ICCV2023 | PTUnifier+:通过Soft Prompts(软提示)统一医学视觉语言预训练

论文标题:Towards Unifying Medical Vision-and-Language Pre-training via Soft Prompts
代码:https://github.com/zhjohnchan/ptunifier
Fusion-encoder type和Dual-encoder type。前者在多模态任务中具有优势,因为模态之间有充分的相互作用; 后者由于具有单模态编码能力,擅长单模态和跨模态任务。该论文PTUnifier统一这两种类型(这里的统一包括模型和输入模态)。
一、IDea
医学数据通常是多模态的,视觉数据(例如,放射照相、磁共振成像和计算机断层扫描)和文本数据(例如,放射学报告和医学文本)。在日常临床实践中成对收集的。医学视觉和语言预训练(MedVLP)旨在从大规模医学图像-文本对中学习通用表示,然后将其迁移到各种医疗任务中,有助于解决医疗领域的数据稀缺问题。
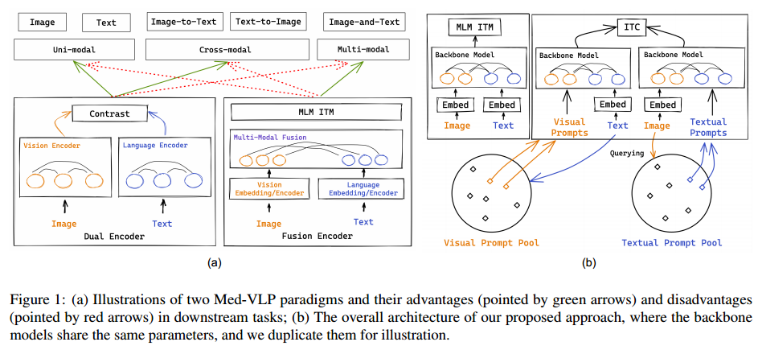
由于缺乏单模态编码,融合编码器不能有效地完成单模态任务和跨模态任务,而双编码器由于模态之间的交互不足,在多模态任务中表现不佳,如图1(a)所示。
二、Model(Bridging the Gap)
模型预训练可以表示为:

1、Unifying Inputs via Prompts
通过soft prompts 统一输入,以执行不同类型的任务。工作机制类似于DETR中的查询向量。
Compatibility using Soft Prompts
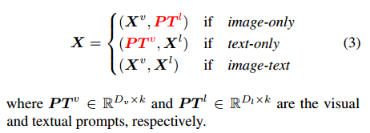
Scalability of Soft Prompts
构建了一个视觉/文本提示池,而不是 static prompts。prompt的选择取决于input embedding。定义一个视觉提示池V和一个文本提示池T。给定 visual embedding sequence Xv输入或 its textual embedding sequence Xl输入,进行池化操作(例如,平均/最大池化),得到现有模态的查询向量(记为qv或ql),即qv = pooling(Xv)和ql = pooling(Xl)。为了得到缺失模态的prompt,根据查询向量与缺失模态池中所有prompts的相似度得分来选择prompt:

Intuitive Explaination:将可视提示池视为一个查询库,其中存储了用于在缺少一个模态时提取单模态特征的query。
Unifying Multiple Pre-training Objectives
Masked Language Modeling (MLM)

Image-Text Matching (ITM)

Image-Text Contrast (ITC)

三、The Model Architecture
首先将视觉和文本标记映射到嵌入空间(Xv和Xl),这些带有或不带有prompts的token embedding将由相同的backbone Mθ共同处理。
1、Visual and Textual Embeddings
Visual:
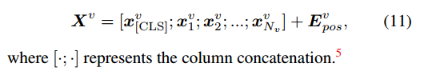
Textual:
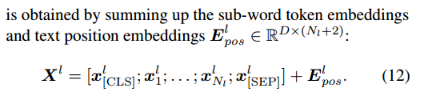
2、The Backbone Model
该模型可以是一个有效模型(包括单模态编码器和多模态融合模块),也可以是一个有效模型(即单个Transformer模型),特征提取后:

四、Experimental Settings
1、Pre-training Datasets
ROCO、MedICaT、MIMIC-CXR
2、Results
Main Results
现有的研究仅针对单一任务设计,而论文方法通常针对所有视觉和/或语言相关的任务,也就是说,没有针对特定任务进行任何量身定制的调整。

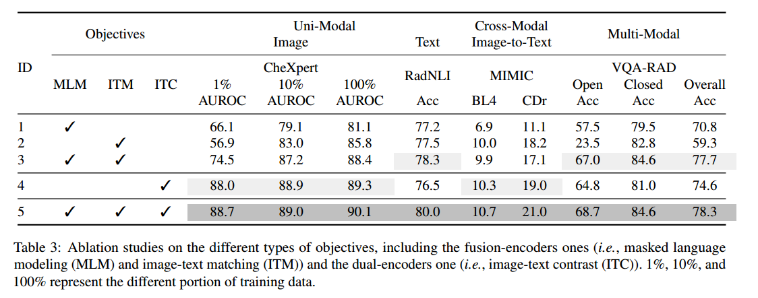
Ablation Study
融合编码器(即MLM和ITM)的目标模型(即ID 3和5)获得比没有它们的其他模型更强大的多模态表征。
双编码器的图像-文本对比学习有助于模型(即id4和id5)学习单模态图像表征和跨模态表征,并且使用ITC目标预训练的模型优于未使用ITC目标预训练的模型。
ITC目标并没有提高单模态文本分类任务的性能。
同时实现两类目标可以促进模型(即ID 5)在所有任务中获得最佳性能,从而证实了融合编码器和双编码器统一研究方向的可行性。
Effects of Soft Prompt
使用不同池大小(范围从0到2048)进行预训练。
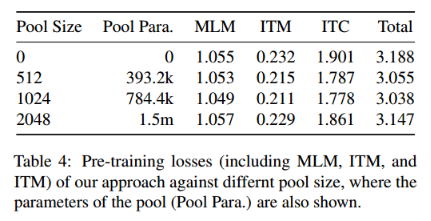
(i)虽然池大小的扩大导致参数数量的增加,但与总参数(350M)相比,引入的参数并不太多(少于0.5%);
(ii)所有有Soft Prompt ?Pools的模型都比没有Soft Prompt ?Pools(即池大小为0)的模型收敛性更好(收敛损失更小),证明了引入提示池的有效性;
(iii)发现设置合适的池大小很重要,当池大小设置为1024时,模型收敛效果最好。这可能是由于池大小控制了在预训练过程中存储的查询信息的数量,而具有大容量的大池可能会“吸收”预训练语料库中的太多噪声。
论文中有意思的是竟然做ITC预训练任务时,把两个模态拆开,分别在soft prompts pools里面找其对应的模态(visual->textual, textual->visual),这样在缺失一个模态的输入的时候,直接在pools中找即可。但是应该有个问题存在,pools中的向量就能准确代表缺失的模态吗?其实在小领域还好,但是在通用领域会不会受限(当然可以通过调节pools size来缓解)?是不是可以像VQ-VAE中使用向量字典的方式来组成缺失的目标对象,而不是直接计算相似度?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 压缩字符串 实现思路及练习题
- 从新手到高手,oppo手机录屏功能全掌握!
- golang csv parse error on line 1, column 1: bare “ in non-quoted-field
- 遥感卫星影像现拍,哪里想看拍哪里!
- 电商铺货上货接口API实现无货源上货(1688/淘宝/京东/拼多多)
- 代码随想录算法训练营29期Day16|LeetCode 104,559,111,222
- JVM篇:JVM内存结构
- 防止串扰可不止3W规则,还有这些方法
- 操作教程|MeterSphere UI测试+VNC:简单、快捷地查看UI测试实时执行详情
- ERA5合集,使用ERA5得到GNSS站点的温度,气压,水汽压,Tm和PWV合集,可以求五个参数