使用强化学习提升扩散模型;轻量级LLM无损加速模块;使用RL动态调整Transformer每层参数量;Lumiere文本生成视频
本文首发于公众号:机器感知
使用强化学习提升扩散模型;轻量级LLM无损加速模块;使用RL动态调整Transformer每层参数量;Lumiere文本生成视频
Large-scale Reinforcement Learning for Diffusion Models

In this paper, we present an effective scalable algorithm to improve diffusion models using Reinforcement Learning (RL) across a diverse set of reward functions, such as human preference, compositionality, and fairness over millions of images. We illustrate how our approach substantially outperforms existing methods for aligning diffusion models with human preferences. We further illustrate how this substantially improves pretrained Stable Diffusion (SD) models, generating samples that are preferred by humans 80.3% of the time over those from the base SD model while simultaneously improving both the composition and diversity of generated samples.
BiTA: Bi-Directional Tuning for Lossless Acceleration in Large Language Models
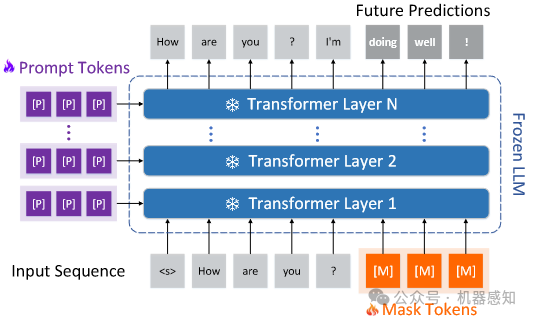
Large language models (LLMs) commonly employ autoregressive generation during inference, leading to high memory bandwidth demand and consequently extended latency. To mitigate this inefficiency, we present Bi-directional Tuning for lossless Acceleration (BiTA), an innovative method expediting LLMs via streamlined semi-autoregressive generation and draft verification. BiTA serves as a lightweight plug-in module, seamlessly boosting the inference efficiency of existing LLMs without requiring additional assistance models or incurring significant extra memory costs. Applying the proposed BiTA, LLaMA-2-70B-Chat achieves a 2.7x speedup on the MT-Bench benchmark.
NeRF-AD: Neural Radiance Field with Attention-based Disentanglement for ?Talking Face Synthesis
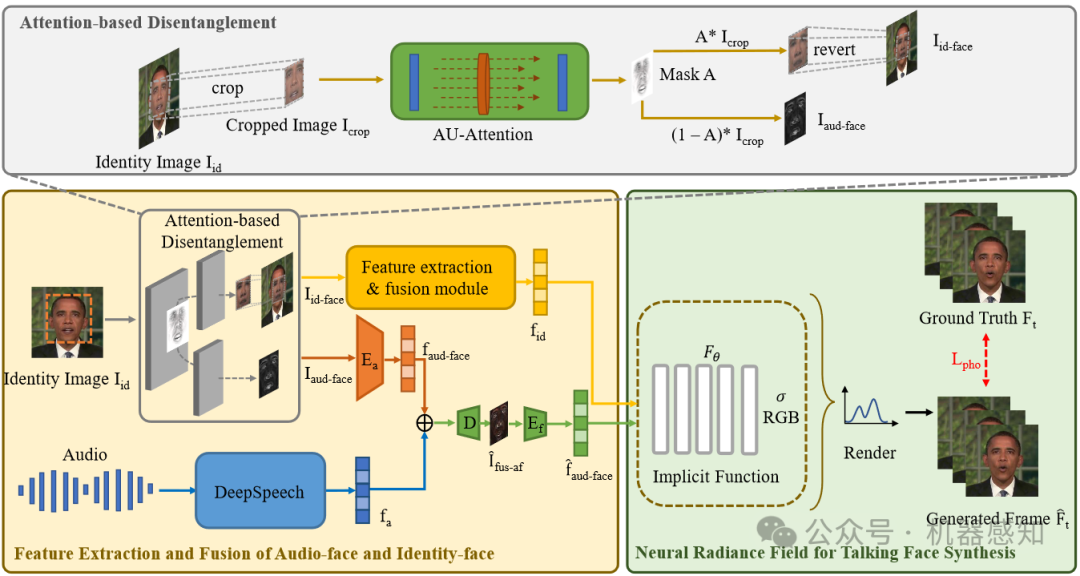
This paper moves a portion of NeRF learning tasks ahead and proposes a talking face synthesis method via NeRF with attention-based disentanglement (NeRF-AD). In particular, an Attention-based Disentanglement module is introduced to disentangle the face into Audio-face and Identity-face using speech-related facial action unit (AU) information. To precisely regulate how audio affects the talking face, we only fuse the Audio-face with audio feature. In addition, AU information is also utilized to supervise the fusion of these two modalities.
UniHDA: Towards Universal Hybrid Domain Adaptation of Image Generators

In this paper, we propose UniHDA, a unified and versatile framework for generative hybrid domain adaptation with multi-modal references from multiple domains. We use CLIP encoder to project multi-modal references into a unified embedding space and then linear interpolate the direction vectors from multiple target domains to achieve hybrid domain adaptation. To ensure the cross-domain consistency, we propose a novel cross-domain spatial structure (CSS) loss that maintains detailed spatial structure information between source and target generator. Additionally, our framework is versatile to multiple generators, eg, StyleGAN2 and Diffusion Models.
Dynamic Layer Tying for Parameter-Efficient Transformers
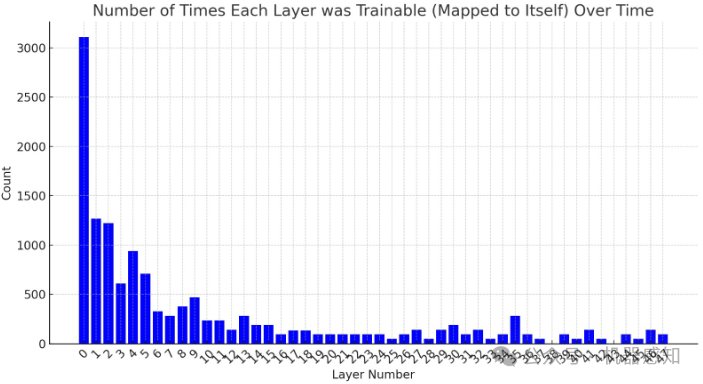
In the pursuit of reducing the number of trainable parameters in deep transformer networks, we employ Reinforcement Learning to dynamically select layers during training and tie them together. Every few iterations, the RL agent is asked whether to train each layer $i$ independently or to copy the weights of a previous layer $j<i$. This facilitates weight sharing, reduces the number of trainable parameters, and also serves as an effective regularization technique. In particular, the memory consumption during training is up to one order of magnitude less than the conventional training method.
Lumiere: A Space-Time Diffusion Model for Video Generation

We introduce Lumiere -- a text-to-video diffusion model designed for synthesizing videos that portray realistic, diverse and coherent motion -- a pivotal challenge in video synthesis. To this end, we introduce a Space-Time U-Net architecture that generates the entire temporal duration of the video at once, through a single pass in the model. This is in contrast to existing video models which synthesize distant keyframes followed by temporal super-resolution -- an approach that inherently makes global temporal consistency difficult to achieve. By deploying both spatial and (importantly) temporal down- and up-sampling and leveraging a pre-trained text-to-image diffusion model, our model learns to directly generate a full-frame-rate, low-resolution video by processing it in multiple space-time scales. Our design easily facilitates a wide range of content creation tasks and video editing applications, including image-to-video, video inpainting, and stylized generation.
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 新手可理解的PyTorch 损失函数:优化机器学习模型的关键
- 嵌入式开发——SPI OLED屏幕案例
- 训练营第四十二天 | 01背包问题,你该了解这些! ● 01背包问题,你该了解这些! 滚动数组 ● 416. 分割等和子集
- 牛客周赛 Round 24 解题报告 | 珂学家 | 二分
- 【每天一个早下班技巧】NPM发包流程
- 轻松祛除烦人水印:三款简单易用的图片去水印工具介绍
- 谢罪——我的懒惰
- 数字经济的不断发展,数字化转型已成为各行各业不可避免的趋势
- Sentinel 轨道数据及下载
- 赛氪受邀参加安徽省翻译协会2023年年会