StarRocks集群元数据恢复
该篇文章记录测试环境中StarRocks元数据恢复的操作流程。
一、恢复元数据步骤
? ? ? ? ? 元数据恢复缘由:2023年7月底基于StarRocks3.0.0集群测试物化视图及动态建表等功能,一切正常。几天后重新连接集群发现已宕机,FE拒接连接,FE 节点之间无法同步数据。
报错日志如下:
 查看fe.conf ,be.conf等配置文件,发现参数已重置为初始值(原因未知),部分截图如下:
查看fe.conf ,be.conf等配置文件,发现参数已重置为初始值(原因未知),部分截图如下:

排查后,源三台服务器的元数据meta以及storage可回溯,路径分别是:/data/starrocks/fe/meta 以及 /data/starrocks/be/storage,针对上述异常,接下来开始手动恢复 FE 服务。
第一步:找出元数据最新的FE节点
? ? ?每台节点依次执行命令:java -jar ?/opt/StarRocks-3.0.0/fe/lib/starrocks-bdb-je-18.3.13.jar ?DbPrintLog -h ?/data/starrocks/fe/meta/bdb/ -vd? 获取 lastVLSN,该值越大则该节点元数据越新。返回结果如下:

注:
- 不同StarRocks版本用到的starrocks-bdb-je的jar包可能不一样,视情况调整;
- ?/data/starrocks/fe/meta/bdb/ 是源集群的dbd绝对路径
例如:节点A以为例,得到 lastVLSN的最大值是30,760,876,如截图

同理得到节点B、节点C的lastVLSN的最大值是30,763,820,30,763,931。比较A,B,C的 lastVLSN 值大小,得出C是元数据最新的节点、同时也是恢复节点。
第二步:确认恢复节点角色
进入节点C的image目录(/data/starrocks/fe/meta/image)查看role文件,获取C的role为FOLLOWER

然后,在C节点的fe.conf 中添加:metadata_failure_recovery = true,该参数官网解释如下:

? 启动完成后,通过MySQL连接节点C的FE,返回结果如下:

确认启动成功后,可以看到当前C的FE角色为?Master,同时可以看到源集群中的其他FE节点(节点A、节点B)。
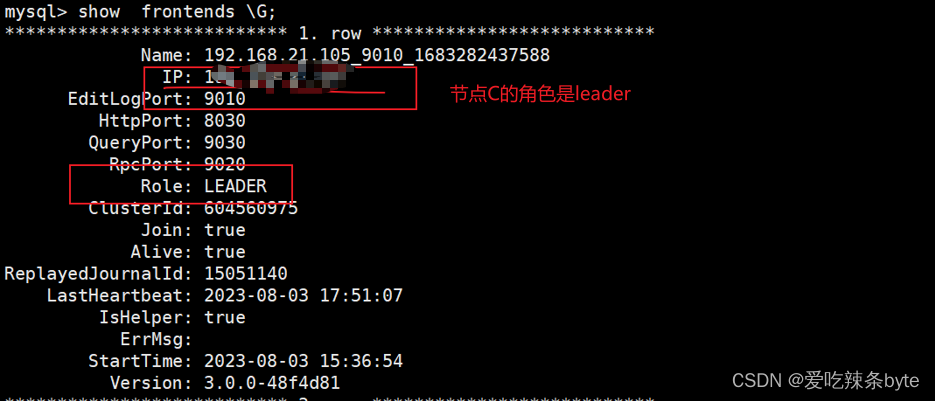

关键步骤:之后将节点C的?fe.conf?中的?metadata_failure_recovery=true?配置项删除,或者设置为?false,如截图。然后重启C的?FE 节点(sh bin/start_fe.sh --daemon)

第三步:重新部署 FE 集群
? ? ? 通过以上步骤,节点C担任可用的FE,同时也是新集群的FE master 、将节点A及节点B的FE 实例从源集群的元数据中移除,即执行以下命令:
? ? ? mysql>? alter system drop follower "B的IP:9010";
? ? ? mysql>? alter system drop follower "A的IP:9010";
? 接着,切换至A、B节点的?/data/starrocks/fe/meta 目录下,清空源集群遗留的bdb及image信息
? 最后将A、B节点作为全新FE实例 ,重新添加到C集群中,命令如下:
? ? ?mysql> ?alter system add follower "B的IP:9010";
? ? ?mysql> ?alter system add follower "A的IP:9010";
?并分别在A、B节点上启动FE,命令如下:
? ? ?./start_fe.sh --helper C的IP:9010 --daemon
?参考文档:
总结:
? ?上述手动恢复 FE 服务的流程,简而言之是:先通过当前?meta_dir?中留存的元数据启动一个新的 Leader 节点,然后逐台添加其他 FE 实例至新的集群。
? 此过程中,需清空除了恢复节点(本案例中的恢复节点是C)以外其他节点的元数据目录,否则可能导致元数据错乱。
二、元数据恢复后,集群情况如下:
| StarRocks3.0.0 | |||
| 机器节点 | A | B | C |
| 部署服务 | BE | BE | BE |
| FE(follower) | FE(follower) | FE(leader) | |
| mysql-client | |||
| 客户端连接地址 | B的ip:9030? ? ?root/root | ||
| FE | 部署目录:/opt/StarRocks-3.0.0/fe | ||
| 日志目录: /data/starrocks/fe/log | |||
| 元数据目录:?/data/starrocks/fe/meta | |||
| BE | 部署目录:/opt/StarRocks-3.0.0/be | ||
| 日志目录: /data/starrocks/be/log | |||
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 我的JavaScript学习之旅:从新手到熟练的转变
- 设置gazebo内sdf,urdf文件路径的可能变量
- 奖励补助!2024年四川省家庭农场省级示范场申报条件要求、主体程序
- Hotspot源码解析-第十八章-元空间的创建与分配
- 如何使用宝塔面板部署Inis博客并实现无公网ip环境远程访问
- 前端性能优化五十一:如何开发一个企业级前端脚手架
- 什么是NPM,NPM使用方法
- LINUX面试题3
- TCP的拥塞控制_基础知识_四种拥塞控制方法
- 【OpenAI】自定义GPTs应用(GPT助手应用)及外部API接口请求