socket通信客户端收到16进制转换出现efbfbd乱码解决办法
发布时间:2024年01月24日
socket客户端接收服务端发来的数据时,发现老有efbfbd乱码,如下图,服务端发送的是02040200013CF0,但是客户端接收到解析后却不一样
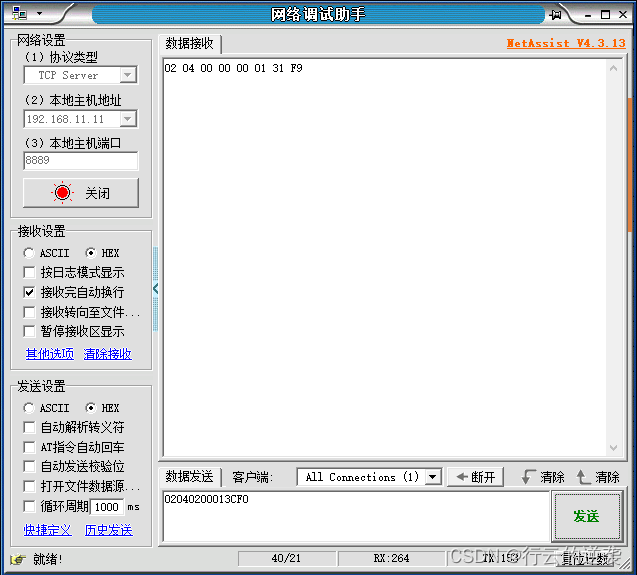
客户端接收解析并打印
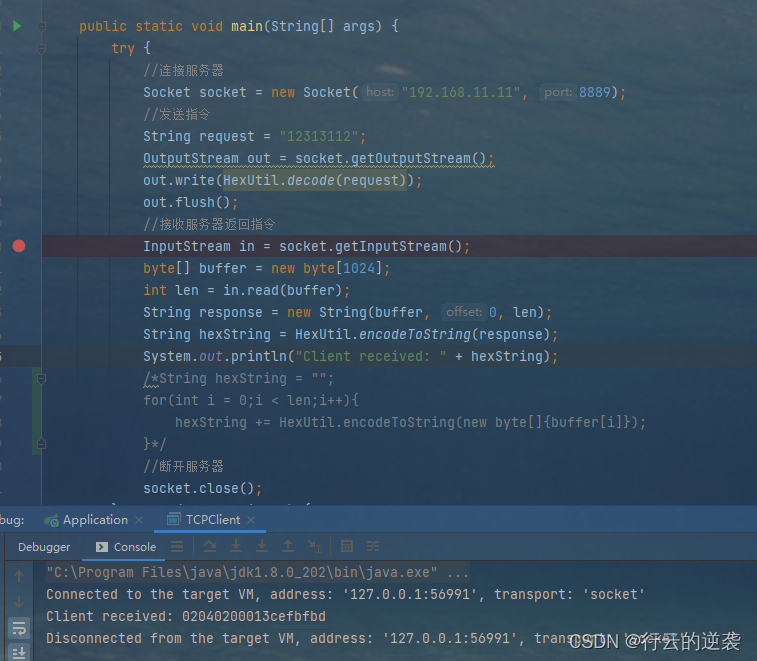
在网上查原因后,原因是将接收的byte数组转换为String后,默认转换为了UTF-8格式,但是后面字节数不够出现了乱码,所以导致解析错误
对代码进行修改,接收的byte数组不转换为String,逐个字节进行接收并转换,然后拼接,结果是正确的,问题解决
InputStream in = socket.getInputStream();
int a = 0;
byte[] buffer = new byte[1024];
int len = in.read(buffer);
String hexString = "";
for(int i = 0;i < len;i++){
hexString += HexUtil.encodeToString(new byte[]{buffer[i]});
}
System.out.println("Client received: " + hexString);
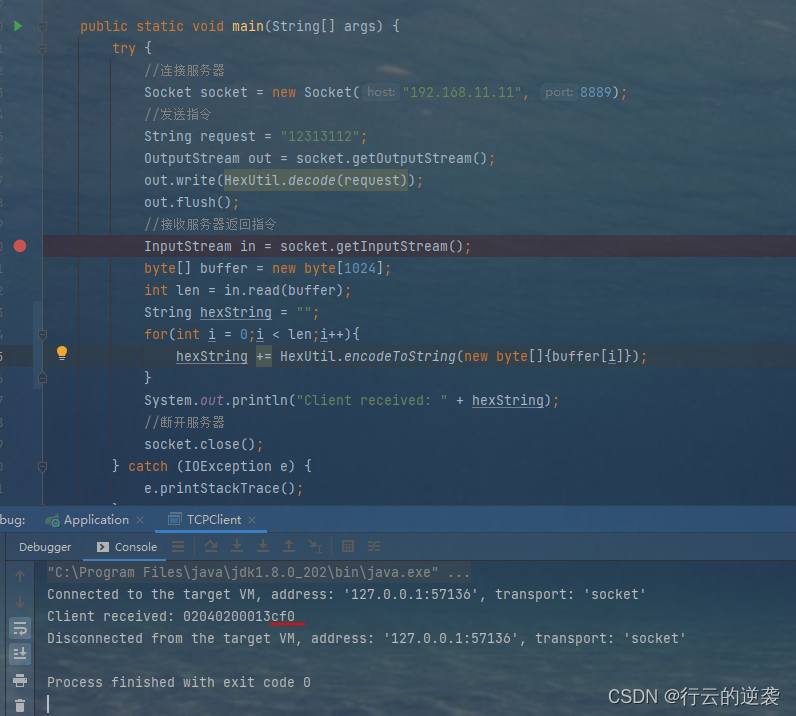
上面的程序需要对逐个字节进行接收并转换,再拼接,效率比较低,可以再优化。这样优化的前提是需要知道接收的数据有多少个字节,在初始化字节数组时,就需要初始化大小。设置1024也可以,不过转换后,会有很多没用的内容,需要再截取。
InputStream in = socket.getInputStream();
int a = 0;
byte[] buffer = new byte[7];
int len = in.read(buffer);
String hexString = HexUtil.encodeToString(buffer);
System.out.println("Client received: " + hexString);
文章来源:https://blog.csdn.net/juligang320/article/details/135776547
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- linux怎么做定时执行命令
- 阶段十-分布式-nginx服务器
- 线性代数-行列式-错题笔记-1
- ECharts实现饼图径向渐变、线性渐变坐标计算
- MD-LIVE 3.4 (Windows) 下载 - 移动取证实时提取和分析
- Python环境安装GDAL
- 在电脑下载offcie2010安装
- 小型洗衣机什么牌子好又便宜?实用的小型洗衣机测评
- 利用python将excel文件转成txt文件,再将txt文件上传hdfs,最后传入hive中
- 一文解释Linux的内存分页管理