Transformer|对图像数据构造patch序列+VIT整体架构解读(需进一步完善)
发布时间:2024年01月20日
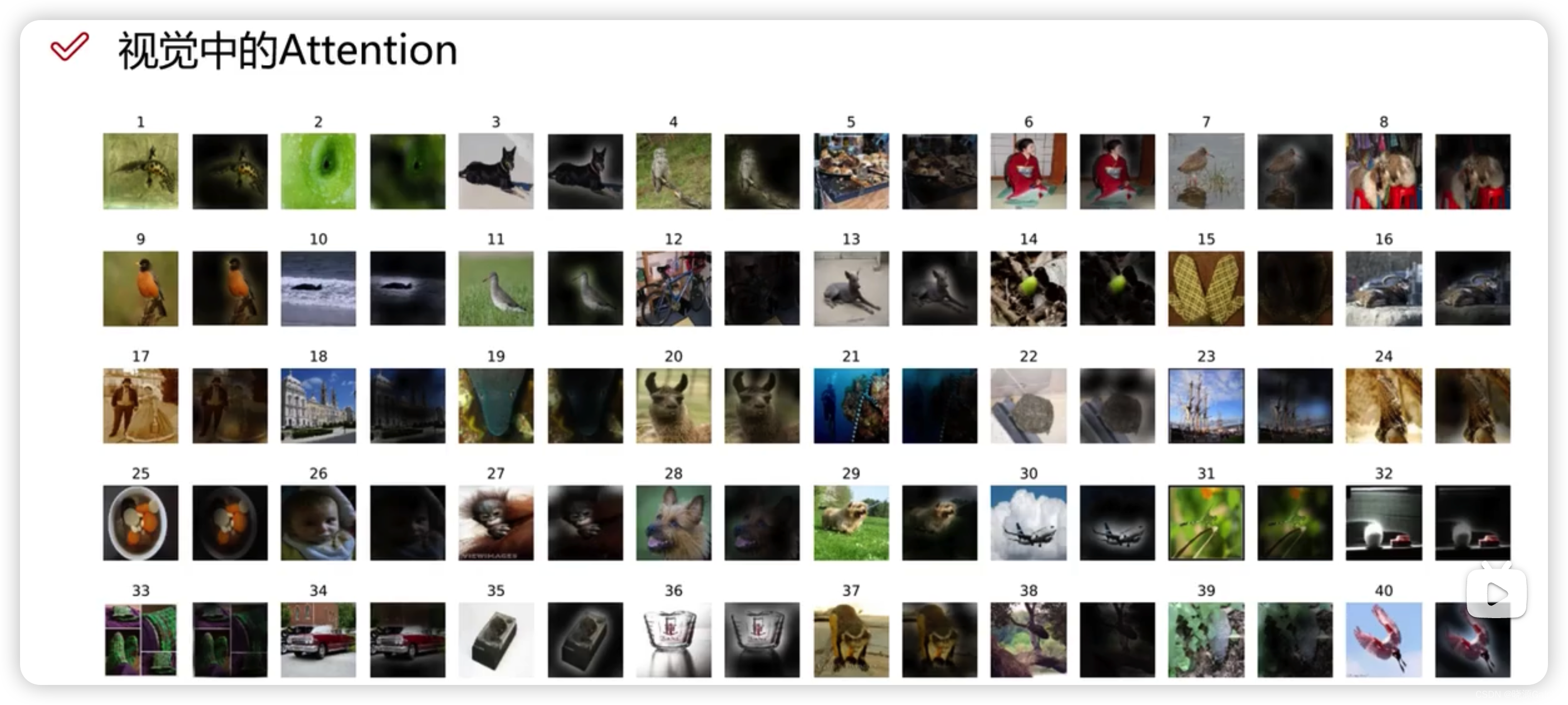
Attention在视觉的作用
使其关注到所值得关注的。
ViT(Vision transformer)
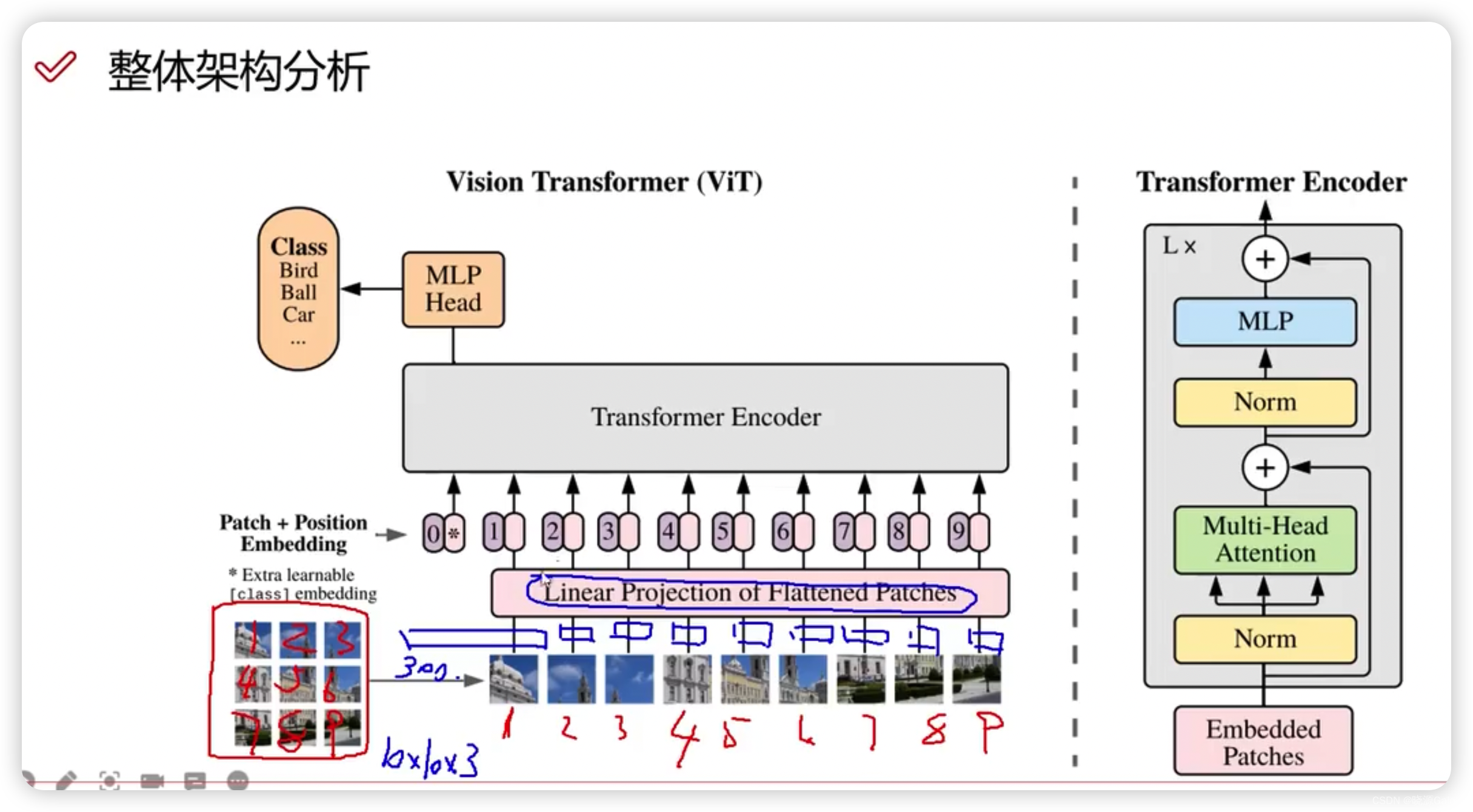
比如说图像是一个30x30x3的大小,可以将其拆分成9个10x10x3的部分,每个部分可以继续将10x10x3的部分拆解成300x1的向量来代表自己。(通常情况下,并不是300x1,这里只是方便理解怎么去生成向量)
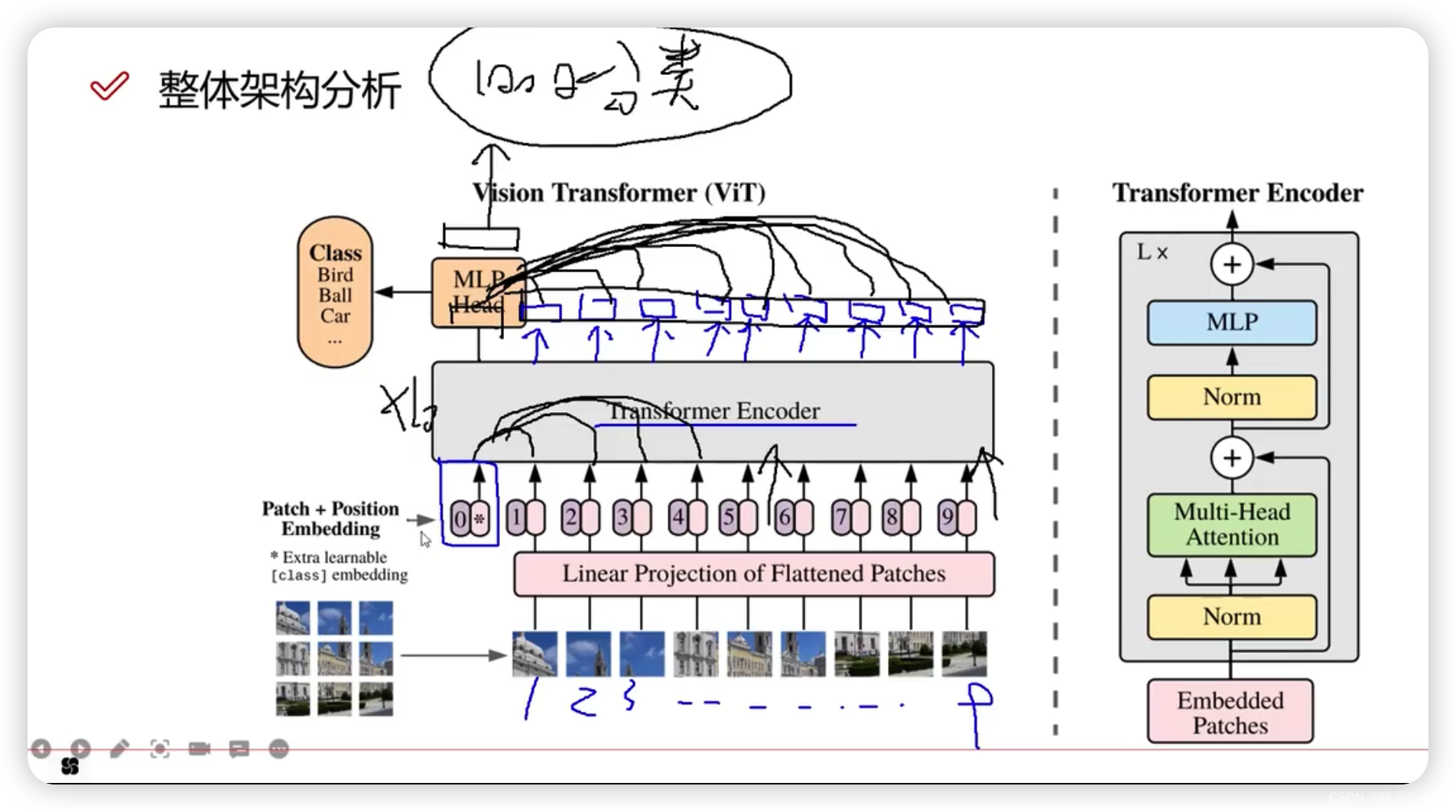
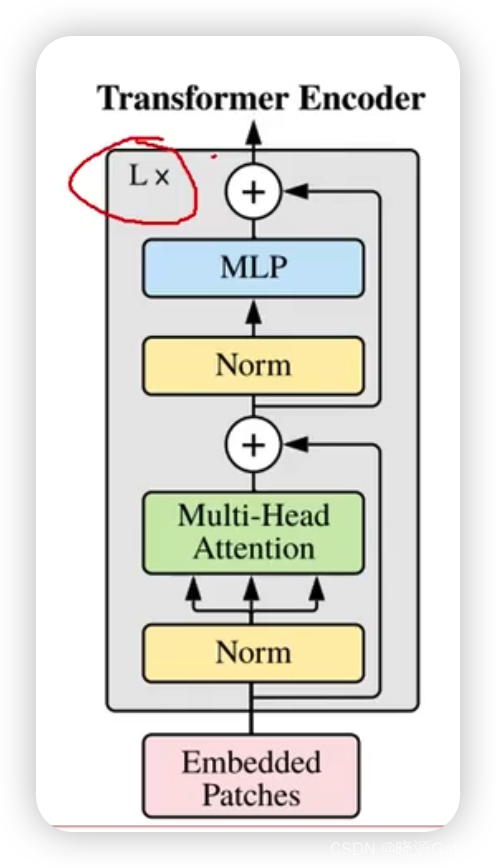
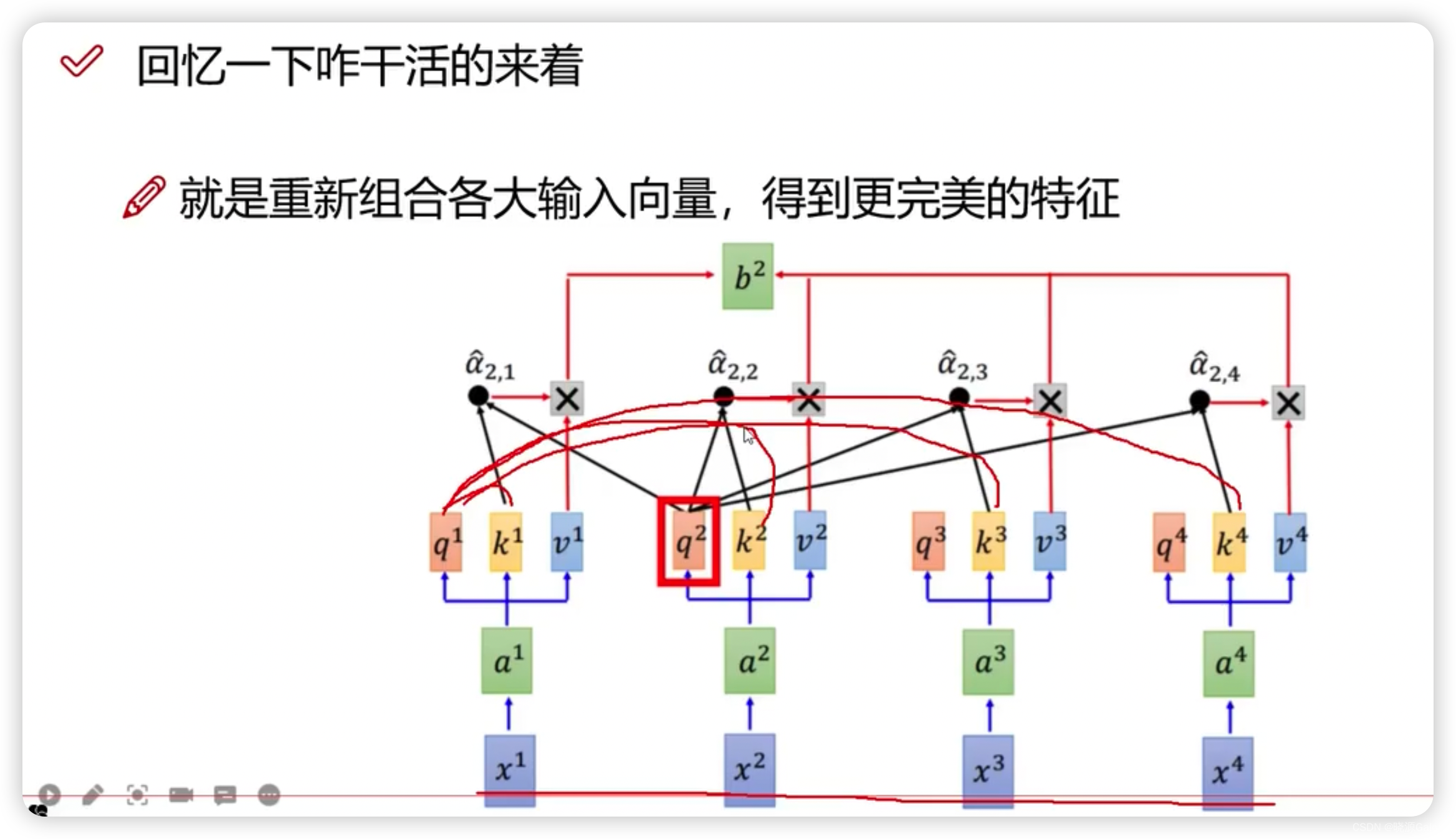
L是执行的次数,也就是说transformer不只做了一次。
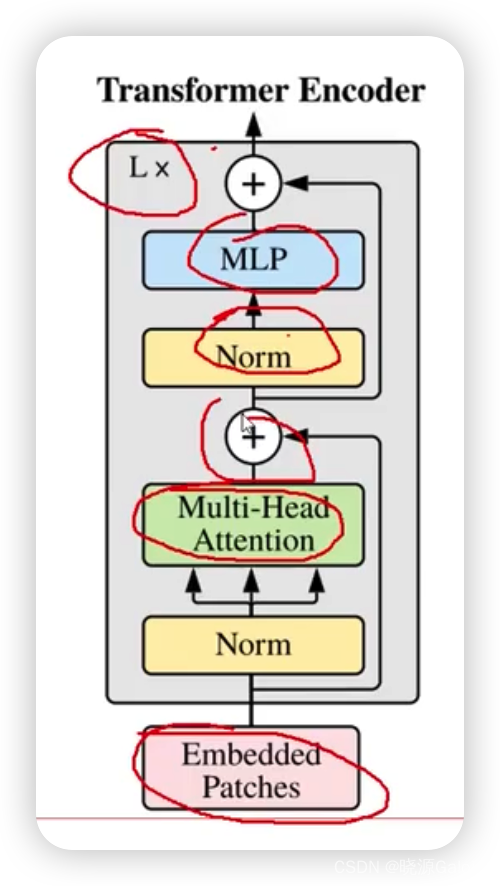
其中+号是指类似ResNet中的残差链接操作。
文章来源:https://blog.csdn.net/Fangyechy/article/details/135712111
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- springboot框架,中间库是mognodb,可以写入2个数据库的Demo
- 【网络安全】Log4j 远程代码执行漏洞解析
- 再传捷报!百望云荣登投资家网“2023年度企业服务领域创新企业TOP20”
- SpringBoot发布项目到docker
- Mobile ALOHA 简介
- ListNode 2487. 从链表中移除节点,单调栈的应用
- 螺纹钢负公差轧制中的测径仪应用
- 嵌套类与匿名类
- 数据库原理及数据库的优化
- juniper EX系列交换机 包过滤(Packet Filtering)配置