Linux之进程(四)(进程地址空间)
目录
一、程序地址空间
我们先来看看下面这张图。这张图是我们在学习语言时就见到过的内存区域划分图。?
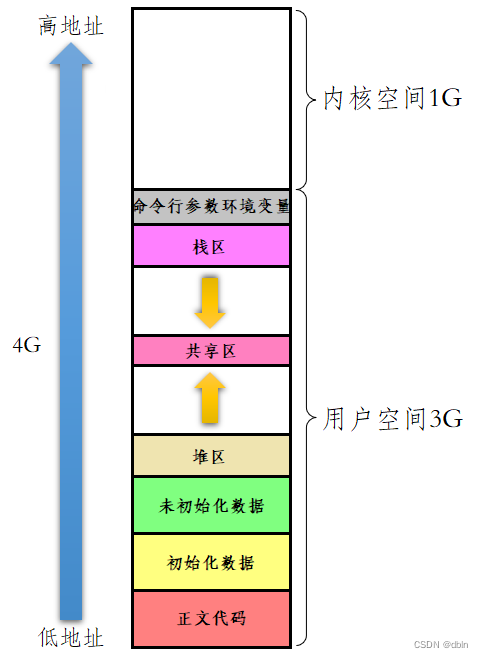
下面我们在Linux下看一看内存区域是不是也是这么划分的。
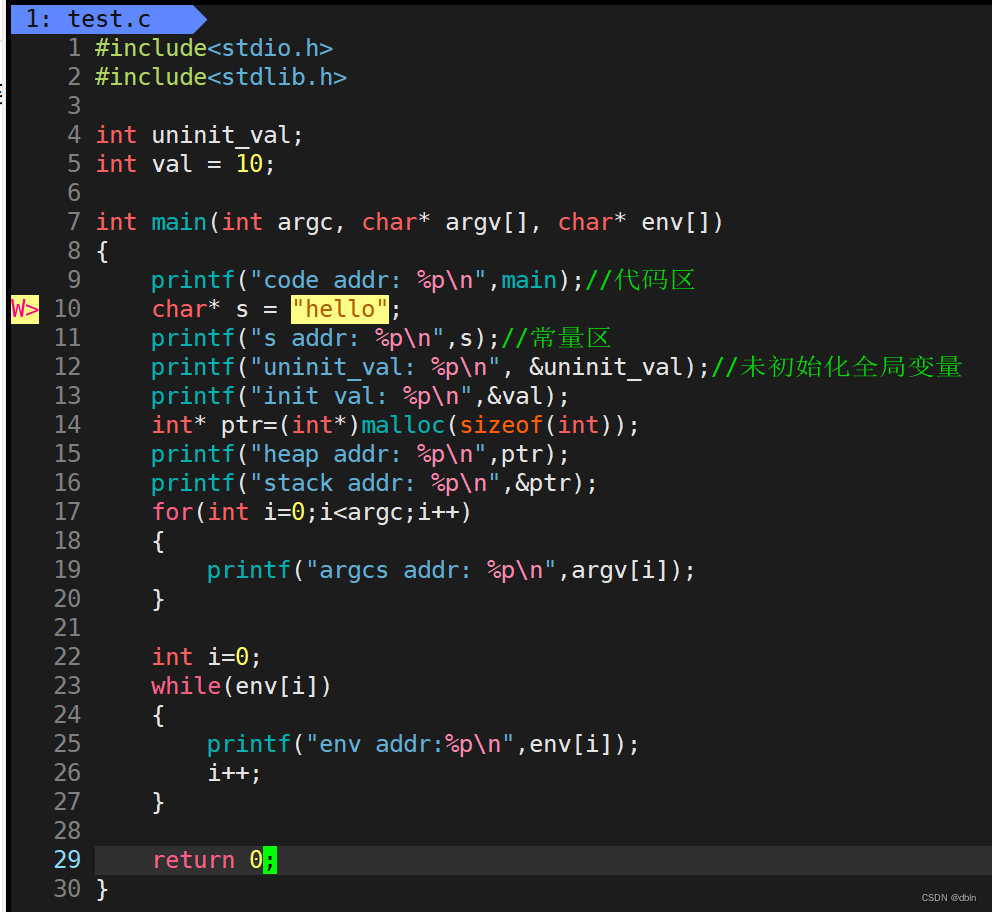

可见在Linux下也是符合上面的分布的。
那么下面我们来看看下面的代码:?

上面的代码中用fork函数创建了一个子进程,其中让子进程相将全局变量g_val该从100改为200后打印,而父进程先休眠3秒钟,然后再打印全局变量的值。
按我们之前所学的来说子进程打印的全局变量的值为200,而父进程是在子进程将全局变量改后再打印的全局变量,而且全局变量在整个程序中应该只有一个,那么也应该是200,但是代码运行结果如下:

从上面的结果中,我们可以看到父进程打印的全局变量g_val的值为100,而子进程打印的是改变后的200。但是,更奇怪的是在父子进程中打印的全局变量g_val的地址是一样的,也就是说父子进程在同一个地址处读出的值是不同。
这就很奇怪了。同一个地址处却存的是不同的值,这和我们之前所学的知识又冲突了。同一个地址的值不应该是一样的吗?这到底是怎么回事呢?
最好的解释就是:在同一个地址处获取到的值却不同,这只能说明我们打印出来的地址绝对不是物理地址。?那是什么地址呢?
事实上,我们在语言层面上打印出来的地址都不是物理地址,而是虚拟地址。所以就算父子进程当中打印出来的全局变量的地址(虚拟地址)完全相同,但是两个进程当中全局变量的值却是不同的。因为每一个进程都有一个属于自己的地址空间!所以即使是地址名相同,也是在不同的地址空间中。
那么这就要求操作系统通过某种方式帮助用户将虚拟地址转换成物理地址。
二、进程地址空间
1、概念
所以之前说‘程序的地址空间’是不准确的,准确的应该说成 ’进程地址空间‘。我们所说的地址空间区域划分并不是对物理内存进行区域划分,而是对进程地址空间进行区域划分。
进程地址空间不是内存,其本质上是内存中的一种内核数据结构,在Linux当中进程地址空间具体由结构体mm_struct实现。所以对于进程地址空间的区域划分,本质上是定义每个区间的结束和开始。
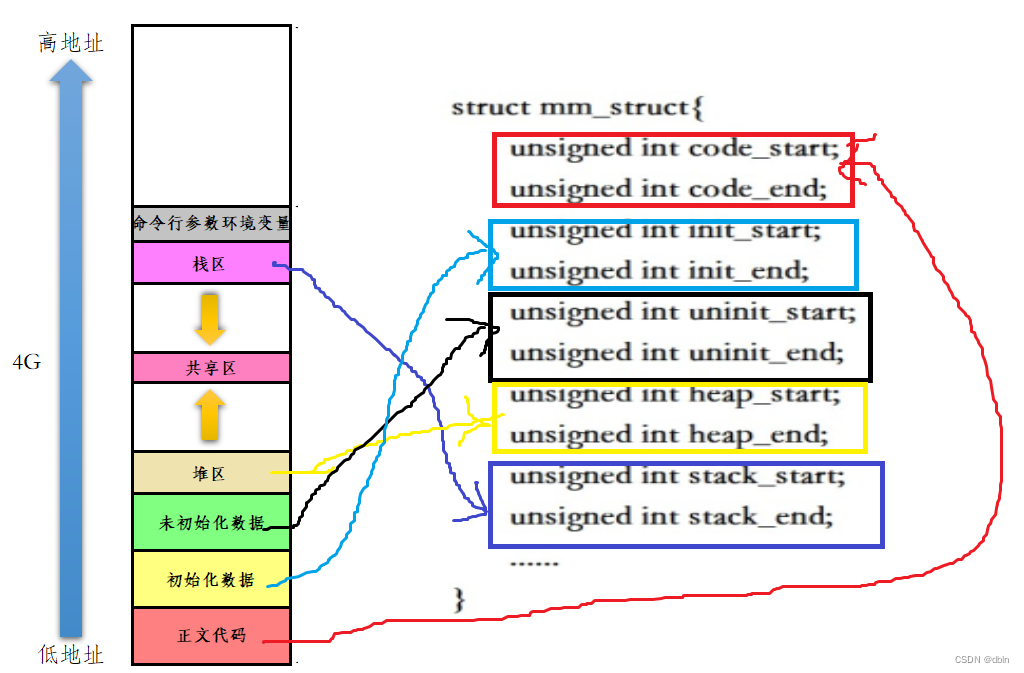
在结构体mm_struct当中,各个边界之间的每一个部分都代表一个虚拟地址,这些虚拟地址通过页表映射与物理内存建立联系。?
每个进程被创建时,其对应的进程控制块(task_struct)和进程地址空间(mm_struct)也会随之被创建。而操作系统可以通过进程的task_struct找到其对应的mm_struct,因为task_struct当中有一个结构体指针存储的是mm_struct的地址。
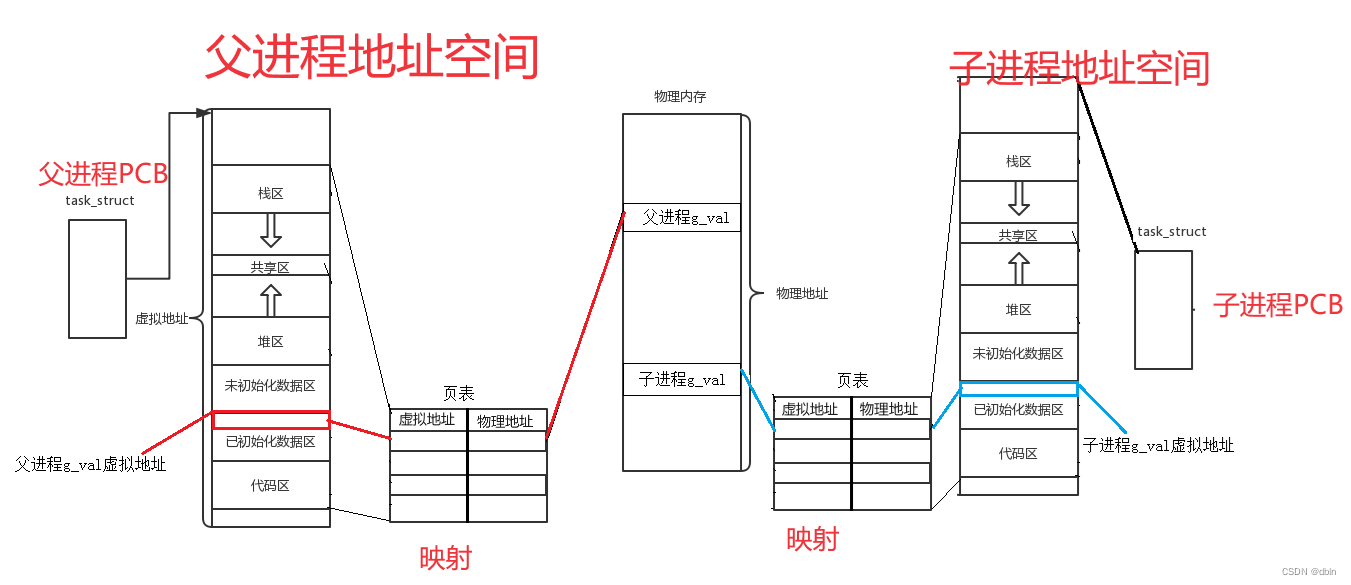
所以上面的代码结果我们就可以解释了。同一个变量,地址相同,其实是虚拟地址相同,内容不同其实是被页表映射到了不同的物理地址。
父子进程的进程地址空间当中的各个虚拟地址分别通过页表映射到物理内存的某个位置。
当子进程刚刚被创建时,子进程和父进程的数据和代码是共享的,即父子进程的代码和数据通过页表映射到物理内存的同一块空间。只有当父进程或子进程需要修改数据时,才将父进程的数据在内存当中重新开一块空间,拷贝一份,然后再进行修改。
这种在需要进行数据修改时再进行拷贝的方法,称为写时拷贝。
2、写时拷贝
~ 为什么要有写时拷贝?
进程具有独立性。多进程运行,需要独享各种资源,多进程运行期间互不干扰,不能让子进程的修改影响到父进程,也不能让父进程影响子进程。
~ 为什么不在创建子进程的时候就进行数据的拷贝?
子进程不一定会使用父进程的所有数据,并且在子进程不对数据进行写入的情况下,没有必要对数据进行拷贝,我们应该按需分配,在需要修改数据的时候再分配(延时分配),这样可以高效的使用内存空间。
写时拷贝是一种延时申请的技术,可以提高整机内存的使用率。
3、为什么要有进程地址空间
每一个进程都有自己的地址空间和页表,这样不仅麻烦而且理解成本也高,那么为什么要有虚拟地址?
~?进程地址空间保证了数据的安全性
首先,我们先来看看如果我们直接使用物理内存会发生什么。如下图:我们在进程1中定义了一个指针char* ,因为我们现在是直接使用物理内存,所以char*直接指向了一个物理内存。如果我们进程1中的代码出现了错误,比如char* 指向了进程2中的地址,那么这样就会出问题,进程1的指针可以改变进程2的内容了。
所以操作系统不能让用户直接使用物理内存,于是就有了进程地址空间。

每个进程都有自己的进程地址空间,所有的进程都要通过页表映射到物理内存,而不同的进程会被映射到不同的物理内存中。万一进程越界非法访问、非法读写时,页表还可以进行拦截,不让其访问。而直接访问物理内存是无法拦截非法访问的,所以保证了内存数据的安全性。
~?可以更方便的进行进程和进程的数据代码的解耦,保证了进程独立性
对于每一个进程而言,它们都有只属于自己的地址空间及页表,不同的进程通过页表映射到不同的物理内存上,所以一个进程数据的改变不会影响到另一个进程,保证了进程的独立性。可以做到物理内存分配和进程的管理之间不会相互影响。
~ 将内存分布有序化
因为在理论上,进程可以加载到物理内存的任意位置,所以在物理内存中几乎所有的代码和数据都是乱序的,而在进程地址空间中代码和数据的分布位置都是确定的。但是因为页表的存在,它可以将虚拟地址和物理地址进行映射,所以在进程的视角上,所有的内存分布都是有序的。
四、总结
其实,程序在编译时,编译器就会给每一个变量、每一个函数都编写一个地址,这个地址就是虚拟地址。当程序被加载到物理内存中,虚拟地址会被填写进页表的左侧。然后将一个代码加载到内存的什么位置的这个物理地址填写到页表的右侧。这就是映射关系的构建。
我们通常所说的地址,一般都是虚拟地址。而不是内存中的物理地址。
我们在语言中使用的new,malloc等申请的空间在本质上也都是申请的虚拟地址空间,而不是物理内存空间。而且申请了之后也不是直接拿到物理内存,只有当用户真正对物理地址空间进行访问的时候,才执行内存相关的管理算法,帮助用户从物理内存上申请空间,构建页表映射关系。然后用户再使用。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Python 用pytorch从头写transformer源码,一行一解释;机器翻译实例代码
- IO、NIO、IO多路复用
- AI智剪:一键批量剪辑,高效助力创作无限可能
- 【理论+实战】带你全面了解 RAG,深入探讨其核心范式、关键技术及未来趋势
- 智慧园区手机云巡更方案蓝牙信标应用
- 在Vue3中使用qrcode库实现二维码生成
- 06 栈
- 有没有一种可以通过扫码出入库的仓库管理软件,有库存预警,摆放货架号?
- QT实现USB通讯
- PFA试剂瓶耐强酸PFA取样瓶可储存高纯水、电子级清洗剂