基于协同过滤的电影评论数据分析与推荐系统
温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :)?
1. 项目介绍
????????随着社会的发展,人们生活水平的提高,欣赏电影逐渐成为人们闲暇时的主要娱乐方式之一。本文电影推荐系统是为了给顾客提供方便快捷的热门电影推荐以及查询电影资讯而建立的,主要包括以下功能:电影分类、热门电影、最新上映、评分最高等信息。本文主要描述系统的分析与设计部分,包含了系统的业务分析、功能需求分析、数据流分析、非功能需求分析等内容。设计部分,包含了架构设计、功能结构设计、主要功能模块设计、数据库设计及界面设计等内容。
????????本电影推荐系统采用的数据库是Mysql,使用 Django框架开发。系统记录用户评论电影等行为数据,利用协同过滤算法,实现电影的个性化推荐。
基于Python的电影评论数据分析与推荐系统
?2.?协同过滤算法
????????基于协同过滤的两种推荐算法,核心思想是很朴素的”物以类聚、人以群分“的思想。所谓物以类聚,就是计算出每个标的物最相似的标的物列表,我们就可以为用户推荐用户喜欢的标的物相似的标的物,这就是基于物品(标的物)的协同过滤。所谓人以群分,就是我们可以将与该用户相似的用户喜欢过的标的物的标的物推荐给该用户(而该用户未曾操作过),这就是基于用户的协同过滤。

?????????协同过滤的核心是怎么计算标的物之间的相似度以及用户之间的相似度。
3.?基于协同过滤的电影评论数据分析与推荐系统
3.1 数据库结构设计
????????用户信息实体主要存储管理信息包括用户名、密码、重新输入密码,陆属性图如图4-5所示。

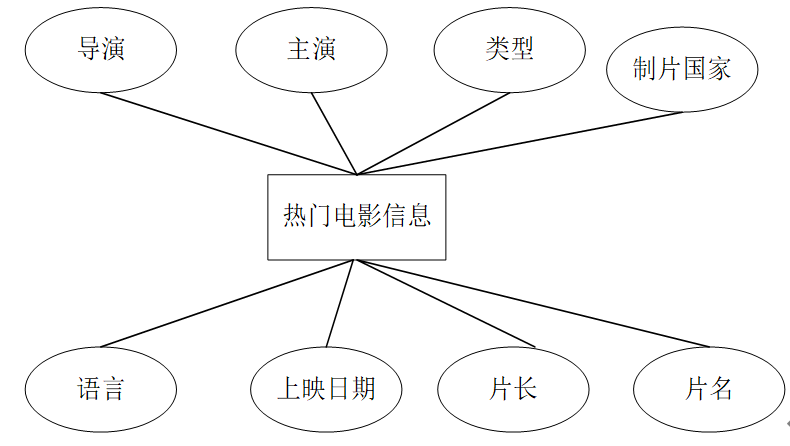
????????热门电影信息:导演、主演、类型、制片国家、语言、上映日期、片长、片名,实体属性图如图4-6所示。
3.2 用户注册登录

3.3 首页电影分类展示?

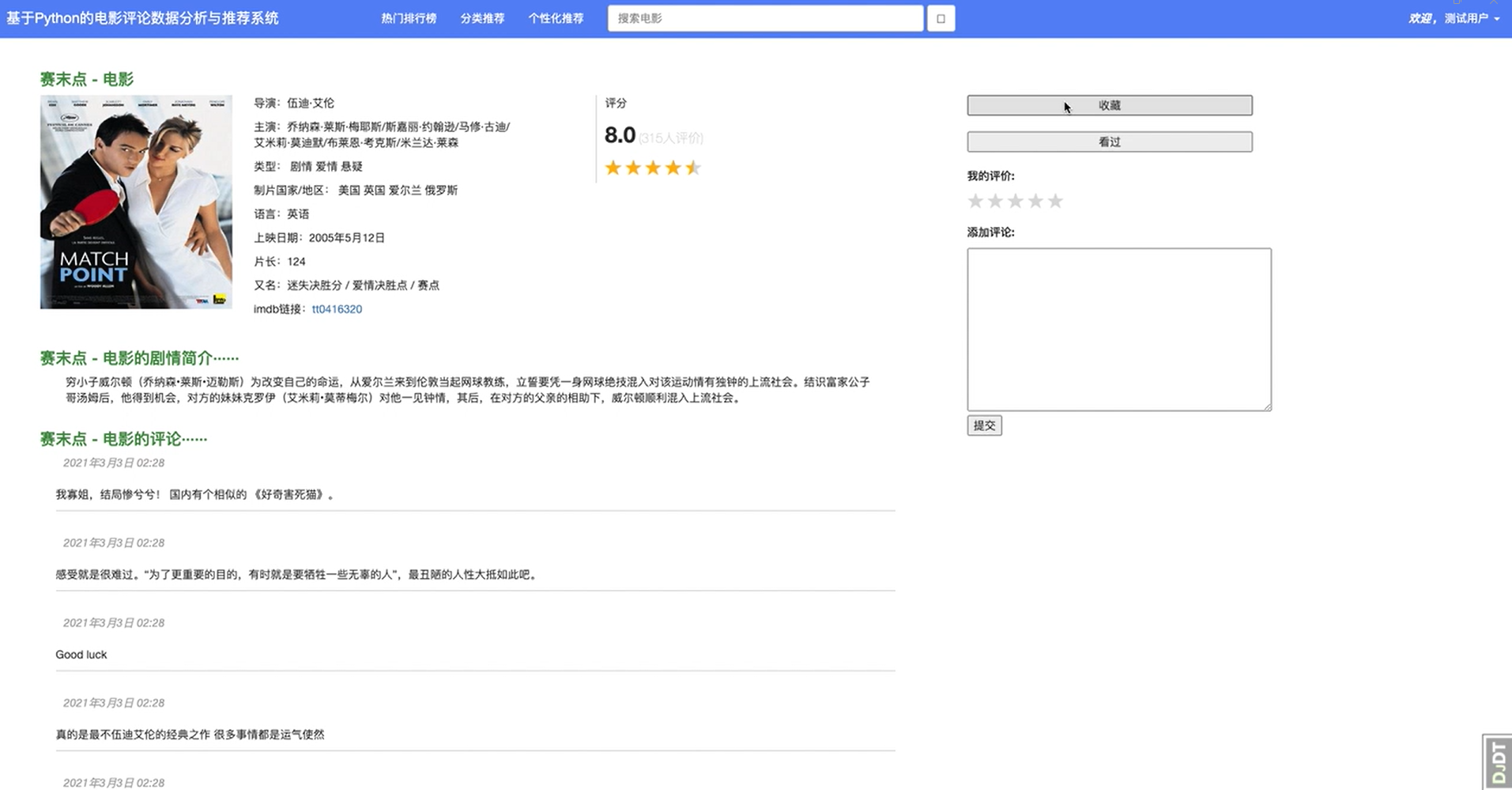
3.4 电影详情与收藏与评论
 3.5 收藏与评论电影列表
3.5 收藏与评论电影列表
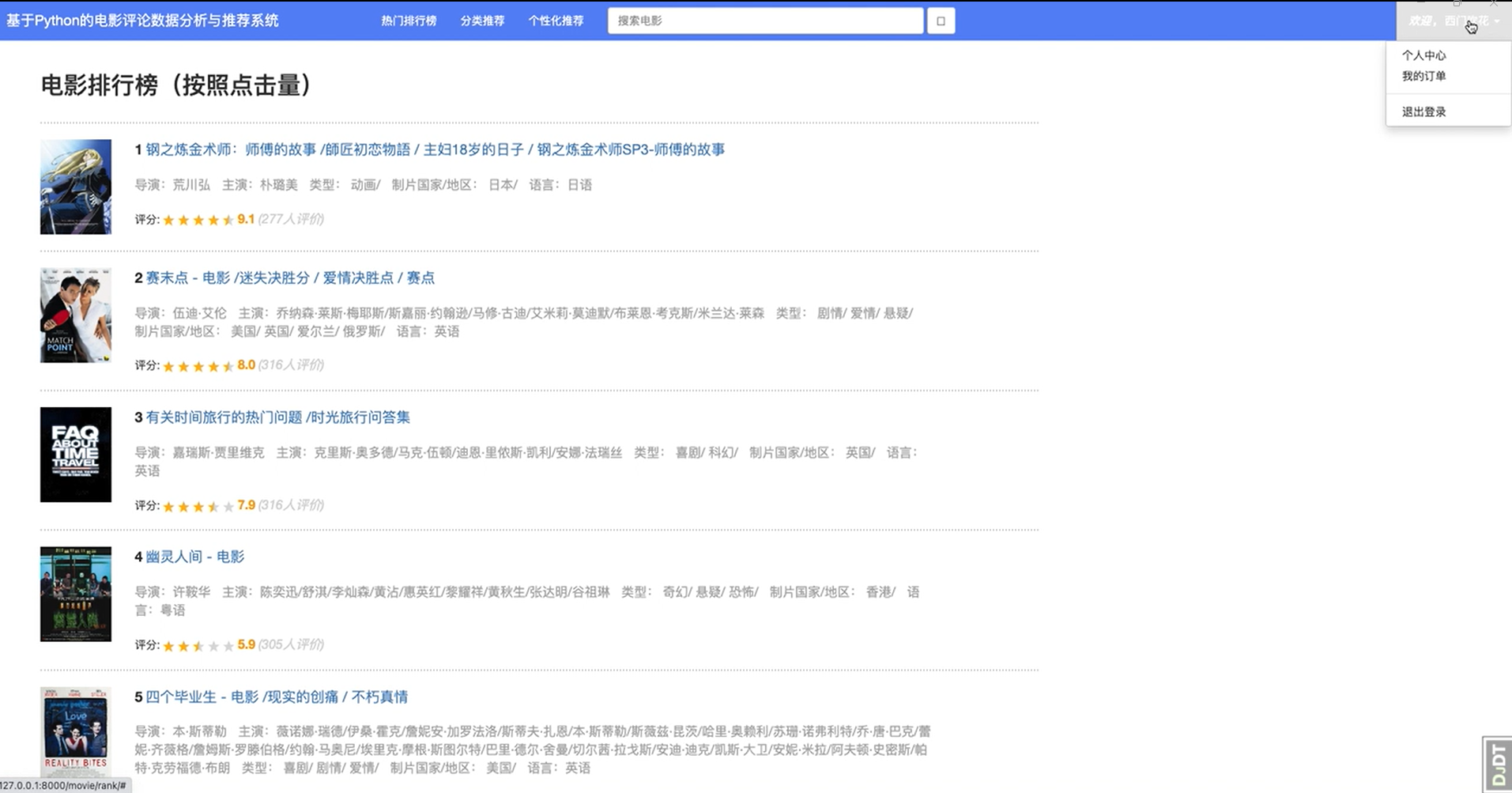
 3.6 电影点击量排行榜
3.6 电影点击量排行榜
 ?
?
3.7 个性化推荐
协调过滤核心算法部分代码:
def recommend(user:User, k):
sims_user_list = cal_user_sims(user, 5)
movie_set = set()
for sim_user_data in sims_user_list:
sim_user = sim_user_data['user']
sim_user_movies = set(sim_user.rating_set.values_list('movie_id', flat=True))
movie_set = movie_set | (sim_user_movies)
exclude_movie_set = set(user.rating_set.values_list('movie_id'))
movie_set = movie_set - exclude_movie_set
# print('movie_set', movie_set)
result = []
for movie_id in movie_set:
rating = 0
sum_sim = 0
for sim_user_data in sims_user_list:
sim_user = sim_user_data['user']
similarity = sim_user_data['similarity']
sim_user_rating = Rating.objects.filter(user=sim_user, movie_id=movie_id).first()
if sim_user_rating:
rating += similarity * (sim_user_rating.score-sim_user.userextra.rating_avg)
sum_sim += similarity
rating = user.userextra.rating_avg + rating/sum_sim
result.append({'movie_id': movie_id, 'rating':rating})
result = sorted(result, key=lambda result: result['rating'], reverse=True)
result = result[:k]
result = [Movie.objects.get(pk=i['movie_id']) for i in result]
return result ?
?
?4. 结论
? ? ? ? 本系统基于Python技术,使用UML建模,采用Django框架组合进行设计,Mysql数据库存储数据。本系统的功能主要包括:用户注册、登录、信息维护、搜索电影、电影评分、个性化推荐以及管理员进行信息管理等。个性化推荐功能使用基于用户的协同过滤算法和热点推荐来实现。开发工具主要有:Pycharm、Python3.8、Django3、mysql8、Navicat等。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。技术交流、源码获取认准下方?CSDN 官方提供的学长 QQ 名片 :)
精彩专栏推荐订阅:

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 矩阵微分笔记(1)
- Python基础语法详解,零基础入门必须掌握的知识点
- C#编程-自定义属性
- 学生信息管理系统winform+sqlserver
- vivado 在非项目模式下使用源、读取各种源文件的非项目模式脚本示例
- 虚拟机VMware安装Linux
- Linux具体命令(三)
- 机器人行业数据闭环实践:从对象存储到 JuiceFS
- [SWPUCTF 2022 新生赛]1z_unserialize
- 微盛·企微管家:用户运营API集成,电商无代码解决方案