【InternLM】基于InternLM和LangChain从0开始搭建你的知识库【完全攻略】【LangChain和向量数据库的详细介绍】
前言
这一篇文章的主要内容是LangChain介绍、向量数据库介绍以及基于InternLM和LangChain从0开始搭建你的知识库实践!一、LangChain介绍
1-1、介绍
LangChain: 是一个开发应用程序的框架。 (简单来说:LangChain允许用户连接大模型和个人数据源,方便基于个人数据源执行任何操作,即引用完整个人数据源,使用大模型来做任何事。)
框架由以下几部分组成:
- LangChain库:Python和JavaScript库,包含无数组件的接口和集成。
- LangChain模板: 对于各种各样的任务有易于部署的框架。
- LangServe: 一个用于将LangChain部署为REST API的库。
- LangSmith: 一个开发平台,允许调试、测评、评估和监控任意构建在LLM框架上的链。
架构图如下所示:
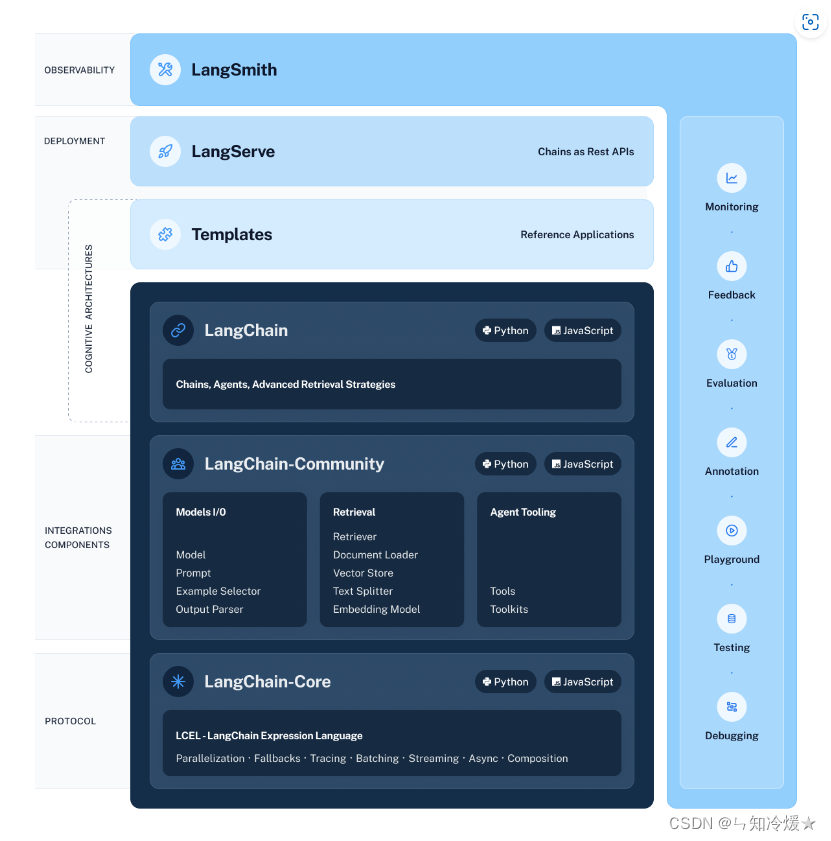
LangChain的核心组成模块:
- 链:将组件组合实现端到端应用,通过一个对象封装实现一系列LLM操作。
- Eg:检索问答链,覆盖了RAG(检索增强生成)的全部流程。
下图为基于LangChain构建RAG应用流程图:

1-2、快速入门
安装:
# langchain安装
pip install langchain
# 如果需要调控、测试以及评估构建在LLM框架上的链,那么你需要设置以下环境变量。
# 设置环境变量以使用LangSmith
export LANGCHAIN_TRACING_V2="true"
export LANGCHAIN_API_KEY="..."
以下为构建链的两种方法:
1-2-1、通过OpenAI使用
导入集成包:
pip install langchain_openai
初始化模型并使用::
from langchain_openai import ChatOpenAI
# openai_api_key:创建账户,获取个人密钥,详细获取方式参见附录
llm = ChatOpenAI(openai_api_key="...")
# 使用
llm.invoke("how can langsmith help with testing?")
使用提示模板来引导LLM回复,比如使用提示词模板来让模型润色输入:
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", "You are world class technical documentation writer."),
("user", "{input}")
])
# 结合成一个简单的LLM链
chain = prompt | llm
# 这时候同样的提问,模型会以更加专业的语气回答。
chain.invoke({"input": "how can langsmith help with testing?"})
1-2-2、通过本地开源模型使用
使用Ollama来运行本地开源模型:
from langchain_community.llms import Ollama
# 加载llama2开源模型
llm = Ollama(model="llama2")
# 使用
llm.invoke("how can langsmith help with testing?")
使用提示模板来引导LLM回复,比如使用提示词模板来让模型润色输入:
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", "You are world class technical documentation writer."),
("user", "{input}")
])
# 结合成一个简单的LLM链
chain = prompt | llm
# 这时候同样的提问,模型会以更加专业的语气回答。
chain.invoke({"input": "how can langsmith help with testing?"})
添加输出解析器,将信息转换为字符串:
from langchain_core.output_parsers import StrOutputParser
output_parser = StrOutputParser()
chain = prompt | llm | output_parser
chain.invoke({"input": "how can langsmith help with testing?"})
1、加载知识库目录下的文件,各种各样的,如:txt pdf docx xlsx ppt 等
2、对文件内容进行embedding,存成vector_store
3、提问并构造prompt
4、送入LLM模型
5、得到响应内容
1-3、与SQL数据库进行交互
1-3-1、概述&功能介绍
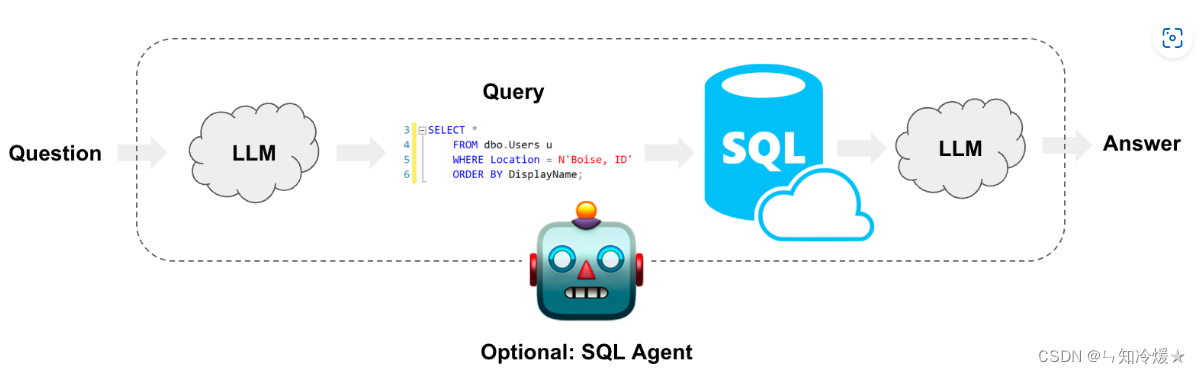
概述:LangChain提供SQL链和代理来构建和运行基于自然语言处理提示的SQL查询。兼容(MySQL, PostgreSQL, Oracle SQL, Databricks, SQLite)等。
具体可以实现的功能:
- 使用自然语言就可以生成查询语句
- 基于数据库,创建聊天机器人,可以回答有关于数据库的任何问题
- 根据用户想要分析的内容构建自定义仪表板
1-3-2、安装&小栗子
安装:
pip install langchain langchain-experimental openai -i https://mirror.baidu.com/pypi/simple
功能一:文本转SQL查询语句
from langchain.chains import create_sql_query_chain
from langchain.chat_models import ChatOpenAI
chain = create_sql_query_chain(ChatOpenAI(temperature=0), db)
response = chain.invoke({"question": "How many employees are there"})
print(response)
功能二:文本转SQL查询语句&执行
注意:该方法容易收到SQL注入的影响。
from langchain.llms import OpenAI
from langchain_experimental.sql import SQLDatabaseChain
llm = OpenAI(temperature=0, verbose=True)
db_chain = SQLDatabaseChain.from_llm(llm, db, verbose=True)
功能三:SQL代理
概述:可以提供更加灵活的与数据库交互的方式。
主要优点:
- 根据数据库的模式和数据库的内容来回答问题
- 通过运行生成的查询、捕捉回溯并重新生成查询来从错误中恢复
from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
# from langchain.agents import AgentExecutor
from langchain.agents.agent_types import AgentType
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
agent_executor = create_sql_agent(
llm=OpenAI(temperature=0),
toolkit=SQLDatabaseToolkit(db=db, llm=OpenAI(temperature=0)),
verbose=True,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
)
代理案例1:
agent_executor.run(
"List the total sales per country. Which country's customers spent the most?"
)
代理案例2:描述图表
agent_executor.run("Describe the playlisttrack table")
二、向量数据库介绍
2-0、引言-大语言模型的不足
2023年,大语言模型爆发元年,不管是CloseAI出品的GPT系列模型,还是LLAma系列开源模型、Google的Gemini等模型等,其表现能力都让人叹为观止,大语言模型在自然语言领域的表现都远超以往任何模型。但是大语言模型也存在很多不足:在处理一些专业领域的知识时,会表现出知识缺失,这时候大语言模型可能无法提供准确答案。在解决此类问题时,数据科学家们通常使用的方法是对模型进行微调来适应特定领域的知识,将知识参数化,尽管这种方法取得了卓越的效果,但是其缺点在于成本高昂,需要专业技术知识。
针对大语言模型的另一种解决方案:参数化知识(微调)存在极大局限性,难以保留训练语料库中的所有知识,每一次知识的更新都要消耗大量的计算资源去训练模型。模型参数无法动态更新,参数化知识会随时过时。但是相比较于参数化知识(即通过模型微调来适应专业知识),非参数化知识(使用向量数据库,即本节案例,基于InternLM和LangChain从0开始搭建你的知识库),存储在外部的知识源。更加方便、易于扩展。这种方法使得开发人员无需为每一个特定任务重新训练整个庞大的模型。他们可以简单地给模型加上一个知识库,通过这种方式增加模型的信息输入,从而提高回答的精确性。为了融合两种方式的优缺点,模型可以采取半参数化的方法,将非参数化的语料库数据库与参数化模型相结合,这种方法被称为检索增强生成(Retrieval-Augmented Generation, RAG)。
下图为RAG与其他模型优化方法的比较:

RAG工作流:
- 输入文本转化为向量(使用先进的词嵌入模型)
- 在向量数据库中匹配相似的文本(预先构建向量数据库)
- 构建提示词模板输入到大模型中去。
- You get it!
2-1、向量数据库定义
向量数据库: 是一种用于存储和检索以及分析大规模向量数据的数据库系统。它主要应用于图像检索、音频检索、文本检索等领域。向量数据库使用专门的数据结构和算法来处理向量之间的相似性计算和查询,通过构建索引结构,能够快速找到最相似的向量,满足各种应用场景中的查询需求。生成式模型容易产生幻觉,向量数据库可以弥补这一缺陷,为生成式人工智能聊天机器人提供外部知识库,确保提供值得信赖的信息。
2-2、工作原理
工作原理: 在向量数据库中,数据以向量的形式进行存储和处理,因此需要将原始的非向量型数据转化为向量表示。数据向量化是指将非向量型的数据转换为向量形式的过程。通过数据向量化,实现了在向量数据库中进行高效的相似性计算和查询。此外,向量数据库使用不同的检索算法来加速向量相似性搜索,如 KD-Tree、VP-Tree、LSH 以及倒排索引等。在实际应用中,需要根据具体场景进行算法的选择和参数的调优,具体选择哪种算法取决于数据集的特征、数据量和查询需求,以及对搜索准确性和效率的要求。
2-3、优点
优点:
- 相似性搜索: 向量数据库专注于处理向量数据,并采用专门的索引结构和相似性计算算法,能够高效地进行相似性搜索。它能够快速找到最相似的向量,适用于人脸识别、图像搜索、推荐系统等需要相似性匹配的应用。
- 复杂数据支持:向量数据库提供多种数据类型的支持,可通过数据向量化方法转换为向量形式。同时,向量数据库还能够支持各种复杂的查询操作,如范围查询、聚类分析、维度约减等。这使得它在不同应用场景下具备更丰富的数据分析和挖掘能力。
- 机器学习能力:向量数据库通常与机器学习算法和工具集成,能够进行自动的特征提取、聚类分析和分类等任务。它能够支持数据驱动的应用,从数据中学习并提取有价值的信息。例如,向量数据库构建相似度模型,从而实现根据向量之间的相似性度量进行快速的相似性匹配和搜索。
2-4、与传统数据库的区别
- 远超传统关系型数据库的规模:传统的关系型数据库管理1亿条数据已经是拥有很大的业务流量,而在向量数据库需求中,一张表千亿数据是底线,并且原始的向量通常比较大,例如512个float=2k,千亿数据需要保存的向量就需要200T的存储空间(不算多副本),单机显然不具备这种能力,可线性扩展的分布式系统才是正确的道路,这对系统的可扩展性,可靠性,低成本提出非常大的挑战。
- 查询方式不同:传统数据库查询通常为精确查询,结果一般为查到或者未查到,而向量数据库的查询是近似查询,即查找与查询条件相近的结果,所以查询到的结果是与输入条件最为相似的结果,这种查询方式对计算能力有非常高的要求。
- 低延时与高并发:与传统数据库相比,时延大大降低,高并发。
三、RAGvs微调
3-0、RAG与微调之间的对比&Naive RAG技术介绍

3-1、Naive RAG(初始RAG技术)
流程包含索引、检索、生成等步骤。
索引:
- 数据索引: 将不同格式的文件转换为纯文本。
- 分块:将文本划分为尽可能小的块
- 嵌入和创建索引:将文本编码为向量(类似与one-hot编码、word2vec编码等),所产生的向量用于后续检索过程中计算与问题向量之间的相似度。之后是创建索引,将原始语料块和嵌入以键值对形式存储,以便未来进行快速搜索。
检索:
- 将用户输入转化为向量,计算问题向量和语料库中文档块向量之间的相似性,挑选相似性高的。
生成:
- 将给定问题与相关文档合并为一个新的提示信息。给与大语言模型来回答问题。
缺点
检索质量:
- 检索到的文档并不都与查询内容相关
- 未能检索到相关内容
- 过时的信息
回复内容的质量问题:
- 回答不相关
- 生成有害或者偏见内容
- 幻觉、虚构答案
数据增强问题:
- 检索到数据的处理:去除冗余、重复。
- 判断检索文档的重要程度,评估重要性。
- 防止模型过度依赖于检索到的信息
后续知识待补充。。。。
四、基于InternLM和LangChain搭建你的知识库实践
4-0、环境搭建
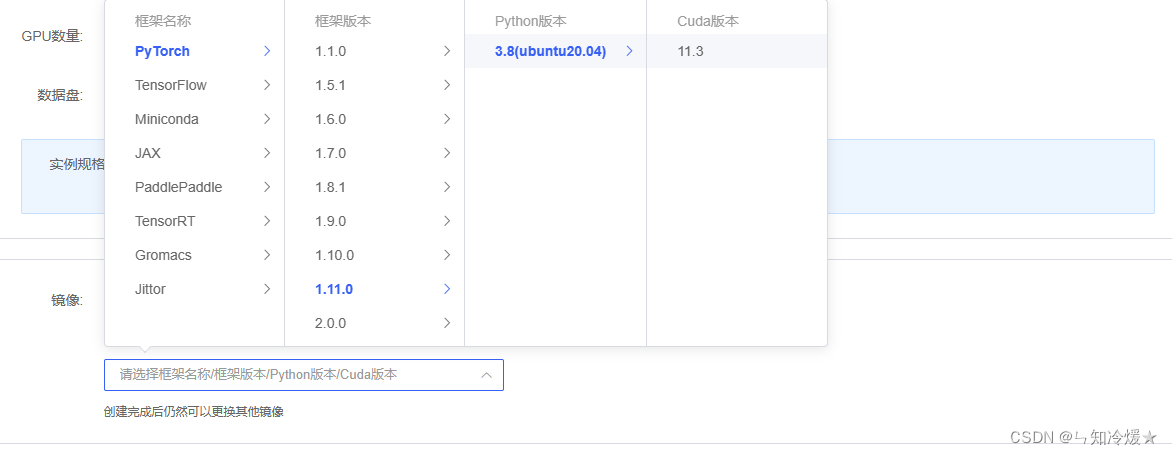
环境:租用autoDL,环境选torch1.11.0,ubuntu20.04,python版本为3.8,cuda版本为11.3,使用v100来进行实验。

4-1、创建虚拟环境
bash # 请每次使用 jupyter lab 打开终端时务必先执行 bash 命令进入 bash 中
# 创建虚拟环境
conda create -n InternLM
# 激活虚拟环境
conda activate InternLM
4-2、导入所需要的包
# 升级pip
python -m pip install --upgrade pip
# 下载速度慢可以考虑一下更换镜像源。
# pip config set global.index-url https://mirrors.cernet.edu.cn/pypi/web/simple
pip install modelscope==1.9.5
pip install transformers==4.35.2
pip install streamlit==1.24.0
pip install sentencepiece==0.1.99
pip install accelerate==0.24.1
# 将以下依赖包放置在txt文件中并使用命令:pip install -r requirements.txt 来进行安装。
Notice: 详细依赖版本点赞收藏关注我后私信获取,以下为部分展示
accelerate==0.24.1
addict==2.4.0
aiohttp==3.9.1
aiosignal==1.3.1
aliyun-python-sdk-core==2.14.0
aliyun-python-sdk-kms==2.16.2
altair==5.2.0
async-timeout==4.0.3
attrs==23.2.0
blinker==1.7.0
Brotli @ file:///tmp/abs_ecyw11_7ze/croots/recipe/brotli-split_1659616059936/work
cachetools==5.3.2
certifi @ file:///croot/certifi_1700501669400/work/certifi
cffi @ file:///croot/cffi_1700254295673/work
charset-normalizer @ file:///tmp/build/80754af9/charset-normalizer_1630003229654/work
click==8.1.7
crcmod==1.7
cryptography @ file:///croot/cryptography_1694444244250/work
datasets==2.13.0
dill==0.3.6
einops==0.7.0
filelock @ file:///croot/filelock_1700591183607/work
frozenlist==1.4.1
fsspec==2023.12.2
gast==0.5.4
gitdb==4.0.11
GitPython==3.1.40
gmpy2 @ file:///tmp/build/80754af9/gmpy2_1645455533097/work
huggingface-hub==0.20.2
idna @ file:///croot/idna_1666125576474/work
importlib-metadata==6.11.0
Jinja2 @ file:///croot/jinja2_1666908132255/work
jmespath==0.10.0
jsonschema==4.20.0
jsonschema-specifications==2023.12.1
markdown-it-py==3.0.0
MarkupSafe @ file:///opt/conda/conda-bld/markupsafe_1654597864307/work
mdurl==0.1.2
mkl-fft @ file:///croot/mkl_fft_1695058164594/work
mkl-random @ file:///croot/mkl_random_1695059800811/work
mkl-service==2.4.0
modelscope==1.9.5
mpmath @ file:///croot/mpmath_1690848262763/work
multidict==6.0.4
multiprocess==0.70.14
networkx @ file:///croot/networkx_1690561992265/work
numpy @ file:///croot/numpy_and_numpy_base_1701295038894/work/dist/numpy-1.26.2-cp310-cp310-linux_x86_64.whl#sha256=2ab675fa590076aa37cc29d18231416c01ea433c0e93be0da3cfd734170cfc6f
oss2==2.18.4
packaging==23.2
pandas==2.1.4
Pillow==9.5.0
platformdirs==4.1.0
protobuf==4.25.1
psutil==5.9.7
pyarrow==14.0.2
pycparser @ file:///tmp/build/80754af9/pycparser_1636541352034/work
pycryptodome==3.19.1
pydeck==0.8.1b0
Pygments==2.17.2
Pympler==1.0.1
pyOpenSSL @ file:///croot/pyopenssl_1690223430423/work
PySocks @ file:///home/builder/ci_310/pysocks_1640793678128/work
python-dateutil==2.8.2
pytz==2023.3.post1
pytz-deprecation-shim==0.1.0.post0
PyYAML==6.0.1
referencing==0.32.1
regex==2023.12.25
requests @ file:///croot/requests_1690400202158/work
rich==13.7.0
rpds-py==0.16.2
safetensors==0.4.1
scipy==1.11.4
sentencepiece==0.1.99
simplejson==3.19.2
six==1.16.0
smmap==5.0.1
sortedcontainers==2.4.0
streamlit==1.24.0
sympy @ file:///croot/sympy_1668202399572/work
tenacity==8.2.3
tokenizers==0.15.0
toml==0.10.2
tomli==2.0.1
toolz==0.12.0
torch==2.0.1
torchaudio==2.0.2
torchvision==0.15.2
tornado==6.4
tqdm==4.66.1
transformers==4.35.2
triton==2.0.0
typing_extensions @ file:///croot/typing_extensions_1690297465030/work
tzdata==2023.4
tzlocal==4.3.1
urllib3 @ file:///croot/urllib3_1698257533958/work
validators==0.22.0
watchdog==3.0.0
xxhash==3.4.1
yapf==0.40.2
yarl==1.9.4
zipp==3.17.0
4-3、模型下载
概述:在 /root 路径下新建目录 data,在目录下新建 download.py 文件并在其中输入以下内容,粘贴代码后记得保存文件,如下图所示。并运行 python /root/data/download.py 执行下载,模型大小为 14 GB,下载模型大概需要 10~20 分钟
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('Shanghai_AI_Laboratory/internlm-chat-7b', cache_dir='/root/data/model', revision='v1.0.3')
4-4、LangChain 相关环境配置&词向量模型Sentence Transformer下载
LangChain 相关环境配置所需安装包如下:
pip install langchain==0.0.292
pip install gradio==4.4.0
pip install chromadb==0.4.15
pip install sentence-transformers==2.2.2
pip install unstructured==0.10.30
pip install markdown==3.3.7
词向量模型Sentence Transformer下载(介绍详见附录):
第一步:安装huggingface_hub
pip install -U huggingface_hub
第二步:执行下载文件download_hf.py,如下所示(模型最终下载到/root/data/model/sentence-transformer路径下)。
import os
# 设置环境变量
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# 下载模型
# resume-download:断点续下
# local-dir:本地存储路径。(linux环境下需要填写绝对路径)
os.system('huggingface-cli download --resume-download sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 --local-dir /root/data/model/sentence-transformer')
4-5、NLTK相关资源下载
概述:在使用开源词向量模型构建开源词向量的时候,需要用到第三方库 nltk 的一些资源。
cd /root
git clone https://gitee.com/yzy0612/nltk_data.git --branch gh-pages
cd nltk_data
mv packages/* ./
cd tokenizers
unzip punkt.zip
cd ../taggers
unzip averaged_perceptron_tagger.zip
4-6、知识库搭建
下载语料库来源
# OpenCompass:面向大模型评测的一站式平台
# IMDeploy:涵盖了 LLM 任务的全套轻量化、部署和服务解决方案的高效推理工具箱
# XTuner:轻量级微调大语言模型的工具库
# InternLM-XComposer:浦语·灵笔,基于书生·浦语大语言模型研发的视觉-语言大模型
# Lagent:一个轻量级、开源的基于大语言模型的智能体(agent)框架
# InternLM:一个开源的轻量级训练框架,旨在支持大模型训练而无需大量的依赖
# 进入到数据库盘
cd /root/data
# clone 上述开源仓库
git clone https://gitee.com/open-compass/opencompass.git
git clone https://gitee.com/InternLM/lmdeploy.git
git clone https://gitee.com/InternLM/xtuner.git
git clone https://gitee.com/InternLM/InternLM-XComposer.git
git clone https://gitee.com/InternLM/lagent.git
git clone https://gitee.com/InternLM/InternLM.git
构建向量数据库(可以在 /root/data 下新建一个 demo目录,将该脚本和后续脚本均放在该目录下运行):
1、get_files函数:将选用上述仓库中所有的 markdown、txt 文件作为示例语料库。该函数返回所有满足条件的文件路径。
2、get_text函数:使用LangChain提供的FileLoader对象来加载目标文件,使用不同的的方法来加载不同类型的文件。
3、对文本进行分块
4、加载开源词向量工具,进行文本向量化
5、使用向量数据库Chroma,基于上文分块后的文档、加载的开源向量化模型,将语料加载到指定路径下。
6、执行该脚本(Knowledge_construction.py ),将向量数据库持久化存储到磁盘上。
# 首先导入所需第三方库
from langchain.document_loaders import UnstructuredFileLoader
from langchain.document_loaders import UnstructuredMarkdownLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from tqdm import tqdm
import os
# 获取文件路径函数,将选用上述仓库中所有的 markdown、txt 文件作为示例语料库。该函数返回所有满足条件的文件路径。
def get_files(dir_path):
# args:dir_path,目标文件夹路径
file_list = []
for filepath, dirnames, filenames in os.walk(dir_path):
# os.walk 函数将递归遍历指定文件夹
for filename in filenames:
# 通过后缀名判断文件类型是否满足要求
if filename.endswith(".md"):
# 如果满足要求,将其绝对路径加入到结果列表
file_list.append(os.path.join(filepath, filename))
elif filename.endswith(".txt"):
file_list.append(os.path.join(filepath, filename))
return file_list
# 加载文件函数,get_text函数,使用LangChain提供的FileLoader对象来加载目标文件,使用不同的的方法来加载不同类型的文件。
def get_text(dir_path):
# args:dir_path,目标文件夹路径
# 首先调用上文定义的函数得到目标文件路径列表
file_lst = get_files(dir_path)
# docs 存放加载之后的纯文本对象
docs = []
# 遍历所有目标文件
for one_file in tqdm(file_lst):
file_type = one_file.split('.')[-1]
if file_type == 'md':
loader = UnstructuredMarkdownLoader(one_file)
elif file_type == 'txt':
loader = UnstructuredFileLoader(one_file)
else:
# 如果是不符合条件的文件,直接跳过
continue
docs.extend(loader.load())
return docs
# 目标文件夹
tar_dir = [
"/root/data/InternLM",
"/root/data/InternLM-XComposer",
"/root/data/lagent",
"/root/data/lmdeploy",
"/root/data/opencompass",
"/root/data/xtuner"
]
# 加载目标文件
docs = []
for dir_path in tar_dir:
docs.extend(get_text(dir_path))
# 对文本进行分块
# 每500个字符进行分块,两块的重叠部分为150.
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, chunk_overlap=150)
split_docs = text_splitter.split_documents(docs)
# 加载开源词向量模型
embeddings = HuggingFaceEmbeddings(model_name="/root/data/model/sentence-transformer")
# 构建向量数据库
# 定义持久化路径
persist_directory = 'data_base/vector_db/chroma'
# 使用向量数据库Chroma,基于上文分块后的文档、加载的开源向量化模型,将语料加载到指定路径下。
vectordb = Chroma.from_documents(
documents=split_docs,
embedding=embeddings,
persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上
)
# 将加载的向量数据库持久化到磁盘上
vectordb.persist()
任意打开一个md文件,如下所示:

4-7、InternLM 接入 LangChain
概述:需要基于本地部署的 InternLM,继承 LangChain 的 LLM 类自定义一个 InternLM的LLM子类,(从LangChain.llms.base.LLM 类继承一个子类,并重写构造函数与 _call 函数即可)从而实现将 InternLM 接入到 LangChain 框架中。完成 LangChain 的自定义 LLM 子类之后,可以以完全一致的方式调用 LangChain 的接口。
完整代码如下:后续我们将以下代码封装为 LLM.py,后续将直接从该文件中引入自定义的 LLM 类。
from langchain.llms.base import LLM
from typing import Any, List, Optional
from langchain.callbacks.manager import CallbackManagerForLLMRun
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
class InternLM_LLM(LLM):
# 基于本地 InternLM 自定义 LLM 类
tokenizer : AutoTokenizer = None
model: AutoModelForCausalLM = None
def __init__(self, model_path :str):
# model_path: InternLM 模型路径
# 从本地初始化模型
super().__init__()
print("正在从本地加载模型...")
# 实例化一开始就加载本地部署的LLM模型
# 避免之后每一次调用加载时间太长。
self.tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
self.model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True).to(torch.bfloat16).cuda()
#
self.model = self.model.eval()
print("完成本地模型的加载")
def _call(self, prompt : str, stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any):
# 重写调用函数
# LangChain 会调用该函数来调用 LLM
system_prompt = """You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.
"""
messages = [(system_prompt, '')]
response, history = self.model.chat(self.tokenizer, prompt , history=messages)
return response
@property
def _llm_type(self) -> str:
return "InternLM"
4-8、构建检索问答链
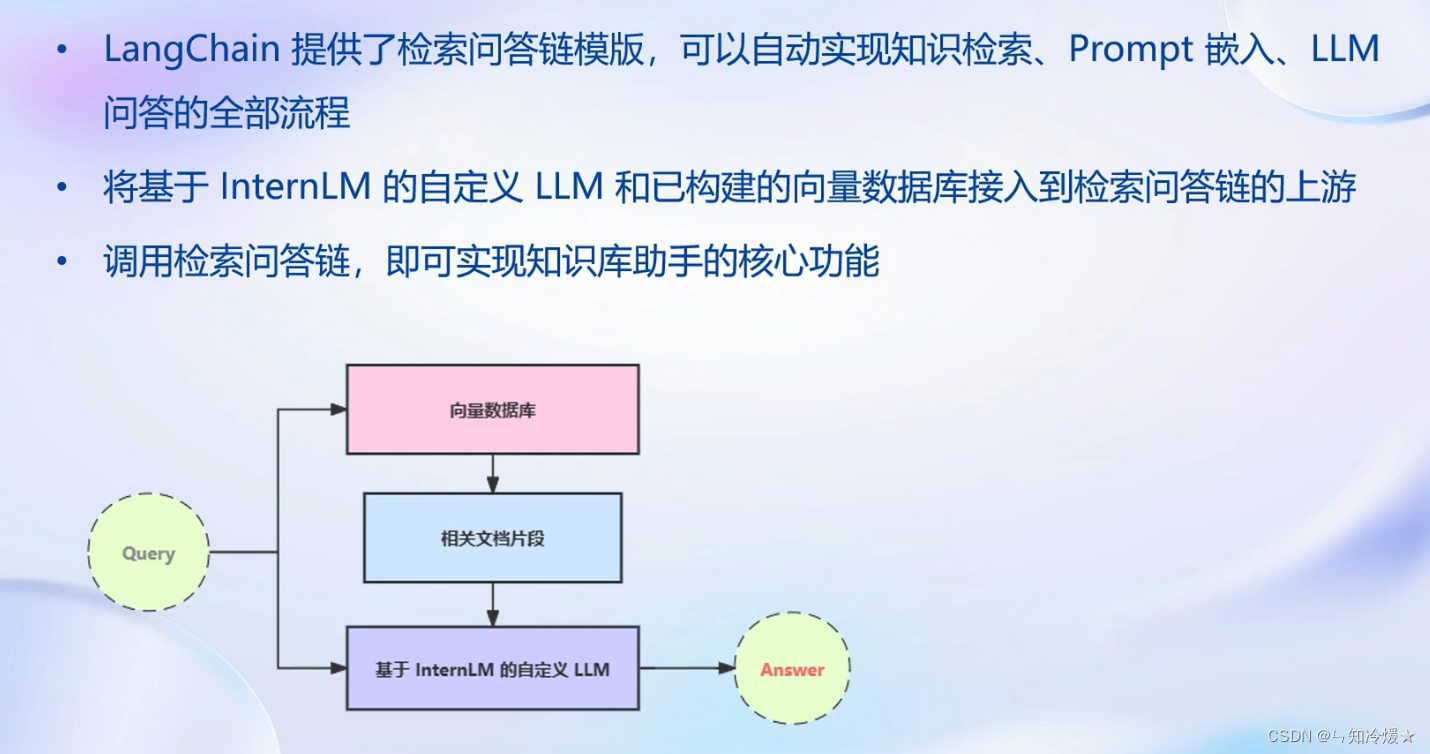
检索问答链: 即通过一个对象完成检索增强问答(即RAG)的全流程, 通过调用一个 LangChain 提供的 RetrievalQA 对象,通过初始化时填入已构建的数据库和自定义 LLM 作为参数,来简便地完成检索增强问答的全流程,LangChain 会自动完成基于用户提问进行检索、获取相关文档、拼接为合适的 Prompt 并交给 LLM 问答的全部流程。以下为构建流程:
1、加载向量数据库,需要两个参数:向量数据库持久化路径以及词嵌入模型sentence-transformer,得到已经构建好的向量数据库对象vectordb。该对象可以针对用户的 query 进行语义向量检索,得到与用户提问相关的知识片段。
2、通过InternLM_LLM实例化一个基于InternLM自定义的LLM对象。
3、构建一个提示词模板,这个过程会将检索到的相关文档片段填入到变量context中去,从而实现带上下文的prompt构建。
4、调用 LangChain 提供的检索问答链构造函数,基于我们的自定义 LLM、Prompt Template 和向量知识库来构建一个基于 InternLM 的检索问答链。
5、效果检测,仅仅是LLM的回答效果和检索问答链的效果对比。
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from LLM import InternLM_LLM
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
import os
# 定义 Embeddings
embeddings = HuggingFaceEmbeddings(model_name="/root/data/model/sentence-transformer")
# 向量数据库持久化路径
persist_directory = 'data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma(
persist_directory=persist_directory,
embedding_function=embeddings
)
# 通过InternLM_LLM实例化一个基于InternLM自定义的LLM对象。
llm = InternLM_LLM(model_path = "/root/data/model/Shanghai_AI_Laboratory/internlm-chat-7b")
llm.predict("你是谁")
# 我们所构造的 Prompt 模板
# 构建一个提示词模板,这个过程会将检索到的相关文档片段填入到变量context中去,从而实现带上下文的prompt构建。
template = """使用以下上下文来回答用户的问题。如果你不知道答案,就说你不知道。总是使用中文回答。
问题: {question}
可参考的上下文:
···
{context}
···
如果给定的上下文无法让你做出回答,请回答你不知道。
有用的回答:"""
# 调用 LangChain 的方法来实例化一个 Template 对象,该对象包含了 context 和 question 两个变量,在实际调用时,这两个变量会被检索到的文档片段和用户提问填充
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],template=template)
qa_chain = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),return_source_documents=True,chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})
# 效果对比
# 检索问答链回答效果
question = "什么是InternLM"
result = qa_chain({"query": question})
print("检索问答链回答 question 的结果:")
print(result["result"])
# 仅 LLM 回答效果
result_2 = llm(question)
print("大模型回答 question 的结果:")
print(result_2)
以下为构建检索问答链流程图:
4-9、部署WebDemo
部署WebDemo: 上述功能测试完成后 ,我们将基于Gradio 框架将其部署到 Web 网页,从而搭建一个小型 Demo。最后映射到本地,详细映射方法见附录。
1、将上文的代码内容封装为一个返回构建的检索问答链对象的函数,并在启动 Gradio 的第一时间调用该函数得到检索问答链对象,后续直接使用该对象进行问答对话,从而避免重复加载模型
2、定义一个类,该类负责加载并存储检索问答链,并响应 Web 界面里调用检索问答链进行回答的动作
3、按照 Gradio 的框架使用方法,实例化一个 Web 界面并将点击动作绑定到上述类的回答方法
4、使用python启动该脚本,并映射到本地,详细映射方法见附录。
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
import os
from LLM import InternLM_LLM
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
def load_chain():
# 加载问答链
# 定义 Embeddings
embeddings = HuggingFaceEmbeddings(model_name="/root/data/model/sentence-transformer")
# 向量数据库持久化路径
persist_directory = 'data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma(
persist_directory=persist_directory, # 允许我们将persist_directory目录保存到磁盘上
embedding_function=embeddings
)
# 加载自定义 LLM
llm = InternLM_LLM(model_path = "/root/data/model/Shanghai_AI_Laboratory/internlm-chat-7b")
# 定义一个 Prompt Template
template = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答
案。尽量使答案简明扼要。总是在回答的最后说“谢谢你的提问!”。
{context}
问题: {question}
有用的回答:"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],template=template)
# 运行 chain
qa_chain = RetrievalQA.from_chain_type(llm,retriever=vectordb.as_retriever(),return_source_documents=True,chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})
return qa_chain
class Model_center():
"""
存储检索问答链的对象
"""
def __init__(self):
# 构造函数,加载检索问答链
self.chain = load_chain()
def qa_chain_self_answer(self, question: str, chat_history: list = []):
"""
调用问答链进行回答
"""
if question == None or len(question) < 1:
return "", chat_history
try:
chat_history.append(
(question, self.chain({"query": question})["result"]))
# 将问答结果直接附加到问答历史中,Gradio 会将其展示出来
return "", chat_history
except Exception as e:
return e, chat_history
import gradio as gr
# 实例化核心功能对象
model_center = Model_center()
# 创建一个 Web 界面
block = gr.Blocks()
with block as demo:
with gr.Row(equal_height=True):
with gr.Column(scale=15):
# 展示的页面标题
gr.Markdown("""<h1><center>InternLM</center></h1>
<center>书生浦语</center>
""")
with gr.Row():
with gr.Column(scale=4):
# 创建一个聊天机器人对象
chatbot = gr.Chatbot(height=450, show_copy_button=True)
# 创建一个文本框组件,用于输入 prompt。
msg = gr.Textbox(label="Prompt/问题")
with gr.Row():
# 创建提交按钮。
db_wo_his_btn = gr.Button("Chat")
with gr.Row():
# 创建一个清除按钮,用于清除聊天机器人组件的内容。
clear = gr.ClearButton(
components=[chatbot], value="Clear console")
# 设置按钮的点击事件。当点击时,调用上面定义的 qa_chain_self_answer 函数,并传入用户的消息和聊天历史记录,然后更新文本框和聊天机器人组件。
db_wo_his_btn.click(model_center.qa_chain_self_answer, inputs=[
msg, chatbot], outputs=[msg, chatbot])
gr.Markdown("""提醒:<br>
1. 初始化数据库时间可能较长,请耐心等待。
2. 使用中如果出现异常,将会在文本输入框进行展示,请不要惊慌。 <br>
""")
gr.close_all()
# 直接启动
demo.launch()
如下图所示:

4-10、RAG方案优化建议
1、基于RAG的问答系统性能核心受限于:
- 检索精度
- Prompt性能
2、一些可能的优化点:
- 检索方面:基于语义分割,保证每一个chunk的语义完整;给每一个chunk生成概括式索引,检索时匹配索引
- Prompt方面:迭代优化Prompt策略
附录
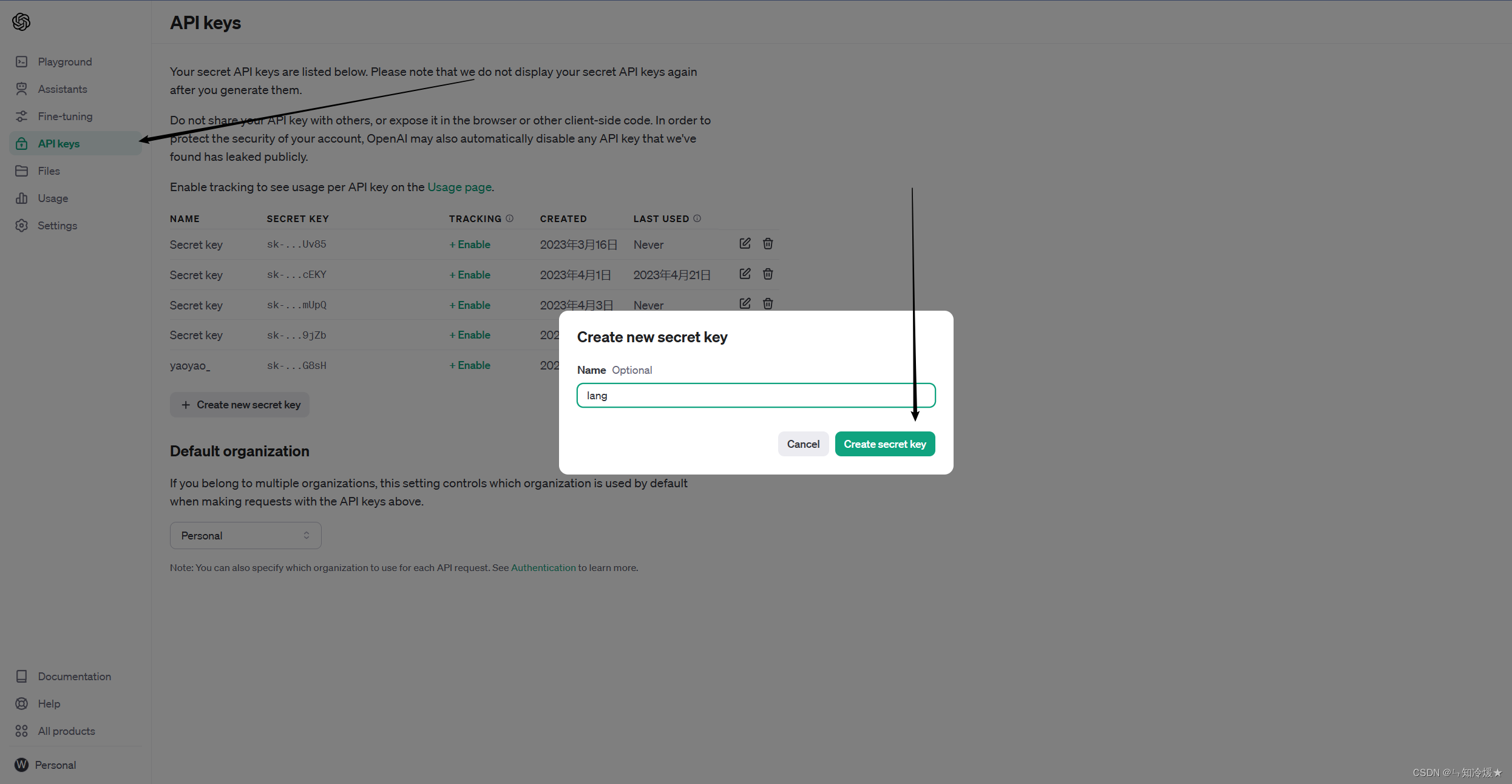
1、OpenAI密钥获取
登录OpenAI官网(谷歌账号登录就🆗):https://platform.openai.com/account/api-keys 详情页如下所示:

左侧API Keys栏,点击Create new secret key:
2、sentence-transformers框架介绍
概述:将句子或者段落映射到384维的密集向量空间,可以被用来执行聚类或者语义搜索任务。
详细来说:SentenceTransformers是一个用于将句子、段落、图像进行Embedding的python框架,可以用来计算100多种语言的Embedding,对于语义文本相似、语义搜索非常有用。
下图为官方文档:Sentence-BERT官方文档
依赖安装:
pip install -U sentence-transformers
直接使用:
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
embeddings = model.encode(sentences)
print(embeddings)
通过HuggingFace Transformers使用:
from transformers import AutoTokenizer, AutoModel
import torch
# Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
model = AutoModel.from_pretrained('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
3、配置本地端口(服务器端口映射到本地)
- 步骤一:本地打开命令行窗口生成公钥,全点击回车就ok(不配置密码)。
# 使用如下命令
ssh-keygen -t rsa
默认放置路径如下图所示:
-
步骤二:打开默认放置路径,复制公钥,在远程服务器上配置公钥。
-
步骤三:本地终端输入命令
# 6006是远程服务启动的端口号(如下图所示,远程启动的端口号为6006),33447是远程ssh连接的编号,
ssh -CNg -L 6006:127.0.0.1:6006 root@ssh.intern-ai.org.cn -p 33447
如下图所示:

4、向量数据库构建步骤
1、确定源文件类型
-
针对不同类型的源文件选用不同的加载器,
-
核心在于将带格式的文本转化为无格式的字符串。
2、对加载的文档进行切分
-
一般按字符串长度进行分割
-
可以手动控制分割块的长度和重叠区间长度
3、使用向量数据库来支持语义检索,需要将文档向量化存入向量数据库
-
可以使用任意一种Embedding模型来进行向量化。
-
可以使用多种支持语义检索的向量数据库,一般使用轻量级的Chroma。
参考文章:
LangChain–GitHub.
InternLM–GitHub.
Sentence-BERT论文
Sentence-BERT官方文档
Huggingface 镜像站
源文档
开源大模型食用指南:推荐
面向大语言模型的检索增强生成技术:调查 [译]
ACL 2023 教程:基于检索的语言模型和应用程序
总结
以上就是今天的全部内容了,结尾挂上今天生成的少女。ヽ(▽゚▽゚)ノ

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!