C语言——小细节和小知识9
一、大小端字节序
1、介绍
在计算机系统中,大小端(Endianness)是指多字节数据的存储和读取顺序。它是数据在内存中如何排列的问题,特别是与字节顺序相关。C语言中的数据存储大小端字节序指的是在内存中存储的多字节数据类型(如整型、浮点型)的字节序排列方式,主要有两种:
-
大端字节序(Big-Endian):在大端字节序中,一个多字节数据的最高有效字节(即“大端”)存储在内存的最低地址处,其余字节按照在数值中的顺序依中次存储在连续的内存地址。例如,一个四字节的整数
0x12345678在内存中的存储顺序(从低地址到高地址)为12 34 56 78。 -
小端字节序(Little-Endian):在小端字节序中,一个多字节数据的最低有效字节(即“小端”)存储在内存的最低地址处,其余字节按照在数值中的逆序存储在连续的内存地址中。采用同样的四字节整数
0x12345678为例,在内存中的存储顺序(从低地址到高地址)将会是78 56 34 12。
大小端字节序通常由硬件决定,即由CPU的设计来规定。例如,Intel的x86架构是小端字节序,而网络协议通常采用大端字节序。在C语言编程中,通常不需要关心数据的字节序,除非你在进行底层的内存操作或者网络通信、跨平台数据传输等需要考虑字节序兼容性的场合。在这些情况下,你可能需要使用函数如 htonl() 和 ntohl() 来在主机字节序和网络字节序之间转换整数类型的数据。
目前,大部分的个人电脑和服务器处理器采用小端(Little-Endian)字节序。这主要是因为Intel的x86架构处理器和后续的x86-64架构(也称为AMD64)都采用小端字节序,而这些处理器在个人电脑和服务器市场中占据主导地位。
除了Intel和AMD之外,许多基于ARM架构的处理器也通常配置为小端模式,尤其是在智能手机和平板电脑等移动设备中。ARM架构是可切换的,即可以在大端和小端之间切换,但在实际应用中,小端模式更为普遍。
大端(Big-Endian)字节序相对来说较少见,但在某些应用和处理器设计中仍然使用,例如在一些嵌入式系统、网络设备和早期的IBM、Sun等公司的系统中。网络协议,如IP协议,使用的是大端字节序,这通常称为网络字节序。
随着市场的发展和技术的演进,小端字节序成为了主流,但在进行跨平台或网络编程时,处理字节序依然非常重要。在这些领域,开发者必须确保数据在不同字节序的系统间正确传输和解释。
2、例子
以下程序的运行结果:
#include <stdio.h>
int main()
{
int arr[] = { 1,2,3,4,5 };
short* p = (short*)arr;
int i = 0;
for (i = 0; i < 5; i++)
{
*(p + i) = 0;
}
for (i = 0; i < 5; i++)
{
printf("%d ", arr[i]);
}
return 0;
}在运行后,我们发现运行结果是:
![]()
这就可以证明这里是小端字节序。
3、分析
数组中元素内容用十六进制表示是:

为什么可以表示成这样呢?实际上可以这样解释:
这是因为一个十六进制数的单个位可以表示4位二进制数的值。换句话说,十六进制数的每一位相当于二进制数的一个四位组(nibble),即:
0?二进制表示为?00001?二进制表示为?00012?二进制表示为?0010- ...
E?二进制表示为?1110F?二进制表示为?1111
十六进制的一位可以表示0 ~ 15这16个数字,而16是2 ^ 4,在二进制下,四位二进制数恰好可以表示0000 ~1111这16个数字,(这里我们可以这样理解,四位二进制数字,每一位有两种状数字,即0或1,而这里有四位,所以总共可表示的数字是2 * 2 * 2 * 2中,即2?^ 4个数字,也就是16个数字),所以可以可以用一位十六进制数字表示四位二进制数字。
所以,一个两位的十六进制数,可以表示两个四位组,即8位二进制,这正好是一个字节(1 Byte)的大小。例如:
- 十六进制的?
00?表示二进制的?0000 0000 - 十六进制的?
01?表示二进制的?0000 0001 - 十六进制的?
FF?表示二进制的?1111 1111
最开始数组的存储是这样的:

由于int的大小为4字节,而short类型是2字节,在经过强制转换后,再通过一个循环对数组的内容进行更改:

从这里我们可以发现这里使用的是小端字节序,因为这里打印时第三个数据是0,如果是大端字节序,则第三个元素应当还是3。
二、整型的首地址
1、介绍
如果整型数据是以小端字节序(Little-Endian)存储的,那么该数据的首地址会指向这个整型数据的最低有效字节。换句话说,整型数据的首个字节(存储在首地址处的字节)包含了这个数值的最低位部分。
这意味着,如果我们有一个32位的整型数值 0x12345678,并且我们的系统是小端字节序,那么在内存中的布局将从首地址开始按照下列方式存储:
Memory Address Value
0x0000 0x78 // 最低有效字节 (LSB)
0x0001 0x56
0x0002 0x34
0x0003 0x12 // 最高有效字节 (MSB)在这种情况下,首地址 0x0000 指向的是值 0x78,这是这个整型数值的最低有效字节。
如果整型数据是以大端字节序(Big-Endian)存储的,那么该数据的首地址会指向这个整型数据的最高有效字节。换句话说,在大端字节序中,整型数据的首个字节(存储在首地址处的字节)包含了这个数值的最高位部分。
例如,考虑相同的32位整型数值 0x12345678。如果我们的系统采用大端字节序,那么在内存中的布局将从首地址开始按照如下方式存储:
Memory Address Value
0x0000 0x12 // 最高有效字节 (MSB)
0x0001 0x34
0x0002 0x56
0x0003 0x78 // 最低有效字节 (LSB)在这个例子中,首地址 0x0000 指向的是值 0x12,这是这个整型数值的最高有效字节。这和小端字节序相对,小端字节序的首地址指向最低有效字节。
所以对于两种字节序,实际上整型的首地址都是较低的地址。
2、例子
#include <stdio.h>
int main()
{
int a = 0x11223344;
char* pa = (char*)&a;
*pa = 0;
printf("%x\n", a);
return 0;
}这个程序的运行结果是:

3、分析
因为整型数据首地址是较低的地址,又因为这里是小端字节序,所以a在内存中的存储是:

由于char类型的数据是1字节,所以在用char *类型指针访问a的时候只能访问到a的首地址中的数据,所以只能更改a首地址指向的内存中的数据,这样就只有一个字节的数据被改动。
所以得到了那样的结果。
三、gets_s函数
1、介绍
我们在需要获取标准输入流中的内容时,一般是用scanf()函数,我们知道在要读取一个字符串时,可以用:
char arr[10001];
scanf("%s", arr);但是我们也知道scanf在读取到空格和换行时会停止读取或进行下一个数据的读取不会将空格和数据读到一个缓冲区中。这就导致如果我们要读取一个完整的英文句子例如:
i love you.
就不能用scanf函数。
然而实际上我们可以用别的函数解决这个问题,那就是gets,这里会有人问了,你的标题不是gets_s么,怎么又变成了gets了?
实际上gets是gets_s的老版本,gets 函数因为安全性问题已经在C11标准中被废弃,并在C17标准中被彻底移除。gets 函数不检查目标缓冲区的长度,因此非常容易造成缓冲区溢出,这是一个严重的安全漏洞。
gets_s 是 gets 的一个安全版本,定义在 <stdio.h> 头文件中,并且它要求调用者提供缓冲区的大小,以避免超出缓冲区边界的写入,因为超出缓冲区可能导致缓冲区溢出攻击或程序崩溃。
函数原型如下:
char *gets_s(char *str, rsize_t n);这里:
str?是指向用来存储输入字符串的字符数组的指针。n?是?str?中可以存储字符的最大数量,包括结尾的空字符('\0')。
如果读取成功,gets_s 会从标准输入读取一行直到遇到换行符或EOF(文件结束符)。换行符不会被复制到数组中,数组会以空字符结尾。
注意,gets_s 函数是可选的,因此不是所有支持C11标准的编译器都实现了这个函数。在实际使用中应该检查你的开发环境是否支持它。
gets_s 的返回值为:
- 如果成功,返回一个指向?
str?的指针。 - 如果遇到错误或文件结束而没有读取任何字符,返回?
NULL。
使用 gets_s 时需要特别小心,即使它比 gets 更安全。你需要确保你传递的 n 值不大于分配给 str 的实际内存大小。即使 gets_s 会检查这个大小,但如果你的大小参数错误,这可能会导致未定义行为。另外,建议避免使用 gets 和 gets_s,而是使用 fgets,因为 fgets 在所有标准的C库中都是可用的,并且也允许你指定缓冲区大小。
2、例子
#include <stdio.h>
int main()
{
char buffer[20] = { '\0' };
gets_s(buffer, 20);
printf("%s\n", buffer);
return 0;
}运行结果:

这里结果只有一个换行,是printf函数中的\n而不是gets_s读取的回车,因为gets_s函数不会将换行符复制到数组中。
四、fgets函数
1、介绍
上面提到了fgets函数使用更广泛,那具体是怎么使用的呢?
fgets 函数是一个在C语言中广泛使用的标准库函数,用于从文件流中读取一行。
fgets 函数的原型定义在 <stdio.h> 头文件中,如下所示:
char *fgets(char *str, int num, FILE *stream);参数说明:
str:指向一个字符数组的指针,这个数组用来存储读取的字符串。num:指定要读取的最大字符数,包括最后的空字符('\0')。简单来说,如果缓冲区大小为?n,那么最多读取?n-1?个字符,保证有空间放置字符串结尾的空字符。stream:要读取的输入流,通常是文件指针。如果你想从标准输入(通常是键盘)读取,可以使用?stdin?作为这个参数。
又有人会问了,为什么上面的gets_s函数的字符串最大存储数(包括'?\0 ')的类型是rsize_t,而这里的fgets函数的是int类型?
gets_s 和 fgets 函数的参数类型不同,这主要是因为它们分别遵循了C的不同标准,并且设计上考虑了不同的安全性和可移植性问题。
gets_s 是在C11标准中引入的安全版本的gets函数。其参数类型 rsize_t 是一种在C11中定义的新的类型。这个类型用于表示对象的大小,是一个无符号的整数类型,并且是为了增强程序的安全性和可移植性。rsize_t 的使用意味着gets_s函数的缓冲区大小参数不应该为负数。
char *gets_s(char *s, rsize_t n);另一方面,fgets 函数存在的时间要比gets_s长得多,它是在之前的C标准中定义的,包括ANSI C和C99,这些标准中没有rsize_t类型。在fgets的定义中,其缓冲区大小参数是int类型,这已经被广泛使用并且在各种C编译器和平台中都得到了支持。
char *fgets(char *str, int n, FILE *stream);虽然从理论上讲,int类型可以接受负数,但在fgets的上下文中,传递一个负数没有逻辑意义,因为它代表了缓冲区的大小。实际上,如果调用fgets时传入了一个负数,函数的行为将是未定义的。
总的来说,rsize_t的使用提供了更强的类型安全性,强调了函数参数应当是一个合理的大小值。而fgets使用int是因为它遵循了旧的标准,而那时候没有为了表示大小而专门设立的无符号类型。在实际使用中,你应该总是传入正数作为这些函数的大小参数。
fgets 会从指定的 stream 读取字符,直到发生以下三种情况之一:
- 读取了?
num-1?个字符。 - 读取到了一个换行符,换行符会被存储在字符串中。
- 遇到了文件结束符(EOF)。
在字符串的末尾,无论是因为读取到了换行符还是因为达到了字符数量限制,fgets 总是会在最后添加一个空字符('\0')来表示字符串的结束。
fgets 的返回值:
- 成功:返回?
str?的指针。 - 失败或遇到文件结束符而没有读取任何字符:返回?
NULL。
由于 fgets 包括换行符在内的读取方式,因此通常在使用 fgets 后需要检查并处理字符串末尾可能存在的换行符。
2、例子
#include <stdio.h>
int main()
{
char buffer[20] = { '\0' };
fgets(buffer, 20, stdin);
printf("%s\n", buffer);
return 0;
}运行结果:
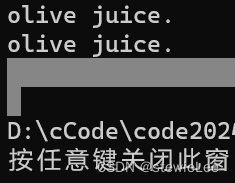
这里结果有两行换行,因为fgets函数会将换行符复制到数组中,再加上printf中的\n,刚好有两个换行。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!