IO流学习笔记
1 .介绍一下Java中的IO流
IO(Input Output)用于实现对数据的输入与输出操作,Java把不同的输入/输出源(键盘、文件、网络等)抽象表述为流(Stream)。流是从起源到接收的有序数据,有了它程序就可以采用同一方式访问不同的输入/输出源。
- ? 按照数据流向,可以将流分为输入流和输出流,其中输入流只能读取数据、不能写入数据,而输出流只能写入数据、不能读取数据。
- ? 按照数据类型,可以将流分为字节流和字符流,其中字节流操作的数据单元是8位的字节,而字符流操作的数据单元是16位的字符。
- ? 按照处理功能,可以将流分为节点流和处理流,其中节点流可以直接从/向一个特定的IO设备(磁盘、网络等)读/写数据,也称为低级流,而处理流是对节点流的连接或封装,用于简化数据读/写功能或提高效率,也称为高级流。
? Java提供了大量的类来支持IO操作,下表给大家整理了其中比较常用的一些类。其中,黑色字体的是抽象基类,其他所有的类都继承自它们。红色字体的是节点流,蓝色字体的是处理流。
? 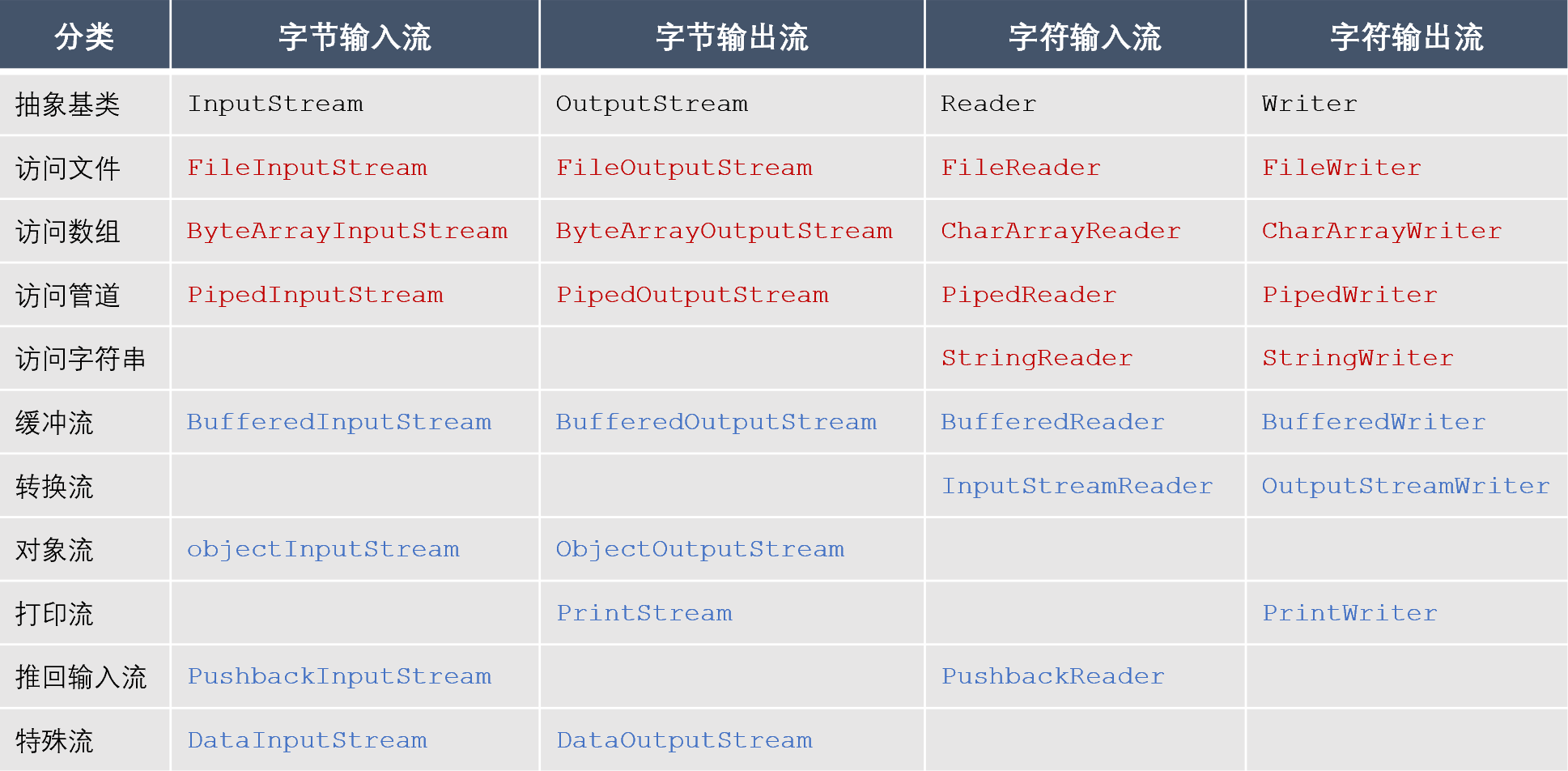
? 根据命名很容易理解各个流的作用:
- ? 以File开头的文件流用于访问文件;
- ? 以ByteArray/CharArray开头的流用于访问内存中的数组;
- ? 以Piped开头的管道流用于访问管道,实现进程之间的通信;
- ? 以String开头的流用于访问内存中的字符串;
- ? 以Buffered开头的缓冲流,用于在读写数据时对数据进行缓存,以减少IO次数;
- ? InputStreamReader、InputStreamWriter是转换流,用于将字节流转换为字符流;
- ? 以Object开头的流是对象流,用于实现对象的序列化;
- ? 以Print开头的流是打印流,用于简化打印操作;
- ? 以Pushback开头的流是推回输入流,用于将已读入的数据推回到缓冲区,从而实现再次读取;
- ? 以Data开头的流是特殊流,用于读写Java基本类型的数据。
2. 怎么用流打开一个大文件?
打开大文件,应避免直接将文件中的数据全部读取到内存中,可以采用分次读取的方式。
- ? 使用缓冲流。缓冲流内部维护了一个缓冲区,通过与缓冲区的交互,减少与设备的交互次数。使用缓冲输入流时,它每次会读取一批数据将缓冲区填满,每次调用读取方法并不是直接从设备取值,而是从缓冲区取值,当缓冲区为空时,它会再一次读取数据,将缓冲区填满。使用缓冲输出流时,每次调用写入方法并不是直接写入到设备,而是写入缓冲区,当缓冲区填满时它会自动刷入设备。
- ? 使用NIO。NIO采用内存映射文件的方式来处理输入/输出,NIO将文件或文件的一段区域映射到内存中,这样就可以像访问内存一样来访问文件了(这种方式模拟了操作系统上的虚拟内存的概念),通过这种方式来进行输入/输出比传统的输入/输出要快得多。
3.说说NIO的实现原理
? Java的NIO主要由三个核心部分组成:Channel、Buffer、Selector。
? 基本上,所有的IO在NIO中都从一个Channel开始,数据可以从Channel读到Buffer中,也可以从Buffer写到Channel中。Channel有好几种类型,其中比较常用的有FileChannel、DatagramChannel、SocketChannel、ServerSocketChannel等,这些通道涵盖了UDP和TCP网络IO以及文件IO。
? Buffer本质上是一块可以写入数据,然后可以从中读取数据的内存。这块内存被包装成NIO Buffer对象,并提供了一组方法,用来方便的访问该块内存。Java NIO里关键的Buffer实现有CharBuffer、ByteBuffer、ShortBuffer、IntBuffer、LongBuffer、FloatBuffer、DoubleBuffer。这些Buffer覆盖了你能通过IO发送的基本数据类型,即byte、short、int、long、float、double、char。
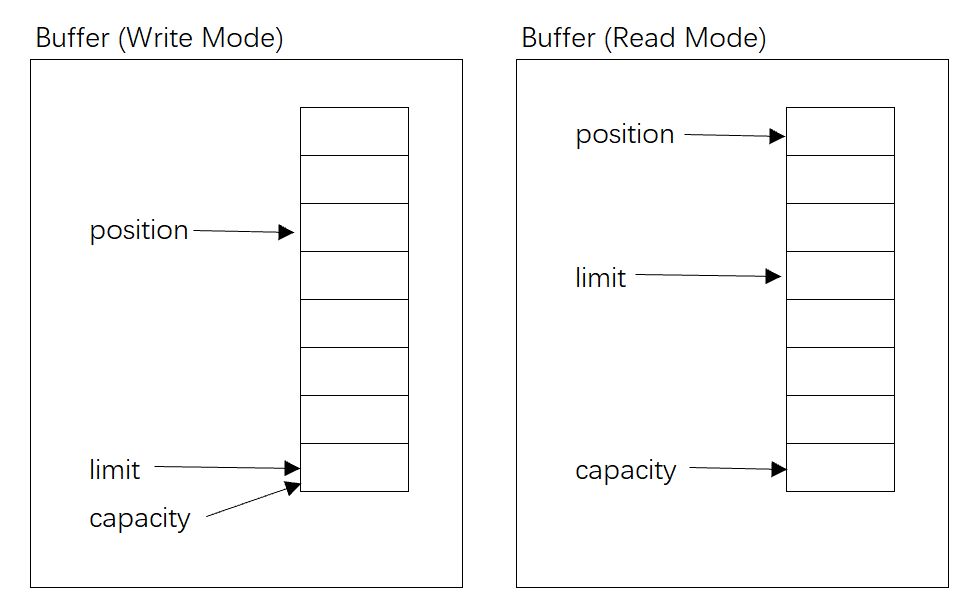
? Buffer对象包含三个重要的属性,分别是capacity、position、limit,其中position和limit的含义取决于Buffer处在读模式还是写模式。但不管Buffer处在什么模式,capacity的含义总是一样的。
- ? capacity:作为一个内存块,Buffer有个固定的最大值,就是capacity。Buffer只能写capacity个数据,一旦Buffer满了,需要将其清空才能继续写数据往里写数据。
- ? position:当写数据到Buffer中时,position表示当前的位置。初始的position值为0。当一个数据写到Buffer后, position会向前移动到下一个可插入数据的Buffer单元。position最大可为capacity–1。当读取数据时,也是从某个特定位置读。当将Buffer从写模式切换到读模式,position会被重置为0。当从Buffer的position处读取数据时,position向前移动到下一个可读的位置。
- ? limit:在写模式下,Buffer的limit表示最多能往Buffer里写多少数据,此时limit等于capacity。当切换Buffer到读模式时, limit表示你最多能读到多少数据,此时limit会被设置成写模式下的position值。
? 三个属性之间的关系,如下图所示:
? 
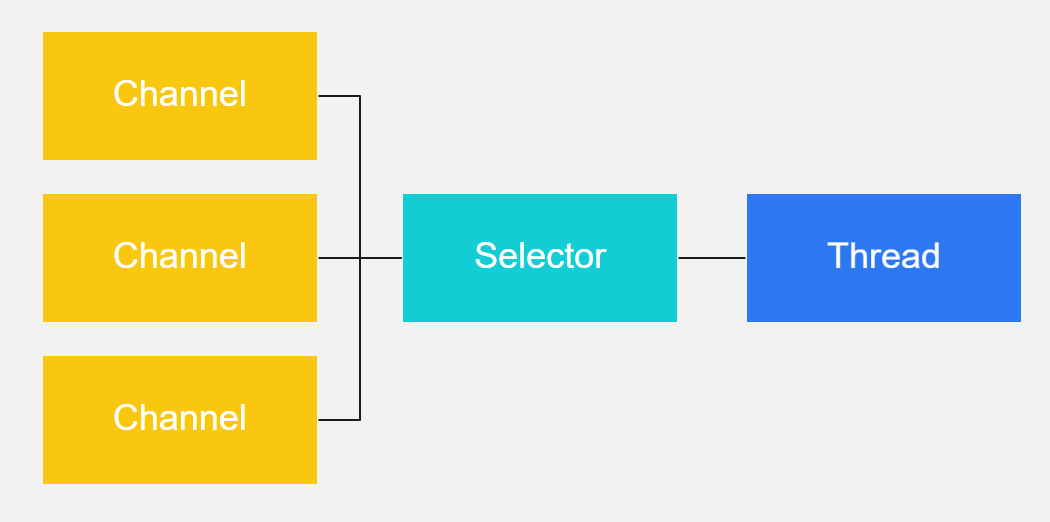
? Selector允许单线程处理多个 Channel,如果你的应用打开了多个连接(通道),但每个连接的流量都很低,使用Selector就会很方便。要使用Selector,得向Selector注册Channel,然后调用它的select()方法。这个方法会一直阻塞到某个注册的通道有事件就绪。一旦这个方法返回,线程就可以处理这些事件,事件例如有新连接进来,数据接收等。
? 这是在一个单线程中使用一个Selector处理3个Channel的图示:
? 
? 扩展阅读
? Java NIO根据操作系统不同, 针对NIO中的Selector有不同的实现:
- ? macosx:KQueueSelectorProvider
- ? solaris:DevPollSelectorProvider
- ? Linux:EPollSelectorProvider (Linux kernels >= 2.6)或PollSelectorProvider
- ? windows:WindowsSelectorProvider
? 所以不需要特别指定,Oracle JDK会自动选择合适的Selector。如果想设置特定的Selector,可以设置属性,例如: -Djava.nio.channels.spi.SelectorProvider=sun.nio.ch.EPollSelectorProvider。
? JDK在Linux已经默认使用epoll方式,但是JDK的epoll采用的是水平触发,所以Netty自4.0.16起, Netty为Linux通过JNI的方式提供了native socket transport。Netty重新实现了epoll机制。
- ? 采用边缘触发方式;
- ? netty epoll transport暴露了更多的nio没有的配置参数,如 TCP_CORK, SO_REUSEADDR等等;
- ? C代码,更少GC,更少synchronized。
4.介绍一下Java的序列化与反序列化
序列化机制可以将对象转换成字节序列,这些字节序列可以保存在磁盘上,也可以在网络中传输,并允许程序将这些字节序列再次恢复成原来的对象。其中,对象的序列化(Serialize),是指将一个Java对象写入IO流中,对象的反序列化(Deserialize),则是指从IO流中恢复该Java对象。
? 若对象要支持序列化机制,则它的类需要实现Serializable接口,该接口是一个标记接口,它没有提供任何方法,只是标明该类是可以序列化的,Java的很多类已经实现了Serializable接口,如包装类、String、Date等。
? 若要实现序列化,则需要使用对象流ObjectInputStream和ObjectOutputStream。其中,在序列化时需要调用ObjectOutputStream对象的writeObject()方法,以输出对象序列。在反序列化时需要调用ObjectInputStream对象的readObject()方法,将对象序列恢复为对象。
5. Serializable接口为什么需要定义serialVersionUID变量?
serialVersionUID代表序列化的版本,通过定义类的序列化版本,在反序列化时,只要对象中所存的版本和当前类的版本一致,就允许做恢复数据的操作,否则将会抛出序列化版本不一致的错误。
? 如果不定义序列化版本,在反序列化时可能出现冲突的情况,例如:
- ? 创建该类的实例,并将这个实例序列化,保存在磁盘上;
- ? 升级这个类,例如增加、删除、修改这个类的成员变量;
- ? 反序列化该类的实例,即从磁盘上恢复修改之前保存的数据。
? 在第3步恢复数据的时候,当前的类已经和序列化的数据的格式产生了冲突,可能会发生各种意想不到的问题。增加了序列化版本之后,在这种情况下则可以抛出异常,以提示这种矛盾的存在,提高数据的安全性。
6 .除了Java自带的序列化之外,你还了解哪些序列化工具?
- ? JSON:目前使用比较频繁的格式化数据工具,简单直观,可读性好,有jackson,gson,fastjson等等,比较优秀的JSON解析工具的表现还是比较好的,有些json解析工具甚至速度超过了一些二进制的序列化方式。
- ? Protobuf:一个用来序列化结构化数据的技术,支持多种语言诸如C++、Java以及Python语言,可以使用该技术来持久化数据或者序列化成网络传输的数据。相比较一些其他的XML技术而言,该技术的一个明显特点就是更加节省空间(以二进制流存储)、速度更快以及更加灵活。另外Protobuf支持的数据类型相对较少,不支持常量类型。由于其设计的理念是纯粹的展现层协议(Presentation Layer),目前并没有一个专门支持Protobuf的RPC框架。
- ? Thrift:是Facebook开源提供的一个高性能,轻量级RPC服务框架,其产生正是为了满足当前大数据量、分布式、跨语言、跨平台数据通讯的需求。 但是,Thrift并不仅仅是序列化协议,而是一个RPC框架。 相对于JSON和XML而言,Thrift在空间开销和解析性能上有了比较大的提升,对于对性能要求比较高的分布式系统,它是一个优秀的RPC解决方案。但是由于Thrift的序列化被嵌入到Thrift框架里面, Thrift框架本身并没有透出序列化和反序列化接口,这导致其很难和其他传输层协议共同使用(例如HTTP)。
- ? Avro:提供两种序列化格式,即JSON格式或者Binary格式。Binary格式在空间开销和解析性能方面可以和Protobuf媲美, JSON格式方便测试阶段的调试。 Avro支持的数据类型非常丰富,包括C++语言里面的union类型。Avro支持JSON格式的IDL和类似于Thrift和Protobuf的IDL(实验阶段),这两者之间可以互转。Schema可以在传输数据的同时发送,加上JSON的自我描述属性,这使得Avro非常适合动态类型语言。 Avro在做文件持久化的时候,一般会和Schema一起存储,所以Avro序列化文件自身具有自我描述属性,所以非常适合于做Hive、Pig和MapReduce的持久化数据格式。对于不同版本的Schema,在进行RPC调用的时候,服务端和客户端可以在握手阶段对Schema进行互相确认,大大提高了最终的数据解析速度。
7 .如果不用JSON工具,该如何实现对实体类的序列化?
可以使用Java原生的序列化机制,但是效率比较低一些,适合小项目;
可以使用其他的一些第三方类库,比如Protobuf、Thrift、Avro等。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- webpack的性能优化(二)——减少打包体积
- Threejs项目实战之三:根据JSON格式数据创建三维地图
- NFT获工信部首肯!“符合中国国情”的Web3.0发展战略即将问世!
- 年度技术盘点 | 探索云原生化的服务架构体系的技术风向,攻克云原生化微服务架构的痛点和特性
- VMware workstation配置Ubuntu20.04.6虚拟机NAT网络上内外网
- 如何快速水出人生中的第一篇SCI系列:深度学习目标检测算法常用评估指标——一文读懂!
- 模型之掷骰子问题
- 【2024最新版】Win11基础配置操作(磁盘分区、修改各种默认存储位置、安装软件操作)【释放C盘空间】
- c++类的静态成员变量和非静态成员变量定义和初始化为什么有区别?
- Grounding 模型 + SAM 报错