记录Flink 线上碰到java.lang.OutOfMemoryError: GC overhead limit exceeded如何处理?
这个问题是Flink TM内存中我们常见的,看到这个问题我们就要想到下面这句话:
程序在垃圾回收上花了很多时间,却收集一点点内存,伴随着会出现CPU的升高。
是不是大家出现这个问题都会出现上面这种情况呢。那我的问题出现如下:
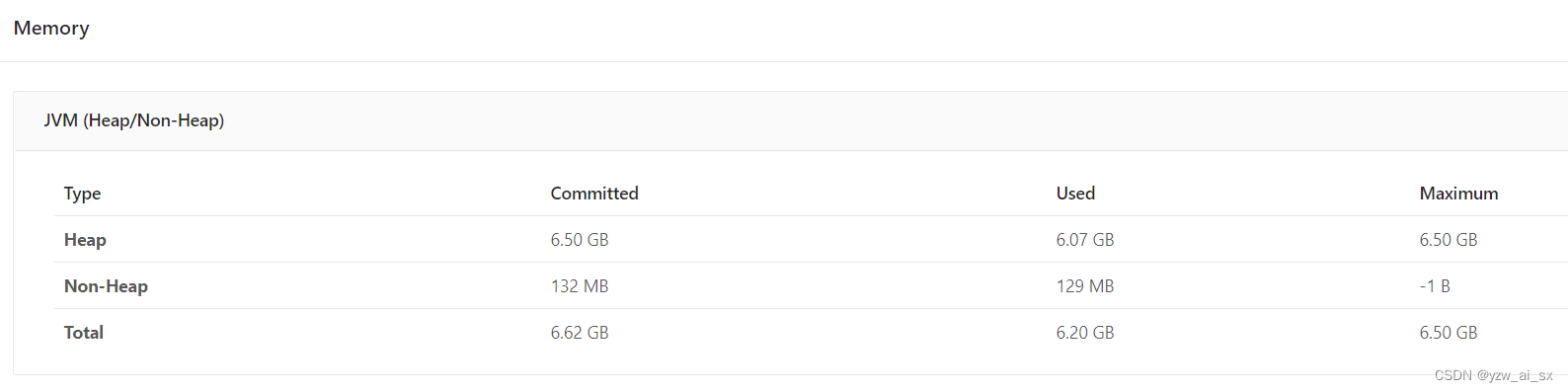
发现JVM Heap堆内存过高。那么堆内存包含2块:
framwork heap 一般设置是128MB,基本上不会出问题
task heap 是我们用户写代码所使用的的堆内存,那我们就要考虑是不是自己业务代码有问题吗?
所以我使用以下判断方法发现问题的。
1 查看某个TM的堆内存占用是否过高,如果过高,通过页面的端口号找到该TM的PID。操作如下:
例:akka.tcp://flink@IP:23567/user/taskmanager_0
找到这个IP的端口,使用 netstat 找到PID ?---> ?netstat -atunpl | grep 23567
tcp6 ? ? ? 0 ? ? ?0 :::23567 ? ? ? ? ? ? ? ?:::* ? ? ? ? ? ? ? ? ? ?LISTEN ? ? ?3081/java ?
? ?
得到该TM的进程为3081
2 利用命令:jmap -histo:live pid 对该PID进行操作
命令:jmap -histo:live 3081 ?| head -20 ?得到
?num ? ? #instances ? ? ? ? #bytes ?class name
----------------------------------------------
? ?1: ? ? ?24781126 ? ? ?792996032 ?java.util.HashMap$Node
? ?2: ? ? ?21094139 ? ? ?737237032 ?[C
? ?3: ? ? ?21094065 ? ? ?506257560 ?java.lang.String
? ?4: ? ? ? 1560788 ? ? ?225984352 ?[Ljava.util.HashMap$Node;
? ?5: ? ? ? 1557686 ? ? ? 74768928 ?java.util.HashMap
? ?6: ? ? ? ?195141 ? ? ? 59546144 ?[B
? ?7: ? ? ? 1198174 ? ? ? 38341568 ?java.util.concurrent.ConcurrentHashMap$Node
? ?8: ? ? ? 1548207 ? ? ? 24771312 ?com.alibaba.fastjson.JSONObject
? ?9: ? ? ? ? 39805 ? ? ? ?9853696 ?[Ljava.lang.Object;
? 10: ? ? ? ? ?1225 ? ? ? ?9522400 ?[Ljava.util.concurrent.ConcurrentHashMap$Node;
? 11: ? ? ? ?157686 ? ? ? ?5045952 ?org.apache.hadoop.hbase.Key
发现使用HashMap占用太多,寻找自己使用HashMap的方法进行排查,发现没有释放HashMap内数据导致内存一直增加。
最后希望我这种判断方式对大家都有帮助!
欢迎大家关注公众号

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Linux】Linux系统的生态
- NXP应用随记(六):S32K3xx的时钟与PIN简介
- 【交通规划原理】第三章 —— 交通与土地利用
- 什么是多域名证书?看这一篇就够了
- 网络音频对讲广播模块-定时广播 ip网络广播音频模块SV-2401
- SpringBoot - SpringBoot手写模拟SpringBoot启动过程
- HTML5+CSS3小实例:旋转彩色loading加载动画
- 【LeetCode-134】加油站(贪心)
- 基于java技术的汽车4S店管理系统的设计与实现(源码+开题)
- 第 8 章 查找算法