Elasticsearch 8.X进阶搜索之“图搜图”实战
Elasticsearch 8.X “图搜图”实战
1、什么是图搜图?
"图搜图"指的是通过图像搜索的一种方法,用户可以通过上传一张图片,搜索引擎会返回类似或者相关的图片结果。这种搜索方式不需要用户输入文字,而是通过比较图片的视觉信息来找到相似或相关的图片。这项技术在许多不同的应用中都很有用,如找到相同或相似的图片,寻找图片的来源,或者识别图片中的物体等等。
图像搜索的技术基础主要包括图像处理和机器学习等方面。通过图像处理,可以提取图像的特征(如颜色、形状、纹理等),然后通过机器学习模型比较这些特征来寻找相似的图片。近年来,深度学习也在图像搜索中发挥了重要作用,使得搜索结果更加精确和高效。
举例:谷歌“按图搜索”、百度识图。

2、为什么要图搜索?传统搜索不香吗?
图像搜索和传统的文本搜索都有它们各自的优点和适用场合。以下是一些使用图像搜索的原因:
- 寻找相似的图片
如果你有一张图片,想找到类似的图片,或者找到这张图片的其他版本(如不同的分辨率或是否有水印等),图像搜索是最直接的方法。
- 找到图片的来源
如果你找到一张你喜欢的图片,但不知道它来自哪里,图像搜索可以帮你找到它的原始来源,比如说是来自哪个网站或者是谁拍摄的。
- 识别图片中的内容
图像搜索也可以帮助你识别图片中的物体或人物。比如说,你有一张含有未知物体的图片,你可以通过图像搜索来识别它是什么。
- 超越语言和文化障碍
有时候,你可能无法用文字准确描述你要搜索的内容,或者你不知道它的正确名称。在这种情况下,图像搜索可以帮助你找到你需要的信息,不需要考虑语言和文化的差异。
举个例子:小区里带孩子玩,遇到一个虫子,小朋友们都围过去,好奇的小朋友就问到“这个虫子叫什么名字?”家长们也都不知道,有点像小时候见过的豆虫,但又不完全一样,最终借助“百度识图”搞定答案。
总的来说,图像搜索是一个非常有用的工具,能够补充和增强传统的文本搜索。不过,它也并不是万能的,有时候还是需要配合文本搜索一起使用才能得到最好的搜索结果。
3、Elasticsearch 8.X 如何实现图搜图?
从宏观角度,类似把“大象放冰箱”的几个大步骤,Elasticsearch 8.X 要实现图搜图需要两个核心步骤:
步骤1:特征提取
使用图像处理和机器学习的方法(如卷积神经网络)来提取图像的特征。这些特征通常会被编码为一个向量,可以用来衡量图像的相似度。有一些开源的工具库可以用于图像特征提取,部分举例如下:
| 工具库 | 语言 | 主要特性 |
|---|---|---|
| OpenCV | C++,Python,Java | 提供多种特征提取算法,如SIFT,SURF,ORB等;同时提供一系列图像处理功能 |
| TensorFlow | Python | 提供预训练的深度神经网络模型,如ResNet,VGG,Inception等,用于提取图像特征 |
| PyTorch | Python | 提供预训练的深度神经网络模型,如ResNet,VGG,Inception等,用于提取图像特征 |
| VLFeat | C,MATLAB | 提供多种特征提取算法,如SIFT,HOG,LBP等 |
这些库都为图像特征提取提供了大量的工具和函数,可以帮助开发者快速地实现图像特征提取。需要注意的是,不同的特征提取方法可能适用于不同的任务,选择何种方法取决于特定的应用需求。
步骤2:索引和搜索
将提取出来的特征向量存储在Elasticsearch中,然后利用Elasticsearch的搜索能力来找出相似的图像。Elasticsearch的向量数据类型可以用来存储向量,而script_score查询可以用来计算相似度。
4、Elasticsearch 8.X “图搜图”实战
4.1 架构梳理
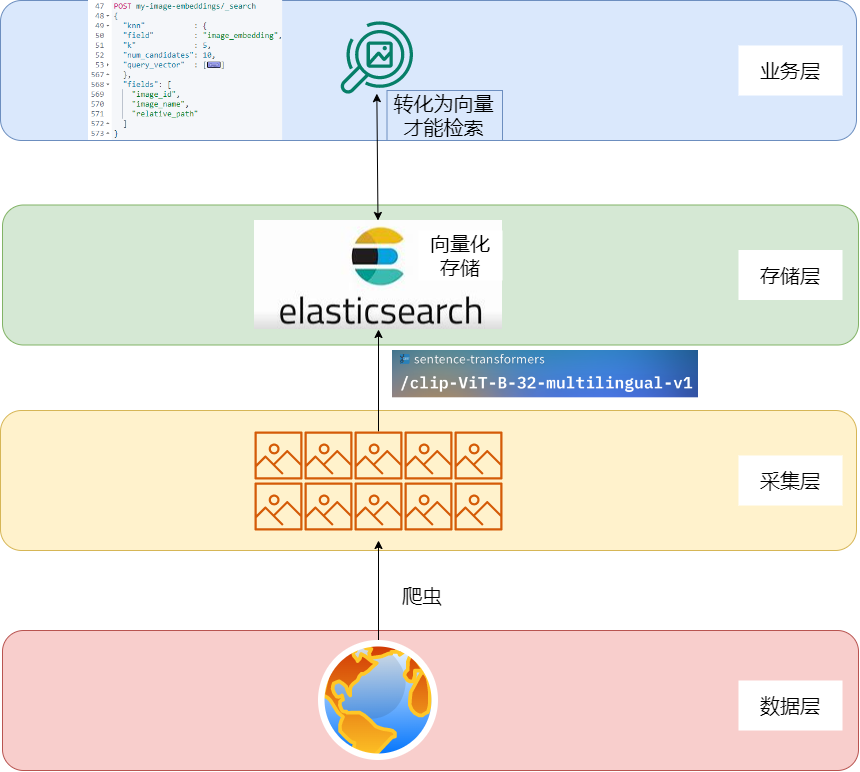
- 数据层:图片数据分散在互联网上,需要采集实现。
- 采集层:借助爬虫或者已有工具采集数据,存储到本地即可。
- 存储层:借助向量转换工具或模型工具,遍历图片为向量存入Elasticsearch。
- 业务层:实现图片转向量后,借助knn检索实现图搜图。
4.2 clip-ViT-B-32-multilingual-v1工具选择
sentence-transformers/clip-ViT-B-32-multilingual-v1是OpenAI的CLIP-ViT-B32模型的多语言版本。
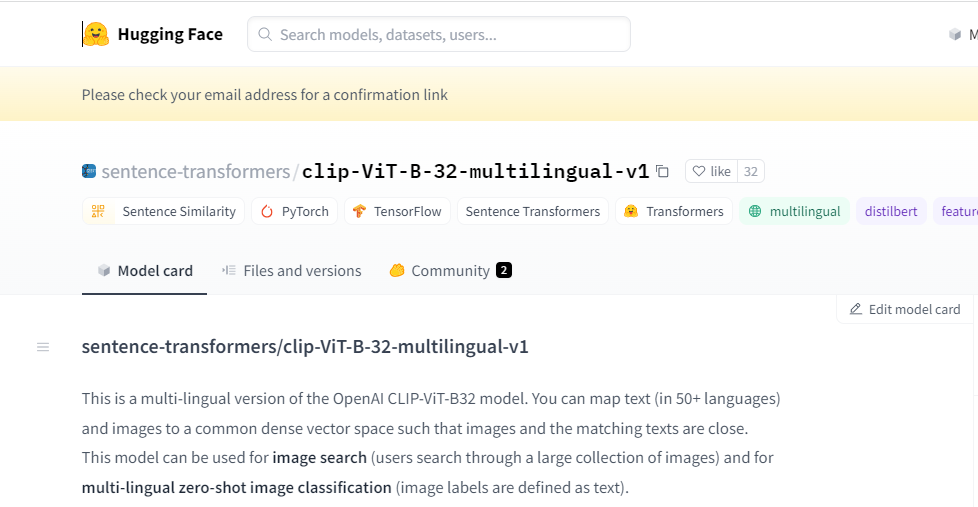
该模型可以将文本(50多种语言)和图像映射到一个公共的密集向量空间中,使得图像和匹配的文本紧密相连。这个模型可以用于图像搜索(用户通过大量的图像进行搜索)和多语言的图像分类(图像标签被定义为文本)。
模型地址:https://huggingface.co/sentence-transformers/clip-ViT-B-32-multilingual-v1
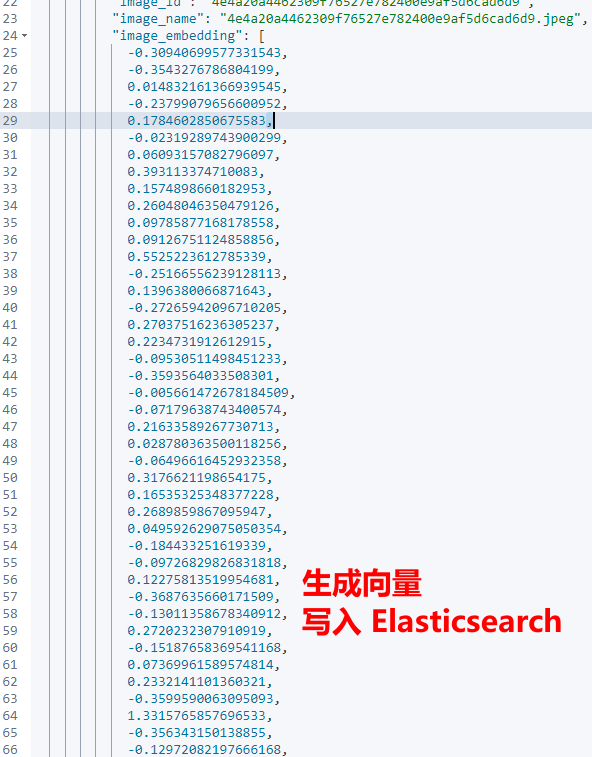
4.3 生成向量
如下的函数能将已有数据集图片生成向量。
model.encode(image)
生成的向量参考如下:
4.4 执行检索
POST my-image-embeddings/_search
{
"knn" : {
"field" : "image_embedding",
"k" : 5,
"num_candidates": 10,
"query_vector" : [
-0.7245588302612305,
0.018258392810821533,
-0.14531010389328003,
-0.08420199155807495,
.....省略.......
]
},
"fields": [
"image_id",
"image_name",
"relative_path"
]
}
登录后复制
如上搜索请求使用了Elasticsearch的k-NN (k-最近邻) 插件来查找与query_vector最接近的图像。
具体的参数含义如下:
| 参数 | 含义 |
|---|---|
| knn | 表示将使用k-最近邻搜索。 |
| field | 定义了执行k-NN搜索的字段。在此例中,image_embedding 字段应包含图像的嵌入向量。 |
| num_candidates | 是一个控制搜索精度和性能权衡的选项。在一个大的索引中,寻找确切的k个最近邻居可能会很慢。因此,k-NN插件首先找到num_candidates个候选,然后在这些候选中找到k个最近邻居。在此例中,num_candidates: 10 ,表示首先找到10个候选,然后在这些候选中找到5个最近邻居。 |
| query_vector | 要比较的查询向量。k-NN插件会计算这个向量与索引中的每个向量的距离,然后返回距离最近的k个向量。在此例中,query_vector 是一个大的浮点数列表,代表图像的嵌入向量。 |
| fields | 定义了返回的字段。在此例中,搜索结果将只包含image_id,image_name,和relative_path字段。如果不指定 fields参数,搜索结果将包含所有字段。 |
4.5 图搜图结果展示
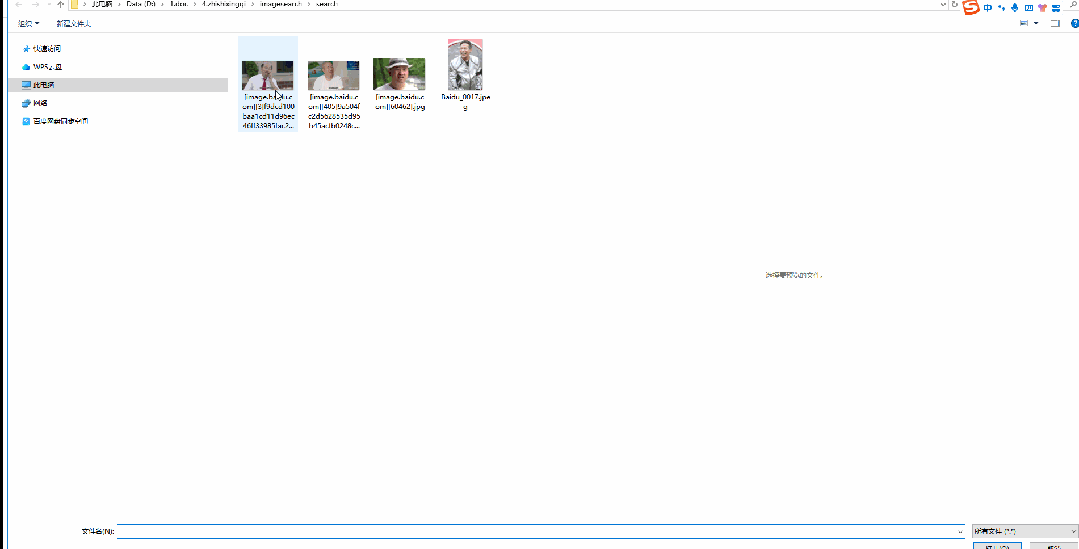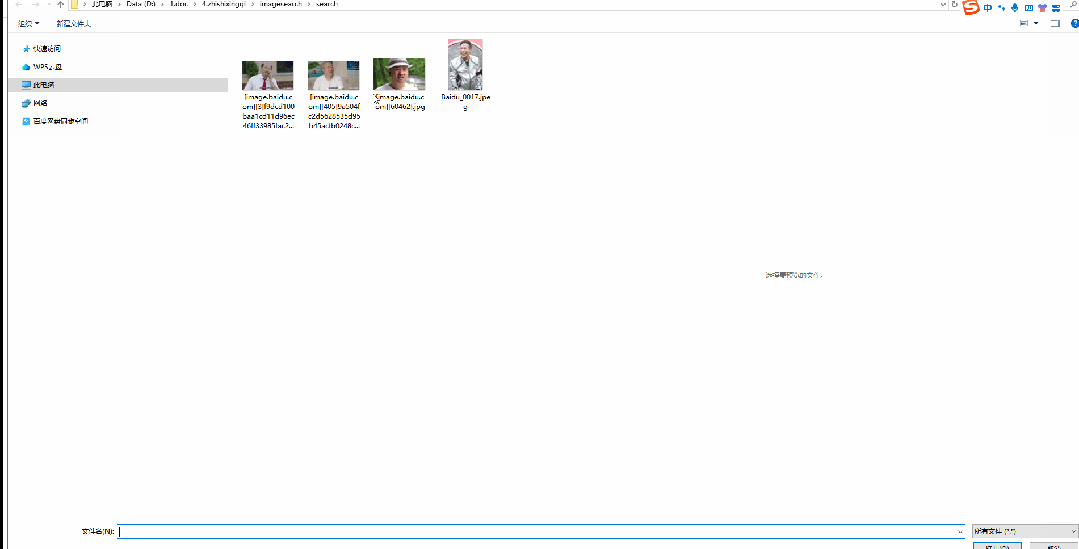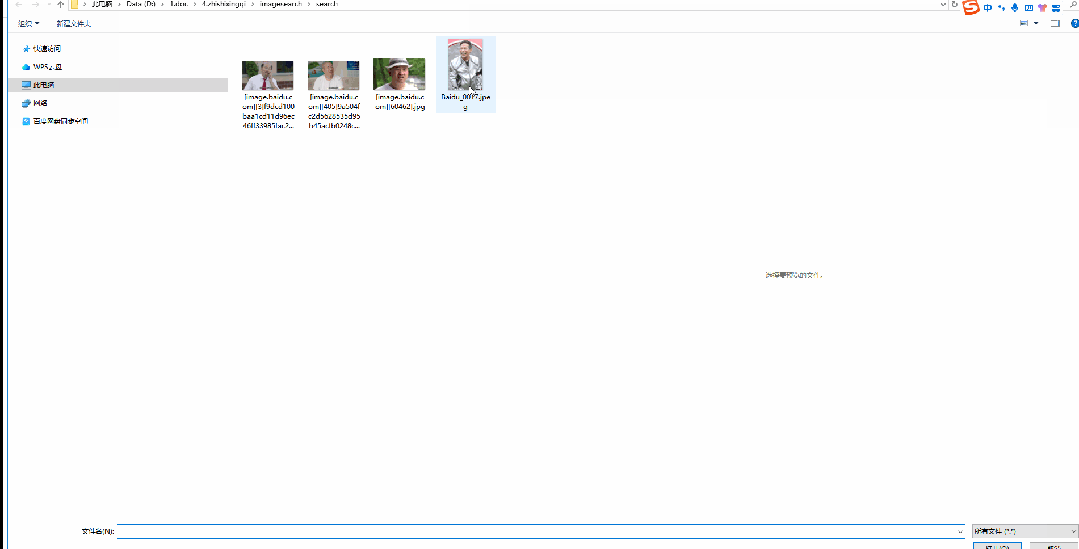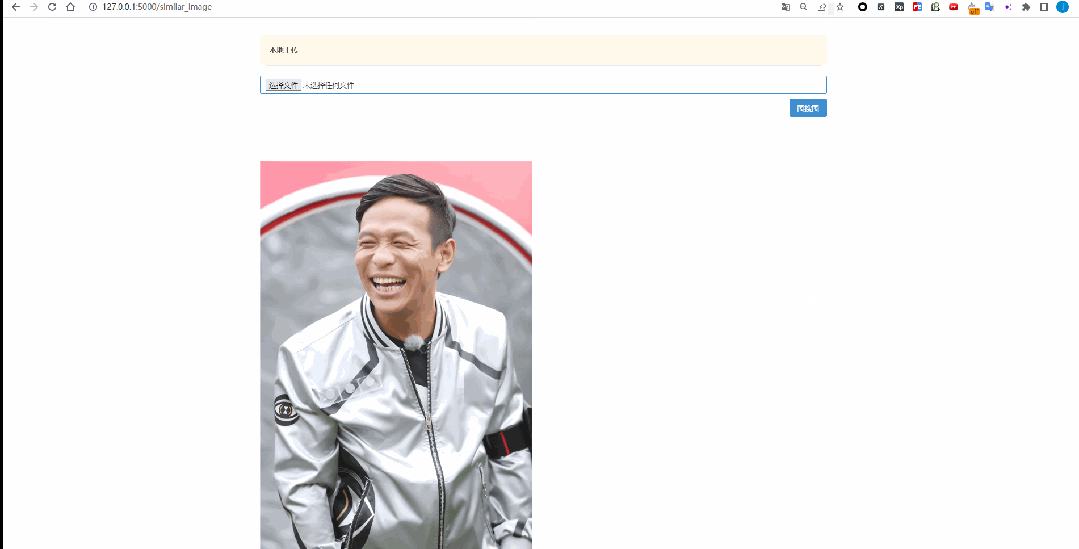
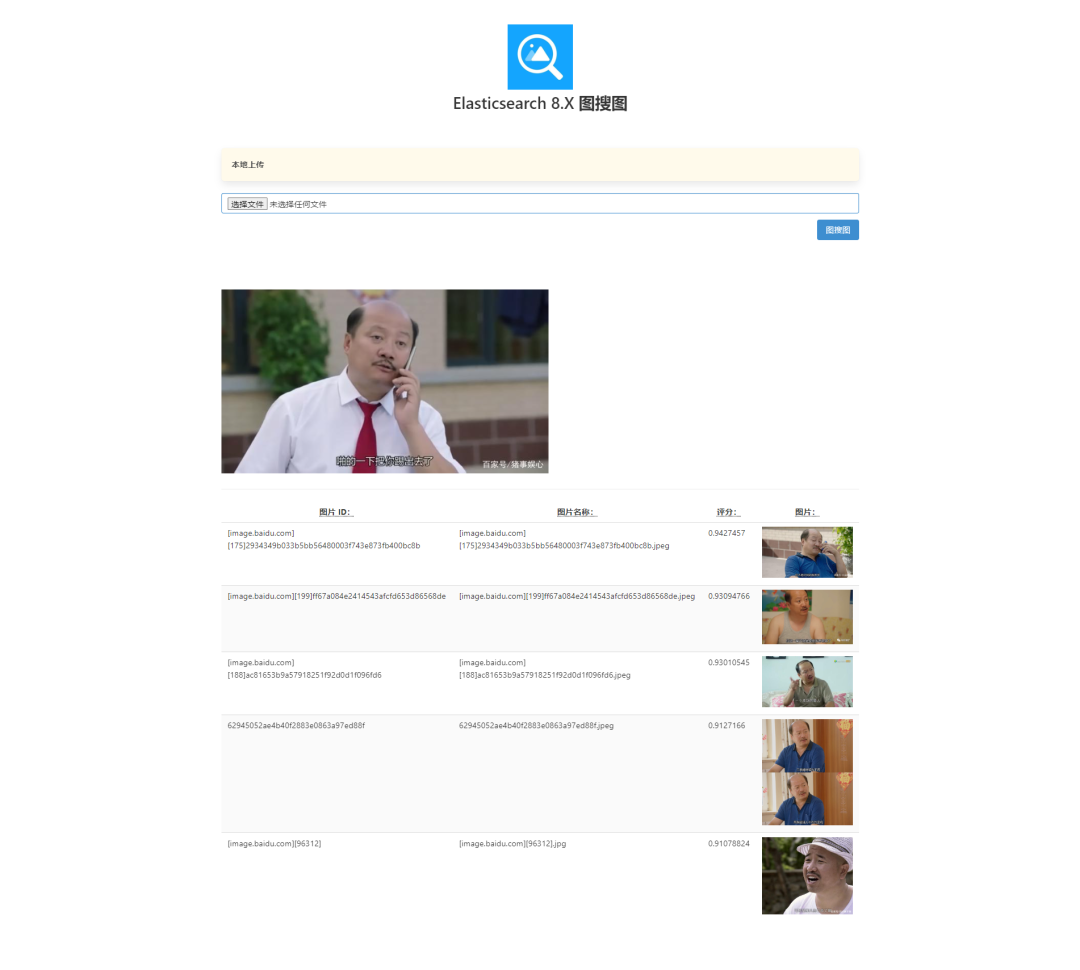
5、小结
总结一下,图搜图功能的实现重点在于两个关键的组件:Elasticsearch和预训练模型 sentence-transformers/clip-ViT-B-32-multilingual-v1。
Elasticsearch,作为一个基于Lucene的搜索服务器,为分布式多用户全文搜索提供了一个基于RESTful web接口的平台。另一方面,sentence-transformers/clip-ViT-B-32-multilingual-v1,这个预训练模型,基于OpenAI的CLIP模型,可以生成文本和图像的向量表示,这对于比较文本和图像的相似性至关重要。
在具体实现过程中,每个图像的特征都由预训练模型提取,得到的向量可以视作图像的数学表示。这些向量将存储在Elasticsearch中,为图搜图功能提供了一个高效的最近邻搜索机制。当有新的图像上传进行搜索时,同样使用预训练模型提取特征,得到向量,并与Elasticsearch中存储的图像向量进行比较,以找出最相似的图像。
整个过程体现了预训练模型在图像特征提取中的重要作用,以及Elasticsearch在进行高效最近邻搜索中的强大能力。两者的结合为图搜图功能的实现提供了一个可靠的技术支持。
参考
- 1、https://huggingface.co/sentence-transformers/clip-ViT-B-32-multilingual-v1
- 2、https://github.com/rkouye/es-clip-image-search
- 3、https://github.com/radoondas/flask-elastic-image-search
- 4、https://www.elastic.co/guide/en/elasticsearch/reference/current/knn-search.html
- 5、https://unsplash.com/data
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!