DQL的基本查询
发布时间:2024年01月17日
DQL(Data Query Language)数据查询语言查询是使用频率最高的一个操作,
可以从一个表中查询数据,也可以从多个表中查询数据
?基础查询
?语法:
select
查询列表
from
表名
;
特点:
查询列表可以是:表中的字段、常量、表达式、函数
查询的结果是一个虚拟的表格
查询结果处理:
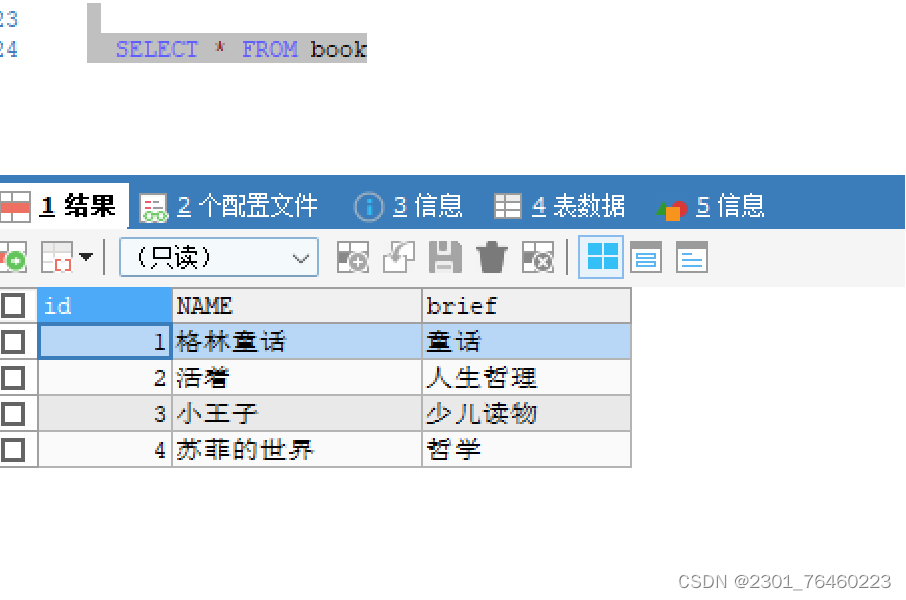
特定列查询
:select column1,column2 from table
全部列查询
: select * from table
算数运算符
:+ - * /
排除重复行
: select distinct column1,column2 from table
查询函数:
select
函数
; /
例如
version()
?函数:
类似于java中的方法,将一组逻辑语句事先在数据库中定义好,可以直接调
分类:
单行函数:如
concat
、
length
、
ifnull
等
分组函数:做统计使用,又称为统计函数、聚合函数、组函数
单行函数
字符函数
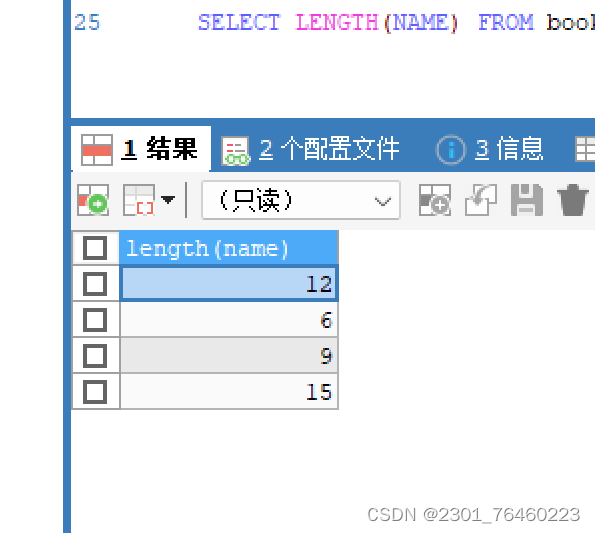
length()
:获取参数值的字节个数
char_length()
获取参数值的字符个数
concat(str1,str2,.....)
:拼接字符串
upper()/lower()
:将字符串变成大写
/
小写
substring(str,pos,length)
:截取字符串 位置从
1
开始
instr(str,
指定字符
)
:返回子串第一次出现的索引,如果找不到返回
0
trim(str)
:去掉字符串前后的空格或子串
,trim(
指定子串
from
字符串
)
lpad(str,length,
填充字符
)
:用指定的字符实现左填充将
str
填充为指定长度
rpad(str,length,
填充字符
)
:用指定的字符实现右填充将
str
填充为指定长度
replace(str,old,new)
:替换,替换所有的子串
单行函数
逻辑处理
case when 条件 then 结果1 else 结果2 end; 可以有多个when
ifnull(被检测值,默认值)函数检测是否为null,如果为null,则返回指定的值,否则返回
原本的值
if函数:if else的 效果 if(条件,结果1,结果2)
数学函数
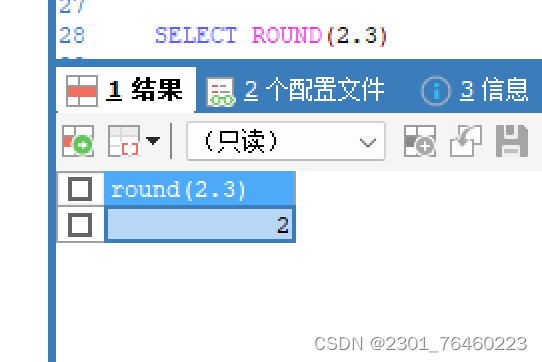
round(
数值
)
:四舍五入
ceil(
数值
)
:向上取整,返回
>=
该参数的最小整数
floor(
数值
)
:向下取整,返回
<=
该参数的最大整数
truncate(
数值
,
保留小数的位数
)
:截断,小数点后截断到几位
mod(
被除数
,
除数
)
:取余,被除数为正,则为正;被除数为负,则为负
rand()
:获取随机数,返回
0-1
之间的小数
日期函数
now()
:返回当前系统日期
+
时间
curdate()
:返回当前系统日期,不包含时间
curtime()
:返回当前时间,不包含日期
可以获取指定的部分,年、月、日、小时、分钟、秒
YEAR(
日期列
),MONTH(
日期
列
),DAY(
日期
列
) ,HOUR(
日期
列
) ,MINUTE(
日期
列
)
SECOND(
日期
列
)
str_to_date(
字符串格式日期
,
格式
)
:将日期格式的字符转换成指定格式的日期
date_format(
日期列
,
格式
)
:将日期转换成字符串
datediff(big,small)
:返回两个日期相差的天数
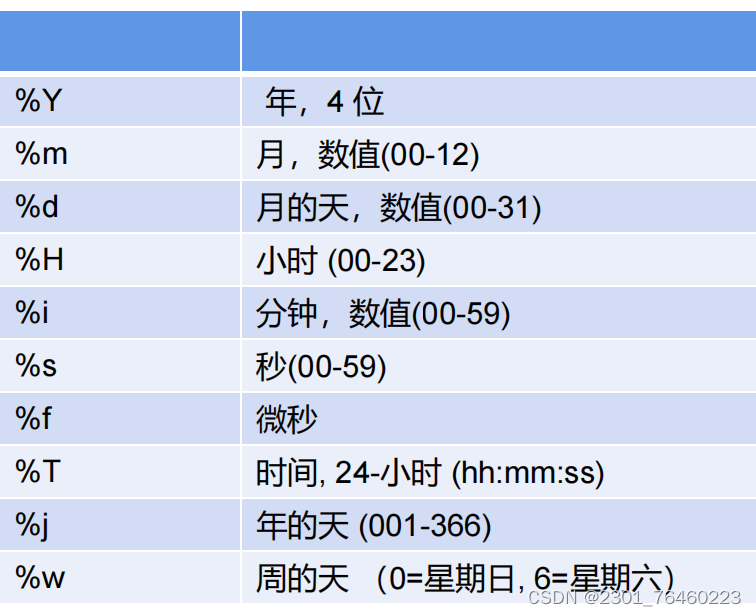
日期格式:
分组函数
功能:用作统计使用,又称为聚合函数或统计函数或组函数
分类:
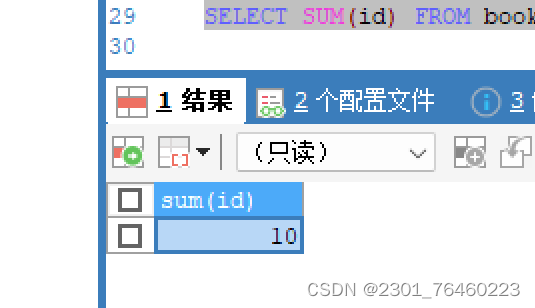
sum
求和、
avg
平均值、
max
最大值、
min
最小值、
count
计数
(非空)
1.sum
,
avg
一般用于处理数值型
max
,
min
,
count
可以处理任何类型
2.
以上分组函数都忽略
null
值
3.count
函数的一般使用
count
(
*
)用作统计行数
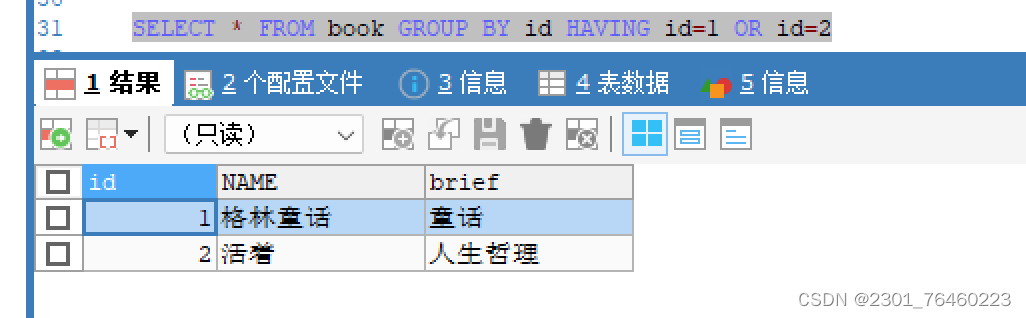
4.
和分组函数一同查询的字段要求是
group by
后的字段
条件查询
使用WHERE 子句,将不满足条件的行过滤掉,WHERE 子句紧随 FROM 子句。
语法
:select <
结果
> from <
表名
> where <
条件
>
比较
=, !=
或
<>, >, <, >=, <=
逻辑运算
and
与
or
或
not
非

模糊查询
LIKE
:是否匹配于一个模式 一般和通配符搭配使用,可以判断字符型数值
或数值型.
通配符: % 任意多个字符
between and 两者之间,包含临界值;
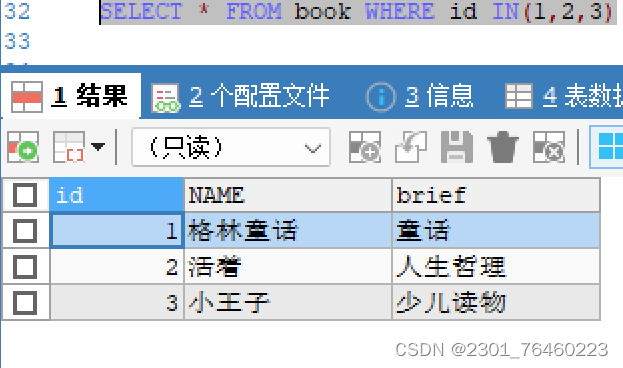
in 判断某字段的值是否属于in列表中的某一项
IS NULL(为空的)或 IS NOT NULL(不为空的)
UNION 的语法如下:
[SQL
语句
1]
UNION
[SQL
语句
2]
2
、
UNION ALL
的语法如下:
[SQL
语句
1]
UNION ALL
[SQL
语句
2]
当使用union 时,mysql 会把结果集中重复的记录删掉,而使用union all ,
mysql 会把所有的记录返回,且效率高于union 。
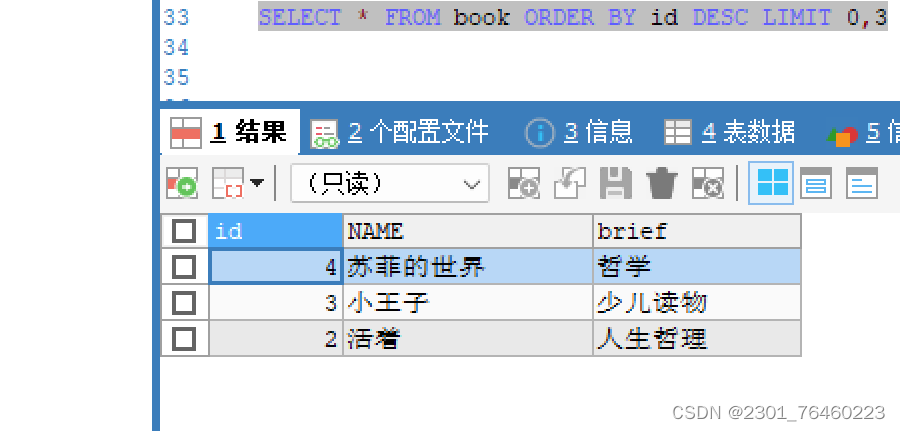
排序
查询结果排序,使用 ORDER BY 子句排序 order by 排序列 ASC/DESC
asc代表的是升序,desc代表的是降序,如果不写,默认是升序
order by子句中可以支持单个字段、多个字段
数量限制
limit子句:对查询的显示结果限制数目 (sql语句最末尾位置)
SELECT * FROM table LIMIT offset rows;
SELECT * from table LIMIT 0,5;
分组查询
语法:
select
分组函数,列(要求出现在
group by
的后面)
from
表
[where
筛选条件
]
group by
分组的列表
[having
分组后的筛选
]
[order by
子句
]
注意:查询列表比较特殊,要求是分组函数和
group by
后出现的字段 。
分组前筛选 原始表
group by
子句的前面
where
分组后筛选 分组后的结果集
group by
的后面
having
文章来源:https://blog.csdn.net/2301_76460223/article/details/135643621
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!