爬虫入门学习(二)——response对象

大家好!我是码银,代码的码,银子的银🥰
欢迎关注🥰:
CSDN:码银
公众号:码银学编程
前言?
在本篇文章,我们继续讨论request模块。从上一节(爬虫学习(1)--requests模块的使用-CSDN博客)中我们可以知道requests.get()?是 Python 的?requests?库中的一个方法,用于发送 HTTP GET 请求。那么使用requests.get()之后传回的数据类型是什么呢?
是Response对象,下面就让我们从认识一下Response对象开始学习吧😆!
正文
response对象
在?requests?库中,response?对象包含了服务器对请求的响应的所有信息。以下是一些常用的?response?对象属性:
response.status_code:HTTP状态码,例如200、404等。response.headers:响应头,是一个字典,包含了服务器返回的所有头部信息。response.text:响应内容,以字符串形式返回。response.json():如果响应内容是JSON格式,可以使用这个方法将其解析为Python对象。response.content:响应内容,以字节形式返回。response.cookies:响应的cookies,是一个字典,包含了所有的cookies。response.url:响应的URL,即请求的URL。
以上是?requests?库中?response?对象的一些常用属性。更多详细的信息可以在?requests?库的文档中找到。
1、查看访问网页是否成功?
import requests # 导入requests模块
response = requests.get('https://blog.csdn.net/weixin_53197693/article/details/131499857')
#response = requests.get('https://requests.readthedocs.io/projects/cn/zh-cn/latest/%E3%80%82')
if response.status_code == requests.codes.ok:
print("取得网页内容成功")
else:
print("取得网页内容失败")
print("HTTP状态码:",response.status_code)访问成功截图:?

?访问失败截图:

2、取得网页内容
import requests # 导入requests模块
response = requests.get('https://requests.readthedocs.io/en/latest/')
if response.status_code == requests.codes.ok:
print("取得网页内容成功")
else:
print("取得网页内容失败")
print("HTTP状态码:",response.status_code)
print("网页的内容大小是:",len(response.text))
print(response.text)#输出网页源代码
?这段代码的功能是发送一个HTTP GET请求到指定的URL,并获取返回的网页内容。然后,它会检查返回的HTTP状态码,如果状态码是200(表示请求成功),则打印“取得网页内容成功”,否则打印“取得网页内容失败”。接下来,它打印HTTP状态码和网页内容的长度(以字节为单位)。最后,它打印出整个网页的内容。?
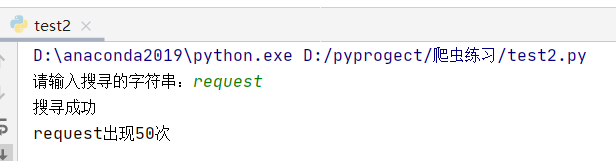
搜索网页特定内容
?获取内容,然后根据用户输入的字符串进行搜索。如果搜索成功,它会输出“搜寻成功”,否则输出“搜寻失败”。接着,它会使用正则表达式对搜索结果进行进一步处理,统计用户输入的字符串在网页内容中出现的次数,并输出这个次数。
import requests # 导入requests模块
import re
response = requests.get('https://requests.readthedocs.io/en/latest/')
if response.status_code == requests.codes.ok:
a=input("请输入搜寻的字符串:")
if a in response.text:
print("搜寻成功")
else:
print("搜寻失败")
name = re.findall(a, response.text)
if name !=None:
print("%s出现%d次" % (a, len(name)))
else:
print("%s出现0次" % a)
?
?出错的异常处理
使用?try/except?块来处理网络请求可能出现的异常是一个很好的做法。这样,如果请求失败,程序不会崩溃,而是会捕获异常并给出相应的错误信息。?
import requests # 导入requests模块
import re
try:
response = requests.get('https://requests.readthedocs.io/en/latest/')
response.raise_for_status() # 如果响应状态码不是200,主动抛出HTTPError异常
a = input("请输入搜寻的字符串:")
if a in response.text:
print("搜寻成功")
else:
print("搜寻失败")
name = re.findall(re.escape(a), response.text) # 使用re.escape()来确保用户输入被当作普通字符串处理
if name:
print("%s出现%d次" % (a, len(name)))
else:
print("%s出现0次" % a)
except requests.exceptions.RequestException as err:
# 捕获所有requests可能抛出的异常
print("网络请求出错:", err)
except Exception as err:
# 捕获其他所有未被上述except捕获的异常
print("发生未知错误:", err)小结
本篇文章中主要介绍了response对象的一些属性、如何搜索网页特定内容和使用try/except处理网络请求可能出现的异常。
日日行,不怕千万里;常常做,不怕千万事。——金樱
推荐一本好书?

购买链接:《Python从入门到精通(第3版)》(明日科技)【简介_书评_在线阅读】 - 当当图书?
在视频生成即将迎来技术和应用大爆发之际,为了帮助企业和广大从业者掌握技术前沿,把握时代机遇,机器之心AI论坛就将国内的视频生成技术力量齐聚一堂,共同分享国内顶尖力量的技术突破和应用实践。
论坛将于2024.01.20在北京举办,现场汇聚领域内专家和一线开发者,期待能为视频生成领域呈现一场高质量、高水平的线下交流活动。
本次活动大咖云集,分享内容中的很多模型/工具都是首次对外进行技术拆解与分享。快来报名,抓住站在浪潮之巅的机会吧。
了解国内视频生成的最新技术进展和应用实践,机器之心 AI 技术论坛将会是一次不错的机会。
活动日程(直达链接:https://hdxu.cn/RmNWu)

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 调用导致堆栈不对称。原因可能是托管的 PInvoke 签名与非托管的目标签名不匹配。请检查 PInvoke 签名的调用约定和参数与非托管的目标签名是否匹配
- 2024.1.3 Spark架构角色和提交任务流程
- 大数据存储技术(4)—— NoSQL数据库
- [音视频]H264码流分析工具
- 新型智慧视频监控系统:基于TSINGSEE青犀边缘计算AI视频识别技术的应用
- Docker(yum)安装
- mac 中vscode设置root启动
- 迭代器模式介绍
- CAN信号发送与APP SWC组件的Port接口映射与连接
- STIMULSOFT Ultimate 2024.1.1 Crack