CnosDB如何确保多步操作的最终一致性?

背景
在时序数据库中,资源的操作是一个复杂且关键的任务。这些操作通常涉及到多个步骤,每个步骤都可能会失败,导致资源处于不一致的状态。例如,一个用户可能想要在CnosDB集群中删除一个租户,这个操作可能需要删除租户下的各种资源(role、database、member等)。如果在这个过程中的任何一步失败了,那么这个操作可能会导致集群处于不一致的状态,为了解决这个问题,我们设计了一个解决方案。
基于这个目标,我们参考了一些设计比较好的产品。
方案参考:HBase的ProcedureV2?(Pv2)?Framework
HBase?中?Procedure?代表一个或一组操作,Procedure?分为了如下状态:
INITIALIZING?-?Procedure?构造中,未提交执行
RUNNABLE??-?Procedure?提交,准备好执行
WAITING?-?Procedure?等待子?Procedure?完成
WAITING_TIMEOUT?-?Procedure等待超时或事件中断
ROLLEDBACK?-?由于Procedure或子Procedure失败,Procedure会回滚,回滚过程中会清理执行时创建的资源。在失败或者重启场景下,回滚会发生多次,因此回滚步骤要保证幂等性
SUCCESS?-?Procedure成功完成,无失败
FAILED?-?Procedure至少执行了一次且失败,已经或尚未回滚,任何处于失败状态的Procedure都将会切换到回滚状态
通过对Procedure的各个步骤的清晰切分和记录,实现了多步骤执行的原子性和一致性。
最终方案:ResourceManager
基于CnosDB的情况,我们引入了ResourceManager功能。
ResourceManager可以在后台重试失败任务,直到操作成功。这样,即使某个步骤失败了,ResourceManager也可以保证最终的一致性。例如,在上述的删除租户操作中,如果在进行到删除database的步骤失败了,那么我们可以创建一个异步任务来重试这个步骤及后续步骤。这个异步任务会在后台运行,并且会不断重试,直到成功。通过这种方式,我们可以确保即使在面对失败时,我们的系统也能保持一致性。
ResourceManager也支持延迟任务,可以对任务预设一个执行时间,当到达时间时,会执行任务,如果失败,也会进行重试。
总的来说,ResourceManager提供了一种强大而灵活的方式来处理时序数据库中的多步骤任务操作,并确保系统的最终一致性。
任务状态划分
根据任务的情况,会被分为不同的状态:
Schedule?-?任务提交到ResourceManager,未执行
Executing?-?正在执行该任务
Successed?-?任务执行成功
Failed?-?任务执行失败,会进行重试
Cancel?-?任务未执行,被取消
Fatal?-?任务执行过程中发生无法恢复错误,不会进行重试
任务状态查看
为了清楚地知道任务当前的执行情况,提供了系统表resource_status,可以通过如下命令查看:
SELECT?*?FROM?information_schema.resource_status;
表信息如下:
| time | name | action | try_count | status | comment |
| 2023-11-03?05:47:28 | cnosdb-db1 | DropDatabase | 1 | Successed |
time?-?任务发生时间
name?-?任务名称
action?-?任务动作
try_count?-?尝试次数
status?-?任务当前状态
comment?-?任务执行信息
具体场景
场景一

在CnosDB集群中,资源操作请求可能会被下发到任意节点进行处理。
例如,一个请求可能会被下发到名为node1的节点。然而,由于网络延迟、硬件故障或其他一些原因,这个请求可能会失败。当node1节点在处理请求时遇到失败,它不只会简单地返回一个错误,并且还会将这个请求作为失败任务记录到meta中。
在CnosDB集群中,多个节点(例如node1、node2)会定时从meta中读取失败任务。为了防止多个节点重试同一个任务,只有一个节点能够成功地读取这个任务。在我们的假设中,node2节点成功地读取了这个任务。
一旦node2节点获取了这个失败任务,它就会开始循环重试这个任务,直到任务成功为止,并且在重试过程中,会记录执行失败的错误信息。这种设计可以确保即使在面对失败时,我们的系统也能够最终完成所有的请求。
目前支持失败重试的操作:
DropTenant,
DropDatabase,
DropTable,
DropColumn,
AddColumn,
AlterColumn,
RenameTagName,
UpdateTagValue
场景二
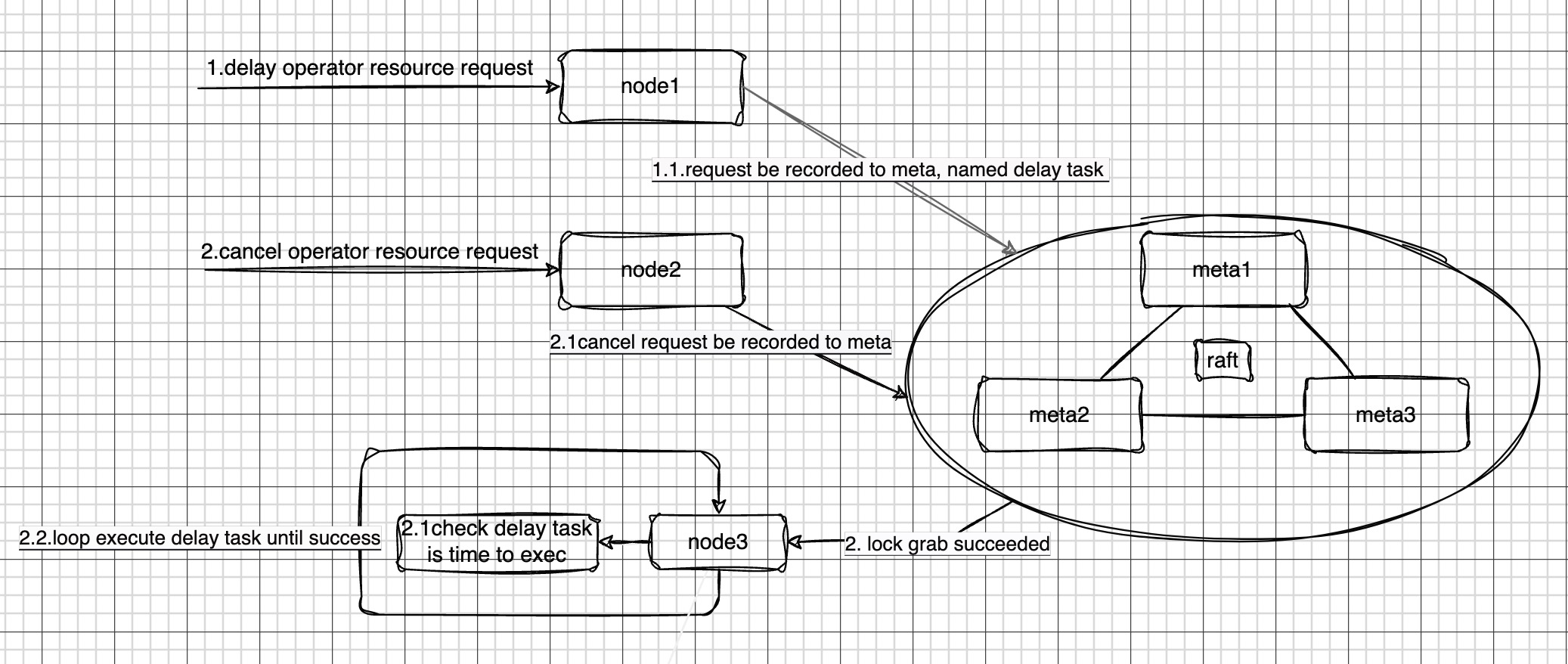
在CnosDB集群中,当node1接收到一个延迟任务时,这个任务会被记录到meta中。meta中有一个用于存储任务信息的数据结构,它能够被系统中的所有节点访问和读取。
多个节点(例如node1、node2、node3等)会尝试从meta中读取任务列表。然而,为了保证任务的一致性和正确性,系统设计了一种锁机制,使得在多个节点中,只有一个节点能够成功地读取到任务列表。在这个例子中,我们假设node3是成功读取任务的节点。
当node3成功地从meta中读取到任务列表后,它会开始对任务进行遍历处理。首先,它会检查当前的时间是否已经达到了任务的预定执行时间。如果还没有到达预定的执行时间,node3会跳过该任务;如果已经到达预定的执行时间,node3则会开始执行这个任务。
在执行任务的过程中,node3会采用一种循环执行的策略。也就是说,如果任务在第一次执行时没有成功,node3会再次尝试执行这个任务,直到任务成功为止。此外,为了保证系统的可靠性和可追踪性,在每次执行任务时,node3都会将当前的执行状态和结果记录到系统表中,可以通过查看系统表查看任务的执行状态。
另一种情况是在node3成功读取前,取消延迟任务的请求下发给node2,该请求会被记录到meta,此时该延迟任务到预设时间后也不会被执行。
通过以上的设计和实现,系统能够对延迟任务进行有效和正确的处理,并且能够实时地跟踪和记录任务的执行状态和结果。
目前支持延迟任务的操作:DropTenant、DropDatabase。
CnosDB简介
CnosDB是一款高性能、高易用性的开源分布式时序数据库,现已正式发布及全部开源。
欢迎关注我们的社区网站:https://cn.cnosdb.com
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 深入探索Git的高级技巧与神奇操作(分支,高效合并)
- half-angle slicing半角切片技术
- java web中 EL表达式的相关案例:
- 改善制造业客户体验的实用技巧与策略
- Microsoft Office 2019 | 先前版本 | office2019注册安装教程
- Java数据结构与算法:图算法之深度优先搜索(DFS)
- Kafka-生产者
- 干洗店洗鞋店小程序开发系统功能特色
- 用云渲染好还是本地渲染好?
- 15、ble_mesh_sensor_model 客户端 传感器