从千问Agent看AI Agent——我们很强,但还有很长的路要走
前言
最近双十一做活动买了台新电脑,显卡好起来了自然也开始大模型的学习工作了,这篇文章可能是该系列的第一弹,本地私有化部署千问agent,后面还会尝试一些其他的大模型结合本地知识库或者做行业垂直模型训练的,一步一步慢慢来吧。
AI Agent
背景介绍
随着今年国外GPT4.0、claude2的出现,在加上国内“百模大战”的盛况,整个大模型领域是真的越来越卷了,但是卷也意味着会出现更多的新赛道,由此 AI Agent 的概念应运而生(2、3月)。
首先开始专注Agent领域的是OpenAI的创始成员Andrej Karpathy,它也曾在一次黑客松演讲(6月)中表示与大模型训练相比,OpenAI内部目前更关注Agent领域,这也侧面说明现在agent的火爆不是一蹴而就的,而是已经被“安排”好了的下一步。
那么,到底什么是agent?我们为什么需要agent呢?agent能带来哪些好处呢?
五层基石理论
在真正进入agent之前,我想先抛出五层基石理论。这个理论的正确性和时效性有待考量,但是至少就目前来看是合理且中肯的。
Seednapse AI创始人提出了构建AI应用的五层基石理论,包括Models、Prompt Templates、Chains、Agent 和 Multi-Agent。这五层基石为不同领域的开发者提供了灵活的工具,让他们能够更轻松地构建自己的Agent应用。
-
Models,也就是我们熟悉的调用大模型API。
-
Prompt Templates,在提示词中引入变量以适应用户输入的提示模版。
-
Chains,对模型的链式调用,以上一个输出为下一个输入的一部分。
-
Agent,能自主执行链式调用,以及访问外部工具。
-
Multi-Agent,多个Agent共享一部分记忆,自主分工相互协作。

定义
我查阅了十余篇文献,其中提到最多的就是:**在大模型的背景下,Agent可以被理解为能够自主理解、规划和执行复杂任务的系统。**但是这个回答也是基于某种背景下来理解的,如果单纯的来解释AI Agent,我个人觉得它是:一种能够自主感知环境、进行决策和执行动作的智能实体(智能体、智能助理),能够让人们以自然语言为交互方式高自动化地执行和处理专业或繁复的工作任务,从而极大程度释放人员精力。
为什么需要Agent
大语言模型的浪潮推动了 AI Agent 相关研究快速发展,AI Agent 是当前通往 AGI 的主要探索路线。大模型庞大的训练数据集中包含了大量人类行为数据,为模拟类 人的交互打下了坚实基础;另一方面,随着模型规模不断增大,大模型涌现出了上 下文学习能力、推理能力、思维链等类似人类思考方式的多种能力。将大模型作为** AI Agent 的核心大脑,就可以实现以往难以实现的将复杂问题拆解成可实现的子任 务、类人的自然语言交互等能力。由于大模型仍存在大量的问题如幻觉、上下文容 量限制等,通过让大模型借助一个或多个 Agent **的能力,构建成为具备自主思考决策和执行能力的智能体,成为了当前通往 AGI 的主要研究方向。
在特定行业场景中,通用大模型具有的泛化服务特性,很难在知识问答、内容生成、业务处理和管理决策等方面精准满足用户的需求。
因此,让通用大模型学习行业知识和行业语料成为行业大模型,再进一步学习业务知识和专业领域工具演进为场景大模型,是生成式AI深入业务场景,承担更复杂任务的关键路径。这一过程的实现,让大模型的持续进化最终以AI Agent的产品形态,开始了对业务的流程及其管理和服务模式的重构与优化。
Agent的好处
正如OpenAI联合创始人安德烈·卡帕斯(Andrej Karpathy)认为,在各类行业组织对数字化实体的打造进程中,对于通用人工智能(AGI)的应用,将广泛采用AI Agent的产品形式开展业务,而来自于各行业领域的开发人员和创业者们,将比通用大模型的开发商们更具有对AI Agent的开发优势。AI Agent,也被越来越多的人认可为是数字经济时代深刻赋能各行各业的高效生产力工具。
不同于传统的人工智能,AI Agent 具备通过独立思考、调用工具去逐步完成给 定目标的能力。AI Agent 和大模型的区别在于,大模型与人类之间的交互是基于 prompt 实现的,用户 prompt 是否清晰明确会影响大模型回答的效果。而 AI Agent 的工作仅需给定一个目标,它就能够针对目标独立思考并做出行动。和传统的 RPA 相比,RPA 只能在给定的情况条件下,根据程序内预设好的流程来进行工作的处 理,而 AI Agent 则可以通过和环境进行交互,感知信息并做出对应的思考和行动。
如何构建Agent
一个基于大模型的** AI Agent **系统可以拆分为大模型、规划、记忆与工具使用四个组 件部分。**AI Agent **可能会成为新时代的开端,其基础架构可以简单划分为 Agent = LLM + 规划技能 + 记忆 + 工具使用,其中 LLM 扮演了 Agent 的“大脑”,在这个系统中提供推理、规划等能力。
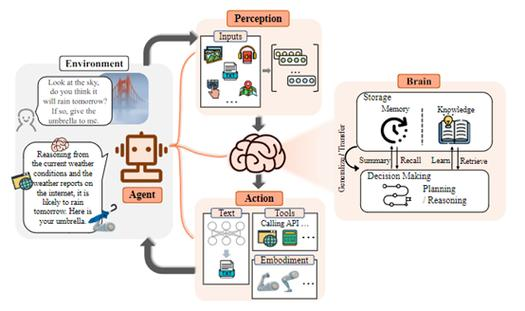
由上图可见,LLM-based Agent的概念框架,由大脑、感知、行动三个部分组成。作为控制器,大脑模块承担记忆、思考和决策等基本任务;感知模块负责感知和处理来自外部环境的多模态信息;行动模块负责使用工具执行任务并影响周围环境。下面还是简要介绍一下这三个模块:
大脑模块
是上述框架的核心,主要由大模型去做。借助大模型强大的自然语言交互能力,大脑可以很好的与外界通过自然语言进行交互,即准确理解感知模块输入的信息和生成准确的输出文本反馈。除了与外界交互,更重要的是其强大的推理、分析和决策能力。这些能力是通过大模型的训练自动涌现的。目前也没有一个特别合理的解释,说明为什么简单的语言模型,当数据量和模型参数到达一定规模,就会涌现出之前没有预料到的能力。当然,想要进行准确的推理、分析和决策,还需要一定的知识作为支撑,这些知识包括常识知识和领域知识等。大模型掌握了非常丰富全面的通用领域的尝试知识,但是对于特定领域知识还是有限。具体内容包括:自然语言交互、知识、记忆、记忆检索方法、推理和规划、可迁移性和通用性。
运行机制:为确保有效交流,自然语言交互能力 至关重要。在接收感知模块处理的信息后,大脑模块首先转向存储,在知识中检索 并从记忆中回忆 。这些结果有助于Agent制定计划、进行推理和做出明智的决定 。此外,大脑模块还能以摘要、矢量或其他数据结构的形式记忆Agent过去的观察、思考和行动。同时,它还可以更新常识和领域知识等知识,以备将来使用。LLM-based Agent还可以利用其固有的概括和迁移能力来适应陌生场景 。
感知模块
指对大脑的输入控制。大脑当前最成熟的感知手段还是自然语言输入。但是人类真是的感知场景的多模态的,即我们感知一个事物主要是通过眼睛去看,通过耳朵去听,通过文字去理解等。因此,大模型的感知部分未来的发展趋势一定是多模态融合的,尤其是文本+图片(视频)+音频。当然,在特定问题上也需要对其他感知形式进行处理,最典型的就是传感器产生的数据的感知。具体内容包括:文本输入、视觉输入、听觉输入、其他输入。
行动模块
当大脑对感知的多模态信息进行整合与分析之后,就需要根据决策内容进行对应行动。最简单的行动就是返回一段文本,把答案或者执行计划用文本形式返回。稍微复杂一些的话,就是让大模型直接调用一些工具去执行操作。这个就需要大模型知道都有哪些工具,每个工具的用途是什么,这些工具的调用方法等。对于不同的需求,大模型会找到适合的工具去调用,并返回结果。这些工具可以是任意能够通过API调用的服务,当前用的最多的是搜索引擎服务。当然,对于嵌入到机器人上,执行的行为可以更复杂,例如具体的机械臂的操作等。具体内容包括:文本输出、工具使用、具身行动。
千问Agent
废话不多说,先直接甩上链接。
千问agent:https://github.com/QwenLM/Qwen-Agent
这里我再说说结论,用了几次之后感觉还凑合(毕竟我这个人很少给人差评的),具备了一些基础能力,就日常办公而言还行,但是跟我前文所述的智能体相比还是有很大的差距,甚至可以说目前的千问agent只是初具雏形。下面是摘自该项目的介绍:
Qwen-Agent 是一个代码框架,用于发掘开源通义千问模型(Qwen)的工具使用、规划、记忆能力。 在 Qwen-Agent 的基础上,我们开发了一个名为 BrowserQwen 的 Chrome 浏览器扩展,它具有以下主要功能:
-
与Qwen讨论当前网页或PDF文档的内容。
-
在获得您的授权后,BrowserQwen会记录您浏览过的网页和PDF材料,以帮助您快速了解多个页面的内容,总结您浏览过的内容,并减少繁琐的文字工作。
-
集成各种插件,包括可用于数学问题求解、数据分析与可视化、处理文件等的代码解释器(Code Interpreter)。
这里也可以看出,它提供的功能其实真的很基础但实用。
本地部署千问Agent
1、设置Python安装默认源(可选)
pip config set global.index-url http://mirrors.aliyun.com/pypi/simple/
将 pip 的默认软件包源(PyPI)更改为阿里云镜像源,好处就是下载速度更快和链接更稳定,但是要注意的是使用这个命令修改全局配置会影响所有使用 pip 安装软件包的项目。如果只想在特定项目中使用该镜像源,可以在项目的根目录下创建一个名为 .pip 或 pip.ini 的文件,并将相同的配置内容写入其中,这样只会影响该项目。
2、创建虚拟环境
conda create -n qwen-agent python=3.10 -y
conda activate qwen-agent
第一句命令 conda create -n qwen-agent python=3.10 -y 是指使用conda来创建一个名为"qwen-agent"的虚拟环境,并指定要安装的Python版本为3.10。其中,-n qwen-agent 指定了要创建的虚拟环境的名称为"qwen-agent",python=3.10 指定了要在该环境中安装的Python版本为3.10,-y 则表示在执行过程中不需要确认操作,直接进行安装。
第二句命令 conda activate qwen-agent 是用于激活名为"qwen-agent"的虚拟环境。激活后,系统中将会使用该虚拟环境中安装的Python版本和相关包来执行Python程序。激活后,命令行提示符通常会显示当前已经激活的虚拟环境名称,如"(qwen-agent)“,以示当前环境已经切换为"qwen-agent”。
3、安装pytorch
pip install torch2.0.0+cu118 torchvision0.15.1+cu118 torchaudio==2.0.1 --index-url https://download.pytorch.org/whl/cu118
这条命令是使用pip安装特定版本的PyTorch、torchvision和torchaudio库,同时指定了运行所需的CUDA版本为cu118,并将下载源设置为PyTorch官方提供的URL。
具体来说,命令中的参数解释如下:
-
torch==2.0.0+cu118: 这表示要安装的PyTorch版本是2.0.0,并且需要与CUDA版本cu118兼容。PyTorch是一个用于深度学习的开源机器学习库。
-
torchvision==0.15.1+cu118: 这表示要安装的torchvision版本是0.15.1,并且需要与CUDA版本cu118兼容。torchvision是PyTorch的一个独立软件包,用于对图像和视频数据进行处理。
-
torchaudio==2.0.1: 这表示要安装的torchaudio版本是2.0.1。torchaudio是一个用于处理音频数据的PyTorch扩展库。
-
–index-url https://download.pytorch.org/whl/cu118: 这是一个额外的选项,用于指定下载PyTorch和相关库时要使用的镜像源或索引URL。在这里,https://download.pytorch.org/whl/cu118 是PyTorch官方提供的针对CUDA 11.1.1版本的URL地址,它指示pip从该地址下载所需的库文件。
4、安装 flash-attention
git clone -b v1.0.8 https://github.com/Dao-AILab/flash-attention; cd flash-attention
pip uninstall -y ninja && pip install ninja
cd flash-attention && pip install .
5、部署 Qwen 模型服务
安装依赖
git clone https://github.com/QwenLM/Qwen.git; cd Qwen
pip install -r requirements.txt
pip install fastapi uvicorn openai “pydantic>=2.3.0” sse_starlette
启动模型服务,通过 -c 参数指定模型版本
-
指定 --server-name 0.0.0.0 将允许其他机器访问您的模型服务
-
指定 --server-name 127.0.0.1 则只允许部署模型的机器自身访问该模型服务
python openai_api.py --server-name 0.0.0.0 --server-port 7905 -c Qwen/Qwen-7B-Chat
目前,支持指定的-c参数为以下模型,按照GPU显存开销从小到大排序:
-
Qwen/Qwen-7B-Chat-Int4
-
Qwen/Qwen-7B-Chat
-
Qwen/Qwen-14B-Chat-Int4
-
Qwen/Qwen-14B-Chat
对于7B模型,请使用2023年9月25日之后从官方HuggingFace重新拉取的版本,因为代码和模型权重都发生了变化。
6、部署 Qwen-Agent
安装依赖
git clone https://github.com/QwenLM/Qwen-Agent.git
cd Qwen-Agent
pip install -r requirements.txt
启动数据库服务,通过 --model_server 参数指定您在 Step 1 里部署好的模型服务
-
若 Step 1 的机器 IP 为 123.45.67.89,则可指定 --model_server http://123.45.67.89:7905/v1
-
若 Step 1 和 Step 2 是同一台机器,则可指定 --model_server http://127.0.0.1:7905/v1
python run_server.py --model_server http://127.0.0.1:7905/v1 --workstation_port 7864
7、浏览器访问Qwen-Agent
打开 http://127.0.0.1:7864/ 来使用工作台(Workstation)的创作模式(Editor模式)和对话模式(Chat模式)。
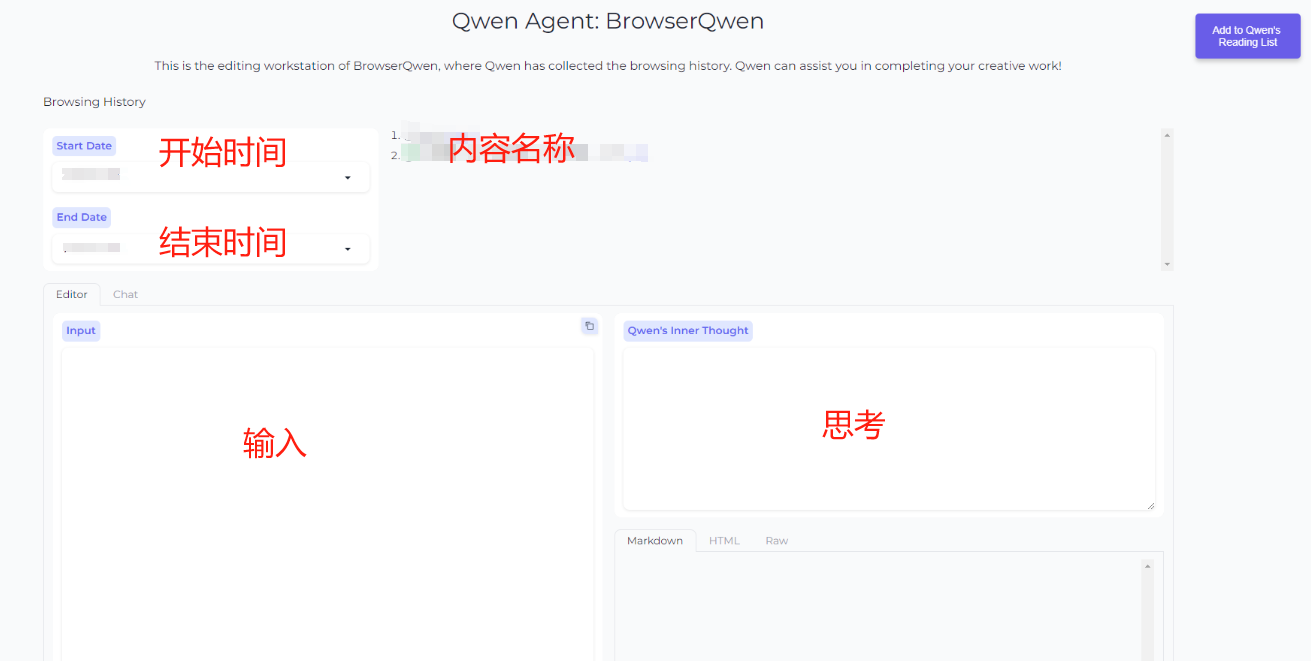
8、安装浏览器助手
安装BrowserQwen的Chrome插件(又称Chrome扩展程序):
-
打开Chrome浏览器,在浏览器的地址栏中输入 chrome://extensions/ 并按下回车键;
-
确保右上角的 开发者模式 处于打开状态,之后点击 加载已解压的扩展程序 上传本项目下的 browser_qwen 目录并启用;
-
单击谷歌浏览器右上角扩展程序图标,将BrowserQwen固定在工具栏。
【注意】:安装Chrome插件后,需要刷新页面,插件才能生效。
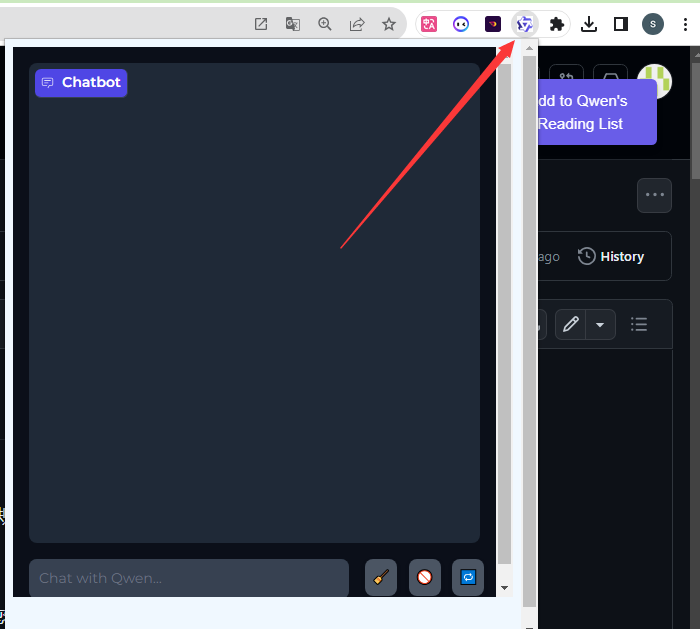
当您想让Qwen阅读当前网页的内容时:
-
请先点击屏幕上的 Add to Qwen’s Reading List 按钮,以授权Qwen在后台分析本页面。
-
再单击浏览器右上角扩展程序栏的Qwen图标,便可以和Qwen交流当前页面的内容了。
结语
在《开源大模型LLaMA 2扮演Android角色?AI大模型创业会集体失败吗?》(https://baijiahao.baidu.com/s?id=1772053289038071546) 一文中曾经提到:大模型落地的方式是系统型超级应用。但系统型超级应用有点像被杜撰出来的一个词,所以这次从 AI Agent 的角度来更加具体的描述下它。
AI Agent 非常关键,没有它我们就无法扩展大模型的应用边界,无法扩展边界就无法完成大模型的成功商业化,无法成功商业化AI可能就会再亏损十年。人工智能如果仅止于现在看到的内容生成等几项应用,就还是单薄的。能不能把价值传递到更多的场景,核心就看AI Agent,所以说AI Agent是大模型与场景间价值传递的桥梁。
对比千问的agent,其实和理想中的AI Agent还是有很大差距的,但是好在我们还有时间去研究、去挖掘,未来的路虽然充满挑战,但也充满希望。随着技术的不断发展和突破,相信千问Agent也会不断向着理想中的方向迈进。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 裸机开发(1)-汇编基础
- 为什么员工都非常抵触「绩效考核」,该怎么办呢?
- AnyDoor任意门:零样本物体级图像定制化
- Lambda表达式??项目中的常见使用方式,通过具体案例总结Lambda的常用写法
- sg - 8504 ca编程晶体振荡器 (SPXO)
- JVM入门到入土-Java虚拟机寄存器指令集与栈指令集
- 阶段五接口测试第四章接口测试框架开发
- 【无标题】
- 07-项目打包 & React Hooks
- 机器人说明书---名词解释027课_python语言_匿名函数