使用Node Exporter采集主机数据
安装 Node Exporter
在 Prometheus 的架构设计中,Prometheus Server 并不直接服务监控特定的目标,其主要任务负责数据的收集,存储并且对外提供数据查询支持。因此为了能够能够监控到某些东西,如主机的 CPU 使用率,我们需要使用到 Exporter。Prometheus 周期性的从 Exporter 暴露的 HTTP 服务地址(通常是/metrics)拉取监控样本数据。
这里为了能够采集到主机的运行指标如 CPU、 内存、磁盘等信息,我们可以使用 Node Exporter。
Node Exporter 同样采用 Golang 编写,并且不存在任何的第三方依赖,只需要下载,解压即可运行。可以从官网获取最新的 node exporter 版本的二进制包。
wget https://github.com/prometheus/node_exporter/releases/download/v1.7.0/node_exporter-1.7.0.linux-amd64.tar.gz
也可以使用 docker 安装
docker run -d -p 9100:9100 prom/node-exporter
访问http://localhost:9100/可以看到页面。
初始 Node Exporter 监控指标:
访问http://localhost:9100/metrics,可以看到当前 node exporter 获取到的当前主机的所有监控数据。
每一个监控指标之前都会有一段类似于如下形式的信息:
# HELP node_cpu Seconds the cpus spent in each mode.
# TYPE node_cpu counter
node_cpu{cpu="cpu0",mode="idle"} 362812.7890625
# HELP node_load1 1m load average.
# TYPE node_load1 gauge
node_load1 3.0703125
其中 HELP 用于解释当前指标的含义,TYPE 则说明当前指标的数据类型。在上面的例子中 node_cpu 的注释表明当前指标是 cpu0 上 idle 进程占用 CPU 的总时间,CPU 占用时间是一个只增不减的度量指标,从类型中也可以看出 node_cpu 的数据类型是计数器(counter),与该指标的实际含义一致。又例如 node_load1 该指标反映了当前主机在最近一分钟以内的负载情况,系统的负载情况会随系统资源的使用而变化,因此 node_load1 反映的是当前状态,数据可能增加也可能减少,从注释中可以看出当前指标类型为仪表盘(gauge),与指标反映的实际含义一致。
除了这些以外,在当前页面中根据物理主机系统的不同,你还可能看到如下监控指标:
- node_boot_time:系统启动时间
- node_cpu:系统 CPU 使用量
- nodedisk*:磁盘 IO
- nodefilesystem*:文件系统用量
- node_load1:系统负载
- nodememeory*:内存使用量
- nodenetwork*:网络带宽
- node_time:当前系统时间
- go_*:node exporter 中 go 相关指标
- process_*:node exporter 自身进程相关运行指标
从 Node Exporter 收集监控数据
为了能够让 Prometheus Server 能够从当前 node exporter 获取到监控数据,这里需要修改 Prometheus 配置文件。编辑 prometheus.yml 并在 scrape_configs 节点下添加以下内容:
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
# 采集node exporter监控数据
- job_name: 'node'
static_configs:
- targets: ['localhost:9100']
重新启动 Prometheus Server。
访问http://localhost:9090,进入到 Prometheus Server。如果输入“up”并且点击执行按钮以后,可以看到如下结果: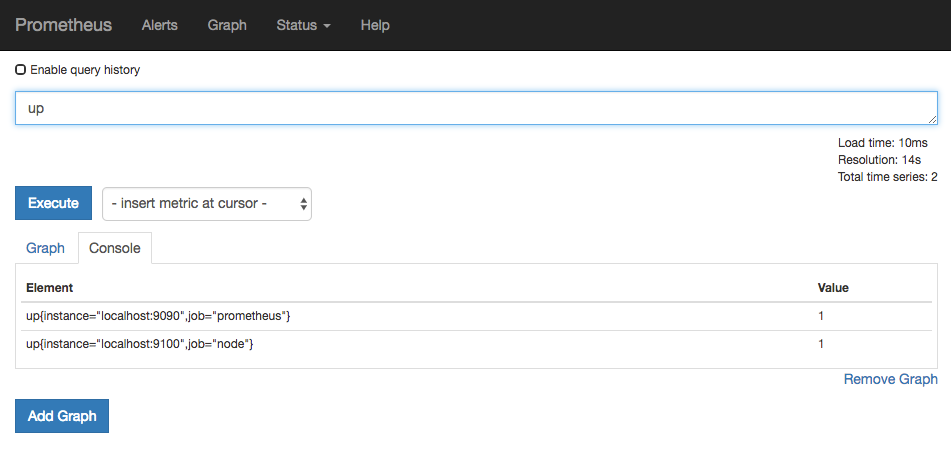
如果 Prometheus 能够正常从 node exporter 获取数据,则会看到以下结果:
up{instance="localhost:9090",job="prometheus"} 1
up{instance="localhost:9100",job="node"} 1
其中“1”表示正常,反之“0”则为异常。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Android 编译过程介绍,Android.mk 和 Android.bp 分析, 在源码中编译 AndroidStudio 构建的 App
- 网络安全中的加解密问题
- IMS基本架构
- Linux下Redis6下载、安装和配置教程-2024年1月5日
- Visual SVN Server实战
- 【flink番外篇】22、通过 Table API 和 SQL Client 操作 Catalog 示例
- ORACLE报错:ORA-04091 表发XXX生了变化,触发器/函数不能读它
- ssh远程登录指定host并且拿到指定路径下的文件列表
- Linux笔记---文件查看和编辑
- centos 安装 配置 zsh