内存编织技术,JVM对内存的又一次压榨
今天这个问题就比较卷了,也是一位面试被虐得体无完肤的小伙伴提供的。放心哈,我已经安抚住他想砍面试官的心了。
其实看到这个问题,我还是挺感叹的:现在的面试题已经难到这个程度了吗?这个问题可是需要你完整得理解JVM是如何实现OOP的封装机制才能答出来的。
所有呢,给小伙伴们一个建议:简历不要凡尔赛,带来关注的同时,也带来了高期待。直接的结果就是问超难的面试题,一上来就给你打蒙圈了。
问题分析
我们先来分析下这个问题。如果你想知道怎么访问对象实例属性的底层原理,就得知道是如何存储的。存储搞明白了,访问就是一句话的事。而想搞明白存储,恰恰不是一件简单的事情。JVM中对象实例属性的存储甚至比原生的C++对象还要复杂。为什么这么说呢?往后看。
对于面向对象类型的语言来说,有两个很重要的概念:类、对象。类的所有信息在编译时就已经确定下来了。但是对象是运行时结构,它的实例属性信息,只有在执行完当前方法及其父类的构造方法才能知晓。针对这个情况,你可以事先定义一个list<T>用来存储对象的实例属性。但是实例属性的类型不确定,有可能是char、int、double、指针…你这个T好像只能用8字节的数据类型来接收才能兼容所有情况。这带来的问题就是严重的内存浪费。
那C++及Java是怎么做的呢?内存编织。解释下这个名词:编织,抽象来说,就是精细化构造。内存编织,即精细化构造内存。即在创建对象时,为了节省内存,根据不同类型的数据,精细化地向内存中填充数据。
为什么说JVM的对象实例属性存储机制比C++更难呢?因为JVM的内存编织需要考虑的点更多:一、JVM有运行时数据结构:数组。什么意思呢?就是说非数组类的元信息是在编译时确定的,而数组的元信息是在运行时确定的;二、JVM为了节省内存,开发了指针压缩技术。一开一关,两套机制需要研究;三、JVM为了比C++更节省内存,引入了字段重排机制,又给研究增加了难度。
OK!问题已经分析完了,开始展开来说。本篇文章只把谜底揭开,不会面面俱到地讲到所有。剩余的情况,有能力有好奇心的小伙伴就自行去研究啦。
其实这个问题的本质就是:JVM是如何实现OOP的封装机制的。看懂了,你对Java的理解就比别人高好几个维度。
C++中的实例属性存储
对比学习效果更佳!先来看看C++中的实例属性是如何存储的,上代码
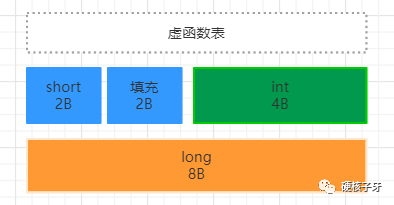
class Person {private:short s;int i;long l;};
这段代码生成的对象在内存中长这个样子,占用16B,浪费了2B
如果我把代码改一下,int移到long的下方,又完全不一样了。就变成了24字节,浪费了10字节。为什么会这样呢?因为C++这块只做到了这个程度。它是希望你在写代码的时候定规范解决这个问题。怎么规范呢?往后看。
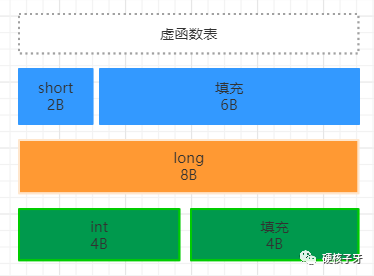
所以高手都知道:定义属性要遵循占字节少的数据类型放前面,占字节多的数据类型放后面。是不是好麻烦?我们写Java代码完全不需要考虑这个问题,JVM已经通过技术手段帮我们解决了。怎么解决的呢?往后看。
JVM中的实例属性存储
说完了C++的对象内存模型,再来说说JVM的对象内存模型,两句话:
-
创建对象进行属性编织时,按照8字节、4字节、2字节、1字节、指针的顺序进行编织。其中指针可以在最后,也可以在最前,可以通过参数控制。默认是放在最后。
-
编织时会将相同类型的属性放在一起。这样敲代码时就不需要关注属性定义的顺序。这项就是JVM独有的字段重排。这个实现起来也不是那么容易的,需要考虑很多很多。
还是上面的代码,对应的JVM对象的内存模型长这个样子
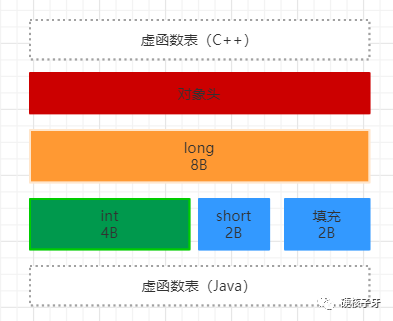
如果上面的图比较抽象,那看这张图

JVM很牛叉有木有?反正我是很喜欢研究JVM的,研究过程中真的给了我很多惊喜。不得不赞叹,跟这些个大佬相比,我怎么好意思睡觉!^_^
JVM中的实例属性访问
JVM的对象内存模型已分析完毕,可以给出答案了。其实这里还要一个问题,就是内存是无态的,比如对象中有两个int,我要取第2个,取的时候怎么知道取的是哪一个呢?这时候就要找到对象的类信息,找到类信息中存储的属性表,然后才能完成取值。上伪代码
属性表 = 对象.类型指针.属性表属性地址 = 属性表[int][1
结语
我是子牙老师,喜欢钻研底层,深入研究Windows、Linux内核、JVM。喜欢分享硬核知识,如果你也喜欢研究底层,喜欢硬核知识,关注我。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 跨境电商的语言障碍:翻译工具的必要性
- 『Linux升级路』冯诺依曼体系结构与操作系统
- 卷积神经网络相关知识点
- overflow-y: scroll;未超出仍然有滚动条
- ABAQUS应用03——装配以及对应的Python代码
- 武汉大学:如何应对来自邮件的APT攻击?
- Winform中设置程序开机自启动(修改注册表和配置自启动快捷方式)
- 【网络面试必问(9)】Web服务器处理Http请求消息及与客户端交互的原理
- Docker 学习路线 3:安装设置 Docker Desktop 与 Docker 引擎指南
- css 实现GTA5 封面