下午好~ 我的论文【CV边角料】(第三期)
CV边角料
Pixel Shuffle
pixelshuffle算法的实现流程如上图,其实现的功能是:将一个H × W的低分辨率输入图像(Low Resolution),通过Sub-pixel操作将其变为rH x rW的高分辨率图像(High Resolution)。
但是其实现过程不是直接通过插值等方式产生这个高分辨率图像,而是通过卷积先得到 r^2个通道的特征图(特征图大小和输入低分辨率图像一致),然后通过周期筛选(periodic shuffing)的方法得到这个高分辨率的图像,其中r为上采样因子(upscaling factor),也就是图像的扩大倍率。
class torch.nn.PixleShuffle(upscale_factor)
ps = nn.PixelShuffle(3)
input = torch.tensor(1, 9, 4, 4)
output = ps(input)
print(output.size())
# torch.Size([1, 1, 12, 12])
SENet
Squeeze-and-Excitation Networks(SENet)主要特点是引入了一种新的网络结构单元——Squeeze-and-Excitation Block(SE Block),通过动态调整特征通道之间的权重来实现对不同特征的重新校准和增强。
SENet中的SE Block包括两个部分:Squeeze和Excitation。Squeeze操作将输入特征图压缩成一个向量,这个向量包含了所有通道的信息;Excitation操作则对这个向量进行非线性变换,生成一个新的权重向量,用于对原始特征进行加权求和。最后,将加权后的特征与原始特征相乘,得到最终的特征表示。

CBAM
Convolutional Block Attention Module(CBAM)是结合了空间(spatial)和通道(channel)的注意力机制,对于输入特征图,CBAM沿着通道和空间两个独立的维度依次推断注意力图,然后将注意力图与原特征图相乘来对特征进行自适应调整。此外,研究表明,相比于只关注通道的注意力机制如SENet,CBAM可以获得更好的效果。

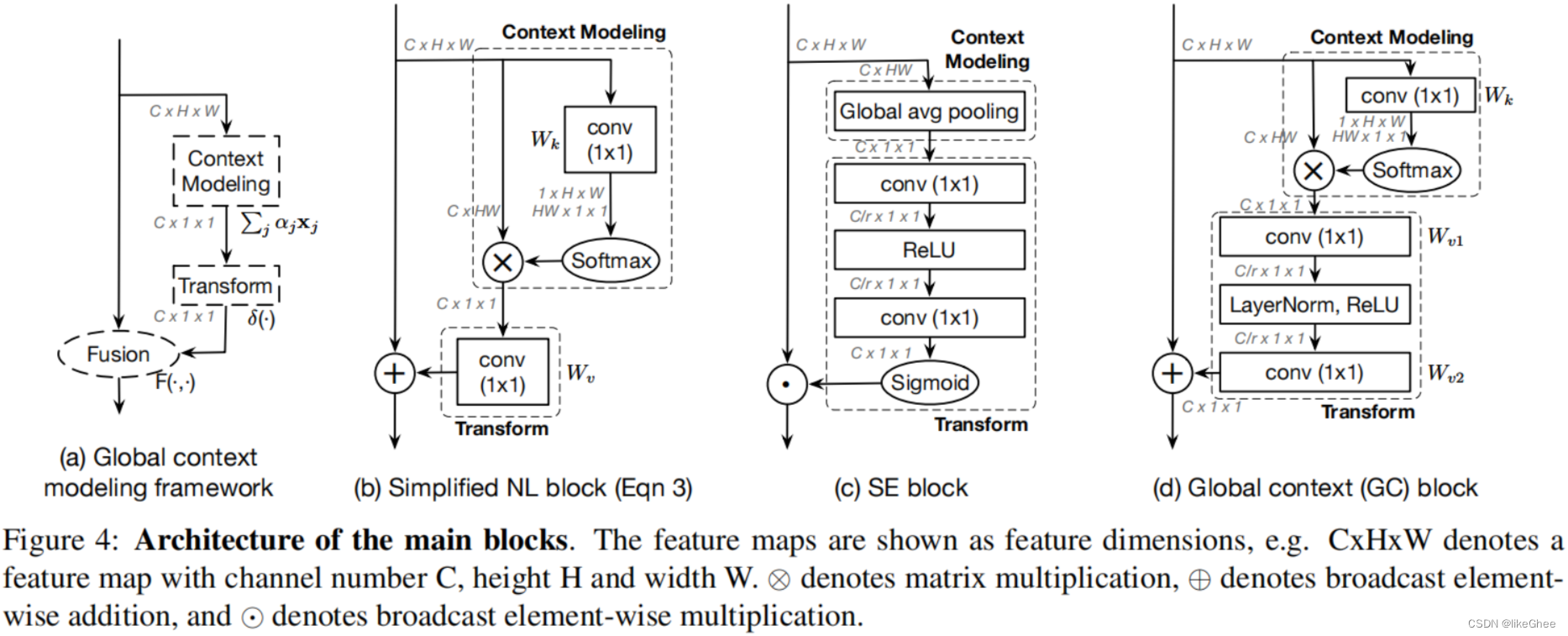
Global Context Block (GC)
是一种全局上下文建模框架,它能够像SNL block一样建立有效的长距离依赖关系,同时还能像SE block一样节省计算量。这种模块的设计理念在于捕获long-range dependency以提取全局信息,对于各种视觉任务都是非常有帮助的。
GC结构主要是基于Squeeze-and-Excitation Networks (SENet)和Non-local Networks。
SENet上面介绍过了。
而非局部神经网络(Non-local Neural Networks)是一种被设计来提升神经网络的泛化能力的模型。这种网络通过在网络中引入非局部块,可以捕获输入数据中的长距离依赖关系,使网络能够学习到更广泛和复杂的特征。
GCBlock首先使用1x1卷积层来减少通道数,然后应用squeeze操作来获取每个通道的全局信息。接下来,通过excitation操作,为每个通道重新分配权重。最后,通过使用这个权重来调整原始特征图。
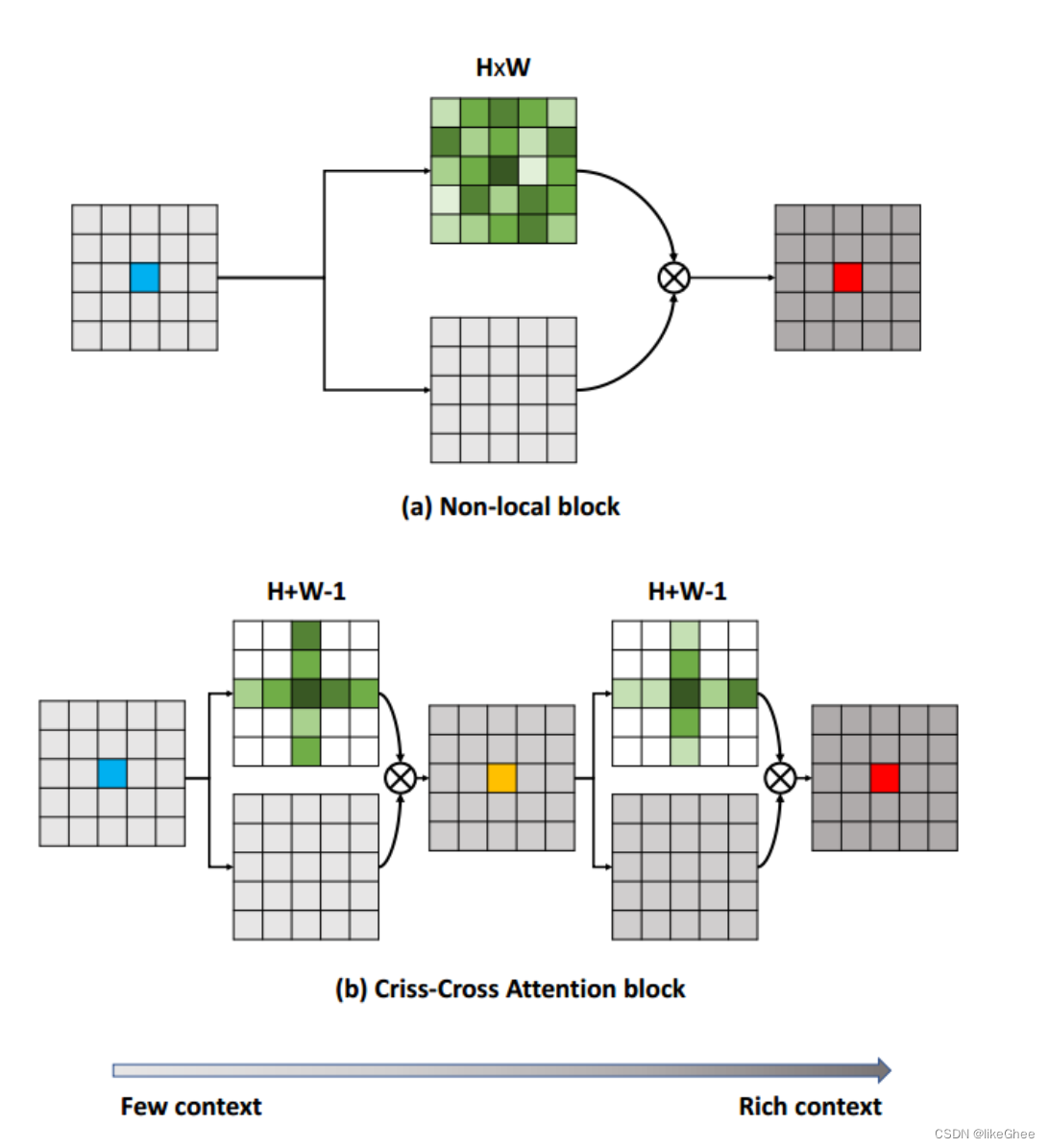
Criss-Cross Attention modules (CC)
是一种在语义分割领域的注意力机制模块,由论文"CCNet: Criss-Cross Attention for Semantic Segmentation"提出。这个模块通过十字交叉注意力的设计,实现了更强的特征表达能力和更高的效率。总的来说,CCNet的优点包括生成更具辨别性的特征以及减少GPU内存的使用。
在criss-cross attention module中,重复使用了两次criss-cross注意力机制(选十字交叉的权重特征参与后续计算),因为只使用一次,该像素点的只能与周围呈十字型的像素点进行信息交互,使用两次之后,较远处的像素点同样可以间接作用于该像素点。信息传播大致如下图二所示。相比与non-local,计算量大大减少。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 聚观早报 |xPad2 Pro系列学习机发布;华为Mate X5典藏版实力过硬
- 高校实验室安全管理视频监控系统设计:AI视频识别技术智能分析网关V4的应用
- Linux文件系统与日志分析管理
- 视频剪辑高手实战:批量置入随机封面,高效制作
- 代码随想录算法训练营第三十八天 | 斐波那契数、爬楼梯、使用最小花费爬楼梯
- 信息收集 - 端口
- HDFS的EC Coding(纠删码)和块管理(WIP)
- 1868_C语言单向链表的实现
- 企业直聘招聘人才求职系统招聘会小程序系统源码
- Python进阶知识:整理1 -> pySpark入门