用于各种目的,例如可视化、聚类或作为其他机器学习算法的输入。
UMAP 在图像分析、基因组学、文本挖掘和推荐系统等各个领域广受欢迎,因为它能够生成高质量的嵌入,在保持本地和全局结构的同时保持计算效率。
分析和验证嵌入是质量保证的重要一步,以确保生成的嵌入准确地表示基础数据。
分析和验证嵌入以保证质量
分析嵌入的一种常见方法是使用 t-SNE 或 PCA 等技术在低维空间(例如 2D 或 3D)中将它们可视化。这可以帮助识别数据中的集群或模式,并提供对嵌入质量的见解。
有一些平台可以创建和绘制数据集的嵌入。当您想要在低维空间中可视化数据集时,这些图非常有用。在这个低维空间中可视化数据可以更容易地识别数据中的任何潜在问题或偏差,可以解决这些问题以提高嵌入的质量。可视化嵌入可以提供一种直观的方式来评估嵌入对特定任务的质量和有用性,从而帮助评估和比较不同的模型。
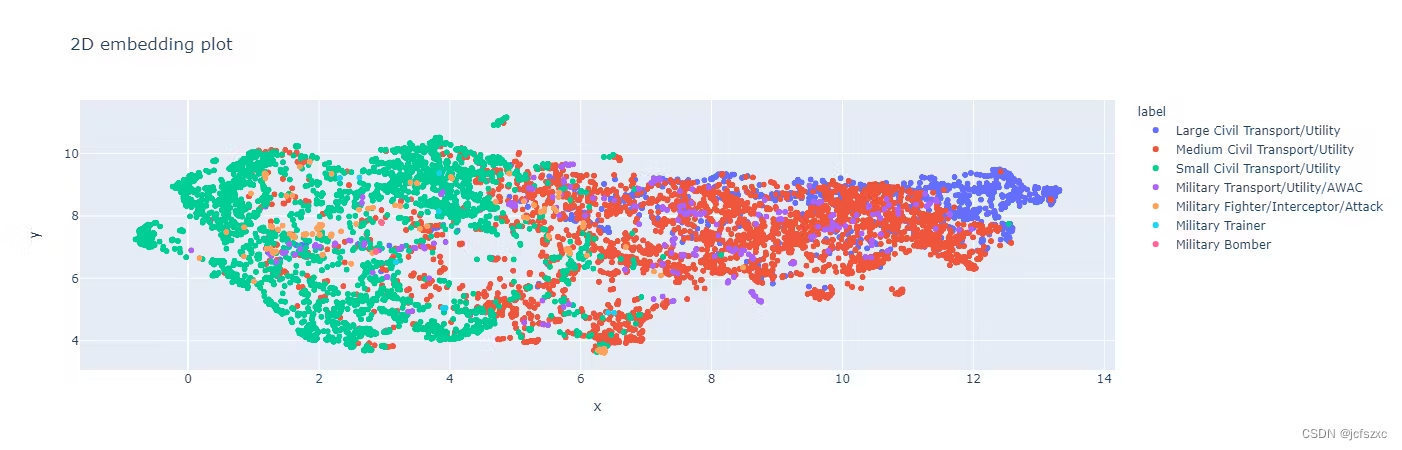
Encord Active 平台就是一个例子,它提供图像数据集的 2D 嵌入图,使用户能够可视化特定集群内的图像。这简化了通过嵌入识别异常值的过程。二维嵌入图不仅可用于验证数据质量,还可用于验证数据集的标签质量。
嵌入的验证涉及评估它们在下游任务(例如分类或预测)上的性能,并将其与其他方法进行比较。这可以帮助确定嵌入在现实场景中的有效性并突出需要改进的领域。
验证的另一个方面是测量嵌入中存在的偏差程度。这很重要,因为嵌入可能反映训练数据中的偏差,从而导致歧视性或不公平的结果。可以使用去偏差等技术来消除这些偏差并确保嵌入公平且无偏差。
现在我们已经探索了嵌入的创建和分析,让我们通过一个案例研究来更深入地了解与传统机器学习算法相比,嵌入如何使机器学习模型受益。
案例研究:嵌入和对象分类
本案例研究重点关注嵌入对对象分类算法的影响。通过可视化训练数据集的嵌入,我们可以探索它们对过程的影响。
图像分类是机器学习的一个流行应用,嵌入对于这项任务非常有效。基于嵌入的图像分类方法涉及学习图像数据的低维表示并使用该表示作为机器学习模型的输入。

分析嵌入可以减少手动特征工程的需要。与传统的机器学习算法相比,基于嵌入的方法可以实现更高效的计算。因此,经过训练的模型通常会实现更高的准确性和对新的、未见过的数据更好的泛化。让我们可视化嵌入以更好地理解这一点。
可视化嵌入
在这里,我们将使用 Encord Active 平台可视化 Caltech-101 数据集的嵌入图。
Caltech-101 数据集由分为 101 类的物体图像组成。数据集中的每个图像都有不同的尺寸,但它们通常具有中等分辨率,尺寸范围从 200 x 200 到 500 x 500 像素。但是,数据集中的维度数量将取决于用于表示每个图像的特征数量。一般来说,大多数 Caltech-101 图像特征将具有数百或数千个维度,这将有助于在低维空间中对其进行可视化。

在您最喜欢的 Python 环境中运行以下命令,使用以下命令将下载 Encord Active:
python3.9 -m venv ea-venv
source ea-venv/bin/activate
# within venv
pip install encord-active
或者您可以按照以下命令使用 GitHub 安装 Encord Active:
pip install git+https://github.com/encord-team/encord-active
要检查 Encord Active 是否已安装,请运行:
encord-active --help
Encord Active 拥有许多沙箱数据集,例如 MNIST、BDD100K、TACO 数据集等等。 Caltech101 数据集就是其中之一。这些沙箱数据集通常在计算机视觉应用程序中用于构建基准模型。
现在您已经安装了 Encord Active,让我们通过运行以下命令来下载 Caltech101 数据集:
encord-active download
该脚本要求您选择一个项目,导航选项 ↓ 和 ↑ 选择 Caltech-101 训练或测试数据集,然后按 Enter 键。为了方便分析数据集,数据集被预先划分为包含60%数据的训练集和包含其余40%数据的测试集。
简单的!现在,您已获得数据。要在浏览器中可视化数据,请运行以下命令:
cd /path/to/downloaded/project
encord-active visualize
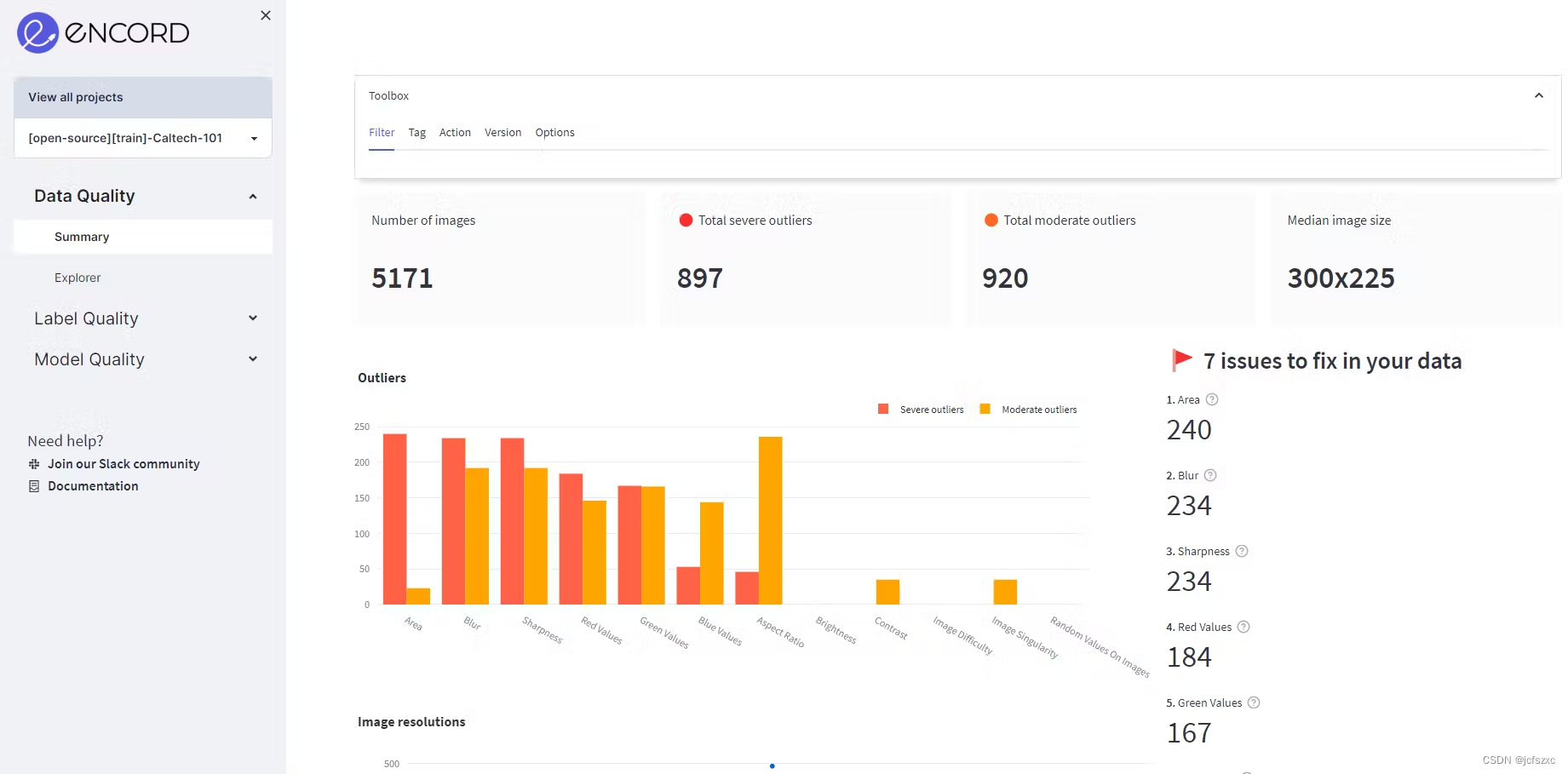
浏览器中可视化数据(数据 = Caltech-101 训练数据 - Caltech-101 数据集的 60%)
2D 嵌入图可以在数据质量和标签质量部分的资源管理器页面中找到。
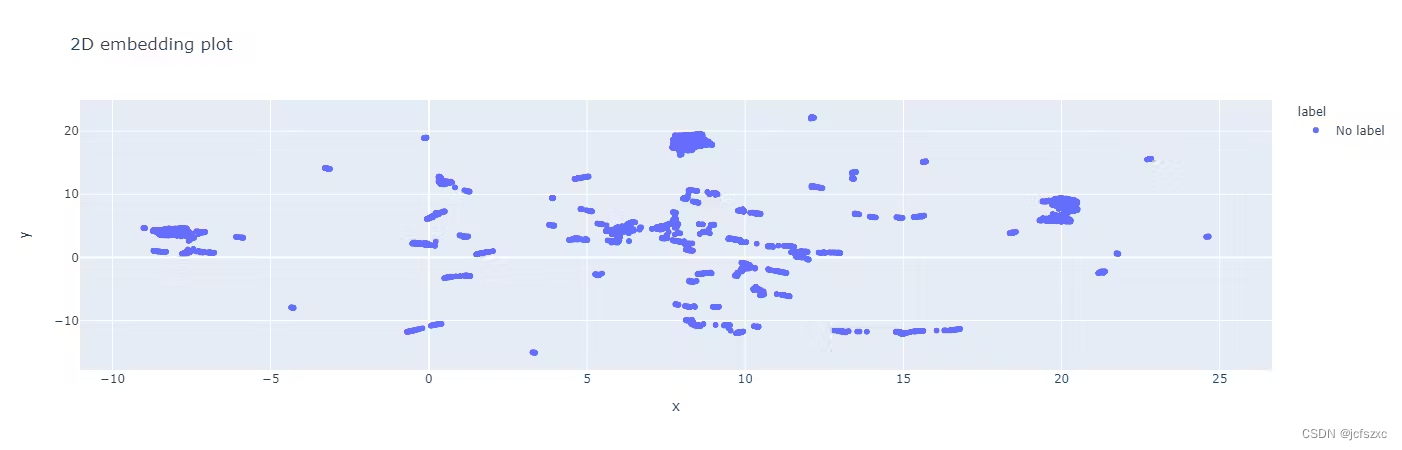
Encord 的 Data Quality Explorer 页面中的 2D 嵌入图。
这里的 2D 嵌入图是散点图,每个点代表数据集中的一个数据点。图中每个点的位置反映了数据点彼此之间的相对相似性或相异性。例如,选择绘图右上角的框或套索选择。选择区域后,您只能可视化所选区域中的图像。
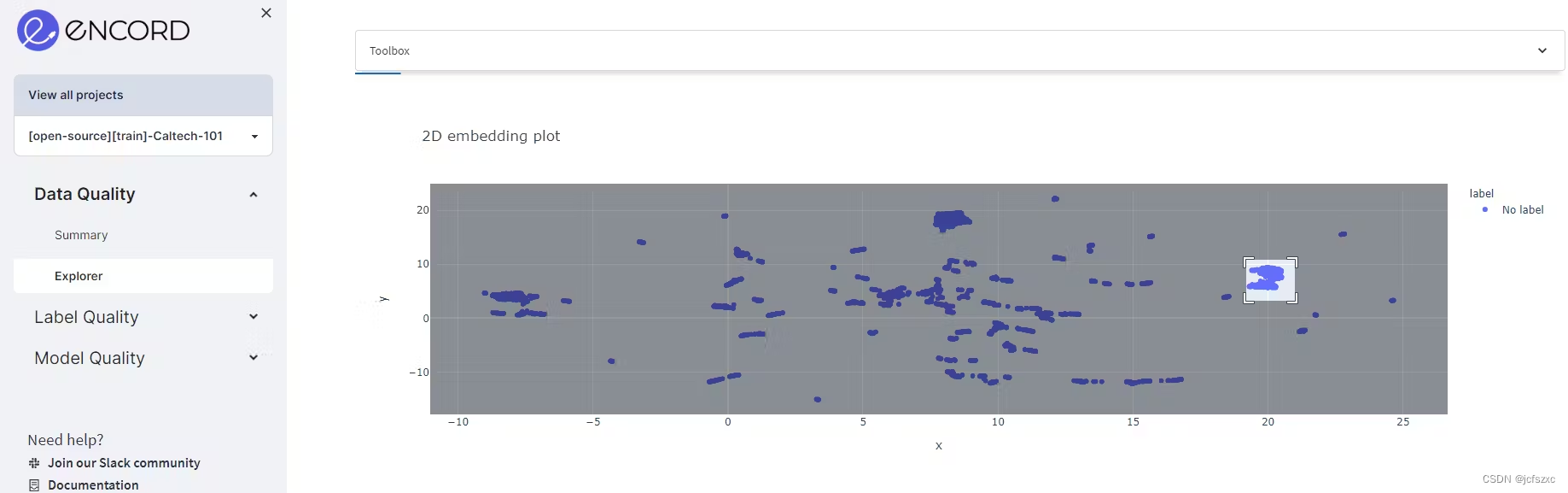
通过将数据投影到二维,您现在可以看到相似数据点、异常值和其他可能对数据分析有用的模式的集群。
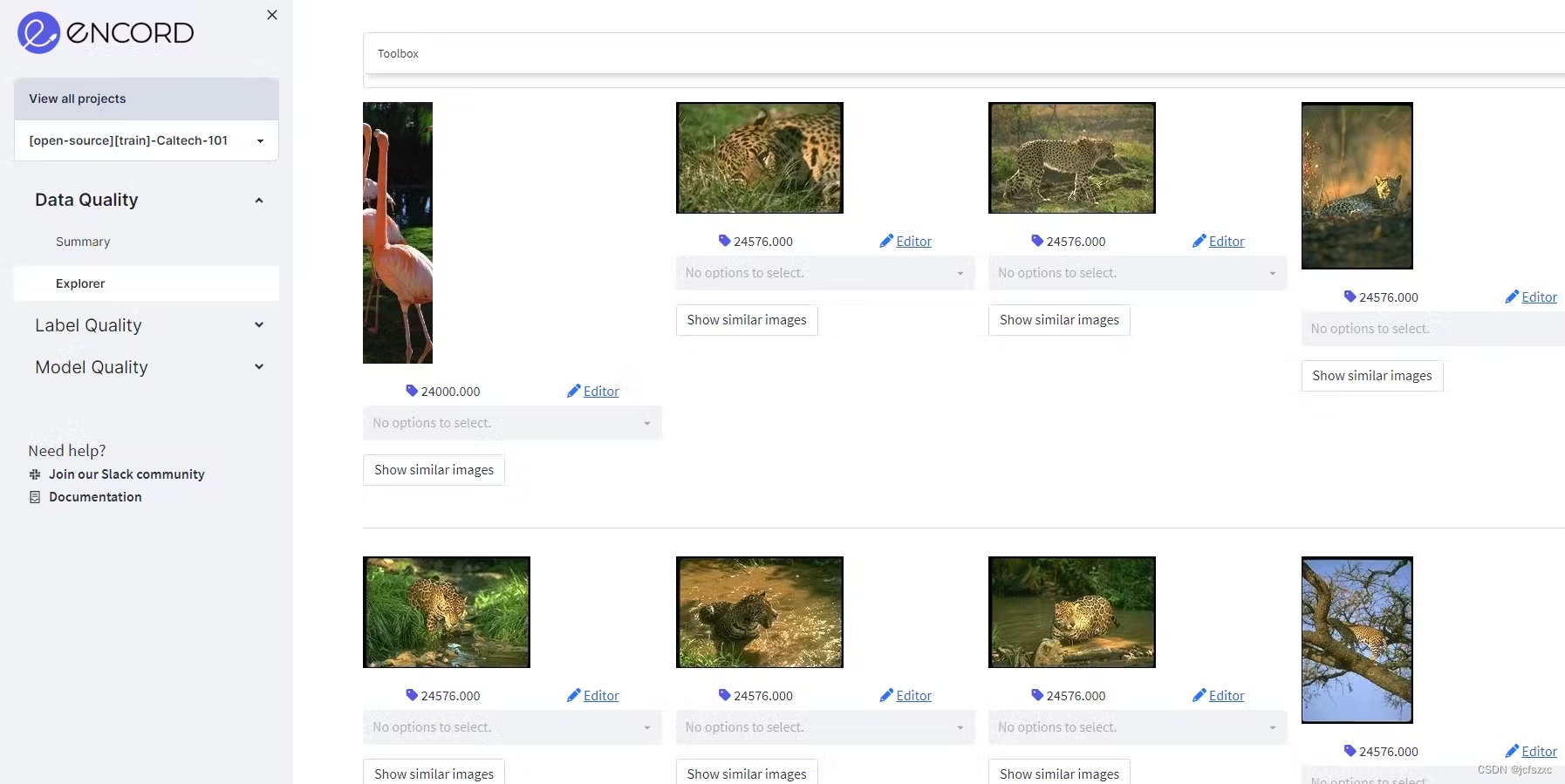
例如,我们在选定的簇中看到,有一个异常值。
标签质量中的 2D 嵌入图显示每个图像的数据点,每种颜色代表对象所属的类。这有助于通过发现对象标签的意外关系或模型偏差的可能区域来找出异常值。
该图还显示了数据集的可分离性。可分离的数据集对于对象识别非常有用,因为它允许使用更简单、更高效的计算机视觉模型,这些模型可以通过相对较少的参数实现高精度。
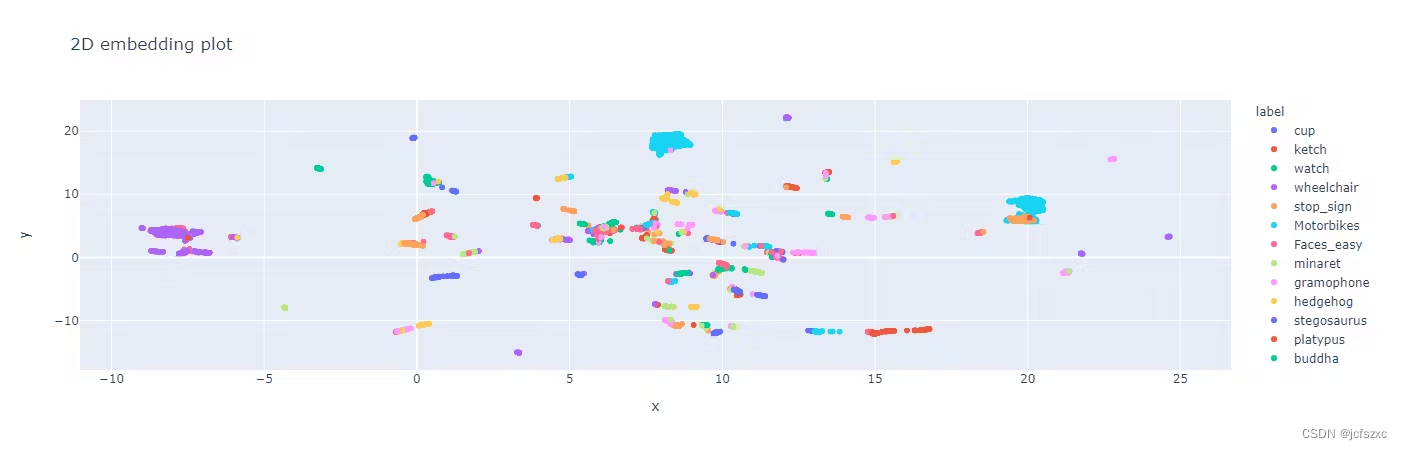
Encord 标签质量浏览器页面中的 2D 嵌入图。
可分离的数据集是对象分类的有用起点,因为它允许我们在需要时探索更复杂的模型之前快速开发和评估简单的机器学习模型。它还可以帮助我们更好地理解区分不同类别对象的数据和特征,这对于将来开发更复杂的模型很有用。
💡阅读 Caltech101 数据集的详细分析,以更好地理解该数据集。您还可以了解如何可视化和分析您的训练数据!
到目前为止,我们已经讨论了各种类型的嵌入以及如何使用它们来分析和提高训练数据的质量。现在,让我们将重点转移到使用 AI 嵌入创建训练数据时应牢记的一些最佳实践。
计算机视觉和机器学习中嵌入的最佳实践
以下是一些最佳实践,可用于检测您为训练数据创建的 AI 嵌入是否具有高质量:
选择合适的嵌入技术
选择合适的嵌入技术对于使用 AI 嵌入创建高质量的训练数据至关重要。
不同的嵌入技术可能更适合不同的数据类型和任务。在选择嵌入技术之前,必须仔细考虑数据和手头的任务。记住嵌入技术所需的计算资源以及生成的嵌入的大小也很重要。
及时了解人工智能嵌入领域的最新研究和技术也很重要。这有助于确保使用最有效和高效的嵌入技术来创建高质量的训练数据。
解决数据偏差并确保数据多样性
使用大型且多样化的数据集来生成训练数据的嵌入是确保嵌入解决数据集中偏差的好方法。这有助于捕获数据的全部变化并产生更准确的嵌入。
验证嵌入
分析嵌入以验证其质量是至关重要的一步。应评估和验证嵌入,以确保它们捕获相关信息并可以有效地用于手头的任务。低维空间中嵌入的可视化可以帮助识别数据中的任何模式或集群,并有助于验证过程。
结论
总之,人工智能嵌入是在机器学习中创建高质量训练数据的强大工具。通过使用嵌入,数据科学家可以提高数据质量,减少手动数据标记的需求,并实现更高效的计算。使用 AI 嵌入的最佳实践包括:
- 选择适当的技术。
- 解决数据偏见并确保多样性。
- 了解可能影响数据质量的限制。
人工智能嵌入在机器学习领域有着广阔的前景,我们建议尽可能在数据创建中实现它们。
未来发展方向
未来,我们预计会看到更复杂的嵌入技术和工具,以及嵌入在图像和文本分类之外的广泛应用中的使用增加。例如,Meta AI 的新模型 ImageBIND 是一种机器学习模型,可为图像、文本和音频等多种模态创建联合嵌入空间。该模型旨在实现多种模式的有效集成,并提高各种多模式机器学习任务的性能。
促进嵌入可视化和分析的平台的开发是一个令人兴奋的研究领域。这些平台可以更轻松地探索高维数据中的结构和关系,并可以帮助识别难以检测到的模式和异常值。 Encord Active 就是此类平台的一个例子,它允许用户在 2D 嵌入图中可视化其图像数据集,并探索特定集群中的图像,正如我们在上面的案例研究中看到的那样!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 鸿蒙Harmony(四)ArkUI---基础组件:Image
- 【QT demo】基于QT6.2.4实现简易的QT_Snake贪吃蛇小游戏
- MySQL 慢查询探究分析
- Power BI案例-医院数据集的仪表盘制作
- 人工智能辅助下的人工心脏:未来医疗的奇迹
- 2023最新版JavaSE教程——第2天:变量与运算符
- Bing AI使用教程
- 基于GA-PSO遗传粒子群混合优化算法的DVRP问题求解matlab仿真
- 腾讯云轻量应用服务器简介、购买、部署新手图文教程
- Eclipse 转IDEA的小伙伴看过来,告诉大家在IDEA中如何快速配置和运行Maven!