【LLM】vLLM部署与int8量化
Acceleration & Quantization

vLLM
vLLM是一个开源的大型语言模型(LLM)推理和服务库,它通过一个名为PagedAttention的新型注意力算法来解决传统LLM在生产环境中部署时所遇到的高内存消耗和计算成本的挑战。PagedAttention算法能有效管理注意力机制中的键和值,将它们分割成更小、更易于管理的块,从而减少了vLLM的内存占用,并使其吞吐量超过传统LLM服务方法。
下图展示了三种不同配置下的语言模型(分别为LLaMA-13B、LLaMA-7B配备A100-40GB GPU和LLaMA-7B配备A10G GPU)在处理文本生成推理(TGI)任务时的服务吞吐量(每分钟处理的请求量)。我们可以看到,vLLM在所有配置中都提供了最高的吞吐量,这表明其在处理大规模模型推理任务时的高效性。
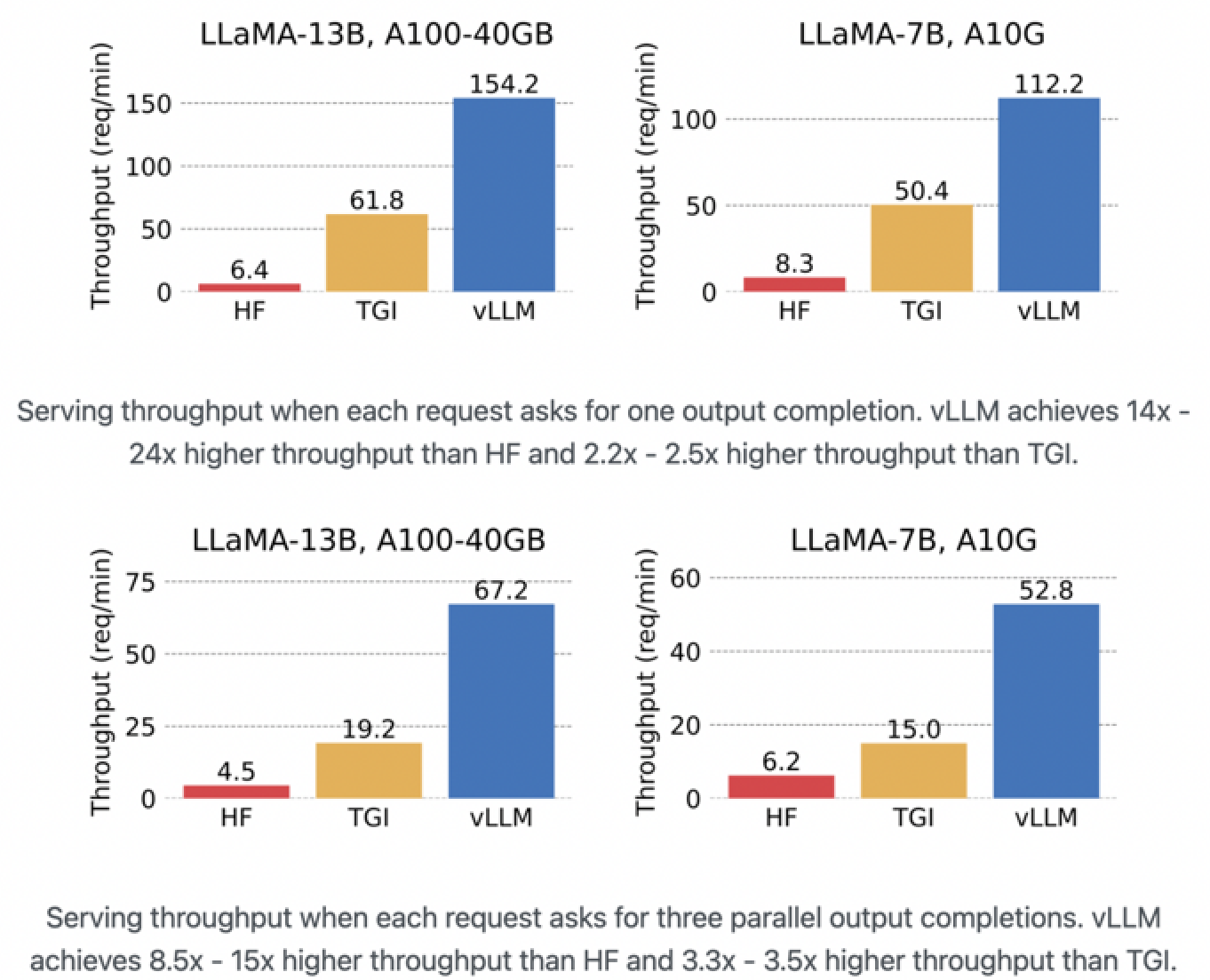
在LLaMA-13B, A100-40GB配置中,vLLM的吞吐量为154.2 req/min,而传统的HuggingFace(HF)模型和TGI分别只有6.4和61.8 req/min。同样,在LLaMA-7B, A100-40GB和LLaMA-7B, A10G配置中,vLLM都显著超过了HF和TGI。
这些数据强调了vLLM在提高服务吞吐量方面的能力,特别是当每个请求需要一个输出完成时,vLLM的吞吐量是HF的24倍,并且是TGI的2.2x到2.5x。当每个请求需要三个输出完成时,vLLM的性能更加突出,其吞吐量是HF的8.5x到15x,并且是TGI的3.3x到3.5x。
可以认为,vLLM因其在服务吞吐量方面的卓越性能,特别适合于生产环境中部署大型语言模型,尤其是在需要高效率处理大量推理请求的场景。
Cache
Cache是目前生成式的Transformer常用的一种加速手段。
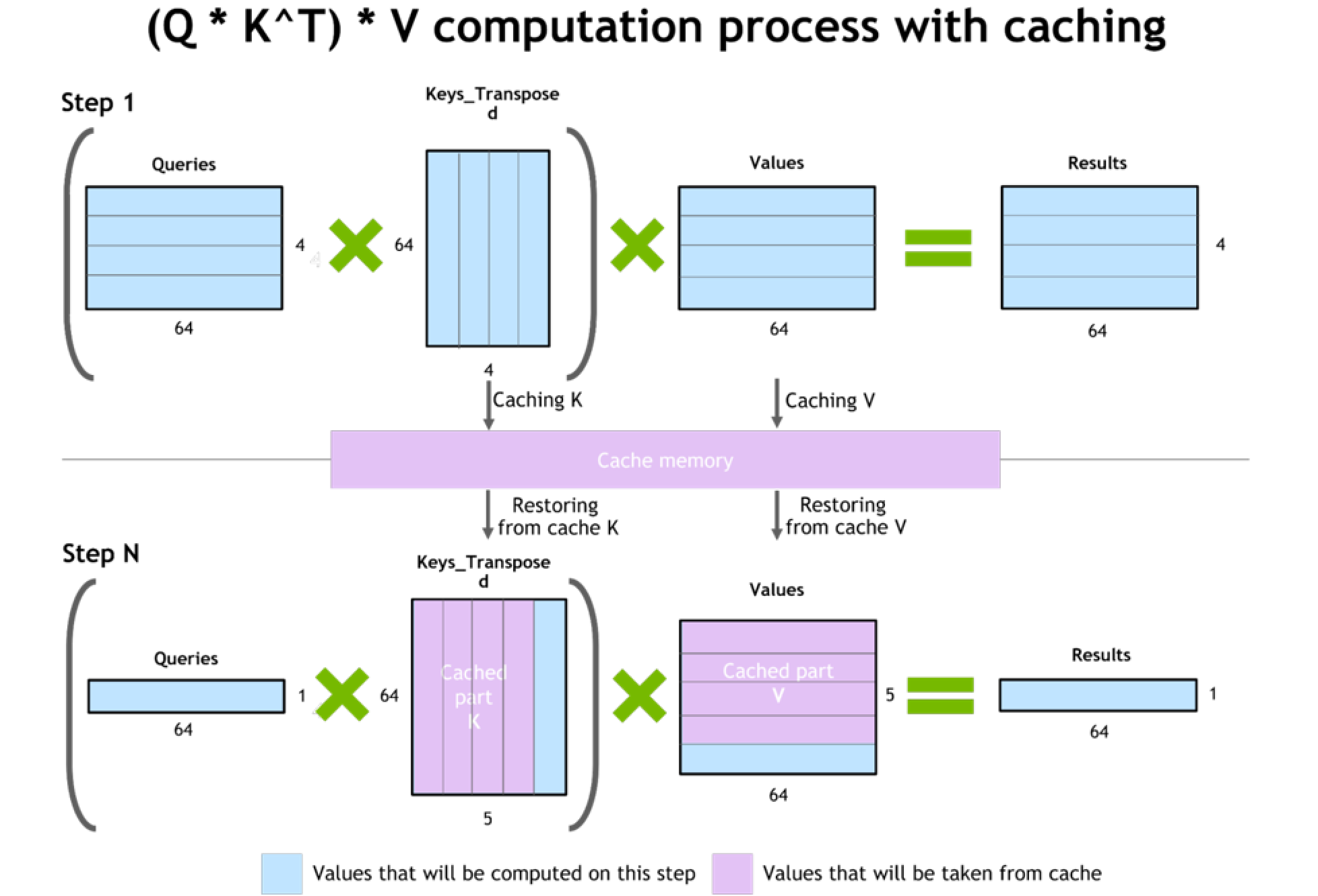
下图解释了在有缓存的情况下计算(Q * K^T)* V,即查询(Q)、键的转置(K^T)和值(V)的乘积的过程。这是一个注意力机制计算的典型步骤,常见于自然语言处理中的Transformer架构。
-
步骤1:查询(Q)与键的转置(K^T)相乘,然后再与值(V)相乘得到结果。在这个过程中,键(K)和值(V)被缓存到缓存内存中,以便将来使用。
-
步骤N:在一个后续步骤中,从缓存中恢复键(K)和值(V),并只计算当前步骤中所需的部分。这样可以提高计算效率,因为可以重复使用之前步骤中已计算和缓存的部分。
蓝色部分表示在当前步骤中将要计算的值,而紫色部分表示将从缓存中取出的值。这种方法通过减少重复计算和利用缓存中的数据,提高了计算效率。
这两张图比较了在自然语言处理模型中,特别是在Transformer架构的注意力机制中,有和没有KV-Cache(键值缓存)时的处理过程。
Without KV-Cache:
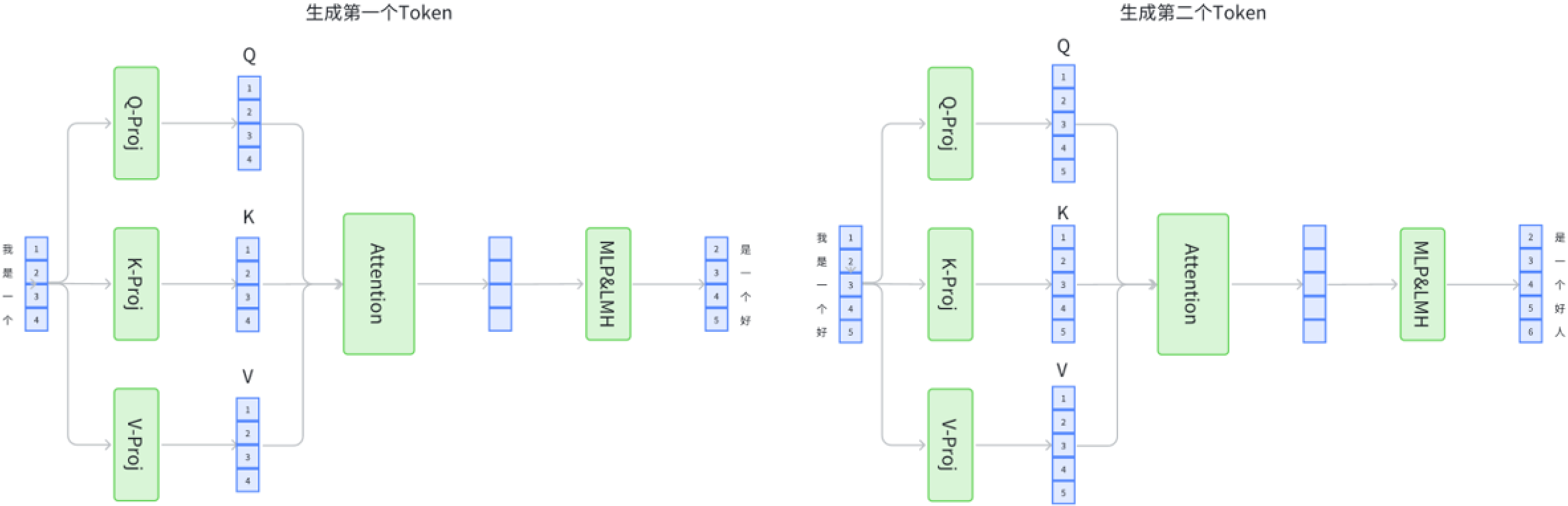
- 每一个输入Token(例如,“我是一个好”的每个词)都会通过Q、K、V矩阵得到相应的查询(Q)、键(K)和值(V)。
- 然后进行Attention计算,此过程包括Q和K的点积,然后用这个结果来加权V,得到最后的输出。
- 由于没有KV-Cache,每次处理新Token时都需要重新计算整个序列。
With KV-Cache:
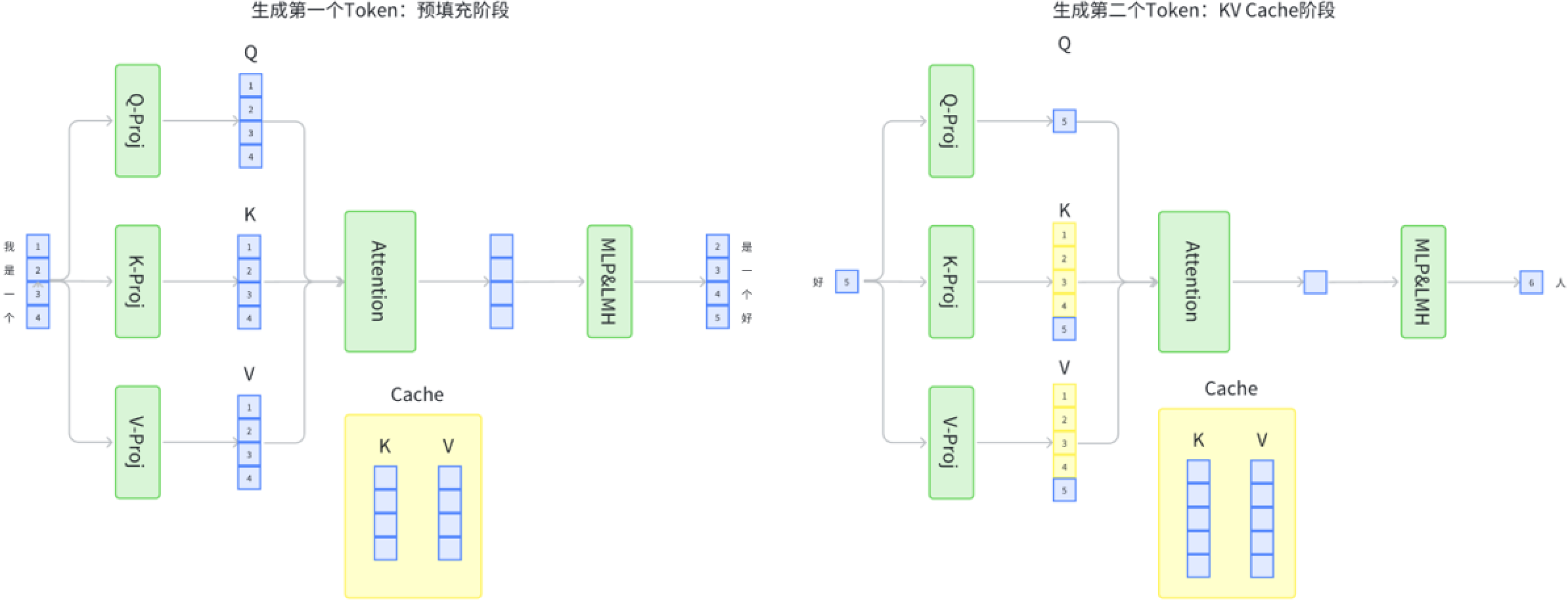
- 在处理序列的第一个Token时,也是通过Q、K、V矩阵得到查询、键和值。
- 计算Attention后,K和V会被存储在缓存中。
- 当处理下一个Token时(例如,“好”字),模型会使用缓存中的K和V值,而不是重新计算它们。
- 这样可以提高效率,因为模型不必每次都处理整个序列,而是可以重复使用已经计算过的值。
在这个例子中,“我是一个好人”中的每个字会被依次处理,而使用KV-Cache可以减少重复计算,从而提高模型的效率。
为什么Cache只存储K、V,而不存储Q?
在Transformer架构的注意力机制中,Q(Query)代表当前输入Token的查询信息,它需要与所有先前和当前的K(Key)进行匹配来决定注意力的分配。因为Q是专门针对当前正在处理的Token的,所以它每次都是独一无二的,即便在没有Cache的情况下,对于序列中的每个新Token,Q都会改变。
相反,K(Key)和V(Value)通常与序列中已经处理过的Token相关,它们可以被缓存起来供后续的Token查询使用。存储K和V使得模型可以重用之前Token的信息,而不必重新计算它们,这样可以大大节省计算资源。如果存储Q值,对于每个新的Token,我们仍然需要重新计算整个Q与所有K的匹配度,这不会减少计算量。因此,只缓存KV值而不缓存Q值,是为了优化计算效率。
PageAttention
铺垫了这么多我们来介绍一下vLLm的PageAttention方法。
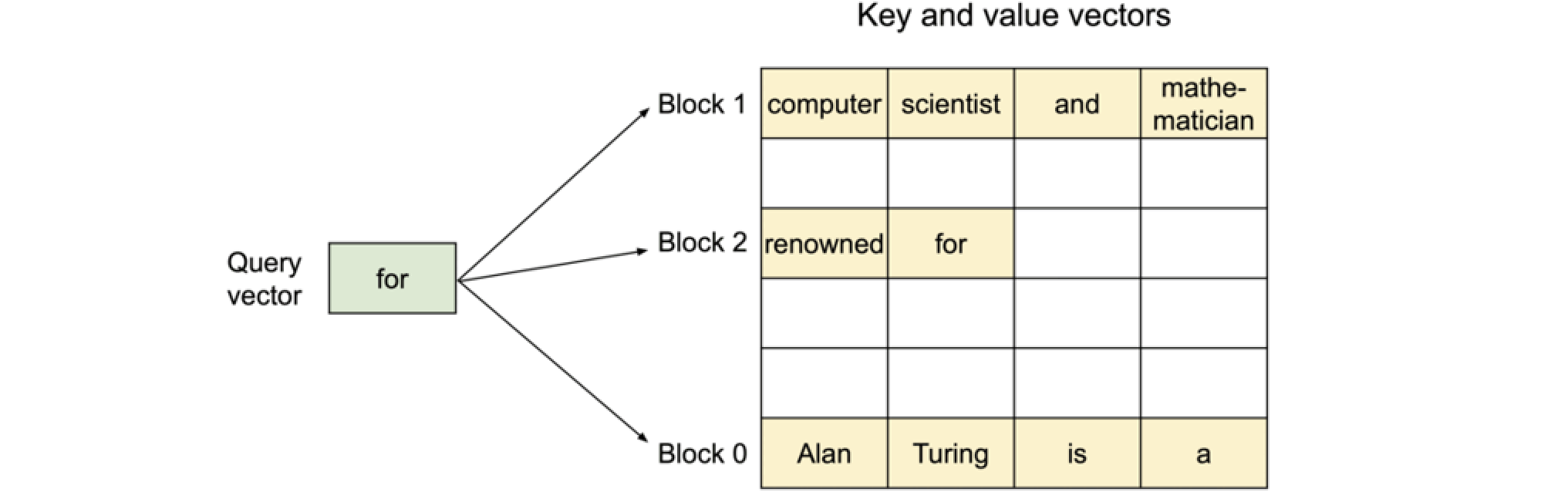
PageAttention机制是一种优化的注意力机制,通过将键(Key)和值(Value)分块来处理,以减少计算资源的使用。
0. Before generation
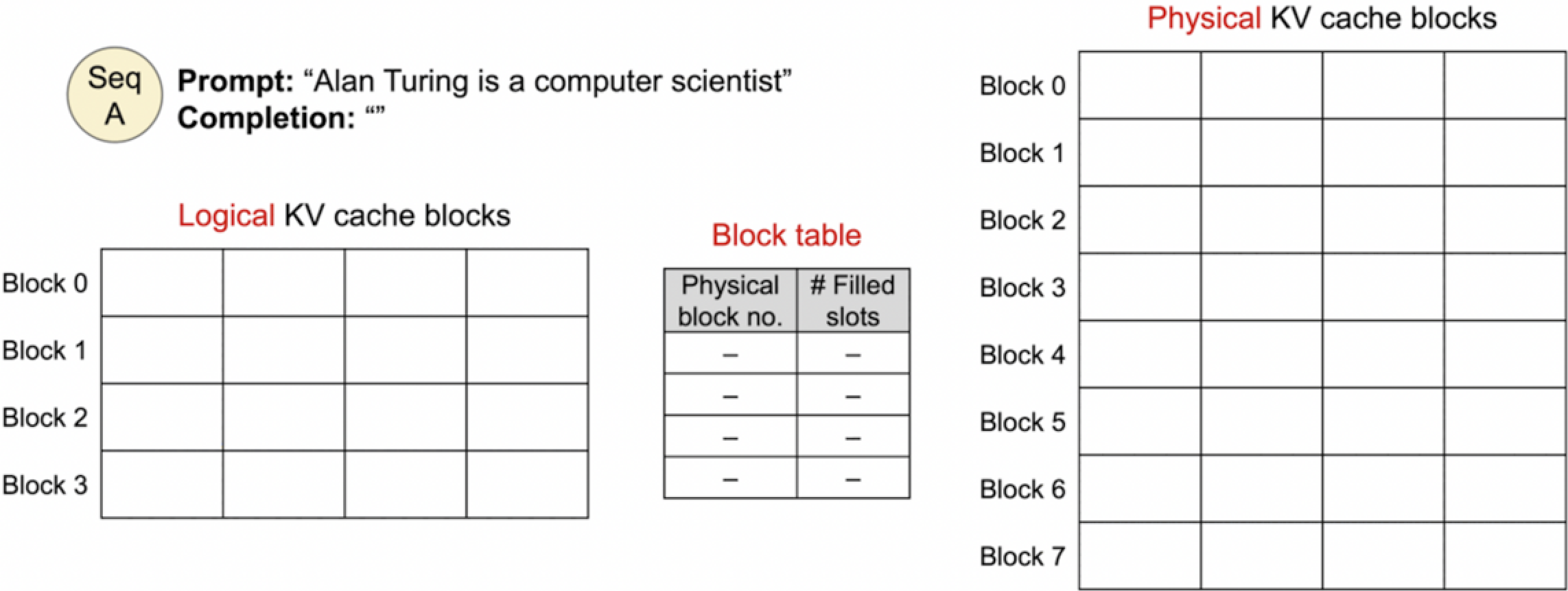
上图表示的是文本生成过程开始前的状态,即逻辑KV缓存块和物理KV缓存块的初始状态
逻辑内存是按需分配的 (由PyTorch或者cuda?),而物理内存是实际存储数据的硬件 (GPU) 。
在图中,我们有一个提示(Prompt):“Alan Turing is a computer scientist”,接下来需要生成(Completion)的文本。逻辑KV缓存块还没有填充任何数据,这表示我们还没有开始文本生成过程。物理KV缓存块同样是空的,显示没有任何键(Key)或值(Value)被存储。
1. Allocate space and store the prompt’s KV cache
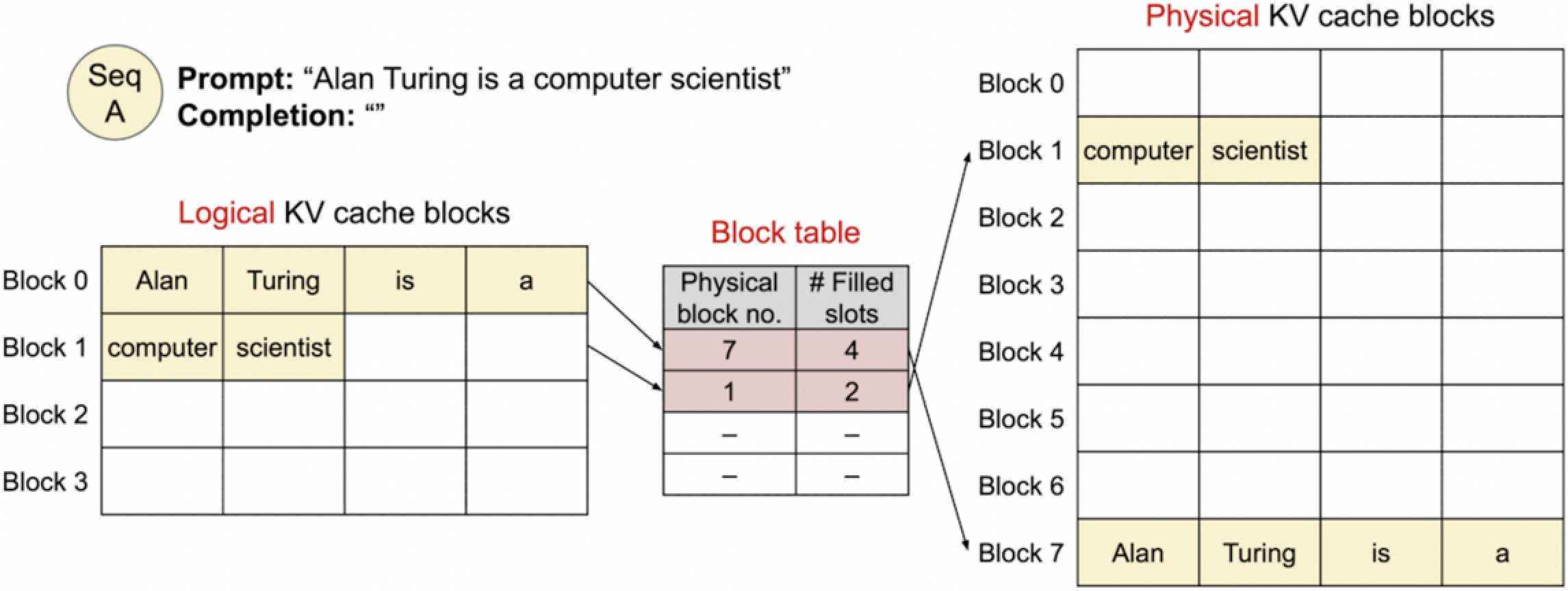
在这张图中,我们看到了提示(Prompt)“Alan Turing is a computer scientist” 的KV缓存已经被分配和存储。逻辑KV缓存块中的Block 0被填充了单词 “Alan”、“Turing”、“is”、“a”,而Block 1则被填充了 “computer” 和 “scientist”。
同时,物理KV缓存块表格显示Block 0实际上被映射到了物理块7,且有4个槽位被填充;Block 1映射到了物理块1,有2个槽位被填充。这表示系统已经为这些词分配了物理存储空间,并且准备好了用于生成过程中的查询。这是将提示转换为KV对并存储到缓存系统中的第一步,为接下来的文本生成做准备。
2. Generated 1st token
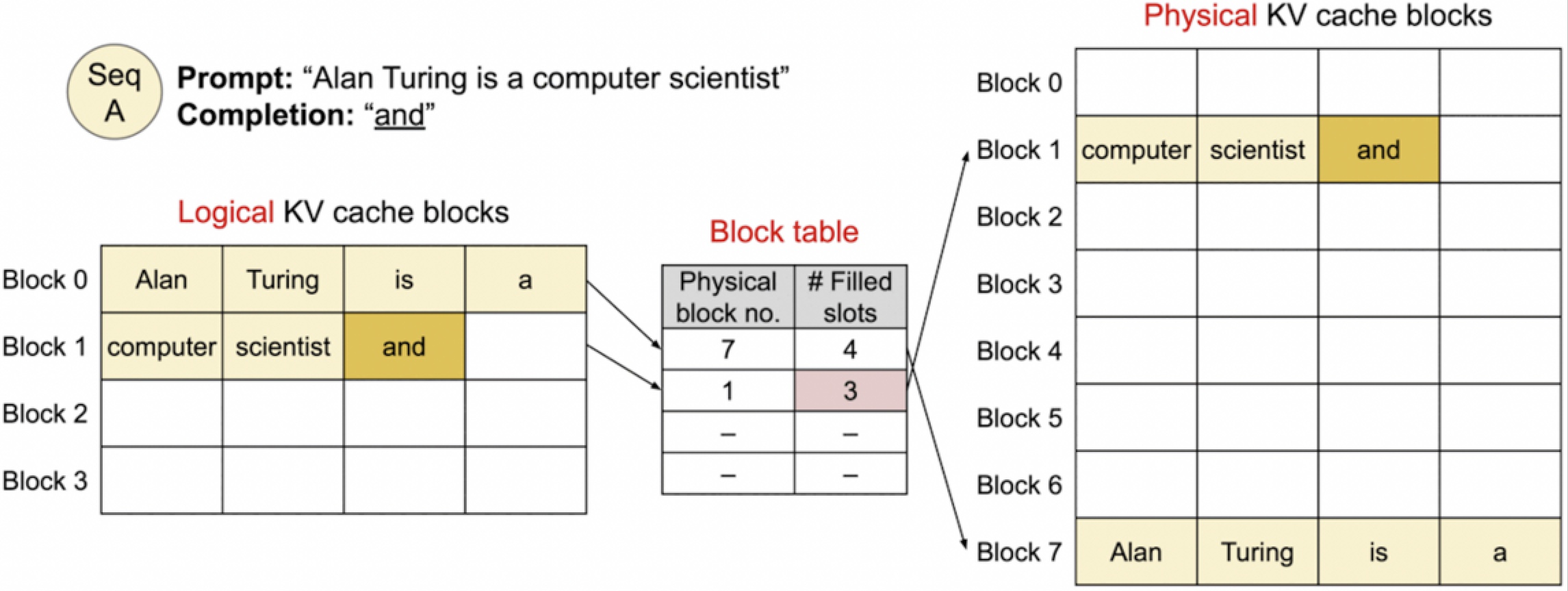
到了这步,文本生成进程已经开始,并且生成了第一个词“and”。在逻辑KV缓存块中,我们可以看到“and”已经被添加到Block 1中,这个块之前已经包含了“computer scientist”。
同时,物理KV缓存块的表格显示Block 1现在填充了3个槽位,这表明“and”已经被添加到了物理块1中。这反映了随着生成过程的进行,逻辑和物理缓存块是如何动态更新以包含新生成的Token的。这允许模型在后续的生成步骤中利用这些新的信息。
3. Generated 2nd token
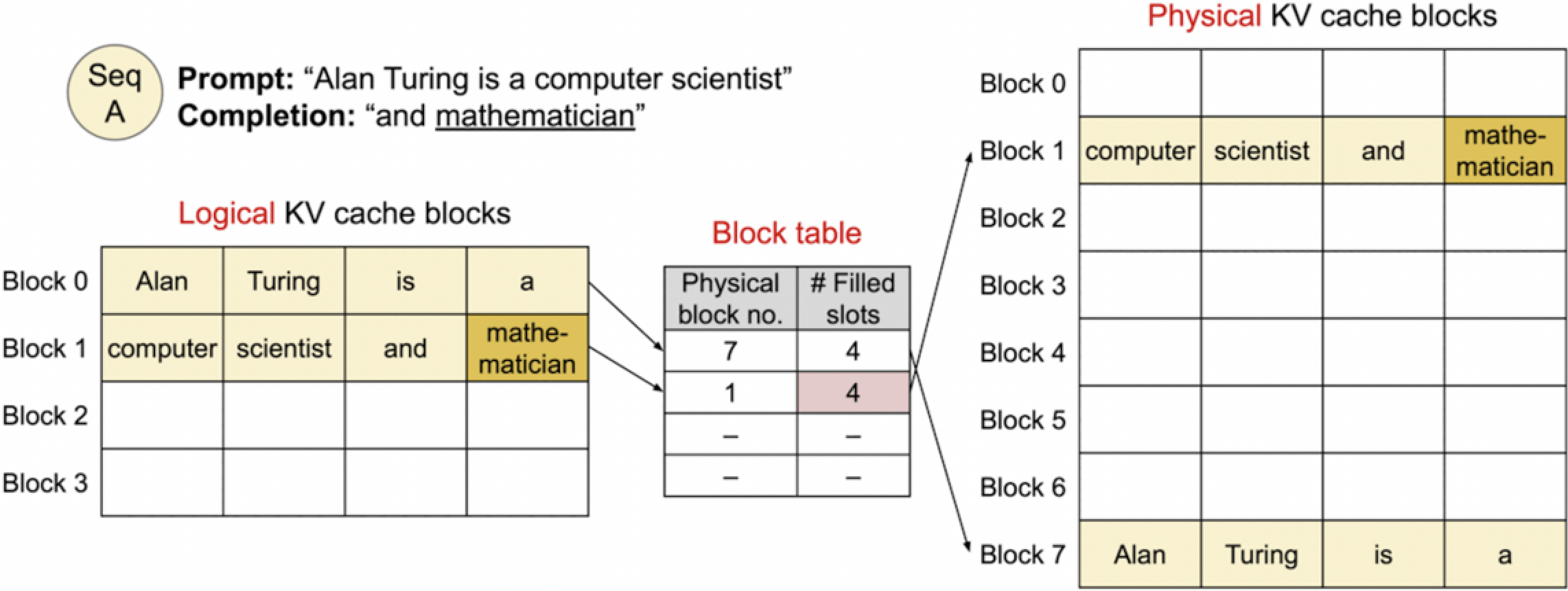
接下来,第二个词“mathematician”已经被生成。逻辑KV缓存块的Block 1现在包含了“computer”、“scientist”、“and”以及新生成的“mathematician”。
4. Generated 3rd token. Allocate new block.
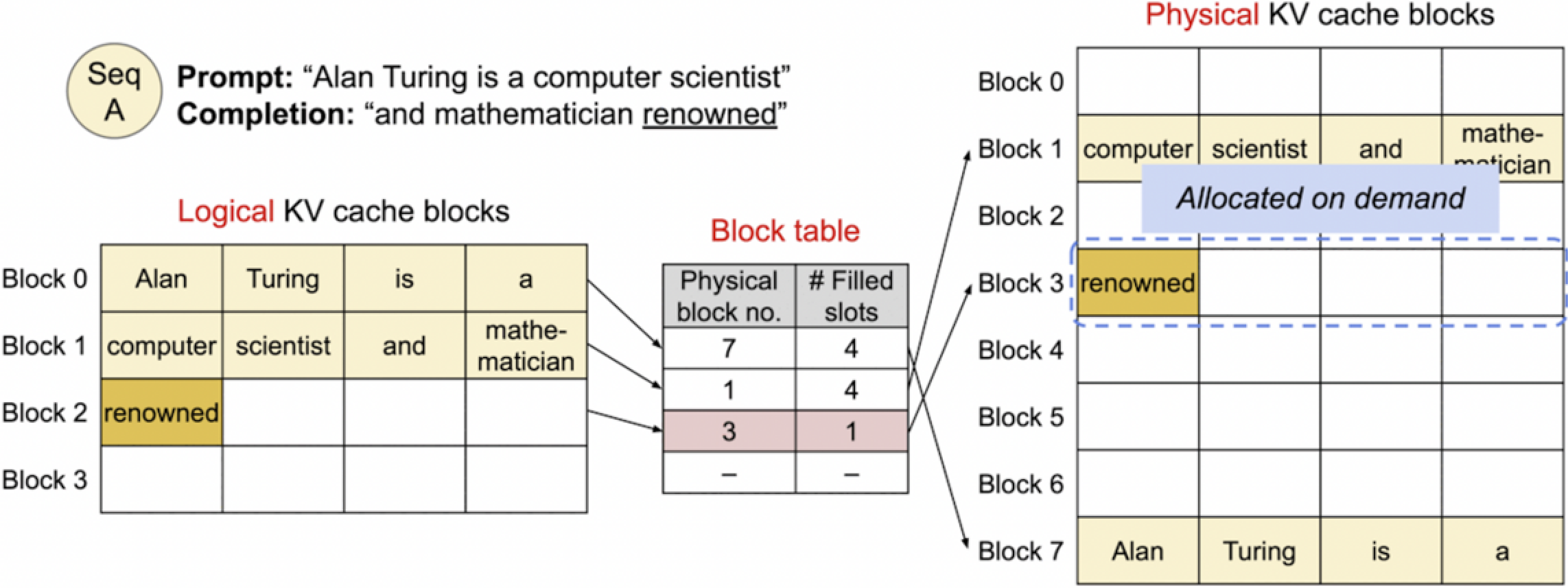
在这张图中,我们看到了文本生成过程的进一步发展。此时"renowned" 这个词已经生成并被添加到了逻辑KV缓存块的Block 2中。对应地,在物理KV缓存块中,一个新的块(Block 3)被分配来存储这个新词,这显示了缓存系统如何动态地根据需求分配空间。
5. Generated 4th token.
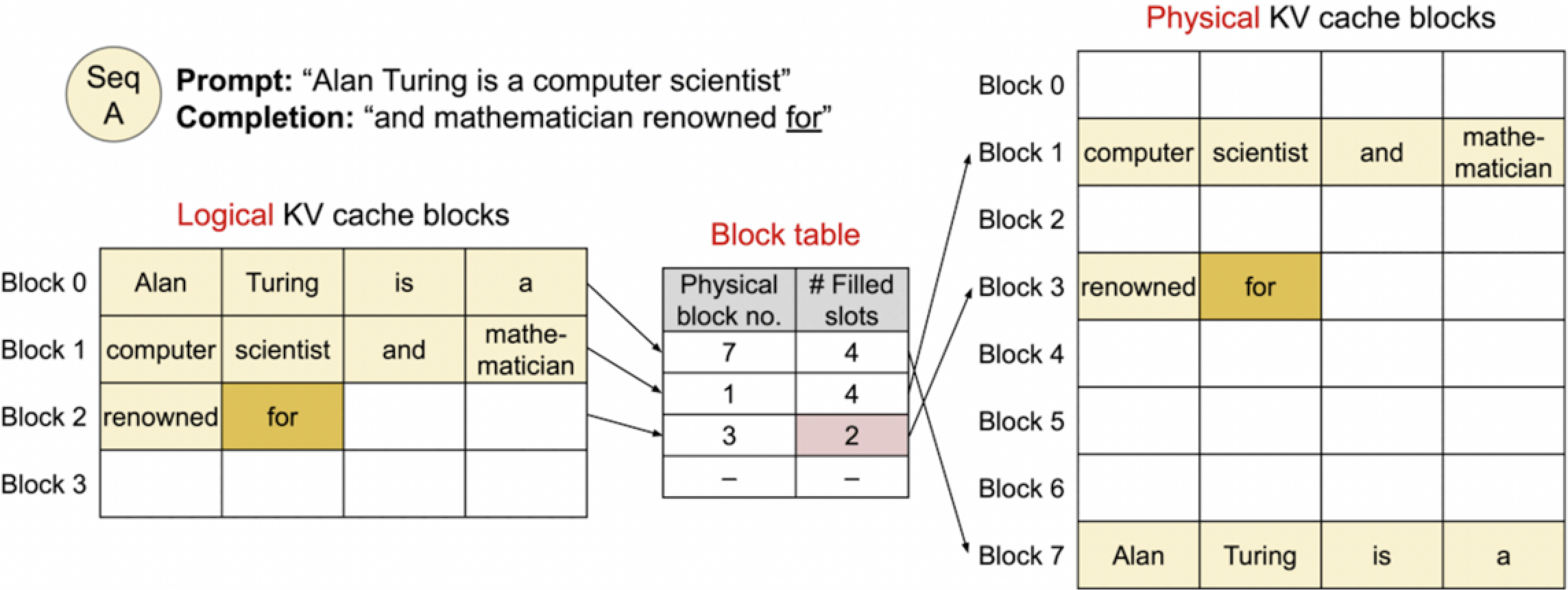
接下来生成的词 “for”,它也被添加到了逻辑KV缓存块的Block 2中。同样,物理KV缓存块的Block 3现在填充了两个槽位,包含了 “renowned” 和 “for”。
这一系列图像描绘了一个动态的、逐步构建的过程,其中每个新生成的Token都被添加到逻辑和物理KV缓存中,以支持连续的文本生成。随着生成的进行,物理缓存块持续更新,以确保快速访问到相关的键和值。
Prompt to Muitiple Outputs
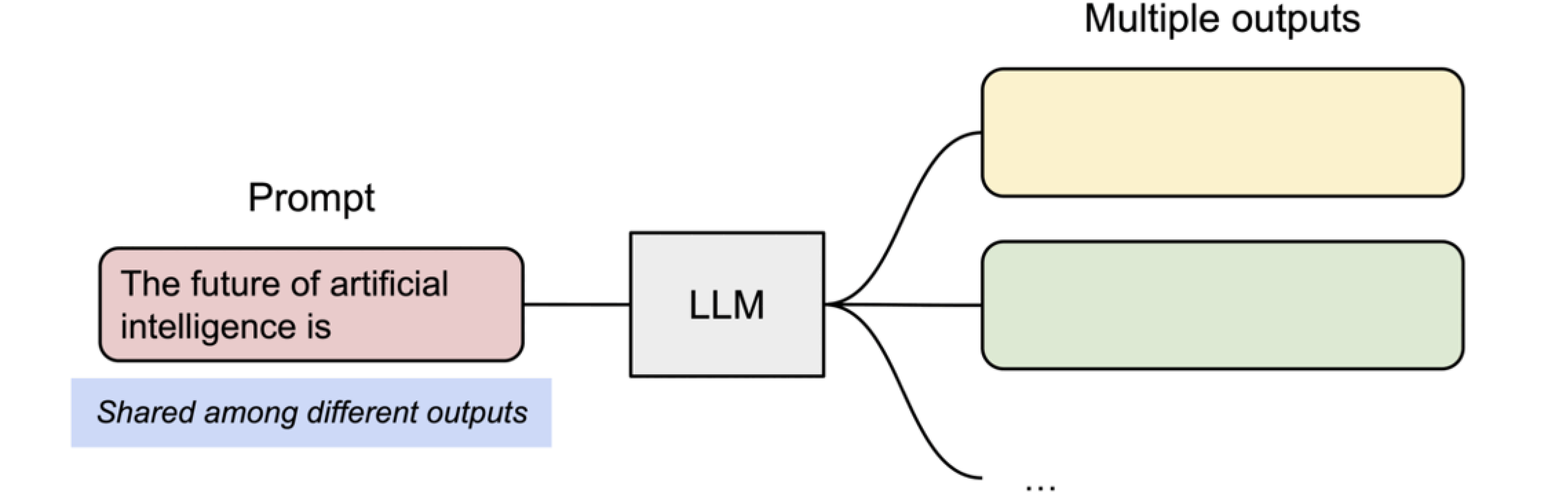
0. Shared prompt: Map logical blocks to the same physical blocks.
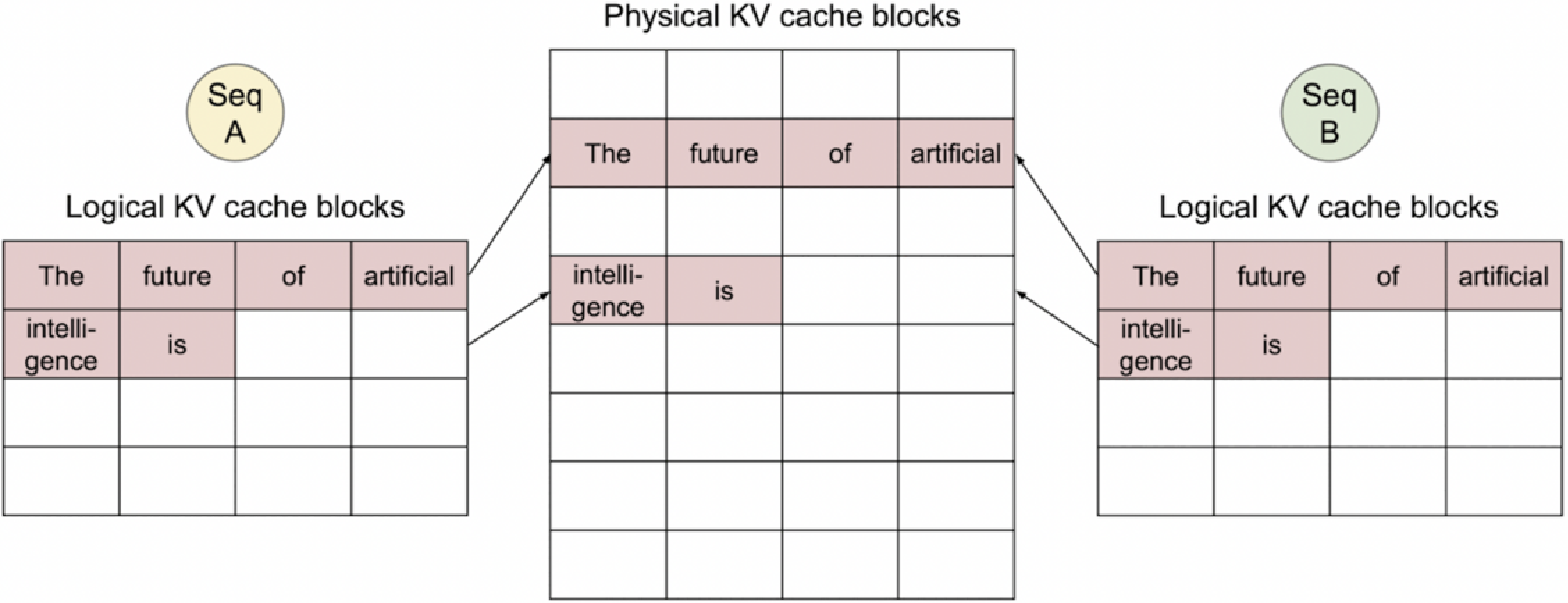
在处理多个序列(例如 Seq A 和 Seq B)时vLLM会共享一个共同的提示(Prompt)。这种设置可能用于一个模型同时进行多个任务,或者在多任务学习环境中。逻辑KV缓存块展示了不同序列可以共享相同的提示“ The future of artificial intelligence is”,而这个提示被映射到相同的物理KV缓存块上。
这种共享方式表明,当多个序列处理相同的初始信息时,可以节省资源和时间,因为模型不需要为每个序列单独存储或计算相同的提示信息。这对于优化处理效率和加快推理速度是有益的。
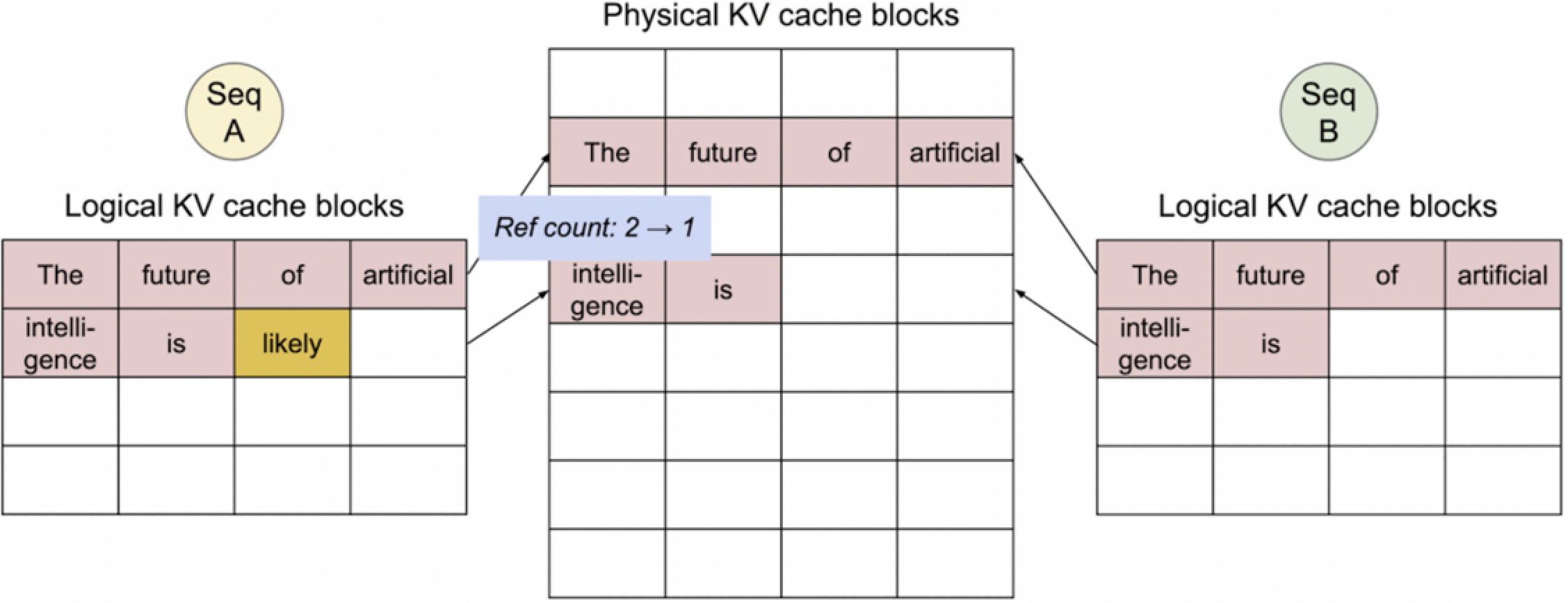
1. Seq A generated 1st token.

此时我们假设 Seq A 生成了一个额外的词 “likely”,并且这个词被添加到了它的逻辑KV缓存块中。物理KV缓存块显示了对应的条目,并有一个引用计数“Ref count: 2”,这意味着有两个不同的逻辑块正在引用这个物理块。
2. Copy-on-Write: Copy to a new block.
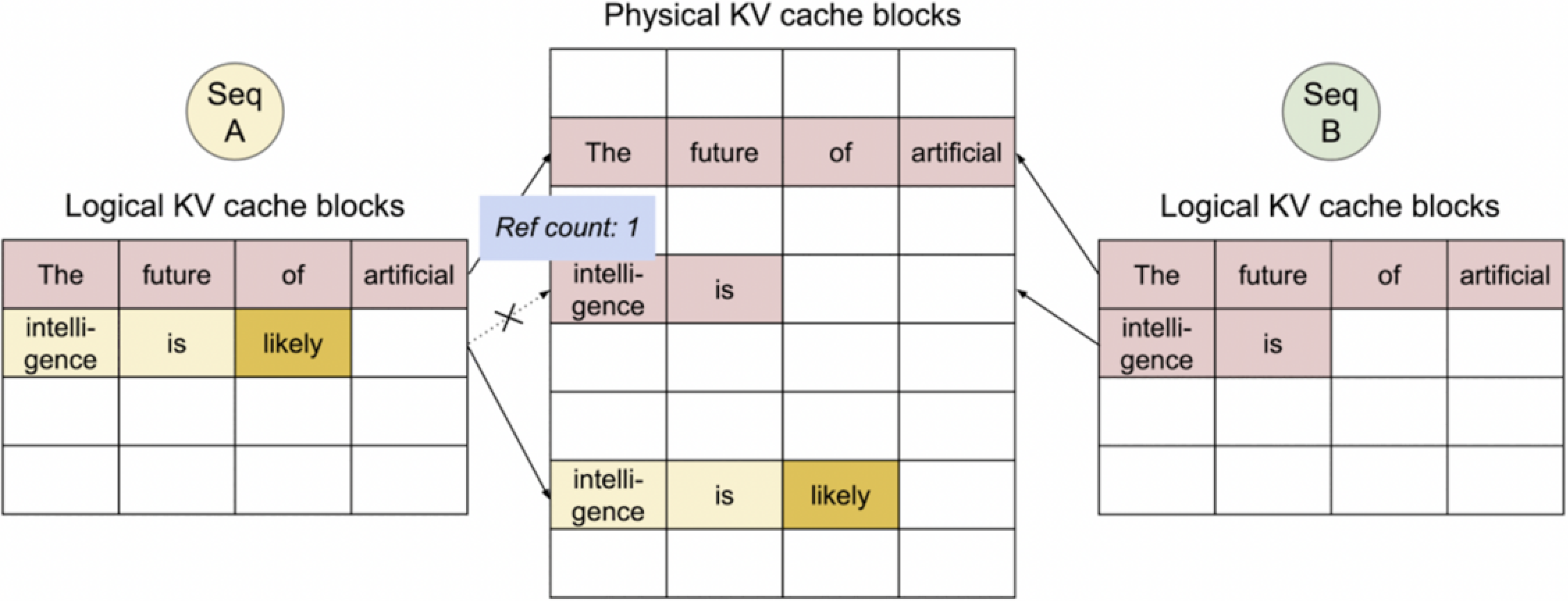
这些图展示了“写时复制”(Copy-on-Write)策略在缓存管理中的应用。当Seq A和Seq B共享相同的物理KV缓存块,并且当Seq A更改其内容时(添加了“likely”),引用计数从2减少到1,表明这些物理块不再被Seq B共享。然后,Seq A的更改被复制到一个新的物理块中,以防止对Seq B的逻辑视图产生影响。这样,每个序列可以独立地维护和更新其状态,而不会干扰到其他序列。
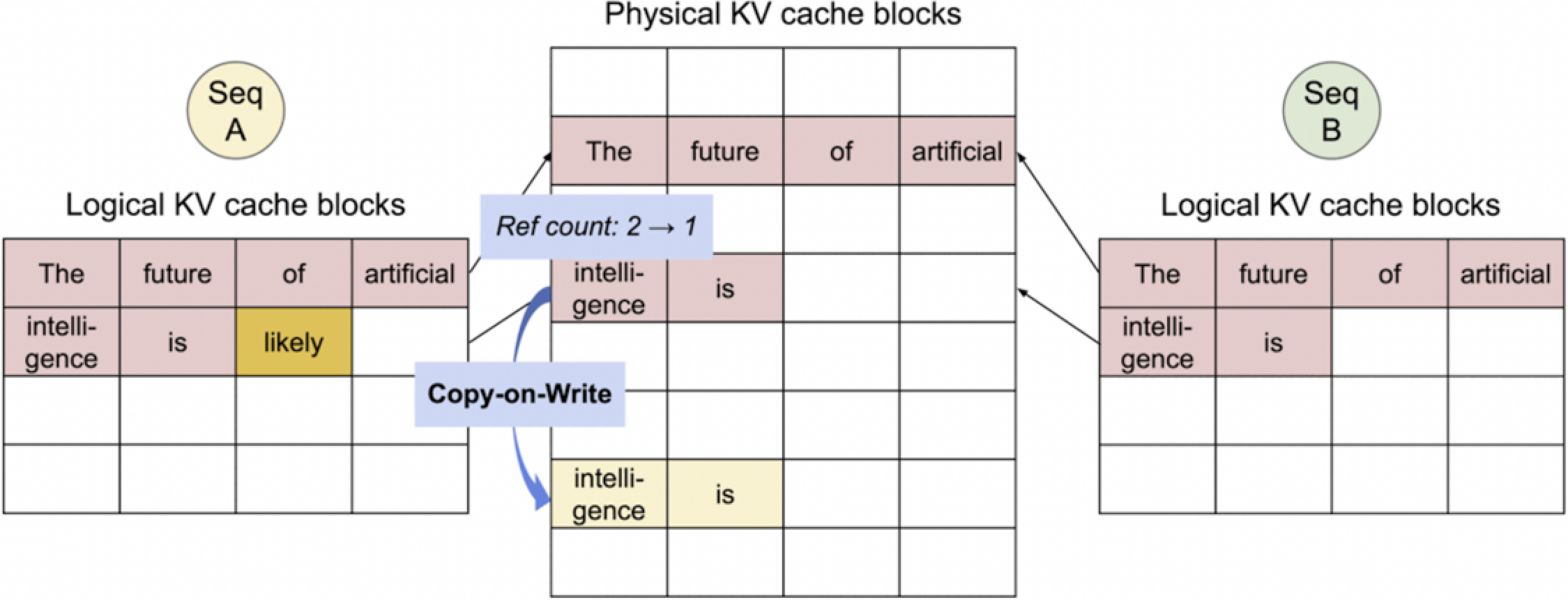
这种机制在多任务处理和内存优化中非常有用。
3. Seq B generated 1st token. No copy needed.
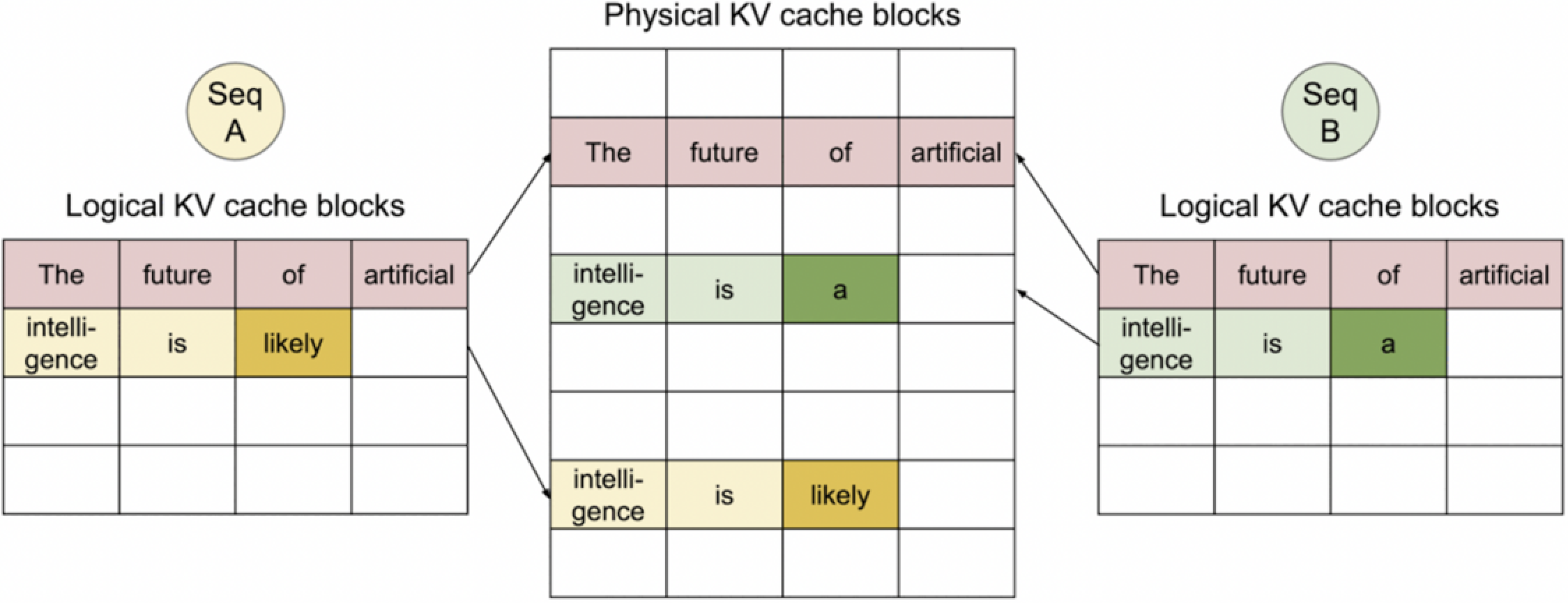
接下来当 Seq B 生成时,不会进行 Copy。
4. Seq A and B generated 2nd token.
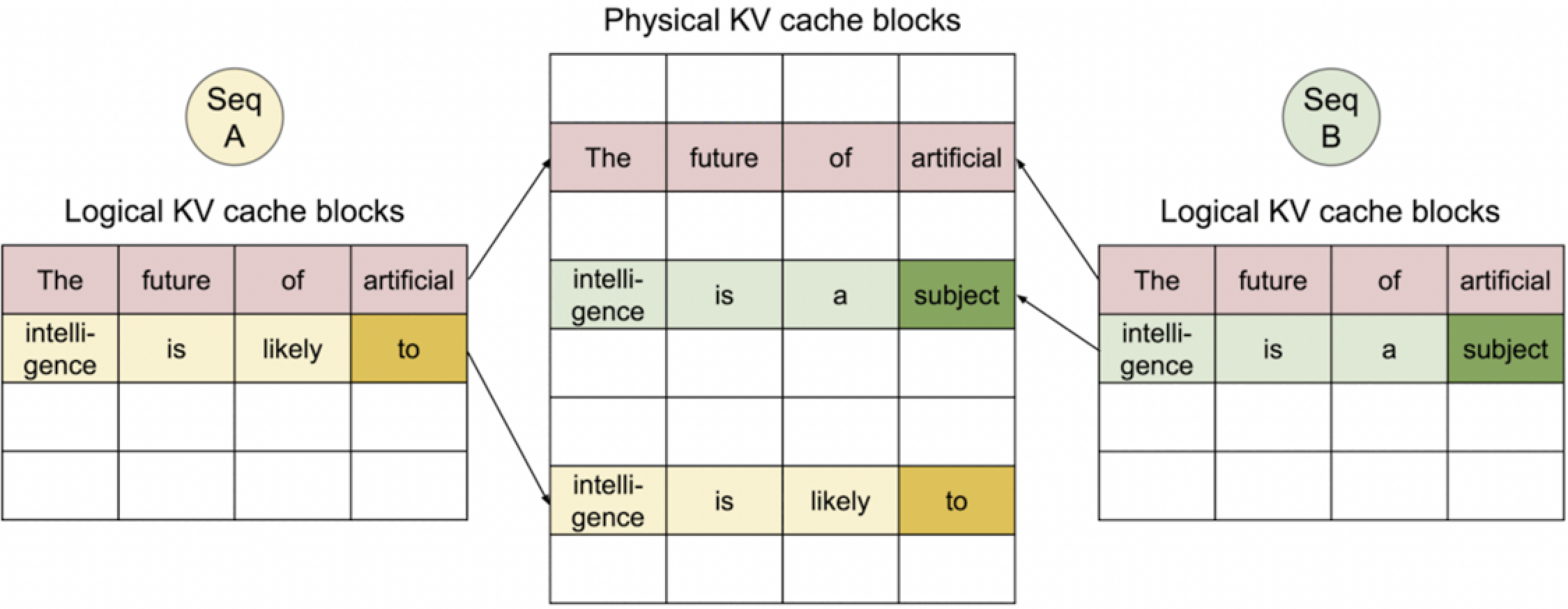
同理生成第2个token。
5. Seq A and B generated 3rd token.
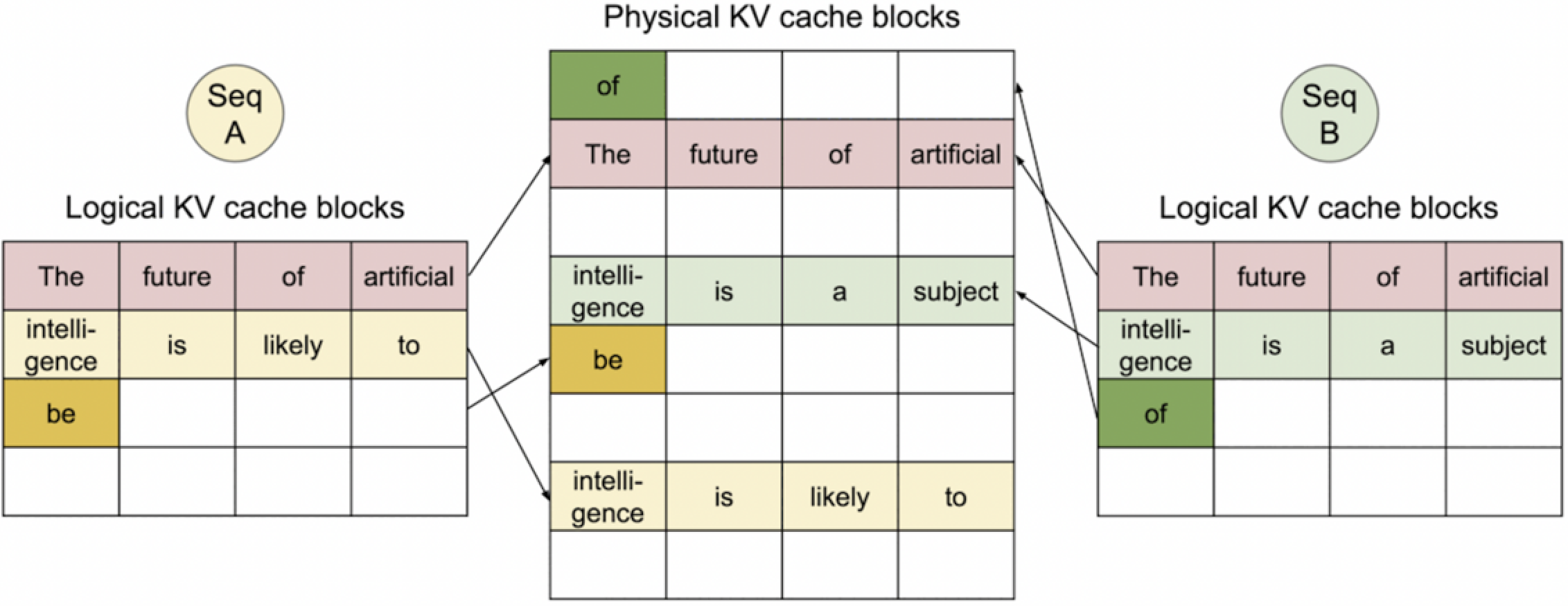
分配新的 Logical-Physical 映射,生成第3个token。
6. Seq A and B generated 4th token.
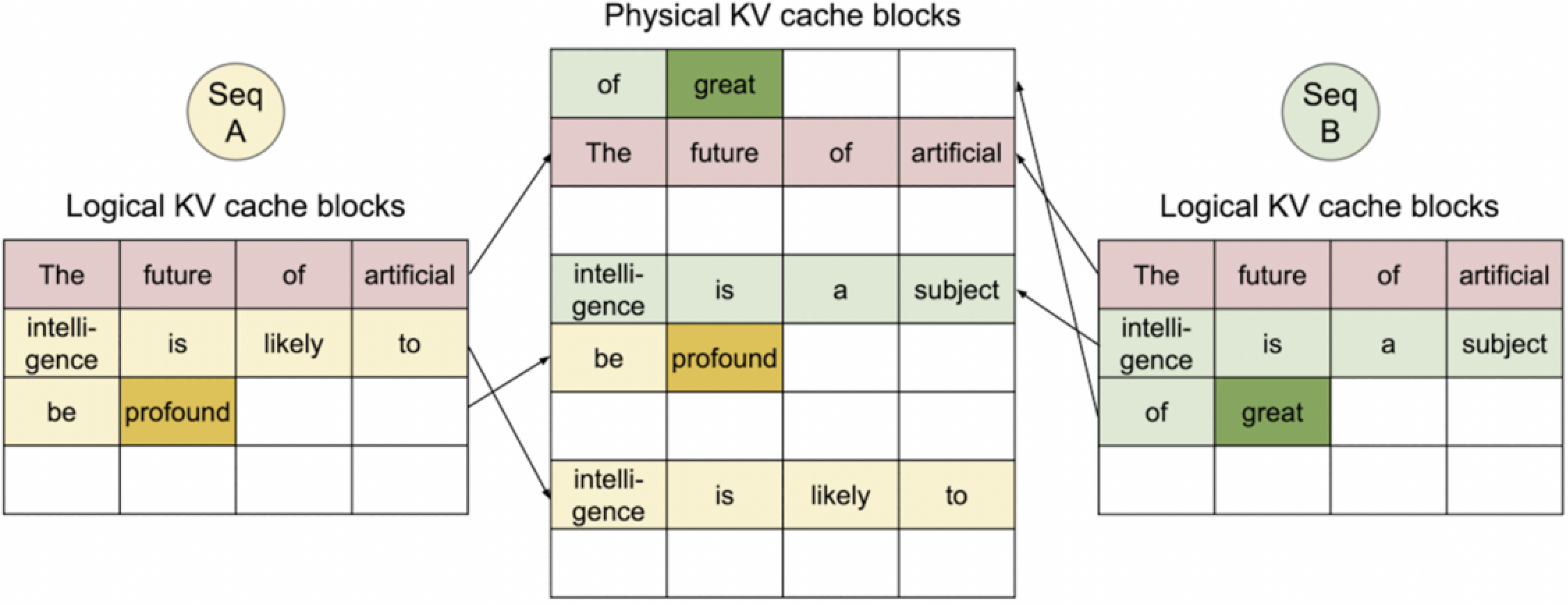
继续生成。
Summary
总结一下,vLLM优化了内存使用上的一些浪费,同时也能够兼容huggingface上一些主流的模型。

vLLM推理部署
vLLM的调用
有两种方式可以调用vLLM来加载模型,一种是通过API Server,另一种是离线推理。
- API Server
!VLLM_USE_MODELSCOPE=True python -m vllm.entrypoints.api_server \
--model="./output/models/llama-"
curl http://localhost:8000/generate \
-d '{
"prompt": "San Francisco is a",
"use_beam_search": true,
"n": 4,
"temperature": 0
}'
from transformers import AutoModel
model = AutoModel.from_pretrained("../Llama-2-7B-Chat-fp16", load_in_8bit=True)
for name, params in model.named_parameters():
print(name, params.dtype)
- Offline Batched Inference
from vllm import LLM, SamplingParams
import torch
# device = torch.device('cuda:2')
llm = LLM(model="../Llama-2-7B-Chat-fp16", gpu_memory_utilization=0.7)
# llm.to(device)
这里的gpu_memory_utilization参数就是vLLM提供的内存优化参数。
可以做个实验
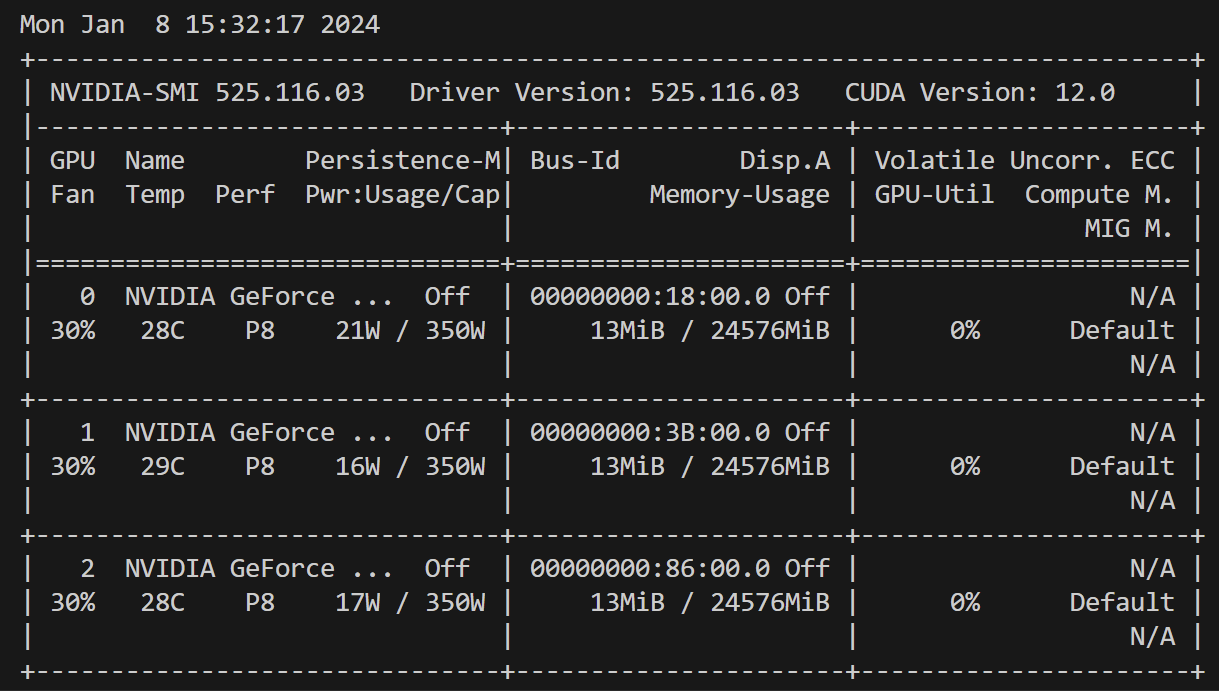
这是我原来的内存,目前只有13M的占用
如果我们直接在24G的现存中加载半精度的Llama-2-7B,会报OM(Out of Memory)
from transformers import AutoModel model = AutoModel.from_pretrained("../Llama-2-7B-Chat-fp16") model = model.to("cuda:0")事实上,要加载半精度的Llama-2-7B需要大约29152MiB的内存空间(对,很尴尬地卡住了24G内存)。
但是,使用vLLM的
gpu_memory_utilization这个参数,我们可以对加载内容进行大小优化from vllm import LLM, SamplingParams llm = LLM(model="../Llama-2-7B-Chat-fp16", gpu_memory_utilization=0.7)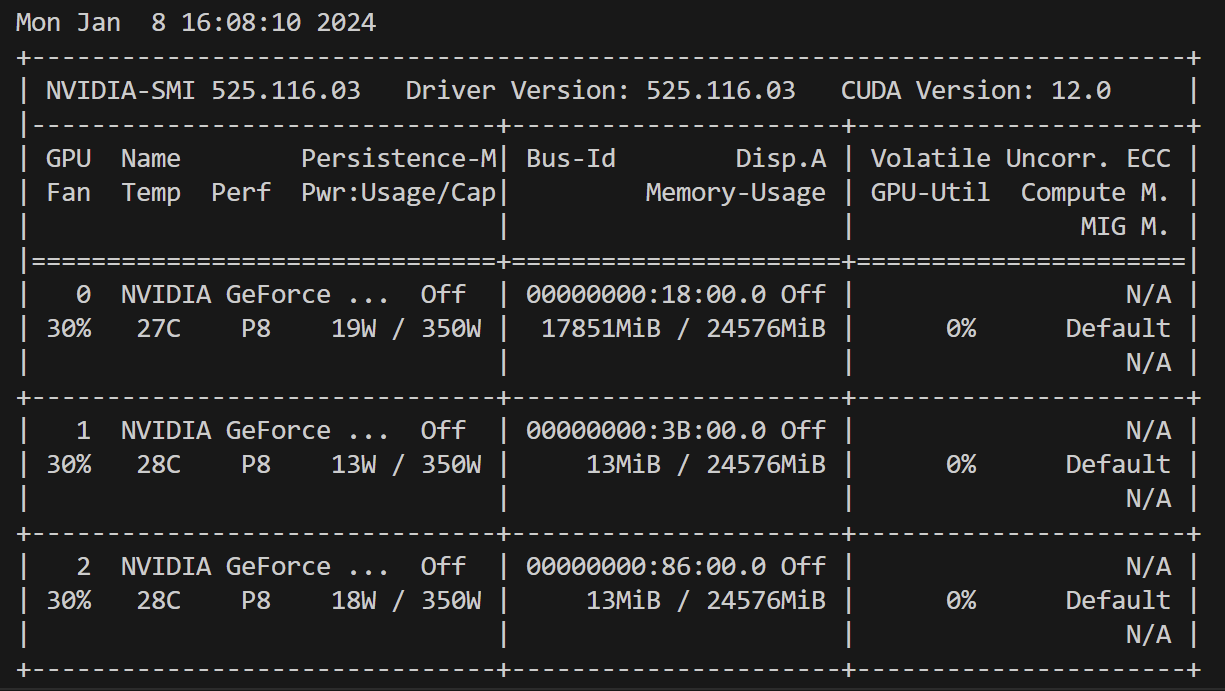
可以看到大约用了17G的内存。
当然,空间不可能无限优化下去,如果进一步测试可以发现
gpu_memory_utilization=0.3是能够加载一个7B模型的极限(大约15G)。
下面来测试一下
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
"One way to crack a password",
"I know unsensored swear words such as"
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")

还是很快的,1秒可以迭代15句。
vLLM with LoRA
vLLM其实一开始并不支持peft,因为显然它在对内存优化的时候改变了一些模型的结构(vllm-vllm-model_executor_models下可以看到它将主要模型的结构都自己重新写了一遍),但这就导致了我们无法对vLLM加载得模型进行LoRA微调。
不过好在Cassia大佬提交了一个repo,加上了vLLM对peft的支持(需要安装以下版本的vllm)
pip install git+https://github.com/troph-team/vllm.git@support_peft
我们用OPT为例看看Cassia大佬究竟做了些什么(lora)
from vllm import LLM, SamplingParams
from vllm.model_executor.adapters import lora
# Create an LLM.
llm = LLM(model="../opt-125m", gpu_memory_utilization=0.2)
prompts = [
"Hello, my name is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0, top_k=-1) # 不做任何sampling,每次只选择最大概率的token
outputs = llm.generate(prompts, sampling_params)

for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")

llm.llm_engine.workers[0].model
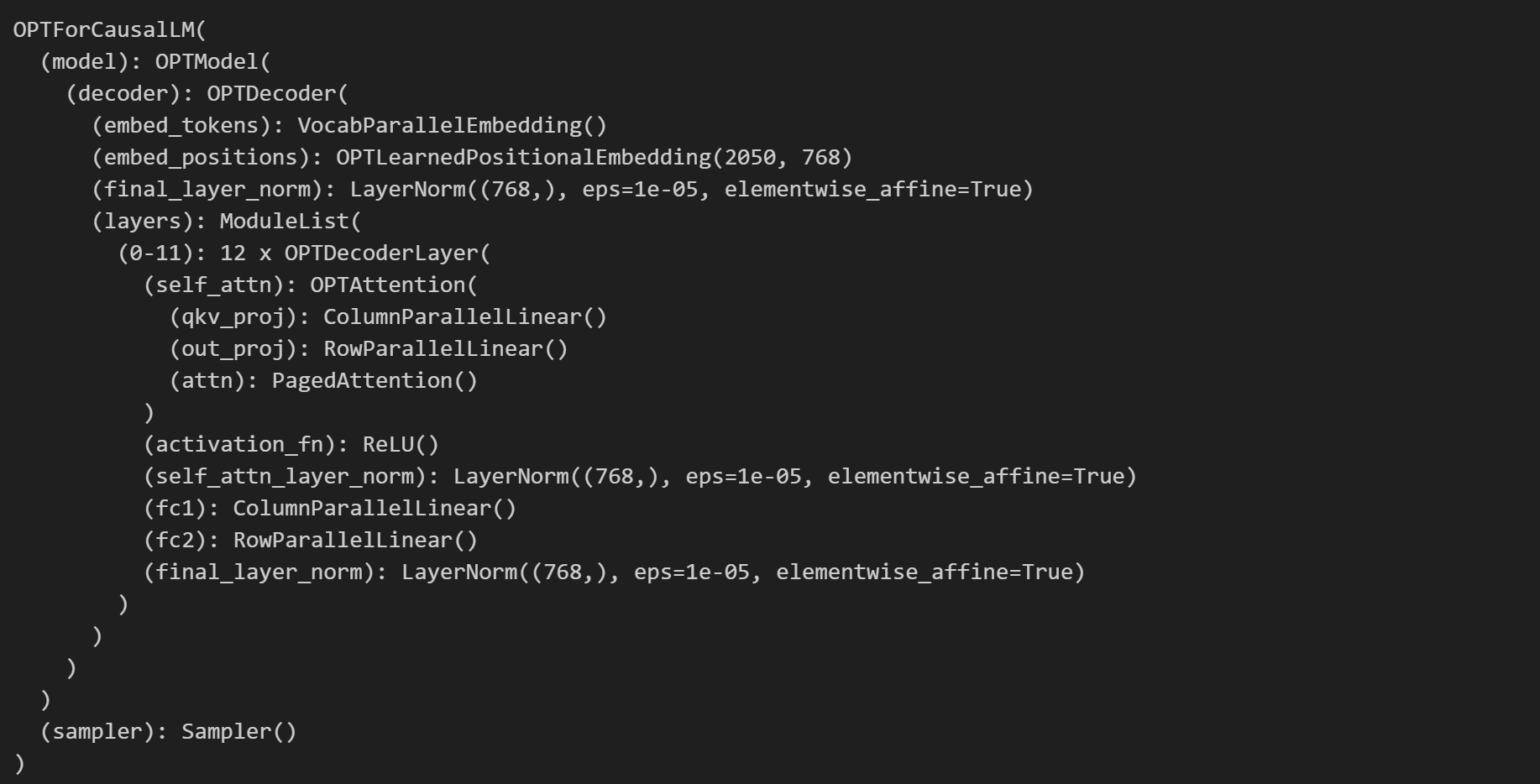
在这里使用lora库的LoRAModel加载了一个adapter(看名字应该是基于imdb数据finetune的一个opt-adapter)
# Add LoRA adapter
lora.LoRAModel.from_pretrained(llm.llm_engine.workers[0].model, "../opt-125m-imdb-lora")
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")

可以看到微调后OPT输出的内容是不一样的。
vllm@support_peft
简单过一下vllm的结构。
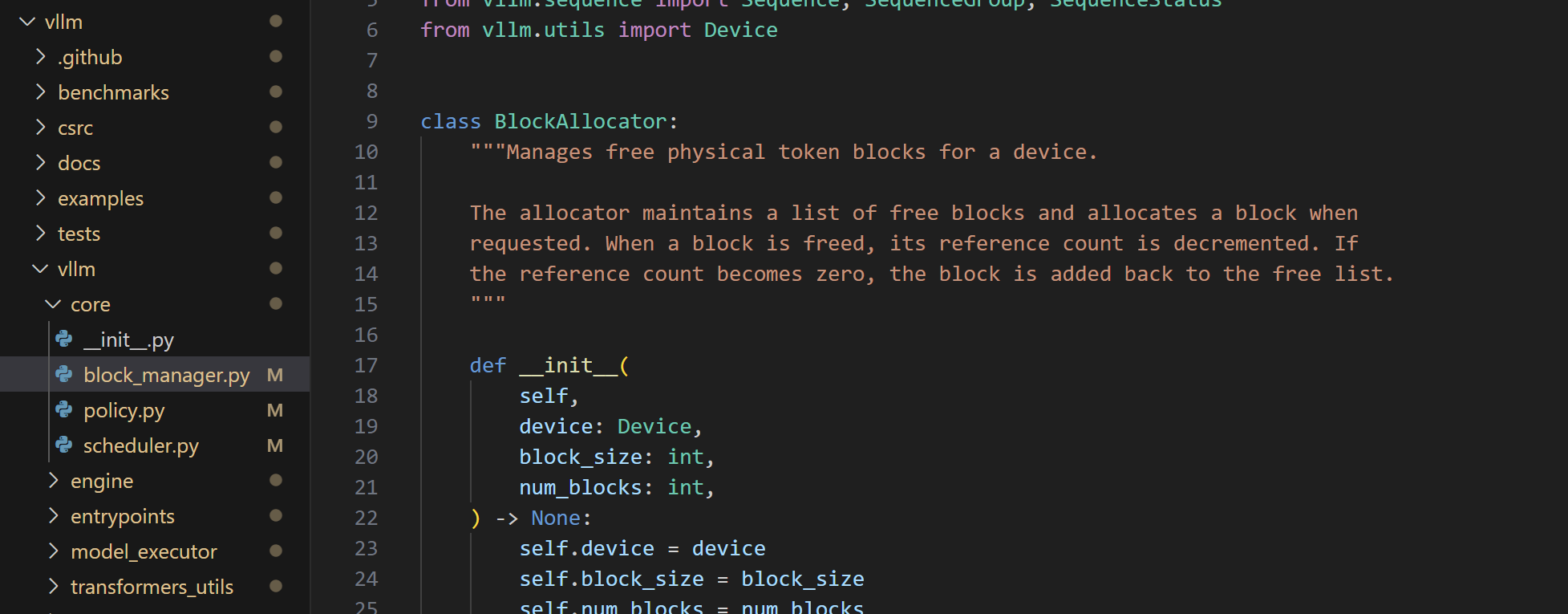
最重要的是vllm-vllm-core下的block_manager.py,负责对内存进行动态分配
我们在前两篇文章中讲过,peft是如何加上LoRA这个旁路的:
- 遍历原来model的所有层数,找到我们需要加上LoRA的某(几)个module(比如self-attetion);
- 把找到的module单独抠出来,放到一个新的module(LoRA module)里面;
- LoRA module中包含A、B两个矩阵,输入给到A、B矩阵后得到的输出 与 原来module的输出相加,得到新的输出。
如果要让vLLM支持peft技术,其实就是要让LoRA中的module对应上vLLM中的module,然后把LoRA module挂到module的旁路上面去。
还是以vllm-vllm-model_executor_models下的llama.py为例,仔细审阅一下LlamaAttention模块
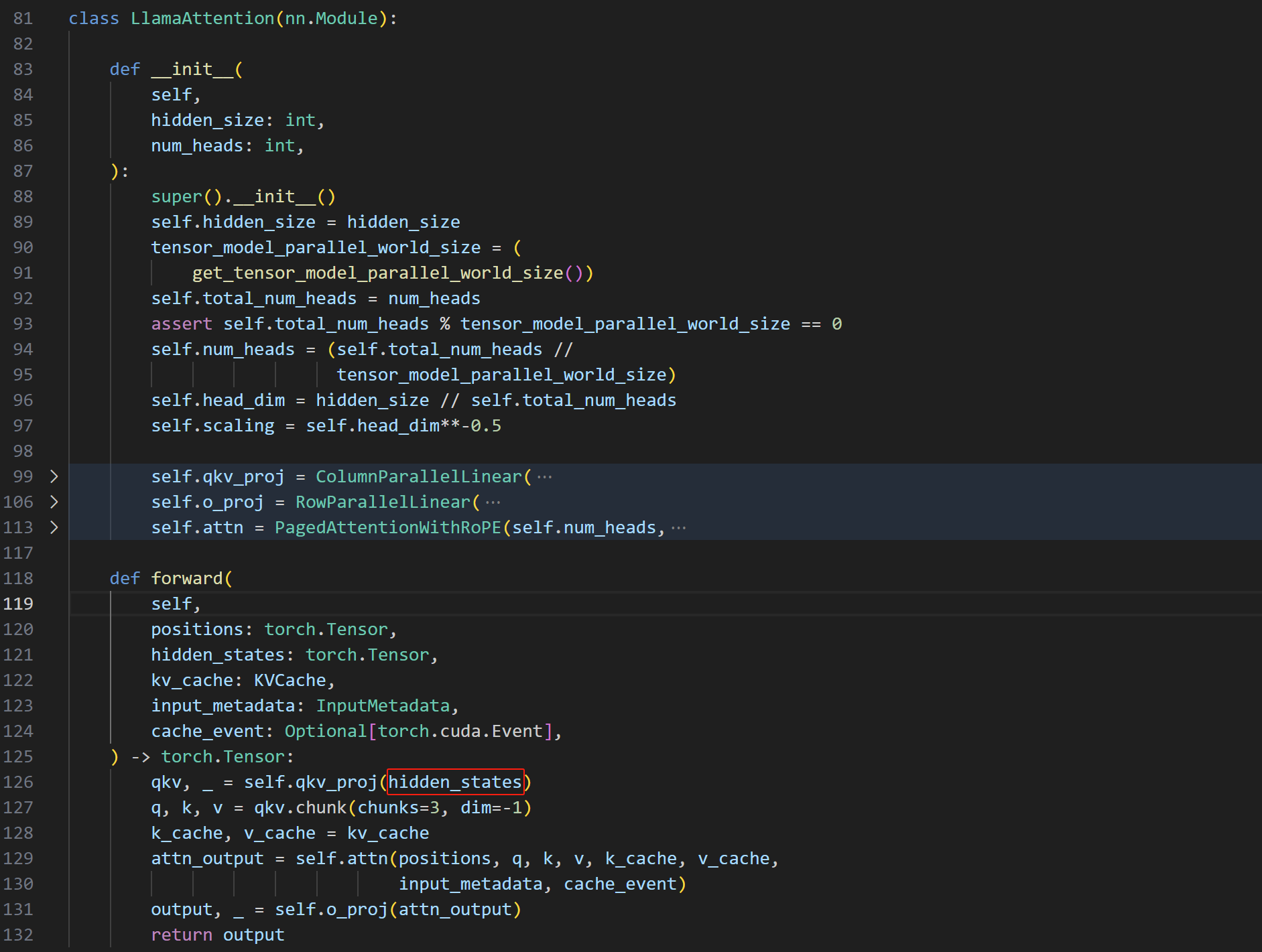
用hidden_states作为输入计算qkv。显然,我们需要让hidden_states同时作为输入给到LoRA module。这里Cassia大佬的实现是在lora.py中,他在load_adapter方法中将原本的qkv_proj模块抠出来扔到了VllmLoRA这个LoRA module中,然后将原来的module替换成新的
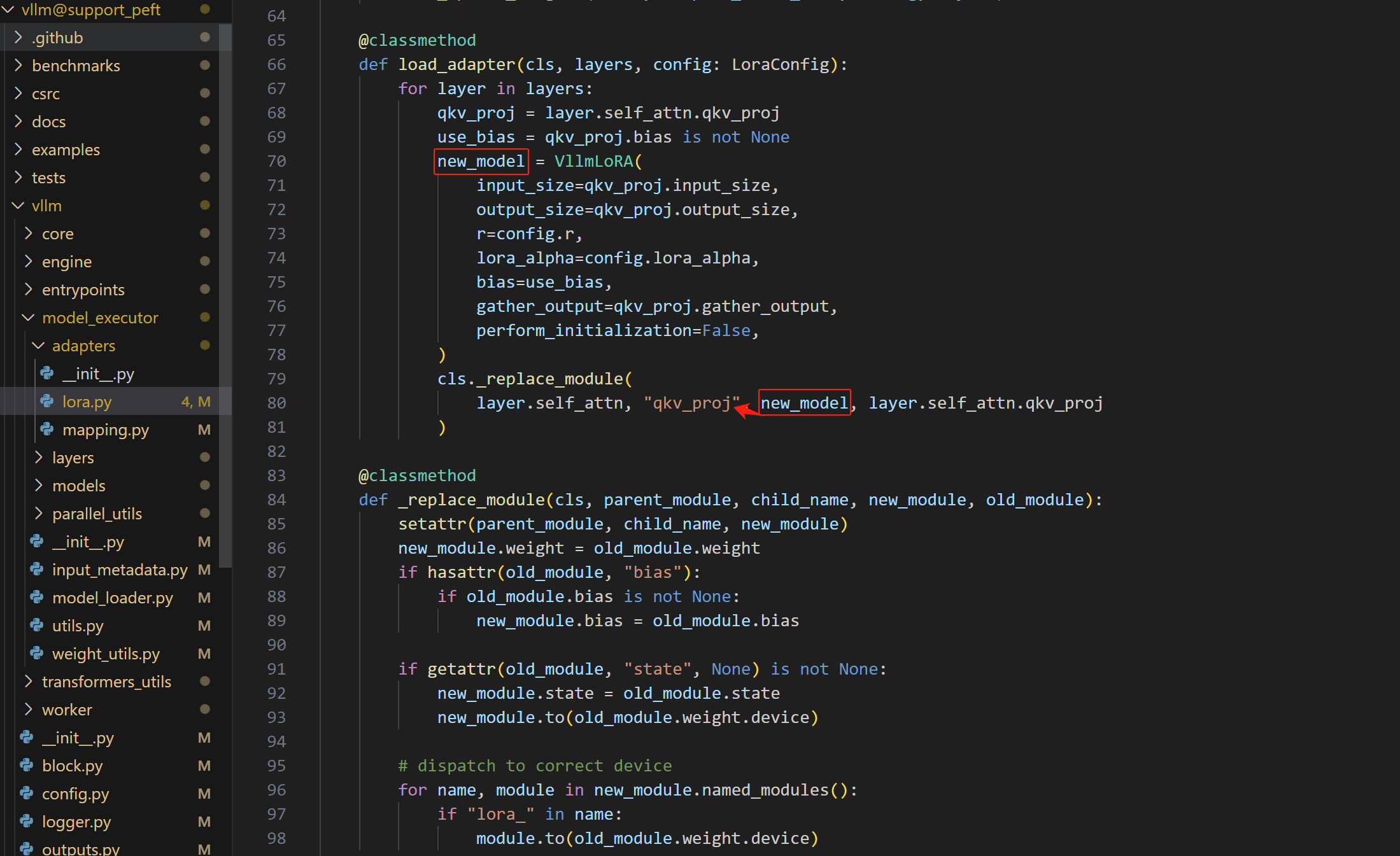
如此一来,当qkv, _ = self.qkv_proj(hidden_states)这句话调用qkv_proj这个模块时,实际上调用的是被lora.py替换后的qkv_proj。
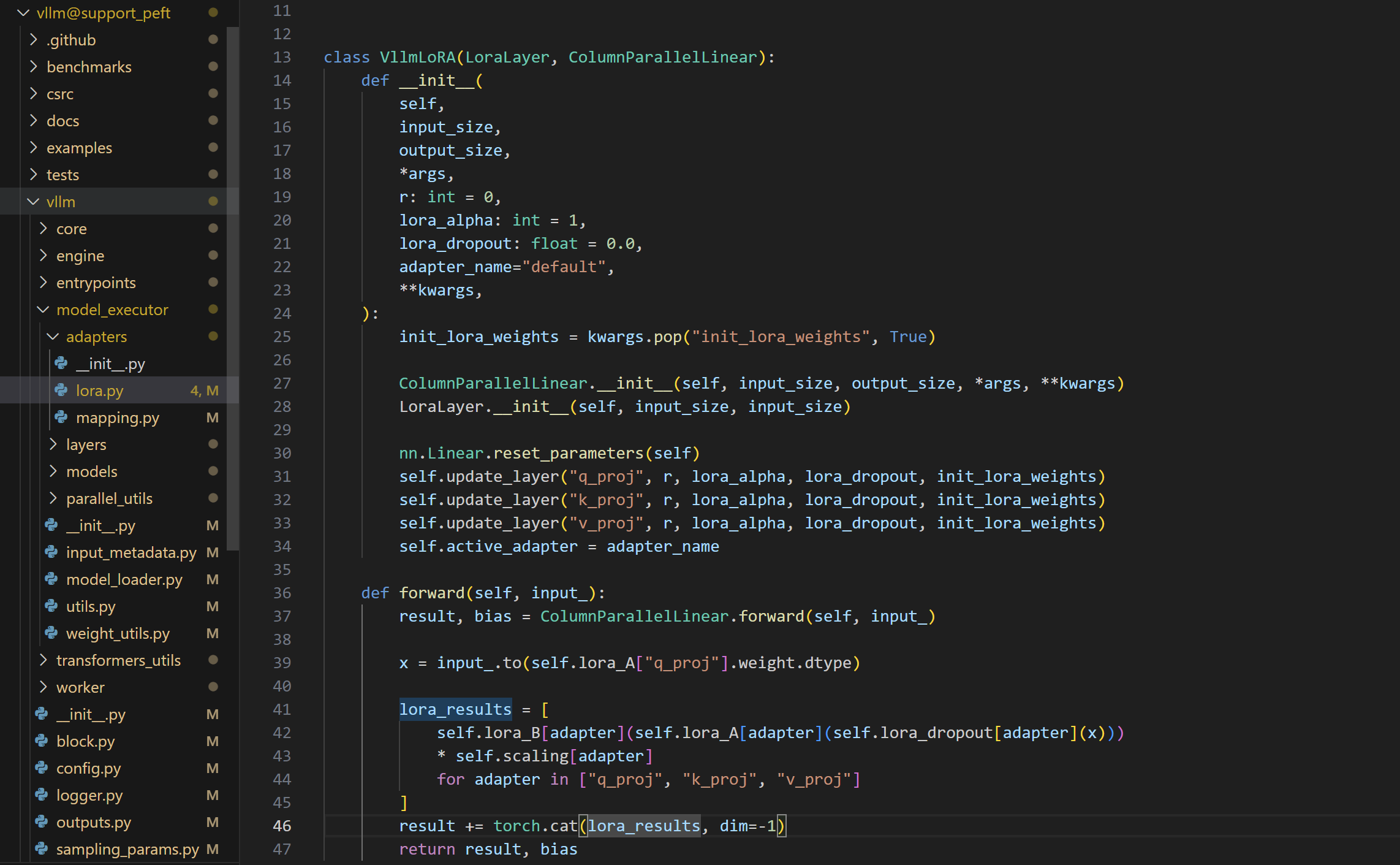
最后来看下VllmLoRA这个LoRA module是怎么写的
-
类定义:
VllmLoRA继承自LoraLayer和ColumnParallelLinear。
-
构造函数:
- 构造函数接收多个参数,包括输入大小(
input_size)、输出大小(output_size)、LoRA参数(r、lora_alpha、lora_dropout)和其他关键字参数。 init_lora_weights用于控制是否初始化 LoRA 权重。- 使用
ColumnParallelLinear和LoraLayer的构造函数初始化该层。 - 重置线性层的参数。
- 使用
update_layer方法初始化q_proj、k_proj和v_proj这三个LoRA层。 active_adapter。
- 构造函数接收多个参数,包括输入大小(
-
前向传播(
forward方法):- 这个方法首先调用
ColumnParallelLinear的前向传播方法来处理输入。 - 将输入数据转换为 LoRA 层所需的数据类型。
- 对于
q_proj、k_proj和v_proj,使用 LoRA 层进行计算,并将结果相加到原始的线性层输出上。 - 返回最终结果和偏置。
- 这个方法首先调用
以上,就是vLLM支持LoRA的方法。
Decoding methods
之前在将分页机制的时候讲到一个Prompt to Muitiple Outputs,一个prompt如何生成多种不同的output,这取决于使用的decoding method。
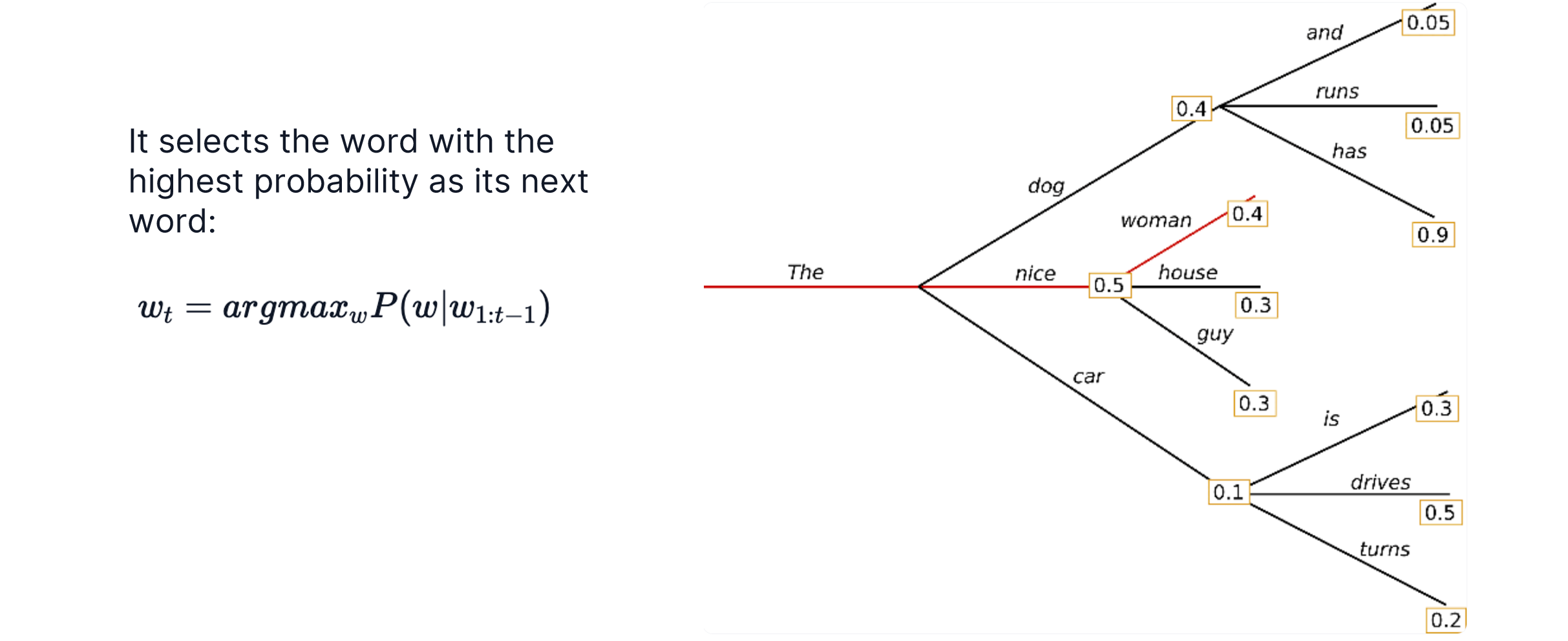
Greedy Search
Greedy search就是贪心,每次取下一步最大的那个token
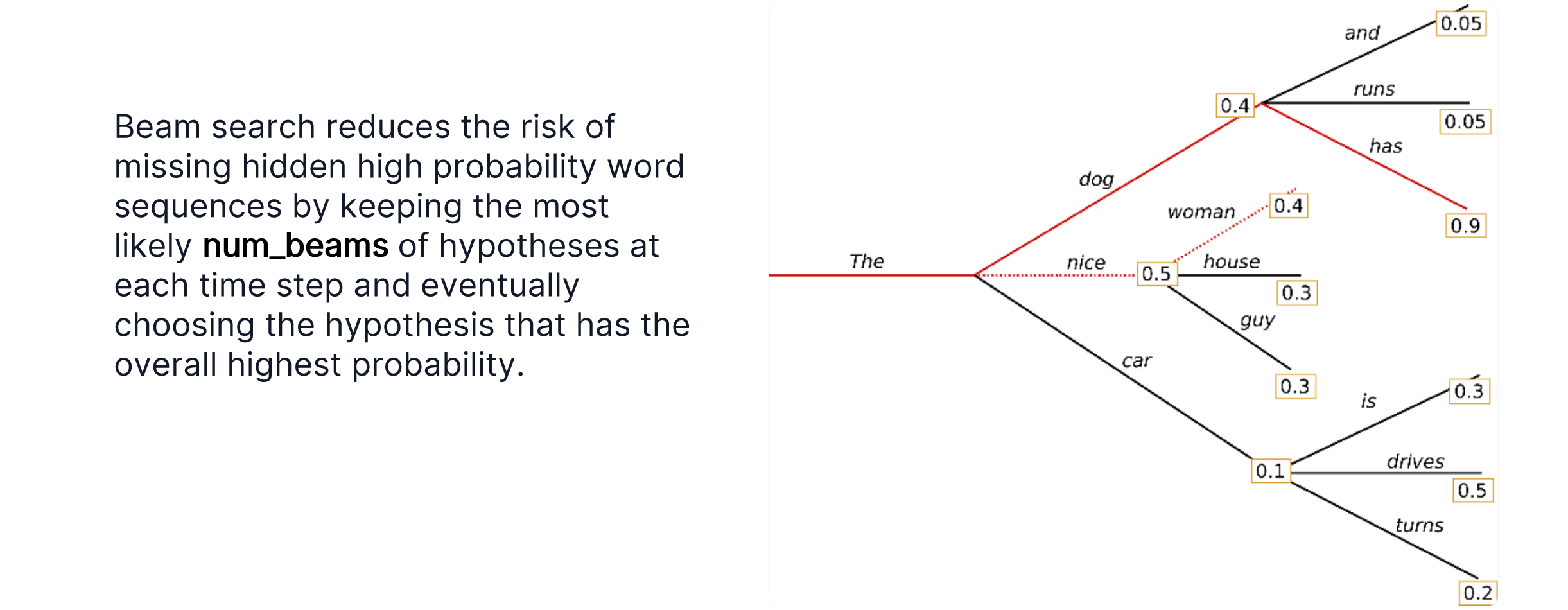
Beam Search
Beam search需要一个参数num_beams,用于决定往后看几步,每次取后几步最大的beam中第一个token
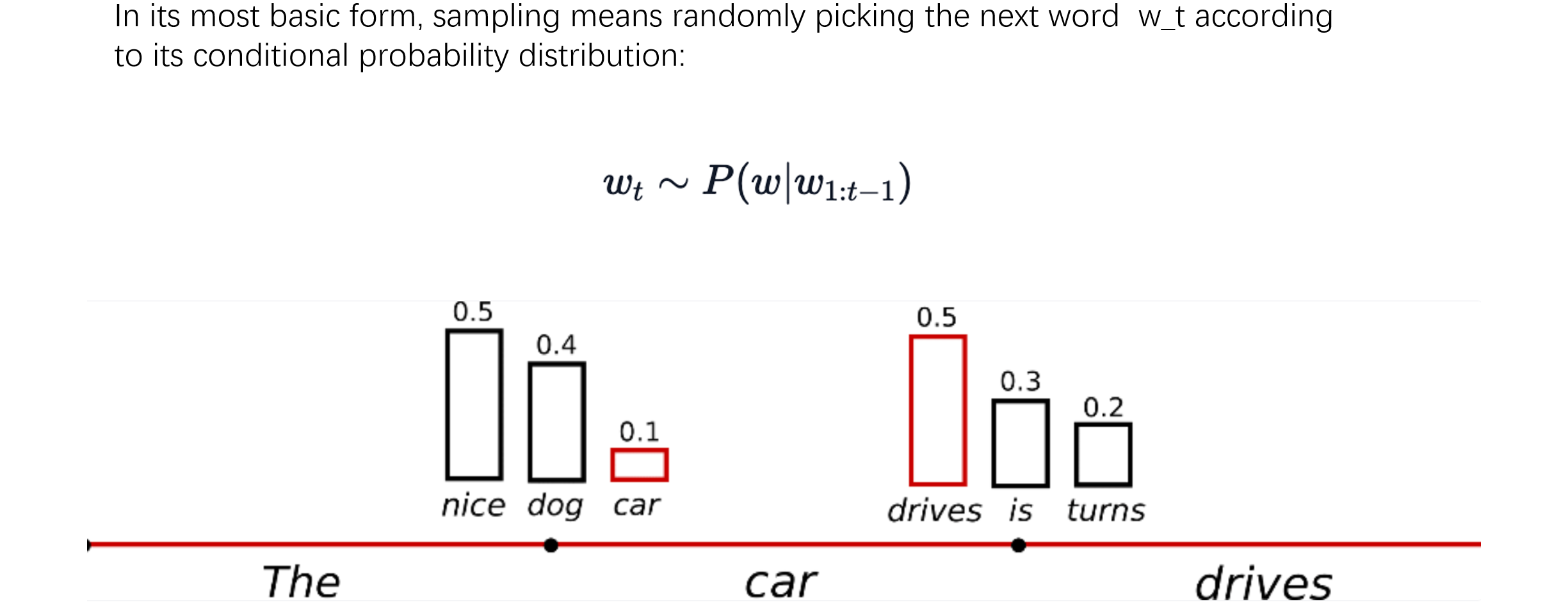
Sampling
每次对下一个token生成的概率进行采样,每个token都有可能被选择
Top-K Sampling
Sampling存在的问题是,它只考虑了上图中那种比较理想的分布情况。然而在现实中,很多token分布的值可能会很接近,所以Top-K Sampling的做法是对采样区域进行一定的限制,只在前K个token之间进行采样
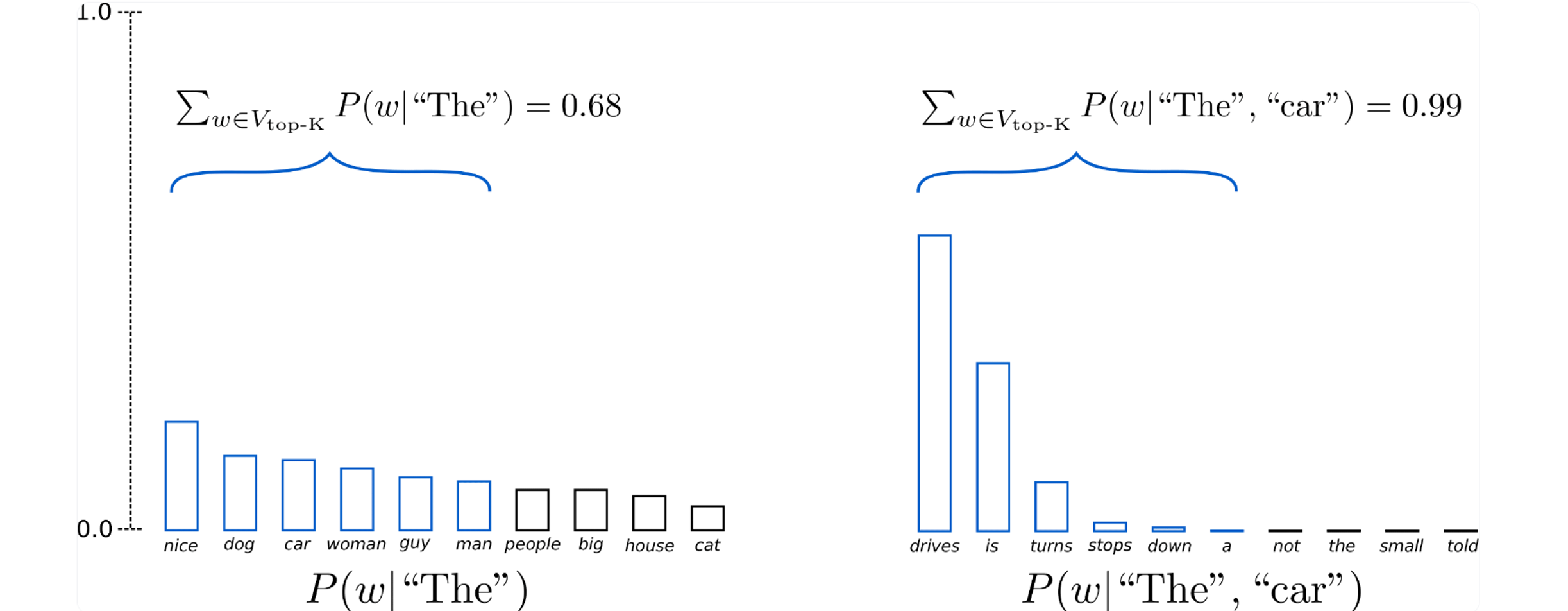
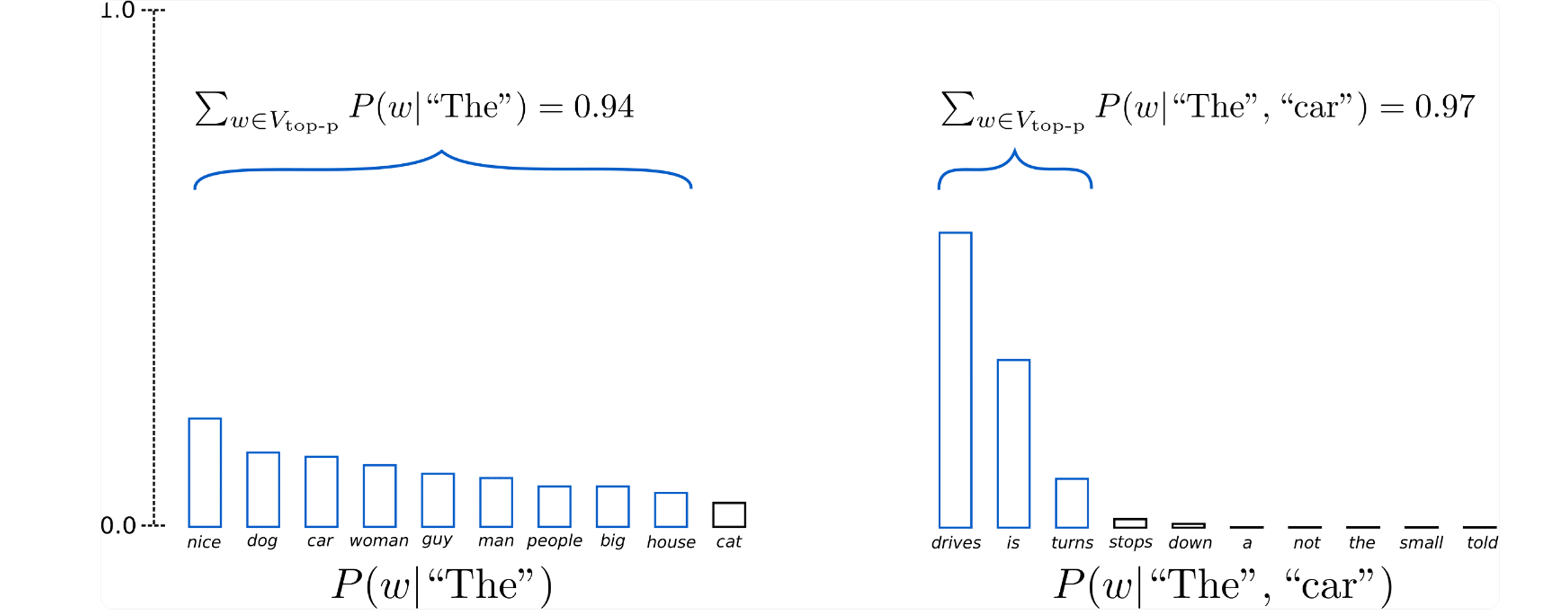
Top-p (nucleus) Sampling
还有种Sampling方法叫做Top-p (nucleus) sampling,当前p个分布之和大于定值(比如0.9)时,将前p个token作为取样范围
Quantization 量化
网上开源的很多模型本身是全精度的,我们用半精度进行加载量化效果较好,但是如果在进行进一步的量化效果可能就会很差。原因在于全精度意味着更多的参数,在复杂情况下,量化带来的误差会被越放越大,导致模型的表现大幅下降。
下图就是半精度16-bit基准线与8-bit基准线的对比,随着参数量变大8-bit基准线会骤降
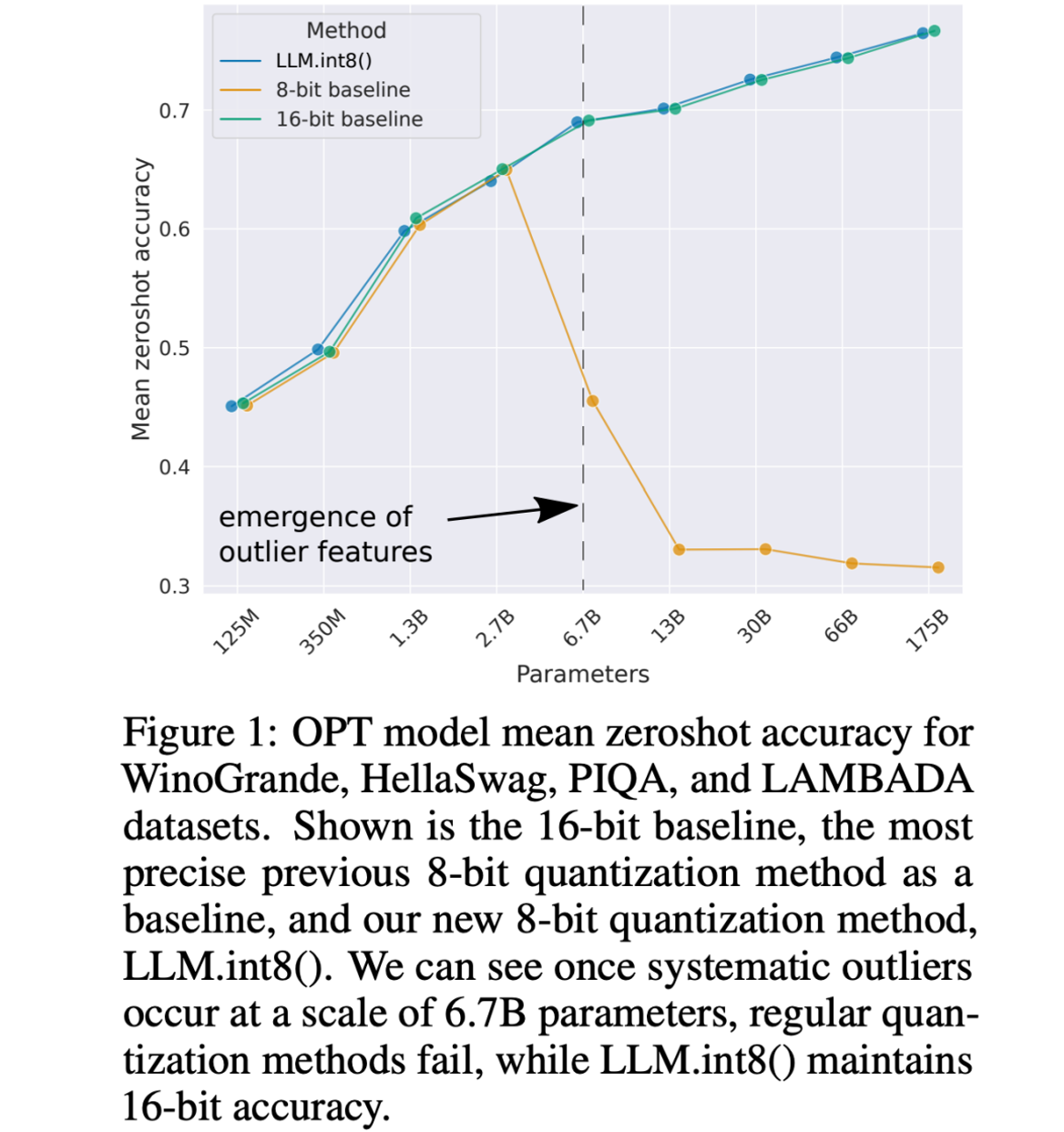
于是,量化中最常用的一种技术LLM.int8出现了,它可以用8-bit达到16-bit基准线的效果。
8-bit量化
在介绍LLM.int8技术之前,先看看8-bit量化是如何做的。
8-bit量化的意思是将原来半精度浮点数转换成int_8(int_8的范围是-177~177),举个例子:
Example 1
- 原始数据: x = [1.52, 2.64, -3.45, 4.32]
- 量化过程:
- x_absmax = 4.32 # 找最大
- scale_factor=127 / x_absmax ≈ 29.4 # 计算量化因素
- q_x = round([1.52, 2.64, -3.45, 4.32] * scale_factor) =[45, 78, -101, 127] # 将半精度浮点数映射到int_8的数组,占用空间会少一半
- 反量化过程:
- x’ = q_x/scale_factor = [1.53, 2.61, 3.44, 4.32] # 除了最大值不变,其他参数会有略微误差
Problem 1
量化过程存在量化误差
- 原始数据:x=[1.52,2.64,-3.45,4.32]
- 反量化结果:x’=[1.53,2.61,3.44,4.32]
如何降低量化误差,提高量化精度?
- 使用更多的量化参数(scale_factor)
- 矩阵乘法A*B可以看作是A的每一行乘上B的每一列,为A的每每一行和B的每一列单独设置scale_factor,这种方式被称之为Vector-wise量化
Example 2
- Data: x = [1.42,1.51,1.54,45.3]
- Quantization process:
- x_absmax = 45.3
- scale_factor=127 / x_absmax ≈ 2.8
- q_x = round([1.42, 1.51, 1.54, 4.32] * scale_factor) = [4, 4,4, 127]
- Dequantization process:
- x’ = q_x/scale_factor = [1.43, 1.43, 1.43, 45.36]
Problem 2
很明显,当最大值相对较大时,其他数值的误差就会很大:
- 离群值:超出某个分布范围的值通常称为离群值
- x = [1.42, 1.51, 1.54, 45.3]
- 8位精度的动态范围极其有限,因此量化具有多个大值的向量会产生严重误差
- 误差在一点点累积的过程中会导致模型的最终性能大幅度下降
LLM.int8()
其实很简单,LLM.int8()方法通过将16位浮点数的特征和权重矩阵分解成小的子矩阵,并将它们转换为8位整数来进行高效的矩阵乘法运算。
该方法特别处理矩阵中的离群值(通过均值和方差),这些值保持为16位浮点数以保证计算的精度。
完成乘法运算后,方法会对结果进行反量化处理,将8位整数输出转换回16位浮点数,然后将离群值结果和常规结果累加以得到最终输出。
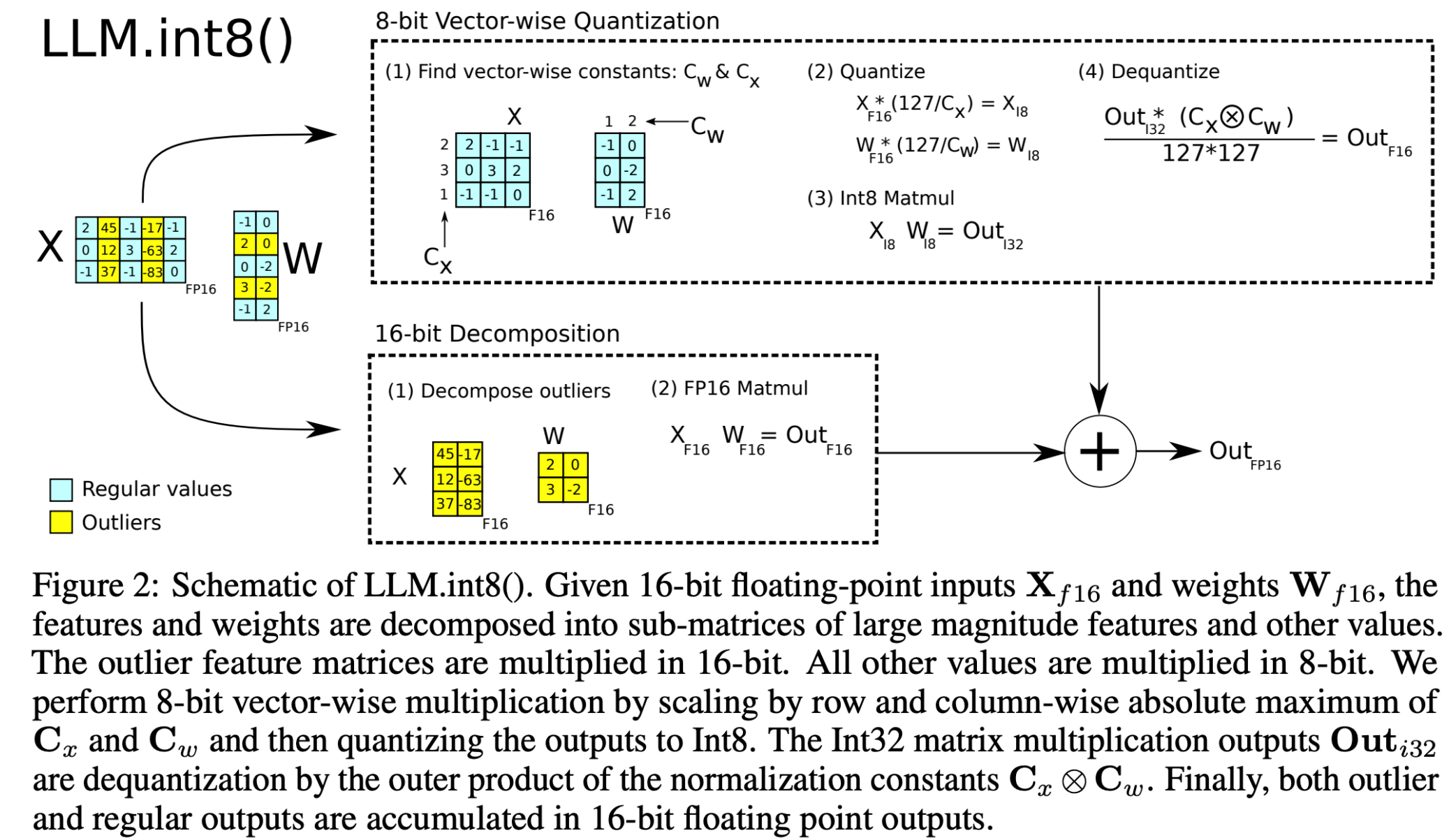
这个过程优化了计算效率,同时尽量减少了精度损失。
还是做个实验
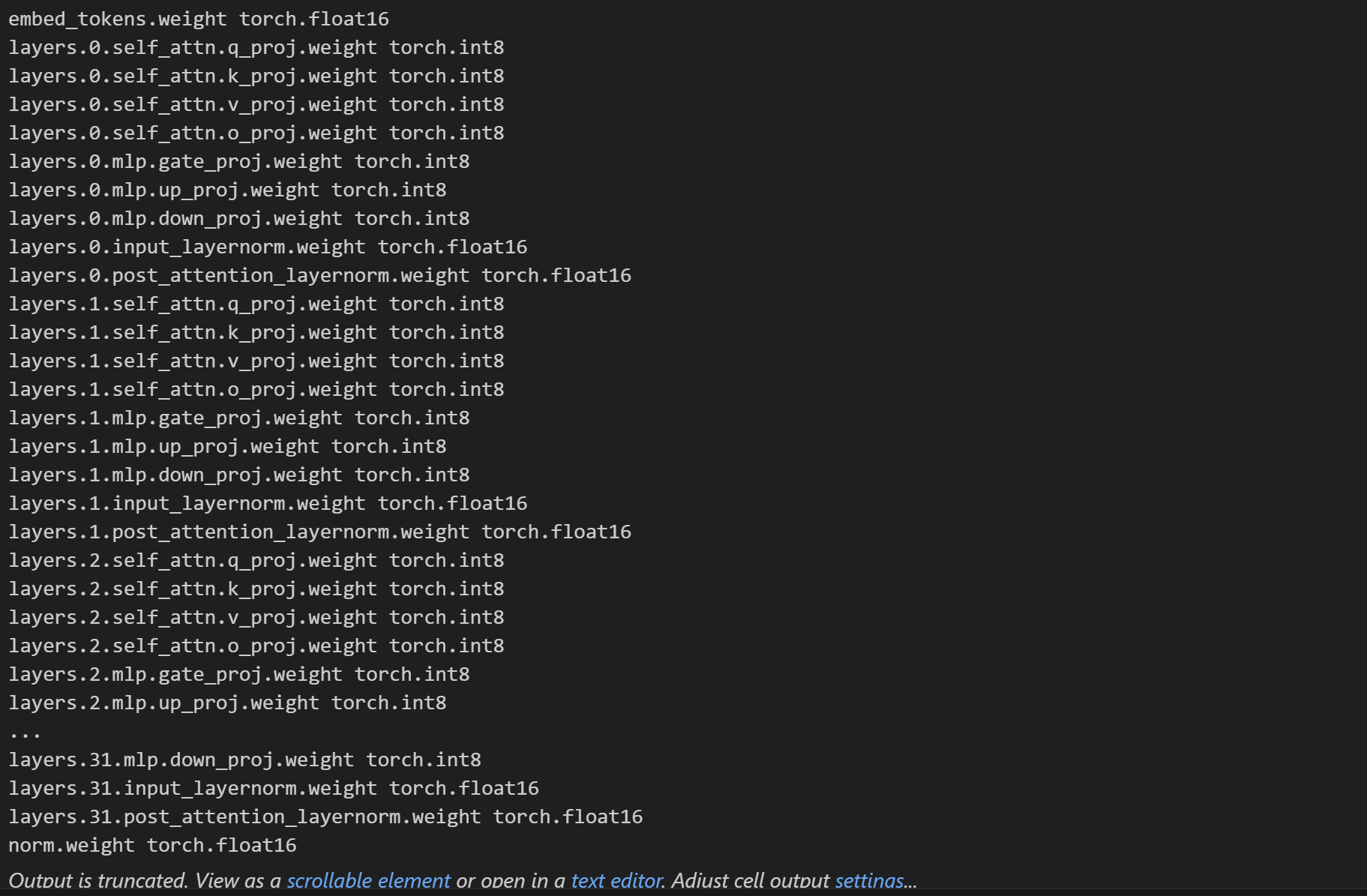
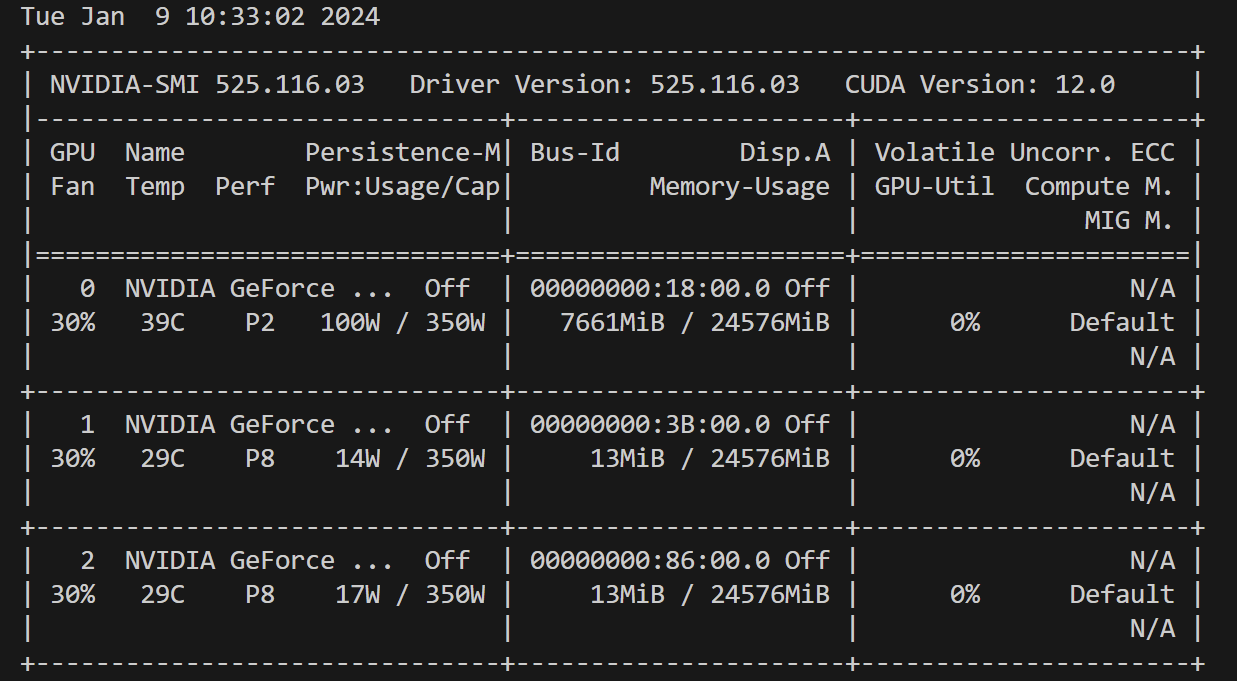
from transformers import AutoModel model = AutoModel.from_pretrained("../Llama-2-7B-Chat-fp16", load_in_8bit=True)用int_8来加载,只用了7661M
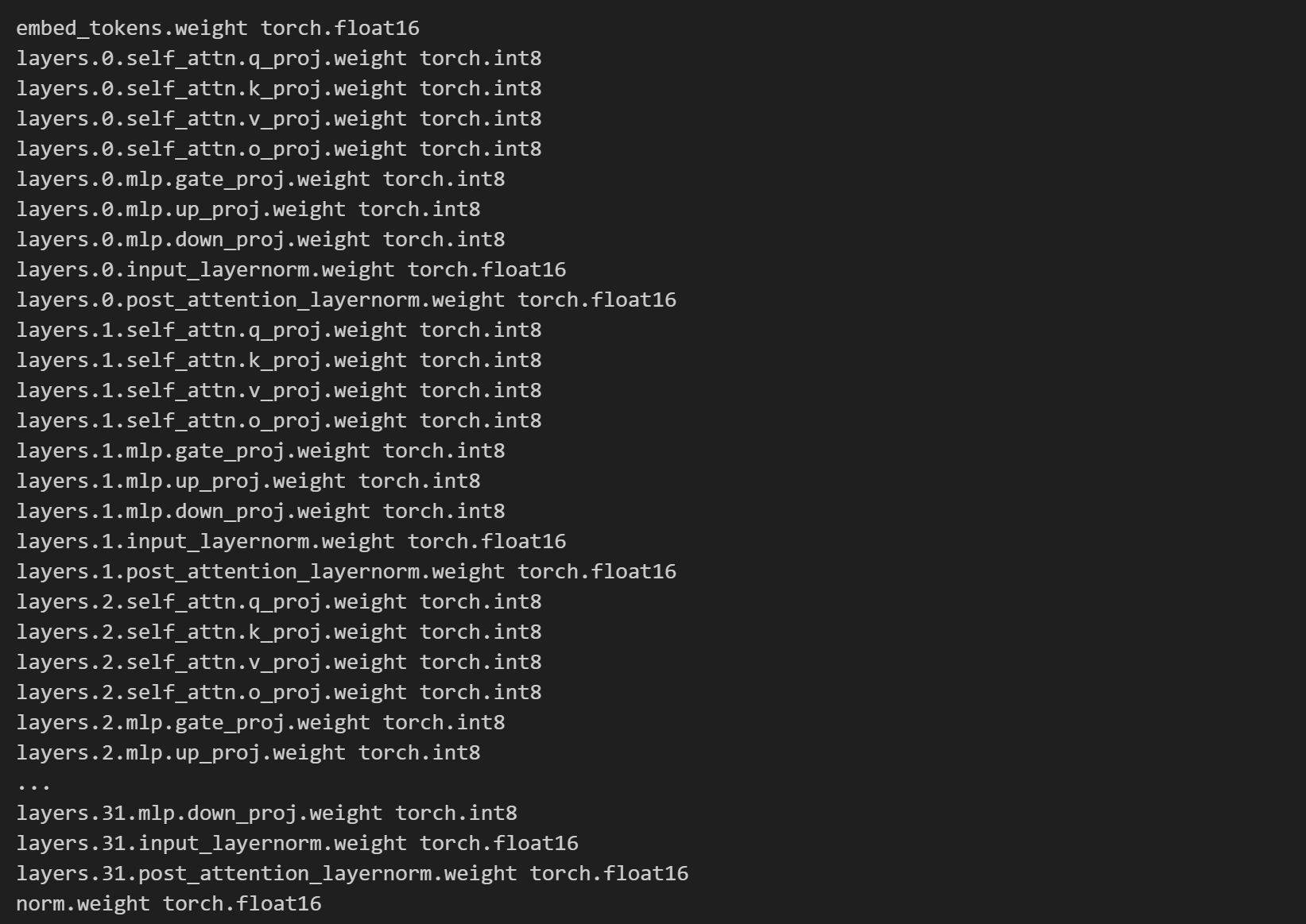
for name, params in model.named_parameters(): print(name, params.dtype)
LLM.int8()会自动处理哪些需要转成int_8,哪些需要保留float_16。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- springboot使用ES查询
- 《剑指 Offer》专项突破版 - 面试题 17 : 包含所有字符的最短子字符串(C++ 实现)
- 数据库基础学习04计算机二级-第四章 数据查询
- 基于NXP I.MX8 + Codesys的工业软PLC解决方案
- 解锁 ESLint 的秘密:代码质量的守护者(下)
- PostgreSQL 100条命令
- 读算法霸权笔记02_盲点炸弹
- FreeRTOS 实时操作系统第四讲 - 任务管理 (创建,删除,挂起,恢复)
- C结构体声明,定义,初始化(赋值),访问
- 从0到1入门C++编程——02 通讯录管理系统