权重衰减weight_decay
发布时间:2023年12月18日
查了好几次了,一直忘,记录一下
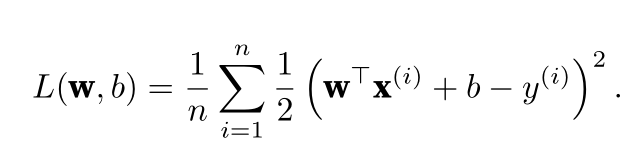
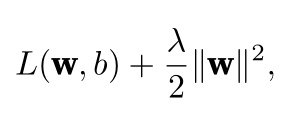 ?
?
?使用L 2 范数的一个原因是它对权重向量的大分量施加了巨大的惩罚。这使得我们的学习算法偏向于在大量特征上均匀分布权重的模型。在实践中,这可能使它们对单个变量中的观测误差更为稳定。
相比之下,L 1 惩罚会导致模型将权重集中在一小部分特征上,而将其他权重清除为零。这称为特征选择(feature selection),这可能是其他场景下需要的
总之就是施加一个惩罚项,防止模型过拟合,并具有鲁棒性。
文章来源:https://blog.csdn.net/qq_72985002/article/details/135060033
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java 线程运行方法和原理
- 如何用Python实现量化交易?
- HTML+CSS:飞翔按钮
- 山西电力市场日前价格预测【2024-01-09】
- Kotlin协程与流(Flow)
- 【python学习】面向对象编程2
- 如何通过 Prompt 优化大模型 Text2SQL 的效果
- YOLOv8改进 | 检测头篇 | 利用DySnakeConv改进检测头专用于分割的检测头(全网独家首发,Seg)
- 应届生谈薪技巧和注意事项,怎么为自己多争取1~2k(FPGA,芯片谈薪,数字IC,嵌入式,模拟IC,FPGA探索者)
- 基于Python的线上兼职平台系统的设计与实现-计算机毕业设计源码83320