NLP论文阅读记录 - 2021 | WOS 使用分层多尺度抽象建模和动态内存进行抽象文本摘要
文章目录
前言

Abstractive Text Summarization with Hierarchical Multi-scale Abstraction Modeling and Dynamic Memory(2107)
在本文中,我们提出了一种新颖的抽象文本摘要方法,具有分层多尺度抽象建模和动态记忆(称为 MADY)。首先,我们提出了一种分层多尺度抽象建模方法,从多个抽象层次中捕获文档的时间依赖性,该方法通过学习低级抽象层的精细时间尺度和粗略时间尺度来模仿人类如何理解文章的过程。高级抽象层的时间尺度。通过应用这种自适应更新机制,高级抽象层的更新频率较低,并且期望比低级抽象层更好地记住长期依赖关系。其次,我们提出了一个动态键值记忆增强注意力网络来跟踪输入文档中显着方面的注意力历史和综合上下文信息。通过这种方式,我们的模型可以避免生成重复的单词和错误的摘要。对两个广泛使用的数据集进行的大量实验证明了所提出的 MADY 模型在自动评估和人工评估方面的有效性。为了重现性,我们在以下位置提交代码和数据:https://github.com/siat-nlp/MADY.git。
0、论文摘要
一、Introduction
抽象文本摘要旨在生成简洁的摘要,保留源文章的显着信息和整体含义。与从输入文档中提取最佳摘要成分的提取文本摘要相反,抽象摘要可能包含源文档中未出现的新短语和句子。抽象文本摘要由于其在自然语言处理(NLP)和信息检索(IR)中的广泛应用而最近引起了越来越多的关注。近年来,序列到序列(seq2seq)模型主导了抽象文本摘要的研究[9,15,16,18,19]。这些方法背后的总体思想是采用长短期记忆(LSTM)网络[7]来获得固定长度的句子表示,然后使用另一个 LSTM 解码器和注意力机制生成摘要。
尽管人们在抽象文本摘要方面付出了巨大的努力[1,10,19,21],但由于两个主要原因,生成准确、简洁、信息丰富的摘要在实践中仍然是一个挑战。首先,一篇文章,尤其是一篇长文档,通常由在抽象层次上讨论的多个方面组成[20]。为了理解文章中的分层多方面信息,需要分层多尺度抽象挖掘来编码不同时间尺度的时间依赖性,这是以前的方法中没有利用的。其次,序列到序列模型(seq2seq)中使用的传统注意力机制无法有效地跟踪注意力历史,以学习源文章的神经表示与相应摘要之间的动态对齐[12]。我们认为,缺乏全面的信息(注意力历史)可能会导致抽象文本摘要出现两个问题:(i)生成令人费解的单词,其中一些子主题被不必要地多次访问;(ii)生成错误的摘要,其中一些显着信息被错误地未探索。
为了缓解上述挑战,在本研究中,我们提出了一种新颖的 MADY 方法,用于具有分层多尺度抽象建模和动态记忆的抽象文本摘要。 MADY 通过研究人类如何理解具有抽象层次的文档并基于动态工作记忆编写摘要,改进了 seq2seq 模型的编码和解码步骤。在编码中,我们建议分层多尺度抽象建模 (HMAM) 模型,用于捕获源文档的多个抽象层次。具体来说,我们用不同的时间尺度对时间依赖性进行编码,这是由于高级抽象变化缓慢而低级抽象具有快速变化的特征这一事实。在解码中,我们提出了动态键值记忆增强注意力(DMA)来缓解生成重复单词和不完整摘要的问题,这使得模型能够跟踪源文档中每个显着方面的综合信息。
1.3本文贡献
总之,我们的贡献如下:
(1)我们提出了一种分层多尺度模式挖掘方法,从多个抽象层次级别捕获文档的时间依赖性。 (2)我们采用动态键值记忆增强注意力机制来更好地跟踪注意力历史和显着信息覆盖范围,通过自动区分哪些显着方面已被描述和哪些显着方面已被描述,有助于解码器克服生成重复和错误摘要的问题哪些显着方面尚未探索。 (3) 在两个基准数据集上的实验表明,所提出的 MADY 方法在自动评估和人工评估方面都明显优于强大的竞争对手。
二.前提
三.本文方法
四 实验效果
4.1数据集
4.2 对比模型
4.3实施细节
4.4评估指标
4.5 实验结果
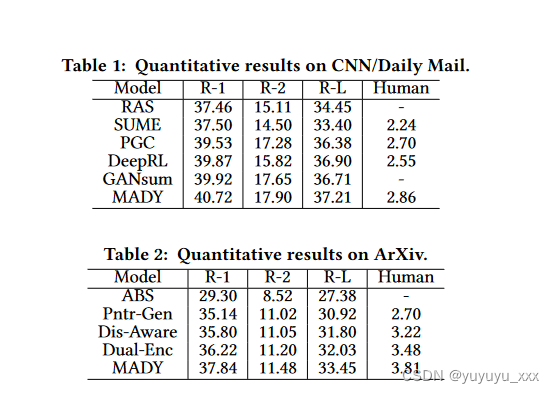
4.6 细粒度分析
五 总结
在本文中,我们通过研究人类如何理解具有层次抽象级别的源文档并基于动态工作记忆编写摘要,提出了一种新颖的抽象文本摘要 MADY 模型,该模型采用分层多尺度抽象建模方法和动态记忆。两个基准数据集的实验结果表明,MADY 显着优于对比方法。
思考
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Vue— Echarts 多系列柱状图,堆叠柱状图, 水球图
- MySQL数据库 DML
- 轻松管理固定资产,易点易动固定资产管理系统为企业开启新篇章
- AI客服的评分机制及自动化测试
- 【python】合并具有相同数字前缀的 CSV 文件
- 设计模式-工厂方法模式
- 深入了解Redis:性能、应用场景与常见问题解决方案
- C# FreeSql使用,基于Sqlite的DB Frist和Code First测试
- 用通俗易懂的方式讲解:OpenAI 新版 API 使用介绍,帮助大家快速解锁这些新功能
- 微信小程序页面传值的几种方式