Java NIO
NIO 简介
在传统的 Java I/O 模型(BIO)中,I/O 操作是以阻塞的方式进行的。也就是说,当一个线程执行一个 I/O 操作时,它会被阻塞直到操作完成。这种阻塞模型在处理多个并发连接时可能会导致性能瓶颈,因为需要为每个连接创建一个线程,而线程的创建和切换都是有开销的。
为了解决这个问题,在 Java1.4 版本引入了一种新的 I/O 模型 — NIO (New IO,也称为 Non-blocking IO) 。NIO 弥补了同步阻塞 I/O 的不足,它在标准 Java 代码中提供了非阻塞、面向缓冲、基于通道的 I/O,可以使用少量的线程来处理多个连接,大大提高了 I/O 效率和并发。
??需要注意:使用 NIO 并不一定意味着高性能,它的性能优势主要体现在高并发和高延迟的网络环境下。当连接数较少、并发程度较低或者网络传输速度较快时,NIO 的性能并不一定优于传统的 BIO
NIO 核心组件
NIO 主要包括以下三个核心组件:
- Buffer(缓冲区):NIO 读写数据都是通过缓冲区进行操作的。读操作的时候将 Channel 中的数据填充到 Buffer 中,而写操作时将 Buffer 中的数据写入到 Channel 中。
- Channel(通道):Channel 是一个双向的、可读可写的数据传输通道,NIO 通过 Channel 来实现数据的输入输出。通道是一个抽象的概念,它可以代表文件、套接字或者其他数据源之间的连接。
- Selector(选择器):允许一个线程处理多个 Channel,基于事件驱动的 I/O 多路复用模型。所有的 Channel 都可以注册到 Selector 上,由 Selector 来分配线程来处理事件。
Buffer(缓冲区)
在传统的 BIO 中,数据的读写是面向流的, 分为字节流和字符流。
在 Java 1.4 的 NIO 库中,所有数据都是用缓冲区处理的,这是新库和之前的 BIO 的一个重要区别,有点类似于 BIO 中的缓冲流。NIO 在读取数据时,它是直接读到缓冲区中的。在写入数据时,写入到缓冲区中。 使用 NIO 在读写数据时,都是通过缓冲区进行操作。
Buffer 的子类如下图所示。其中,最常用的是 ByteBuffer,它可以用来存储和操作字节数据。
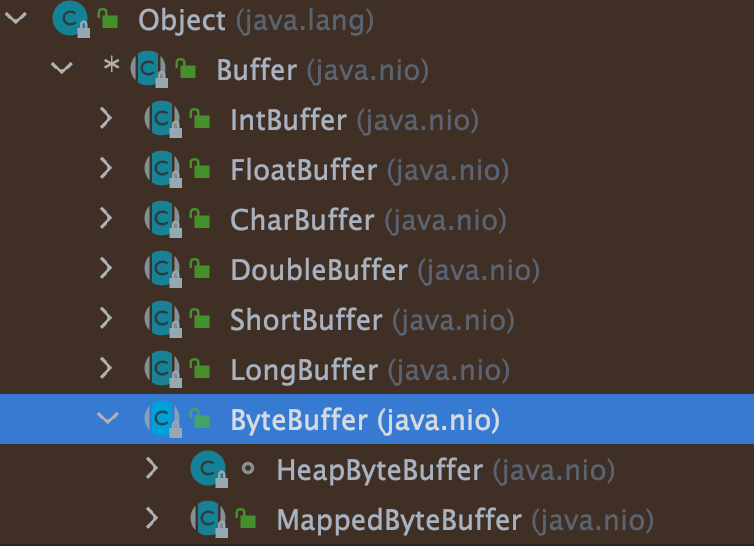
你可以将 Buffer 理解为一个数组,IntBuffer、FloatBuffer、CharBuffer 等分别对应 int[]、float[]、char[] 等。
为了更清晰地认识缓冲区,我们来简单看看Buffer 类中定义的四个成员变量:
public abstract class Buffer {
// Invariants: mark <= position <= limit <= capacity
private int mark = -1;
private int position = 0;
private int limit;
private int capacity;
}
这四个成员变量的具体含义如下:
- 容量(
capacity):Buffer可以存储的最大数据量,Buffer创建时设置且不可改变; - 界限(
limit):Buffer中可以读/写数据的边界。写模式下,limit代表最多能写入的数据,一般等于capacity(可以通过limit(int newLimit)方法设置);读模式下,limit等于 Buffer 中实际写入的数据大小。 - 位置(
position):下一个可以被读写的数据的位置(索引)。从写操作模式到读操作模式切换的时候(flip),position都会归零,这样就可以从头开始读写了。 - 标记(
mark):Buffer允许将位置直接定位到该标记处,这是一个可选属性;
并且,上述变量满足如下的关系:0 <= mark <= position <= limit <= capacity 。
另外,Buffer 有读模式和写模式这两种模式,分别用于从 Buffer 中读取数据或者向 Buffer 中写入数据。Buffer 被创建之后默认是写模式,调用 flip() 可以切换到读模式。如果要再次切换回写模式,可以调用 clear() 或者 compact() 方法。
Buffer 对象不能通过 new 调用构造方法创建对象 ,只能通过静态方法实例化 Buffer。
这里以 ByteBuffer为例进行介绍:
// 分配堆内存
public static ByteBuffer allocate(int capacity);
// 分配直接内存
public static ByteBuffer allocateDirect(int capacity);
Buffer 最核心的两个方法:
get: 读取缓冲区的数据put:向缓冲区写入数据
除上述两个方法之外,其他的重要方法:
flip:将缓冲区从写模式切换到读模式,它会将limit的值设置为当前position的值,将position的值设置为 0。clear: 清空缓冲区,将缓冲区从读模式切换到写模式,并将position的值设置为 0,将limit的值设置为capacity的值。- ……
Channel(通道)
Channel 是一个通道,它建立了与数据源(如文件、网络套接字等)之间的连接。我们可以利用它来读取和写入数据,就像打开了一条自来水管,让数据在 Channel 中自由流动。
BIO 中的流是单向的,分为各种 InputStream(输入流)和 OutputStream(输出流),数据只是在一个方向上传输。通道与流的不同之处在于通道是双向的,它可以用于读、写或者同时用于读写。
Channel 与前面介绍的 Buffer 打交道,读操作的时候将 Channel 中的数据填充到 Buffer 中,而写操作时将 Buffer 中的数据写入到 Channel 中

另外,因为 Channel 是全双工的,所以它可以比流更好地映射底层操作系统的 API。特别是在 UNIX 网络编程模型中,底层操作系统的通道都是全双工的,同时支持读写操作。
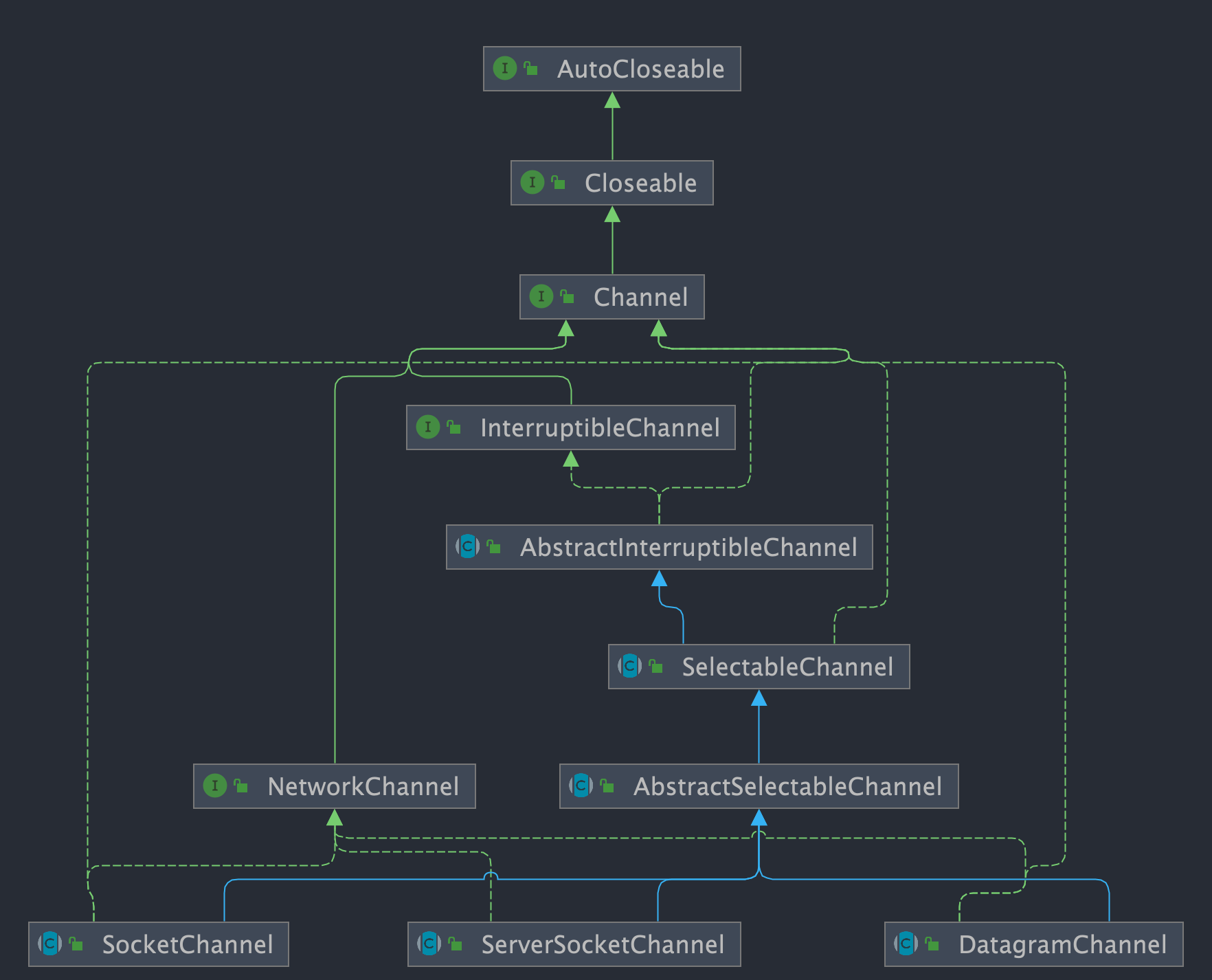
Channel 的子类如下图所示。

其中,最常用的是以下几种类型的通道:
FileChannel:文件访问通道;SocketChannel、ServerSocketChannel:TCP 通信通道;DatagramChannel:UDP 通信通道;
Channel 最核心的两个方法:
read:读取数据并写入到 Buffer 中。write:将 Buffer 中的数据写入到 Channel 中。
这里我们以 FileChannel 为例演示一下是读取文件数据的
RandomAccessFile reader = new RandomAccessFile("/Users/guide/Documents/test_read.in", "r"))
FileChannel channel = reader.getChannel();
ByteBuffer buffer = ByteBuffer.allocate(1024);
channel.read(buffer);
Selector(选择器)
Selector(选择器) 是 NIO 中的一个关键组件,它允许一个线程处理多个 Channel。Selector 是基于事件驱动的 I/O 多路复用模型,主要运作原理是:通过 Selector 注册通道的事件,Selector 会不断地轮询注册在其上的 Channel。当事件发生时,比如:某个 Channel 上面有新的 TCP 连接接入、读和写事件,这个 Channel 就处于就绪状态,会被 Selector 轮询出来。Selector 会将相关的 Channel 加入到就绪集合中。通过 SelectionKey 可以获取就绪 Channel 的集合,然后对这些就绪的 Channel 进行响应的 I/O 操作。
一个多路复用器 Selector 可以同时轮询多个 Channel,由于 JDK 使用了 epoll() 代替传统的 select 实现,所以它并没有最大连接句柄 1024/2048 的限制。这也就意味着只需要一个线程负责 Selector 的轮询,就可以接入成千上万的客户端。
Selector 可以监听以下四种事件类型:
SelectionKey.OP_ACCEPT:表示通道接受连接的事件,这通常用于ServerSocketChannel。SelectionKey.OP_CONNECT:表示通道完成连接的事件,这通常用于SocketChannel。SelectionKey.OP_READ:表示通道准备好进行读取的事件,即有数据可读。SelectionKey.OP_WRITE:表示通道准备好进行写入的事件,即可以写入数据。
Selector是抽象类,可以通过调用此类的 open() 静态方法来创建 Selector 实例。Selector 可以同时监控多个 SelectableChannel 的 IO 状况,是非阻塞 IO 的核心。
一个 Selector 实例有三个 SelectionKey 集合:
- 所有的
SelectionKey集合:代表了注册在该 Selector 上的Channel,这个集合可以通过keys()方法返回。 - 被选择的
SelectionKey集合:代表了所有可通过select()方法获取的、需要进行IO处理的 Channel,这个集合可以通过selectedKeys()返回。 - 被取消的
SelectionKey集合:代表了所有被取消注册关系的Channel,在下一次执行select()方法时,这些Channel对应的SelectionKey会被彻底删除,程序通常无须直接访问该集合,也没有暴露访问的方法。
简单演示一下如何遍历被选择的 SelectionKey 集合并进行处理:
NIO 零拷贝
零拷贝是提升 IO 操作性能的一个常用手段,像 ActiveMQ、Kafka 、RocketMQ、QMQ、Netty 等顶级开源项目都用到了零拷贝。
零拷贝是指计算机执行 IO 操作时,CPU 不需要将数据从一个存储区域复制到另一个存储区域,从而可以减少上下文切换以及 CPU 的拷贝时间。也就是说,零拷贝主主要解决操作系统在处理 I/O 操作时频繁复制数据的问题。零拷贝的常见实现技术有: mmap+write、sendfile和 sendfile + DMA gather copy 。
下图展示了各种零拷贝技术的对比图:
| CPU 拷贝 | DMA 拷贝 | 系统调用 | 上下文切换 | |
|---|---|---|---|---|
| 传统方法 | 2 | 2 | read+write | 4 |
| mmap+write | 1 | 2 | mmap+write | 4 |
| sendfile | 1 | 2 | sendfile | 2 |
| sendfile + DMA gather copy | 0 | 2 | sendfile | 2 |
可以看出,无论是传统的 I/O 方式,还是引入了零拷贝之后,2 次 DMA(Direct Memory Access) 拷贝是都少不了的。因为两次 DMA 都是依赖硬件完成的。零拷贝主要是减少了 CPU 拷贝及上下文的切换。
Java 对零拷贝的支持:
MappedByteBuffer是 NIO 基于内存映射(mmap)这种零拷??式的提供的?种实现,底层实际是调用了 Linux 内核的mmap系统调用。它可以将一个文件或者文件的一部分映射到内存中,形成一个虚拟内存文件,这样就可以直接操作内存中的数据,而不需要通过系统调用来读写文件。FileChannel的transferTo()/transferFrom()是 NIO 基于发送文件(sendfile)这种零拷贝方式的提供的一种实现,底层实际是调用了 Linux 内核的sendfile系统调用。它可以直接将文件数据从磁盘发送到网络,而不需要经过用户空间的缓冲区
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 一个冷门的需求,golang实现邮件回复生成邮件链
- jenkins+selenium+python实现web自动化测试
- TKEStack容器管理平台实战之部署wordpress应用
- 数字化转型浪潮中的挑战与机遇:企业如何应对七大难点_光点科技
- Android基于Matrix绘制PaintDrawable设置BitmapShader,以手指触点为中心显示原图像圆图,Kotlin(2)
- 在当前网页嵌套其他网站的解决方案
- Html、Css基础
- Git的merge和rebase你真的了解吗?
- Gazebo GUI模型编辑器
- 胶囊-药品广告数据库-解锁药品营销市场