机器学习(七) — 决策树
model 4 — decision tree
1 decision tree
1. component
usage: classification
- root node
- decision node
2. choose feature on each node
maximize purity (minimize inpurity)
3. stop splitting
- a node is 100% on class
- splitting a node will result in the tree exceeding a maximum depth
- improvement in purity score are below a threshold
- number of examples in a node is below a threshold
2 meature of impurity
use entropy( H H H) as a meature of impurity
H ( p ) = ? p l o g 2 ( p ) ? ( 1 ? p ) l o g 2 ( 1 ? p ) n o t e : 0 l o g 0 = 0 H(p) = -plog_2(p) - (1-p)log_2(1-p)\\ note: 0log0 = 0 H(p)=?plog2?(p)?(1?p)log2?(1?p)note:0log0=0

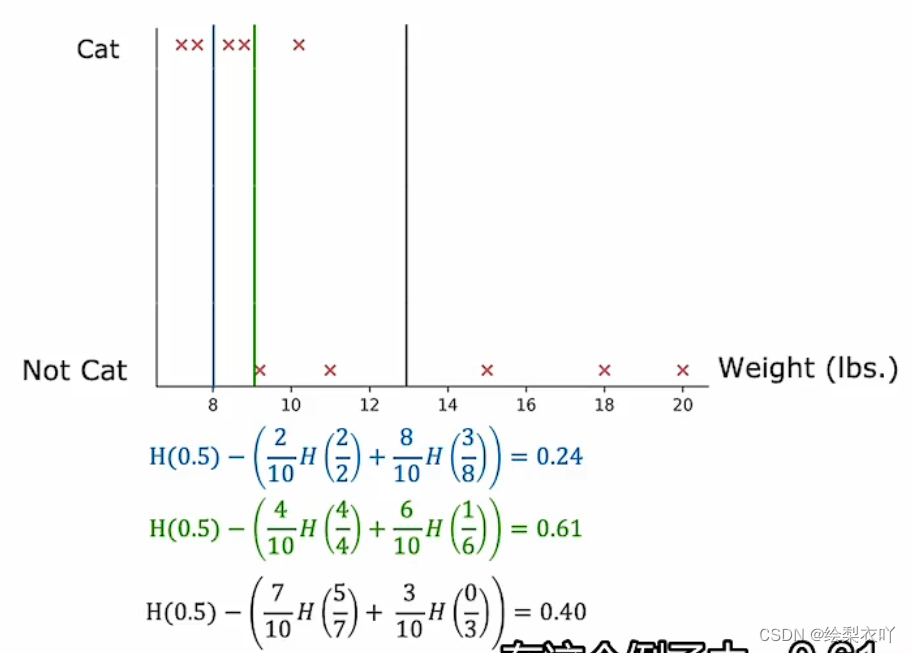
3 information gain
1. definition
i n f o m a t i o n _ g a i n = H ( p r o o t ) ? ( w l e f t H ( p l e f t ) + w r i g h t H ( p r i g h t ) ) infomation\_gain = H(p^{root}) - (w^{left}H(p^{left}) + w^{right}H(p^{right})) infomation_gain=H(proot)?(wleftH(pleft)+wrightH(pright))
2. usage
- meature the reduction in entropy
- a signal of stopping splitting
3. continuous
find the threshold that has the most infomation gain
4 random forest
- generating a tree sample
given training set of size m
for b = 1 to B:
use sampling with replacement to create a new training set of size m
train a decision tree on the training set
- randomizing the feature choice: at each node, when choosing a feature to use to split, if n features is available, pick a random subset of k < n(usually k = n k = \sqrt{n} k=n?) features and alow the algorithm to only choose from that subset of features
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java基础面试题汇总
- Python中使用os库进行文件重命名的实用案例
- 基于SpringBoot的足球青训俱乐部
- 歌曲《未来派》:来自歌手荆涛对未来的探索与期待
- 【C++11特性篇】lambda表达式玩法全解
- 微信公众号(小程序)验证URL和事件推送
- 【openGauss/MogDB使用mog_xlogdump解析 xlog文件内容】
- 【C++配置yaml】yaml-cpp使用
- SpringBoot操作world格式的文件与pdf格式的文件互转
- 王者荣耀与元梦之星联名小乔皮肤即将下架!