[SGDiff] A Style Guided Diffusion model for fashion synthesis
发布时间:2023年12月20日
Abstract
①提出一个 风格引导的扩散模型(SGDiff),把 图像模态 与 预训练的t2i模型 组合起来。
②提出一个 数据集 SG-Fashion。
Method
SGDiff Overview
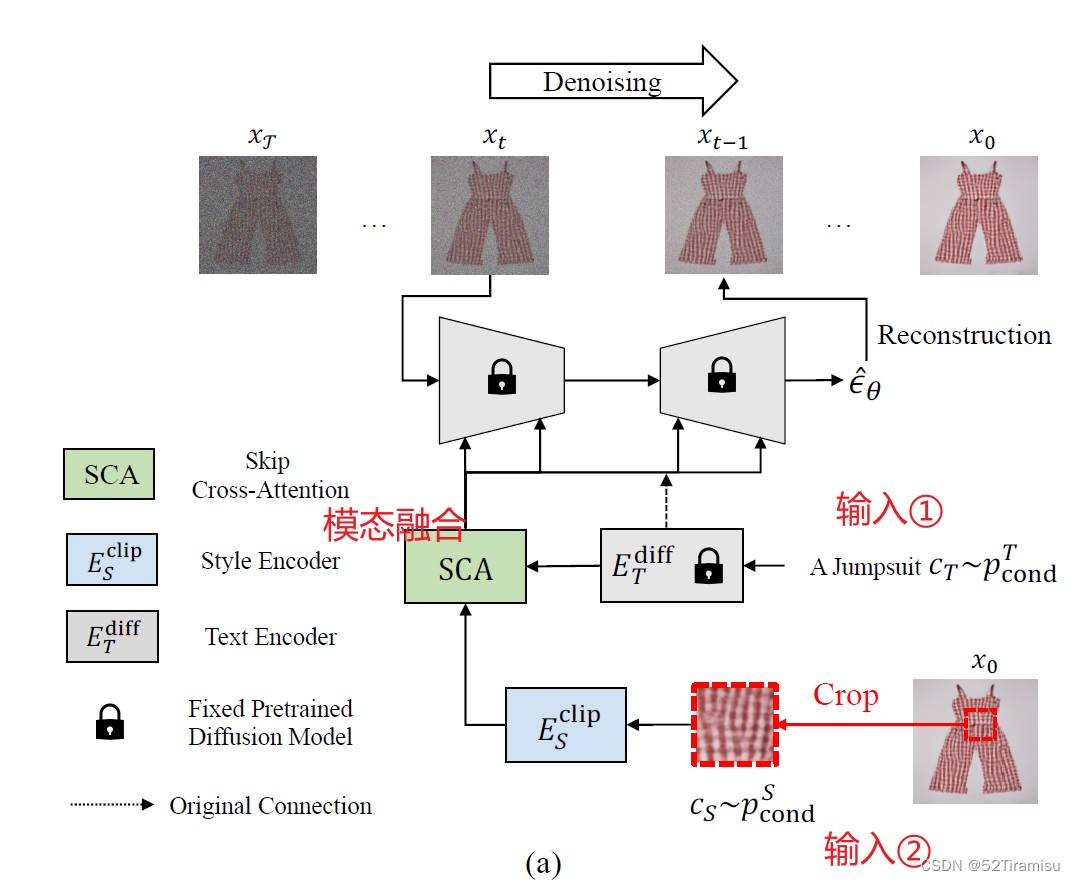
?
公式含义:在给定时间点 t 上的输入
,目标文本的语义表示
,风格表示
。通过扩散网络
?估计该时刻的噪声
。
输入:①文本text;②风格图像。
文本条件??通过扩散模型的?
?生成?
风格条件??通过CLIP模型的?
?生成?
这两个特征在 SCA 模块中进行特征融合(融合细节如下图:)

?:
:
再特征拼接:![]()
输出?:

最后再来一个 skip-connection:
Training Objective
从每一时间步骤t,获得重建图像?

Perceptual Loss:
![]()
Perceptual Losses for Real-Time Style Transfer and Super-Resolution. 2016
?,
?分别表示 生成图像?
?和真实图像?
?在VGG网络的第 m 层的特征表示。
VGG网络,包含多个卷积层和池化层,用于提取图像特征。
最后基于 Improved DDPM,提出最终目标Loss:
![]()
Experiment
数据集:SG-Fashion,包含17,000 张从优衣库等网站上下载的各类图片。
模型架构:GLIDE+CLIP(ViT/32)
显卡:a single RTX3090
定性比较

定量比较
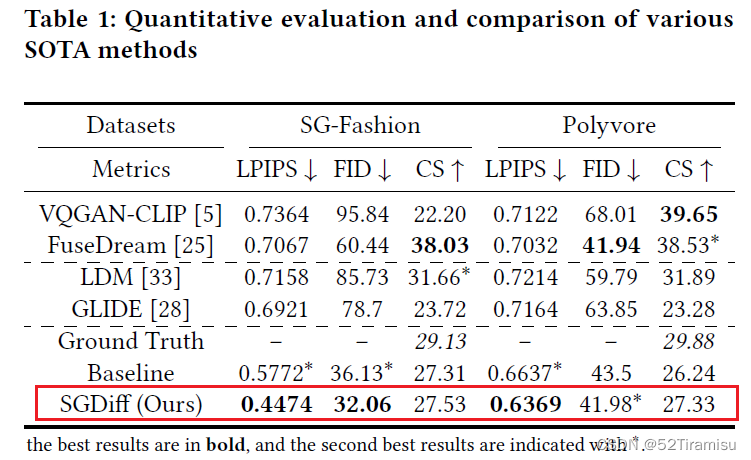
?
文章来源:https://blog.csdn.net/gsj9086/article/details/135096088
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!